
API de Fala para Texto: Como Escolher a Correta em 2025
Você criou um app que os usuários adoram — mas os pedidos de recursos continuam chegando: "Posso apenas falar em vez de digitar?" Então você começa a avaliar APIs de fala para texto. Na primeira hora, você já encontrou pelo menos quatro modelos de preços contraditórios, reclamações de precisão que variam de "95%" a "99%+" sem uma definição compartilhada do que está sendo medido, e qualidade de SDK que varia de três linhas para cair direto a passar uma semana lendo documentação ruim.
As apostas são reais em ambos os extremos. Escolha errado em escala e você vai ou gastar $3.000–$8.000/mês em excedentes de streaming, ou vai lançar um recurso de voz que falha em 1 a cada 5 enunciados. De acordo com Koenecke et al. na PNAS (2020), as taxas de erro nos cinco principais sistemas comerciais de reconhecimento de fala chegaram a 35% para falantes de Inglês Vernacular Afro-Americano vs. 19% para falantes brancos — um gap que transforma um "problema de precisão" em um problema de 30%-dos-usuários-não-conseguem-usar-seu-produto.
Este guia fornece o framework de decisão, o método de cálculo de preço, o protocolo piloto, e uma comparação frente a frente de seis provedores — incluindo como um modelo baseado em créditos se encaixa em builds com cargas de trabalho variáveis.

Índice
- Os Cinco Eixos de Decisão que Realmente Orientam a Escolha de API de Fala para Texto
- Precisão em Contexto — Por que "99% Benchmark" Mente Sobre Seu Áudio de Produção
- Latência, Streaming e o Multiplicador de Custo em Tempo Real
- Modelos de Custo Desmistificados — Por Minuto vs. Concorrente vs. Pools de Créditos
- Realidades de Integração — A Auditoria de 9 Perguntas de SDK e API
- Snapshot Comparativo de Provedores — Quando Escolher Cada API de Fala para Texto
- Sua Lista de Verificação de Seleção de API de Fala para Texto
Os Cinco Eixos de Decisão que Realmente Orientam a Escolha de API de Fala para Texto
A maioria dos posts de comparação lista mais de 30 recursos e chama isso de pesquisa. Rejeite isso. Apenas seis eixos determinam se uma API de fala para texto funcionará para seu build específico — e em qualquer projeto dado, apenas dois ou três deles realmente importam.
Precisão em seu domínio. Um app de transcrição médica usando uma API de propósito geral vai renderizar mal "metoprolol" como "meta peral." Taxa de Erro de Palavra agregada esconde esse tipo de falha. Como Dan Jurafsky argumenta em Processamento de Fala e Linguagem, WER trata todos os erros igualmente — mas em um contexto clínico ou legal, um nome de droga errado ou uma negação perdida tem impacto desproporcional. O que importa é WER específico do domínio em seu áudio, não uma manchete de benchmark.
Perfil de latência. Uma ferramenta de legendagem ao vivo para acessibilidade precisa de resposta de ponta a ponta em menos de 1 segundo. Um pipeline de transcrição de podcast pode esperar 10 minutos. De acordo com Nielsen Norman Group's "Response Times: The 3 Important Limits", respostas em menos de 100 ms se sentem instantâneas, menos de 1 segundo preservam o fluxo, e mais de 10 segundos causam abandono de tarefa. Mapeie seu caso de uso para uma camada antes de fazer compras.
Capacidade offline / on-device. Um app de pesquisa de campo em áreas rurais não pode depender de viagens em nuvem. API SpeechAnalyzer da Apple (WWDC 2025) é uma opção on-device de nível de plataforma para iOS/macOS. Whisper auto-hospedado ou Vosk oferece controle offline completo se você estiver disposto a gerenciar GPUs.
Cobertura de idioma e code-switching. Whisper suporta mais de 50 idiomas com qualidade comparável após treinamento em 680.000 horas de áudio multilíngue (Radford et al., OpenAI 2022). Google e AWS usam grupos de idioma em camadas onde idiomas da Tier B obtêm menor precisão e às vezes preços separados.
Arquitetura do modelo de custo. Pay-per-minute, conexões concorrentes e pools de créditos quebram diferentemente em escala. Um YouTuber enviando 4 horas uma semana e 40 a próxima é punido por faturamento por minuto em semanas lentas e semanas de pico. Pools de créditos com rollover absorvem essa variância.
Área de superfície de integração. Qualidade de SDK, webhook vs. polling, padrões de tratamento de erro. É aqui que a "API fácil" vira três semanas perdidas.
Cinco eixos orientam cada decisão de API de fala para texto que vale a pena fazer — e apenas dois ou três deles se aplicam ao seu build.
| Eixo de Decisão | Por que Importa | Armadilha Comum | Caso de Uso de Melhor Ajuste |
|---|---|---|---|
| Precisão do domínio | Reclamações de "99%" de fornecedor usam fala de leitura limpa | Confiar em LibriSpeech para áudio móvel barulhento | Apps médicos, legais, financeiros |
| Perfil de latência | Streaming custa 3–5x lote | Comprar streaming para casos tolerantes a lote | Legendas ao vivo vs. upload de podcast |
| Capacidade offline | Privacidade + ambientes com conectividade restrita | Assumir que Web Speech API é offline | Apps de saúde em campo, mobile-first |
| Cobertura de idioma | Idiomas Tier B = menor precisão | Auto-detecção em áudio multilíngue | SaaS multilíngue, conteúdo global |
| Modelo de custo | Por minuto parece barato até streaming começar | Ignorar armazenamento, egresso, custos de retry | Fluxos de trabalho de criador com volume variável |
| Superfície de integração | SDKs ruins custam semanas de desenvolvimento | "Simples em docs" ≠ envia facilmente | Todos os builders |
Esta tabela é um filtro, não um veredicto. Um criador do YouTube enviando 10 trabalhos em lote por semana se importa com modelo de custo e cobertura de idioma. Um app de saúde se importa com precisão e capacidade offline. Uma ferramenta de reunião em tempo real se importa com latência e superfície de integração.
Antes de continuar lendo, circule os dois ou três eixos que mais importam para seu build específico. A seção de custo (diferença de $-milhares) e o snapshot de provedor no final parecerão completamente diferentes dependendo de quais eixos você priorizou. Tentar otimizar todos os seis em uma decisão vai, a cada vez, entregar você ao provedor mais caro com recursos que você nunca vai usar.
Precisão em Contexto — Por que "99% Benchmark" Mente Sobre Seu Áudio de Produção
Todo provedor de API de fala para texto publica números de precisão. Quase nenhum deles prediz como a API funcionará em seu áudio de produção. Aqui está o porquê e como testar pelo que realmente importa.
Áudio de benchmark é limpo; áudio de produção não é. Benchmarks públicos como LibriSpeech consistem em fala de livro de áudio lido — único falante, sotaque neutro, gravação limpa. O modelo grande do Whisper relata aproximadamente 4,7% WER em teste-limpo do LibriSpeech e aproximadamente 8–9% WER em teste-outro, o conjunto mais desafiador (Radford et al., OpenAI 2022). O gap em áudio real de produção — barulhento, com sotaque, falantes sobrepostos — é ainda mais amplo. Se um fornecedor cita WER sem especificar o dataset e condições de gravação, trate o número como cópia de marketing, não dados de engenharia.
WER é a métrica errada para muitos apps. A definição padrão das diretrizes de Avaliação ASR do NIST é (Substituições + Deleções + Inserções) / palavras de referência. Trata cada palavra como igualmente importante. Mas renderizar mal o nome da medicação de um paciente, uma figura financeira, ou o nome de uma testemunha em tribunal tem consequências que largar uma palavra de preenchimento não tem. Argumento de Jurafsky: avaliar com métricas específicas da tarefa — precisão de preenchimento de slot para assistentes de voz, recall de termo crítico para uso médico e legal, precisão de entidade nomeada para jornalismo. WER agregado pode ser 7%; WER de termo crítico pode ser 22%. Apenas um desses números importa para seus usuários.
Performance de sotaque e dialeto varia dramaticamente. O estudo PNAS citado no topo deste guia testou cinco sistemas comerciais principais e encontrou WER para falantes de Inglês Vernacular Afro-Americano em média 0,35 vs. 0,19 para falantes brancos — aproximadamente duas vezes pior. Isso não é uma nota de rodapé de justiça. É um risco de negócio: um app que falha para um terço de sua base potencial de usuários porque foi QA'd apenas em Inglês Americano neutro está sendo lançado quebrado. A correção não é escolher um provedor diferente (a maioria tem o mesmo gap). A correção é testar em áudio que representa seus usuários reais antes de assinar qualquer coisa.
Uma reclamação de 99% de precisão em um benchmark não diz nada sobre como a API lida com seus usuários — o que importa é performance em seu áudio, seus sotaques e seu vocabulário de domínio.
Precisão de streaming é pior que precisão de lote. Sistemas de streaming emitem palavras provisórias ("parciais") que são reescritas conforme mais áudio chega. Sistemas em lote esperam pela enunciação completa e refinam. WER de streaming é tipicamente 5–15% pior que lote para o mesmo conteúdo no mesmo motor. Este gap quase nunca é divulgado no marketing de fornecedor. Se você está construindo um produto de transcrição ao vivo, fatore isso.
Code-switching quebra a maioria das APIs. Code-switching significa alternar idiomas no meio de um enunciado: Spanglish, Hinglish, Tagalog-Inglês. Whisper lida melhor que a maioria porque foi treinado em 680.000 horas de áudio multilíngue (Radford et al., 2022). A maioria das APIs em nuvem exige que você declare o idioma antecipadamente e degrada com força quando o falante muda de idioma no meio da sentença. Se seus usuários falam mais de um idioma na mesma sessão, teste este caso explicitamente. Para fluxos de trabalho multilíngues que também precisam de localização downstream, plataformas com AI Dubbing integrado em 33 idiomas podem colapsar transcrição, tradução e dublagem em um pipeline.
O Protocolo Piloto de 7 Dias
Em vez de confiar em reclamações de precisão de fornecedor, execute uma prova de conceito de uma semana.
- Dias 1–2: Reúna 30 minutos de áudio de estilo produção real. Inclua seu pior caso: ambientes barulhentos, falantes com sotaque, jargão de domínio, fala sobreposta.
- Dias 3–4: Transcreva com 3 APIs candidatas. Corrija manualmente uma versão para usar como sua transcrição de referência.
- Dia 5: Meça WER geral, depois quebre por falante, sotaque e recall de termo de domínio.
- Dia 6: Teste streaming vs. lote nos mesmos arquivos. Meça o delta de precisão.
- Dia 7: Documente custos incorridos e atrito de integração — complexidade de autenticação, problemas de SDK, qualidade de resposta de erro.
Um engenheiro escrevendo em ITNEXT relatou que após ajustar configuração de microfone e vocabulário customizado, fala para texto moderno produzia menos erros que sua própria digitação para escrita técnica. O aprendizado não é que qualquer API única é mágica. É que escolha de API importa, mas o pipeline de áudio ao redor da API importa pelo menos tanto. Uma API ótima em áudio ruim perde para uma API decente em áudio ajustado.
Latência, Streaming e o Multiplicador de Custo em Tempo Real
Latência é o eixo onde engenheiros mais frequentemente gastam demais. Transcrição em tempo real se sente mágica em uma demonstração e custa 3–5x mais que lote em produção. Decida o que seus usuários realmente precisam antes de se inscrever em infraestrutura de streaming.
- Latência de streaming síncrono (legendas ao vivo, assistentes de voz). Objetivo em menos de 1 segundo ponta a ponta para legendagem de acessibilidade, 300–800 ms round-trip para chatbots de voz para se sentirem conversacionais. Acima de 2 segundos e a ilusão de tempo real quebra. Esses limiares mapeiam para pesquisa UX estabelecida sobre percepção de tempo de resposta (Nielsen Norman Group). APIs de streaming alcançam através de conexões WebSocket persistentes que emitem resultados provisórios conforme áudio chega.
- Latência de lote assíncrona (uploads de podcast, revisão de chamada de suporte, legendas do YouTube). Tempo de processamento de minutos a horas é aceitável. Lote é aproximadamente 3–5x mais barato por minuto de áudio que streaming no mesmo provedor, porque infraestrutura não está mantendo conexões abertas (docs de preço Google Cloud e AWS Transcribe). Para fluxos de trabalho de criador enviando conteúdo gravado, lote é quase sempre correto.
- Híbrido / quase-tempo-real (rascunho ao vivo com correção atrasada). Alguns fluxos de trabalho aceitam latência de 2–5 segundos em troca de maior precisão e custo mais baixo. Uma ferramenta de transcrição de reunião pode mostrar texto bruto em 3 segundos e refiná-lo em 30. Este padrão usa streaming para a visualização ao vivo e reprocessamento em lote para a transcrição salva — frequentemente via callback webhook em vez de polling. Plataformas construídas propositalmente para fluxos de trabalho de mídia, como a AI Dubbing API do DubSmart, usam callbacks webhook para trabalhos concluídos em vez de forçar seu backend a fazer polling de status (thread da comunidade Make.com sobre integração de webhook do AudioPen).
- Real-Time Factor (RTF) — a métrica do engenheiro. Sistemas de produção visam RTF < 1,0 para uso interativo: processamento de 1 segundo de áudio em menos de 1 segundo de tempo de parede. Implementações de Whisper aceleradas por GPU no-device ou on-device alcançam aproximadamente RTF 0,5–0,9 para modelos médios em GPUs de consumidor. Se sua configuração auto-hospedada executa RTF > 1,0, streaming é impossível sem fila.

O triângulo latência-custo-precisão é inegociável: você pode escolher dois. Streaming sacrifica precisão e orçamento pela imediatez. Lote sacrifica imediatez por precisão e custo. Arquiteturas híbridas são cada vez mais comuns mas adicionam complexidade de integração. Antes de escolher, faça uma pergunta: meus usuários realmente notariam um atraso de 5 segundos? Se a resposta é não, lote é a arquitetura correta e você acabou de economizar 70% de seus gastos anuais com API.
Modelos de Custo Desmistificados — Por Minuto vs. Concorrente vs. Pools de Créditos
Existem três arquiteturas de preço no mercado de API de fala para texto, e confundi-las é o erro de compras mais comum.
Pay-per-minute (padrão em lote). Você é faturado por minuto de áudio enviado, frequentemente em incrementos de 15 segundos. Simples de prever para cargas de trabalho previsíveis. OpenAI Whisper API é aproximadamente $0,006/minuto (página de preço do OpenAI) — frequentemente 3–5x mais barato que provedores ASR de nuvem tradicionais, que se agrupam em torno de $0,02–0,03/minuto para modelos de lote padrão em inglês.
Conexões concorrentes (streaming em tempo real). Você paga por fluxo aberto simultâneo, frequentemente cobrado por minuto de conexão ou por slot concorrente. É aqui que as contas disparam: se 50 usuários começam a transmitir ao mesmo tempo, você está pagando por 50 conexões — não 50 minutos de áudio. Google Cloud e AWS publicam taxas distintas e maiores para sessões de streaming vs. trabalhos em lote offline.
Pools de créditos com rollover (cargas de trabalho flexíveis). Você compra um pool de créditos que consomem em taxas variáveis dependendo de quais recursos você usa (transcrição, dublagem, clonagem de voz, conversão de texto em fala). Créditos não utilizados rolam. Este modelo se encaixa em cargas de trabalho variáveis — um YouTuber que envia 4 horas uma semana e 40 na próxima não é penalizado pelo pico ou fica preso com minutos não utilizados. DubSmart AI usa este modelo, agrupando transcrição com Clonagem de Voz e Conversão de Texto em Fala sob um saldo de crédito.
Exemplo prático — Criador do YouTube:
- 10 vídeos/semana × 30 min cada = 300 min/semana de áudio fonte
- Transcrição em lote em $0,006/min = $1,80/semana, ou cerca de $94/ano
- Adicione uma demo com legendagem ao vivo em streaming (5 horas/mês) em taxa 4x lote = aproximadamente $72/ano adicional
- Se o criador dubla em 3 idiomas, necessidade de crédito de transcrição + dub mensal total é aproximadamente 5.000 créditos — se encaixa em um plano de pool de crédito de nível médio
Em qualquer volume abaixo de 5.000 horas por mês, construir sua própria pilha de transcrição é mais barato em fantasia do que em realidade — um tier de API de $50 envia em um dia, enquanto uma implantação Whisper auto-hospedada envia em um trimestre.
| Provedor | Modelo de Preço | Taxa Publicada | Tier Gratuito |
|---|---|---|---|
| Google Cloud STT | Por incremento de 15 seg; sobretaxa de streaming | Variável; em camadas | 60 min/mês |
| AWS Transcribe | Lote por segundo + SKUs de streaming | Variável por região/modelo | 60 min/mês, 12 meses |
| OpenAI Whisper API | Flat por minuto | ~$0,006/min | Nenhum publicado |
| Rev.com (Máquina) | Por minuto | $0,25/min | Nenhum |
| Rev.com (Humano) | Por minuto | $1,50/min | Nenhum |
| DubSmart AI | Pool de créditos c/ rollover | Planos em camadas | Tier gratuito disponível |
Fontes: páginas de preço de fornecedor OpenAI, Google Cloud, AWS Transcribe, Rev.com.

Três custos ocultos quase nunca aparecem em calculadores de fornecedor.
Armazenamento e egresso. Se você armazena transcrições e áudio fonte em S3 ou GCS, você paga armazenamento mais largura de banda em recuperação. Em escala esses se tornam itens de linha não triviais. Um arquivo de 1 TB em taxas padrão com releituras frequentes pode adicionar centenas de dólares por mês antes de qualquer chamada de API acertar.
Diarização de falante geralmente é medida separadamente. AWS Transcribe e AssemblyAI ambos cobram identificação de falante como item de linha separado na parte superior de transcrição base (documentação AWS Transcribe; docs AssemblyAI). Orçamento apenas em taxa base por minuto subestima seu custo real em aproximadamente 20–40% se você precisar de rótulos de falante.
Retry e custos de erro. Requisições falhadas ainda consomem cota em alguns provedores. Se seu pipeline de áudio tem taxa de erro de 2% em 100.000 minutos/mês, isso é 2.000 minutos de retentativas pagas — aproximadamente $12/mês em taxas Whisper, mas facilmente $60/mês em STT de nuvem tradicional.
Break-even de construir vs. comprar. Experiência de engenharia de times em Mozilla (DeepSpeech), Descript e AssemblyAI sugere auto-hospedar ASR com Whisper ou Kaldi apenas faz sentido em >5.000 horas/mês com headcount dedicado de ML e DevOps. Abaixo desse volume, infraestrutura, manutenção de modelo, custos de GPU e overhead de on-call excedem a conta de API de $50–$500/mês — frequentemente por um fator de cinco ou mais.
Realidades de Integração — A Auditoria de 9 Perguntas de SDK e API
"Fácil de integrar" é a frase mais sobrecarregada na economia de API. Uma API pode ser fácil de chamar em uma requisição curl e infernal de enviar em produção. Antes de assinar um contrato, execute cada candidata através dessas nove perguntas. Respostas ruins aqui predizem as semanas de tratamento de erro customizado e lógica de retry que você vai escrever depois.
- A API suporta streaming e lote em um único SDK? Alguns provedores forçam você a escolher arquitetura antecipadamente, depois cobram para mudar. As melhores APIs expõem ambas via a mesma camada de autenticação e deixam você migrar cargas de trabalho conforme comportamento de usuário evolui. Se seu caso de uso inicial é lote mas você pode adicionar legendagem ao vivo em seis meses, isso importa agora.
- O que acontece quando a API está fora do ar ou rate-limitada? Teste. Envie 200 requisições em 1 segundo para um tier gratuito. O SDK as coloca em fila, superfícies um 429 limpo, ou fica pendurado? Fornecedores que publicam SLA e semântica de retry em linguagem simples te poupam semanas de resposta a incidente. Fornecedores que não o fazem eventualmente te acordarão às 3 da manhã.
- Você pode especificar o idioma de áudio explicitamente, ou ele auto-detecta? Auto-detecção soa amigável mas quebra em áudio multilíngue ou code-switched. Para builds de produção, sempre especifique o idioma e caia para auto-detecção apenas quando confiança é baixa. APIs que não deixam você definir o idioma explicitamente são pré-engenheiradas para falhar em seus casos extremos.
- Suporta diarização de falante fora da caixa? Diarização é frequentemente um add-on com preço separado. AssemblyAI e AWS Transcribe ambos medem separadamente. Verifique se seu provedor retorna rótulos de falante de nível de segmento ou nível de palavra — a diferença importa para análise, busca e qualquer sumarização downstream.
- Você pode sinalizar ou editar PII (números de cartão de crédito, SSNs, nomes)? A maioria das APIs focadas em empresa (AWS Transcribe, AssemblyAI) suportam redação de PII. Whisper e Web Speech API não. Para apps de saúde ou financeiros, isso não é um nice-to-have.
- Callbacks webhook ou polling para trabalhos async? Webhooks são o padrão moderno. Polling gera chamadas de API desnecessárias e custos. Plataformas maduras emitem eventos webhook em conclusão de trabalho — o padrão mostrado no thread da comunidade Make.com sobre integração do AudioPen onde conclusão de transcrição aciona automação downstream.
- Quais são os limites de tamanho de arquivo e duração máximos por requisição? Muitas APIs de nuvem limitam requisições individuais em 15 minutos ou aproximadamente 1 hora com limites de tamanho de arquivo em dezenas a centenas de MBs (docs Google Cloud Speech-to-Text; docs AWS Transcribe). Áudio de forma longa — podcasts de duas horas, deposições, gravações de conferência — deve ser segmentado. Gateways HTTP frequentemente aplicam timeouts de 15 minutos independentemente dos limites próprios da API.
- Pontuações de confiança são expostas no nível de palavra? Confiança em nível de palavra deixa você sinalizar regiões de baixa confiança para revisão humana ou correção interativa. APIs que retornam texto bruto sem confiança forçam você ou confiar em tudo ou re-transcrever. Para qualquer fluxo de trabalho com revisão humana no loop, este recurso é a diferença entre uma fila de QA usável e uma parede de texto ilegível.
- Qual é a qualidade do SDK em seu idioma? Um SDK Node.js ou Python com tipagem forte, lógica de retry e classes de erro limpo vale um prêmio de preço de 30% sobre uma API que você tem que HTTP bruto em produção. Teste o SDK antes de comprometer com a API. Escreva uma pequena integração. Cronometre. O SDK que você realmente gosta de trabalhar vai poupar mais horas de engenharia que a taxa por minuto mais barata jamais economizará em dólares.
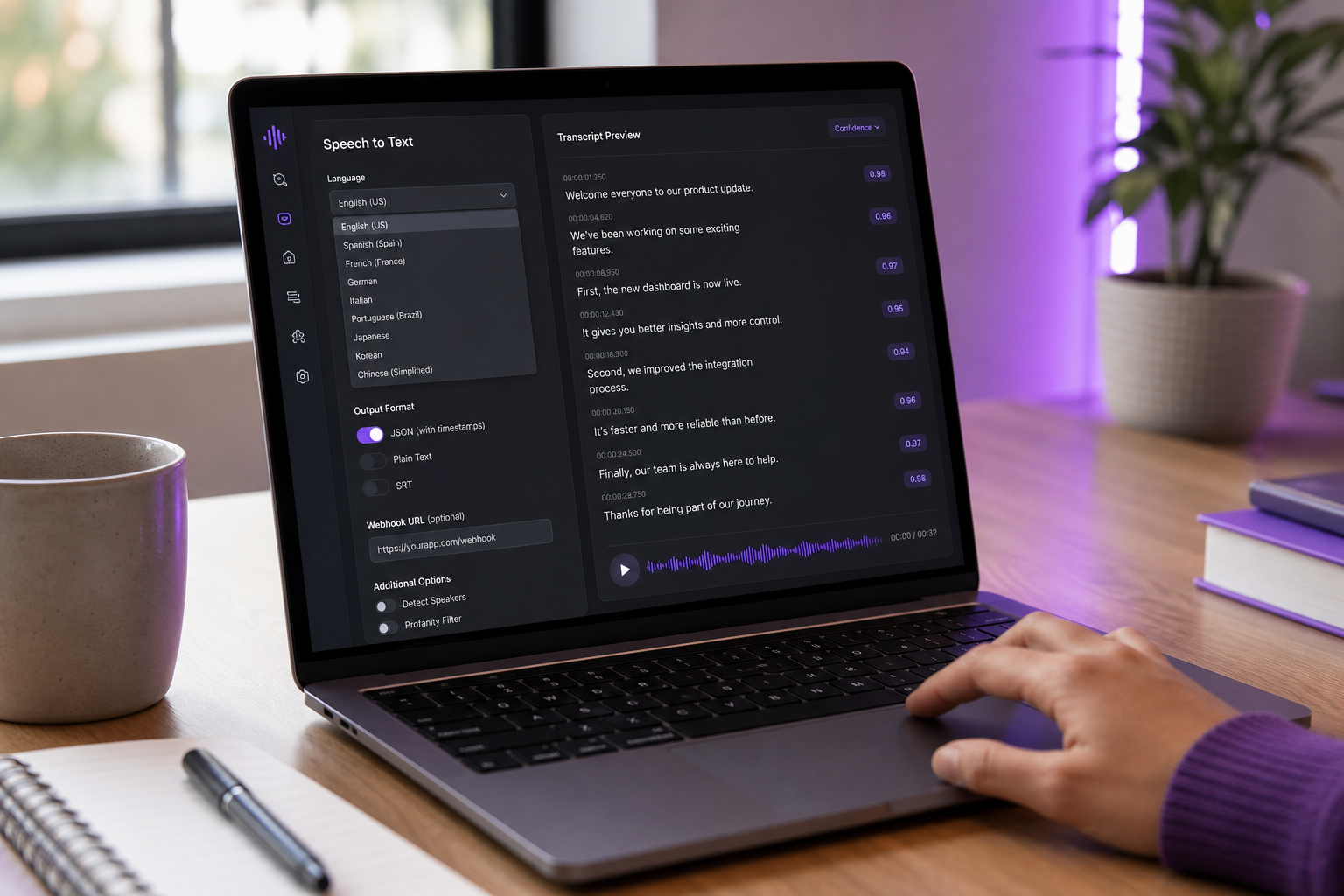
Open-source vs. proprietário permanece o maior fork de integração.
Open-source (Whisper, Vosk). Custo zero por chamada, controle total, executa offline. Você possui hospedagem, escala, provisionamento de GPU, atualizações de modelo, observabilidade e o incidente às 3 da manhã. Implantação realista para um time de 5+ com capacidade de ML e DevOps.
Proprietário em nuvem (Google, AWS, AssemblyAI, OpenAI Whisper API, DubSmart). Você troca custo por minuto por confiabilidade, SLA, versionamento e suporte a SDK. Para a maioria dos times abaixo de 5.000 horas/mês, proprietário ganha em custo total de propriedade. Plataformas que agrupam fala para texto com API de Conversão de Texto em Fala e API de Clonagem de Voz sob um SDK reduzem ainda mais área de superfície de integração — um fluxo de autenticação, um modelo de erro, um painel de faturamento para o pipeline de mídia completo.
On-device de nível de plataforma (Apple SpeechAnalyzer, WWDC 2025). Uma categoria mais nova. Preservação de privacidade, capacidade offline, mas precisão e cobertura de idioma podem ficar para trás em modelos de nuvem. Melhor para apps mobile-first onde privacidade é um ativo de marketing, não apenas uma marca de conformidade.
A pergunta de integração que supera todas as outras: quão rápido você pode enviar? Uma API baseada em créditos bem documentada que agrupa fala para texto, clonagem de voz e dublagem sob um SDK frequentemente supera uma API STT autônoma mais barata uma vez que você contabiliza o segundo e terceiro recursos que você vai precisar dentro de seis meses.
Snapshot Comparativo de Provedores — Quando Escolher Cada API de Fala para Texto
Esta é uma varredura de referência rápida, não uma revisão exaustiva. Cada entrada cobre melhor caso de uso, fraqueza primária, principal determinante de custo e caráter de integração. Fontes para reclamações de preço e recurso são documentação de fornecedor a partir de final de 2024.
Google Cloud Speech-to-Text
- Melhor para: Transcrição de inglês de alta precisão, times já em GCP, cargas de trabalho empresariais com volume previsível.
- Fraqueza: Preço de streaming escala rápido; camadas de idioma criam inconsistência de precisão para áudio não-inglês.
- Determinante de custo: Incrementos de 15 segundos por-cada com SKU de streaming separado (maior); tier gratuito de 60 min/mês.
- Integração: Autenticação GCP nativa via contas de serviço. Apps não-GCP enfrentam overhead IAM. SDKs maduros para todas as linguagens principais.
AWS Transcribe
- Melhor para: Cargas de trabalho pesadas em lote em escala, times nativos da AWS, pipelines de conteúdo multilíngue, análise de call center.
- Fraqueza: Latência de streaming ligeiramente maior que concorrentes especializados em streaming. Diarização e modelos médicos com preço separado.
- Determinante de custo: Duração de áudio em segundos, com SKUs separados para streaming, médicos e add-ons de análise de chamada.
- Integração: Pesada em IAM. Direta se você for nativo da AWS. Bem documentada mas verbosa.
OpenAI Whisper API
- Melhor para: Builds conscientes de orçamento, conteúdo multilíngue com code-switching, times que querem nenhum vendor lock-in além do OpenAI em si.
- Fraqueza: Nenhum suporte nativo de streaming. Nenhum desconto de volume. Nenhum compromisso de SLA comparável a AWS ou GCP.
- Determinante de custo: Flat $0,006/minuto sem cobrança de conexão concorrente e nenhum desconto empresarial em camadas publicado.
- Integração: API HTTP mais simples do mercado. Multilíngue sem declaração de idioma graças aos 680.000 horas de dados de treinamento documentados no papel Whisper.
AssemblyAI
- Melhor para: Times orientados por desenvolvedor, streaming em tempo real com latência mínima, saída estruturada com timestamps no nível de palavra, rótulos de falante e pontuações de confiança.
- Fraqueza: Preço premium. Densidade de recursos é overkill para casos de uso de lote simples.
- Determinante de custo: Conexões de streaming concorrentes mais itens de linha de diarização.
- Integração: SDKs e documentação excelentes. Arquitetura focada em webhook. Ferramentas de observabilidade forte.
Rev.com (Máquina + Híbrido Humano)
- Melhor para: Fluxos de trabalho onde precisão é inegociável e turnaround pode esperar horas — deposições legais, jornalismo, conteúdo crítico para acessibilidade.
- Fraqueza: Não em tempo real. Revisão humana leva horas. Caro em escala.
- Determinante de custo: $0,25/minuto para máquina, $1,50/minuto para revisão humana.
- Integração: API REST simples. O atrito é tempo de turnaround, não a integração em si.
DubSmart AI Speech to Text API
- Melhor para: Criadores de conteúdo e times construindo fluxos de trabalho multilíngues onde transcrição é um passo em um pipeline mais longo — transcrever, traduzir, dublar, publicar. Preço baseado em crédito absorve cargas de trabalho variáveis.
- Fraqueza: Plataforma mais jovem que hiperscalers legados. Termos SLA empresariais podem não combinar com AWS ou GCP para times de compras avessos ao risco.
- Determinante de custo: Pool de créditos com rollover. Agrupa transcrição com clonagem de voz de uma amostra de 20 segundos, 300+ vozes TTS, e AI Dubbing através de mais de 60 idiomas fonte em 33 idiomas alvo.
- Integração: Construída propositalmente para fluxos de trabalho de mídia. SDK único cobre transcrição + TTS + clonagem + dublagem. Callbacks webhook para trabalhos async. Confiado por 500.000+ usuários.
Sua Lista de Verificação de Seleção de API de Fala para Texto
Este é o fluxo de trabalho para executar antes de assinar qualquer contrato. Compacta tudo acima em oito passos executáveis. Bloqueie quatro horas para a primeira passagem; espere uma semana de teste piloto na etapa 4.
- Defina seu caso de uso dominante em uma frase. Escreva: "Preciso transcrever podcasts" ou "legendar streams ao vivo" ou "analisar chamadas de vendas" ou "dublar vídeos enviados por usuários." Se você não conseguir escrever em uma frase, você tem dois produtos e precisa duas avaliações. Combine o caso de uso ao tier de latência da Seção 3 e à demanda de precisão da Seção 2 antes de olhar para qualquer preço de fornecedor.
- Circule os dois ou três eixos de decisão que mais importam. Do framework: precisão, latência, offline, cobertura de idioma, modelo de custo, superfície de integração. Se você tentar otimizar todos os seis, vai escolher o provedor mais caro com recursos que nunca vai usar. A maioria dos builders deve classificar modelo de custo e superfície de integração primeiro. Precisão e latência se tornam solucionadores de empate entre finalistas.
- Projete volume de 12 meses com buffer de surge de 3x. Estime minutos mensais para mês 1, mês 6 e mês 12. Multiplique o número do mês 12 por 3 para manejar spikes de lançamento e crescimento viral. Este número determina se você precisa de pool de créditos, preço por minuto, ou contrato empresarial com desconto de volume — e é o número que você vai citar fornecedores durante negociação.
- Execute o piloto de 7 dias. Trinta minutos de seu áudio real, três APIs candidatas, pontuadas manualmente contra uma única transcrição de referência corrigida por humano. Meça WER por falante, por sotaque e por termo de domínio — não apenas agregado. Teste streaming vs. lote nos mesmos arquivos. Documente atrito de SDK em um doc compartilhado conforme você vai, enquanto a dor é fresca.
- Teste tratamento de erro sob estresse. Envie áudio malformado, tokens expirados, bursts que burlam rate-limit e arquivos oversized. O SDK falha limpo com erros acionáveis, ou fica pendurado? Uma API que falha mal sob stress controlado vai falhar mal em produção às 3 da manhã, e o custo de limpeza vai reduzir qualquer economia por minuto que você trancou no lançamento.
- Calcule custo total real de propriedade. Inclua custo base por minuto, surcharges de streaming, itens de linha de diarização, armazenamento, egresso, overhead de retry, e as horas de engenharia economizadas ou perdidas por qualidade de SDK. Compare contra modelo de pool de créditos se sua carga de trabalho é variável — um plano de crédito de aproximadamente $99/mês frequentemente supera preço de $0,006/minuto quando tráfego é espigado e agrupa múltiplos recursos de mídia sob uma conta.
- Audite padrões de privacidade e retenção de dados. Confirme se o provedor retém áudio e transcrições para melhoria de modelo, e se você pode optar por sair contratualmente. Requisitos GDPR, HIPAA e SOC 2 podem eliminar provedores independente de preço. De acordo com orientação do Conselho Europeu de Proteção de Dados sobre assistentes de voz, provedores STT de nuvem podem criar "datasets de sombra" de dados de voz a menos que explicitamente restringidos em contrato — esta é uma pergunta de compras, não uma pergunta de recurso.
- Negocie antes de se comprometer. A maioria dos provedores oferece descontos de 15–30% em compromissos de 12 meses acima de 500 horas/mês. Se você completou etapas 1–7 com confiança, você tem alavanca. Peça preço trancado, contato de suporte dedicado, tier gratuito expandido para ambientes de staging, e cláusula de saída se precisão degrad abaixo de um limiar acordado. Se seu roadmap inclui localização, avalie APIs como a AI Dubbing API que traduzem e dublam em uma chamada.
Esta lista é sua defesa contra marketing de fornecedor e sua ofensiva contra atrasos de envio. Os times que enviam recursos de voz mais rápido não são os que escolheram a API mais barata — são os que executaram um piloto real, calcularam TCO verdadeiro e escolheram uma superfície de integração que seus desenvolvedores queriam trabalhar. Se seu build também envolve dublagem, clonagem de voz ou geração de fala sintética, avalie plataformas que agrupam Conversão de Texto em Fala, clonagem de voz e dublagem sob um saldo de crédito único e um SDK — o segundo e terceiro recursos que você vai precisar dentro de seis meses vão custar menos e enviar mais rápido.