
สิ่งที่ผู้ฟังจะได้ยินเมื่อการเลียนแบบเสียงสำเร็จ
เทค 17 การเลียนแบบมอร์แกน ฟรีแมน ใกล้เคียงมาก — จังหวะมีอยู่ สำเนียงมิสซิสซิปปี้เกือบจะเชื่อได้ — แต่ความสำคัญหายไป ผู้ฟังของคุณพูดว่า "เกือบ" ซึ่งในงานเสียงนั้นเป็นคำเดียวกับ "ไม่" คุณลบเทคนั้น คุณลองอีกครั้ง สี่สิบนาทีต่อมาคุณไม่มีอะไรที่ใช้ได้สำหรับ YouTube voiceover และลำคอของคุณเริ่มเหนื่อย
นี่คือกับดักที่ดูดซึ่งผู้สร้างสื่อพยายามสร้างช่องสื่อหลายภาษา: การยึดคำแสดงตัวละครในภาษาอังกฤษ จากนั้นดูมันพังเมื่อการ dub ภาษาสเปนหรือฮินดี้เข้ามาในแผนการจำหน่าย — เพราะการเลียนแบบเป็นการจำลำดับเสียงตามอักษร ไม่ใช่ลายเซ็นเสียงที่ได้รับการอุปนิสัย ชั่วโมงในสตูดิโอจะสะสม เทคจะถูกปฏิเสธ แผนการ localization จะเงียบ ๆ ถูกวาง เนื้อหาที่ควรจะส่งจะไม่ถูกส่ง
คู่มือนี้อธิบายว่าคืออะไร การเลียนแบบเสียง ที่ลงจอดจริง ๆ บนหูของผู้ฟัง การสาธารณูปโภคสี่รายการที่สร้างกลศาสตร์พื้นฐาน และสถานที่ที่เทคโนโลยี AI voice cloning เข้าสู่เวิร์กโฟลว์เป็นเครื่องมือการปรับขนาด — ไม่ใช่การแทนที่ทักษะที่อยู่ข้างใต้

สารบัญ
- สิ่งที่ผู้ฟังจะได้ยินเมื่อการเลียนแบบเสียงสำเร็จ
- บล็อกการสร้างเสียงห้าบล็อกที่การเลียนแบบทั้งหมดอยู่บน
- แบบฝึกสี่รายการที่สร้าง Voice Impression Muscle Memory
- ที่ไหนการฝึกเลียนแบบเสียงด้วยตนเองชนกับเพดานที่ยาก
- วิธีที่ AI Voice Cloning เพิ่มช่วงของ Impressionist ที่มีทักษะ
- สร้างชุดเครื่องมือ Voice Impression ของคุณ — จับคู่ขวดของคุณกับเส้นทางที่ถูกต้อง
- FAQ
ผู้ฟังไม่ระบุเสียงเพียงแค่ระดับเสียงเท่านั้น พวกเขาระบุพวกเขาด้วย ลายนิ้วมือสเปกตรัม — โครงสร้าง formant ลวนลามการสั่นและลายเซ็นการจับเวลาที่กายวิภาคระบบเสียงเฉพาะผลิต ตามที่นักวิทยาศาสตร์เสียง Ingo R. Titze ใน Principles of Voice Production คุณภาพเสียงนั้นประกอบด้วย การกำหนดค่าและสิ่งหนึ่งของระบบเสียง ไม่ใช่ความถี่พื้นฐาน คนสองคนสามารถคำนำเสียงโน้ตเดียวกันได้ทุกประการ และยังคงไม่เสียงคล้ายเลย เพราะลำคอ ปาก และกระโหลก กระทำเป็นตัวกรองที่แตกต่างกันสำหรับการสั่นเดียวกัน
นั่นคือการปลดล็อคสำหรับ การเลียนแบบเสียง งานไม่ใช่การจับคู่ตัวแปรเดียว มันคือการสร้างลายเซ็นห้าชั้น:
- 轮廓ระดับเสียง — ไม่ใช่แค่ระดับเสียงเฉลี่ย แต่ว่าที่ใดมันเพิ่มขึ้นและลดลงภายในประโยค
- การวางสิ่งหนึ่ง — หน้าอก หน้ากาก จมูก หัว
- ลวนลามของลมหายใจและจังหวะ — ที่ผู้พูดสูดลมหายใจและนานแค่ไหนการหยุดพักของพวกเขา
- ลายเซ็นหนังสือธรรมชาติ — การโจมตีพยัญชนะและรูปร่างสระ
- บริบทอารมณ์ — ความรู้สึกที่นำทางทุกคำ ชั้นที่มือโปรข้าม
ตารางการวินิจฉัยแบบเต็มมาในส่วนถัดไป สำหรับตอนนี้ให้ถือกรอบ: ลายเซ็น ไม่ใช่พื้นผิว
ฟังดูเหมือนกับ Versus Performing As
มีความแตกต่างที่โลกการแสดงเสียงการทำงานถือว่าไม่สามารถเจรจาได้: ฟังดูเหมือนใครสักคนและการแสดงเป็นพวกเขาเป็นทักษะที่แตกต่าง Dee Bradley Baker — นักแสดงเสียงตัวละครอยู่เบื้องหลังมากมายของ Star Wars: The Clone Wars และ Avatar: The Last Airbender — ได้สร้างการฝึกการสอนของเขาทั้งหมดรอบ ๆ อาร์กิวเมนต์ว่าเสียงตัวละครจะทำงานได้เฉพาะเมื่อผู้แสดงเข้าใจ ชีวิตอารมณ์ เจตนา และร่างกายของตัวละคร ไม่ใช่แค่สำเนียง ไม่ใช่แค่โทน ตามวัสดุการศึกษาของเขาใน I Want to Be a Voice Actor! การเลียนแบบที่เล็งทำให้เสียงโดยไม่มีเจตนาสร้าง บางสิ่งที่ผู้ฟังลงทะเบียนเป็นกลไกแม้ว่าพวกเขาจะไม่สามารถสื่อความหมายได้
การสลายตัวสองแบบที่ทำให้ทฤษฎีเป็นรูปธรรม
พิจารณาการเลียนแบบ Darth Vader ของสมัครเล่น พวกเขาฟังเบาบางเพราะพวกเขาเล็งผิดตัวแปรสองตัว: ระดับเสียง (ต่ำ) และเอฟเฟกต์ลมหายใจ (หายใจออกหนัก) สิ่งที่พวกเขาพลาดคือ สิ่งหนึ่งของหน้าอก ที่ James Earl Jones' เสียงจริง ๆ อาศัยอยู่ เอฟเฟกต์ลมหายใจเป็นชั้นที่ทาสีบนสิ่งหนึ่งที่ลึกลงไปในหน้าอก — ไม่ใช่การแทนที่ เมื่อไม่มีสมอสิ่งหนึ่งนั้น การเลียนแบบเสียงคล้ายกับคนกระซิบพยายามแทนที่การพูดจากภายในวิหาร
เสียงที่부드러운 พลิกลำดับความสำคัญ ด้วย David Attenborough จังหวะการถือประมาณ 70% ของโหลด การสูดลมหายใจช้า ๆ ก่อน adjectives หลัก ลิฟท์บน wonder-words การจบวลีลงเล็บ การคัดลอก received-pronunciation สำเนียงโดยไม่มีจังหวะสร้าง parody สารคดี — ไม่ใช่ Attenborough
ทำไมสิ่งนี้จึงสำคัญสำหรับการ AI Cloning
การสลายตัวการรับรู้เดียวกันที่สร้างการเลียนแบบของมนุษย์ที่ดีขึ้นยังสร้างโคลนเสียง AI ที่ดีขึ้น รูปแบบจะเรียนรู้ ลายเซ็น ไม่ใช่พื้นผิว ดังนั้นผู้สร้างสื่อที่ได้รับการภายในการวางสิ่งหนึ่งและจังหวะไม่เพียงแต่ดีกว่าในการแสดงตัวละคร — พวกเขากำลังบันทึกข้อมูลการฝึกที่ดีขึ้นเมื่อพวกเขานั่งลงเพื่อโคลนตัวละครเสียงนั้น ทักษะการถ่ายโอน ส่วนที่ลึกกว่าของบทความครอบคลุมวิธีการ
บล็อกการสร้างเสียงห้าบล็อกที่การเลียนแบบทั้งหมดอยู่บน
ส่วนก่อนหน้านี้ตั้งชื่อชั้น ส่วนนี้เปลี่ยนพวกเขาเป็นเครื่องมือการวินิจฉัยที่คุณสามารถนำไปใช้กับเสียงอ้างอิงใด ๆ ในห้านาทีหรือน้อยกว่า
| องค์ประกอบ | มันคืออะไร | วิธีระบุในข้อมูลอ้างอิง | ข้อผิดพลาดของมือโปร |
|---|---|---|---|
| ระดับเสียงและลงทะเบียน | ความถี่พื้นฐานตามธรรมชาติและช่วงที่ผู้พูดเคลื่อนไหวภายใน | ฝึกร้องตามคำคล้อง ค้นหาบันทึกที่มีการรักษาต่ำสุดและ "บ้าน" โน้ตปกติ | ล็อคเข้ากับระดับเสียงเดียวแทนการตามรอยโครงร่าง |
| สิ่งหนึ่งและโทน | ที่เสียงสั่นทางกายภาพ — หน้าอก หน้ากาก จมูก หัว | วางมือบนหน้าอก ลำคอ กระดูกแก้มขณะเล่นข้อมูลอ้างอิง รู้สึกว่าพื้นที่ใดจะบ้วน | คัดลอก timbre จากลำคอแทนโพรงที่ถูกต้อง |
| ลมหายใจและจังหวะ | จุดสูดลมหายใจ ความยาวพัก คำต่อนาที อัตราจังหวะวลี | ทำเครื่องหมายลมหายใจทุกครั้งในคลิป 30 วินาที นับพยางค์ระหว่างลมหายใจ | พูดเร็วเกินไป ยุบจังหวะของตัวละคร |
| หนังสือธรรมชาติและความชัดเจน | ความแข็งแรงของการโจมตีพยัญชนะ การเปิดสระ การวางลิ้นสำเนียง | ชะลอข้อมูลอ้างอิงเป็น 0.5x ความเร็ว แยกจุดเริ่มต้นของพยัญชนะ | ดิก "ดี" ทั่วไปแทนการเลือกเฉพาะของตัวละคร |
| บริบทอารมณ์ | ความรู้สึกพื้นฐานระบายสีทุกบรรทัด | ถาม: ตัวละครนี้ต้องการอะไรในช่วงเวลานี้? | แสดงคำแทนเจตนาที่อยู่ข้างใต้พวกเขา |
ลำดับในตารางไม่ใช่เกี่ยวกับความเสียงสวย ระดับเสียงและสิ่งหนึ่งเป็น กายวิภาค — พวกเขาตั้งค่าตามที่คุณวางเสียงภายในร่างกายของคุณ ได้ผิดพลาดและจำนวนจังหวะหรือหนังสือธรรมชาติไม่สามารถช่วยเหลือการเลียนแบบจำหน่ายได้ จังหวะและหนังสือธรรมชาติเป็น พฤติกรรม — ปรับเปลี่ยนผ่านการทำซ้ำ บริบทอารมณ์คือ ตีความ — ชั้นที่ยกระดับการเลียนแบบที่แม่นยำด้านเทคนิคให้เป็นอันที่น่าเชื่อ
ลองการวินิจฉัยบนเป้าหมายที่เป็นรูปธรรม ผู้สร้างสื่อพยายาม Cate Blanchett's Galadriel พบระดับเสียงอย่างรวดเร็ว: ต่ำกลาง ลมหายใจ กับดักคือสิ่งหนึ่ง เสียงของเธอนั่งอยู่ใน หน้ากาก — พื้นที่อยู่เบื้องหลังกระดูกแก้ม — ไม่ใช่ในลำคอ ความพยายามของมือโปรส่วนใหญ่ดึงสิ่งหนึ่งลงเข้าไปในลำคอ ซึ่งเสียงเล็กและอ่อนกว่า เมื่อสิ่งหนึ่งอยู่ในตำแหน่งที่ถูกต้องในหน้ากาก จังหวะช้า ๆ และการขยายสระตามธรรมชาติ เพราะโพรงตัวเองกำหนดจังหวะ แก้ไขชั้นกายวิภาคและชั้นพฤติกรรมแก้ไขตัวเอง
หมายเหตุสำหรับใครก็ตามที่วางแผนการโคลนการเลียนแบบของพวกเขา
การวินิจฉัยข้างต้นยังใช้กลับกันได้ เมื่อคุณบันทึกเสียงการฝึกสำหรับ voice clone รูปแบบจะจับสิ่งใดก็ตามที่เป็นสัญญาณอ้างอิงส่วนใหญ่ในชุดข้อมูล ตามที่ Voiceover Masterclass cloning guide ผู้สร้างสื่อควรบันทึกในแบบ สไตล์คงที่ ที่เป็นกลาง ตลอดหนึ่งเซสชั่นต่อเนื่อง — เว้นแต่เป้าหมายที่ชัดเจนคือการโคลนเสียงตัวละครที่มีสไตล์ การแปล: หากคุณต้องการโคลนของ การเลียนแบบตัวละครของคุณ แทนเสียงพูดในชีวิตประจำวันของคุณ คุณต้องอยู่ในตัวละครสำหรับการบันทึกการฝึกทั้งหมด การเลื่อนเข้าและออกจากมันสร้างโคลน mushy ที่ฟังเหมือนไม่ใช่ทั้งสองอย่าง
นี่คือเหตุผลที่ชั้นการรับรู้ของส่วน 1 สำคัญในการปฏิบัติการ ผู้แสดงการเลื่อนสร้างข้อมูลการเลื่อน ผู้แสดงที่มีการวางสิ่งหนึ่งภายในสร้างข้อมูลที่เสถียร โคลนนั้นดีเท่ากับความสม่ำเสมอของลายเซ็นที่มันเรียนรู้
แบบฝึกสี่รายการที่สร้าง Voice Impression Muscle Memory
การรู้องค์ประกอบเสียงห้าอย่างคือการวินิจฉัย แบบฝึกสี่รายการนี้คือการบำบัด แต่ละแบบเล็งที่โหมดความล้มเหลวที่เฉพาะเจาะจงและใช้เวลา 15 นาทีหรือน้อยกว่า
Drill 1 — The Isolation Loop
Targets: ความแม่นยำของระดับเสียงและสิ่งหนึ่ง
- เลือกวลี 5 คำจากข้อมูลอ้างอิงของคุณ (เช่น "ฉันรอคอยคุณ")
- วนลูปข้อมูลอ้างอิง 10 ครั้งเพื่อให้เสียงเป้าหมายติดอยู่ในหูของคุณ
- บันทึกเวอร์ชันของคุณที่เน้นที่ ระดับเสียงเท่านั้น — ละเว้นสิ่งหนึ่ง ละเว้นตัวละคร เพียงจับคู่โครงร่างสำเร็จ
- บันทึกใหม่ที่เน้นที่ สิ่งหนึ่งเท่านั้น — วลีเดียวกัน เป้าหมายโพรงที่ถูกต้อง
- บันทึกใหม่ที่เน้นที่ จังหวะและลมหายใจ — วลีเดียวกัน จับคู่การจับเวลาอย่างแม่นยำ
- เวลา: 15 นาทีต่อวัน
ทำไมมันทำงาน: หลักการการเรียนรู้มอเตอร์ในวิทยาศาสตร์การสอนเสียงสนับสนุน การฝึกแบบปิด (ตัวแปรเดียวตามครั้ง) มากกว่าการฝึกแบบแปรผันเมื่อเรียนรู้การประสานงานใหม่ ตำแหน่งนี้สอดคล้องกับกรอบของ Titze ใน Principles of Voice Production การแยกตัวแปรเดียวฝึกกลุ่มกล้ามเนื้อที่รับผิดชอบโดยไม่ต้องโหลดการรับรู้ของการจับคู่ทั้งห้า
Drill 2 — The Blind Reference Test
Targets: การฝึกหู การหลอกตัวเอง
- บันทึกเทคสามเทคของข้อความ 15 วินาทีในตัวละคร
- รอสักครู่อย่างน้อย 4 ชั่วโมง — หูสดใหม่
- เล่นข้อมูลอ้างอิง จากนั้นเทคที่ดีที่สุดของคุณ สลับกันโดยไม่มองไปที่รูปคลื่น
- ให้คะแนนอย่างสุจริต: อันไหนเสียงเหมือน พวกเขา มากกว่า?
ผู้สร้างสื่อส่วนใหญ่ค้นพบเทค "ที่ดีที่สุด" ของพวกเขาไม่ใช่เทคที่ใกล้ที่สุด พวกเขาให้รางวัลเทคที่พวกเขาสนใจพยายามมากที่สุดแทนเทคที่ลงจอดได้แม่นยำที่สุด การทดสอบตาบอดหลีกเลี่ยงอคตินั้น เรียกใช้รายสัปดาห์
Drill 3 — The Emotional Anchor
Targets: บริบทอารมณ์ ความสัตย์ของการแสดง
ก่อนบันทึก ตั้งชื่อสถานะอารมณ์ของตัวละครในฉาก Gandalf ตะโกน "You shall not pass!" ไม่ใช่ความโกรธ — มันคือการแก้ไขป้องกันภายใต้ความเหนื่อยล้า สองสถานะดังกล่าวฟังเหมือนแตกต่างกันทั้งแม้ว่าคำนั้นจะเหมือนกัน สวมใส่มันทางกายภาพ: ท่าทาง ลึกลมหายใจ ที่คุณถือความตึงเครียดในร่างกายของคุณ จุดซ้ำของ Dee Bradley Baker ใน I Want to Be a Voice Actor! คือเสียงตัวละครโดยไม่มีเจตนาตัวละครเสียงกลไก บันทึกหลังจากการติดจอยแล้วเท่านั้น ทุกเซสชั่น
Drill 4 — The Cross-Language Pressure Test
Targets: การอุปนิสัยลายเซ็นเทียบกับการจำลำดับเสียงตามอักษร
นำการเลียนแบบของคุณและแสดงมันบนสคริปต์ที่แตกต่างกันทั้งหมด — รายชอปปิง รายงานอากาศ เนื้อเพลงเพลงโปรดของคุณ — ในเสียงเดียวกัน หากการเลียนแบบพังเมื่อคำเปลี่ยนแปลง คุณได้จำลำดับเสียงตามอักษรแทนการอุปนิสัยลายเซ็นเสียง
แบบฝึกนี้คือเกตคีพสำหรับงาน localization หากการเลียนแบบของคุณไม่สามารถ reside การใช้ได้ในรายชอปปิงในภาษาอังกฤษ มันจะไม่รักษากับการ dub ลงในโปรตุเกส รายสัปดาห์ cadence
ถ้าการเลียนแบบของคุณไม่สามารถรักษาได้ปลอดภัย บทบาทใช้กับรายชอปปิง มันจะไม่รักษากับการ dub ลงในภาษาที่สอง
ตารางสัปดาห์ Voice Impression Training ของคุณ
- 15 นาทีรายวันวนลูปการแยกในองค์ประกอบเสียงเดียว (หมุน: ระดับเสียง → สิ่งหนึ่ง → จังหวะ → หนังสือธรรมชาติ)
- สร้างสมอทางอารมณ์ก่อนเซสชั่นบันทึกทุกเซสชั่น
- การทดสอบข้อมูลอ้างอิงตาบอดหนึ่งครั้งต่อสัปดาห์พร้อมการแยก 4+ ชั่วโมงระหว่างเทคและการทบทวน
- การทดสอบความกดดันข้ามภาษาหนึ่งครั้งต่อสัปดาห์โดยใช้วัสดุไม่ใช่สคริปต์
- บันทึก "ลายเซ็นใช้" 30 วินาทีทุกวันศุกร์ — วลีเดียวกัน ตัวละครเดียวกัน — เพื่อติดตามความก้าวหน้าในสัปดาห์ต่อสัปดาห์
- รักษาพื้นความเครียด −60 dB หรือต่ำกว่า ในพื้นที่บันทึกของคุณ (แผง การบินหา ไม่มี HVAC ไม่มีพัด) ตาม Voiceover Masterclass มาตรฐาน — สิ่งนี้สำคัญสำหรับการฝึกหูของมนุษย์และการใช้การโคลนในอนาคตใด ๆ
ที่ไหนการฝึกเลียนแบบเสียงด้วยตนเองชนกับเพดานที่ยาก
แบบฝึกข้างต้นสร้างทักษะจริงที่ไม่มีเครื่องมือใดสามารถปลอมได้ พวกเขายังมีเพดาน ผู้แสดงเดียวที่มีทักษะมีผลผลิตที่มี จำกัด — ขวดไม่ใช่ความสามารถ มันคือชีววิทยาและนาฬิกา สี่สถานการณ์แสดงที่เพดานนั้นกลายเป็นข้อ จำกัด ด้านธุรกิจ
ปัญหาวิดีโอ 30 นาที ผู้สร้างสื่อถือเสียงตัวละครข้าม 30 นาทีของบทสนทนาเหนื่อยศีรษะ เทค 40 ไม่ตรงกับเทค 4 ระดับเสียง漂 ขึ้น ลมหายใจหลบหนี สิ่งหนึ่งของหน้าอกย้ายเข้าไปในลำคอ การแก้ไขห้องแก้ไขใช้เวลาหลายชั่วโมง
ปัญหา localization 6 ภาษา แม้แต่ผู้สร้างสื่อที่คล่องคล่องในภาษาสเปนไม่สามารถ แสดง เสียงตัวละครภาษาอังกฤษของพวกเขาอย่างมีความเชื่อได้ในภาษาสเปน คูณด้วยหกภาษาเป้าหมายและแผนการ localization กลายเป็นหนึ่งปีของงานเสียง — สมมติว่าทักษะการแสดงหลายภาษามีอยู่เลย
ปัญหาการปรับแก้ไขของไคลเอนต์ การเปลี่ยนแปลงบรรทัดในสัปดาห์ 8 หมายถึงการบันทึกซ้ำในสถานะเสียงเดียวกัน — ห้องเดียวกัน เวลาในวันเดียวกัน ความชื้นลำคอเดียวกัน ปฏิบัติไม่ได้ที่จะจับคู่อย่างสมบูรณ์
ปัญหาตัวละครหลายตัว ผู้สร้างสื่อให้เสียง 4 ตัวละครในฉากบทสนทนาเดียว ต้องการตัวละครแยก 4 ครั้งขั้นต่ำ และการเปลี่ยนเสียงเหนื่อยลำคออย่างรวดเร็ว
วิธีการผลิต Voice Impression เปรียบเทียบ
| ปัจจัย | การเลียนแบบที่บันทึกเอง | การจ้างนักแสดงเสียง | AI Voice Cloning |
|---|---|---|---|
| เวลาการใช้ครั้งแรกสามารถใช้ได้ | สัปดาห์ถึงเดือนของการฝึกแบบกระจาย | 1–3 วัน (การส่งสายรูปแบบ + บันทึก) | วินาทีสำหรับโคลนมือใหม่จากตัวอย่าง 10 วินาที 30–120 นิ้ว บันทึกสำหรับเกรด prosumer |
| ตัวอย่างบันทึกที่ต้องการ | N/A — การแสดงสดใจ | N/A — การแสดงสดใจ | 30–120 วินาที (turnkey); 10–15 นาที (RVC); 30 นาที–2 ชั่วโมง (มืออาชีพ) |
| ความสม่ำเสมอเทคต่อเทค | ตัวแปร —漂 ไปมาพร้อมความเหนื่อยล้า | สูงภายในเซสชั่น ตัวแปรข้ามเซสชั่น | ซ้ำได้อย่างสมบูรณ์สำหรับข้อความและพารามิเตอร์ที่กำหนด |
| การปรับขนาดหลายภาษา | ต้องมีทักษะ + ความเชี่ยวชาญการเลียนแบบในแต่ละ | นักแสดงหลายภาษาหรือนักแสดงหลายคน | AI Dubbing ข้ามภาษา รักษา timbre ข้ามเป้าหมาย |
| ความพอดีที่ดีที่สุด | การแสดงสดใจ แบบสั้น การฝึกหู | ผลิตภัณฑ์ premium ครั้งเดียว | แบบยาว หลายภาษา ซ้ำแล้วซ้ำเล่า |
แหล่งที่มาสำหรับตัวเลขข้างต้น: ElevenLabs tutorial, DeepReel, CloudPano, Kukarella และ RVC tutorial
นี่ไม่ใช่การตัดสินว่า AI ชนะ การฝึกด้วยตนเองสร้างทักษะที่เปลี่ยนเป็นการแสดงสดใจ podcasting โรงละครและการฝึกหูที่ทำให้ทุกวิธีอื่น ดีขึ้น ตารางแยกสถานการณ์การผลิตเฉพาะที่ชีววิทยากลายเป็นข้อจำกัด
หลักฐานต่อต้านนั้นสำคัญเช่นกัน นักแสดงเสียงและ SAG-AFTRA ได้สังเกตว่าโคลน AI ปัจจุบันยังคงดิ้นรนกับ ความเห็นอารมณ์ที่ซับซ้อน บริบท และงาน sceneที่ไดนามิก — โดยเฉพาะในละครและตลกที่ microtiming มีความหมาย สำหรับผู้สร้างสื่อผลิตวิดีโอคำอธิบายหกภาษา ข้อ จำกัด นั้นสามารถรับได้ สำหรับผู้สร้างสื่อผลิต animation การบรรยายที่มีสามเทิร์นอารมณ์ต่อฉาก มันยังไม่ใช่ สังเคราะห์ที่ซื่อสัตย์: คำถามไม่ใช่ "ด้วยตนเองหรือ AI" มันคือ "ที่ไหนวิธีแต่ละวิธีที่อยู่ในเวิร์กโฟลว์?"
ขวดในงานประเมินเสียงไม่ใช่ความสามารถ — มันคือชีววิทยาและนาฬิกา
วิธีที่ AI Voice Cloning เพิ่มช่วงของ Impressionist ที่มีทักษะ
สิ่งที่ Cloning จริง ๆ จับ
โคลนเสียงไม่ใช่การบันทึก มันเป็นแบบจำลองที่เรียนรู้ของลายเซ็นเสียง แบบจำลองจับโปรไฟล์สิ่งหนึ่ง รูปแบบ contour ระดับเสียง จังหวะลมหายใจ และแนวโน้มหนังสือธรรมชาติจากเสียงการฝึก จากนั้นใช้มันกับข้อความใหม่ วิทยาศาสตร์การพูดของ Rupal Patel ผู้ก่อตั้ง VocaliD ได้โต้แย้งใน TED talk ของเธอและการสัมภาษณ์ที่เกี่ยวข้องว่าเสียง synthetic ที่ถูกต้องจะต้องจับ prosody idiosyncratic ไม่เพียงแค่ระดับเสียงเฉลี่ย เพื่ออ่านเป็นจริงแทนที่จะเป็นทั่วไป
นั่นเป็นเหตุผลว่าทำไมการเลียนแบบที่บ้านสำหรับดี ดีกว่า โคลนผู้สมัครแทนการเสียงสงบเปล่า ลายเซ็นที่รูปแบบเรียนรู้เป็นลายเซ็นตัวละคร ผู้สร้างสื่อที่ทำแบบฝึก Section 3 เดินเข้าสู่เซสชั่น voice cloning พร้อมข้อมูลสะอาด สม่ำเสมอมากกว่าคนที่ไม่ได้ — และโคลนที่เกิดขึ้นสะท้อนความแตกต่างนั้นโดยตรง
ความเป็นจริง Dataset
มี Tier คุณภาพสามชั้น แต่ละมีความต้องการตัวอย่างที่เฉพาะเจาะจง
- Beginner / instant clone: ~10 วินาทีของเสียงที่ชัดเจนให้ผลมา โคลนการทดสอบพื้นฐานที่คุณสามารถทดลองได้ในเวลาไม่กี่วินาที ตาม ElevenLabs tutorial
- Creator-grade narrator clone: 30–120 วินาทีของเสียงสะอาดสร้าง stable narrator-style clone, ตาม DeepReel และ CloudPano
- Professional-grade clone: 30 นาทีถึง 2 ชั่วโมงของการบันทึก ผลลัพธ์ได้ดีขึ้นอย่างเห็นได้ชัดใกล้กับเครื่องหมาย 2 ชั่วโมง เวลาประมวลผลบนโครงสร้างพื้นฐานผู้ให้บริการประมาณ 2–6 ชั่วโมง ตาม ElevenLabs tutorial
- Open-source RVC stack: 10–15 นาทีของเสียงสะอาดเป็นจุดหวาน practitioner เป้าหมาย 2–10 นาทีเป็นไปได้พร้อมการแลกเปลี่ยนคุณภาพ 40 kHz อัตราตัวอย่างเป็น practitioner เริ่มต้น ตาม RVC tutorial
พื้นเทคนิคไม่สามารถเจรจาได้: พื้นความเครียด ≤ −60 dB และ ไม่มี compression, EQ, de-essing หรือ noise reduction ใช้กับไฟล์การฝึกดิบ ตาม Voiceover Masterclass มาตรฐาน ขยะเข้า ขยะออก ใช้สองครั้ง — แบบจำลองขยายสิ่งสัตว์ใดก็ตามที่มีอยู่ในแหล่งที่มา

สองกรณีการศึกษาเวิร์กโฟลว์
Case A — YouTuber 30 นาที ผู้สร้างสื่อยึดการเลียนแบบตัวละครสำหรับ 30 วินาทีแต่สูญเสียความสม่ำเสมอข้ามตอน long-form เวิร์กโฟลว์: บันทึกหนึ่ง 90 วินาทีที่สมบูรณ์ของเสียงตัวละครในตัวละคร โคลนมัน สร้างบทสนทนาพื้นหลังกับโคลนโดยใช้ Text to Speech ขณะเวลาสงวนพลังงานการแสดงสำหรับห้าหรือหกตีอารมณ์สำคัญที่ดำเนินการตอนเรื่อง ผลลัพธ์: เสียงสม่ำเสมอข้าม 30 นาที ยอดการแสดง ที่พวกเขาอำนาจ เซสชั่นบันทึกบีบอัด จากประมาณ 8 ชั่วโมงประมาณ 90 นาที
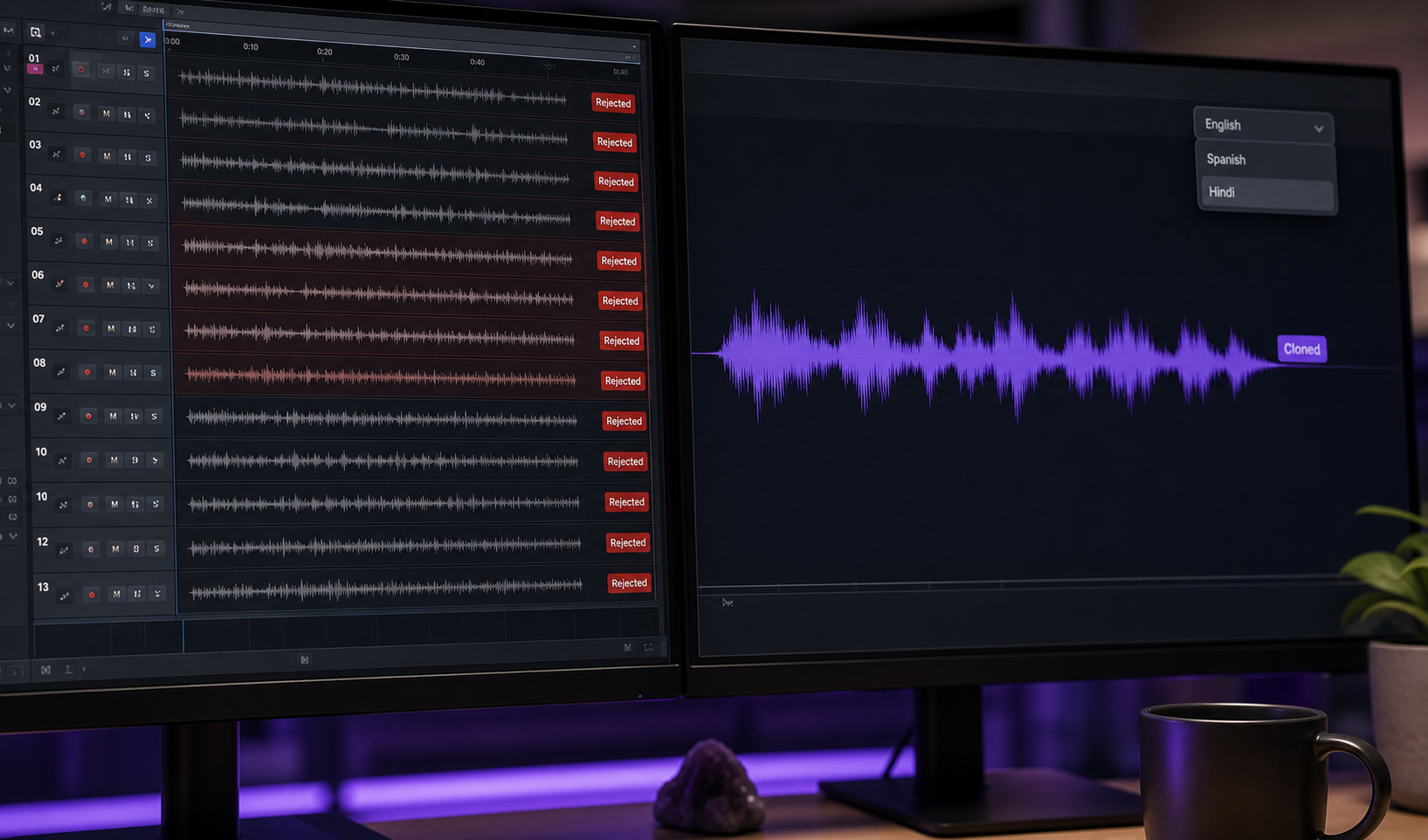
Case B — วิดีโอการฝึก 6 ภาษา ธุรกิจเล็ก ๆ ผลิตโมดูลการฝึกภายในความยาว 15 นาทีบรรยายด้วยเสียงตัวละครที่อบอุ่นและมีอำนาจ เวิร์กโฟลว์: บันทึกเวอร์ชันภาษาอังกฤษครั้งเดียวด้วยความประทับใจสดใจ โคลนเสียง ใช้การ cloning แบบข้ามภาษาผ่าน Voice Cloning API เพื่อให้ "สเปน โปรตุเกส ฝรั่งเศส เยอรมัน ฮินดี และ Japanese versions เก็บบรรยากาศตัวละครข้ามภาษา ตาม DeepReel และ Kukarella ตัวละครเดียวกัน "พูด" ทั้งหกภาษาเพราะ signature ถ่ายโอน แม้ว่าภาษาจะไม่
Voice cloning ไม่แทนที่ทักษะของการยึดการเลียนแบบ — มันขยาย มันทำให้ส่วนที่ยากเป็นการเลียนแบบขวา เทคโนโลยีเพียงแค่ลบการทำซ้ำ
จริยธรรมและขอบเขตความถูกต้อง
เสียง Synthetic สามารถถูกทำให้ร้ายแรง ศาสตราจารย์กฎหมาย Danielle Citron ใน The Fight for Privacy และสิ้นข่าวขนาดเดีย-fake ที่เกี่ยวข้องได้บันทึกว่าการ cloning เสียงที่ไม่ยินยอมเป็นไปได้ personification การหลอกลวง และการสร้างข้อมูลที่ไม่ถูกต้องทางการเมือง — และโต้แย้งสำหรับทั้งชั่งน้ำหนักทางกฎหมายและ guardrails ระดับการออกแบบ บนเครื่องมือเชิงพาณิชย์
เส้นจริยธรรมสำหรับผู้สร้างสื่อเป็นไปได้ตรงไปตรงมา การ cloning ของตัวเอง เสียงสำหรับ ของตัวเอง เนื้อหาคือ unambiguously ดี การ cloning เสียงตัวละครแต่งตั้งที่คุณฟอร์มแรกตัวเองคือ ดี การ cloning บุคคลสาธารณะจริง หรือใครก็ตาม โดยไม่ยินยอมที่ชัดเจนคือ ไม่ การเปิดเผยในเครดิตเมื่อ AI dubbing ใช้เป็นการฝึกตัวอักษรมาตรฐานและเป็นค่าเริ่มต้นที่ปลอดภัยกว่าสำหรับงานเชิงพาณิชย์
สร้างชุดเครื่องมือ Voice Impression ของคุณ — จับคู่ขวดของคุณกับเส้นทางที่ถูกต้อง
ตัวเลือกไม่ใช่การฝึกด้วยตนเอง หรือ AI cloning มันคือการระบุข้อจำกัดที่ฉันกำลังบล็อกงาน ของคุณตอนนี้และใช้เส้นทางจับคู่ เมทริกซ์ด้านล่างแม่ปสถานการณ์ผู้สร้างสี่สาธารณะกับการดำเนินการแรก