
Você já rolou por quarenta amostras de voz. Fones de ouvido colocados, você toca a pré-visualização, escuta por três segundos, toca na próxima, e na próxima, até que todas as amostras se misturam no mesmo zumbido indistinto. Esta é "calorosa" ou apenas "suave"? O explicativo deveria soar "autoritário" ou "amigável"? O problema não é a falta de opções — bibliotecas modernas têm mais de 300 vozes, e você pode testá-las por uma hora sem decidir por nenhuma. O problema são os descritores de voz: o vocabulário preciso de que você precisa para distinguir uma voz de outra e combiná-la ao seu conteúdo com intenção. Sem esse vocabulário, a seleção de voz se torna um chute e a dublagem vira um caro processo de tentativa e erro. Segundo o WP SEO AI, rótulos de uma só palavra como "natural" ou "envolvente" são vagos demais para serem acionáveis — um retrato vocal claro exige especificar várias dimensões interagentes de uma vez. Ao final deste artigo, você será capaz de descrever qualquer voz com precisão entre tom, altura tonal e estilo, para que possa buscar, filtrar e instruir ferramentas de voz — ou orientar um projeto de clonagem — com confiança em vez de sorte.

Índice
- As Quatro Dimensões em Que Todo Descritor de Voz se Enquadra
- Descritores de Tom Decodificados — De "Caloroso" a "Autoritário"
- Altura Tonal e Ritmo — Os Descritores Técnicos Que as Pessoas Confundem
- Estilo e Registro — Combinando a Voz ao Contexto do Conteúdo
- Empilhando Descritores em uma Busca ou Prompt de Voz Preciso
- Armadilhas dos Descritores — Onde a Seleção de Voz Falha Silenciosamente
- Seu Modelo de Briefing de Descritor de Voz Para Copiar e Colar
- Perguntas Sobre Descritores de Voz Que os Criadores Realmente Fazem
As Quatro Dimensões em Que Todo Descritor de Voz se Enquadra
Todo descritor de voz que você já leu — por mais poético que seja — se reduz a quatro dimensões mensuráveis. Uma vez que você consegue nomeá-las, o vocabulário deixa de parecer subjetivo e passa a se comportar como um conjunto de controles que você pode ajustar de forma independente.
Tom é a cor emocional ou a atitude da voz. Caloroso, frio, entusiasmado, distante — esse é o caráter emocional que o ouvinte sente antes de processar o significado de uma única palavra. É a dimensão que decide se o seu público se aproxima ou se afasta.
Altura tonal é a percepção de quão alto ou baixo é o som. Um barítono profundo e ressonante fica em uma extremidade; um som brilhante, leve e juvenil fica na outra. A altura tonal é fundamentalmente uma propriedade de frequência, o que a torna um dos descritores mais objetivos dos quatro — mas também é um dos mais frequentemente confundidos com o ritmo.
Ritmo e cadência descrevem a velocidade da fala e sua cadência. Rápido, comedido, vagaroso, deliberado — o ritmo inclui as pausas entre frases e os padrões de inflexão que se sobrepõem a elas. Duas vozes lendo roteiros idênticos em ritmos diferentes podem parecer performances inteiramente distintas.
Estilo e registro governam o contexto da performance e a formalidade. Narração, conversacional, broadcast, e-learning — formal versus casual. Esta é a dimensão que decide qual papel a voz está desempenhando para o ouvinte.
Esta taxonomia não é uma opinião pessoal. O Nielsen Norman Group formaliza o tom ao longo de quatro eixos independentes — formal vs. casual, sério vs. engraçado, respeitoso vs. irreverente, e objetivo vs. entusiasmado — demonstrando que o tom é multieixo, não um único controle deslizante que você arrasta de "chato" a "divertido". Plataformas comerciais operacionalizam a mesma lógica. O marketplace de vozes Voices.com agrupa a descrição vocal em quatro qualidades: altura tonal e tom, volume e projeção, articulação e enunciação, e velocidade e inflexão. Rótulos diferentes, mesma estrutura subjacente.

Por que separar as dimensões importa tanto? O coach de comunicação Robin Kermode enquadra tom, altura tonal e ritmo como as três alavancas que juntas criam "variedade vocal" — definindo tom como caráter emocional, altura tonal como a frequência percebida que pode alterar o significado emocional, e ritmo como a velocidade da entrega. Estilo e registro formam a quarta alavanca, e ela se posiciona acima das outras três, governando o contexto em que operam. Em termos simples: tom, altura tonal e ritmo descrevem como a voz soa; estilo e registro descrevem qual papel ela está desempenhando.
Todo descritor de voz que você já leu se reduz a quatro alavancas — tom, altura tonal, ritmo e estilo. Domine as alavancas e você para de adivinhar.
Guarde este modelo. Cada seção a seguir aprofunda exatamente uma destas quatro dimensões, e nenhuma delas vai redefinir a estrutura. Quando você se deparar com um descritor em qualquer lugar — um filtro de marketplace, um campo de prompt de IA, um briefing de agência — sua primeira tarefa é encaixá-lo em uma das quatro categorias. Esse único hábito converte uma parede de adjetivos em um painel de controle organizado.
Descritores de Tom Decodificados — De "Caloroso" a "Autoritário"
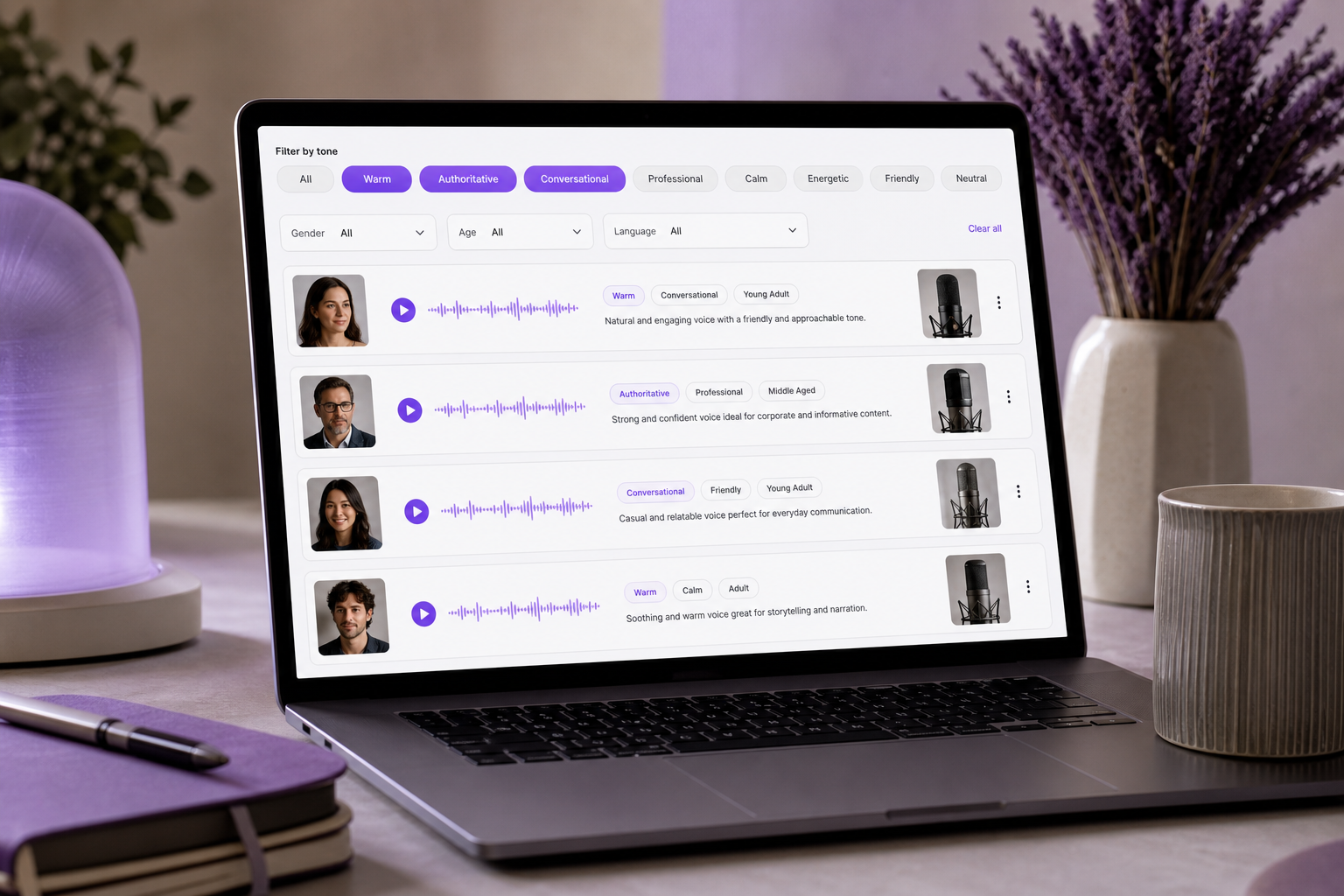
O tom é a dimensão que o público registra primeiro, e é a que mais comumente recebe briefings errados porque se apoia em adjetivos subjetivos. A pesquisa do Nielsen Norman Group mostra que o tom opera ao longo de múltiplos eixos independentes — humor, formalidade, respeitabilidade e entusiasmo são alavancas separadas — o que significa que uma única palavra de tom raramente captura o que você realmente quer. Agrupe seus descritores de tom em vez disso, e você obtém tanto precisão quanto uma maneira prática de filtrar.
Construção de confiança (caloroso, amigável, tranquilizador). Esse agrupamento constrói segurança emocional antes que o significado chegue. É a escolha certa para explicativos de saúde, IVR de atendimento ao cliente e vídeos de onboarding, onde o ouvinte precisa se sentir acolhido antes de absorver instruções. O WP SEO AI lista "caloroso" entre os adjetivos de tom emocional mais usados, e com boa razão — é a base que a maioria dos públicos tende a confiar por padrão.
Enérgico (animado, entusiasmado, vivaz). Esse agrupamento sinaliza impulso e empolgação. É o melhor para lançamentos de produtos, leituras de anúncios e shorts de redes sociais, onde os primeiros dois segundos decidem se alguém continua assistindo. O eixo "entusiasmado" da NN/g mapeia diretamente aqui — e note que é independente da formalidade, então você pode ser enérgico e profissional ao mesmo tempo.
Sério (autoritário, profissional, sóbrio). Esse agrupamento transmite credibilidade e peso. Recorra a ele em treinamento corporativo, explicativos financeiros e narração de documentários, onde o público precisa confiar que o falante sabe mais do que eles. "Autoritário" é um descritor de destaque na lista de retrato vocal do WP SEO AI — é específico o suficiente para filtrar e amplo o suficiente para aplicar em diversos formatos.
Íntimo (suave, calmante, conversacional). Esse agrupamento cria proximidade e calma. Foi feito para apps de meditação, introduções de podcast e conteúdo no estilo ASMR, onde o ouvinte muitas vezes está sozinho e a voz parece falar diretamente com ele. A intimidade vem tanto da contenção quanto do calor — esse agrupamento recua em vez de projetar.
O tom é a única dimensão que o público nota primeiro e esquece por último — ele estabelece a confiança emocional antes que o significado de uma única palavra chegue.
Esses agrupamentos não são apenas um modelo mental — são como as ferramentas modernas permitem que você busque. Uma plataforma de TTS como o SymTrain documenta a filtragem de vozes por tom, como "articulada, casual, ansiosa", estreitando uma grande biblioteca antes mesmo de você tocar a pré-visualização. Esse é o retorno prático de agrupar seus descritores de voz: do mesmo jeito que uma biblioteca de Text to Speech permite filtrar por tom antes de pré-visualizar, um agrupamento de tom claro transforma uma hora de testes em uma lista curta e focada de três.
Altura Tonal e Ritmo — Os Descritores Técnicos Que as Pessoas Confundem
Altura tonal e ritmo são as duas dimensões mais confundidas em qualquer briefing de voz, e a confusão custa tempo real aos criadores. Altura tonal é frequência — a percepção de quão alta ou baixa é uma voz. Ritmo é velocidade e cadência — palavras por minuto, cadência e a colocação das pausas. A divisão tripla de Robin Kermode os mantém limpos: tom é caráter emocional, altura tonal é frequência percebida, ritmo é velocidade da fala. Três coisas separadas.
O erro clássico é trocar o vocabulário. Os criadores dizem "rápido" quando querem dizer "agudo", ou "profundo" quando querem dizer "lento". Esses são controles independentes. Uma voz profunda pode ser ágil. Uma voz aguda pode ser comedida. Tratá-los como um único adjetivo embaralhado é como os briefings dão errado antes de alguém gravar uma sílaba.
| Descritor | O Que Controla | Soa Como | Melhor Para |
|---|---|---|---|
| Profundo | Altura tonal (frequência baixa) | Barítono, ressonante | Documentário, marca de luxo |
| Brilhante | Altura tonal (frequência alta) | Leve, arejado, juvenil | Conteúdo infantil, anúncios animados |
| Comedido | Ritmo (lento/uniforme) | Deliberado, espaçoso | E-learning, tutoriais |
| Ágil | Ritmo (rápido) | Enérgico, urgente | Notícias, promoções |
| Cortado | Ritmo + articulação | Nítido, paradas precisas | Técnico, instrucional |
| Arrastado | Ritmo (lento/relaxado) | Esticado, casual | Narrativa, personagem |
O trabalho interessante acontece quando a altura tonal e o ritmo se combinam, porque a impressão composta é quase sempre mais forte do que qualquer descritor isolado. Altura tonal profunda com ritmo ágil transmite urgência confiante — a voz de alguém que conhece o material e não está desperdiçando seu tempo. Altura tonal brilhante com ritmo comedido transmite paciência amigável — ideal quando você está guiando um usuário nervoso por uma primeira configuração. Troque as combinações e o significado se inverte completamente, e é exatamente por isso que você não pode colapsar os dois campos em um.
Essa separação está embutida na forma como plataformas sérias estruturam suas orientações. O Voices.com trata altura tonal/tom e velocidade/inflexão como duas de suas quatro qualidades distintas, nunca como uma única configuração. A documentação da API Hamsa lista de forma semelhante o ritmo de fala e a pronúncia/clareza como critérios de seleção separados, cada um avaliado por conta própria antes que uma voz entre em produção. A lição para o profissional é direta: em qualquer briefing, dê à altura tonal e ao ritmo seus próprios campos. Escreva "altura tonal profunda, ritmo ágil", e não "uma voz profunda e impactante" na esperança de que o leitor desembarace. E lembre-se de que os mesmos traços de altura tonal e ritmo que você especifica aqui são o que um modelo de clonagem de voz preserva de uma amostra de origem — então acertar o vocabulário na etapa de briefing carrega-se por todo o caminho até a saída clonada.
Estilo e Registro — Combinando a Voz ao Contexto do Conteúdo
A habilidade de maior alavancagem na seleção de voz não é escolher a voz mais impressionante. É escolher o estilo e o registro certos para o contexto de entrega — a voz que o seu público espera e nunca questiona. A orientação do design-system da PatternFly separa estilo (escolhas de gramática e sintaxe), voz (personalidade da marca) e tom (o estado emocional do usuário), e o paralelo com a voz falada mapeia de forma limpa: estilo e registro de um lado, tom emocional do outro. Erre o registro e até uma voz linda parece estranha.
A documentação da Hamsa torna a distinção de estilo concreta com uma justificativa explícita por caso de uso. "Conversacional" é natural e amigável — melhor para atendimento ao cliente e suporte. "Narrador" é claro e articulado — adequado para explicações. Esse enquadramento de "soa como / melhor para" é exatamente o que transforma o estilo em uma decisão que você pode tomar em segundos em vez de debater por uma tarde inteira.
| Tipo de Conteúdo | Descritor de Estilo Recomendado | Por Que Funciona |
|---|---|---|
| Explicativo do YouTube | Conversacional | Natural, amigável — mantém os espectadores casuais engajados |
| Treinamento corporativo | Narrador | Claro, articulado — adequado para explicações |
| Introdução de podcast | Conversacional / broadcast | Estabelece uma presença de apresentador calorosa e familiar |
| Audiolivro | Narrador | Clareza sustentada ao longo de escuta de formato longo |
| Anúncio / promoção | Broadcast enérgico | Projeta impulso e um chamado à ação |
Por baixo do estilo está o registro — a escolha entre formal e casual que tempera tudo acima dele. O eixo formal↔casual da NN/g é a maneira mais limpa de pensar sobre isso: o mesmo estilo conversacional pode soar como um apresentador de broadcast polido ou um amigo conversando do outro lado da mesa, dependendo de onde você ajusta o controle de registro. Um narrador de treinamento corporativo em um registro casual parece acessível; o mesmo narrador em um registro formal parece institucional. Nenhum está errado — são respostas a briefings diferentes.
Duas camadas adicionais se empilham por cima. Sotaque e dialeto são critérios de seleção fundamentais na lista de verificação da Hamsa, e carregam um peso cultural que nenhum descritor de tom pode anular — uma voz "americana neutra" e uma voz "RP britânica" podem compartilhar tom, altura tonal e ritmo idênticos e ainda assim soar completamente diferentes para um público. O SymTrain recomenda filtros de faixa etária — jovem, adulto, mais velho — junto com o tom, porque a idade percebida muda o quão autoritária ou identificável uma voz parece.
O descritor de estilo certo não é a voz mais impressionante — é aquela que seu público espera ouvir naquele momento e nunca questiona.
O ponto mais afiado da PatternFly é que estilo e tom devem responder ao estado emocional do público, não a um padrão de toda a marca. Conteúdo de solução de problemas precisa de um registro neutro e prestativo; um anúncio precisa de um entusiasmado. O contexto dita o registro toda vez. E as decisões de registro não permanecem fixas quando seu conteúdo viaja — um registro casual e conversacional que funciona perfeitamente em inglês pode soar leviano ou pouco profissional em outro mercado. É uma escolha de registro que precisa se sustentar quando você passa o conteúdo por AI Dubbing para outros idiomas, que é exatamente onde a próxima camada de disciplina compensa.
Empilhando Descritores em uma Busca ou Prompt de Voz Preciso
O vocabulário só importa se você puder transformá-lo em um método repetível. A pesquisa é consistente sobre o princípio central: descritores empilhados superam rótulos isolados toda vez. O WP SEO AI recomenda combinar adjetivos de tom emocional como "caloroso", "nítido" ou "autoritário" com detalhes concretos sobre ritmo, variação de altura tonal, ressonância e clareza para construir um retrato vocal claro. O Voices.com formaliza um pipeline de três etapas — defina o personagem (idade, gênero, estilo), defina o tom e, em seguida, escolha palavras-chave apropriadas. Aqui está essa lógica dividida em sete passos que você pode executar toda vez.
- Defina o objetivo emocional. Nomeie o sentimento com o qual o público deve sair — confiança, empolgação, calma. Tudo a jusante serve a essa única decisão.
- Escolha um agrupamento de tom. Escolha entre os quatro agrupamentos: construção de confiança, enérgico, sério ou íntimo. Resista à tentação de misturar agrupamentos conflitantes — é aí que os briefings se desfazem.
- Defina a faixa de altura tonal. Profunda, média ou brilhante. Uma palavra, não um parágrafo.
- Defina o ritmo. Comedido, ágil ou cortado. Mantenha-o separado da altura tonal.
- Trave o estilo e o registro. Conversacional, narrador ou broadcast — depois formal ou casual.
- Adicione demografia e sotaque. Acrescente faixa etária e dialeto, da forma que os filtros do SymTrain e da Hamsa esperam.
- Teste contra 2 a 3 amostras. A lista de verificação da Hamsa — pronúncia, clareza, ritmo, tom, sotaque — é seu portão final de validação antes que algo seja entregue.

Veja como fica a pilha finalizada como uma única string: caloroso + altura tonal média + ritmo comedido + estilo conversacional + feminino + 30 e poucos anos + sotaque americano neutro. Essa única linha cumpre dupla função. Coloque-a em uma barra de busca e ela reduz drasticamente seu tempo de filtragem em uma biblioteca de mais de 300 vozes para um punhado de candidatas. Alimente a mesma string empilhada em um preset de TTS e ela se torna um prompt de geração. A disciplina de escrevê-la uma vez é o que poupa você de ter que testar todo o catálogo novamente. E porque o formato é consistente, a mesma string empilhada que você alimentaria em um preset de TTS pode passar diretamente para uma chamada de Voice Cloning API — um briefing, múltiplos destinos, zero retradução entre ferramentas.
Armadilhas dos Descritores — Onde a Seleção de Voz Falha Silenciosamente
A maioria dos projetos de voz não falha na etapa de gravação. Eles falham no briefing, de formas que são invisíveis até você estar ouvindo um arquivo finalizado que, de algum modo, está errado. Estes são os modos de falha que não aparecem até que seja caro consertar.
Empilhar descritores contraditórios. "Enérgico mas calmante" se cancela — a voz não pode disparar e sussurrar ao mesmo tempo. A pesquisa da NN/g é útil aqui: humor, respeito e entusiasmo são alavancas independentes, então muitas combinações funcionam bem, mas algumas genuinamente entram em conflito. A solução é escolher um agrupamento de tom dominante e refinar dentro dele em vez de buscar entre agrupamentos uma variedade de que você não precisa.
Tratar "natural" como uma direção. "Natural" e "envolvente" parecem instruções, mas não são acionáveis. O WP SEO AI argumenta que esses termos genéricos falham tanto para ferramentas de IA quanto para talentos remotos porque não especificam nenhuma das dimensões interagentes. A solução é substituir cada termo genérico pela pilha de quatro dimensões — tom, altura tonal, ritmo, estilo — mais a demografia. Se um descritor não se encaixa em uma dessas categorias, não é uma direção.
Presumir que os descritores se traduzem entre idiomas. O tom percebido muda quando você dubla para outro idioma e cultura — um registro que soa caloroso em inglês pode soar excessivamente familiar em outro lugar. A solução é revalidar o tom por idioma-alvo em vez de confiar que o descritor de origem vai se transferir. Quando você está dublando para 33 idiomas-alvo, as verificações de tom por idioma não são um polimento opcional; são a diferença entre um conteúdo que conecta e um conteúdo que sutilmente afasta. É por isso que equipes que passam conteúdo por uma AI Dubbing API reverificam o tom por idioma-alvo em vez de presumir que o briefing original ainda se mantém.
Ignorar o contexto emocional do público. A PatternFly alerta que um tom tamanho único falha — um fluxo de solução de problemas precisa de uma voz neutra e prestativa, enquanto um anúncio precisa de uma entusiasmada. A solução é escolher descritores para o momento em que seu público se encontra, não para o padrão de toda a marca que você definiu seis meses atrás.
Pular o briefing e confiar na intuição. A abordagem de guia de tom de Ed Gandia critica diretrizes vagas exigindo parâmetros concretos — público, especificidades de tom como "caloroso mas não tagarela", formalidade, comprimento de frase e padrões recorrentes. A solução é a mais simples de todas: escreva o briefing empilhado antes de pré-visualizar uma única voz. A intuição é boa para escolher entre dois finalistas. É terrível para reduzir 300 para 3.

"Natural" não descreve nada — é a expectativa padrão, não uma direção criativa.
Seu Modelo de Briefing de Descritor de Voz Para Copiar e Colar
Aqui está a versão operacional de tudo que foi dito acima — uma estrutura de preencher lacunas que você pode colar em qualquer ferramenta de voz, briefing de agência ou pedido de clonagem. É o modelo de quatro dimensões mais a demografia, formatado para que você nunca precise reconstruí-lo do zero. Trate-o como a única fonte da verdade para os descritores de voz de um projeto.
BRIEFING DE DESCRITOR DE VOZ
----------------------------------------
Objetivo emocional: ____ (o que o público deve sentir)
Agrupamento de tom: ____ (construção de confiança / enérgico / sério / íntimo)
Altura tonal: ____ (profunda / média / brilhante)
Ritmo: ____ (comedido / ágil / cortado)
Estilo / registro: ____ (conversacional / narrador / broadcast; formal / casual)
Demografia: ____ (gênero, faixa etária)
Sotaque / idioma: ____ (dialeto + idiomas-alvo)
Voz de referência: ____ (opcional — uma voz conhecida para ancorar expectativas)
Essa estrutura não é arbitrária. Ela espelha o resumo de voz conciso de 3 a 5 frases de Ed Gandia, combinado com parâmetros específicos de tom, formalidade e cadência, e segue o pipeline personagem → tom → palavra-chave do Voices.com na ordem em que você realmente toma as decisões. Preencha de cima para baixo e cada campo estreita o próximo.
Aqui está o modelo preenchido para um cenário real — A Introdução de Canal Multilíngue do YouTube:
- Objetivo emocional: boas-vindas confiante
- Agrupamento de tom: construção de confiança / caloroso
- Altura tonal: média
- Ritmo: ágil
- Estilo / registro: broadcast conversacional
- Demografia: feminino, 30 e poucos anos
- Sotaque / idioma: inglês americano neutro, dublado para espanhol + português
- Voz de referência: nenhuma
Esse único briefing de voz cumpre três funções sem modificação. Ele estreita sua busca na biblioteca para uma lista curta. Ele se torna o prompt que conduz a geração de TTS. E ele se transporta para a etapa de dublagem, onde os mesmos descritores são revalidados por idioma-alvo em vez de reconstruídos do zero. Um briefing, três saídas, sem rebriefing.
A vantagem prática dessa abordagem aparece quando suas ferramentas estão em um só lugar. Quando Text to Speech, clonagem de voz e dublagem compartilham um fluxo de trabalho, o mesmo briefing de descritor que conduz uma pré-visualização pode passar diretamente para uma requisição de Text to Speech API — e então adiante para a dublagem — em vez de ser redigitado e reinterpretado a cada etapa. Escreva o briefing uma vez. Use-o em todos os lugares.
Perguntas Sobre Descritores de Voz Que os Criadores Realmente Fazem
Qual é a diferença entre tom e timbre nos descritores de voz?
Tom é o caráter emocional de uma voz — caloroso, sério, distante. Timbre é a textura ou qualidade única do próprio som — suave, áspero, sedoso, duro. O WP SEO AI lista a textura como uma dimensão de descritor separada do tom emocional, e a distinção importa na prática: duas vozes podem compartilhar exatamente o mesmo tom e ainda ter timbres completamente diferentes. Quando uma voz parece certa emocionalmente mas, de algum modo, errada, o timbre costuma ser a variável que você ainda não nomeou.
Os descritores de voz se traduzem com precisão ao dublar para outros idiomas?
Não automaticamente. O tom percebido pode mudar entre idiomas e culturas, então o registro caloroso e casual que funciona em inglês pode soar diferente em outro mercado. A jogada confiável é revalidar o descritor por idioma-alvo em vez de presumir que ele se transfere. Com dublagem para 33 idiomas-alvo disponível, embutir uma verificação de tom por idioma no seu fluxo de trabalho não é trabalho extra — é o que mantém um único briefing honesto em todos os mercados em que você publica.
Quantos descritores devo usar ao instruir uma ferramenta de voz por IA ou de clonagem?
Busque as quatro dimensões centrais mais a demografia — cerca de 5 a 7 descritores empilhados. O WP SEO AI mostra que descritores empilhados superam rótulos isolados, e o pipeline do Voices.com confirma personagem mais tom mais palavras-chave como o mínimo de trabalho. Mantenha-se nessa faixa. Menos de cinco e você está de volta aos termos genéricos vagos; mais de sete e você começa a arriscar contradições que se cancelam.
Posso descrever uma voz fazendo referência a uma voz conhecida ou de celebridade em vez de usar descritores?
Uma voz de referência é uma âncora útil — é por isso que "voz de referência" é um campo opcional no modelo de briefing. Mas ela não substitui os descritores. Uma referência diz a uma ferramenta ou a um humano aproximadamente por onde começar; tom, altura tonal, ritmo e estilo dizem a eles onde chegar. Combinar uma referência com descritores explícitos dá o resultado mais confiável, porque os descritores resolvem a ambiguidade que a referência deixa em aberto.