
ประเด็นสำคัญ:
- ทำไมถึงสำคัญ: คุณภาพการแปลมีผลต่อความไว้วางใจ, การปฏิบัติตามกฎระเบียบ, และรายได้ อุตสาหกรรมเช่นการแพทย์ (ความแม่นยำ 99.9%) และกฎหมาย (ความแม่นยำ 98%) ต้องการความแม่นยำสูง
-
เป้าหมายหลักของการทดสอบ:
- ความแม่นยำของความหมาย: เครื่องมืออย่าง COMET สอดคล้องกับการประเมินของมนุษย์ 89% ของเวลา
- ความสม่ำเสมอของศัพท์เฉพาะ: ด้านกฎหมายต้องการความสม่ำเสมอในศัพท์เฉพาะถึง 99.5%
- การปรับตัวทางวัฒนธรรม: เนื้อหาที่ปรับให้เหมาะสามารถเพิ่มการเก็บผู้ใช้ได้ 34%
-
มาตรวัด & เครื่องมือ:
- แบบดั้งเดิม: BLEU, TER, ROUGE (เช่น BLEU ≥0.4 สำหรับใช้งาน)
- ขั้นสูง: COMET (ความสัมพันธ์ 0.81 กับคะแนนมนุษย์) และ MQM สำหรับการจัดประเภทข้อผิดพลาดอย่างละเอียด
-
ความท้าทาย:
- ข้อผิดพลาดด้านบริบท, ภาษาทรัพยากรต่ำ, และข้อมูลการฝึกฝนล้าสมัย
- ตัวอย่าง: การเพิ่มข้อมูลโซเชียลมีเดียช่วยเพิ่มความแม่นยำในการแปลภาษาเคิร์ดได้ 45%
-
แนวทางแก้ไข:
- ระบบการเรียนรู้เชิงรับช่วยลดข้อผิดพลาดโดยการติดธงผลลัพธ์ที่มีความมั่นใจต่ำ
- การผสมผสานเครื่องมือ AI กับการตรวจสอบของมนุษย์ช่วยเพิ่มอัตราการตรวจพบข้อบกพร่องได้ถึง 91%
การเปรียบเทียบมาตรวัดอย่างรวดเร็ว:
| มาตรวัด | พื้นที่โฟกัส | กรณีการใช้ & เกณฑ์ |
|---|---|---|
| BLEU | ความแม่นยำของเอ็นแกรม | การตรวจสอบรวดเร็ว, คะแนน ≥0.4 |
| TER | ระยะติ่งแก้ไข | ระดับมืออาชีพ, <9% ที่ต้องการ |
| ROUGE | การวัดการเรียก | การตรวจสอบเนื้อหา, ช่วง 0.3-0.5 |
| COMET | การประเมินความหมาย | ความสัมพันธ์ที่แข็งแรง (0.81) |
| MQM | การจัดประเภทข้อผิดพลาด | รายละเอียดระดับองค์กร |
คู่มือนี้อธิบายวิธีที่ธุรกิจสามารถรวมระบบอัตโนมัติและความเชี่ยวชาญของมนุษย์เพื่อให้ได้การแปลที่ปรับปริมาณได้, แม่นยำ, และเกี่ยวข้องกับวัฒนธรรม
มาตรวัดการวัดคุณภาพ
เครื่องมือสมัยใหม่ผสมผสานระบบอัตโนมัติกับความเชี่ยวชาญของมนุษย์เพื่อส่งมอบการแปลที่แม่นยำและรู้เท่าทันบริบท มาตรวัดเหล่านี้ออกแบบมาเพื่อให้บรรลุวัตถุประสงค์หลัก เช่น ความแม่นยำทางความหมาย, ความสม่ำเสมอของศัพท์เฉพาะ, และการปรับให้เข้ากับความแตกต่างทางวัฒนธรรม
มาตรวัดพื้นฐาน: BLEU, TER, ROUGE
มาตรวัดหลักสามตัวเป็นส่วนสำคัญของการทดสอบคุณภาพการแปล:
| มาตรวัด | พื้นที่โฟกัส | กรณีการใช้ & เกณฑ์ |
|---|---|---|
| BLEU | ความแม่นยำของเอ็นแกรม | การตรวจสอบรวดเร็ว, คะแนน ≥0.4 ใช้ได้ |
| TER | ระยะติ่งแก้ไข | ระดับมืออาชีพ, <9% ที่ต้องการ |
| ROUGE | การวัดการเรียก | การตรวจสอบเนื้อหา, ช่วง 0.3-0.5 |
การแปลที่ได้คะแนนเกิน 0.6 ใน BLEU มักเกินมูลค่ามาตรฐานของมนุษย์ อย่างไรก็ตาม การศึกษาในปี 2023 เผยว่า BLEU มีข้อจำกัด: BLEU แบบอ้างอิงเดียวมีความสัมพันธ์อ่อนกับการตัดสินของมนุษย์ (r=0.32) ในขณะที่การตั้งค่าหลายอ้างอิงทำงานได้ดีกว่า (r=0.68)
มาตรวัดใหม่: COMET และ MQM
กรอบงานใหม่ตอบโจทย์ช่องว่างในมาตรวัดแบบดั้งเดิม COMET ใช้กำลังของเครือข่ายประสาทเพื่อประเมินความหมายและดำเนินความสัมพันธ์ที่แข็งแรง 0.81 กับคะแนนมนุษย์ในมาตรฐาน WMT2022 - ดีกว่า BLEU ที่มีความสัมพันธ์ 0.45 มาก
MQM แบ่งข้อผิดพลาดออกเป็นหมวดหมู่เช่น ความแม่นยำ, ความไหลลื่น, และศัพท์เฉพาะ, โดยให้ความถ่วงน้ำหนักแบบความรุนแรง วิธีการที่ละเอียดนี้มีประโยชน์พิเศษสำหรับการแปลระดับองค์กร
การทดสอบด้วยเครื่องจักร vs. มนุษย์
แนวทางที่สมดุลผสมผสานการประเมินของเครื่องจักรและมนุษย์เป็นสิ่งจำเป็น ผู้นำในอุตสาหกรรมนำลำดับการทำงานเช่นนี้มาใช้:
"การกรอง TER เริ่มต้น → การประเมินความหมายของ COMET → การแก้ไขภายหลังของมนุษย์สำหรับคะแนน COMET <0.8 → การทบทวนของลูกค้าครั้งสุดท้าย วิธีการนี้ลดค่าใช้จ่ายในการประเมินลง 40% ขณะที่ยังคงความสอดคล้องคุณภาพ 98%".
สำหรับเนื้อหาที่มีความเชี่ยวชาญสูง ส่วนร่วมของมนุษย์ขาดไม่ได้ มาตรวัดในอนาคตเริ่มสนใจปัจจัยอย่างความสม่ำเสมอด้านบริบทและการจับโทนอารมณ์ ซึ่งจะนำไปสู่การจัดการกับความท้าทายที่เป็นจริงได้ ความก้าวหน้าเหล่านี้จะถูกกล่าวถึงเพิ่มเติมในส่วนถัดไปในประเด็นปัญหาการแปลทั่วไป
ปัญหาการแปลทั่วไป
ข้อมูลอุตสาหกรรมชี้ไปที่ความท้าทายสำคัญสามประการที่มักเกิดขึ้น:
บริบทและความหมาย
38% ที่สำคัญของการแปลที่ถูกประเมินด้วยมาตรวัด BLEU พื้นฐานต้องการการแทรกแซงของมนุษย์เมื่อต้องการจัดการกับสำนวน สิ่งนี้ปรากฎเด่นชัดในสภาพแวดล้อมมืออาชีพ
"คำผิดพลาดในสัญญาของ EU ที่แปลว่า 'ร่วมและรับผิดชอบเต็มที่' ทำให้เกิดความสูญเสียถึง €2.8M สืบเนื่องจากข้อมูลการฝึกอบรมด้านกฎหมายไม่ครบถ้วน การวิเคราะห์ภายหลังเหตุการณ์พบว่าการเพิ่มเอกสารกฎหมายที่ได้รับการรับรอง 15,000 ฉบับช่วยลดข้อผิดพลาดที่คล้ายกันได้ 78% "
เครื่องมืออย่างนักวิเคราะห์บริบทวิดีโอของ DubSmart ได้บรรลุความแม่นยำบริบทถึง 92% โดยการซิงค์การแปลสัญลักษณ์ด้วยคำพูดที่แปลแล้ว วิธีนี้ลดการแปลผิดเพศได้ 63% โดยการใช้การรู้จักฉาก-วัตถุ
ภาษาไม่ค่อยพบ
ภาษาที่มีทรัพยากรดิจิทัลน้อยเผชิญกับอุปสรรคพิเศษในคุณภาพการแปล นี่คือการแจกแจงว่าการมีทรัพยากรมีผลอย่างไรต่อประสิทธิภาพ:
| ระดับทรัพยากร | ผลกระทบต่อคุณภาพ | ประสิทธิภาพของแนวทางแก้ปัญหา |
|---|---|---|
| ภาษาทรัพยากรสูง | ประสิทธิภาพพื้นฐาน | การทดสอบมาตรฐานเพียงพอ |
| ภาษาทรัพยากรกลาง | ลดคุณภาพ 15% | การแปลกลับช่วยได้ |
| ภาษาทรัพยากรต่ำ | คะแนน TER สูงขึ้น 22% | ต้องการการเรียนรู้แบบถ่ายโอน |
การศึกษากรณีภาษาเคิร์ดเน้นว่าการเพิ่มข้อมูลโซเชียลมีเดียปรับปรุงความแม่นยำได้ 45% ยิ่งไปกว่านั้น การเรียนรู้การถ่ายโอนจากกลุ่มภาษาที่เกี่ยวข้องได้ลดความต้องการข้อมูลการฝึกฝนลง 30%
คุณภาพข้อมูลการฝึกอบรม
คุณภาพของข้อมูลการฝึกอบรมมีบทบาทสำคัญในความแม่นยำของการแปลโดยเฉพาะในสาขาที่เฉพาะเจาะจง การศึกษาในปี 2024 พบว่า 68% ของข้อผิดพลาดในการแปลทางการแพทย์เป็นผลมาจากความลำเอียงต่อศัพท์แพทย์ตะวันตกในชุดข้อมูลการฝึกฝน ความไม่สมดุลนี้ชัดเจน ด้วยอัตราส่วน 5:1 ที่ให้ความสำคัญกับข้อฺหมายตะวันตกมากกว่าแนวคิดแพทย์พื้นบ้าน
การแปลทางเทคนิคยังเผชิญกับความท้าทายที่ผูกพันกับข้อมูลล้าสมัย:
"พจนานุกรมเทคนิคที่เก่ากว่า 3 ปี แสดงอัตราข้อผิดพลาดสูงขึ้น 22% โครงการแปลคู่มือเซมิคอนดักเตอร์ต้องการการอัพเดททุกเดือนเพื่อรักษาข้อผิดพลาดของศัพท์น้อยกว่า 2%"
ระบบการเรียนรู้เชิงรับที่ติดธงศัพท์ล้าสมัยพิสูจน์แล้วว่ามีประสิทธิภาพ ลดภาระงานการทบทวนลง 37% โดยเฉพาะในโดเมนทางเทคนิค
ความท้าทายเหล่านี้เน้นความสำคัญของวิธีการทดสอบที่ใช้งานได้ในส่วนถัดไปเพื่อให้มั่นใจว่าคุณภาพการแปลยังคงสูง
การทดสอบในทางปฏิบัติ
วิธีการทดสอบที่ใช้งานได้จัดการกับความท้าทายของข้อมูลการฝึกฝนและบริบทผ่านกลยุทธ์ที่เน้นบางประการ:
DubSmart การแปลวิดีโอ
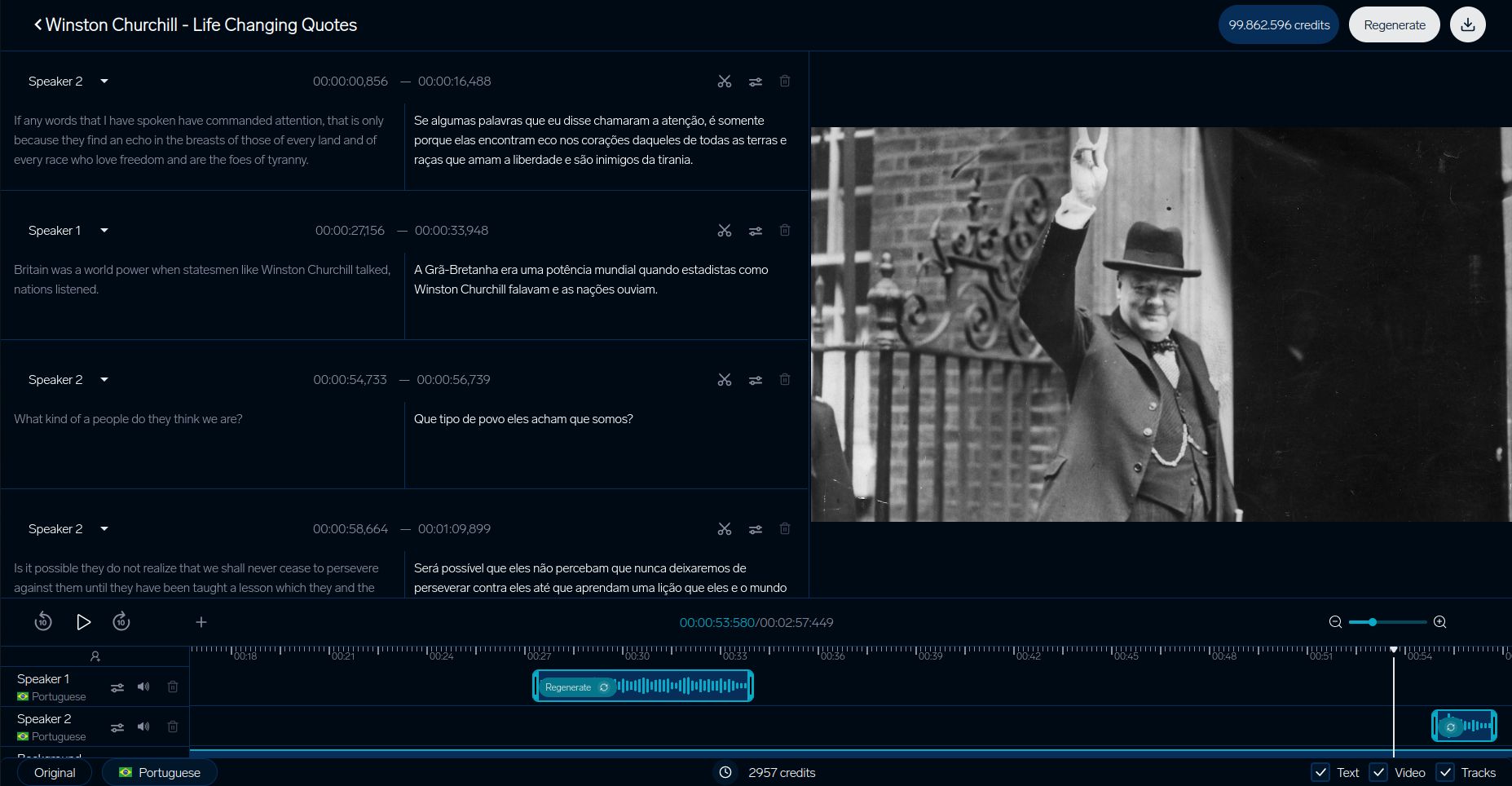
ระบบการทดสอบของ DubSmart แสดงให้เห็นว่าแพลตฟอร์มการแปลวิดีโอทำให้มั่นใจในคุณภาพอย่างไร กระบวนการที่ละเอียดของพวกเขามุ่งเน้นที่การประสานบริบทภาพ โดยเฉพาะการจัดการกับปัญหาการแปลผิดเพศที่กล่าวถึงก่อนหน้านี้:
| องค์ประกอบ | มาตรวัด |
|---|---|
| การซิงค์ริมฝีปาก | ความล่าช้าน้อยกว่า 200ms |
| การจับคู่เสียง | ความคล้ายคลึงกัน 93% |
| การซิงค์ภาพ | ข้อบกพร่องน้อยกว่า 5% |
กรณีศึกษาในธุรกิจ
บริษัทยักษ์ใหญ่ได้สร้างระบบการทดสอบขั้นสูงที่ผสมผสานเครื่องมือ AI กับความเชี่ยวชาญมนุษย์ การใช้กรอบงาน MQM-DQF ของ SAP เป็นตัวอย่างที่โดดเด่น:
"โดยการรวมเอาท์พุตของการแปลโดยใช้เครือข่ายธีรภาวะข่ายประสาทด้วยทีมตรวจสอบจากนักภาษาศาสตร์, SAP ได้บรรลุการลดภาระการแก้ไขภายหลังลง 40% ในขณะที่รักษาอัตราความแม่นยำ 98%".
IKEA ลดระยะเวลาในการนำบทแปลเข้าสู่ตลาดได้ถึง 35% โดยใช้การผสมผสานการตรวจสอบจากมนุษย์และ AI
Booking.com ยังแสดงให้เห็นถึงพลังของการทดสอบอัตโนมัติ ระบบของพวกเขาจัดการกับการแปลเกิน 1 พันล้านครั้งต่อปีใน 45 ภาษา, ลดค่าใช้จ่ายได้ 40% ขณะรักษาคุณภาพให้คงเส้นคงวาสำหรับเนื้อหาที่ผู้ใช้สร้าง
ตัวอย่างเหล่านี้แสดงให้เห็นว่าธุรกิจกำลังปรับปรุงความแม่นยำ, ประสิทธิภาพ, และความสามารถในการปรับปริมาณในกระบวนการทดสอบการแปล
sbb-itb-f4517a0
ขั้นตอนต่อไปในการทดสอบการแปล
เมื่อวิธีการทดสอบปรับปรุงขึ้น สามพื้นที่สำคัญกำลังผลักดันมาตรฐานคุณภาพไปสู่ระดับใหม่:
การถ่ายโทนอารมณ์
ระบบทันสมัยตอนนี้ดีกว่ามากในการรักษารายละเอียดของอารมณ์, ขอบคุณกรอบงาน EMO-BLEU ซึ่งมีความสัมพันธ์แบบเพียร์สัน 0.73 กับการรับรู้ของมนุษย์เมื่อเทียบกับ 0.41 ของ BLEU โมเดลทรานส์ฟอร์มเมอร์หลายโหมดได้ก้าวไกล, รักษาความเข้มข้นทางอารมณ์ให้อยู่ใน ±2dB ข้ามภาษาในขณะที่จัดการกับสัญลักษณ์อารมณ์ที่ซับซ้อน
การแปลตามบริบท
ระบบที่ใส่บริบทกำลังเปลี่ยนแปลงวิธีการประเมินคุณภาพการแปล ตัวอย่างที่ดีคือ Context Mode ของ DeepL ที่ใช้การติดตามเอนทิตี้ในระดับเอกสารและการปรับปรุงความสุภาพแบบเรียลไทม์
การทดสอบสำหรับระบบเหล่านี้ได้ก้าวไปสู่แบบทดสอบที่ก้าวหน้า โดยเน้นที่เกณฑ์มาตรฐานหลัก:
| องค์ประกอบการทดสอบ | เกณฑ์มาตรฐานปัจจุบัน | โฟกัสการวัดผล |
|---|---|---|
| การตอบคำแรก | <900ms | ความแม่นยำเริ่มต้นการพูด |
| คุณภาพการสตรีม | <4 word lag | ความต่อเนื่องของบัฟเฟอร์ |
| การปรับการบริบท | >0.8 คะแนน | การปรับตัวแบบไดนามิก |
ระบบเหล่านี้จัดการคู่ประโยคบริบทกว่า 100 ล้านคู่, พร้อมกับคำอธิบายชั้นที่หลากหลาย
เรียนรู้ระบบ AI
ระบบการแปลที่ปรับปรุงตัวเองกำลังเปลี่ยนแปลงวิธีการทดสอบคุณภาพโดยการรวมการตอบสนองด้านการตอบโต้ต่อเนื่อง กรอบงานของ Orq.ai เน้นการเปลี่ยนแปลงนี้ โดยลดค่าใช้จ่ายในการแก้ไขภายหลังลง 37% ไตรมาสหนึ่งผ่าน:
"สถาปัตยกรรมการเรียนรู้เชิงรุกที่ติดธงเซ็กเมนต์ที่มีความมั่นใจต่ำโดยใช้คะแนน COMET ต่ำกว่า 0.6, นำเสนอทางเลือกผ่าน UI ของรูปแบบการแก้ไขข้อผิดพลาด MQM และอัพเดทน้ำหนักโมเดลทุกสองสัปดาห์ด้วยตัวอย่างที่ได้รับการยืนยัน"
ระบบเหล่านี้ระบุการแปลที่มีความมั่นใจต่ำอัตโนมัติ (COMET <0.6) และอัพเดทโมเดลของมันทุกสองสัปดาห์โดยใช้ตัวอย่างที่ได้รับการยืนยันจากนักภาษาศาสตร์ อย่างไรก็ตาม พวกเขายังเผชิญกับความท้าทายด้านจริยธรรม การวิจัยจาก MIT แสดงการล่องลอยในความเท่าเทียมทางเพศ 22% โดยไม่มีมาตรการแก้ไขความลำเอียงที่เหมาะสม ปัญหานี้ผูกพันกับปัญหาข้อมูลการฝึกฝนที่มีความลำเอียง, เน้นความจำเป็นสำหรับโปรโตคอลการติดตามที่อัพเดท
เครื่องมือในอุตสาหกรรมเช่นกรอบงานมาตรฐานคุณภาพแบบไดนามิก v3.1 ของ TAUS ช่วยให้มั่นใจว่าระบบเหล่านี้สอดคล้องกับมาตรฐานที่กำลังก้าวหน้าอยู่เสมอ
สรุป
วิธีทดสอบหลัก
เทคนิคการทดสอบสมัยใหม่ได้เติบโตเกินกว่าการจับคู่เอ็นแกรมแบบง่ายและตอนนี้มุ่งเน้นไปที่การวิเคราะห์บริบท มาตรวัดแบบดั้งเดิมอย่าง BLEU, TER, และ ROUGE ยังคงให้ฐานรากสำหรับการประเมินพื้นฐาน อย่างไรก็ตาม, วิธีการใหม่ ๆ เช่น COMET และ MQM ได้พิสูจน์ว่าเข้ากับการตัดสินของมนุษย์ได้ดียิ่งขึ้น
เช่น กรอบงาน EMO-BLEU ได้แสดงให้เห็นว่ามาตรวัดอัตโนมัติสามารถได้ความสัมพันธ์ 73% กับการตัดสินของมนุษย์เมื่อประเมินวิธีที่เนื้อหาอารมณ์ได้รับการอนุรักษ์ ปัจจุบันการทดสอบคุณภาพเน้นไม่เพียงแต่ความแม่นยำทางเทคนิคเท่านั้น แต่ยังให้ความสำคัญกับการสอดคล้องกับความแตกต่างทางวัฒนธรรมด้วย โดยมีเป้าหมายหลักสำหรับการใช้งานระดับองค์กร
เครื่องมือและทรัพยากร
การทดสอบการแปลสมัยใหม่มักใช้แพลตฟอร์มที่นำวิธีการประเมินหลายแบบมารวมกัน ตัวอย่างหนึ่งคือ DubSmart ที่เสนอคุณสมบัติทดสอบที่หลากหลายและระบบตรวจสอบเนื้อหาขั้นสูง
องค์ประกอบหลักของการทดสอบที่มีประสิทธิภาพรวมถึง:
- COMET-based quality gates ที่มีเกณฑ์ต่ำกว่า 0.6
- คำศัพท์เฉพาะที่ผ่านการตรวจสอบความเกี่ยวข้องทางวัฒนธรรม
- ระบบการเรียนรู้เชิงรับที่อัพเดททุกสองสัปดาห์
สำหรับสาขาเฉพาะทาง เช่น การแพทย์, กฎหมาย, และเนื้อหาทางเทคนิค, การทดสอบจะผสมผสานมาตรวัดทั่วไปกับมาตรวัดเฉพาะที่ใช้ภายในอุตสาหกรรม วิธีการนี้ได้พัฒนาให้มีการปรับปรุงคุณภาพขึ้น 22% เมื่อใช้ระบบการประเมินรวมกัน
คำถามที่พบบ่อย
ข้อเสียของคะแนน BLEU คืออะไร?
คะแนน BLEU แม้จะได้รับการใช้งานอย่างแพร่หลาย มีข้อจำกัดที่สำคัญเมื่อใช้ในการประเมินคุณภาพการแปล นี่คือจุดอ่อนหลักของมัน:
| ข้อจำกัด | ผลบนการประเมินการแปล |
|---|---|
| ความบอดค้นหาความหมาย | เน้นเฉพาะการจับคู่คำ, ไม่สนใจความหมายหรือบริบท |
| การลงโทษรูปแบบที่หลากหลาย | ลงโทษการแปลที่ถูกต้องที่ใช้รูปแบบที่ต่างจากข้อความอ้างอิง |
เพื่อแก้ไขปัญหาเหล่านี้, แพลตฟอร์มโลคัลไลเซชันวิดีโอหลาย ๆ แห่งใช้การประเมินแบบผู้รวมกัน ตัวอย่างเช่น, นักวิเคราะห์บริบทของ DubSmart รวมเอาหลายมาตรวัดเข้าด้วยกันเพื่อให้การประเมินที่แม่นยำยิ่งขึ้น
"แม้ว่า BLEU จะให้การวัดระดับฐานได้, การทดสอบที่ครอบคลุมจำเป็นต้องการวิเคราะห์ความหมายและบริบท - โดยเฉพาะสำหรับการแปลที่สำคัญต่อธุรกิจ".
เพื่อความแม่นยำที่ดีกว่า, ผู้เชี่ยวชาญแนะนำให้:
- COMET สำหรับการประเมินความหมายและความสัมพันธ์
- การตรวจสอบของมนุษย์ เพื่อเข้าใจความแตกต่างทางวัฒนธรรม
- เครื่องมือเฉพาะภาษา เพื่อจัดการกับโครงสร้างไวยากรณ์ที่ซับซ้อน
วิธีการหลายชั้นนี้, เช่นที่ใช้โดย DubSmart, ผสมผสานเครื่องมืออัตโนมัติกับความเข้าใจของมนุษย์เพื่อให้มั่นใจว่าการแปลตรงตามมาตรฐานทั้งทางเทคนิคและบริบท