
ความลังเลนั้นถูกต้อง ในตอนท้ายของบทความนี้ คุณจะรู้ได้อย่างแน่นอนว่า Perchance AI text to speech ทำอะไรได้ดี ที่ไหนที่มันแตกหักเงียบ ๆ และอีก 4 ทางเลือกที่มีชื่อ ซึ่งเหมาะกับขั้นตอนการทำงานจริงของคุณ — ไม่ว่าจะเป็นการบรรยายอย่างสั้น ๆ เนื้อหา YouTube ที่เป็นตัวเงิน การเสียงพูดหลายภาษา หรือการรวมเข้าไปในผลิตภัณฑ์ที่ขับเคลื่อนด้วย API
สารบัญ
- Perchance AI Text-to-Speech ทำอะไรได้จริง (และที่ไหนที่มันหยุด)
- วิธีที่ Perchance แสดงผลเสียง — อธิบายไปป์ไลน์การสังเคราะห์
- เมื่อ Perchance TTS เป็นตัวเลือกที่ถูกต้อง (และเมื่อมันไม่สำเร็จเงียบ ๆ)
- Perchance กับ Purpose-Built TTS Platforms — ทีละคุณสมบัติ
- การเลือก TTS Tool ที่เหมาะสำหรับขั้นตอนการทำงานจริงของคุณ
- รายการตรวจสอบการตัดสินใจเพื่อเลือก TTS Tool ถัดไปของคุณ
Perchance AI Text-to-Speech ทำอะไรได้จริง (และที่ไหนที่มันหยุด)
เพื่อให้เข้าใจ Perchance AI text to speech ก่อนอื่นคุณต้องเข้าใจว่า Perchance คืออะไรในโครงสร้าง Perchance.org เป็นแพลตฟอร์มเครื่องกำเนิดที่ขับเคลื่อนโดยชุมชน — ตัวตนของมันสร้างขึ้นจากเครื่องกำเนิดข้อความสุ่ม การเขียนเรื่องราว AI และการสร้างภาพ AI คุณสมบัติ TTS เป็นด้านข้าง ไม่ใช่ยานหลัก ความจริงหนึ่งนี้อธิบายข้อจำกัดเกือบทั้งหมดที่คุณจะพบ
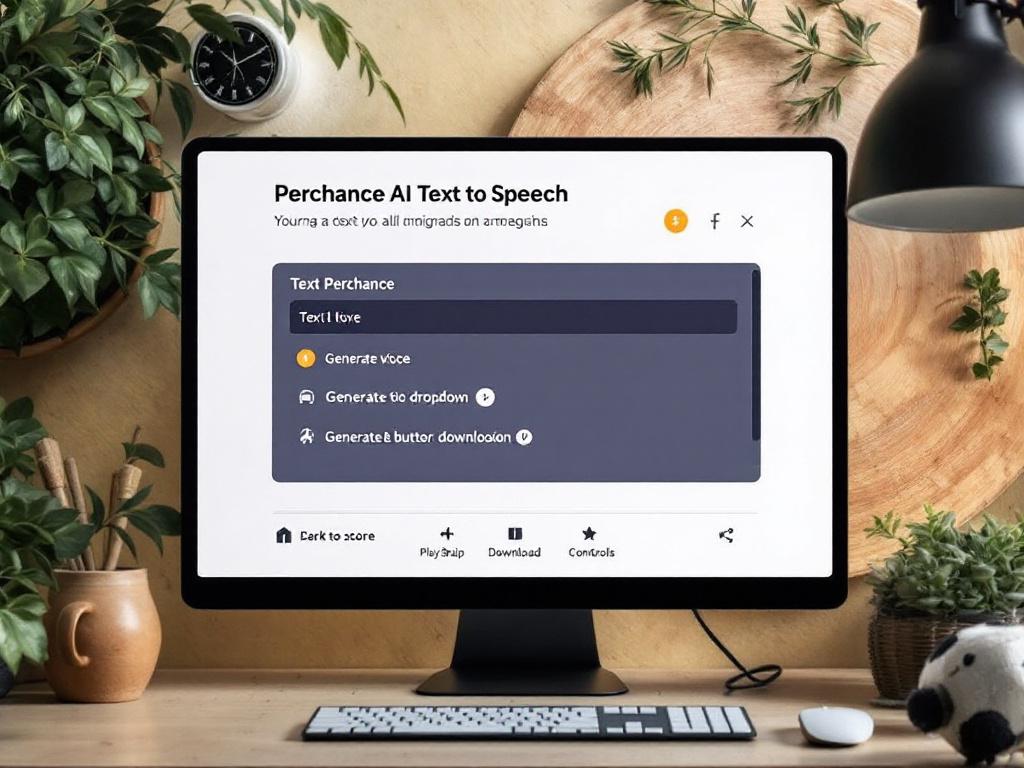
คุณสมบัติเองนั้นตรงไปตรงมา คุณวาง text เข้าไปในช่องอินพุต (โดยปกติจำกัดไว้ที่อักขระไม่กี่พันตัวต่อการสร้าง) เลือกเสียงที่ตั้งไว้ล่วงหน้าจากดรอปดาวน์ขนาดเล็กจัดกลุ่มตามภาษาและสำเนียง — English US, English UK, ภาษาอื่น ๆ ที่มีจำนวน จำกัด ที่มีความเป็นธรรมชาติจำกัด — และคลิก generate แพลตฟอร์มแสดงผลเสียงในเบราว์เซอร์โดยใช้เครื่องมือการสังเคราะห์ที่ดึงมาจาก browser/web speech APIs และแบบจำลองโอเพนซอร์สแบบบูรณาการ คุณได้รับการควบคุมการเล่นและปุ่มดาวน์โหลดสำหรับเอาต์พุต MP3 หรือ WAV มาตรฐาน ไม่จำเป็นต้องมีบัญชีสำหรับการใช้พื้นฐาน มันฟรีจริง ๆ โดยไม่มีประตูซ่อนอยู่ก่อนที่คุณจะได้ยินผลลัพธ์
นั่นคือพื้นผิว คำถามที่น่าสนใจคือสิ่งที่ Perchance TTS ไม่ทำ เพราะนั่นคือที่ที่การตัดสินใจของขั้นตอนการทำงานจริงอยู่
ไม่มีการ voice cloning — คุณไม่สามารถอัปโหลดตัวอย่างของเสียงของคุณเอง (หรือเสียงใดก็ตามที่คุณมีสิทธิ์) และให้แพลตฟอร์มทำซ้ำได้ ไม่มีการสนับสนุน SSML ซึ่งหมายถึงไม่มีการควบคุมรายละเอียดเหนือหยุดชั่วคราว การเน้น เส้นโค้งระดับเสียง หรือการออกเสียงคำที่ยาก ไม่มีไปป์ไลน์การเสียงพูดหลายภาษา — คุณไม่สามารถวาง video และรับ voiceover ที่ได้รับการแปลซึ่งซิงค์กับการจับเวลาดั้งเดิม ไม่มีการเข้าถึง API ดังนั้นการรวมแบบโปรแกรมลงในผลิตภัณฑ์หรือขั้นตอนการทำงานแบบแบตช์ของคุณเองจึงออกจากโต๊ะ ไม่มีกรอบการออกใบอนุญาตเชิงพาณิชย์ที่ชัดเจน — เงื่อนไขของ Perchance ครอบคลุมผลลัพธ์เครื่องกำเนิดอย่างกว้าง ๆ แต่ไม่ได้ให้ความรับประกันการใช้เชิงพาณิชย์ที่ชัดแจ้งซึ่งแพลตฟอร์มที่เสียเงินเผยแพร่บนหน้าราคา
ไม่มีความสอดคล้องของเสียงในโครงการยาวนาน คำนวณเสียงย่อหน้าเดียวกันสองครั้งและคุณอาจได้ลักษณะเสียงที่แตกต่างกันเล็กน้อย — ใช้ได้สำหรับการใช้งานส่วนตัว ร้ายแรงสำหรับเนื้อหาแบบแบรนด์ที่ความสอดคล้องจากตอนหนึ่งไปยังตอนหนึ่งเป็นประเด็นทั้งหมด ไม่มีการจัดการโครงการ ไม่มีประวัติเวอร์ชัน ไม่มีพื้นที่ทำงานของทีม เมื่อคุณปิดแท็บ เสียงจะหายไปเว้นแต่คุณจะดาวน์โหลด
Perchance AI voice synthesis เหมาะสำหรับการบรรยายแบบอดสมัคร: เสียง D&D ส่วนชิ้นงาน อ่านจ้อง fanfiction รายการจดหมายพิมพ์ที่คุณต้องการได้ยิน โครงงานของร่างภาพ ก่อนที่คุณจะจ้างผู้บรรยายจริง มันไม่เหมาะสำหรับเนื้อหาที่สร้างรายได้ วิดีโอแบรนด์ คำสั่งซื้อของลูกค้า หรือโครงการใดก็ตามที่ความสอดคล้องของเสียงในทั่วช่วงเวลามีความสำคัญ
หมายเหตุผู้ปฏิบัติการที่ตรงไปตรงมาเกี่ยวกับคุณภาพเสียง: เป็นหุ่นยนต์ที่ยอมรับได้ คุณรู้ว่ามันเป็นเสียงสังเคราะห์ในขณะที่คุณได้ยิน นั่นใช้ได้ดีเมื่อคุณเป็นผู้ฟังเพียงคนเดียว มันเป็นปัญหาเมื่อผู้ชมกำลังสร้างความประทับใจของแบรนด์ของคุณโดยอาศัยสิ่งที่ออกมาจากหูฟังของพวกเขา Perchance TTS ของแพลตฟอร์ม Text-to-Speech ที่ได้รับการอัปเดตแล้วในเวลาต่อมาได้ผ่านคุณภาพของหุ่นยนต์ที่ยุ่งง่านไปแล้ว Perchance TTS ยังไม่สำเร็จ และเนื่องจากมันเป็นฟีเจอร์ฟรีด้านข้างของไซต์การเขียนเรื่องราวสร้างสรรค์ มันอาจจะไม่เป็น
Perchance TTS เป็นคุณสมบัติด้านข้าง ไม่ใช่ผลิตภัณฑ์เรือธง — และความแตกต่างจะแสดงในทุกข้อจำกัดที่คุณจะพบในโครงการที่สอง
หากกรณีการใช้ของคุณคือ "ฉันต้องการได้ยินการเขียนของตัวเองอ่านออกมาเสียง ตอนนี้ ฟรี ไม่มีแรงเสียดทาน" Perchance เป็นคำตอบที่สะอาด หากกรณีการใช้ของคุณมีมิติพาณิชย์ใด ๆ เลย — แม้แต่ขนาดเล็ก — บทความส่วนที่เหลือมีอยู่เพื่อไม่ให้คุณเรียนรู้บทเรียนนั้นในแบบที่มีค่าใช้จ่าย
วิธีที่ Perchance แสดงผลเสียง — อธิบายไปป์ไลน์การสังเคราะห์
การเข้าใจวิธีที่ Perchance สร้างคำพูดทำให้ข้อจำกัดหยุดรู้สึกเหมือนเอกพจน์และเริ่มรู้สึกเหมือนโครงสร้าง นี่คือสิ่งที่เกิดขึ้นระหว่างวาง แล้วเล่น
ขั้นตอนที่ 1: อินพุต Text และ Tokenization
คุณวาง text เข้าไปในช่องอินพุต แพลตฟอร์มแบ่ง text นั้นออกเป็น tokens — คำ และหน่วยย่อย — และเตรียมไว้สำหรับแบบจำลองการสังเคราะห์ เพดาน practical โดยปกติ คือ อักขระไม่กี่พันตัวต่อการสร้าง โครงงานที่ยาวกว่านั้นต้องแบ่งเป็นชิ้นด้วยตนเอง ซึ่งเป็นสถานที่แรกที่ความสอดคล้องของเสียงเริ่มลื่นไถล ไม่มีขั้นตอนการทำงาน "อัปโหลดเอกสาร 10,000 คำและรับไฟล์เสียงต่อเนื่อง" แต่ละชิ้นเป็นเหตุการณ์การสร้างของตัวเอง
ขั้นตอนที่ 2: การเลือกเสียงจากห้องสมุดที่ตั้งไว้ล่วงหน้า
คุณเลือกจาก dropdown ของโปรไฟล์เสียงที่อัปเดตล่วงหน้าแล้ว สิ่งเหล่านี้ไม่สามารถปรับแต่งได้ พวกเขาไม่ใช่เสียงของคุณ พวกเขาไม่สามารถโคลนจากตัวอย่างที่คุณจัดเตรียม ห้องสมุดมีขนาดเล็ก — บางแห่งในช่วง 20–40 เสียงขึ้นอยู่กับสิ่งที่เปิดใช้งานในเวลาที่คุณไปเยี่ยม สำหรับการเปรียบเทียบ ElevenLabs มี 300+ เสียง และ DubSmart AI มี 300+ เสียงที่เป็นธรรมชาติ บวก voice cloning จากตัวอย่างเสียง 20 วินาที ความแตกต่างในโครงสร้างคือว่าแพลตฟอร์มปฏิบัติต่อเสียงเป็นเมนูคงที่หรือเป็นพารามิเตอร์ที่คุณควบคุม
ขั้นตอนที่ 3: Synthesis Engine ประมวลผล Tokens
แบบจำลองแปลง tokens ออกเป็น phonemes (หน่วยเสียง) จากนั้นเป็นรูปคลื่นเสียง Perchance พึ่งพาแบบจำลอง TTS โอเพนซอร์สแบบบูรณาการและ browser speech APIs เพื่อทำงานนี้ ในภาษาที่ชัดเจน: แบบจำลองกำลังคาดการณ์ เฟรมต่อเฟรม ว่าเสียงใดควรมาต่อจากข้อมูล text ที่ป้อนและเสียงที่เลือก ไม่มีชั้นอนุมานอารมณ์ที่ควรพูด และการรับรู้บริบท ขั้นต่ำ — ระบบไม่ได้รู้จริง ๆ ว่าประโยคนั้นเป็นการเสียดสี เร่งด่วน หรือเศร้า มันสร้างเอาต์พุต prosody ที่แท้จริง ซึ่งเป็นเหตุที่ข้อความยาว ๆ สามารถฟังเรียบเนียนเมื่อเทียบกับแพลตฟอร์มที่ลงทุนในการสังเคราะห์ที่สื่อสาร
ขั้นตอนที่ 4: การแสดงผลเสียงและการเล่น
รูปคลื่นถูกเข้ารหัสเป็นรูปแบบที่เล่นได้และนำเสนออุปสงค์การเล่นในเบราว์เซอร์ Latency มักจะเป็นไม่กี่วินาทีสำหรับข้อความสั้น ๆ และนานกว่าสำหรับย่อหน้าทั้งหมด ไม่มีการสตรีมแบบเรียลไทม์ ไม่มีการประมวลผลแบบแบตช์ และไม่มีคิว background — คุณรอให้การสร้างแต่ละรายการเสร็จสิ้น จากนั้นไปยังรายการถัดไป สำหรับผู้สร้างที่สร้างเสียงสำหรับโครงการวิดีโอ 20 นาที นี่คือ friction tax: chunk generate wait listen chunk again
ขั้นตอนที่ 5: ดาวน์โหลดหรือละทิ้ง
คุณสามารถดาวน์โหลดผลลัพธ์เป็น MP3 หรือ WAV ไม่มีการบันทึกโครงการภายใน Perchance — เมื่อคุณออกจากหน้า เสียงจะมีอยู่บนเครื่องของคุณเท่านั้น หากคุณหยิบมันมา และไม่มี Text to Speech API ที่จะเรียกจากแอปพลิเคชันของคุณเอง ซึ่งทำให้ Perchance ไม่เหมาะสมสำหรับนักพัฒนา หน่วยงาน และทีมใด ๆ ที่พยายามรวมเสียงลงในขั้นตอนการทำงาน workflow ของผลิตภัณฑ์
ไปป์ไลน์นั้นมีความสามารถ นอกจากนี้ยังมีความตั้งใจขั้นต่ำ — สร้างขึ้นเพื่อส่งมอบประสบการณ์ text-in, audio-out ที่เรียบง่ายสำหรับผู้ใช้ที่ไม่เป็นทางการ ทุกข้อจำกัดที่คุณอ่านข้างบนนั้นติดตามไปยังตัวเลือกการออกแบบนั้น การรู้ว่าสถาปัตยกรรมช่วยให้คุณหยุดสงสัยว่าคุณพลาดการตั้งค่าที่ซ่อนไว้ คุณไม่ได้ คุณสมบัติเหล่านั้นไม่มี
เมื่อ Perchance TTS เป็นตัวเลือกที่ถูกต้อง (และเมื่อมันไม่สำเร็จเงียบ ๆ)
คำถามถัดไปคือว่าเรื่องราวการใช้งานของคุณจะพอดีกับสิ่งที่ Perchance นำเสนอจริง ๆ หรือไม่ เมทริกซ์นี้จับคู่สถานการณ์ผู้สร้างจริงกับขอบเขต capability ของแพลตฟอร์มที่ตรงไปตรงมา
| กรณีการใช้ | Perchance Fit | ทำไมมันได้ผล / ทำไมมันแตกหัก |
|---|---|---|
| การบรรยายเรื่องราวส่วนตัว (D&D fanfic journaling) | พอดีอย่างหนาแน่น | ฟรี เร็ว คุณภาพเสียงยอมรับได้สำหรับการฟังตัวเอง |
| เร็ว 15–30 วินาทีสารคดี social clip narration | พอดีที่ยอมรับได้ | ทำได้สำหรับเนื้อหา low-stakes คาดว่าเสียงเป็นหุ่นยนต์ |
| YouTube channel ที่มีรายได้โฆษณา (ขนาดใด ๆ) | พอดีไม่ดี | ไม่มีความสอดคล้องของเสียง ความคลุมเครือด้านใบอนุญาต ผู้ชมรับรู้คุณภาพสังเคราะห์ |
| เนื้อหาหลายภาษาสำหรับผู้ชมระดับโลก | พอดีแย่มาก | ไม่มีไปป์ไลน์การเสียงพูด ไม่มีการจับคู่ภาษาพร้อมการซิงค์วิดีโอ |
| E-learning / โมดูลการฝึกอบรมในองค์กร | พอดีแย่มาก | ไม่มี SSML ไม่มีการควบคุมการออกเสียง ไม่มีใบอนุญาตขององค์กร |
| Podcast intro/outro generation | พอดีไม่ดี | ความไม่สอดคล้องกันในตอนต่าง ๆ หักการสร้างแบรนด์ |
| โครงงาน Prototype/draft ก่อนจ้างผู้บรรยาย | พอดีอย่างหนาแน่น | สมบูรณ์สำหรับดูตัวอย่าง pacing และตัวเลือก word |
| Accessibility narration สำหรับ blog ส่วนตัว | พอดีที่ยอมรับได้ | เหมาะสมหากไม่มีตัวเลือกอื่น เครื่องมือเฉพาะที่ดีกว่า |
ตารางเป็นส่วนที่ง่ายของ การตัดสินใจด้านล่างเป็นจุดที่ผู้สร้างส่วนใหญ่ล้ม
เครื่องมือทุกอย่างมี time tax ด้านบนของราคาติดป้าย Perchance ฟรี แต่ช่วงเวลาที่คุณเริ่มต่อสู้ข้อจำกัดของมัน — สร้างใหม่เพื่อความสอดคล้อง การแบ่ง text ที่ยาวเป็นชิ้น ๆ ด้วยตนเอง การทำงานรอบ ๆ ความหมายลับด้านใบอนุญาต — คุณได้ใช้เวลามากกว่า subscription รายเดือนของแพลตฟอร์มที่เสียเงินแล้ว ผู้สร้างที่ประเมินค่าเวลาของตนเองในอัตรา $40/ชั่วโมง และใช้เวลา 3 ชั่วโมงต่อสัปดาห์ต่อต้านข้อจำกัดเครื่องมือได้เผาเวลา $480/เดือนสำหรับ "บันทึก" $20/เดือนบนการสมัครสมาชิก คณิตศาสตร์เปิดเผยตัวเองในวันที่คุณจริง ๆ นั่งลง และวัด
นอกจากนี้ยังมี hidden switching cost ที่ไม่แสดงในวันแรก ผู้สร้างที่เริ่มช่อง YouTube บน Perchance สร้างผู้ชมรอบเสียงโดยเฉพาะ จากนั้นย้ายไปยังแพลตฟอร์มเชิงวิชาการ ค้นพบว่าพวกเขาต้องบันทึกใหม่ทั้งหมด — เพราะเสียงของแพลตฟอร์มใหม่จะไม่ตรงกับเสียงเก่า และไม่สามารถส่งออก Perchance's voices เป็นแบบจำลอง cloneable ได้ นี่คือ free-tool tax: ไม่ต้องจ่ายตอนนี้ เสียเงินสองเท่าต่อมา ยิ่งเร็วคุณจะเปลี่ยน ยิ่งราคาถูก migration
ค่าจริงของเครื่องมือฟรี คือต้นทุนของการสลับในวันที่มันหยุดจ่ายตัวด้วยคุณ
ไม่มีอะไรเลยที่หมายความว่า Perchance ผิดเป็นจุดเริ่มต้น หากคุณสร้างเสียงเพื่อตัวเอง สำรวจแนวคิด ทดสอบว่าย่อหน้าเสียงเหมือนไรก่อนที่จะมุ่งมั่นไปยังทิศทาง script หรือเรียกใช้โครงการสร้างสรรค์ส่วนตัว Perchance เป็นคำตอบที่ถูกต้อง อย่าพูดตัวเองเข้า tool ที่เสียเงิน ซึ่งคุณยังไม่ต้องการ
สัญญาณสามประการว่าคุณได้ outgrown Perchance TTS นั้นง่าย ประการแรก: คุณได้สร้างข้อความเดียวกันใหม่สามครั้งขึ้นไปเพื่อความสอดคล้อง ประการที่สอง: คุณต้องการภาษาที่สอง ประการที่สาม: มีคนจ่ายเงินให้คุณสำหรับเอาต์พุต — โดยตรงผ่านงานลูกค้า หรือโดยอ้อมผ่านเนื้อหาที่เป็นตัวเงิน ตีตัวเลือกใด ๆ ในสามตัวเลือกนั้น และการคำนวณจะพลิกกลับ
Perchance กับ Purpose-Built TTS Platforms — ทีละคุณสมบัติ
เมื่อคุณผ่านเกณฑ์สมัครเล่น คำถามก็จะกลายเป็นแพลตฟอร์มเฉพาะที่ไหนพอดีกับขั้นตอนการทำงานของคุณ นี่คือวิธีที่ Perchance เปรียบเทียบกับทางเลือกสี่ที่เกี่ยวข้องมากที่สุดในความสามารถ
| ความสามารถ | Perchance | ElevenLabs | DubSmart AI | Murf.ai |
|---|---|---|---|---|
| ขนาดห้องสมุดเสียง | ~20–40 presets | 300+ เสียง | 300+ เสียง | 200+ เสียง |
| Voice cloning | ไม่พร้อมใช้งาน | พร้อมใช้งาน (จ่าย) | 20-วินาที sample | Enterprise tier |
| ภาษาต้นฉบับ | จำกัด | 30+ | 60+ | 20+ |
| ภาษา dubbing เป้าหมาย | ไม่มี | TTS เท่านั้น | 33 | จำกัด |
| API access | ไม่พร้อมใช้งาน | พร้อมใช้งาน | TTS Cloning Dubbing | จำกัด |
Rask.ai นั่งในเลน separate ที่มูลค่า noting: ~100+ เสียง cloning จำกัด 130+ ภาษา source/target สำหรับการ dubbing API access จำกัด และ dubbing-first workflow มากกว่า TTS suite เต็ม มันถูกรวมไว้ในบล็อกการตัดสินใจของหัวข้อถัดไปเพราะมันให้บริการโปรไฟล์ผู้ซื้อที่เฉพาะเจาะจงอย่างสะอาด
ส่วนสำคัญที่สองของการเปรียบเทียบครอบคลุมหลักการพาณิชย์ที่ตัดสินใจว่าแพลตฟอร์มสามารถดำเนินงานการผลิต
| Platform | Free Tier | Commercial Licensing | Primary Use Case |
|---|---|---|---|
| Perchance | ใช่ ไม่มีบัญชี | ไม่ชัดเจน | Hobby narration |
| ElevenLabs | ~10k chars/mo | ชัดเจน (paid tiers) | Audiobook/narration |
| DubSmart AI | Credit-based free tier | ชัดเจน (all paid tiers) | Video localization & dubbing |
| Murf.ai | จำกัด | ชัดเจน | E-learning / corporate |
| Rask.ai | จำกัด | ชัดเจน | Video dubbing |
ความแตกต่างของโครงสร้างสำคัญมากกว่าแถวแต่ละแถว Perchance เป็นแพลตฟอร์มการเขียนเรื่องราว creative พร้อม TTS เป็นคุณสมบัติ อีกสี่เป็นแพลตฟอร์มเสียงหรือการเสียงพูดเฉพาะ นี่ไม่ใช่การต่อสู้ที่เป็นธรรมชาติเกี่ยวกับความสามารถ — มันคือคำถามว่าคุณต้องการมีดสวิสแห่งกรรม (Perchance) หรือเครื่องมือเฉพาะ (ทั้งหมด)
ช่องว่าง voice cloning เป็นเส้นแบ่ง sharpest DubSmart AI ต้องการเพียง 20 วินาทีของเสียง clone เสียง — ผู้แข่งขันมักต้องการหนึ่งถึงห้านาที และ Perchance ไม่ได้ clone ใด ๆ เลย พื้นสูง 20 วินาทีมีความสำคัญเพราะหมายความว่าคุณสามารถ clone เสียงจากคลิปที่ผู้สร้างเกือบทุกคนมีอยู่แล้ว: intro podcast voiceover YouTube memo โทรศัพท์ friction ของการสร้างโปรไฟล์เสียงที่ใช้ได้ลดลงเป็นศูนย์เกือบ
Multilingual reach เป็น structural gap ที่สอง DubSmart 60-source-to-33-target language pipeline และ Rask.ai broader dubbing range มีอยู่เพราะสถาปัตยกรรมทั้งหมดของพวกเขาสร้างขึ้นรอบการแปล plus voice sync — รับเสียงต้นฉบับ สร้าง translated script สร้าง speech ใหม่ในภาษา target language จัดตำแหน่งให้กับการจับเวลา video ของต้นฉบับ Perchance ไม่มี feature category เทียบเท่า หากโครงการเนื้อหาของคุณรวมถึงผู้ชมที่ไม่ใช่ภาษาอังกฤษใด ๆ นี่ไม่ใช่ "nice to have" — มันคือจุดทั้งหมด คุณสามารถอ่านเพิ่มเติมเกี่ยวกับวิธีที่ไปป์ไลน์ประเภทนี้ทำงานได้ที่ AI Dubbing
API access เป็น divider ที่สาม และเป็นบรรทัด hard DubSmart สำหรับนักพัฒนา และหน่วยงาน มี three distinct APIs: Text to Speech Voice Cloning และ AI Dubbing ElevenLabs มี TTS API อันสมบูรณ์ที่ใช้กันอย่างแพร่หลายในการผลิต Perchance ไม่มี หากคุณต้องการ access แบบโปรแกรม — รวมเสียงเข้าไปในผลิตภัณฑ์ของคุณเอง batch-process เนื้อหากลับคืน หรือ pipe TTS ลงใน CMS workflow — Perchance ถูกไม่ปลอดภัยทันที
มี subtle trap ภายในการเปรียบเทียบ free-tier มี free access ทั้งห้า platforms แต่ free tier ของ Perchance เป็น entire product ในขณะที่ free tiers ของ paid platforms เป็นตัวอย่างที่ออกแบบมาให้แสดง upgrade นั่นฟังดูเหมือน Perchance advantage จนกว่าคุณจะตระหนักว่า free tiers ของแพลตฟอร์มที่จ่ายค่าอยู่เพราะพวกเขาคาดหวังว่าคุณจะ upgrade — ซึ่งหมายความว่าผลิตภัณฑ์ถูกสร้างมาเพื่อ scale นอกเหนือ free tier Perchance's free experience เป็น ceiling ไม่ใช่ floor
Perchance TTS เป็นคุณสมบัติสะดวกสบายภายในสนามเด็กเล่นการเขียนเรื่องราว creative — ไม่ใช่แพลตฟอร์มที่คุณสร้าง content business ด้านบนของ

การเลือก TTS Tool ที่เหมาะสำหรับขั้นตอนการทำงานจริงของคุณ
การเลือก tool ไม่ใช่ exercise ในการจัดอันดับ มันเป็น fit exercise บล็อกการตัดสินใจห้าบล็อกนี้จัดระเบียบตามโปรไฟล์ผู้อ่าน ไม่ใช่ตามความชอบของผู้ขาย — เลือกสิ่งที่อธิบาย six months ถัดไปของคุณ และหยุดอ่าน others
เลือก ElevenLabs หากคุณกำลังสร้างเนื้อหา audiobook หรือ narration-heavy
- ดีที่สุดสำหรับ: Solo audiobook narrators fiction podcasters premium long-form content creators ที่ต้องการคุณภาพเสียงภาษาอังกฤษธรรมชาติมากที่สุดที่มีอยู่ในตลาด
- ทำไมมันชนะ: ElevenLabs สร้างชื่อเสียงโดยเฉพาะอย่างยิ่งบนความเป็นจริงอารมณ์ใน synthesized speech — โดยเฉพาะสำหรับ long-form English narration Voice cloning เป็นผู้ใหญ่ เป็นเอกสาร และผลิต audio ที่สามารถปกป้องได้ในหลาย ๆ ชั่วโมง API เป็น production-grade และใช้กันอย่างแพร่หลาย
- Cost framing: Free tier ครอบคลุมประมาณ 10k characters ต่อเดือน paid plans โดยปกติ range จากประมาณ $5/เดือน (Starter) ถึง $99+/เดือน (Pro) พร้อม enterprise pricing ด้านบน ROI ที่ดีที่สุดเมื่อเนื้อหาของคุณ voice-quality-sensitive และ English-dominant
เลือก DubSmart AI หากคุณเป็น video creator ไปหลายภาษา
- ดีที่สุดสำหรับ: YouTubers ขยายไป global audiences marketers localizing video campaigns course creators dubbing เข้า multiple languages podcasters cloning เสียงของตัวเองสำหรับ translated episodes และ developers รวม TTS cloning หรือ dubbing เข้า products ของตัวเองผ่าน API
- ทำไมมันชนะ: แพลตฟอร์มถูก built เป็น end-to-end localization pipeline — อัปโหลด video รับ dubbed version ใน 33 target languages ใด ๆ พร้อม optional voice cloning จาก 20-วินาที sample นอกเหนือจาก AI Dubbing และ Voice Cloning workspace bundles Text to Speech Speech to Text Speech Separator AI image generator และ Image to Video tools ซึ่งหมายความว่า entire content workflow อยู่ใน place เดียวแทน fragmenting ขึ้น four subscriptions Credit-based pricing พร้อม rollover หมายถึง unused capacity ไม่หายไป ท้ายของเดือน Developers สามารถตี platform programmatically ผ่าน AI Dubbing API
- Cost framing: Free tier พร้อม starter credits paid tiers scale พร้อม usage และ enterprise plans พร้อมสำหรับ high-volume teams ROI ที่ดีที่สุดเมื่อ localization หรือ voice cloning เป็นหลัก strategy เนื้อหา — และ especially strong เมื่อ you'd otherwise จ่ายสำหรับ dubbing TTS และ cloning เป็น subscriptions สามตัวแยกกัน
เลือก Murf.ai หากคุณผลิต e-learning หรือ corporate training
- ดีที่สุดสำหรับ: Instructional designers L&D teams corporate training video producers และ HR communications teams ที่ต้องการ presentation-style narration พร้อม template support และ slide synchronization
- ทำไมมันชนะ: Strong template library slide-sync features และ AI avatars สร้างอยู่โดยเฉพาะสำหรับ training content ผลิตภัณฑ์ shape รอบ corporate workflow แทนที่จะเป็น entertainment — pacing clarity และ instructional tone มาก่อน
- Cost framing: Plans โดยปกติ run ประมาณ $12 ถึง $96 ต่อเดือนต่อผู้ใช้ พร้อม enterprise pricing สำหรับทีม ROI ที่ดีที่สุดเมื่อคุณผลิต structured training modules ในปริมาณ
เลือก Rask.ai หากการ dubbing เป็น only need และ language breadth ของเรื่อง
- ดีที่สุดสำหรับ: Localization-first creators ผลิต video content สำหรับ niche language markets โดยเฉพาะเมื่อคุณต้องการ reach ภาษาที่แพลตฟอร์มเล็ก ๆ ไม่รองรับ
- ทำไมมันชนะ: Dubbing-focused workflow พร้อม very broad language support — 130+ languages บน dubbing side ซึ่ง wider กว่า competitors มากที่สุด Streamlined หากคุณไม่ต้องการ TTS cloning หรือ asset generation นอกเหนือจาก dubbing pipeline
- Cost framing: Pay-per-minute model — predictable สำหรับ batch dubbing jobs และ easy to forecast กับ campaign budget
ค้างบน Perchance TTS หากคุณเป็น hobbyist ที่มี zero monetization plans
- ดีที่สุดสำหรับ: Personal narration projects draft scripts ก่อนจ้าง voice actor exploratory creative work D&D session prep accessibility narration สำหรับ personal blog
- ทำไมมันชนะ: ฟรีจริง ๆ ไม่ต้องมีบัญชี ไม่มี commitment ไม่มี upsell pressure คุณได้สิ่งที่คุณมา นั่นใน under นาที
- Cost framing: $0 ในดอลลาร์ — แต่ factor ในเวลา cost ของ regenerating passages manually chunking text ยาว และ eventually re-recording everything เมื่อคุณ outgrow มัน สำหรับ right user tradeoff ที่ถูกต้องใจ สำหรับ wrong user มันเป็น invisible debt
คำถามผิด คือ "เครื่องมือไหนดีที่สุด" คำถามที่ถูกต้องคือ "เครื่องมือไหนที่จับคู่ 6 เดือนถัดไปของขั้นตอนการทำงาน" หากคุณจ่ายอายุขั้ว multilingual video คำตอบคือ DubSmart หรือ Rask หากคุณบันทึก long-form English narration คำตอบคือ ElevenLabs หากคุณสร้าง corporate training คำตอบคือ Murf หากไม่มีอะไรเลยนั่นอธิบายคุณ Perchance ก็ดี — จนกว่ามันจะไม่เป็น
การเลือก tool ไม่ใช่เกี่ยวกับ features มันเกี่ยวกับ workflow fit — แพลตฟอร์มที่มี 500 features ไร้ประโยชน์หากคุณสมบัติ 499 ช้าลง

รายการตรวจสอบการตัดสินใจเพื่อเลือก TTS Tool ถัดไปของคุณ
Frameworks เอาชนะ opinions ทำ 4 phases นี้เป็นลำดับและคุณจะมี working tool decision ก่อน Monday ถัดไป — โดยไม่อ่าน review อื่น
Phase 1: Map Your Real Constraints (Before Looking at Any Tool)
- ระบุ primary content format ของคุณ เอาต์พุตของคุณคือ written narration video podcast audio หรือ training material หรือ format แต่ละอันมี optimal tool ต่างกัน และเริ่มต้นจาก format ป้องกัน getting sold ที่ features คุณจะไม่ใช้
- ตัดสินใจหากการ voice cloning เป็น mandatory หรือ optional หากแบรนด์ของคุณขึ้นอยู่กับเสียง specific — yours หรือ hired talent's — คุณต้อง cloning หากเสียง natural ใด ๆ ที่ใช้ได้ preset library พอ และ cheaper
- คาดการณ์ language needs ของคุณสำหรับ 6 เดือนถัดไป หากคุณจะต้องการภาษา second rule out ใด ๆ platform โดยไม่มี dubbing ตอนนี้ สลับต่อมา costs มากกว่า choosing ถูก วันนี้ เพราะ piece ทั้งหมดของเนื้อหา already produced ต้อง reconciled กับ tool ใหม่
- กำหนด budget ceiling — รวม free option "Free" เป็น budget ที่ถูกต้อง แต่เป็น honest เกี่ยวกับว่า free-tier limits จะกลายเป็น blocker ภายในเดือน free tool ที่ costs คุณ 10 ชั่วโมง friction ต่อเดือนไม่เป็น actually ฟรี
Phase 2: Pressure-Test a Shortlist (Not a Long List)
- สร้าง 200-word script เดียวกัน ใน 3 platforms ใช้ Perchance บวก 2 paid alternatives บน free tiers ของพวกเขา ฟังด้วย headphones ไม่ใช่ laptop speakers — ความแตกต่างในคุณภาพระหว่าง platforms ไม่มองเห็น ได้ บนเสียง audio ไม่ดี
- ทดสอบ worst-case sentence รวม proper noun acronym และ number — สำหรับ example: "Visit our 2025 Q3 launch at NVIDIA headquarters in Santa Clara" นี่คือ where weak TTS engines collapse ออน pronunciation และ where strong ones พิสูจน์ตัวเองได้
- ลองทดสอบ multilingual หากเกี่ยวข้อง ใช้ paragraph หนึ่ง และพยายาม dub มันลงใน target language นี่ notes ที่ tools ให้ capability นี้ และ which ones actually produce listenable output
- Time ว่า test แต่ละตัว takes นาน Workflow friction ไม่มองเห็น ได้ จนกว่าคุณ