
คุณมีไอเดียเพลงที่ทำค้างไว้ครึ่งทาง — อาจจะเป็นแฟนด้บ มีมเอดิท หรือคัฟเวอร์ร้องเพลง — และคุณต้องการเสียง Hatsune Miku ที่สดใส โปร่งเบา และเป็นเอกลักษณ์ไม่อาจเข้าใจผิดมาช่วยขับเคลื่อนมัน แต่เส้นทางไปสู่จุดนั้นกลับเต็มไปด้วยตัวเลือกแย่ๆ ซอฟต์แวร์ Vocaloid และ Synthesizer V อย่างเป็นทางการต้องเสียเงินและต้องมานั่งเรียนรู้ทีละโน้ต เว็บไซต์ "เสียง Miku ฟรี" ที่คุณเจอก็ให้เสียงที่แบนราบและเพี้ยนคีย์ และเครื่องมือ AI ทั่วไปก็ฟังดูเหมือนหุ่นยนต์หรือไม่ก็ตกอยู่ในเขตลิขสิทธิ์ที่คลุมเครือ เวิร์กโฟลว์ miku voice generator ที่ถูกต้องจะตัดผ่านปัญหาทั้งหมดนั้นได้ แต่จะทำได้ก็ต่อเมื่อคุณเข้าใจจุดเสียดทานที่แท้จริงสองอย่างก่อน นั่นคือ ความสมจริง (ได้สิ่งที่ฟังออกว่าเป็น "Miku" จริงๆ ไม่ใช่แค่คลิป TTS เสียงแหลม) และความถูกต้องตามกฎหมาย (รู้ว่าคุณได้รับอนุญาตให้เผยแพร่สิ่งที่คุณสร้างหรือไม่)
คู่มือฉบับนี้จะให้เส้นทางที่ชัดเจนและใช้งานได้จริงแก่คุณ — เส้นทางกฎหมายที่คุณข้ามไม่ได้ วิธีเลือกระหว่างการเลือกเสียงกับการโคลนเสียง ความแตกต่างระหว่างเอาต์พุตการพูดกับการร้อง วิธีปรับโทนเสียงที่เป็นเอกลักษณ์ และวิธีส่งออกเสียงที่คุณใช้งานได้จริง ไม่มีการโฆษณาเกินจริง มีแค่วิธีการที่ใช้งานได้สำหรับการสร้างเสียง AI Miku ที่ทนทาน

สารบัญ
- Vocaloid กับ AI Voice Generator: เส้นทางไหนเหมาะกับโปรเจกต์ Miku ของคุณ
- เส้นกฎหมายและจริยธรรมก่อนที่คุณจะสร้างแม้แต่โน้ตเดียว
- การสร้างเสียง Miku ของคุณใน DubSmart AI: ทีละขั้นตอน
- ปรับเสียงที่เป็นเอกลักษณ์: พิตช์ โทน และลักษณะเสียงร้อง
- จากการพูดสู่การร้อง: เปลี่ยนเสียงที่สร้างขึ้นให้เป็นแทร็กเสียงร้อง
- การส่งออก การแปลให้เข้ากับท้องถิ่น และการขยายขนาดเนื้อหาสไตล์ Miku ของคุณ
- เช็กลิสต์ก่อนเริ่มสร้างเสียง Miku ของคุณ
- คำถามที่พบบ่อย
Vocaloid กับ AI Voice Generator: เส้นทางไหนเหมาะกับโปรเจกต์ Miku ของคุณ
มีเส้นทางสองทางที่แตกต่างกันอย่างแท้จริงในการสร้างเสียงสไตล์ Miku และการเลือกผิดทางก็เสียเวลาไปหลายชั่วโมง ตัวเลือกของคุณขึ้นอยู่กับว่าคุณกำลังสร้างอะไรทั้งหมด
เส้นทาง A — ซอฟต์แวร์สังเคราะห์เสียงร้องที่มีลิขสิทธิ์ (Vocaloid / Synthesizer V) Vocaloid สังเคราะห์เสียงร้องโดยรวมตัวอย่างเสียงที่บันทึกไว้ล่วงหน้าจากนักพากย์เข้ากับทำนอง และ เนื้อร้องที่ผู้ใช้ป้อนเข้าไป นั่นทำให้มันเป็นเอ็นจิ้นร้องเพลงที่ขับเคลื่อนด้วยข้อความและโน้ต ไม่ใช่เครื่องมือแปลงข้อความเป็นเสียงพูด คุณป้อนโน้ตทีละตัว จากนั้นปรับหน่วยเสียงและไดนามิกด้วยมือ การสังเคราะห์แบบดิบเป็นเพียงการผ่านครั้งแรกเท่านั้น — การปรับแต่งอย่างละเอียดเป็นสิ่งจำเป็นเพื่อให้ได้เอาต์พุตที่น่าเชื่อถือ ตามที่ บทเรียนการสร้าง VSynth และ Vocaloid เน้นย้ำซ้ำๆ ข้อดีคือการควบคุมทำนองได้อย่างสมบูรณ์ภายในเอดิเตอร์เดียว งานวิจัย VOCALOID:AI ของ Yamaha ระบุว่าระบบสมัยใหม่ใช้โมเดล machine-learning ที่ฝึกบนชุดข้อมูลเสียงขนาดใหญ่เพื่อสร้างโทนเสียงที่เป็นธรรมชาติมากกว่าเอ็นจิ้นแบบ concatenative รุ่นเก่า ตาม ภาพรวมการสังเคราะห์เสียงด้วย AI ของ Yamaha
เส้นทาง B — AI voice generators (TTS + การโคลนเสียง) สิ่งเหล่านี้มุ่งเน้นที่การออกเสียงและจังหวะของคำพูด และไม่รองรับการควบคุมพิตช์ทางดนตรีโดยกำเนิด หากต้องการร้อง คุณต้องส่งเอาต์พุตผ่านเครื่องมือแก้ไขพิตช์อย่าง DAW หรือ Melodyne ข้อแลกเปลี่ยนคือความเร็ว: ไม่ต้องป้อนโน้ต โคลนได้เร็วจากเสียงอ้างอิงสั้นๆ และให้เอาต์พุตหลายภาษาได้ทันที

| เกณฑ์ | Vocaloid / Synth V | AI TTS ทั่วไป | การโคลนเสียงด้วย AI |
|---|---|---|---|
| ค่าใช้จ่ายโดยทั่วไป | ใบอนุญาตแบบเสียเงิน | ฟรีถึงเสียเงิน | ฟรีถึงเสียเงิน |
| ความยากในการเรียนรู้ | สูง | ต่ำ | ต่ำ–ปานกลาง |
| การควบคุมพิตช์โดยกำเนิด | มี | ไม่มี (ต้องใช้ DAW) | ไม่มี (ต้องใช้ DAW) |
| เอาต์พุตการพูด | จำกัด | มี | มี |
| การตั้งค่าก่อนได้เสียง | ทำนอง + เนื้อร้อง + การปรับแต่ง | พิมพ์ข้อความ | อ้างอิง 20 วินาที |
(ค่าใช้จ่าย ความยากในการเรียนรู้ การร้องเพลง และการตั้งค่า อ้างอิงจากคำอธิบายทางเทคนิคของ "Vocaloid" ใน Wikipedia และ บทเรียนคัฟเวอร์ VSynth; ความชัดเจนเรื่องการใช้งานเชิงพาณิชย์อ้างอิงจาก Crypton/Vocaloid Wiki และ Berkeley Technology Law Journal ไม่มีคอลัมน์คำตัดสิน — ตัวเลือกที่ถูกต้องขึ้นอยู่กับกรณีการใช้งานของคุณ)
แล้วเส้นทางไหนเหมาะกับคุณ? หากคุณต้องการประโยคพูดที่รวดเร็ว — มีม แฟนด้บบทสนทนา หรือคลิปเสียงสั้นๆ — เลือก AI Text to Speech มันเป็นเส้นทางที่เร็วที่สุดสู่เสียงที่ใช้งานได้ และคุณจะได้คลิปภายในไม่ถึงหนึ่งนาที หากคุณกำลังผลิตคัฟเวอร์ร้องเต็มเพลงและต้องการควบคุมทุกโน้ต เส้นทาง Vocaloid หรือ Synthesizer V ที่มีลิขสิทธิ์จะให้ความแม่นยำนั้นแก่คุณ แลกกับเส้นทางการเรียนรู้ที่ชันกว่า
หากคุณต้องการความเร็ว บวกกับ โทนเสียงที่กำหนดเอง — เช่น เสียงที่สดใสกว่าหรือเป็นเอกลักษณ์กว่าที่ไลบรารีมาตรฐานมีให้ — เวิร์กโฟลว์การโคลนเสียงคู่กับ DAW สำหรับพิตช์คือทางสายกลางของคุณ คุณโคลนเสียงอ้างอิงที่สดใส สร้างประโยคพูดได้เร็ว จากนั้นแมปพิตช์ใน DAW ของคุณเพื่อการร้อง
ข้อแลกเปลี่ยนที่ตรงไปตรงมาคือ: เส้นทางที่เร็วที่สุดมักไม่ใช่เส้นทางที่แม่นยำทางดนตรีที่สุด Vocaloid ให้การควบคุมระดับโน้ตแก่คุณแต่ต้องอาศัยความอดทน AI generators ให้เอาต์พุตทันทีแต่ทิ้งงานพิตช์ให้คุณทำเองภายหลัง ยังมีความแตกต่างเรื่องทรัพย์สินทางปัญญาที่ซ่อนอยู่เบื้องหลังทั้งหมดนี้ด้วย — เอกสารของ Crypton แยกลิขสิทธิ์ของชื่อ Miku และภาพมาสคอตออกจากเอาต์พุตเสียงร้องที่สังเคราะห์ขึ้น การแยกนั้นมีความสำคัญอย่างมหาศาลต่อสิ่งที่คุณสามารถเผยแพร่ได้ และเป็นหัวข้อของส่วนถัดไป
เส้นทางที่เร็วที่สุดสู่เสียงสไตล์ Miku มักไม่ใช่เส้นทางที่สมจริงที่สุด — จับคู่เครื่องมือกับว่าคุณกำลังพูดหรือร้อง
เส้นกฎหมายและจริยธรรมก่อนที่คุณจะสร้างแม้แต่โน้ตเดียว
นี่คือส่วนที่ครีเอเตอร์ส่วนใหญ่ข้ามไปและมาเสียใจภายหลัง ก่อนที่คุณจะแตะ miku voice generator คุณต้องเข้าใจว่าคุณได้รับอนุญาตให้ทำอะไร — และกฎเหล่านี้เฉพาะเจาะจงกว่าคำว่า "เนื้อหาแฟนทำได้ไม่มีปัญหา"
อาร์ตตัวละครและเสียงได้รับอนุญาตต่างกัน Crypton Future Media นำใบอนุญาต Creative Commons Attribution–NonCommercial 3.0 (CC BY-NC 3.0) มาใช้สำหรับภาพประกอบตัวละคร Piapro ดั้งเดิมในปี 2012 ตาม หน้า Hatsune Miku อย่างเป็นทางการของ Crypton และ ข้อกำหนดใบอนุญาต Piapro ใบอนุญาตนั้นครอบคลุม ภาพ สำหรับการใช้งานที่ไม่ใช่เชิงพาณิชย์พร้อมการให้เครดิต มันไม่ใช่สิทธิ์เหมารวมในการเลียนแบบหรือสร้างรายได้จากเสียงของเธอด้วย AI เชิงพาณิชย์ ใบอนุญาตอาร์ตและเสียงเป็นคำถามที่แยกกัน
ใบอนุญาต Piapro ครอบคลุมอะไรจริงๆ มันใช้กับตัวละครหลักหกตัว — Hatsune Miku, Kagamine Rin, Kagamine Len, Megurine Luka, MEIKO และ KAITO ภาพประกอบดั้งเดิมของพวกเขาอาจถูกคัดลอก ดัดแปลง และเผยแพร่เพื่อการใช้งานที่ไม่ใช่เชิงพาณิชย์ได้ โดยมีเงื่อนไขว่าคุณต้องใส่บรรทัดเครดิตที่กำหนด เช่น "Hatsune Miku, © Crypton Future Media, Inc. 2007, licensed under CC BY-NC" ตาม คำถามที่พบบ่อยเกี่ยวกับใบอนุญาต Piapro ข้ามการให้เครดิตไปแล้วคุณก็จะตกอยู่นอกใบอนุญาต
ใบอนุญาตซอฟต์แวร์ Character Vocal Series มีกฎของตัวเอง ภายใต้ใบอนุญาต CV Series ของ Crypton ผู้ใช้อาจสังเคราะห์เสียงร้องเพื่อการใช้งานเชิงพาณิชย์ และ ไม่ใช่เชิงพาณิชย์ได้ — แต่มีข้อจำกัดที่เข้มงวด คุณไม่สามารถสร้างเนื้อร้องที่ดูหมิ่นหรือรบกวนจิตใจได้ คุณไม่สามารถเผยแพร่เพลงเชิงพาณิชย์ที่ทำการตลาดอย่างชัดเจนว่า "ขับร้องโดยตัวละคร" ได้ และคุณไม่สามารถนำภาพมาสคอตไปวางบนผลิตภัณฑ์เชิงพาณิชย์โดยไม่ได้รับความยินยอมจาก Crypton ได้ ตามที่สรุปไว้โดย Vocaloid Wiki ข้อจำกัด "ขับร้องโดยตัวละคร" ทำให้หลายคนสะดุด ที่คิดว่าเอาต์พุตเสียงร้องใดๆ ก็ใช้ได้ทั้งหมด
การโคลนเสียงจริงทำให้เกิดกฎหมายในส่วนที่แตกต่างไปอย่างสิ้นเชิง การวิเคราะห์ทางกฎหมายจาก Skadden, Arps, Slate, Meagher & Flom LLP อธิบายว่าลิขสิทธิ์ของรัฐบาลกลางคุ้มครองการบันทึกเสียงที่ตายตัว แต่ไม่คุ้มครองคุณสมบัติเชิงนามธรรมของเสียง — เอกลักษณ์ทางเสียงตกอยู่ภายใต้กฎหมายสิทธิ์ในการเผยแพร่ภาพลักษณ์ระดับรัฐและกฎหมายสัญญาแทน ทีมงานของบริษัทด้านเสียง Respeecher กล่าวอย่างตรงไปตรงมาว่า: "คุณไม่สามารถจดลิขสิทธิ์เสียง AI แบบดิบได้… อย่างไรก็ตาม หากมันฟังดูเหมือนคนจริง คุณก็ยังคงไม่สามารถใช้มันได้โดยไม่ได้รับอนุญาตเนื่องจากสิทธิ์ในการเผยแพร่ภาพลักษณ์ของพวกเขา" โดยทั่วไปไฟล์เสียง AI แบบดิบจะไม่สามารถจดลิขสิทธิ์ได้เพราะขาดการประพันธ์โดยมนุษย์ — แต่หากมันฟังดูเหมือนบุคคลจริงเฉพาะเจาะจง สิทธิ์ในการเผยแพร่ภาพลักษณ์ของพวกเขาก็ยังคงควบคุมการใช้งานของมัน
"สไตล์ Miku" เทียบกับการโคลนโดยตรงเป็นเส้นที่ปลอดภัยกว่า การฝึกบนข้อมูลที่มีลิขสิทธิ์ ไม่ใช่ของคนดัง จะสร้างเสียง "ใหม่" ซึ่งสิทธิ์ขึ้นอยู่กับสัญญาการอนุญาตใช้ข้อมูลแทนเอกลักษณ์ของบุคคลเฉพาะเจาะจง ตาม Berkeley Technology Law Journal การสร้างเสียงสังเคราะห์สดใสที่ ได้แรงบันดาลใจจาก Miku แบบดั้งเดิมจะทำให้คุณอยู่บนพื้นฐานที่ป้องกันได้มากกว่าการโคลน voicebank อย่างเป็นทางการโดยตรง
การสร้างรายได้คือเส้นแบ่งที่ชัดเจน เนื้อหาแฟนที่ไม่ใช่เชิงพาณิชย์ภายใต้ CC BY-NC นั้นกว้างขวางและใจกว้าง ทันทีที่คุณก้าวข้ามไปสู่การใช้งานเชิงพาณิชย์ — ขายผลิตภัณฑ์ ทำแคมเปญหารายได้ — คุณต้องได้รับอนุญาตแยกต่างหากจาก Crypton นั่นคือจุดตัดสินใจที่ต้องวางแผนล่วงหน้า
แนวทางที่ป้องกันได้นั้นตรงไปตรงมา: สร้างเสียงสดใสที่ได้แรงบันดาลใจจาก Miku แบบดั้งเดิมสำหรับงานแฟนที่ไม่ใช่เชิงพาณิชย์ ให้เครดิตอาร์ตตัวละครอย่างเหมาะสม และขอใบอนุญาตก่อนการเผยแพร่เชิงพาณิชย์ใดๆ
ความสามารถทางเทคนิคไม่ใช่การอนุญาตทางกฎหมาย — เครื่องมือที่ให้คุณโคลนเสียงไม่ได้บอกอะไรเลยเกี่ยวกับว่าคุณได้รับอนุญาตให้เผยแพร่มันหรือไม่
การสร้างเสียง Miku ของคุณใน DubSmart AI: ทีละขั้นตอน
เมื่อรากฐานทางกฎหมายเรียบร้อยแล้ว นี่คือเวิร์กโฟลว์ miku voice generator ที่แท้จริงภายใน DubSmart AI ตั้งแต่การสร้างบัญชีไปจนถึงคลิปที่พรีวิวแล้ว ประเด็นทั้งหมดคือการทดสอบก่อนใช้จ่าย ดังนั้นแต่ละขั้นตอนจึงปกป้องเวลาและเครดิตของคุณ

1. สร้างบัญชีและเลือกระดับฟรี เริ่มต้นที่ระดับฟรีเพื่อให้คุณทดลองได้ก่อนใช้จ่ายอะไร แพลตฟอร์มทำงานบนโมเดลที่อิงเครดิตพร้อมเครดิตทบยอด ซึ่งหมายความว่าเครดิตที่ไม่ได้ใช้จะไม่หายไปเมื่อสิ้นรอบการเรียกเก็บเงิน — มันจะยกยอดไป ดังนั้นการทดสอบในช่วงต้นจะไม่ทำให้คุณเสียเปรียบในภายหลัง
2. เลือกเครื่องมือของคุณ: Text to Speech หรือ Voice Cloning ใช้ Text to Speech สำหรับประโยคพูดสไตล์ Miku ที่รวดเร็ว — บทสนทนา การอ่านมีม เนื้อหาแฟนที่มีเสียงพูด ใช้ Voice Cloning เมื่อคุณต้องการเสียงสดใสที่กำหนดเองซึ่งสร้างจากอ้างอิงเฉพาะแทนโปรไฟล์มาตรฐาน
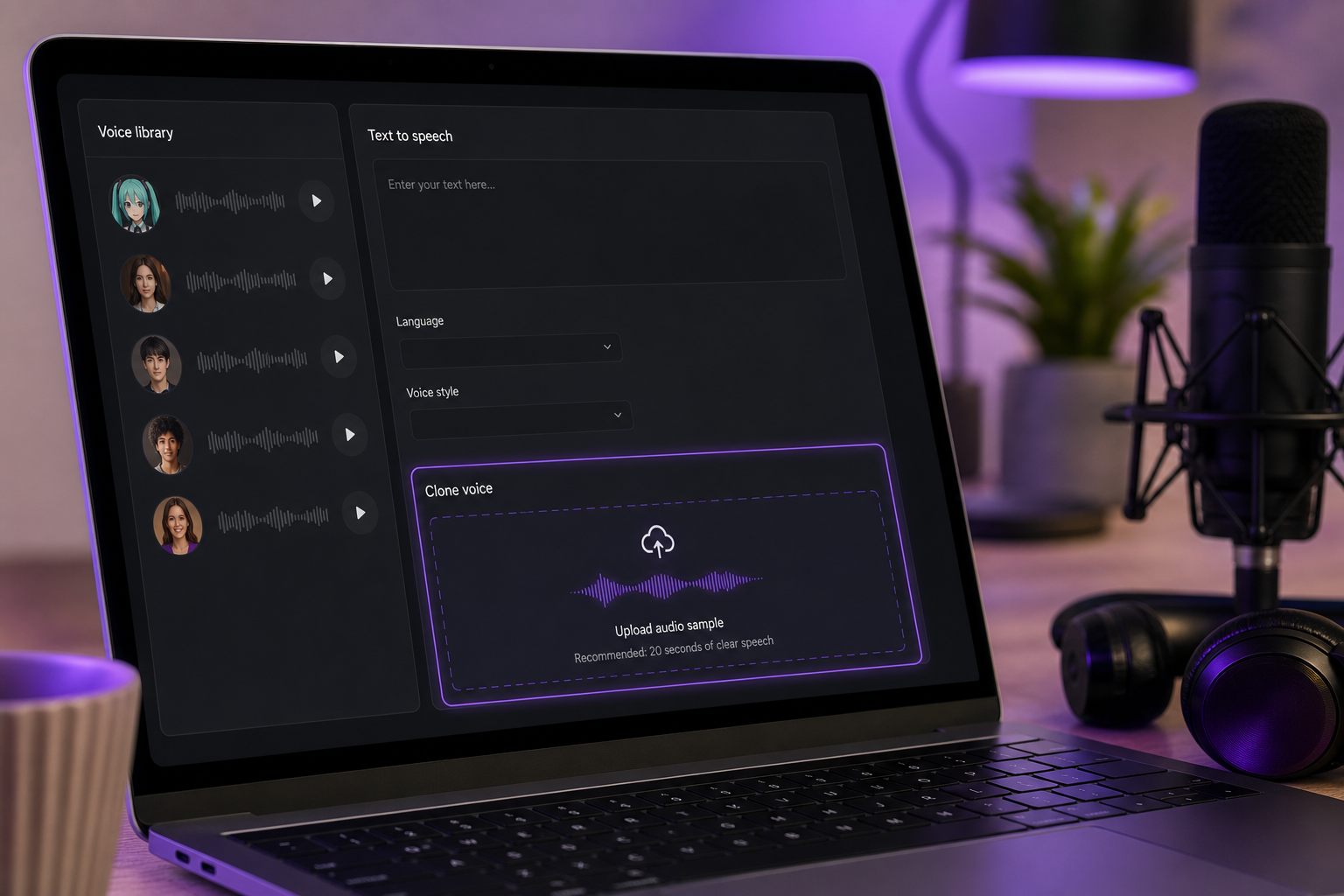
3. เลือกโปรไฟล์เสียงหรือโคลนจากอ้างอิง เลือกเสียงที่แหลมและสดใสจากไลบรารีเสียงกว่า 300 เสียง หรือสร้างของคุณเองผ่าน การโคลนเสียง จากเสียงอ้างอิงที่สะอาดประมาณ 20 วินาที หากคุณโคลน อ้างอิงต้องเป็นเสียงร้องที่แยกออกมาอย่างสะอาด — ไม่มีดนตรีประกอบ ไม่มีเสียงรบกวนจากห้อง การโคลนจะดีได้แค่เท่ากับแหล่งที่มาเท่านั้น
4. ป้อนเนื้อร้องหรือบทสนทนาของคุณ วางข้อความของคุณลงในช่องป้อนข้อมูล สำหรับเนื้อหาที่พูด นี่คือข้อความสุดท้ายของคุณ สำหรับประโยคร้อง วางวลีเนื้อร้อง — คุณจะจัดการทำนองจริงในภายหลังใน DAW ซึ่งจะกล่าวถึงในส่วนต่อไปด้านล่าง
5. ปรับพิตช์ ความเร็ว และโทนไปสู่ช่วงเสียง Miku ที่เป็นเอกลักษณ์ ผลักดันเสียงให้ไปทางสดใส สูง และคมชัด เกณฑ์มาตรฐานในที่นี้คืองานวิจัย VOCALOID:AI ของ Yamaha ซึ่งวางกรอบเสียงร้องสังเคราะห์สมัยใหม่ให้มุ่งเป้าไปที่การออกเสียงที่เป็นธรรมชาติและโทนเสียงสดใสมากกว่าการตั้งค่าหุ่นยนต์ที่หนักหน่วง ตาม ภาพรวมการสังเคราะห์เสียงด้วย AI ของ Yamaha มุ่งเป้าให้สะอาดและชัดเจน ไม่ใช่เสียงหึ่งๆ เป้าหมายที่แม่นยำจะมาในส่วนถัดไป

6. สร้างและพรีวิวก่อนใช้เครดิตเต็มจำนวน เรนเดอร์คลิปสั้นๆ ก่อนเสมอ พรีวิวมัน ตัดสินว่าช่วงเสียงฟังออกว่าเป็น Miku หรือไม่ ปรับแต่ง และเพิ่งจะยอมสร้างเต็มจำนวนหลังจากนั้น นิสัยอย่างเดียวนี้ช่วยประหยัดเครดิตได้มากกว่าวิธีอื่นใด
ความสามารถอีกอย่างที่ควรรู้ไว้สำหรับภายหลัง: AI Dubbing ของแพลตฟอร์มรองรับการพากย์เสียงจากภาษาต้นทางกว่า 60 ภาษาเป็นภาษาเป้าหมาย 33 ภาษา ซึ่งจะมีประโยชน์เมื่อคุณต้องการแปลเนื้อหาแฟนที่ทำเสร็จแล้วให้เข้ากับท้องถิ่นสำหรับผู้ชมต่างประเทศ
ปรับเสียงที่เป็นเอกลักษณ์: พิตช์ โทน และลักษณะเสียงร้อง
นี่คือจุดที่ความพยายามส่วนใหญ่ล้มเหลว ผู้คนปั่นพิตช์ขึ้นไป ได้ยินเสียงสูง และคิดว่าทำเสร็จแล้ว — แต่คลิป TTS เสียงแหลมไม่ใช่เสียง Hatsune Miku AI ตัวละครนี้อยู่ในการรวมกันเฉพาะของช่วงเสียง การออกเสียง และน้ำหนัก ทำสิ่งเหล่านั้นให้ถูกต้องแล้วเสียงนั้นจะ ฟังออก ว่าเป็น Miku แม้กระทั่งก่อนที่ใครจะได้ยินคำที่จดจำได้แม้แต่คำเดียว
มุ่งเป้าไปที่โทนเสียงที่ถูกต้อง งานวิจัย VOCALOID:AI ของ Yamaha วางกรอบเสียงร้องสังเคราะห์สมัยใหม่ให้มุ่งเป้าไปที่การออกเสียงที่เป็นธรรมชาติและโทนเสียงสดใสมากกว่าการตั้งค่าหุ่นยนต์ที่หนักหน่วง ตั้งเกณฑ์มาตรฐานไปทางเสียงที่สะอาด ช่วงเสียงสูง ออกเสียงแม่นยำ — ไม่ใช่เสียงโมโนโทนหึ่งๆ เสียงสังเคราะห์ร่วมสมัยนั้นสดใสและชัดเจน ไม่ใช่เครื่องจักรกล หากเอาต์พุตของคุณฟังดูเหมือนหุ่นยนต์อ่านเมนูโทรศัพท์ แสดงว่าคุณทำให้มันแบนเกินไปแล้ว
ดันพิตช์ไปทางเพดาน แต่หยุดก่อนเกิดอาร์ติแฟกต์ คุณภาพ "Miku" อยู่ในเพดานพิตช์ที่ผสานกับพยัญชนะที่คมชัด ไม่ได้อยู่ที่ความดัง ยกช่วงเสียงขึ้นไปจนกระทั่งคุณถึงขอบของอาร์ติแฟกต์ที่ได้ยินได้ — คุณภาพที่บาง กระตุก ยืดแบบดิจิทัล — จากนั้นถอยกลับมาเล็กน้อย จุดที่ลงตัวคือสูงและสดใสแต่ยังคงสะอาด เสียงที่ปรับพิตช์ต่ำเกินไปฟังดูเหมือน TTS ธรรมดา ซึ่งเป็นความล้มเหลวที่พบบ่อยที่สุด
ความเร็วและการออกเสียงสำคัญกว่าที่คุณคาดคิด การออกเสียงที่เร็วขึ้นเล็กน้อยและสะอาดขึ้นจะฟังออกว่าน่ารักแบบสังเคราะห์ ซึ่งเป็นแก่นของตัวละคร เสียงลมหายใจที่ทำให้เป็นธรรมชาติเกินไปจะดึงเสียงกลับไปทาง "ผู้บรรยายทั่วไป" ทำให้การออกเสียงกระชับ ทำให้พยัญชนะลงตัวอย่างคมชัด ความแม่นยำนั้นเป็นส่วนหนึ่งของสิ่งที่หูของคุณรับรู้ว่าเป็นเสียงสังเคราะห์มากกว่ามนุษย์
ควบคุมเสียงลมหายใจอย่างจริงจัง ลดลมหายใจและความอบอุ่นลง Miku ฟังออกว่าเกือบไร้น้ำหนัก — เธอขาดเสียงก้องในอกของเสียงผู้ใหญ่ตามธรรมชาติ หากคุณได้ยินลมหายใจ อากาศ และปอดในเอาต์พุต แสดงว่าคุณกำลังเคลื่อนห่างจากตัวละคร ขอบเสียงสังเคราะห์ขึ้นอยู่กับความไร้น้ำหนักนั้น หากมีเสียงลมหายใจมากเกินไป คุณจะสูญเสียมันไปอย่างสิ้นเชิง
Miku ไม่ได้อยู่ในคำพูด — เธออยู่ในเพดานพิตช์และการออกเสียงที่คมชัด เกือบไร้น้ำหนัก
เอาต์พุตภาษาญี่ปุ่นกับภาษาอังกฤษทำงานต่างกัน หน่วยเสียงภาษาญี่ปุ่นมักจะลงตัวในแบบที่ฟังออกว่าเป็น "Miku คลาสสิก" มากกว่า ส่วนหนึ่งเพราะนั่นคือเสียงที่ผู้ฟังส่วนใหญ่เชื่อมโยงกับตัวละคร เอาต์พุตภาษาอังกฤษต้องการการออกเสียงที่กระชับกว่าเพื่อหลีกเลี่ยงการลื่นไถลไปสู่ดินแดน TTS ทั่วไป หากคุณกำลังทำงานในภาษาอังกฤษและมันฟังดูแบน วิธีแก้ไขมักจะเป็นพยัญชนะที่คมชัดกว่าและช่วงเสียงที่สูงกว่า ไม่ใช่ความดังที่มากกว่า
เตรียมอ้างอิงการโคลนที่สะอาดก่อนทำสิ่งอื่นใด หากคุณกำลังโคลนแทนที่จะเลือกเสียงมาตรฐาน คุณภาพของอ้างอิงเป็นตัวกำหนดทุกอย่าง ตรวจสอบว่าความชัดเจนสูงพอสำหรับการถอดความที่สะอาด — หาก AI ดิ้นรนที่จะถอดความมัน การโคลนของคุณก็จะขุ่นมัวด้วย ใช้ Speech Separator เพื่อแยกเสียงร้องที่สะอาดออกจากดนตรีประกอบใดๆ ก่อนการโคลน ขยะเข้าก็จะได้การโคลนที่ขุ่นมัวออกมาทุกครั้ง สำหรับครีเอเตอร์ที่กำลังเตรียมอ้างอิงหลายตัวพร้อมกัน การเข้าถึงแบบโปรแกรมผ่าน Voice Cloning API ทำให้การเตรียมเป็นชุดน่าเบื่อน้อยลงมาก
ข้อผิดพลาดรวมตัวกันเป็นสามรูปแบบ พิตช์ต่ำเกินไปฟังดูเหมือน TTS ธรรมดา เสียงลมหายใจมากเกินไปสูญเสียขอบเสียงสังเคราะห์ เสียงโมโนโทนแบบหุ่นยนต์ทำให้เสียงแบนเกินไป ซึ่งขัดแย้งโดยตรงกับเกณฑ์มาตรฐานการออกเสียงสดใสของ VOCALOID:AI หลีกเลี่ยงทั้งสามอย่างแล้วคุณก็เกือบถึงเป้าหมายแล้ว
สุดท้าย ยอมรับว่าการสังเคราะห์แบบดิบเป็นการผ่านครั้งแรก คู่มือการสร้าง Vocaloid เน้นย้ำว่าการปรับแต่งหน่วยเสียง จังหวะ และไดนามิกเป็นสิ่งจำเป็นเพื่อให้ได้เอาต์พุตที่น่าเชื่อถือ — และวินัยเดียวกันนี้ใช้กับ AI generators บทเรียนคัฟเวอร์ VSynth และ คู่มือสำหรับผู้เริ่มต้น Vocaloid ต่างก็มองว่าการเรนเดอร์ครั้งแรกคือจุดเริ่มต้นของงาน ไม่ใช่จุดจบ สร้าง ฟังอย่างวิพากษ์ ปรับ สร้างใหม่ เสียงที่ฟังออกว่าเป็น Miku แทบไม่เคยเป็นเสียงแรกที่คุณทำ
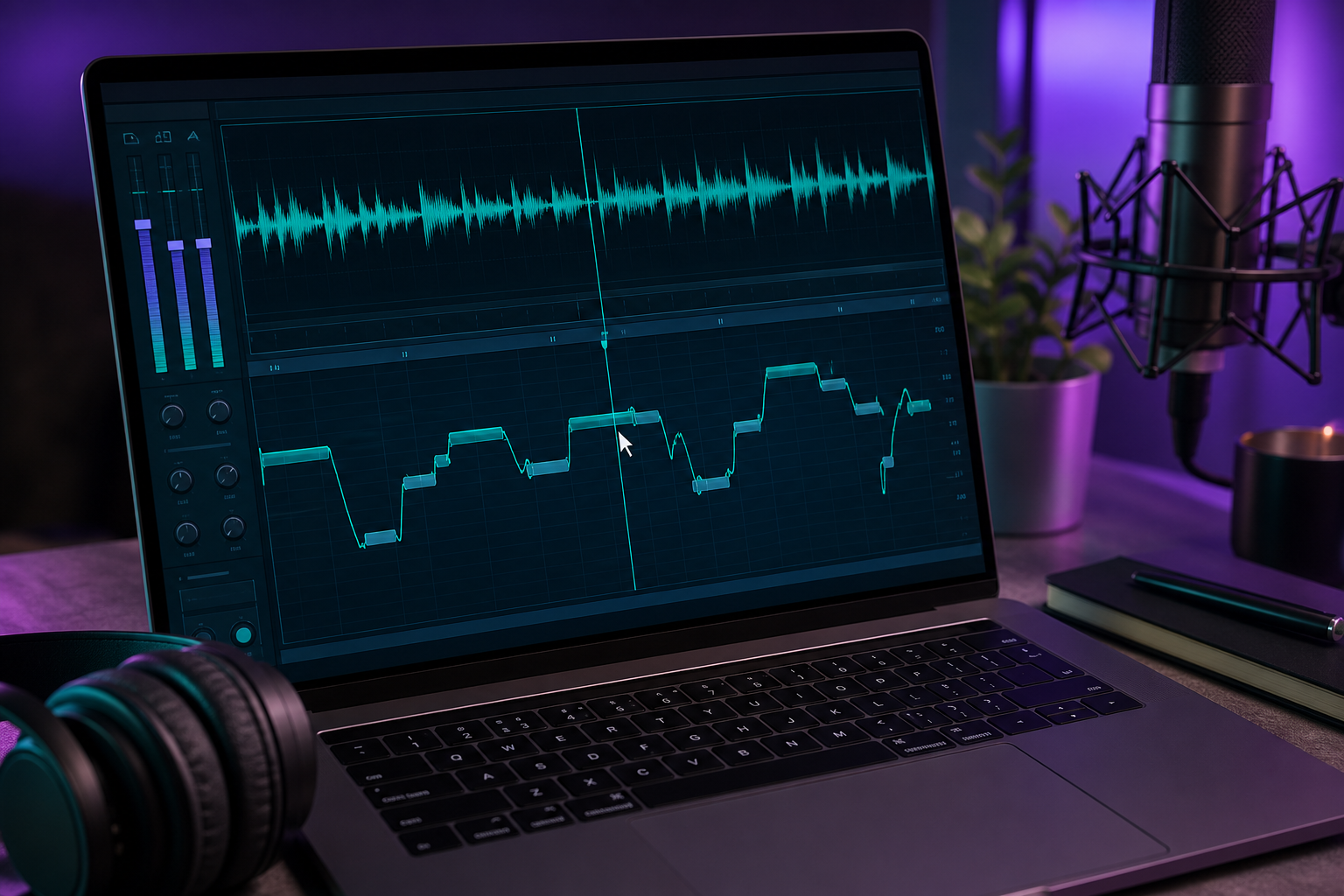
จากการพูดสู่การร้อง: เปลี่ยนเสียงที่สร้างขึ้นให้เป็นแทร็กเสียงร้อง
นี่คือช่องว่างที่ตรงไปตรงมา: AI generators ส่วนใหญ่พูดได้ แต่ Miku มีชื่อเสียงในเรื่องการร้องเพลง การเชื่อมช่องว่างนั้นต้องอาศัยขั้นตอนที่ตั้งใจไม่กี่ขั้นและ DAW นี่คือวิธีที่คุณเปลี่ยนประโยคพูดจาก miku voice generator ให้เป็นแทร็กเสียงร้องสำหรับคัฟเวอร์ Miku AI
1. สร้างวลีเสียงร้องที่สะอาด ผลิตประโยคสั้นๆ ที่ออกเสียงดีแทนที่จะเป็นข้อความบล็อกยาวๆ ก้อนเดียว วลีสั้นจะแมปพิตช์และจัดให้เข้ากับทำนองได้ง่ายกว่ามาก วลีสี่ห้องที่คุณขยับเข้าที่ได้ดีกว่าบทพูดยาวสามสิบวินาทีที่คุณต้องตัดแยกอย่างประณีต
2. กำหนด BPM ของเพลง ใช้เครื่องมือนับ BPM ในเบราว์เซอร์ของคุณ แตะตามไปจนกว่าจังหวะเฉลี่ยจะคงที่ จากนั้นตั้ง BPM เป็นเลขจำนวนเต็มที่ใกล้ที่สุดใน DAW ของคุณ บทเรียนคัฟเวอร์ VSynth ระบุว่า "99.9% ของเวลา คุณต้องการแค่ตัวเลขจำนวนเต็มของ BPM" เพราะเพลงมักไม่ค่อยมีจังหวะเป็นทศนิยม อย่าคิดมากเกินไป — จังหวะที่เป็นจำนวนเต็มที่สะอาดมักจะถูกต้องเสมอ
3. นำเข้าวลีเข้าสู่ DAW บนโปรเจกต์ที่จัดให้เข้ากับกริด ตั้งค่าโปรเจกต์ของคุณเพื่อให้คลิปเสียงร้องสแนปเข้ากับเวลาเทียบกับแทร็กประกอบ การจัดให้เข้ากับกริดคือสิ่งที่ทำให้เสียงร้องสังเคราะห์ล็อกเข้ากับเครื่องดนตรี — หากไม่มีมัน ทุกอย่างจะคลาดเคลื่อน วินัยกริดและจังหวะนี้เป็นเงื่อนไขเบื้องต้นมาตรฐานก่อนงานปรับแต่งใดๆ จะเริ่มต้น
4. จัดพิตช์วลีให้เข้ากับทำนอง ใช้ Melodyne หรือ auto-tune เพื่อดัดแต่ละวลีให้เข้ากับโน้ตที่ถูกต้อง ขั้นตอนนี้จำเป็น ไม่ใช่ตัวเลือก เพราะ AI TTS ทั่วไป