
Những Gì Người Nghe Thực Sự Nghe Thấy Khi một Giọng Nói Được Thể Hiện Hoàn Hảo
Lần quay thứ 17. Giọng nói Morgan Freeman gần như chính xác — nhịp điệu ở đó, giọng Mississippi gần như thuyết phục — nhưng sự trầm lắng bị mất. Người nghe của bạn nói "gần như," từ này trong công việc giọng nói có cùng nghĩa với "không." Bạn xóa cảnh quay. Bạn thử lại. Bốn mươi phút sau, bạn không có gì có thể sử dụng cho giọng nói YouTube và cổ họng bắt đầu mệt.
Đây là cái bẫy nuốt chửng những người sáng tạo cố gắng xây dựng kênh đa ngôn ngữ: làm chủ giọng nói nhân vật bằng tiếng Anh, rồi xem nó sụp đổ ngay khi phụ đề tiếng Tây Ban Nha hoặc tiếng Hindi xuất hiện trong kế hoạch sản xuất — vì giọng nói là ghi nhớ âm tiết, chứ không phải chữ ký giọng được nội tâm hóa. Giờ phòng thu tích tụ. Các cảnh quay bị từ chối. Kế hoạch địa phương hóa lặng lẽ bị dừng. Nội dung nên được phát hành nhưng không.
Hướng dẫn này phân tích những gì khiến giọng nói được thể hiện thực sự đạt được tai người nghe, bốn bài tập xây dựng kỹ năng nền tảng, và nơi sao chép giọng nói AI phù hợp với quy trình làm việc như một công cụ mở rộng quy mô — không phải thay thế cho kỹ năng bên dưới.

Mục Lục
- Những Gì Người Nghe Thực Sự Nghe Thấy Khi một Giọng Nói Được Thể Hiện Hoàn Hảo
- Năm Khối Xây Dựng Giọng Nói Mà Mọi Giọng Nói Phụ Thuộc Vào
- Bốn Bài Tập Xây Dựng Trí Nhớ Cơ Bắp Giọng Nói
- Nơi Thực Hành Giọng Nói Thủ Công Chạm Trần Cứng
- Cách Sao Chép Giọng Nói AI Mở Rộng Phạm Vi Của Một Diễn Viên Giọng Nói Tài Năng
- Xây Dựng Bộ Công Cụ Giọng Nói của Bạn — Kết Hợp Nút Cổ Chai của Bạn với Đường Đi Đúng
- Câu Hỏi Thường Gặp
Người nghe không xác định giọng nói chỉ bằng cao độ. Họ xác định bằng dấu vân tay quang phổ — cấu trúc formant, các mẫu rung động, và chữ ký thời gian mà một nền giải phẫu đường vocal cụ thể tạo ra. Theo nhà khoa học giọng nói Ingo R. Titze trong Principles of Voice Production, chất lượng giọng nói được hình thành chủ yếu bởi cấu hình đường vocal và cộng hưởng, không phải tần số cơ bản. Hai người có thể huýt sáo cùng một nốt nhạc chính xác và vẫn nghe hoàn toàn khác nhau, vì cổ họng, miệng, và xoang của họ hoạt động như những bộ lọc khác nhau trên cùng một rung động.
Đó là chìa khóa cho giọng nói được thể hiện. Công việc không phải là khớp một biến. Đó là tái tạo một chữ ký năm lớp:
- Đường cong cao độ — không chỉ cao độ trung bình, mà là nơi nó tăng và giảm bên trong một câu
- Vị trí cộng hưởng — ngực, mặt, mũi, đầu
- Mẫu thở và tốc độ — nơi người nói hít vào và bao lâu tạm dừng của họ
- Chữ ký phát âm — sức tấn công phụ âm và hình dạng nguyên âm
- Ngữ cảnh cảm xúc — cảm giác thúc đẩy mọi từ, lớp mà người tập chưa học bỏ qua
Một bảng chẩn đoán đầy đủ được đưa ra trong phần tiếp theo. Bây giờ, hãy giữ khung hình: chữ ký, không phải bề mặt.
Nghe Giống Như Với Thể Hiện Là
Có một sự phân biệt mà thế giới diễn xuất giọng nói làm việc xem như không thể thương lượng: nghe giống như ai đó và thể hiện giống họ là những kỹ năng khác nhau. Dee Bradley Baker — diễn viên giọng nói nhân vật đằng sau nhiều phần của Star Wars: The Clone Wars và Avatar: The Last Airbender — đã xây dựng toàn bộ thực hành giảng dạy của mình xung quanh lập luận rằng giọng nói nhân vật chỉ hoạt động khi diễn viên hiểu cuộc sống cảm xúc, ý định, và vật lý của nhân vật. Không chỉ phát âm. Không chỉ tông giọng. Theo tài liệu giáo dục của anh ta trong I Want to Be a Voice Actor!, một giọng nói hướng đến âm thanh mà không có ý định tạo ra điều gì đó người nghe ghi lại là cơ học, ngay cả khi họ không thể nói rõ tại sao.
Hai Phân Tích Để Làm Cho Lý Thuyết Cụ Thể
Xem xét các giọng nói Darth Vader của người tập. Chúng nghe mỏng vì chúng hướng đến sai hai biến: cao độ (thấp) và hiệu ứng thở (thở ra nặng). Những gì họ bỏ lỡ là cộng hưởng ngực nơi giọng nói của James Earl Jones thực sự sống. Hiệu ứng hơi thở là một lớp vẽ trên một căn bản có nền cộng hưởng ngực — không phải thay thế cho nó. Nếu không có mỏi neo cộng hưởng đó, giọng nói nghe giống như ai đó thì thầm với nỗ lực thay vì nói từ bên trong một nhà thờ.
Một giọng nói mềm mại lật ngược ưu tiên. Với David Attenborough, tốc độ mang khoảng 70% của tải. Hít vào chậm trước các tính từ chính. Nâng trên những từ kỳ diệu. Kết thúc cụm từ giảm dần. Sao chép phát âm Anh nhận được mà không có nhịp điệu tạo ra bộ phim tài liệu parody — không phải Attenborough.
Tại Sao Điều Này Quan Trọng Đối Với Sao Chép AI
Sự phân tích cảm giác tương tự xây dựng các giọng nói tốt hơn của con người cũng tạo ra các bản sao giọng nói AI tốt hơn. Mô hình học chữ ký, không phải bề mặt. Vì vậy, một người sáng tạo đã nội tâm hóa vị trí cộng hưởng và tốc độ không chỉ tốt hơn ở việc thể hiện nhân vật — họ đang ghi lại dữ liệu huấn luyện tốt hơn khi họ ngồi để sao chép giọng nói của nhân vật. Kỹ năng chuyển tiếp. Phần sâu hơn của bài viết giải thích cách thức.
Năm Khối Xây Dựng Giọng Nói Mà Mọi Giọng Nói Phụ Thuộc Vào
Phần trước đặt tên các lớp. Phần này biến chúng thành một công cụ chẩn đoán bạn có thể áp dụng cho bất kỳ âm thanh tham chiếu nào trong vòng năm phút.
| Yếu Tố | Nó Là Gì | Cách Xác Định Trong Tài Liệu Tham Khảo | Sai Lầm Phổ Biến Của Người Tập |
|---|---|---|---|
| Cao Độ & Âm Vực | Tần số cơ bản tự nhiên và phạm vi mà người nói chuyển động trong | Huýt sáo cùng; tìm nốt âm thấp nhất được duy trì và nốt "nhà" điển hình | Khóa vào một cao độ thay vì theo dõi đường cong |
| Cộng Hưởng & Âm Sắc | Nơi giọng nói rung động về mặt vật lý — ngực, mặt, mũi, đầu | Đặt tay lên ngực, cổ họng, xương gò má khi phát giọng tham khảo; cảm nhận khu vực nào sẽ rung | Sao chép âm sắc từ cổ họng thay vì thay vì khoang đúng |
| Thở & Tốc Độ | Điểm hít vào, độ dài tạm dừng, từ mỗi phút, nhịp điệu cụm từ | Đánh dấu mọi hơi thở trong clip 30 giây; đếm âm tiết giữa các hơi thở | Nói quá nhanh, làm sụp đổ tốc độ của nhân vật |
| Phát Âm & Sự Rõ Ràng | Sức tấn công phụ âm, độ rộng của nguyên âm, vị trí lưỡi phương ngữ | Làm chậm tài liệu tham khảo xuống 0,5x tốc độ; cách ly sự bắt đầu của phụ âm | Phát âm "tốt chung chung" thay vì các lựa chọn cụ thể của nhân vật |
| Ngữ Cảnh Cảm Xúc | Cảm giác cơ bản tô màu mọi dòng | Hỏi: cái gì mà nhân vật này muốn tại thời điểm này? | Thể hiện từ ngữ thay vì ý định bên dưới chúng |
Thứ tự trên bảng không phải là mỹ phẩm. Cao độ và cộng hưởng là giải phẫu — chúng được đặt bởi nơi bạn đặt giọng nói bên trong cơ thể của mình. Nếu sai những cái đó, không có lượng tốc độ hoặc phát âm nào có thể cứu giọng nói phía sau. Tốc độ và phát âm là hành vi — có thể điều chỉnh thông qua lặp lại. Ngữ cảnh cảm xúc là giải thích — lớp nâng cao một giọng nói được thể hiện chính xác về mặt kỹ thuật thành một cái thuyết phục.
Thử chẩn đoán trên mục tiêu cụ thể. Một người sáng tạo cố gắng thể hiện Galadriel của Cate Blanchett tìm thấy cao độ nhanh chóng: trung bình thấp, hơi thở. Cái bẫy là cộng hưởng. Giọng nói của cô ấy nằm trong mặt — khu vực phía sau xương gò má — không phải ở cổ họng. Hầu hết các nỗ lực của người tập kéo cộng hưởng xuống vào cổ họng, nghe nhỏ hơn và trẻ hơn. Khi cộng hưởng được đặt đúng trong mặt, tốc độ chậm và nguyên âm kéo dài theo tự nhiên, vì khoang chính nó chỉ định nhịp điệu. Sửa lớp giải phẫu và lớp hành vi tự sửa.
Một Lưu Ý Cho Bất Kỳ Ai Có Kế Hoạch Sao Chép Giọng Nói Của Họ
Chẩn đoán ở trên cũng áp dụng ngược lại. Khi bạn ghi âm huấn luyện cho sao chép giọng nói, mô hình nắm bắt chữ ký nào nhất quán nhất trên toàn bộ tập dữ liệu. Theo hướng dẫn sao chép Voiceover Masterclass, những người sáng tạo nên ghi âm với phong cách nhất quán, trung lập trong một phiên liên tục — trừ khi mục tiêu rõ ràng là sao chép giọng nói nhân vật kiểu cách. Bản dịch: nếu bạn muốn một bản sao của giọng nói nhân vật của bạn thay vì giọng nói nói chuyện hàng ngày của bạn, bạn phải ở trong nhân vật cho toàn bộ bản ghi huấn luyện. Lênh đênh vào và ra khỏi nó tạo ra một bản sao bùng nhùng không nghe giống như cái nào.
Đó cũng là lý do tại sao các lớp cảm giác của Phần 1 quan trọng về mặt hoạt động. Một diễn viên lênh đênh tạo ra dữ liệu lênh đênh. Một diễn viên có vị trí cộng hưởng nội tâm hóa tạo ra dữ liệu ổn định. Bản sao chỉ tốt như mức độ nhất quán của chữ ký mà nó học.
Bốn Bài Tập Xây Dựng Trí Nhớ Cơ Bắp Giọng Nói
Biết năm yếu tố giọng nói là chẩn đoán. Bốn bài tập này là điều trị. Mỗi cái nhắm vào một chế độ lỗi cụ thể và mất 15 phút hoặc ít hơn.
Bài Tập 1 — Vòng Cách Ly
Nhắm Vào: độ chính xác cao độ và cộng hưởng.
- Chọn một cụm từ 5 từ từ tài liệu tham khảo của bạn (ví dụ, "I have been expecting you")
- Lặp lại tài liệu tham khảo 10 lần để nhúng âm thanh mục tiêu vào tai của bạn
- Ghi lại phiên bản của bạn tập trung vào cao độ duy nhất — bỏ qua cộng hưởng, bỏ qua nhân vật, chỉ khớp đường cong giai điệu
- Ghi lại tập trung vào cộng hưởng duy nhất — cụm từ tương tự, nhắm vào khoang đúng
- Ghi lại tập trung vào tốc độ và thở — cụm từ tương tự, khớp thời gian chính xác
- Thời gian: 15 phút hàng ngày
Tại Sao Nó Hoạt Động: các nguyên tắc học động cơ trong sư phạm giọng nói hỗ trợ thực hành bị chặn (một biến tại một thời điểm) so với thực hành biến đổi khi học các điều phối mới, một vị trí phù hợp với khuôn khổ của Titze trong Principles of Voice Production. Cách ly một biến huấn luyện nhóm cơ chịu trách nhiệm cho nó mà không có tải nhận thức của sự liên tiếp tất cả năm cái.
Bài Tập 2 — Kiểm Tra Tài Liệu Tham Khảo Mù
Nhắm Vào: huấn luyện tai, tự lừa dối.
- Ghi âm ba lần quay của một đoạn 15 giây trong nhân vật
- Chờ ít nhất 4 giờ — tai mới
- Phát tài liệu tham khảo, sau đó lần quay tốt nhất của bạn, xen kẽ mà không nhìn vào dạng sóng
- Xếp hạng trung thực: cái nào nghe giống như họ hơn?
Hầu hết những người sáng tạo khám phá "lần quay tốt nhất" của họ không phải là lần gần nhất. Họ đang khen thưởng lần quay nơi họ cảm thấy nỗ lực nhất thay vì lần quay hạ cánh chính xác nhất. Bài kiểm tra mù phá vỡ sự thiên vị đó. Chạy nó hàng tuần.
Bài Tập 3 — Mỏi Cảm Xúc
Nhắm Vào: ngữ cảnh cảm xúc, xác thực hiệu suất.
Trước khi ghi âm, hãy đặt tên trạng thái cảm xúc của nhân vật trong cảnh. Gandalf la hét "You shall not pass!" không phải giận dữ — đó là quyết tâm bảo vệ dưới sự kiệt sức. Hai trạng thái nghe hoàn toàn khác nhau ngay cả khi các từ giống hệt nhau. Cụ thể hóa nó về mặt thể chất: tư thế, độ sâu thở, nơi bạn giữ căng thẳng trong cơ thể của bạn. Điểm lặp đi lặp lại của Dee Bradley Baker trong I Want to Be a Voice Actor! là giọng nói nhân vật mà không có ý định nhân vật nghe cơ học. Ghi âm chỉ sau khi mỏi được đặt. Mỗi phiên họp.
Bài Tập 4 — Kiểm Tra Áp Lực Đa Ngôn Ngữ
Nhắm Vào: nội tâm hóa chữ ký so với ghi nhớ âm tiết.
Lấy giọng nói của bạn và thể hiện nó trên một kịch bản hoàn toàn khác — danh sách mua sắm, báo cáo thời tiết, lời bài hát yêu thích của bạn — bằng cùng một giọng nói. Nếu giọng nói sụp đổ ngay khi các từ thay đổi, bạn đã ghi nhớ một chuỗi âm tiết thay vì nội tâm hóa chữ ký giọng nói.
Bài tập này là người gác cửa cho công việc địa phương hóa. Nếu giọng nói của bạn không thể chịu được ứng dụng vào danh sách mua sắm bằng tiếng Anh, nó sẽ không chịu được lồng tiếng thành tiếng Bồ Đào Nha. Nhịp điệu hàng tuần.
Nếu giọng nói của bạn không thể sống sót được áp dụng vào danh sách mua sắm, nó sẽ không sống sót được lồng tiếng thành ngôn ngữ thứ hai.
Lịch Trình Huấn Luyện Giọng Nói Hàng Tuần Của Bạn
- Vòng cách ly 15 phút hàng ngày trên một yếu tố giọng nói (xoay vòng: cao độ → cộng hưởng → tốc độ → phát âm)
- Thiết lập một mỏi cảm xúc trước mỗi phiên ghi âm
- Một kiểm tra tài liệu tham khảo mù mỗi tuần với 4+ giờ tách biệt giữa các lần quay và xem xét
- Một kiểm tra áp lực đa ngôn ngữ mỗi tuần bằng tài liệu không phải kịch bản
- Ghi âm một "lần quay chữ ký" 30 giây mỗi thứ Sáu — cùng một đoạn, cùng một nhân vật — để theo dõi tiến trình từ tuần này sang tuần khác
- Duy trì sàn tiếng ồn −60 dB hoặc thấp hơn trong không gian ghi âm của bạn (tấm âm học, không HVAC, không quạt), theo tiêu chuẩn Voiceover Masterclass — điều này quan trọng cho cả huấn luyện tai người và bất kỳ sử dụng sao chép trong tương lai
Nơi Thực Hành Giọng Nói Thủ Công Chạm Trần Cứng
Các bài tập ở trên xây dựng kỹ năng thực sự mà không có công cụ nào có thể giả mạo. Họ cũng có trần. Một diễn viên tài năng duy nhất có thông lượng hữu hạn — nút cổ chai không phải là tài năng, đó là sinh học và đồng hồ. Bốn kịch bản cho thấy nơi nút cổ chai đó trở thành ràng buộc kinh doanh.
Vấn đề video 30 phút. Một người sáng tạo giữ giọng nói nhân vật trên 30 phút đối thoại bị mệt mỏi về giọng. Lần quay 40 không khớp lần quay 4. Cao độ tăng cao, hơi thở rút ngắn, cộng hưởng ngực chuyển sang cổ họng. Các bản sửa phòng biên tập tốn hàng giờ.
Vấn đề địa phương hóa 6 ngôn ngữ. Ngay cả một người sáng tạo thành thạo tiếng Tây Ban Nha cũng không nhất thiết có thể thể hiện giọng nói nhân vật tiếng Anh của họ một cách thuyết phục bằng tiếng Tây Ban Nha. Nhân nó với sáu ngôn ngữ mục tiêu và kế hoạch địa phương hóa trở thành một năm công việc giọng nói — giả sử kỹ năng biểu diễn đa ngôn ngữ tồn tại.
Vấn đề sửa đổi khách hàng. Một thay đổi dòng ở tuần 8 có nghĩa là ghi lại trong cùng trạng thái giọng nói — cùng phòng, cùng thời gian trong ngày, cùng độ ẩm cổ họng. Hầu như không thể khớp hoàn hảo.
Vấn đề đa nhân vật. Một người sáng tạo phát âm bốn nhân vật trong một cảnh đối thoại duy nhất cần ít nhất bốn lần quay ghi âm riêng biệt, và những chuyển đổi giọng nói làm kiệt sức thanh quản nhanh chóng.
So Sánh Các Phương Pháp Sản Xuất Giọng Nói Được Thể Hiện
| Yếu Tố | Giọng Nói Được Ghi Âm Tự Thân | Thuê một Diễn Viên Giọng Nói | Sao Chép Giọng Nói AI |
|---|---|---|---|
| Thời gian đến lần quay có thể sử dụng đầu tiên | Tuần đến tháng của thực hành phân tán | 1–3 ngày (đúc + ghi âm) | Vài giây cho bản sao người mới bắt đầu từ mẫu 10 giây; 30–120 phút ghi âm cho prosumer-grade |
| Mẫu ghi âm cần thiết | N/A — biểu diễn trực tiếp | N/A — biểu diễn trực tiếp | 30–120 giây (lọ đóng); 10–15 phút (RVC); 30 phút–2 giờ (chuyên nghiệp) |
| Tính nhất quán lần quay | Biến đổi — trôi dạt với mệt mỏi | Cao trong một phiên; biến đổi trên các phiên | Hoàn toàn lặp lại cho văn bản và tham số nhất định |
| Mở rộng quy mô đa ngôn ngữ | Yêu cầu thành thạo + kỹ năng thể hiện ở mỗi | Diễn viên đa ngôn ngữ hoặc nhiều diễn viên | Lồng Tiếng AI đa ngôn ngữ bảo tồn tông màu trên các mục tiêu |
| Phù hợp nhất | Biểu diễn trực tiếp, dạng ngắn, huấn luyện tai | Sản xuất premium một lần | Dạng dài, đa ngôn ngữ, nội dung lặp lại |
Nguồn cho các con số trên: hướng dẫn ElevenLabs, DeepReel, CloudPano, Kukarella, và hướng dẫn RVC.
Đây không phải là phán quyết rằng AI thắng. Thực hành thủ công tạo ra kỹ năng chuyển tiếp đến biểu diễn trực tiếp, podcast, sân khấu, và huấn luyện tai làm cho mọi phương pháp khác tốt hơn. Bảng cách ly các kịch bản sản xuất cụ thể nơi sinh học trở thành một ràng buộc.
Bằng chứng ngược cũng quan trọng. Các diễn viên giọng nói và SAG-AFTRA đã công khai lưu ý rằng các bản sao AI hiện tại vẫn gặp khó khăn với sắc thái cảm xúc phức tạp, ngữ cảnh phụ, và công việc cảnh động — đặc biệt là trong kịch và hài kịch nơi thời gian vi mô mang theo ý nghĩa. Đối với một người sáng tạo sản xuất video giải thích sáu ngôn ngữ, hạn chế đó có thể chấp nhận được. Đối với một người sáng tạo sản xuất hoạt hình tường thuật với ba lần chuyển cảm xúc mỗi cảnh, nó chưa ở đó. Tổng hợp trung thực: câu hỏi không phải "thủ công hoặc AI." Đó là "nơi mỗi phương pháp thuộc về quy trình làm việc?"
Nút cổ chai trong công việc giọng nói được thể hiện không phải là tài năng — đó là sinh học và đồng hồ.
Cách Sao Chép Giọng Nói AI Mở Rộng Phạm Vi Của Một Diễn Viên Giọng Nói Tài Năng
Những Gì Sao Chép Thực Sự Nắm Bắt
Một bản sao giọng nói không phải là một bản ghi âm. Đó là một mô hình đã học của chữ ký giọng nói. Mô hình nắm bắt hồ sơ cộng hưởng, mẫu đường cong cao độ, nhịp điệu thở, và xu hướng phát âm từ âm thanh huấn luyện, sau đó áp dụng chúng cho văn bản mới. Nhà khoa học nói chuyện Rupal Patel, người sáng lập VocaliD, đã lập luận trong bài nói TED và các cuộc phỏng vấn liên quan rằng giọng nói tổng hợp xác thực phải nắm bắt prosody thích nghi, không chỉ cao độ trung bình, để đọc là thực thay vì chung chung.
Đó chính xác là lý do tại sao một giọng nói được thể hiện được thực hiện tốt là một ứng cử viên bản sao tốt hơn so với một lần quay trung lập. Chữ ký mô hình học là chữ ký nhân vật. Một người sáng tạo đã làm các bài tập Phần 3 bước vào phiên sao chép giọng nói với dữ liệu sạch hơn, nhất quán hơn so với ai đó chưa — và bản sao kết quả phản ánh sự khác biệt đó trực tiếp.
Thực Tế Tập Dữ Liệu
Có ba tầng chất lượng, mỗi cái có yêu cầu mẫu cụ thể.
- Bản sao người mới bắt đầu / tức thì: ~10 giây lời nói rõ ràng mang lại một bản sao thử nghiệm cơ bản bạn có thể thử nghiệm trong vài giây, theo hướng dẫn ElevenLabs.
- Bản sao người kể chuyện cấp độ người sáng tạo: 30–120 giây âm thanh sạch tạo ra một bản sao kiểu người kể chuyện ổn định, theo DeepReel và CloudPano.
- Bản sao cấp độ chuyên nghiệp: 30 phút đến 2 giờ bản ghi, với kết quả rõ ràng tốt hơn gần mốc 2 giờ; thời gian xử lý trên cơ sở hạ tầng nhà cung cấp chạy khoảng 2–6 giờ, theo hướng dẫn ElevenLabs.
- Ngăn xếp RVC mã nguồn mở: 10–15 phút âm thanh sạch là điểm ngọt người thực hành; 2–10 phút là có thể với sự đánh đổi chất lượng; 40 kHz tần số lấy mẫu là mặc định người thực hành, theo hướng dẫn RVC.
Sàn kỹ thuật là không thể thương lượng: một sàn tiếng ồn ≤ −60 dB, và không nén, EQ, de-essing, hoặc giảm tiếng ồn áp dụng cho các tệp đào tạo thô, theo tiêu chuẩn Voiceover Masterclass. Rác vào, rác ra áp dụng hai lần — mô hình khuếch đại bất kỳ hiện tượng nào tồn tại trong nguồn.

Hai Nghiên Cứu Trường Hợp Quy Trình Làm Việc
Trường Hợp A — YouTuber 30 Phút. Một người sáng tạo làm chủ một giọng nói nhân vật ấn tượng trong 30 giây nhưng mất tính nhất quán trên một tập phim dạng dài. Quy trình làm việc: ghi âm một lần quay 90 giây hoàn hảo của giọng nói nhân vật. Sao chép nó. Tạo đối thoại nền bằng bản sao sử dụng Văn Bản Thành Lời Nói, trong khi dành năng lượng biểu diễn trực tiếp cho năm hoặc sáu beat cảm xúc chính mang theo tập phim. Kết quả: giọng nói nhất quán trong 30 phút, đỉnh hiệu suất nơi chúng quan trọng, phiên ghi âm nén từ khoảng 8 giờ xuống khoảng 90 phút.
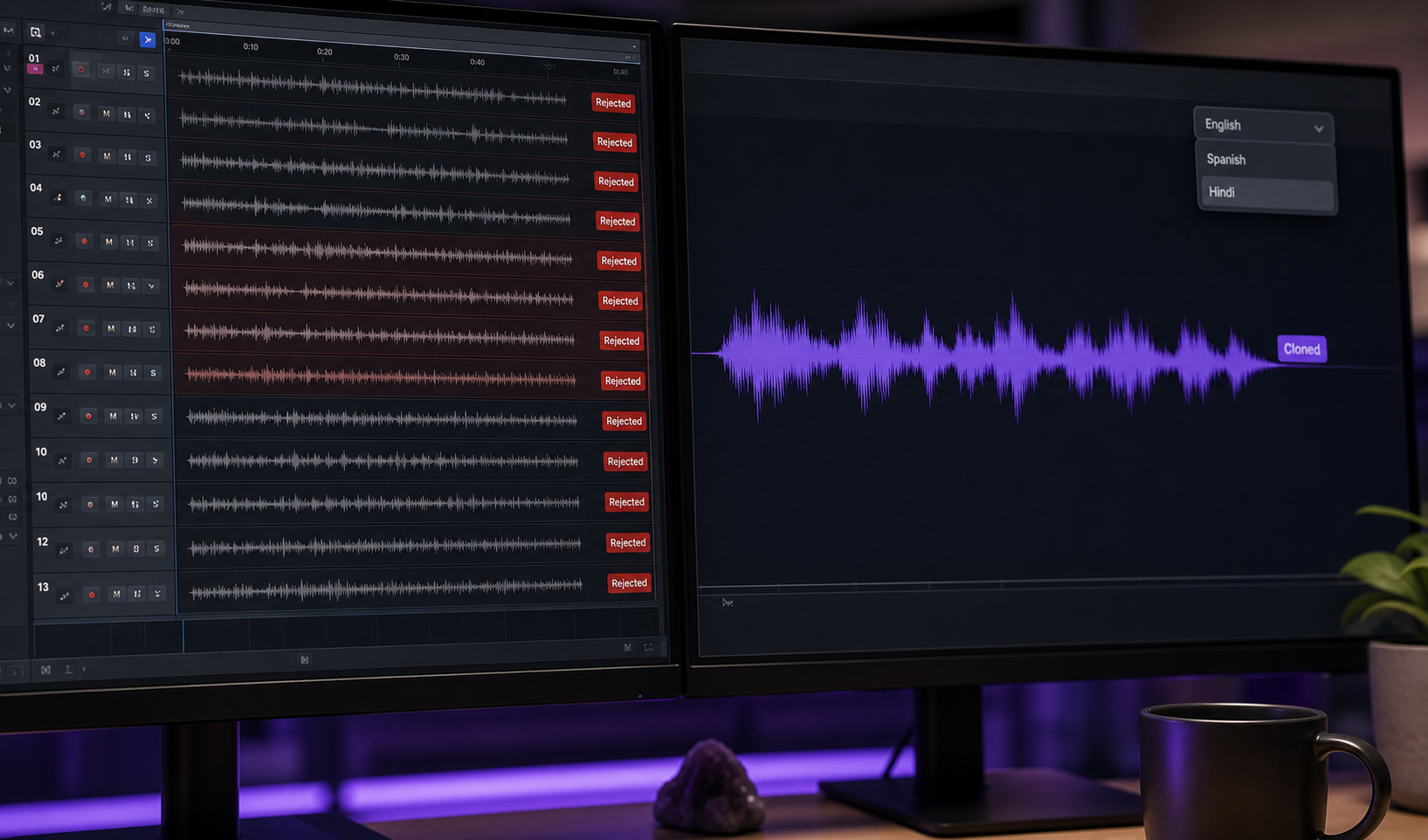
Trường Hợp B — Video Huấn Luyện 6 Ngôn Ngữ. Một doanh nghiệp nhỏ sản xuất một mô-đun huấn luyện nội bộ 15 phút được kể bằng một giọng nói nhân vật ấm áp, có thẩm quyền. Quy trình làm việc: ghi âm phiên bản tiếng Anh một lần với ấn tượng trực tiếp. Sao chép giọng nói. Sử dụng sao chép đa ngôn ngữ thông qua một API Sao Chép Giọng Nói để kết xuất các phiên bản tiếng Tây Ban Nha, Bồ Đào Nha, Pháp, Đức, Ấn Độ, và Nhật Bản trong khi bảo tồn tông màu nhân vật trên các ngôn ngữ, theo DeepReel và Kukarella. Nhân vật tương tự "nói" tất cả sáu ngôn ngữ vì chữ ký chuyển tiếp, ngay cả khi ngôn ngữ không.
Sao chép giọng nói không thay thế kỹ năng điều chỉnh một ấn tượng — nó khuếch đại nó. Phần khó là vẫn làm cho nhân vật đúng; công nghệ chỉ loại bỏ sự lặp lại.
Đạo Đức và Biên Giới Hợp Pháp
Giọng nói tổng hợp có thể bị vũ khí. Giáo sư pháp luật Danielle Citron, trong The Fight for Privacy và học bổng deepfake liên quan, đã ghi lại cách sao chép giọng nói không được đồng ý cho phép giả mạo, gian lận, và thông tin sai lệch chính trị — và đã lập luận cho cả lợi ích pháp lý và bảo vệ cấp độ thiết kế trên các công cụ thương mại.
Ranh giới đạo đức cho người sáng tạo rõ ràng. Sao chép riêng của bạn giọng nói cho nội dung riêng của bạn là rõ ràng tốt. Sao chép một giọng nói nhân vật hư cấu bạn đã phát triển cho chính bạn là tốt. Sao chép một nhân vật công cộng thực tế, hoặc bất cứ ai, mà không có sự đồng ý rõ ràng không. Tiết lộ trong tín dụng khi lồng tiếng AI được sử dụng đang trở thành thực tiễn tiêu chuẩn và là mặc định an toàn hơn cho bất kỳ công việc thương mại nào.
Xây Dựng Bộ Công Cụ Giọng Nói của Bạn — Kết Hợp Nút Cổ Chai của Bạn với Đường Đi Đúng
Lựa chọn không phải là thực hành thủ công hoặc sao chép AI. Đó là xác định nút cổ chai nào thực sự chặn công việc của bạn ngay bây giờ, và áp dụng đường đi khớp. Ma trận dưới đây ánh xạ bốn tình huống người sáng tạo phổ biến đến các hành động cụ thể đầu tiên.
Đường Đi Ấn Tượng Giọng Nói Nào Phù Hợp với Nút Cổ Chai Của Bạn?
| Tình Huống Của Bạn | Nút Cổ Chai Chính | Ưu Tiên Công Cụ | Hành Động Đầu Tiên Tuần Này |
|---|---|---|---|
| Ấn tượng chưa thuyết phục — xây dựng kỹ năng cho YouTube hoặc Twitch | Khoảng cách kỹ năng | Bài tập từ Phần 3 + phản hồi ngang hàng | Chọn một nhân vật; chạy vòng cách ly hàng ngày trong 14 ngày trước khi đánh giá |
| Ấn tượng mạnh, nhưng kiệt sức ghi lại lại các video dài | Mệt mỏi giọng nói, trôi dạt tính nhất quán | Sao chép giọng nói trên ấn tượng biểu diễn của riêng bạn | Ghi âm một lần quay 90 giây sạch trong nhân vật tại −60 dB; sao chép nó; kiểm tra trên một đoạn 2 phút được tạo |
| Địa phương hóa nội dung tiếng Anh hiện có thành nhiều ngôn ngữ | Khoảng cách biểu diễn đa ngôn ngữ | Sao chép đa ngôn ngữ + lồng tiếng AI | Sao chép ấn tượng tham chiếu của bạn một lần; lồng tiếng mẫu 2 phút thành ngôn ngữ ưu tiên hàng đầu của bạn; xem xét bảo tồn nhân vật |
| Đội sản xuất nội dung đa ngôn ngữ được xây dựng thương hiệu ở khối lượng | Khả năng mở rộng đường ống | Sao chép + tích hợp API | Nguyên mẫu quy trình làm việc API Lồng Tiếng AI trên một dự án sản xuất |
Ba nguyên tắc làm việc để sử dụng ma trận này một cách trung thực.
Ma trận không phải là vĩnh viễn. Một người sáng tạo hôm nay ở hàng một chuyển sang hàng ba trong mười tám tháng. Nút cổ chai thay đổi khi công việc thay đổi. Đánh giá lại hàng quý.
Sao chép khuếch đại; nó không bắt nguồn. Phát hiện lặp lại trên các hướng dẫn sao chép — Voiceover Masterclass, hướng dẫn ElevenLabs, hướng dẫn RVC — là chất lượng âm thanh và chất lượng hiệu suất trong nguồn xác định chất lượng bản sao. Một người sáng tạo bỏ qua bài tập Phần 3 của và cố gắng sao chép một ấn tượng lởm chởm nhận được bản sao của một ấn tượng lởm chởm. Công nghệ trung thực đối với đầu vào của nó.
Sàn 30 giây quan trọng về mặt hoạt động. Một số nền tảng lọ đóng có thể tạo ra một hồ sơ giọng nói làm việc từ khoảng 20–30 giây âm thanh sạch. Điều đó có nghĩa là một người sáng tạo đã có một lần quay tốt của giọng nói nhân vật của họ là một tải lên từ một tài sản sản xuất có thể tái sử dụng. Rào cản không phải là công nghệ — đó là có lần quay tốt đó.
Giải quyết áp lực ngược quá. Một số huấn luyện viên giọng nói cảnh báo rằng dựa vào sao chép nặng nề sớm có thể hạn chế phát triển kỹ năng nền tảng: hỗ trợ thở, kiểm soát cộng hưởng, phát âm. Con đường giữa thực dụng là tiếp tục làm các bài tập ngay cả khi bạn sử dụng bản sao để sản xuất, vì các bài tập làm cho mọi bản sao tương lai tốt hơn.
Kế Hoạch Hành Động Hai Tuần Của Bạn
- Xác định hàng nào của ma trận mô tả nút cổ chai hiện tại của bạn — hãy trung thực; hầu hết những người sáng tạo ngồi trong hai hàng cùng một lúc. Chọn cái đau hơn.
- Nếu hàng của bạn là "khoảng cách kỹ năng": cam kết vòng cách ly hàng ngày 15 phút và một kiểm tra tài liệu tham khảo mù hàng tuần cho toàn bộ 14 ngày trước khi đánh giá lại.
- Nếu hàng của bạn liên quan đến sao chép: ghi âm một lần quay tài liệu tham khảo sạch 30–90 giây với sàn tiếng ồn tại hoặc dưới −60 dB, trong nhân vật, trong một phiên liên tục duy nhất, không có EQ hoặc nén áp dụng.
- Chạy bài kiểm tra bản sao rủi ro thấp trước bất kỳ công việc khách hàng hoặc doanh thu — sử dụng nó trên video nội bộ, bài kiểm tra kênh cá nhân, hoặc dự thảo kịch bản.
- Nếu địa phương hóa: chọn ngôn ngữ ưu tiên cao nhất của bạn và lồng tiếng mẫu 2 phút. Xem xét cụ thể bảo tồn nhân vật, không chỉ độ chính xác dịch.
- Nếu tích hợp vào quy trình sản xuất: nguyên mẫu quy trình làm việc API trên một dự án trước khi tiêu chuẩn hóa. Kiểm tra API Văn Bản Thành Lời Nói và API Sao Chép Giọng Nói trên một loại nội dung đại diện.
- Đặt một điểm kiểm tra 14 ngày để đánh giá lại nút cổ chai của bạn — nó có thể đã chuyển.
Những người sáng tạo thắng tại nội dung đa ngôn ngữ vào năm 2025 không phải là những người chọn công cụ đúng. Họ là những người xây dựng một ấn tượng thực sự đầu tiên, sau đó để các công cụ làm những gì công cụ làm tốt nhất — lặp lại nó, mở rộng quy mô nó, và bảo tồn nó trên các ngôn ngữ họ không nói.
Câu Hỏi Thường Gặp
Tôi có thể sử dụng sao chép giọng nói AI để thực hiện ấn tượng của các nhân vật công cộng thực tế không?
Về mặt p