
重要なポイント:
- なぜ重要なのか: 翻訳の品質は信頼性、コンプライアンス、収益に影響を与えます。医療(99.9%の正確さ)や法律(98%の正確さ)などの業界では精度が求められます。
-
主なテスト目標:
- 意味の正確性: COMETなどのツールは、人間の評価と89%一致します。
- 用語の一貫性: 法律分野では99.5%の用語一貫性が求められます。
- 文化的適応: カスタマイズされたコンテンツはユーザーの維持率を34%向上させることができます。
-
指標とツール:
- 従来のもの: BLEU、TER、ROUGE(例: BLEU ≥0.4は使用可能)。
- 先進的なもの: COMET(人間のスコアとの相関0.81)とMQMの詳細なエラー分類。
-
課題:
- 文脈上のエラー、低リソース言語、古い学習データ。
- 例: ソーシャルメディアデータの追加によりクルド語の翻訳精度が45%向上しました。
-
解決策:
- アクティブラーニングシステムは低信頼度の出力をフラグ化することでエラーを減少させます。
- AIツールと人間の監視を組み合わせることで不具合検出率が91%向上します。
指標の迅速な比較:
| 指標 | 重点分野 | 使用ケースと閾値 |
|---|---|---|
| BLEU | N-gram精度 | 迅速なチェック、スコア≥0.4 |
| TER | 編集距離 | プロフェッショナルグレード、<9%推奨 |
| ROUGE | リコール測定 | コンテンツの検証、0.3-0.5 |
| COMET | 意味評価 | 強い相関(0.81) |
| MQM | エラー分類 | 企業レベルの詳細 |
このガイドは、企業が自動化と人間の専門知識を組み合わせて、拡張性のある正確で文化的に関連性のある翻訳を達成する方法を説明します。
品質測定指標
現代のツールは、自動化と人間の専門知識を融合させ、正確で文脈に合った翻訳を提供します。これらの指標は、意味の正確性、用語の一貫性、および文化的ニュアンスへの適応などの主要な目的を満たすように設計されています。
基本指標: BLEU、TER、ROUGE
翻訳品質テストの基盤を形成する3つのコア指標:
| 指標 | 重点分野 | 使用ケースと閾値 |
|---|---|---|
| BLEU | N-gram精度 | 迅速なチェック、スコア≥0.4が使用可能 |
| TER | 編集距離 | プロフェッショナルグレード、<9%推奨 |
| ROUGE | リコール測定 | コンテンツの検証、0.3-0.5の範囲 |
BLEUで0.6を超える翻訳は、人間の平均品質を超えることがよくあります。しかし、2023年の研究では、BLEUの限界が強調されました: 単一参照のBLEUは人間の判断と弱い相関(r=0.32)を示し、複数参照のセットアップではより良好な相関(r=0.68)でした。
新しい指標: COMETとMQM
新しいフレームワークは、伝統的な指標のギャップを埋めます。COMETはニューラルネットワークによって駆動され、意味を評価し、WMT2022のベンチマークで人間のスコアとの強い0.81の相関を達成しました - BLEUの0.45の相関よりも優れています。
MQMは、エラーを正確さ、流暢さ、用語などのカテゴリに分け、重要度の重みを割り当てます。この詳細なアプローチは、特に企業レベルの翻訳に有用です。
機械対人間のテスト
機械と人間の評価を組み合わせるバランスの取れたアプローチが不可欠です。業界のリーダーたちは次のようなワークフローを採用しています:
"初期TERフィルタリング → COMET意味評価 → COMETスコア<0.8の場合の人間によるポストエディティング → 最終クライアントレビュー。このプロセスは、評価コストを40%削減し、98%の品質コンプライアンスを維持します。"
高度に専門化されたコンテンツに対しては、人間の関与が不可欠です。新たに登場した指標は、文脈の一貫性や情緒的なトーンのキャプチャーといった要素に焦点を当てており、実際的な課題への取り組みを進めています。これらの進展は、次のセクションである「共通の翻訳問題」でさらに議論されます。
共通の翻訳問題
業界データによれば、しばしば発生する3つの主な課題があります:
文脈と意味
基本的なBLEU指標で評価された翻訳の38%は、イディオムの取扱において人間の介入が必要です。この問題は特に専門の環境で顕著です。
"EUの契約における「共同および個別責任」という誤訳は280万ユーロの損失を引き起こしました。それは不完全な法律訓練データに起因しました。この出来事の後の分析では、15,000件の認定法律文書を追加することで、同様のエラーが78%削減されました。"
DubSmartのビデオコンテキストアナライザーのようなツールは、翻訳された対話にビジュアルな手がかりを同期させることで92%の文脈的な正確さを達成しました。このアプローチは、シーンオブジェクト認識の使用により、性別の誤訳を63%削減しました。
稀少な言語
デジタルリソースが少ない言語は、翻訳品質において特有の困難に直面します。リソースの利用可能性がパフォーマンスに与える影響を以下に示します:
| リソースレベル | 品質への影響 | ソリューションの効果 |
|---|---|---|
| 高リソース言語 | 基本性能 | 標準テストで十分 |
| 中リソース言語 | 品質15%減少 | バック翻訳が有効 |
| 低リソース言語 | TERスコア22%上昇 | 転移学習が必要 |
クルド語のケーススタディは、ソーシャルメディアデータの追加が精度を45%向上させたことを示しています。また、関連する言語ファミリーからの転移学習は、必要な訓練データを30%削減しています。
訓練データの品質
訓練データの品質は、特に専門分野での翻訳精度において重要な役割を果たします。2024年の研究によると、医療翻訳エラーの68%は、西洋医学用語に偏った訓練データセットから生じていました。この不均衡は、西洋の用語が伝統医学の概念の5:1の比率で優遇されていることを如実に示しています。
技術的な翻訳も、古いデータに関連する課題に直面しています:
"技術用語集が3年以上古いと、エラー率が22%高くなります。半導体マニュアル翻訳プロジェクトでは、月次の更新が必要で、用語エラーを2%未満に保っています。"
アウトデートされた用語をフラグ化するアクティブラーニングシステムは、特に技術分野で修正作業量を37%削減することが証明されています。
これらの課題は、翻訳品質を高く維持するために次のセクションで取り上げる実践的なテスト方法の重要性を示しています。
実践におけるテスト
実用的なテスト方法は、訓練データと文脈の課題を特定の戦略を通じて取り組みます:
DubSmartビデオ翻訳
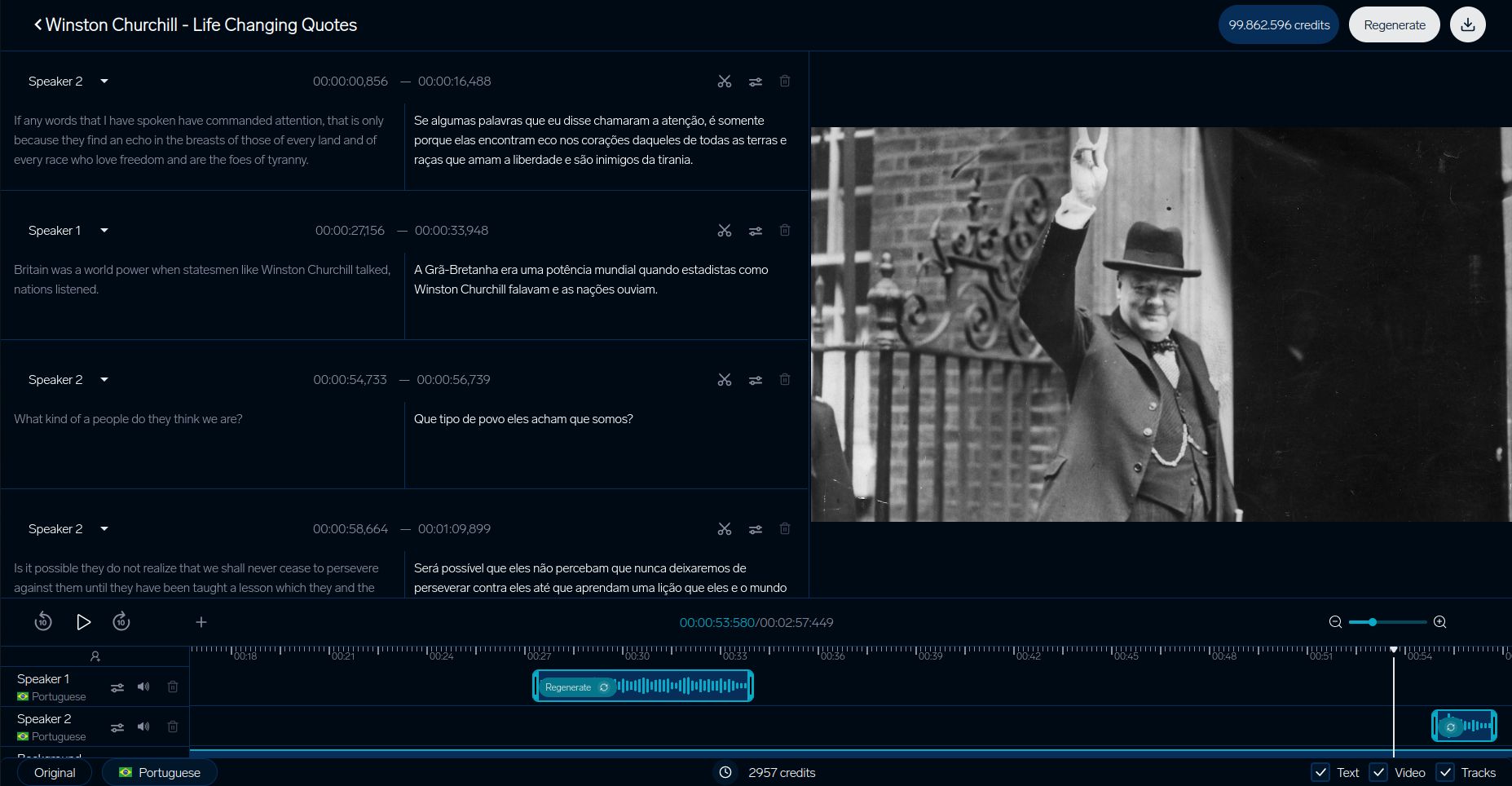
DubSmartのテストシステムは、ビデオ翻訳プラットフォームが品質を確保する方法を示しています。彼らの詳細なプロセスは、特に先に述べた性別の誤訳問題を解決するための視覚的文脈の整合に焦点を当てています:
| コンポーネント | 指標 |
|---|---|
| リップシンク | 200ms未満の遅延 |
| ボイスマッチ | 93%の類似性 |
| ビジュアルシンク | 5%未満のミスマッチ |
ビジネスケーススタディ
大企業はAIツールと人間の専門知識を組み合わせた高度なテストシステムを作り上げました。SAPによるMQM-DQFフレームワークの使用は注目すべき例です:
"ニューラルMT出力と言語学者検証チームを組み合わせることで、SAPは98%の正確率を維持しながら、ポストエディティング作業負荷を40%削減しました。"
IKEAはそのカタログローカリゼーションプロセスを合理化し、ヒューマンとAI検証のミックスにより市場投入までの時間を35%短縮しました。
Booking.comも自動テストの力を証明しています。同社のシステムは毎年45言語で10億以上の翻訳を処理し、コストを40%削減しながらユーザー生成コンテンツの品質を一貫して保っています。
これらの例は、企業が翻訳テストにおける精度、効率、および拡張性を向上させている方法を示しています。
sbb-itb-f4517a0
翻訳テストの次のステップ
テスト手法が進化する中で、3つの重要な分野が品質基準を新たなレベルに引き上げています:
トーンと感情の転送
現代のシステムは、EMO-BLEUフレームワークのおかげで、感情のニュアンスを保持する能力が向上しており、BLEUの0.41に比べて人間の知覚と0.73のピアソン相関を示しています。マルチモーダルトランスフォーマーモデルは大幅に進化し、話者の感情を維持しています。これらのシステムは、言語間の音量変化を±2dB以内に維持し、複雑な感情マーカーを管理することができます。
コンテキストベースの翻訳
コンテキストに敏感なシステムが、翻訳の品質評価の形を再構築しています。優れた例としてDeepLのコンテキストモードがあり、ドキュメントレベルのエンティティトラッキングとリアルタイムなフォーマリティ調整を使用しています。
これらのシステムのテストは、主要なベンチマークに焦点を当ててより高度になっています:
| テストコンポーネント | 現在のベンチマーク | 測定の焦点 |
|---|---|---|
| ファーストワードレスポンス | <900ms | スピーチ開始の正確性 |
| ストリーミング品質 | <4ワードラグ | バッファーの一貫性 |
| コンテキストの整合性 | >0.8スコア | 動的適応 |
これらのシステムは、注釈がレイヤードされた1億以上の文脈に依存するセンテンスペアを処理します。
学習AIシステム
自己改善する翻訳システムは、継続的なフィードバックを統合することにより品質テストの方法を変えつつあります。Orq.aiのフレームワークはこのシフトを強調し、次のようにポストエディティングコストを四半期ごとに37%削減しています:
"COMETスコアが0.6未満の低信頼度セグメントをフラグするアクティブラーニングアーキテクチャ。MQMエラー類型UIで代替案を提示し、検証済みサンプルを使用してモデルの重みを2週間ごとに更新"。
これらのシステムは、低信頼度の翻訳(COMET <0.6)を自動的に識別し、言語専門家によって検証されたサンプルを使用して2週間ごとにモデルを更新します。しかしながら、彼らは倫理的な課題にも直面しています。MITの研究では、適切なデバイアス措置がないと、ジェンダーニュートラリティが22%崩れることが示されています。この問題は、偏った訓練データの問題に関連しており、更新されたモニタリングプロトコルの必要性を強調しています。
TAUSダイナミッククオリティフレームワークv3.1のような業界ツールは、これらのシステムが進化する基準を満たすように支援します。
サマリー
主要なテスト方法
現代のテスト技術は、単純なn-gramマッチングを超え、コンテキスト分析に集中しています。従来の指標のBLEU、TER、ROUGEは、基本評価のための基盤を提供し続けています。しかし、COMETやMQMなどの新しい手法は、人間の判断とより密接に一致していることが証明されています。
例を挙げると、EMO-BLEUフレームワークは、感情的なコンテンツがどれだけよく保持されているかを評価する際に、自動化された指標が人間の判断と73%の相関を達成することを示しています。今日の品質テストは、技術的な正確性だけでなく、文化的ニュアンスの調整の重要性にも重点を置いており、これは企業レベルの導入においての重要な目標です。
ツールとリソース
現代の翻訳テストは、複数の評価方法を融合するプラットフォームを使用することがよくあります。一例としては、幅広いテスト機能と高度なコンテンツ検証システムを提供するDubSmartです。
効果的なテストの主要コンポーネントには次のものがあります:
- 0.6未満の閾値を持つCOMETベースの品質ゲート
- 文化的関連性を確認したグロッサリー
- 2週間ごとに更新されるアクティブラーニングシステム
医療、法律、技術的なコンテンツのような専門分野では、一般的な指標と業界特有の指標を組み合わせてテストが行われます。このアプローチは、評価システムを組み合わせることで品質を22%向上させる結果となりました。
よくある質問
BLEUスコアのデメリットは何ですか?
BLEUスコアは広く使用されているものの、翻訳品質評価においては顕著な限界があります。主な弱点は以下の通りです:
| 限界 | 翻訳評価への影響 |
|---|---|
| 意味的盲点 | 単語の一致だけに注目し、意味や文脈を無視 |
| フレージング多様性のペナルティ | 参考テキストとは異なるフレージングを使用する有効な翻訳をペナルティ |
こうした問題に対処するため、多くのビデオローカリゼーションプラットフォームは評価方法を組み合わせています。例えば、DubSmartのコンテキストアナライザーは、複数の指標を組み合わせてより正確な評価を提供しています。
"BLEUが基礎的な測定を提供する一方で、ビジネス上重要な翻訳には特にセマンティックとコンテキストの分析を必要とする総合的なテストが求められます。"
より正確にするには、専門家は以下を推奨しています:
- 意味とセマンティクスの評価にはCOMET
- 文化的ニュアンスを理解するための人間による検証
- 複雑な文法構造を扱うための言語特化ツール
DubSmartのようにこの層状アプローチは、翻訳が技術的および文脈的基準を満たすように自動化ツールと人間の洞察を組み合わせています。