
I modelli di riconoscimento vocale sono giudicati in base a quanto accuratamente trascrivono il parlato e mantengono il significato in diverse condizioni. Le tre principali metriche utilizzate sono:
- Indice di Errore di Parola (WER): Misura gli errori di trascrizione (inserzioni, cancellazioni, sostituzioni). Migliore per audio pulito ma fatica con rumore o accenti.
- Indice di Errore di Carattere (CER): Traccia l'accuratezza a livello di carattere, ideale per lingue come il cinese o il giapponese.
- SeMaScore: Si concentra sul significato semantico, performando bene in ambienti rumorosi e con accenti diversi.
Rapido Confronto delle Metriche
| Metrica | Focus | Migliore Per | Limitazioni |
|---|---|---|---|
| WER | Accuratezza a livello di parola | Parlato pulito | Fatica con rumore/accenti |
| CER | Accuratezza a livello di carattere | Lingue asiatiche | Nessuna comprensione semantica |
| SeMaScore | Mantenimento del significato semantico | Audio rumorosi, multilingue | Maggiore richiesta computazionale |
Metodi avanzati come la modellazione acustica e unificata potenziano ulteriormente le valutazioni simulando condizioni reali. Queste metriche sono cruciali per migliorare strumenti come le piattaforme di trascrizione multilingue.
Metriche Chiave per Valutare il Riconoscimento Vocale
I modelli di riconoscimento vocale utilizzano metriche specifiche per valutare la loro performance. Queste metriche aiutano gli sviluppatori e i ricercatori a comprendere quanto siano efficaci i loro sistemi di Riconoscimento Vocale Automatico (ASR) in diverse condizioni e lingue.
Indice di Errore di Parola (WER)
Indice di Errore di Parola (WER) è una delle metriche più ampiamente utilizzate per misurare quanto accuratamente un sistema trascrive il parlato. Identifica errori in tre categorie:
- Inserzioni: Parole aggiunte che non dovrebbero esserci.
- Cancellazioni: Parole mancanti nella trascrizione.
- Sostituzioni: Parole errate che sostituiscono quelle corrette.
L'obiettivo è ottenere un WER più basso, poiché riflette una maggiore accuratezza. Detto questo, il WER può avere degli svantaggi, specialmente in situazioni con rumore di fondo o modelli di parlato inusuali.
Indice di Errore di Carattere (CER)
Indice di Errore di Carattere (CER) offre un'analisi più dettagliata concentrandosi su singoli caratteri piuttosto che su intere parole. Questo lo rende particolarmente utile per lingue come il cinese o il giapponese, dove i caratteri portano significati significativi.
Il CER è particolarmente efficace per sistemi multilingue o casi in cui i confini delle parole non sono chiari. Sebbene fornisca un'analisi linguistica dettagliata, metriche più recenti come il SeMaScore mirano ad affrontare sfide più ampie relative al significato.
SeMaScore
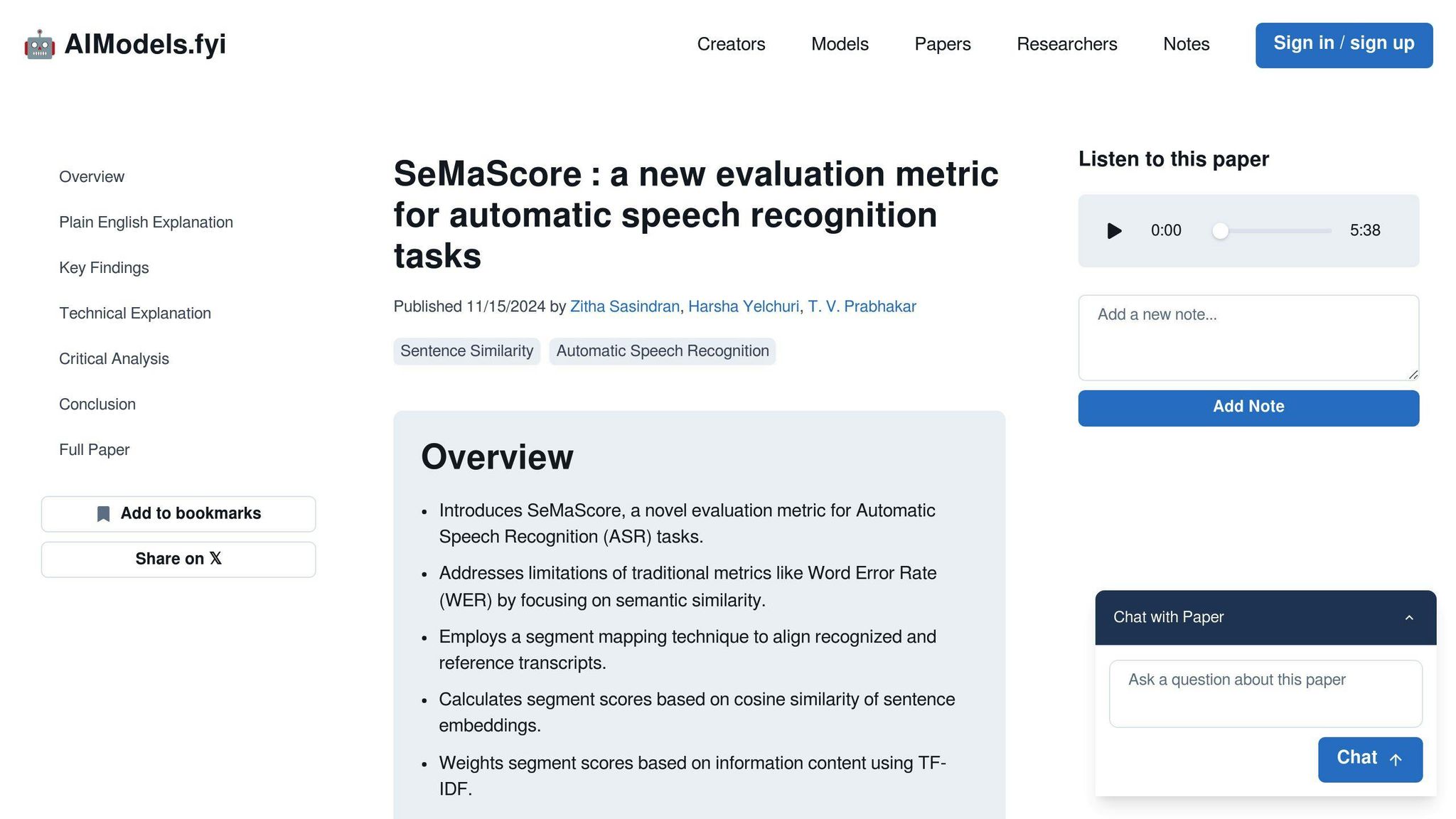
SeMaScore va oltre le metriche tradizionali come il WER e il CER incorporando uno strato semantico nel processo di valutazione. Misura quanto bene il sistema mantiene il significato inteso, non solo le parole o i caratteri esatti.
Ecco come il SeMaScore si distingue in scenari specifici:
| Tipo di Scenario | Come Aiuta SeMaScore |
|---|---|
| Ambiente Rumoroso | Si allinea con la percezione umana in contesti rumorosi |
| Parlato Atipico | Si allinea con le valutazioni esperte del significato |
| Dialetti Complessi | Preserva l'accuratezza semantica attraverso i dialetti |
SeMaScore è particolarmente utile per valutare i sistemi ASR in condizioni difficili, fornendo una valutazione più ampia e significativa delle loro prestazioni. Insieme, queste metriche offrono un quadro ben arrotondato per comprendere come i sistemi ASR performano in diverse situazioni.
Metodi Avanzati per Valutare i Modelli ASR
Il processo di valutazione dei modelli di Riconoscimento Vocale Automatico (ASR) è andato oltre le metriche di base, utilizzando tecniche più avanzate per ottenere una comprensione più profonda di come questi sistemi performano.
Il Ruolo della Modellazione Acustica
La modellazione acustica collega segnali audio a unità linguistiche utilizzando rappresentazioni statistiche delle caratteristiche del parlato. Il suo ruolo nella valutazione ASR dipende da diversi fattori tecnici:
| Fattore | Effetto sulla Valutazione |
|---|---|
| Frequenza di Campionamento & Bit per Campione | Valori più alti migliorano l'accuratezza del riconoscimento ma possono rallentare il processo e aumentare la dimensione del modello |
| Rumore Ambientale & Variazioni del Parlato | Rende il riconoscimento più difficile; i modelli devono essere testati con dati diversi e impegnativi |
I modelli acustici sono progettati per gestire una varietà di modelli di parlato e sfide ambientali, che spesso vengono trascurate dalle metriche di valutazione tradizionali.
La Modellazione Unificata nell'ASR
A differenza della modellazione acustica, che si concentra su specifiche caratteristiche del parlato, la modellazione unificata combina più compiti di riconoscimento in un'unica struttura. Questo approccio migliora la valutazione dell'ASR riflettendo i casi d'uso reali, dove i sistemi gestiscono spesso più compiti contemporaneamente.
Fattori importanti per la valutazione includono:
- Bilanciare velocità e accuratezza
- Mantenere le prestazioni sotto uso intenso
- Garantire risultati costanti in ambienti diversi
Piattaforme come DubSmart utilizzano queste tecniche avanzate per migliorare il riconoscimento vocale per contenuti multilingue e clonazione vocale.
Questi metodi forniscono una base per confrontare diverse metriche di valutazione, mettendo in luce i loro vantaggi e limitazioni.
Applicazioni e Sfide delle Metriche di Valutazione
Le metriche di valutazione svolgono un ruolo cruciale nel migliorare strumenti come DubSmart e affrontare ostacoli continui nei sistemi di riconoscimento vocale automatico (ASR).
Uso in Strumenti AI come DubSmart
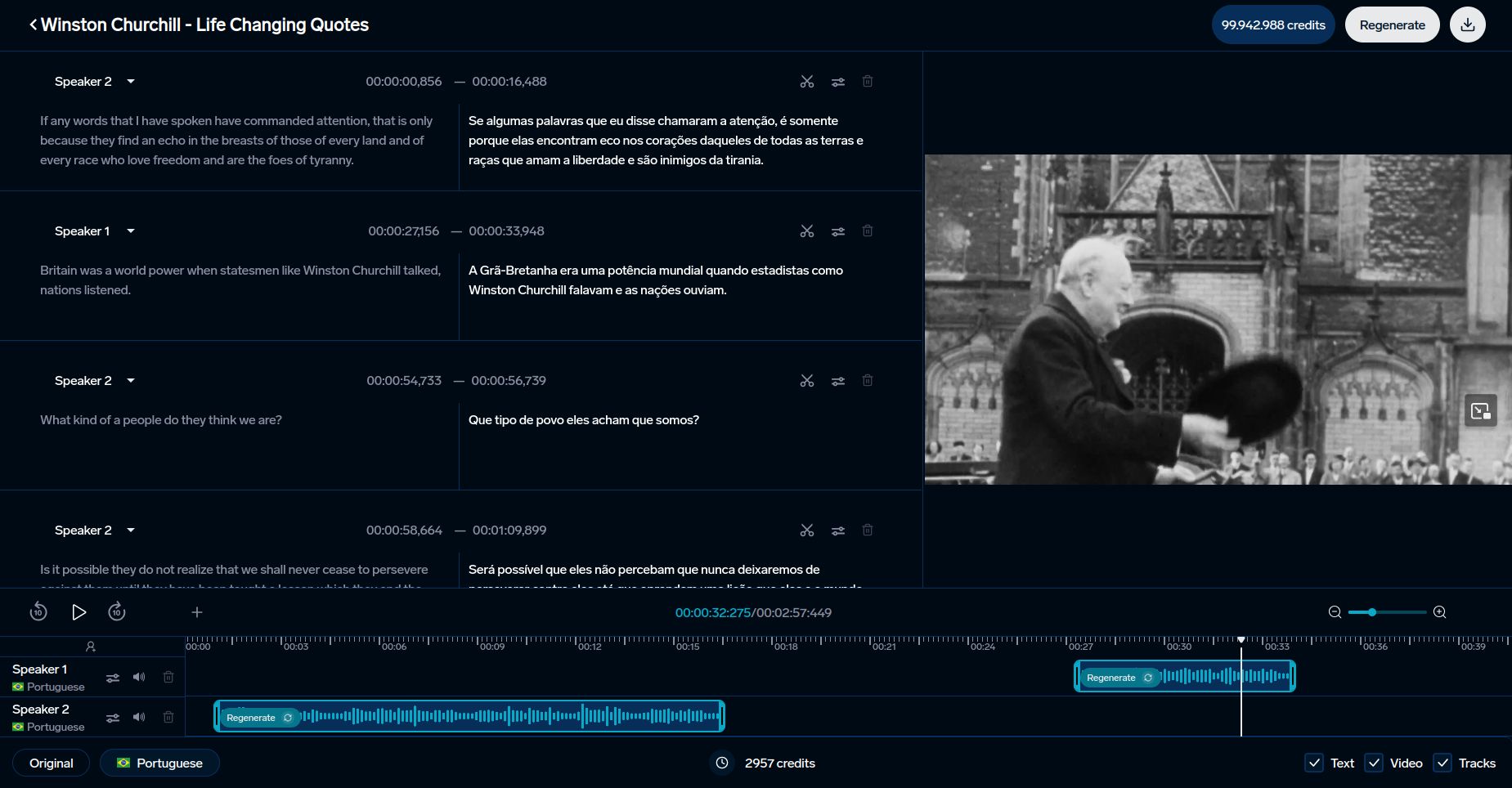
Le metriche di riconoscimento vocale sono essenziali per migliorare gli strumenti linguistici basati su AI. DubSmart sfrutta queste metriche per offrire servizi di doppiaggio e trascrizione multilingue in 33 lingue. La piattaforma integra metriche sia tradizionali che avanzate per garantire la qualità:
| Metrica | Applicazione | Impatto |
|---|---|---|
| SeMaScore | Ambientazioni Multilingue e Rumorose | Preserva l'accuratezza semantica e il mantenimento del significato |
Questa combinazione assicura alta precisione, anche in scenari difficili come l'elaborazione di più parlanti o la gestione di audio complessi. L'accuratezza semantica è particolarmente importante per compiti come la clonazione vocale e la generazione di contenuti multilingue.
Sfide nella Valutazione dell'ASR
I metodi di valutazione tradizionali spesso falliscono nel gestire accenti, rumori di fondo o variazioni di dialetto. Strumenti avanzati come il SeMaScore colmano queste lacune integrando un'analisi basata sul significato. SeMaScore, in particolare, rappresenta un progresso fondendo la valutazione delle percentuali di errore con una comprensione semantica più profonda.
"La valutazione del riconoscimento vocale richiede l'equilibrio tra accuratezza, velocità e adattabilità attraverso lingue, accenti e ambienti."
Per migliorare la valutazione dell'ASR, diversi fattori entrano in gioco:
- Migliorare i modelli acustici per raggiungere un equilibrio tra precisione ed efficienza
- Soddisfare le esigenze di elaborazione in tempo reale senza compromettere l'accuratezza
- Garantire prestazioni costanti in contesti variegati
Tecniche di valutazione più recenti mirano a fornire approfondimenti più dettagliati sulla performance dell'ASR, specialmente in situazioni impegnative. Questi avanzamenti aiutano a perfezionare gli strumenti per un miglior confronto dei sistemi e un'efficacia complessiva.
sbb-itb-f4517a0
Confronto delle Metriche di Valutazione
Valutare i sistemi di riconoscimento vocale spesso implica scegliere la giusta metrica. Ognuna evidenzia diversi aspetti della performance, rendendo cruciale adattare la metrica al caso d'uso specifico.
Mentre WER (Indice di Errore di Parola) e CER (Indice di Errore di Carattere) sono ben consolidati, opzioni più recenti come SeMaScore offrono una prospettiva più ampia. Ecco come si confrontano:
Tabella di Confronto delle Metriche
| Metrica | Performance di Accuratezza | Comprensione Semantica | Scenari d'Uso | Velocità di Elaborazione | Richieste Computazionali |
|---|---|---|---|---|---|
| WER | Alta per parlato pulito, fatica con rumore | Contesto semantico limitato | Valutazione ASR standard, audio pulito | Molto veloce | Minime |
| CER | Eccellente per analisi a livello di carattere | Nessuna analisi semantica | Lingue asiatiche, valutazione fonetica | Veloce | Basse |
| SeMaScore | Forte in condizioni varie | Alta correlazione semantica | Ambienti multi-accento, rumorosi | Moderata | Medio-alte |
WER funziona bene in scenari di audio pulito ma fatica con discorsi rumorosi o accentati a causa della sua mancanza di profondità semantica. D'altra parte, SeMaScore colma questo divario combinando l'analisi degli errori con la comprensione semantica, rendendolo un'opzione migliore per condizioni di discorso varie e impegnative.
Con strumenti come DubSmart che integrano sistemi ASR in trascrizioni multilingue e clonazioni vocali, la scelta della metrica giusta diventa critica. La ricerca mostra che SeMaScore performa meglio in ambienti rumorosi o complessi, offrendo una valutazione più affidabile.
Alla fine, la scelta dipende da fattori come la complessità del parlato, la diversità degli accenti e le risorse disponibili. WER e CER sono ottimi per compiti più semplici, mentre SeMaScore è migliore per valutazioni più sfumate, riflettendo un cambiamento verso metriche che si allineano più strettamente con l'interpretazione umana.
Questi confronti mostrano come la valutazione dell'ASR stia evolvendo, modellando gli strumenti e i sistemi che si affidano a queste tecnologie.
Conclusione
Il confronto delle metriche evidenzia come la valutazione dell'ASR sia cresciuta e dove sta andando. Le metriche si sono adattate per soddisfare le esigenze di sistemi ASR sempre più complessi. Mentre Indice di Errore di Parola (WER) e Indice di Errore di Carattere (CER) rimangono punti di riferimento chiave, misure più nuove come SeMaScore riflettono un focus sulla combinazione della comprensione semantica con l'analisi degli errori tradizionale.
SeMaScore offre un equilibrio tra velocità e precisione, rendendolo una scelta forte per applicazioni pratiche. I sistemi ASR moderni, come quelli utilizzati dalle piattaforme come DubSmart, devono navigare in scenari reali complessi, incluse condizioni acustiche diverse ed esigenze multilingue. Ad esempio, DubSmart supporta il riconoscimento vocale in 70 lingue, dimostrando la necessità di metodi di valutazione avanzati. Queste metriche non solo migliorano l'accuratezza del sistema ma ne potenziano anche la capacità di gestire sfide linguistiche e acustiche variegate.
Guardando al futuro, ci si aspetta che le metriche future combinino l'analisi degli errori con una comprensione più profonda del significato. Man mano che la tecnologia del riconoscimento vocale progredisce, i metodi di valutazione dovranno affrontare la sfida di ambienti rumorosi, accenti variegati e schemi di discorso complessi. Questo cambiamento influenzerà il modo in cui le aziende progettano e implementano i sistemi ASR, dando priorità a metriche che valutano sia l'accuratezza che la comprensione.
Selezionare la metrica appropriata è cruciale, che sia per audio pulito o scenari multilingue complessi. Man mano che la tecnologia ASR continua a progredire, queste metriche in evoluzione giocheranno un ruolo chiave nel modellare sistemi che rispondono meglio alle esigenze di comunicazione umana.
FAQ
Quale metrica viene utilizzata per valutare i programmi di riconoscimento vocale?
La principale metrica per valutare i sistemi di Riconoscimento Vocale Automatico (ASR) è il Indice di Errore di Parola (WER). Calcola l'accuratezza della trascrizione confrontando il numero di errori (inserzioni, cancellazioni e sostituzioni) con il totale delle parole nella trascrizione originale. Un altro metodo, il SeMaScore, si concentra sulla valutazione semantica, offrendo migliori spunti in scenari impegnativi, come discorsi accentati o rumorosi.
Come si valuta un modello ASR?
Valutare un modello ASR comporta l'uso di un mix di metriche per misurare sia l'accuratezza della trascrizione che quanto bene il significato viene mantenuto. Questo assicura che il sistema performi in modo affidabile in varie situazioni.
| Componente di Valutazione | Descrizione | Migliore Pratica |
|---|---|---|
| Indice di Errore di Parola (WER) | Traccia l'accuratezza a livello di parola rispetto a trascrizioni umane | Calcolare il rapporto degli errori (inserzioni, cancellazioni, sostituzioni) rispetto al totale delle parole |
| Indice di Errore di Carattere (CER) | Si concentra sull'accuratezza a livello di carattere | Migliore per lingue come il cinese o il giapponese |
| Comprensione Semantica | Controlla se il significato è preservato | Usare SeMaScore per una valutazione semantica più profonda |
| Test nel Mondo Reale | Valuta le prestazioni in ambienti diversi (ad esempio, rumorosi, multilingue) | Testare in vari ambienti acustici |
"La valutazione dell'ASR si è tradizionalmente basata su metriche di errore".
Quando si valutano modelli ASR, considerare questi fattori pratici insieme alle metriche di accuratezza:
- Performance in diversi ambienti sonori
- Gestione di accenti e dialetti
- Capacità di elaborazione in tempo reale
- Robustezza contro il rumore di fondo
Adattare il processo di valutazione alla propria applicazione specifica rispettando gli standard del settore. Ad esempio, piattaforme come DubSmart enfatizzano l'accuratezza semantica per contenuti multilingue, rendendo questi metodi di valutazione particolarmente rilevanti.