
แบบจำลองการจดจำเสียงพูดจะถูกตัดสินจากความแม่นยำในการถอดเสียงและการรักษาความหมายในสภาพที่แตกต่างกัน ตัวชี้วัดหลักทั้งสามที่ใช้คือ:
- อัตราความผิดพลาดของคำ (WER): วัดข้อผิดพลาดในการถอดเสียง (การแทรก การลบ การแทนที่) เหมาะสำหรับเสียงที่ชัดเจนแต่มีปัญหากับเสียงรบกวนหรือสำเนียง
- อัตราความผิดพลาดของตัวอักษร (CER): ติดตามความถูกต้องในระดับตัวอักษร เหมาะสำหรับภาษาจีนหรือญี่ปุ่น
- SeMaScore: เน้นที่ความหมายเชิงสัณฐาน เหมาะกับสภาพแวดล้อมที่มีเสียงรบกวนและสำเนียงหลากหลาย
การเปรียบเทียบอย่างรวดเร็วของตัวชี้วัด
| ตัวชี้วัด | เน้นที่ | เหมาะสมสำหรับ | ข้อจำกัด |
|---|---|---|---|
| WER | ความถูกต้องระดับคำ | คำพูดที่ชัดเจน | มีปัญหากับเสียงรบกวน/สำเนียง |
| CER | ความถูกต้องระดับตัวอักษร | ภาษาเอเชีย | ไม่มีความเข้าใจเชิงความหมาย |
| SeMaScore | การรักษาความหมายเชิงสัณฐาน | เสียงหลายภาษา เสียงรบกวน | ต้องการความสามารถในการคำนวณสูง |
วิธีที่ทันสมัยกว่าอย่างการสร้างแบบจำลองเสียงและการสร้างแบบจำลองรวมช่วยเสริมการประเมินโดยการจำลองเงื่อนไขจริง ตัวชี้วัดเหล่านี้มีความสำคัญในการปรับปรุงเครื่องมืออย่างแพลตฟอร์มการถอดความหลายภาษา
ตัวชี้วัดสำคัญสำหรับการประเมินการจดจำเสียง
แบบจำลองการจดจำเสียงใช้ตัวชี้วัดเฉพาะในการวัดประสิทธิภาพ ตัวชี้วัดเหล่านี้ช่วยให้นักพัฒนาและนักวิจัยเข้าใจว่า ASR (การจดจำเสียงอัตโนมัติ) มีประสิทธิภาพแค่ไหนในสภาวะและภาษาต่างๆ
อัตราความผิดพลาดของคำ (WER)
อัตราความผิดพลาดของคำ (WER) เป็นหนึ่งในตัวชี้วัดที่ใช้กันอย่างแพร่หลายในการวัดความแม่นยำของการถอดเสียงของระบบ มันระบุข้อผิดพลาดในสามประเภท:
- การเพิ่ม: คำที่ถูกเพิ่มเข้ามาโดยไม่ควรมี
- การลบ: คำที่หายไปจากการถอดเสียง
- การแทนที่: คำที่ไม่ถูกต้องแทนที่คำที่ถูกต้อง
เป้าหมายคือการได้ WER ที่ต่ำกว่า เนื่องจากมันสะท้อนความแม่นยำที่ดีกว่า อย่างไรก็ตาม WER อาจมีข้อจำกัด โดยเฉพาะในสถานการณ์ที่มีเสียงรบกวนหรือรูปแบบการพูดที่ไม่ปกติ
อัตราความผิดพลาดของตัวอักษร (CER)
อัตราความผิดพลาดของตัวอักษร (CER) ให้การวิเคราะห์ที่ละเอียดขึ้นโดยเน้นที่ตัวอักษรเดี่ยวๆ มากกว่าคำทั้งหมด ทำให้มีความเหมาะสมอย่างยิ่งสำหรับภาษาที่ตัวอักษรมีความหมายมาก เช่น ภาษาไทย จีน หรือญี่ปุ่น
CER มีประสิทธิภาพโดยเฉพาะสำหรับระบบหลายภาษาหรือในกรณีที่ขอบเขตของคำไม่ชัดเจน แม้ว่าจะให้การวิเคราะห์ทางภาษาที่ละเอียด แต่ตัวชี้วัดใหม่ๆ เช่น SeMaScore พยายามที่จะตอบโจทย์ในงานที่เกี่ยวข้องกับความหมายที่กว้างกว่า
SeMaScore
SeMaScore เสริมชั้นเชิงสัณฐานต่อกระบวนการประเมินโดยเพิ่มไปจากตัวชี้วัดแบบดั้งเดิมอย่าง WER และ CER มันวัดว่าระบบรักษาความหมายที่ต้องการได้ดีเพียงใด ไม่ใช่แค่คำหรือตัวอักษรที่ถูกต้องเท่านั้น
นี่คือวิธีที่ SeMaScore แตกต่างในบางสถานการณ์:
| ประเภทของสถานการณ์ | SeMaScore ช่วยได้อย่างไร |
|---|---|
| สภาพแวดล้อมที่มีเสียงดัง | ตรงกับการรับรู้ของมนุษย์ในสภาพที่มีเสียงดัง |
| การพูดที่ไม่ปกติ | สอดคล้องกับการประเมินของผู้เชี่ยวชาญด้านความหมาย |
| ภาษาถิ่นที่ซับซ้อน | รักษาความถูกต้องเชิงสัณฐานข้ามภาษาถิ่น |
SeMaScore เป็นประโยชน์เฉพาะสำหรับการประเมินระบบ ASR ในสภาวะที่ท้าทาย ทำให้การประเมินมีความกว้างและมีความหมายมากขึ้นในการประเมินประสิทธิภาพของพวกเขา ตัวชี้วัดเหล่านี้เสนอกรอบงานที่รอบคอบสำหรับการทำความเข้าใจวิธีที่ระบบ ASR ทำงานในสถานการณ์ต่างๆ
วิธีการขั้นสูงสำหรับการประเมินโมเดล ASR
กระบวนการของการประเมินแบบจำลอง ASR ได้เคลื่อนที่ไปเกินกว่าตัวชี้วัดพื้นฐาน โดยใช้เทคนิคล้ำหน้าเพื่อให้เข้าใจลึกซึ้งขึ้นเกี่ยวกับวิธีการที่ระบบเหล่านี้ทำงาน
บทบาทของการสร้างแบบจำลองเสียง
การสร้างแบบจำลองเสียงเชื่อมโยงสัญญาณเสียงกับหน่วยทางภาษาโดยใช้ตัวแทนทางสถิติของลักษณะเสียง บทบาทของมันในการประเมิน ASR ขึ้นอยู่กับหลายปัจจัยทางเทคนิค:
| ปัจจัย | ผลกระทบต่อการประเมิน |
|---|---|
| อัตราการสุ่มตัวอย่างและบิตต่อหนึ่งตัวอย่าง | ค่าที่สูงขึ้นปรับปรุงความแม่นยำในการรับรู้ แต่สามารถทำให้การประมวลผลช้าลงและเพิ่มขนาดโมเดล |
| เสียงสิ่งแวดล้อมและความหลากหลายของการพูด | ทำให้การรับรู้ยากขึ้น โมเดลต้องการการทดสอบด้วยข้อมูลที่หลากหลายและท้าทาย |
โมเดลเสียงถูกออกแบบให้จัดการกับรูปแบบการพูดและความท้าทายจากสภาพแวดล้อมที่หลากหลาย ซึ่งมักจะถูกมองข้ามจากตัวชี้วัดการประเมินแบบดั้งเดิม
การรวมแบบจำลองใน ASR
แตกต่างจากการสร้างแบบจำลองเสียงซึ่งเน้นที่ลักษณะเสียงเฉพาะ การรวมแบบจำลองผสมผสานงานการรู้จำหลายอย่างเข้าในกรอบการทำงานเดียว วิธีนี้ปรับปรุงการประเมิน ASR โดยสะท้อนการใช้จริงในโลกจริง ที่ระบบมักจะจัดการกับงานหลายอย่างพร้อมกัน
ปัจจัยสำคัญสำหรับการประเมินได้แก่:
- ความสมดุลระหว่างความเร็วกับความแม่นยำ
- รักษาประสิทธิภาพภายใต้การใช้งานหนัก
- รับประกันผลลัพธ์ที่สม่ำเสมอในสภาพแวดล้อมที่แตกต่างกัน
แพลตฟอร์มอย่าง DubSmart ใช้เทคนิคขั้นสูงเหล่านี้เพื่อเสริมการรู้จำเสียงสำหรับเนื้อหาหลายภาษาและการโคลนนิ่งเสียง
วิธีการเหล่านี้เป็นรากฐานสำหรับการเปรียบเทียบตัวชี้วัดการประเมินที่ต่างกัน เปิดเผยถึงข้อได้เปรียบและข้อจำกัดของพวกเขา
การประยุกต์ใช้และความท้าทายของตัวชี้วัดการประเมิน
ตัวชี้วัดการประเมินมีบทบาทสำคัญในการปรับปรุงเครื่องมืออย่าง DubSmart และแก้ไขอุปสรรคอย่างต่อเนื่องในระบบการจดจำเสียงอัตโนมัติ (ASR)
การใช้ในเครื่องมือ AI เช่น DubSmart
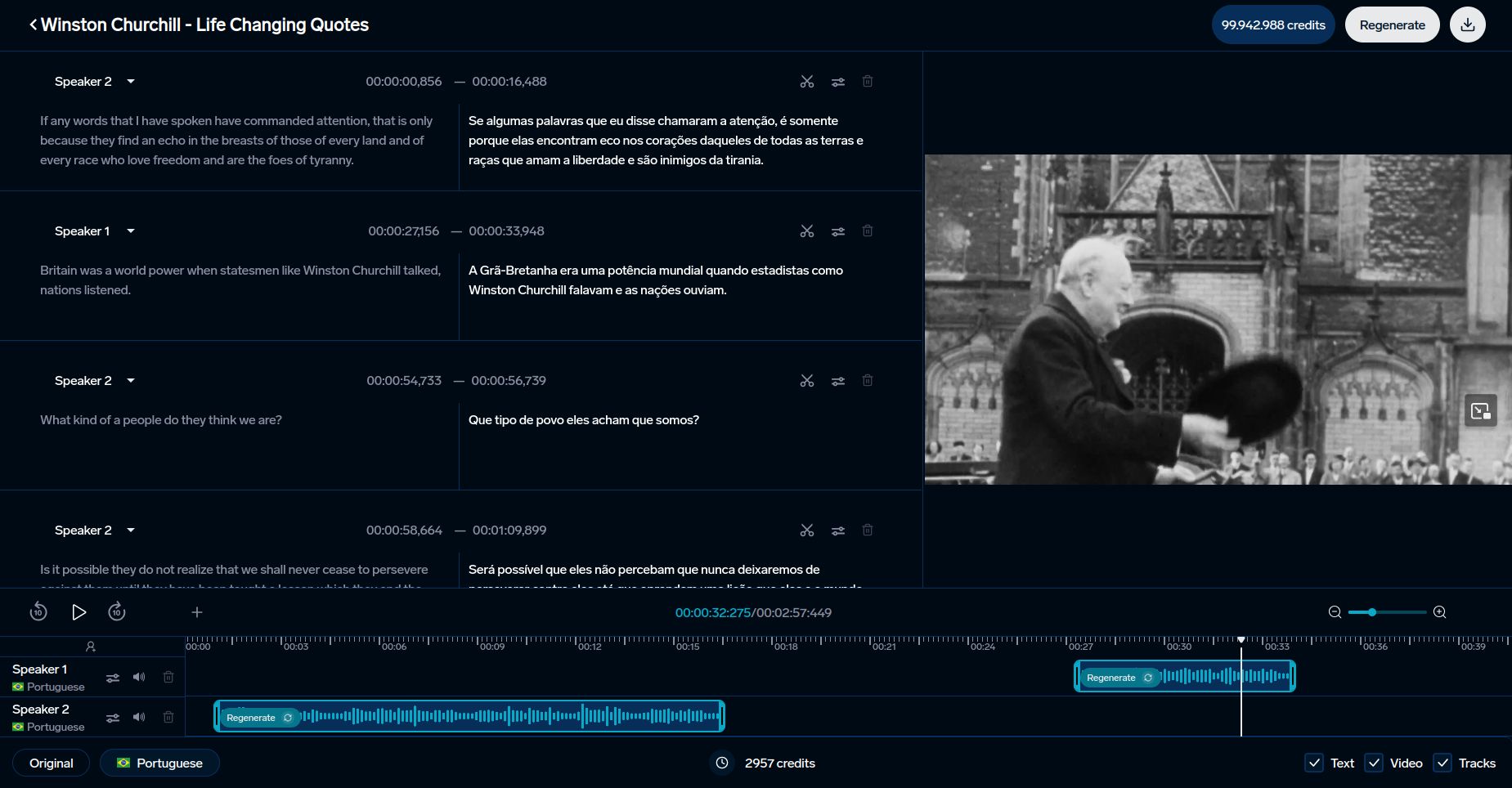
ตัวชี้วัดการจดจำเสียงพูดมีความจำเป็นสำหรับการพัฒนาเครื่องมือภาษาที่ขับเคลื่อนด้วย AI DubSmart ใช้ประโยชน์จากตัวชี้วัดเหล่านี้ในการให้บริการแปลเสียงและถอดความหลายภาษากว่า 33 ภาษา แพลตฟอร์มนี้รวมทั้งตัวชี้วัดดั้งเดิมและขั้นสูงเพื่อให้แน่ใจว่ามีคุณภาพ:
| ตัวชี้วัด | การประยุกต์ใช้ | ผลกระทบ |
|---|---|---|
| SeMaScore | สภาพแวดล้อมที่มีเสียงรบกวนและหลากหลายภาษา | รักษาความถูกต้องเชิงสัณฐานและการรักษาความหมาย |
การรวมกันนี้ทำให้มั่นใจว่ามีความแม่นยำสูง แม้ในสถานการณ์ที่ท้าทาย เช่น การประมวลผลผู้พูดหลายคนหรือการจัดการเสียงที่ซับซ้อน ความแม่นยำเชิงสัณฐานมีความสำคัญอย่างยิ่งสำหรับงานที่ต้องทำ เช่น การโคลนนิ่งเสียงและการสร้างเนื้อหาหลายภาษา
ความท้าทายในการประเมิน ASR
วิธีการประเมินแบบดั้งเดิมมักขาดประสิทธิภาพเมื่อจัดการกับสำเนียง เสียงพื้นหลัง หรือการเปลี่ยนแปลงของภาษาถิ่น เครื่องมือขั้นสูงอย่าง SeMaScore ใช้วิธีวิเคราะห์เชิงสัณฐานเพื่อแก้ไขจุดอ่อนเหล่านี้ โดยเฉพาะอย่างยิ่ง SeMaScore ก้าวหน้าขึ้นโดยการผสมผสานการประเมินอัตราความผิดพลาดกับความเข้าใจเชิงสัณฐานที่ลึกซึ้งขึ้น
"การประเมินการจดจำเสียงจำเป็นต้องปรับสมดุลระหว่างความแม่นยำ ความเร็ว และความยืดหยุ่นในหลายภาษา สำเนียง และสภาพแวดล้อม"
ในการปรับปรุงการประเมิน ASR ปัจจัยหลายอย่างมีบทบาท:
- การเสริมสร้างโมเดลเสียงเพื่อให้ได้ความสมดุลระหว่างความแม่นยำและประสิทธิภาพ
- รองรับการประมวลผลแบบเรียลไทม์โดยไม่ลดความแม่นยำลง
- รับประกันผลลัพธ์ที่สม่ำเสมอในสถานการณ์ที่หลากหลาย
เทคนิคการประเมินที่ใหม่กว่านี้มีเป้าหมายเพื่อให้ข้อมูลเชิงลึกที่ละเอียดมากขึ้นเกี่ยวกับประสิทธิภาพของ ASR โดยเฉพาะในสถานการณ์ที่ต้องใช้ความสามารถในการพัฒนา ระบบเหล่านี้ช่วยให้เครื่องมือปรับปรุงความสามารถในการเปรียบเทียบและความสามารถในการทำงานทั้งหมด
sbb-itb-f4517a0
การเปรียบเทียบตัวชี้วัดการประเมิน
การประเมินระบบการจดจำเสียงมักขึ้นอยู่กับการเลือกตัวชี้วัดที่ถูกต้อง ตัวชี้วัดแต่ละตัวเน้นแง่มุมต่างๆ ของประสิทธิภาพ ทำให้สำคัญต่อการจับคู่ตัวชี้วัดกับกรณีการใช้งานเฉพาะ
ในขณะที่ WER (อัตราความผิดพลาดของคำ) และ CER (อัตราความผิดพลาดของตัวอักษร) ได้รับการยอมรับอย่างแพร่หลาย ตัวเลือกใหม่อย่าง SeMaScore ให้มุมมองที่กว้างขึ้น นี่คือการเปรียบเทียบระหว่างกัน:
ตารางเปรียบเทียบตัวชี้วัด
| ตัวชี้วัด | ความแม่นยำ | ความเข้าใจเชิงสัณฐาน | กรณีการใช้งาน | ความเร็วในการประมวลผล | ความต้องการในการคำนวณ |
|---|---|---|---|---|---|
| WER | สูงสำหรับคำพูดที่ชัดเจน มีปัญหากับเสียงรบกวน | มีความเข้าใจเชิงสัณฐานจำกัด | การประเมิน ASR มาตรฐาน เสียงที่ชัดเจน | รวดเร็วมาก | น้อยมาก |
| CER | ยอดเยี่ยมสำหรับการวิเคราะห์ในระดับตัวอักษร | ไม่มีการวิเคราะห์เชิงสัณฐาน | ภาษาตะวันออก การประเมินเสียงพูด | รวดเร็ว | ต่ำ |
| SeMaScore | แข็งแกร่งในสภาพแวดล้อมที่หลากหลาย | มีการสัมพันธ์เชิงสัณฐานสูง | หลายสำเนียง สภาพแวดล้อมที่มีเสียงรบกวน | ปานกลาง | กลางถึงสูง |
WER ทำงานได้ดีในสถานการณ์เสียงที่ชัดเจน แต่มีปัญหากับการพูดที่มีเสียงรบกวนหรือสำเนียงเนื่องจากขาดความลึกเชิงสัณฐาน ในขณะที่ SeMaScore แก้ไขสิ่งนั้นโดยการรวมการวิเคราะห์ทางข้อผิดพลาดกับความเข้าใจเชิงสัณฐาน ทำให้เหมาะสมที่จะถูกนำมาใช้เมื่อมีเงื่อนไขการพูดที่ท้าทายและหลากหลาย
ในขณะที่เครื่องมืออย่าง DubSmart รวมระบบ ASR เข้ากับการถอดความหลายภาษาซึ่งการเลือกตัวชี้วัดที่ถูกต้องมีความสำคัญ การศึกษาวิจัยแสดงให้เห็นว่า SeMaScore มีประสิทธิภาพดีกว่าในสภาพแวดล้อมที่มีเสียงรบกวนหรือความซับซ้อน ซึ่งสามารถให้การประเมินที่เชื่อถือได้มากขึ้น
ในที่สุดการเลือกนั้นขึ้นอยู่กับปัจจัยหลายอย่าง เช่น ความซับซ้อนของการพูด ความหลากหลายของสำเนียงและทรัพยากรที่มี WER และ CER เหมาะสมสำหรับงานที่ง่ายกว่าในขณะที่ SeMaScore เหมาะสมสำหรับการประเมินในระยะลึกขึ้น ซึ่งสะท้อนการเปลี่ยนแปลงไปยังตัวชี้วัดที่สอดคล้องกับการตีความของมนุษย์มากขึ้น
การเปรียบเทียบนี้แสดงให้เห็นถึงการวิธีการประเมิน ASR กำลังพัฒนาเครื่องมือและระบบที่ใช้เทคโนโลยีเหล่านี้
บทสรุป
การเปรียบเทียบตัวชี้วัดแสดงให้เห็นว่าการประเมิน ASR ได้พัฒนาและกำลังมุ่งหน้าไปที่ใด ตัวชี้วัดได้ปรับตัวให้เข้ากับความต้องการของระบบ ASR ที่ซับซ้อนมากขึ้น ในขณะที่ WER (อัตราความผิดพลาดของคำ) และ CER (อัตราความผิดพลาดของตัวอักษร) ยังคงเป็นดัชนีชี้วัดที่สำคัญ แต่การวัดใหม่อย่าง SeMaScore สะท้อนถึงการเน้นที่การรวมความเข้าใจเชิงสัณฐานกับการวิเคราะห์ข้อผิดพลาด
SeMaScore ให้ความสมดุลของความเร็วและความแม่นยำ ทำให้มันเป็นทางเลือกที่แข็งแกร่งสำหรับการประยุกต์ใช้งานได้ในเชิงปฎิบัติ ระบบ ASR ทันสมัย เช่นที่แพลตฟอร์มอย่าง DubSmart ใช้ ต้องนำในสถานการณ์ที่ท้าทาย ประกอบด้วยเงื่อนไขการได้ยินที่หลากหลายและความต้องการหลายภาษา เช่น DubSmart รองรับการจดจำเสียงได้ใน 70 ภาษา ซึ่งแสดงให้เห็นถึงความจำเป็นของวิธีการประเมินขั้นสูง ตัวชี้วัดเหล่านี้ไม่เพียงแต่ปรับปรุงความแม่นยำของระบบ แต่ยังเพิ่มความสามารถของพวกเขาในการจัดการกับความท้าทายทางภาษาและเสียงที่หลากหลาย
มองไปข้างหน้า ตัววัดในอนาคตคาดหวังที่จะรวมการวิเคราะห์ข้อผิดพลาดกับการเข้าใจความหมายที่ลึกกว่า เมื่อเทคโนโลยีการจดจำเสียงพูดมีการพัฒนาขึ้น วิธีการประเมินต้องสอดคล้องกับความท้าทายของเสียงรบกวน สำเนียงที่หลากหลาย และรูปแบบการพูดที่ซับซ้อน การเปลี่ยนแปลงนี้จะมีอิทธิพลต่อวิธีที่บริษัทออกแบบและใช้ระบบ ASR โดยให้ความสำคัญกับตัววัดที่ประเมินทั้งความแม่นยำและความเข้าใจ
การเลือกตัววัดที่เหมาะสมเป็นสิ่งสำคัญ ไม่ว่าจะสำหรับเสียงที่ชัดเจนหรือสถานการณ์หลายภาษาที่ซับซ้อน เมื่อเทคโนโลยี ASR ยังคงก้าวหน้า ตัววัดที่พัฒนาเหล่านี้จะมีบทบาทสำคัญในการปรับปรุงระบบที่ตอบสนองความต้องการในการสื่อสารของมนุษย์ได้ดียิ่งขึ้น
คำถามที่พบบ่อย
ตัววัดใดที่ใช้เพื่อประเมินโปรแกรมการจดจำเสียงพูด?
ตัววัดหลักสำหรับการประเมินระบบการจดจำเสียงอัตโนมัติ (ASR) คือ อัตราความผิดพลาดของคำ (WER) มันคำนวณความแม่นยำในการถอดเสียงโดยการเปรียบเทียบจำนวนข้อผิดพลาด (การเพิ่ม การลบ การแทนที่) กับจำนวนคำทั้งหมดในข้อมูลต้นฉบับ อีกวิธีหนึ่ง SeMaScore มุ่งเน้นที่การประเมินเชิงสัณฐาน เสนอความเข้าใจที่ดีขึ้นในสถานการณ์ที่ท้าทาย เช่น การพูดที่มีสำเนียงหรือเสียงรบกวน
คุณจะประเมินโมเดล ASR ได้อย่างไร?
การประเมินโมเดล ASR รวมถึงการใช้ตัวชี้วัดหลายตัวเพื่อวัดความถูกต้องในการถอดเสียงและการรักษาความหมาย เพื่อให้มั่นใจว่าระบบทำงานได้อย่างน่าเชื่อถือในสถานการณ์ที่หลากหลาย
| องค์ประกอบการประเมิน | คำอธิบาย | วิธีที่ดีที่สุด |
|---|---|---|
| อัตราความผิดพลาดของคำ (WER) | ติดตามความถูกต้องระดับคำเปรียบเทียบกับการถอดเสียงของมนุษย์ | คำนวณอัตราส่วนของข้อผิดพลาด (การเพิ่ม การลบ การแทนที่) กับคำทั้งหมด |
| อัตราความผิดพลาดของตัวอักษร (CER) | เน้นที่ความถูกต้องในระดับตัวอักษร | ดีที่สุดสำหรับภาษาไทย จีนหรือญี่ปุ่น |
| ความเข้าใจเชิงสัณฐาน | ตรวจสอบว่าความหมายถูกเก็บรักษาไว้ | ใช้ SeMaScore สำหรับการประเมินเชิงสัณฐานที่ลึกซึ้งกว่า |
| การทดสอบในโลกจริง | ประเมินผลในสภาพแวดล้อมที่หลากหลาย (เช่น เสียงดัง หลายภาษา) | ทดสอบในสภาพเสียงที่หลากหลาย |
"การประเมิน ASR มักพึ่งพาตัวชี้วัดที่อิงข้อผิดพลาด"
เมื่อประเมินโมเดล ASR ให้พิจารณาปัจจัยเชิงปฏิบัติเหล่านี้ควบคู่ไปกับตัวชี้วัดความแม่นยำ:
- ประสิทธิภาพในสภาพแวดล้อมเสียงที่แตกต่างกัน
- การจัดการกับสำเนียงและภาษาถิ่น
- ความสามารถในการประมวลผลแบบเรียลไทม์
- ความแข็งแกร่งต่อเสียงรบกวนพื้นหลัง
ปรับกระบวนการประเมินให้เป็นไปตามการประยุกต์ใช้ที่เฉพาะเจาะจงของคุณในขณะที่ยึดมั่นตามมาตรฐานอุตสาหกรรม ตัวอย่างเช่น แพลตฟอร์มอย่าง DubSmart เน้นที่ความถูกต้องเชิงสัณฐานสำหรับเนื้อหาหลายภาษา ทำให้วิธีการประเมินเหล่านี้มีความเกี่ยวข้องโดยเฉพาะ