
Spracherkennungsmodelle werden danach bewertet, wie genau sie Sprache transkribieren und die Bedeutung unter verschiedenen Bedingungen beibehalten. Die drei Hauptmetriken sind:
- Word Error Rate (WER): Misst Transkriptionsfehler (Einfügungen, Löschungen, Ersetzungen). Am besten für saubere Audioaufnahmen, hat jedoch Probleme mit Lärm oder Akzenten.
- Character Error Rate (CER): Verfolgt die Genauigkeit auf Zeichenebene, ideal für Sprachen wie Chinesisch oder Japanisch.
- SeMaScore: Konzentriert sich auf die semantische Bedeutung und funktioniert gut in lauten Umgebungen und bei verschiedenen Akzenten.
Schneller Vergleich der Metriken
| Metrik | Fokus | Am besten für | Einschränkungen |
|---|---|---|---|
| WER | Wortgenauigkeit | Saubere Sprache | Hat Probleme mit Lärm/Akzenten |
| CER | Zeichen-Genauigkeit | Asiatische Sprachen | Kein semantisches Verständnis |
| SeMaScore | Erhalt der semantischen Bedeutung | Laute, mehrsprachige Audioaufnahmen | Höherer Rechenaufwand |
Fortschrittliche Methoden wie akustisches und einheitliches Modellieren verbessern die Bewertungen, indem sie reale Bedingungen simulieren. Diese Metriken sind entscheidend für die Verbesserung von Tools wie mehrsprachigen Transkriptionsplattformen.
Wichtige Metriken zur Bewertung der Spracherkennung
Spracherkennungsmodelle verwenden spezifische Metriken, um zu bewerten, wie gut sie abschneiden. Diese Metriken helfen Entwicklern und Forschern zu verstehen, wie effektiv ihre Automatic Speech Recognition (ASR)-Systeme unter verschiedenen Bedingungen und Sprachen sind.
Word Error Rate (WER)
Word Error Rate (WER) ist eine der am häufigsten verwendeten Metriken, um zu messen, wie genau ein System Sprache transkribiert. Es identifiziert Fehler in drei Kategorien:
- Einfügungen: Wörter, die hinzugefügt wurden und nicht da sein sollten.
- Löschungen: Wörter, die in der Transkription fehlen.
- Ersetzungen: Falsche Wörter, die anstelle der richtigen Worte verwendet werden.
Das Ziel ist es, einen niedrigeren WER zu erreichen, da er eine bessere Genauigkeit widerspiegelt. Dennoch kann WER Nachteile haben, insbesondere in Situationen mit Hintergrundgeräuschen oder ungewöhnlichen Sprachmustern.
Character Error Rate (CER)
Character Error Rate (CER) bietet eine detailliertere Analyse, indem es sich auf einzelne Zeichen anstatt auf ganze Wörter konzentriert. Dies macht es besonders nützlich für Sprachen wie Chinesisch oder Japanisch, in denen Zeichen eine wichtige Bedeutung haben.
CER ist besonders effektiv für mehrsprachige Systeme oder Fälle, in denen Wortgrenzen unklar sind. Während es eine detaillierte sprachliche Analyse bietet, zielen neuere Metriken wie SeMaScore darauf ab, breitere Herausforderungen im Zusammenhang mit Bedeutung anzugehen.
SeMaScore
SeMaScore geht über traditionelle Metriken wie WER und CER hinaus, indem es eine semantische Ebene in den Bewertungsprozess einbezieht. Es misst, wie gut das System die beabsichtigte Bedeutung beibehält, nicht nur die genauen Wörter oder Zeichen.
So hebt sich SeMaScore in bestimmten Szenarien ab:
| Szenariotyp | Wie SeMaScore hilft |
|---|---|
| Laute Umgebung | Entspricht menschlicher Wahrnehmung in lauten Umgebungen |
| Ungewöhnliche Sprache | Stimmt mit Expertenbewertungen der Bedeutung überein |
| Komplexe Dialekte | Erhält semantische Genauigkeit über Dialekte hinweg |
SeMaScore ist besonders nützlich für die Bewertung von ASR-Systemen unter schwierigen Bedingungen und bietet eine umfassendere und bedeutungsvollere Bewertung ihrer Leistung. Zusammen bieten diese Metriken ein umfassendes Rahmenwerk zum Verständnis der Leistung von ASR-Systemen in verschiedenen Situationen.
Fortgeschrittene Methoden zur Bewertung von ASR-Modellen
Der Prozess der Bewertung von Automatic Speech Recognition (ASR)-Modellen geht über einfache Metriken hinaus und verwendet fortschrittlichere Techniken, um tiefere Einblicke in die Leistung dieser Systeme zu gewinnen.
Die Rolle der akustischen Modellierung
Die akustische Modellierung verbindet Audiosignale mit sprachlichen Einheiten, indem statistische Darstellungen von Sprachmerkmalen verwendet werden. Ihre Rolle bei der ASR-Bewertung hängt von mehreren technischen Faktoren ab:
| Faktor | Auswirkung auf die Bewertung |
|---|---|
| Abtastrate & Bits pro Abtastung | Höhere Werte verbessern die Erkennungsgenauigkeit, können jedoch die Verarbeitung verlangsamen und die Modellgröße erhöhen |
| Umgebungsgeräusche & Sprachvariationen | Erschweren die Erkennung; Modelle müssen mit vielfältigen und herausfordernden Daten getestet werden |
Akustische Modelle sind darauf ausgelegt, eine Vielzahl von Sprachmustern und Umweltbedingungen zu bewältigen, die bei herkömmlichen Bewertungsmetriken oft übersehen werden.
Einheitliches Modellieren in der ASR
Im Gegensatz zur akustischen Modellierung, die sich auf spezifische Sprachmerkmale konzentriert, kombiniert das einheitliche Modellieren mehrere Erkennungsaufgaben in einem einzigen Framework. Dieser Ansatz verbessert die ASR-Bewertung, indem er reale Anwendungsfälle widerspiegelt, bei denen Systeme oft mehrere Aufgaben gleichzeitig bewältigen.
Wichtige Faktoren für die Bewertung sind:
- Ausgewogenheit von Geschwindigkeit und Genauigkeit
- Aufrechterhaltung der Leistung unter starker Nutzung
- Sicherstellung konsistenter Ergebnisse in unterschiedlichen Umgebungen
Plattformen wie DubSmart nutzen diese fortschrittlichen Techniken, um die Spracherkennung für mehrsprachige Inhalte und Stimmenklonen zu verbessern.
Diese Methoden bieten eine Grundlage für den Vergleich verschiedener Bewertungsmetriken und beleuchten ihre Vor- und Nachteile.
Anwendungen und Herausforderungen von Bewertungsmetriken
Bewertungsmetriken spielen eine entscheidende Rolle bei der Verbesserung von Tools wie DubSmart und der Bewältigung laufender Herausforderungen in Automatic Speech Recognition (ASR)-Systemen.
Verwendung in KI-Tools wie DubSmart
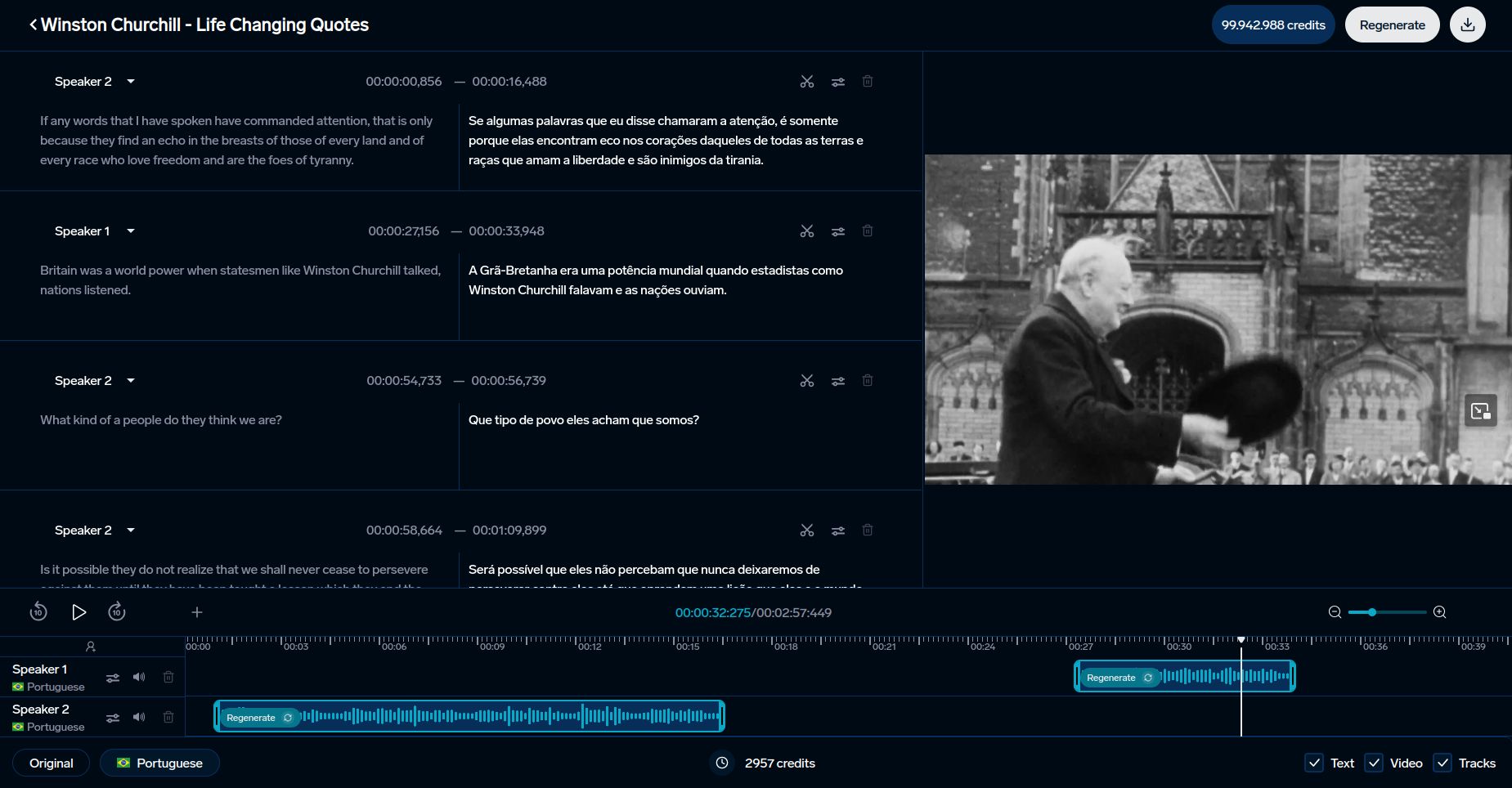
Spracherkennungsmetriken sind entscheidend für die Verbesserung von KI-gestützten Sprachtools. DubSmart nutzt diese Metriken, um mehrsprachige Synchronisations- und Transkriptionsdienste in 33 Sprachen anzubieten. Die Plattform integriert sowohl traditionelle als auch fortschrittliche Metriken, um Qualität sicherzustellen:
| Metrik | Anwendung | Auswirkung |
|---|---|---|
| SeMaScore | Mehrsprachige und laute Umgebungen | Erhält semantische Genauigkeit und Bedeutungsbeibehaltung |
Diese Kombination gewährleistet hohe Präzision, selbst in herausfordernden Szenarien wie der Verarbeitung mehrerer Sprecher oder der Handhabung komplexer Audiosignale. Semantische Genauigkeit ist besonders wichtig für Aufgaben wie Stimmenklonen und die Erstellung mehrsprachiger Inhalte.
Herausforderungen bei der ASR-Bewertung
Traditionelle Bewertungsmethoden stoßen oft an ihre Grenzen, wenn es um Akzente, Hintergrundgeräusche oder Dialektvariationen geht. Fortgeschrittene Tools wie SeMaScore schließen diese Lücken, indem sie eine auf semantischer Basis durchgeführte Analyse einbeziehen. SeMaScore markiert insbesondere einen Fortschritt, indem es Fehlerratenbewertungen mit einem tieferen semantischen Verständnis kombiniert.
"Die Bewertung der Spracherkennung erfordert eine Balance zwischen Genauigkeit, Geschwindigkeit und Anpassungsfähigkeit über Sprachen, Akzente und Umgebungen hinweg."
Zur Verbesserung der ASR-Bewertung spielen mehrere Faktoren eine Rolle:
- Verbesserung der akustischen Modelle, um ein Gleichgewicht zwischen Präzision und Effizienz zu erreichen
- Deckung der Echtzeit-Verarbeitungsanforderungen ohne Kompromisse bei der Genauigkeit
- Sicherstellung gleichbleibender Leistung in unterschiedlichen Kontexten
Neuere Bewertungstechniken zielen darauf ab, detailliertere Einblicke in die ASR-Leistung zu bieten, insbesondere in anspruchsvollen Situationen. Diese Fortschritte helfen, Tools für bessere Systemvergleiche und eine insgesamt bessere Effektivität zu verfeinern.
sbb-itb-f4517a0
Vergleich der Bewertungsmetriken
Die Bewertung von Spracherkennungssystemen hängt oft davon ab, die richtige Metrik auszuwählen. Jede hebt unterschiedliche Aspekte der Leistung hervor, weshalb es wichtig ist, die Metrik an den spezifischen Anwendungsfall anzupassen.
Während WER (Word Error Rate) und CER (Character Error Rate) gut etabliert sind, bieten neuere Optionen wie SeMaScore eine breitere Perspektive. So bewerten sie sich im Vergleich:
Metrik-Vergleichstabelle
| Metrik | Genauigkeitsleistung | Semantisches Verständnis | Anwendungsszenarien | Verarbeitungsgeschwindigkeit | Rechenanforderungen |
|---|---|---|---|---|---|
| WER | Hoch für saubere Sprache, Probleme bei Lärm | Begrenzter semantischer Kontext | Standard-ASR-Bewertung, sauberes Audio | Sehr schnell | Minimal |
| CER | Großartig für zeichenbasierte Analyse | Keine semantische Analyse | Asiatische Sprachen, phonetik Bewertung | Schnell | Niedrig |
| SeMaScore | Stark unter verschiedenen Bedingungen | Hohe semantische Korrelation | Multi-Akzent, laute Umgebungen | Moderat | Mittel bis hoch |
WER funktioniert gut in sauberen Audioszenarien, hat jedoch Probleme mit lauter oder akzentreicher Sprache aufgrund des Mangels an semantischer Tiefe. Auf der anderen Seite überbrückt SeMaScore diese Lücke, indem es Fehleranalyse mit semantischem Verständnis kombiniert, was es besser für vielfältige und herausfordernde Sprachbedingungen macht.
Da Tools wie DubSmart ASR-Systeme in mehrsprachige Transkription und Stimmenklonen integrieren, wird die Auswahl der richtigen Metrik kritisch. Studien zeigen, dass SeMaScore in lauten oder komplexen Umgebungen besser abschneidet und eine zuverlässigere Bewertung bietet.
Letztendlich hängt die Wahl von Faktoren wie der Komplexität der Sprache, der Vielfalt der Akzente und den verfügbaren Ressourcen ab. WER und CER sind großartig für einfachere Aufgaben, während SeMaScore besser für subtilere Bewertungen geeignet ist und einen Wandel hin zu Metriken widerspiegelt, die stärker mit menschlicher Interpretation übereinstimmen.
Diese Vergleiche zeigen, wie sich die ASR-Bewertung entwickelt und die Werkzeuge und Systeme formt, die auf diese Technologien angewiesen sind.
Fazit
Der Vergleich von Metriken zeigt, wie sich die ASR-Bewertung weiterentwickelt hat und wohin sie sich bewegt. Die Metriken haben sich angepasst, um den Anforderungen immer komplexer werdender ASR-Systeme gerecht zu werden. Während Word Error Rate (WER) und Character Error Rate (CER) nach wie vor wichtige Maßstäbe sind, spiegeln neuere Messungen wie SeMaScore einen Fokus auf die Kombination von semantischem Verständnis mit traditioneller Fehleranalyse wider.
SeMaScore bietet eine Balance aus Geschwindigkeit und Präzision und ist damit eine starke Wahl für praktische Anwendungen. Moderne ASR-Systeme, wie die von Plattformen wie DubSmart genutzten, müssen schwierige reale Szenarien navigieren, einschließlich diverser akustischer Bedingungen und mehrsprachiger Anforderungen. Zum Beispiel unterstützt DubSmart die Spracherkennung in 70 Sprachen, was die Notwendigkeit fortschrittlicher Bewertungsmethoden verdeutlicht. Diese Metriken verbessern nicht nur die Systemgenauigkeit, sondern auch ihre Fähigkeit, mit vielfältigen sprachlichen und akustischen Herausforderungen umzugehen.
Mit Blick auf die Zukunft wird erwartet, dass zukünftige Metriken Fehleranalysen mit einem tieferen Verständnis der Bedeutung kombinieren. Da sich die Spracherkennungstechnologie weiterentwickelt, müssen sich auch die Bewertungsmethoden den Herausforderungen lauter Umgebungen, vielfältiger Akzente und komplexer Sprachmuster stellen. Diese Verschiebung wird beeinflussen, wie Unternehmen ASR-Systeme entwerfen und implementieren und Metriken priorisieren, die sowohl Genauigkeit als auch Verständnis bewerten.
Die Auswahl der geeigneten Metrik ist entscheidend, sei es für sauberes Audio oder komplexe mehrsprachige Szenarien. Da sich die ASR-Technologie weiterentwickelt, werden diese sich entwickelnden Metriken eine Schlüsselrolle bei der Gestaltung von Systemen spielen, die besser auf menschliche Kommunikationsbedürfnisse eingehen.
FAQs
Welche Metrik wird zur Bewertung von Spracherkennungsprogrammen verwendet?
Die Hauptmetrik zur Bewertung von Automatic Speech Recognition (ASR)-Systemen ist die Word Error Rate (WER). Sie berechnet die Genauigkeit der Transkription, indem sie die Anzahl der Fehler (Einfügungen, Löschungen und Ersetzungen) mit der Gesamtanzahl der Wörter im ursprünglichen Transkript vergleicht. Eine weitere Methode, SeMaScore, konzentriert sich auf die semantische Bewertung und bietet bessere Einblicke in herausfordernden Szenarien, wie akzentuierter oder lauter Sprache.
Wie bewertet man ein ASR-Modell?
Die Bewertung eines ASR-Modells umfasst die Verwendung einer Mischung von Metriken, um sowohl die Genauigkeit der Transkription als auch die Beibehaltung der Bedeutung zu messen. Dies stellt sicher, dass das System in verschiedenen Situationen zuverlässig arbeitet.
| Bewertungskomponente | Beschreibung | Best Practice |
|---|---|---|
| Word Error Rate (WER) | Verfolgt die Genauigkeit auf Wortebene im Vergleich zu menschlichen Transkripten | Das Verhältnis von Fehlern (Einfügungen, Löschungen, Ersetzungen) zu Gesamtwörtern berechnen |
| Character Error Rate (CER) | Konzentriert sich auf die Genauigkeit auf Zeichenebene | Am besten für Sprachen wie Chinesisch oder Japanisch |
| Semantisches Verständnis | Prüft, ob die Bedeutung erhalten bleibt | SeMaScore für tiefergehende semantische Bewertung verwenden |
| Echte Umwelttests | Bewertet die Leistung in unterschiedlichen Einstellungen (z.B. laut, mehrsprachig) | In verschiedenen akustischen Umgebungen testen |
"ASR-Evaluation hat sich traditionell auf fehlerbasierte Metriken verlassen".
Bei der Bewertung von ASR-Modellen sollten neben Genauigkeitsmetriken auch diese praktischen Faktoren berücksichtigt werden:
- Leistung in verschiedenen Klanganwendungen
- Umgang mit Akzenten und Dialekten
- Echtzeit-Verarbeitungsfähigkeit
- Robustheit gegenüber Hintergrundgeräuschen
Passen Sie den Bewertungsprozess an Ihre spezifische Anwendung an und halten Sie dabei branchenübliche Standards ein. Beispielsweise betonen Plattformen wie DubSmart die semantische Genauigkeit für mehrsprachige Inhalte, sodass diese Bewertungsmethoden besonders relevant sind.