
คุณเลื่อนผ่านตัวอย่างเสียงมาแล้วกว่าสี่สิบรายการ สวมหูฟัง แตะปุ่มฟังตัวอย่าง ฟังสามวินาที แตะรายการถัดไป แล้วก็ถัดไปอีก จนกระทั่งทุกตัวอย่างเบลอกลายเป็นเสียงฮัมที่ฟังไม่ออกเหมือนกันไปหมด เสียงนี้ "อบอุ่น" หรือแค่ "นุ่ม"? เสียงบรรยายควรฟัง "น่าเชื่อถือ" หรือ "เป็นมิตร"? ปัญหาไม่ได้อยู่ที่การขาดแคลนตัวเลือก — คลังเสียงสมัยใหม่มีเสียงให้เลือกกว่า 300 เสียง และคุณสามารถนั่งฟังได้เป็นชั่วโมงโดยไม่เลือกได้สักเสียง ปัญหาอยู่ที่ คำอธิบายลักษณะเสียง (voice descriptors) นั่นคือคำศัพท์ที่แม่นยำซึ่งคุณต้องใช้เพื่อแยกเสียงหนึ่งออกจากอีกเสียงหนึ่ง และจับคู่มันเข้ากับเนื้อหาของคุณอย่างมีเจตนา หากปราศจากคำศัพท์เหล่านั้น การเลือกเสียงจะกลายเป็นการเดาสุ่ม และการพากย์เสียงก็จะกลายเป็นการลองผิดลองถูกที่แสนแพง ตามที่ WP SEO AI ระบุ ป้ายกำกับคำเดียวอย่าง "เป็นธรรมชาติ" หรือ "น่าดึงดูด" คลุมเครือเกินกว่าจะนำไปใช้ได้จริง — ภาพเสียงที่ชัดเจนต้องระบุมิติหลายอย่างที่มีปฏิสัมพันธ์กันพร้อม ๆ กัน เมื่อจบบทความนี้ คุณจะสามารถอธิบายเสียงใด ๆ ได้อย่างแม่นยำในด้าน โทน ระดับเสียง และสไตล์ เพื่อให้คุณสามารถค้นหา กรอง และสั่งงานเครื่องมือเสียง — หรือบรีฟโครงการโคลนเสียง — ได้ด้วยความมั่นใจแทนการอาศัยโชค

สารบัญ
- สี่มิติที่คำอธิบายลักษณะเสียงทุกคำจัดอยู่ภายใต้
- ถอดรหัสคำอธิบายโทน — จาก "อบอุ่น" ถึง "น่าเชื่อถือ"
- ระดับเสียงและจังหวะ — คำอธิบายเชิงเทคนิคที่คนเข้าใจผิด
- สไตล์และระดับภาษา — จับคู่เสียงเข้ากับบริบทของเนื้อหา
- การซ้อนคำอธิบายเพื่อค้นหาเสียงหรือสร้างพรอมต์ที่แม่นยำ
- หลุมพรางของคำอธิบาย — จุดที่การเลือกเสียงพังแบบเงียบ ๆ
- เทมเพลตบรีฟคำอธิบายลักษณะเสียงแบบคัดลอกวาง
- คำถามเกี่ยวกับคำอธิบายลักษณะเสียงที่ครีเอเตอร์ถามกันจริง ๆ
สี่มิติที่คำอธิบายลักษณะเสียงทุกคำจัดอยู่ภายใต้
คำอธิบายลักษณะเสียงทุกคำที่คุณเคยอ่าน — ไม่ว่าจะกวีแค่ไหน — ก็ยุบรวมลงสู่สี่มิติที่วัดได้ เมื่อคุณตั้งชื่อมันได้ คำศัพท์ก็จะหยุดให้ความรู้สึกว่าเป็นเรื่องอัตวิสัย และเริ่มทำตัวเหมือนชุดของตัวควบคุมที่คุณปรับได้อย่างเป็นอิสระ
โทน (Tone) คือสีสันทางอารมณ์หรือทัศนคติของเสียง อบอุ่น เย็นชา กระตือรือร้น ห่างเหิน — นี่คือลักษณะทางอารมณ์ที่ผู้ฟังรับรู้ก่อนที่จะประมวลผลความหมายของคำแม้แต่คำเดียว มันคือมิติที่ตัดสินว่าผู้ชมของคุณจะโน้มตัวเข้ามาหรือเลิกสนใจไป
ระดับเสียง (Pitch) คือความสูงต่ำของเสียงที่รับรู้ได้ เสียงทุ้มต่ำก้องกังวานอยู่ปลายด้านหนึ่ง ส่วนเสียงสว่าง เบา และเยาว์วัยอยู่ปลายอีกด้าน ระดับเสียงโดยพื้นฐานเป็นคุณสมบัติของความถี่ ซึ่งทำให้มันเป็นหนึ่งในคำอธิบายที่เป็นปรนัยที่สุดในสี่มิติ — แต่ก็เป็นหนึ่งในคำที่ถูกสับสนกับจังหวะบ่อยที่สุดด้วย
จังหวะและทำนอง (Pace and rhythm) อธิบายความเร็วของการพูดและลีลาของมัน รวดเร็ว มีจังหวะ เนิบช้า เน้นย้ำ — จังหวะรวมถึงการหยุดเว้นระหว่างวลี และรูปแบบการขึ้นลงของน้ำเสียงที่ซ้อนทับอยู่ด้านบน เสียงสองเสียงที่อ่านสคริปต์เดียวกันด้วยจังหวะที่ต่างกัน อาจให้ความรู้สึกเหมือนเป็นการแสดงคนละแบบกันโดยสิ้นเชิง
สไตล์และระดับภาษา (Style and register) ควบคุมบริบทของการแสดงและความเป็นทางการ การบรรยาย การสนทนา การออกอากาศ การเรียนออนไลน์ — เป็นทางการเทียบกับไม่เป็นทางการ นี่คือมิติที่ตัดสินว่าเสียงนั้นกำลังเล่นบทบาทใดให้แก่ผู้ฟัง
การจัดหมวดหมู่นี้ไม่ใช่ความคิดเห็นส่วนตัว Nielsen Norman Group ได้กำหนดโทนตามแกนอิสระสี่แกน — เป็นทางการเทียบกับไม่เป็นทางการ จริงจังเทียบกับตลก เคารพเทียบกับไม่เกรงใจ และเรียบ ๆ ตามข้อเท็จจริงเทียบกับกระตือรือร้น — แสดงให้เห็นว่าโทนเป็นแบบหลายแกน ไม่ใช่แค่แถบเลื่อนเดียวที่คุณลากจาก "น่าเบื่อ" ไป "สนุก" แพลตฟอร์มเชิงพาณิชย์นำตรรกะเดียวกันไปใช้งานจริง ตลาดเสียงอย่าง Voices.com จัดกลุ่มการอธิบายเสียงออกเป็นสี่คุณสมบัติ ได้แก่ ระดับเสียงและโทน ปริมาณเสียงและการฉายเสียง การออกเสียงและความชัดของพยางค์ และอัตราเร็วกับการขึ้นลงของน้ำเสียง ป้ายกำกับต่างกัน แต่โครงสร้างพื้นฐานเหมือนกัน

ทำไมการแยกมิติออกจากกันจึงสำคัญมากนัก? โค้ชด้านการสื่อสาร Robin Kermode มองโทน ระดับเสียง และจังหวะ ว่าเป็นคันบังคับสามตัวที่ร่วมกันสร้าง "ความหลากหลายของเสียง" — โดยนิยามโทนว่าเป็นลักษณะทางอารมณ์ ระดับเสียงเป็นความถี่ที่รับรู้ได้ซึ่งเปลี่ยนแปลงความหมายทางอารมณ์ได้ และจังหวะเป็นความเร็วในการนำเสนอ สไตล์และระดับภาษาเป็นคันบังคับตัวที่สี่ และมันตั้งอยู่ เหนือ อีกสามตัว โดยควบคุมบริบทที่ทั้งสามตัวทำงานอยู่ พูดง่าย ๆ คือ โทน ระดับเสียง และจังหวะ อธิบาย ว่าเสียงฟังเป็นอย่างไร ส่วนสไตล์และระดับภาษาอธิบาย ว่ามันกำลังเล่นบทบาทใด
คำอธิบายลักษณะเสียงทุกคำที่คุณเคยอ่านยุบรวมลงสู่คันบังคับสี่ตัว — โทน ระดับเสียง จังหวะ และสไตล์ เชี่ยวชาญคันบังคับเหล่านี้แล้วคุณจะเลิกเดาสุ่ม
จดจำแบบจำลองนี้ไว้ ทุกหัวข้อต่อจากนี้จะเจาะลึกลงไปในมิติใดมิติหนึ่งในสี่มิตินี้พอดี และไม่มีหัวข้อใดที่จะนิยามกรอบแนวคิดใหม่ เมื่อคุณพบคำอธิบายที่ไหนก็ตาม — ตัวกรองในตลาดเสียง ช่องพรอมต์ AI หรือบรีฟของเอเจนซี — งานแรกของคุณคือการจัดมันเข้าไปในหนึ่งในสี่ถัง นิสัยเพียงข้อนั้นเปลี่ยนกำแพงของคำคุณศัพท์ให้กลายเป็นแผงควบคุมที่จัดระเบียบเรียบร้อย
ถอดรหัสคำอธิบายโทน — จาก "อบอุ่น" ถึง "น่าเชื่อถือ"
โทนเป็นมิติที่ผู้ชมรับรู้เป็นอันดับแรก และเป็นมิติที่มักถูกบรีฟผิดบ่อยที่สุดเพราะมันพึ่งพิงคำคุณศัพท์เชิงอัตวิสัย งานวิจัยของ Nielsen Norman Group แสดงให้เห็นว่าโทนทำงานข้ามแกนอิสระหลายแกน — อารมณ์ขัน ความเป็นทางการ ความเคารพ และความกระตือรือร้น เป็นคันบังคับแยกจากกัน — ซึ่งหมายความว่าคำโทนคำเดียวแทบไม่อาจจับสิ่งที่คุณต้องการจริง ๆ ได้ ให้จัดกลุ่มคำอธิบายโทนของคุณแทน แล้วคุณจะได้ทั้งความแม่นยำและวิธีการกรองที่ใช้งานได้จริง
สร้างความไว้วางใจ (อบอุ่น เป็นมิตร ให้ความมั่นใจ) กลุ่มนี้สร้างความรู้สึกปลอดภัยทางอารมณ์ก่อนที่ความหมายจะมาถึง เป็นตัวเลือกที่ถูกต้องสำหรับวิดีโออธิบายด้านสุขภาพ ระบบ IVR ฝ่ายบริการลูกค้า และวิดีโอเริ่มต้นใช้งาน ที่ผู้ฟังต้องรู้สึกว่าได้รับการดูแลก่อนจะซึมซับคำแนะนำ WP SEO AI ระบุว่า "อบอุ่น" เป็นหนึ่งในคำคุณศัพท์โทนทางอารมณ์ที่ใช้บ่อยที่สุด และมีเหตุผลรองรับ — มันเป็นพื้นฐานที่ผู้ชมส่วนใหญ่ไว้วางใจเป็นค่าตั้งต้น
มีพลัง (สดใส กระตือรือร้น มีชีวิตชีวา) กลุ่มนี้ส่งสัญญาณถึงความเคลื่อนไหวและความตื่นเต้น เหมาะที่สุดสำหรับการเปิดตัวสินค้า การอ่านโฆษณา และคลิปสั้นบนโซเชียลที่สองวินาทีแรกเป็นตัวตัดสินว่าใครจะดูต่อหรือไม่ แกน "กระตือรือร้น" ของ NN/g ตรงกับตรงนี้พอดี — และสังเกตว่ามันเป็นอิสระจากความเป็นทางการ ดังนั้นคุณจึงสามารถมีพลังและเป็นมืออาชีพในเวลาเดียวกันได้
จริงจัง (น่าเชื่อถือ เป็นมืออาชีพ เคร่งขรึม) กลุ่มนี้ถ่ายทอดความน่าเชื่อถือและน้ำหนัก หยิบมาใช้กับการฝึกอบรมองค์กร วิดีโออธิบายด้านการเงิน และการบรรยายสารคดี ที่ผู้ชมต้องเชื่อว่าผู้พูดรู้มากกว่าพวกเขา "น่าเชื่อถือ" เป็นคำอธิบายชั้นนำในรายการภาพเสียงของ WP SEO AI — มันเฉพาะเจาะจงพอที่จะใช้กรองได้ และกว้างพอที่จะใช้ได้กับหลากหลายรูปแบบ
ใกล้ชิด (นุ่ม ผ่อนคลาย สนทนา) กลุ่มนี้สร้างความใกล้ชิดและความสงบ ถูกสร้างมาสำหรับแอปทำสมาธิ อินโทรพอดแคสต์ และเนื้อหาสไตล์ ASMR ที่ผู้ฟังมักอยู่คนเดียวและเสียงรู้สึกเหมือนกำลังพูดกับพวกเขาโดยตรง ความใกล้ชิดมาจากการยับยั้งพอ ๆ กับความอบอุ่น — กลุ่มนี้ดึงกลับมากกว่าจะฉายออกไป
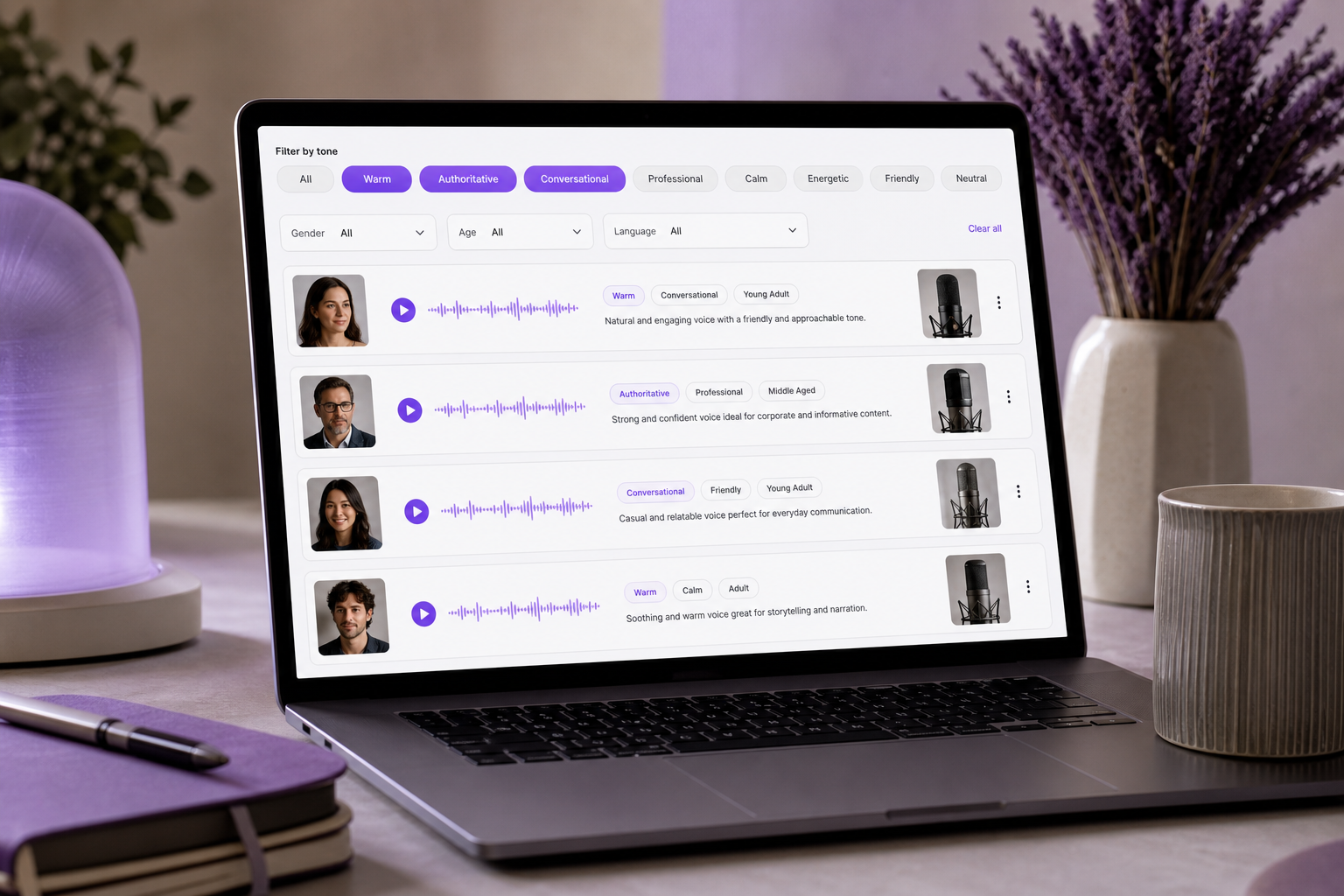
โทนเป็นมิติเดียวที่ผู้ชมสังเกตเห็นเป็นอันดับแรกและลืมเป็นอันดับสุดท้าย — มันตั้งความไว้วางใจทางอารมณ์ก่อนที่ความหมายของคำแม้แต่คำเดียวจะมาถึง
กลุ่มเหล่านี้ไม่ใช่แค่แบบจำลองทางความคิด — แต่เป็นวิธีที่เครื่องมือสมัยใหม่ให้คุณค้นหา แพลตฟอร์ม TTS อย่าง SymTrain มีการบันทึกการกรองเสียงตามโทน เช่น "ชัดถ้อยชัดคำ ไม่เป็นทางการ วิตกกังวล" เพื่อจำกัดวงคลังเสียงขนาดใหญ่ก่อนที่คุณจะกดฟังตัวอย่างเสียด้วยซ้ำ นั่นคือผลตอบแทนที่ใช้งานได้จริงของการจัดกลุ่มคำอธิบายลักษณะเสียงของคุณ: เช่นเดียวกับที่คลัง Text to Speech ให้คุณกรองตามโทนก่อนฟังตัวอย่าง กลุ่มโทนที่ชัดเจนเปลี่ยนการนั่งฟังเป็นชั่วโมงให้กลายเป็นรายชื่อผู้เข้ารอบสามเสียงที่โฟกัส
ระดับเสียงและจังหวะ — คำอธิบายเชิงเทคนิคที่คนเข้าใจผิด
ระดับเสียงและจังหวะเป็นสองมิติที่ถูกสับสนมากที่สุดในบรีฟเสียงใด ๆ และความสับสนนั้นทำให้ครีเอเตอร์เสียเวลาจริง ๆ ระดับเสียงคือความถี่ — ความสูงต่ำของเสียงที่รับรู้ได้ จังหวะคือความเร็วและทำนอง — จำนวนคำต่อนาที ลีลา และตำแหน่งของการหยุดเว้น การแบ่งสามทางของ Robin Kermode ทำให้พวกมันชัดเจน: โทนคือลักษณะทางอารมณ์ ระดับเสียงคือความถี่ที่รับรู้ได้ จังหวะคือความเร็วของการพูด สามสิ่งที่แยกจากกัน
ข้อผิดพลาดคลาสสิกคือการสลับคำศัพท์ ครีเอเตอร์พูดว่า "เร็ว" ทั้งที่หมายถึง "เสียงสูง" หรือ "ทุ้ม" ทั้งที่หมายถึง "ช้า" สิ่งเหล่านี้เป็นตัวควบคุมที่เป็นอิสระต่อกัน เสียงทุ้มสามารถพูดเร็วได้ เสียงสูงสามารถพูดเป็นจังหวะได้ การปฏิบัติกับมันเหมือนเป็นคำคุณศัพท์เบลอ ๆ คำเดียว คือสาเหตุที่ทำให้บรีฟผิดพลาดก่อนที่ใครจะอัดเสียงสักพยางค์
| คำอธิบาย | ควบคุมอะไร | ฟังเป็นอย่างไร | เหมาะกับ |
|---|---|---|---|
| ทุ้ม (Deep) | ระดับเสียง (ความถี่ต่ำ) | เสียงทุ้ม ก้องกังวาน | สารคดี แบรนด์หรู |
| สว่าง (Bright) | ระดับเสียง (ความถี่สูง) | เบา โปร่ง เยาว์วัย | เนื้อหาสำหรับเด็ก โฆษณาสดใส |
| มีจังหวะ (Measured) | จังหวะ (ช้า/สม่ำเสมอ) | เนิบ ๆ มีช่องว่าง | การเรียนออนไลน์ บทเรียน |
| กระฉับกระเฉง (Brisk) | จังหวะ (เร็ว) | มีพลัง เร่งด่วน | ข่าว โปรโมชัน |
| ห้วน ๆ (Clipped) | จังหวะ + การออกเสียง | คมชัด หยุดได้แม่นยำ | เทคนิค การสอน |
| ลากเสียง (Drawling) | จังหวะ (ช้า/ผ่อนคลาย) | ยืดยาว สบาย ๆ | การเล่าเรื่อง บทบาทตัวละคร |
งานที่น่าสนใจเกิดขึ้นเมื่อระดับเสียงและจังหวะรวมกัน เพราะความประทับใจแบบผสมแทบจะแข็งแกร่งกว่าคำอธิบายเดี่ยว ๆ เสมอ ระดับเสียงทุ้มกับจังหวะกระฉับกระเฉงสื่อถึงความเร่งด่วนแบบมั่นใจ — เสียงของคนที่รู้เนื้อหาดีและไม่เสียเวลาของคุณ ระดับเสียงสว่างกับจังหวะมีจังหวะสื่อถึงความอดทนแบบเป็นมิตร — เหมาะเมื่อคุณพาผู้ใช้ที่กำลังประหม่าผ่านการตั้งค่าครั้งแรก สลับการผสมแล้วความหมายจะพลิกกลับโดยสิ้นเชิง ซึ่งนั่นคือเหตุผลที่คุณไม่สามารถยุบรวมสองช่องนี้เป็นช่องเดียวได้
การแยกนี้ถูกฝังอยู่ในวิธีที่แพลตฟอร์มจริงจังจัดโครงสร้างคำแนะนำของพวกเขา Voices.com ปฏิบัติกับระดับเสียง/โทน และอัตราเร็ว/การขึ้นลงของน้ำเสียง ว่าเป็นสองในสี่คุณสมบัติที่แตกต่างกัน ไม่เคยรวมเป็นการตั้งค่าเดียว เอกสาร Hamsa API ก็จัดรายการจังหวะการพูดและการออกเสียง/ความชัดเจนเป็นเกณฑ์การเลือกที่แยกจากกันในทำนองเดียวกัน โดยแต่ละอย่างถูกประเมินด้วยตัวมันเองก่อนที่เสียงจะเข้าสู่การผลิต ข้อสรุปสำหรับนักปฏิบัตินั้นตรงไปตรงมา: ในบรีฟใด ๆ ให้ช่องแยกแก่ระดับเสียงและจังหวะ เขียนว่า "ระดับเสียงทุ้ม จังหวะกระฉับกระเฉง" ไม่ใช่ "เสียงทุ้มหนักแน่น" แล้วหวังว่าผู้อ่านจะแยกแยะได้ และจำไว้ว่าลักษณะระดับเสียงและจังหวะเดียวกันที่คุณระบุไว้ตรงนี้ คือสิ่งที่โมเดล Voice cloning รักษาไว้จากตัวอย่างต้นฉบับ — ดังนั้นการใช้คำศัพท์ให้ถูกต้องตั้งแต่ขั้นตอนบรีฟ จึงส่งผลต่อเนื่องไปจนถึงผลลัพธ์ของเสียงที่โคลนออกมา
สไตล์และระดับภาษา — จับคู่เสียงเข้ากับบริบทของเนื้อหา
ทักษะที่ให้ผลตอบแทนสูงที่สุดในการเลือกเสียงไม่ใช่การเลือกเสียงที่น่าประทับใจที่สุด แต่คือการเลือกสไตล์และระดับภาษาที่ถูกต้องสำหรับบริบทการนำเสนอ — เสียงที่ผู้ชมคาดหวังและไม่เคยตั้งคำถาม คำแนะนำระบบออกแบบของ PatternFly แยกสไตล์ (ทางเลือกด้านไวยากรณ์และวากยสัมพันธ์) เสียง (บุคลิกภาพแบรนด์) และโทน (สภาวะทางอารมณ์ของผู้ใช้) ออกจากกัน และความคู่ขนานในเสียงพูดก็จับคู่ได้อย่างสะอาดหมดจด: สไตล์และระดับภาษาอยู่ฝั่งหนึ่ง โทนทางอารมณ์อยู่อีกฝั่ง หากใช้ระดับภาษาผิด แม้แต่เสียงที่สวยงามก็จะให้ความรู้สึกไม่เข้าที่
เอกสารของ Hamsa ทำให้ความแตกต่างของสไตล์เป็นรูปธรรมด้วยเหตุผลตามกรณีการใช้งานอย่างชัดเจน "การสนทนา" เป็นธรรมชาติและเป็นมิตร — เหมาะที่สุดสำหรับการบริการลูกค้าและการสนับสนุน "ผู้บรรยาย" ชัดเจนและชัดถ้อยชัดคำ — เหมาะกับการอธิบาย กรอบ "ฟังเป็นอย่างไร / เหมาะกับ" นั้นคือสิ่งที่เปลี่ยนสไตล์ให้กลายเป็นการตัดสินใจที่คุณทำได้ในไม่กี่วินาที แทนที่จะถกเถียงกันทั้งบ่าย
| ประเภทเนื้อหา | คำอธิบายสไตล์ที่แนะนำ | ทำไมจึงได้ผล |
|---|---|---|
| วิดีโออธิบายบน YouTube | การสนทนา | เป็นธรรมชาติ เป็นมิตร — ดึงผู้ชมแบบสบาย ๆ ให้อยู่ต่อ |
| การฝึกอบรมองค์กร | ผู้บรรยาย | ชัดเจน ชัดถ้อยชัดคำ — เหมาะกับการอธิบาย |
| อินโทรพอดแคสต์ | การสนทนา / การออกอากาศ | สร้างการปรากฏตัวของพิธีกรที่อบอุ่นคุ้นเคย |
| หนังสือเสียง | ผู้บรรยาย | ความชัดเจนที่คงทนตลอดการฟังเนื้อหายาว |
| โฆษณา / โปรโมชัน | การออกอากาศที่มีพลัง | ฉายความเคลื่อนไหวและการเรียกร้องให้ลงมือทำ |
ภายใต้สไตล์คือ ระดับภาษา — ทางเลือกระหว่างเป็นทางการกับไม่เป็นทางการที่เพิ่มรสชาติให้ทุกอย่างเหนือมัน แกนเป็นทางการ↔ไม่เป็นทางการของ NN/g เป็นวิธีคิดที่สะอาดที่สุด: สไตล์การสนทนาแบบเดียวกันสามารถอ่านได้เป็นพิธีกรออกอากาศที่ขัดเกลา หรือเพื่อนที่คุยกันข้ามโต๊ะ ขึ้นอยู่กับว่าคุณตั้งหมุนระดับภาษาไว้ตรงไหน ผู้บรรยายการฝึกอบรมองค์กรที่ระดับภาษาไม่เป็นทางการให้ความรู้สึกเข้าถึงได้ง่าย ส่วนผู้บรรยายคนเดียวกันที่ระดับภาษาเป็นทางการให้ความรู้สึกเหมือนสถาบัน ทั้งสองอย่างไม่ผิด — มันคือคำตอบของบรีฟที่แตกต่างกัน
มีอีกสองชั้นที่ซ้อนทับอยู่ด้านบน สำเนียงและภาษาถิ่นเป็นเกณฑ์การเลือกหลักในเช็กลิสต์ของ Hamsa และพวกมันมีน้ำหนักทางวัฒนธรรมที่ไม่มีคำอธิบายโทนใดสามารถลบล้างได้ — เสียง "อเมริกันกลาง ๆ" กับเสียง "อังกฤษ RP" สามารถมีโทน ระดับเสียง และจังหวะที่เหมือนกันทุกประการ แต่ยังคงให้ความรู้สึกแตกต่างกับผู้ชมโดยสิ้นเชิง SymTrain แนะนำตัวกรองตามกลุ่มอายุ — เด็ก ผู้ใหญ่ ผู้สูงวัย — ควบคู่ไปกับโทน เพราะอายุที่รับรู้ได้เปลี่ยนความน่าเชื่อถือหรือความเข้าถึงได้ของเสียง
คำอธิบายสไตล์ที่ถูกต้องไม่ใช่เสียงที่น่าประทับใจที่สุด — แต่คือเสียงที่ผู้ชมคาดหวังว่าจะได้ยินในช่วงเวลานั้นและไม่เคยตั้งคำถาม
ประเด็นที่คมคายที่สุดของ PatternFly คือสไตล์และโทนต้องตอบสนองต่อสภาวะทางอารมณ์ของผู้ชม ไม่ใช่ค่าตั้งต้นแบบครอบคลุมทั้งแบรนด์ เนื้อหาแก้ไขปัญหาต้องการระดับภาษาที่เป็นกลางและให้ความช่วยเหลือ ส่วนการประกาศต้องการระดับภาษาที่กระตือรือร้น บริบทกำหนดระดับภาษาทุกครั้ง และการตัดสินใจเรื่องระดับภาษาก็ไม่อยู่นิ่งเมื่อเนื้อหาของคุณเดินทาง — ระดับภาษาแบบสบาย ๆ และเป็นกันเองที่ลงตัวพอดีในภาษาอังกฤษ อาจอ่านได้เป็นการดูแคลนหรือไม่เป็นมืออาชีพในอีกตลาดหนึ่ง นั่นคือทางเลือกระดับภาษาที่ต้องยืนหยัดได้เมื่อคุณส่งเนื้อหาผ่าน AI Dubbing เข้าไปยังภาษาอื่น ซึ่งนั่นคือจุดที่วินัยชั้นถัดไปจะให้ผลตอบแทน
การซ้อนคำอธิบายเพื่อค้นหาเสียงหรือสร้างพรอมต์ที่แม่นยำ
คำศัพท์จะมีความหมายก็ต่อเมื่อคุณสามารถเปลี่ยนมันให้เป็นวิธีการที่ทำซ้ำได้ งานวิจัยสอดคล้องกันในหลักการหลัก: คำอธิบายที่ซ้อนกันชนะป้ายกำกับเดี่ยวทุกครั้ง WP SEO AI แนะนำให้รวมคำคุณศัพท์โทนทางอารมณ์อย่าง "อบอุ่น" "คมชัด" หรือ "น่าเชื่อถือ" เข้ากับรายละเอียดที่เป็นรูปธรรมเกี่ยวกับจังหวะ ความหลากหลายของระดับเสียง การก้องกังวาน และความชัดเจน เพื่อสร้างภาพเสียงที่ชัดเจน Voices.com กำหนดกระบวนการสามขั้นตอน — นิยามตัวละคร (อายุ เพศ สไตล์) ตั้งโทน แล้วเลือกคีย์เวิร์ดที่เหมาะสม นี่คือตรรกะนั้นที่แบ่งออกเป็นเจ็ดขั้นตอนที่คุณสามารถดำเนินการได้ทุกครั้ง
- นิยามเป้าหมายทางอารมณ์ ตั้งชื่อความรู้สึกที่ผู้ชมควรได้รับกลับไป — ความไว้วางใจ ความตื่นเต้น ความสงบ ทุกสิ่งที่ตามมาล้วนรับใช้การตัดสินใจเดียวนี้
- เลือกกลุ่มโทนหนึ่งกลุ่ม เลือกจากสี่กลุ่ม: สร้างความไว้วางใจ มีพลัง จริงจัง หรือใกล้ชิด ต้านความอยากที่จะผสมกลุ่มที่ขัดแย้งกัน — นั่นคือจุดที่บรีฟแตกออก
- ตั้งช่วงระดับเสียง ทุ้ม กลาง หรือสว่าง คำเดียว ไม่ใช่ย่อหน้า
- ตั้งจังหวะ มีจังหวะ กระฉับกระเฉง หรือห้วน ๆ แยกออกจากระดับเสียง
- ล็อกสไตล์และระดับภาษา การสนทนา ผู้บรรยาย หรือการออกอากาศ — แล้วเป็นทางการหรือไม่เป็นทางการ
- ซ้อนข้อมูลประชากรและสำเนียง เพิ่มกลุ่มอายุและภาษาถิ่น ในแบบที่ตัวกรองของ SymTrain และ Hamsa คาดหวัง
- ทดสอบกับตัวอย่าง 2–3 เสียง เช็กลิสต์ของ Hamsa — การออกเสียง ความชัดเจน จังหวะ โทน สำเนียง — คือประตูตรวจสอบขั้นสุดท้ายของคุณก่อนที่อะไรก็ตามจะออกใช้งาน

นี่คือสิ่งที่ชุดคำอธิบายที่เสร็จสมบูรณ์มีหน้าตาเป็นสตริงเดียว: อบอุ่น + ระดับเสียงกลาง + จังหวะมีจังหวะ + สไตล์การสนทนา + หญิง + อายุ 30 ปี + สำเนียงอเมริกันกลาง ๆ บรรทัดเดียวนั้นทำหน้าที่สองอย่าง ใส่มันลงในช่องค้นหาแล้วมันจะลดเวลาการกรองของคุณในคลังเสียงกว่า 300 เสียงให้เหลือเพียงไม่กี่ตัวเลือก ป้อนสตริงที่ซ้อนกันแบบเดียวกันเข้าไปในพรีเซ็ต TTS แล้วมันจะกลายเป็นพรอมต์สร้างเสียง วินัยของการเขียนมันครั้งเดียวคือสิ่งที่ช่วยให้คุณรอดพ้นจากการต้องนั่งฟังตัวอย่างทั้งแคตตาล็อกอีกครั้ง และเพราะรูปแบบมีความสม่ำเสมอ สตริงที่ซ้อนกันแบบเดียวกันที่คุณจะป้อนเข้าพรีเซ็ต TTS จึงสามารถส่งตรงไปยังการเรียกใช้ Voice Cloning API ได้ — บรีฟเดียว หลายปลายทาง โดยไม่ต้องแปลใหม่ระหว่างเครื่องมือ
หลุมพรางของคำอธิบาย — จุดที่การเลือกเสียงพังแบบเงียบ ๆ
โครงการเสียงส่วนใหญ่ไม่ได้ล้มเหลวในขั้นตอนการอัดเสียง แต่ล้มเหลวที่บรีฟ ในแบบที่มองไม่เห็นจนกระทั่งคุณกำลังฟังไฟล์ที่เสร็จแล้วซึ่งผิดอย่างใดอย่างหนึ่ง เหล่านี้คือรูปแบบความล้มเหลวที่ไม่ปรากฏให้เห็นจนกว่าจะแก้ไขได้ในราคาแพง
การซ้อนคำอธิบายที่ขัดแย้งกันมากเกินไป "มีพลังแต่ผ่อนคลาย" หักล้างตัวเอง — เสียงไม่สามารถวิ่งและกระซิบในเวลาเดียวกันได้ งานวิจัยของ NN/g มีประโยชน์ตรงนี้: อารมณ์ขัน ความเคารพ และความกระตือรือร้น เป็นคันบังคับที่เป็นอิสระ ดังนั้นการผสมหลายอย่างจึงใช้ได้ดี แต่บางการผสมขัดแย้งกันจริง ๆ ทางแก้คือเลือกกลุ่มโทนหลักหนึ่งกลุ่มและปรับแต่ง ภายใน มัน แทนการเอื้อมข้ามกลุ่มเพื่อหาความหลากหลายที่คุณไม่ต้องการ
การปฏิบัติกับ "เป็นธรรมชาติ" ว่าเป็นทิศทาง "เป็นธรรมชาติ" และ "น่าดึงดูด" ให้ความรู้สึกเหมือนเป็นคำสั่ง แต่มันไม่สามารถนำไปปฏิบัติได้ WP SEO AI ชี้ว่าคำครอบจักรวาลเช่นนี้ใช้ไม่ได้กับทั้งเครื่องมือ AI และนักพากย์ทางไกล เพราะมันไม่ได้ระบุมิติที่มีปฏิสัมพันธ์กันใด ๆ ทางแก้คือแทนที่คำครอบจักรวาลทุกคำด้วยชุดสี่มิติ — โทน ระดับเสียง จังหวะ สไตล์ — บวกกับข้อมูลประชากร หากคำอธิบายไม่สามารถจัดเข้าไปในถังใดถังหนึ่งเหล่านั้นได้ มันก็ไม่ใช่ทิศทาง
การสมมติว่าคำอธิบายแปลข้ามภาษาได้ โทนที่รับรู้ได้เปลี่ยนไปเมื่อคุณพากย์เป็นภาษาและวัฒนธรรมอื่น — ระดับภาษาที่อ่านได้เป็นอบอุ่นในภาษาอังกฤษอาจกลายเป็นคุ้นเคยเกินไปในที่อื่น ทางแก้คือการตรวจสอบโทนใหม่ต่อภาษาเป้าหมาย แทนการเชื่อว่าคำอธิบายต้นฉบับจะถ่ายทอดข้ามไปได้ เมื่อคุณกำลังพากย์เป็น 33 ภาษาเป้าหมาย การตรวจสอบโทนต่อภาษาไม่ใช่การขัดเงาเสริม แต่เป็นความแตกต่างระหว่างเนื้อหาที่เชื่อมโ