
Model pengenalan ucapan dinilai berdasarkan seberapa akurat mereka menyalin ucapan dan mempertahankan makna dalam berbagai kondisi. Tiga metrik utama yang digunakan adalah:
- Tingkat Kesalahan Kata (WER): Mengukur kesalahan transkripsi (penambahan, penghapusan, penggantian). Terbaik untuk audio bersih tetapi kesulitan dengan kebisingan atau aksen.
- Tingkat Kesalahan Karakter (CER): Melacak akurasi tingkat karakter, ideal untuk bahasa seperti Cina atau Jepang.
- SeMaScore: Berfokus pada makna semantik, berkinerja baik di lingkungan bising dan dengan aksen yang beragam.
Perbandingan Cepat Metrik
| Metrik | Fokus | Terbaik Untuk | Keterbatasan |
|---|---|---|---|
| WER | Akurasi tingkat kata | Ucapan bersih | Kesulitan dengan kebisingan/aksen |
| CER | Akurasi tingkat karakter | Bahasa Asia | Tidak ada pemahaman semantik |
| SeMaScore | Pertahankan makna semantik | Audio bising, multibahasa | Tuntutan komputasi lebih tinggi |
Metode lanjutan seperti pemodelan akustik dan terpadu lebih meningkatkan evaluasi dengan mensimulasikan kondisi dunia nyata. Metrik ini sangat penting untuk meningkatkan alat seperti platform transkripsi multibahasa.
Metrik Kunci untuk Mengevaluasi Pengenalan Ucapan
Model pengenalan ucapan menggunakan metrik tertentu untuk mengukur seberapa baik kinerjanya. Metrik ini membantu pengembang dan peneliti memahami seberapa efektif sistem Pengenalan Ucapan Otomatis (ASR) mereka dalam berbagai kondisi dan bahasa.
Tingkat Kesalahan Kata (WER)
Tingkat Kesalahan Kata (WER) adalah salah satu metrik yang paling banyak digunakan untuk mengukur seberapa akurat sebuah sistem menyalin ucapan. Ini mengidentifikasi kesalahan dalam tiga kategori:
- Penambahan: Kata-kata yang ditambahkan yang seharusnya tidak ada.
- Penghapusan: Kata-kata yang hilang dari transkripsi.
- Penggantian: Kata-kata yang salah menggantikan yang benar.
Tujuannya adalah mencapai WER yang lebih rendah, karena mencerminkan akurasi yang lebih baik. Namun, WER dapat memiliki kelemahan, terutama dalam situasi dengan kebisingan latar belakang atau pola ucapan yang tidak biasa.
Tingkat Kesalahan Karakter (CER)
Tingkat Kesalahan Karakter (CER) menawarkan analisis yang lebih rinci dengan berfokus pada karakter individual daripada kata lengkap. Hal ini membuatnya sangat berguna untuk bahasa seperti Cina atau Jepang, di mana karakter membawa makna yang signifikan.
CER sangat efektif untuk sistem multibahasa atau kasus di mana batasan kata tidak jelas. Meskipun memberikan analisis linguistik yang rinci, metrik baru seperti SeMaScore bertujuan untuk menjawab tantangan yang lebih luas terkait makna.
SeMaScore
SeMaScore melampaui metrik tradisional seperti WER dan CER dengan memasukkan lapisan semantik ke dalam proses evaluasi. Ini mengukur seberapa baik sistem mempertahankan makna yang dimaksudkan, bukan hanya kata atau karakter yang tepat.
Berikut ini bagaimana SeMaScore menonjol dalam skenario tertentu:
| Tipe Skenario | Bagaimana SeMaScore Membantu |
|---|---|
| Lingkungan Bising | Mengikuti persepsi manusia di lingkungan bising |
| Ucapan Atypical | Sejalan dengan evaluasi ahli terhadap makna |
| Dialek Kompleks | Mempertahankan akurasi semantik di berbagai dialek |
SeMaScore sangat berguna untuk menilai sistem ASR dalam kondisi yang menantang, memberikan evaluasi yang lebih luas dan lebih berarti terhadap kinerjanya. Bersama-sama, metrik ini menawarkan kerangka kerja yang baik untuk memahami bagaimana performa sistem ASR dalam situasi yang berbeda.
Metode Lanjutan untuk Mengevaluasi Model ASR
Proses evaluasi model Pengenalan Ucapan Otomatis (ASR) telah bergerak melampaui metrik dasar, menggunakan teknik yang lebih maju untuk mendapatkan wawasan lebih mendalam tentang bagaimana sistem ini bekerja.
Peran Pemodelan Akustik
Pemodelan akustik menghubungkan sinyal audio dengan unit linguistik dengan menggunakan representasi statistik dari fitur ucapan. Perannya dalam evaluasi ASR bergantung pada beberapa faktor teknis:
| Faktor | Dampak pada Evaluasi |
|---|---|
| Sampling Rate & Bits per Sample | Nilai yang lebih tinggi meningkatkan akurasi pengenalan tetapi dapat memperlambat pemrosesan dan meningkatkan ukuran model |
| Kebisingan Lingkungan & Variasi Ucapan | Membuat pengenalan lebih sulit; model perlu diuji dengan data yang sangat beragam dan menantang |
Model akustik dirancang untuk menangani berbagai pola ucapan dan tantangan lingkungan, yang sering kali terlewat oleh metrik evaluasi tradisional.
Pemodelan Terpadu dalam ASR
Tidak seperti pemodelan akustik yang berfokus pada fitur ucapan tertentu, pemodelan terpadu menggabungkan beberapa tugas pengenalan ke dalam satu kerangka kerja. Pendekatan ini meningkatkan evaluasi ASR dengan mencerminkan kasus penggunaan dunia nyata, di mana sistem sering menangani beberapa tugas sekaligus.
Faktor penting untuk evaluasi meliputi:
- Menyeimbangkan kecepatan dengan akurasi
- Mempertahankan kinerja di bawah penggunaan yang berat
- Memastikan hasil yang konsisten di berbagai lingkungan
Platform seperti DubSmart menggunakan teknik canggih ini untuk meningkatkan pengenalan ucapan untuk konten multibahasa dan pengkloningan suara.
Metode ini memberikan dasar untuk membandingkan metrik evaluasi yang berbeda, memberikan wawasan tentang kelebihan dan keterbatasannya.
Aplikasi dan Tantangan Metrik Evaluasi
Metrik evaluasi memainkan peran penting dalam meningkatkan alat seperti DubSmart dan mengatasi tantangan berkelanjutan dalam sistem pengenalan ucapan otomatis (ASR).
Penggunaan dalam Alat AI seperti DubSmart
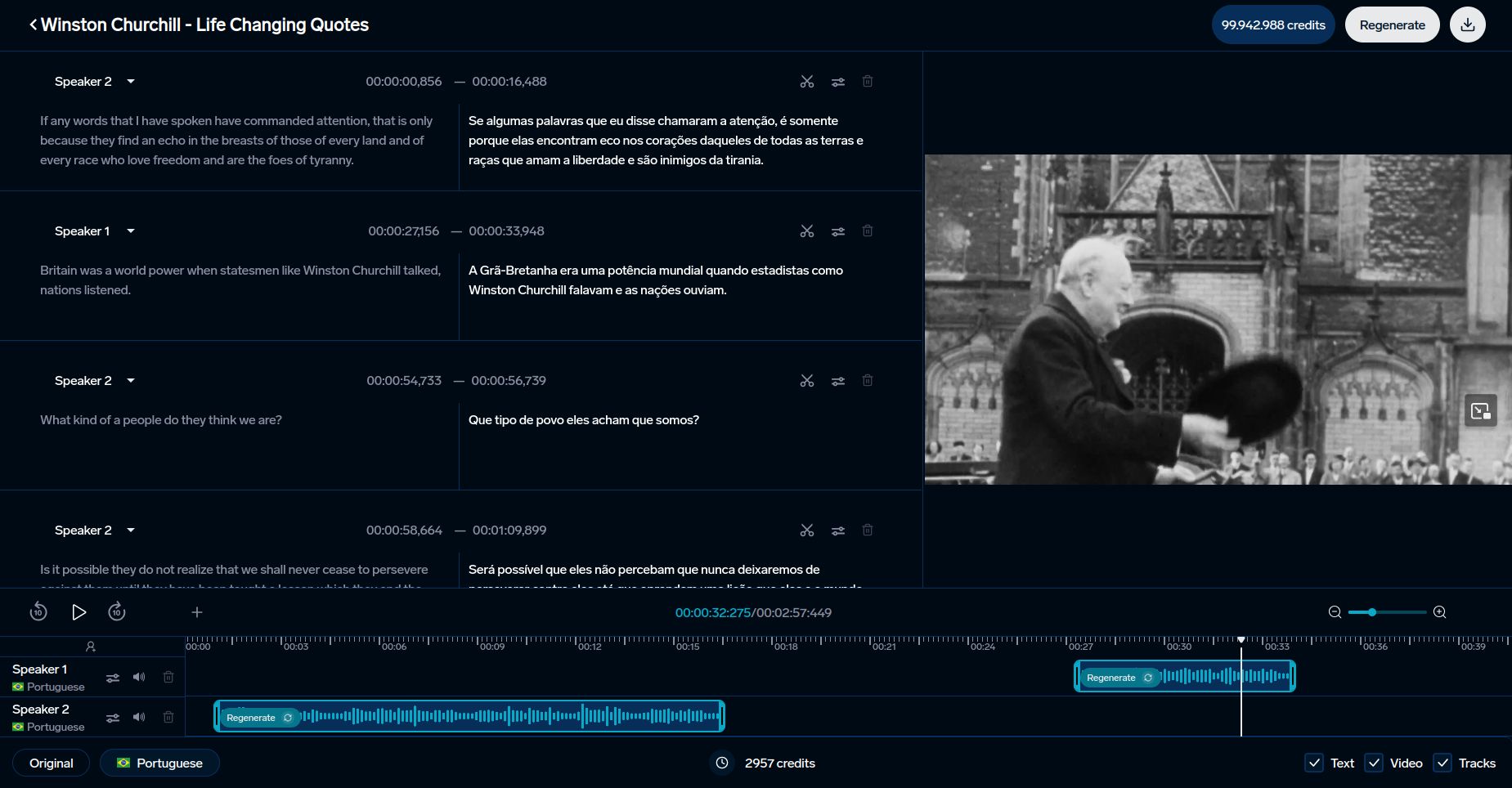
Metrik pengenalan ucapan sangat penting untuk meningkatkan alat bahasa berbasis AI. DubSmart memanfaatkan metrik ini untuk menyediakan layanan dubbing dan transkripsi multibahasa dalam 33 bahasa. Platform ini mengintegrasikan baik metrik tradisional maupun lanjut untuk memastikan kualitas:
| Metrik | Aplikasi | Dampak |
|---|---|---|
| SeMaScore | Lingkungan Multibahasa dan Bising | Mempertahankan akurasi semantik dan retensi makna |
Kombinasi ini memastikan presisi tinggi, bahkan dalam skenario yang menantang seperti memproses banyak pembicara atau menangani audio yang kompleks. Akurasi semantik sangat penting untuk tugas seperti pengkloningan suara dan menghasilkan konten multibahasa.
Tantangan dalam Evaluasi ASR
Metode evaluasi tradisional sering jatuh pendek ketika berhadapan dengan aksen, kebisingan latar belakang, atau variasi dialek. Alat lanjutan seperti SeMaScore menjawab kekurangan ini dengan memasukkan analisis berbasis semantik. SeMaScore, pada khususnya, menandai kemajuan dengan menggabungkan evaluasi tingkat kesalahan dengan pemahaman semantik yang lebih dalam.
"Evaluasi pengenalan ucapan memerlukan keseimbangan antara akurasi, kecepatan, dan adaptabilitas di berbagai bahasa, aksen, dan lingkungan."
Untuk meningkatkan evaluasi ASR, beberapa faktor turut berperan:
- Meningkatkan model akustik untuk mencapai keseimbangan antara presisi dan efisiensi
- Memenuhi kebutuhan pemrosesan real-time tanpa mengorbankan akurasi
- Memastikan kinerja konsisten di berbagai konteks
Teknik evaluasi baru bertujuan untuk memberikan wawasan yang lebih rinci ke dalam kinerja ASR, terutama dalam situasi yang menuntut. Kemajuan ini membantu menyempurnakan alat untuk perbandingan sistem yang lebih baik dan efektivitas keseluruhan.
sbb-itb-f4517a0
Perbandingan Metrik Evaluasi
Mengevaluasi sistem pengenalan ucapan sering kali berkaitan dengan memilih metrik yang tepat. Setiap metrik menyoroti aspek kinerja yang berbeda, sehingga penting untuk mencocokkan metrik dengan kasus penggunaan spesifik.
Sementara WER (Tingkat Kesalahan Kata) dan CER (Tingkat Kesalahan Karakter) sudah mapan, opsi baru seperti SeMaScore memberikan perspektif yang lebih luas. Inilah bagaimana mereka saling dibandingkan:
Tabel Perbandingan Metrik
| Metrik | Kinerja Akurasi | Pemahaman Semantik | Skenario Kasus Penggunaan | Kecepatan Pemrosesan | Tuntutan Komputasi |
|---|---|---|---|---|---|
| WER | Tinggi untuk ucapan bersih, kesulitan dengan kebisingan | Konteks semantik terbatas | Evaluasi ASR standar, audio bersih | Sangat cepat | Minimal |
| CER | Bagus untuk analisis tingkat karakter | Tidak ada analisis semantik | Bahasa Asia, evaluasi fonetik | Cepat | Rendah |
| SeMaScore | Kuat di berbagai kondisi | Korelasi semantik tinggi | Multiaksen, lingkungan bising | Sedang | Sedang hingga tinggi |
WER bekerja dengan baik dalam skenario audio bersih tetapi kesulitan dengan ucapan berisik atau beraksen karena kurangnya kedalaman semantik. Di sisi lain, SeMaScore menjembatani celah tersebut dengan menggabungkan analisis kesalahan dengan pemahaman semantik, menjadikannya pilihan yang lebih baik untuk kondisi ucapan yang beragam dan menantang.
Seiring alat seperti DubSmart mengintegrasikan sistem ASR ke dalam transkripsi multibahasa dan pengkloningan suara, memilih metrik yang tepat menjadi sangat penting. Penelitian menunjukkan bahwa SeMaScore berkinerja lebih baik dalam lingkungan berisik atau kompleks, memberikan evaluasi yang lebih andal.
Pada akhirnya, pilihan bergantung pada faktor seperti kompleksitas ucapan, keberagaman aksen, dan sumber daya yang tersedia. WER dan CER bagus untuk tugas sederhana, sedangkan SeMaScore lebih baik untuk penilaian yang lebih bernuansa, mencerminkan pergeseran ke arah metrik yang lebih sesuai dengan interpretasi manusia.
Perbandingan ini menunjukkan bagaimana evaluasi ASR berkembang, membentuk alat dan sistem yang mengandalkan teknologi ini.
Kesimpulan
Perbandingan metrik menyoroti bagaimana evaluasi ASR telah tumbuh dan ke mana arahnya. Metrik telah beradaptasi untuk memenuhi tuntutan sistem ASR yang semakin kompleks. Sementara Tingkat Kesalahan Kata (WER) dan Tingkat Kesalahan Karakter (CER) tetap menjadi tolok ukur utama, ukuran baru seperti SeMaScore mencerminkan fokus pada menggabungkan pemahaman semantik dengan analisis kesalahan tradisional.
SeMaScore menawarkan keseimbangan antara kecepatan dan presisi, menjadikannya pilihan yang kuat untuk aplikasi praktis. Sistem ASR modern, seperti yang digunakan oleh platform seperti DubSmart, harus menavigasi skenario dunia nyata yang menantang, termasuk kondisi akustik yang beragam dan kebutuhan multibahasa. Misalnya, DubSmart mendukung pengenalan ucapan dalam 70 bahasa, menunjukkan pentingnya metode evaluasi lanjutan. Metrik ini tidak hanya meningkatkan akurasi sistem tetapi juga memperkuat kemampuan mereka menghadapi tantangan linguistik dan akustik yang bervariasi.
Ke depan, metrik masa depan diperkirakan akan menggabungkan analisis kesalahan dengan pemahaman makna yang lebih dalam. Seiring teknologi pengenalan ucapan berkembang, metode evaluasi harus menghadapi tantangan lingkungan berisik, aksen yang beragam, dan pola ucapan yang rumit. Pergeseran ini akan mempengaruhi cara perusahaan merancang dan menerapkan sistem ASR, memprioritaskan metrik yang menilai baik akurasi maupun pemahaman.
Memilih metrik yang tepat sangat penting, baik untuk audio bersih atau skenario multibahasa kompleks. Seiring teknologi ASR terus berkembang, metrik yang berkembang ini akan memainkan peran penting dalam membentuk sistem yang lebih memenuhi kebutuhan komunikasi manusia.
FAQs
Metrik apa yang digunakan untuk mengevaluasi program pengenalan ucapan?
Metrik utama untuk mengevaluasi sistem Pengenalan Ucapan Otomatis (ASR) adalah Tingkat Kesalahan Kata (WER). Ini menghitung akurasi transkripsi dengan membandingkan jumlah kesalahan (penambahan, penghapusan, dan penggantian) dengan total kata dalam transkrip asli. Metode lain, SeMaScore, fokus pada evaluasi semantik, menawarkan wawasan yang lebih baik dalam skenario menantang, seperti ucapan yang beraksen atau berisik.
Bagaimana Anda mengevaluasi model ASR?
Mengevaluasi model ASR melibatkan penggunaan campuran metrik untuk mengukur baik akurasi transkripsi dan seberapa baik makna dipertahankan. Ini memastikan sistem berkinerja andal dalam berbagai situasi.
| Komponen Evaluasi | Deskripsi | Praktik Terbaik |
|---|---|---|
| Tingkat Kesalahan Kata (WER) | Melacak akurasi tingkat kata dibandingkan dengan transkrip manusia | Hitung rasio kesalahan (penambahan, penghapusan, penggantian) terhadap total kata |
| Tingkat Kesalahan Karakter (CER) | Fokus pada akurasi di tingkat karakter | Terbaik untuk bahasa seperti Cina atau Jepang |
| Pemahaman Semantik | Memeriksa apakah makna dipertahankan | Gunakan SeMaScore untuk evaluasi semantik yang lebih dalam |
| Pengujian Dunia Nyata | Mengevaluasi kinerja dalam pengaturan yang beragam (mis. bising, multibahasa) | Uji di berbagai lingkungan akustik |
"Evaluasi ASR secara tradisional mengandalkan metrik berbasis kesalahan".
Saat menilai model ASR, pertimbangkan faktor praktis ini di samping metrik akurasi:
- Kinerja dalam lingkungan suara yang berbeda
- Penanganan aksen dan dialek
- Kemampuan pemrosesan real-time
- Ketahanan terhadap kebisingan latar belakang
Sesuaikan proses evaluasi dengan aplikasi spesifik Anda sambil mematuhi standar industri. Misalnya, platform seperti DubSmart menekankan akurasi semantik untuk konten multibahasa, menjadikan metode evaluasi ini sangat relevan.