
Co Słyszą Słuchacze, Kiedy Imitacja Głosu Się Udaje
Próba 17. Imitacja Morgan Freemana jest bliska — kadencja jest tam, południownik z Missisipi jest prawie przekonujący — ale brakuje powagi. Twój słuchacz mówi „prawie", co w pracy głosowej jest tym samym słowem co „nie". Usuwasz próbę. Spróbujesz ponownie. Czterdzieści minut później nie masz niczego użytecznego do YouTubowego lektora i twoje gardło zaczyna się męczyć.
To jest pułapka, która pochłania twórców próbujących budować kanał wielojęzyczny: opanowanie charakteru głosu w angielskim, a potem obserwowanie jego upadku w momencie, gdy wejdzie do planu produkcji dubbing do hiszpańskiego lub hindi — ponieważ imitacja była fonetycznym zapamiętywaniem, a nie ucieleśnioną sygnaturą głosu. Studio hours się kumulują. Próby zostają odrzucone. Plany lokalizacji cicho trafiają na półkę. Treść, która powinna zostać wydana, tego nie robi.
Ten przewodnik wyjaśnia, co sprawia, że imitacje głosu rzeczywiście trafiają do ucha słuchacza, cztery ćwiczenia, które budują podstawową umiejętność, i gdzie klonowanie głosu AI wpisuje się w przepływ pracy jako narzędzie skalowania — a nie zamiennik umiejętności poniżej.

Spis Treści
- Co Słyszą Słuchacze, Kiedy Imitacja Głosu Się Udaje
- Pięć Vokalno-Budujących Elementów, Na Których Opiera Się Każda Imitacja
- Cztery Ćwiczenia, Które Budują Pamięć Mięśniową Imitacji Głosu
- Gdzie Ręczna Praktyka Imitacji Głosu Napotyka Twardy Sufit
- Jak Klonowanie Głosu AI Wzmacnia Zasięg Doświadczonego Imitatora
- Zbuduj Swój Zestaw Narzędzi do Imitacji Głosu — Dopasuj Wąskie Gardło do Właściwej Ścieżki
- FAQ
Słuchacze nie identyfikują głosów tylko na podstawie wysokości dźwięku. Identyfikują je za pomocą spektralnego odcisku palca — struktury formantu, wzorów drgań i podpisów czasowych, które produkuje określona anatomia narządu mowy. Według naukowca głosu Ingo R. Titze w Principles of Voice Production, jakość głosu jest kształtowana przede wszystkim przez konfigurację narządu mowy i rezonans, a nie częstotliwość podstawową. Dwie osoby mogą nucić dokładnie tę samą notę i nadal brzmieć zupełnie inaczej, ponieważ ich gardła, usta i zatoki działają jako różne filtry na tę samą wibrację.
To jest otwarcie dla imitacji głosu. Zadanie nie polega na dopasowaniu jednej zmiennej. Chodzi o odtworzenie pięciowarstwowego podpisu:
- Kontur wysokości — nie tylko średnia wysokość, ale gdzie się podnosi i opada w zdaniu
- Umiejscowienie rezonansu — pierś, maska, nosowy, głowa
- Wzór oddychania i tempo — gdzie mówca wdycha i jak długo trwają ich pauzy
- Podpis artykulacji — atak spółgłoski i kształt samogłoski
- Podtekst emocjonalny — uczucie napędzające każde słowo, warstwa, którą pomijają amatorzy
Pełna tabela diagnostyczna znajduje się w następnej sekcji. Na razie pamiętaj: podpis, a nie powierzchnia.
Brzmienie Jak Kogoś Versus Granie Jako Ktoś
Istnieje rozróżnienie, które pracujący świat głosowy traktuje jako nie do negocjowania: brzmienie jak ktoś i granie jako ktoś to różne umiejętności. Dee Bradley Baker — aktor głosowy postaci stojący za większością Star Wars: The Clone Wars i Avatar: The Last Airbender — zbudował swoją całą praktykę nauczania na argumentu, że głosy postaci działają tylko wtedy, gdy performer rozumie życie emocjonalne postaci, intencję i fizyczność. Nie tylko akcent. Nie tylko ton. Według jego materiałów edukacyjnych w I Want to Be a Voice Actor!, imitacja, która skupia się na dźwięku bez intencji, produkuje coś, co słuchacz rejestruje jako mechaniczne, nawet jeśli nie potrafi tego wyrazić.
Dwie Dekonstrukcje, Które Czynią Teorię Konkretną
Rozważ amatorkę imitacji Dartha Vadera. Brzmią cienkie, ponieważ skupiają się na dwóch złych zmiennych: wysokości (niska) i efekcie oddychania (ciężki wydech). Co im umyka, to rezonans piersi, gdzie naprawdę żyje głos Jamesa Earla Jonesa. Efekt oddychania jest warstwą namalowaną na wierzchu fundamentu ukierunkowanego na pierś — a nie jego zamiennikiem. Bez tego rezonującego zakotwiczenia, imitacja brzmmi jak ktoś szepczący z wysiłkiem zamiast mówienia z wnętrza katedry.
Cichszy głos odwraca priorytet. Z Davidem Attenborough'em, tempo niesie mniej więcej 70% obciążenia. Powolny wdech przed kluczowymi przymiotnikami. Podniesienie na słowach pełnych zdumienia. Opadające zakończenia fraz. Kopiowanie akcentu received-pronunciation bez rytmu daje dokumentalną parodię — a nie Attenborough'a.
Dlaczego To Ma Znaczenie Dla Klonowania AI
Ten sam perceptualny rozkład, który buduje lepsze imitacje człowieka, produkuje również lepsze klony głosowe AI. Model uczy się podpisu, a nie powierzchni. Więc twórca, który internalizował umiejscowienie rezonansu i tempo, nie jest tylko lepszy w graniu postaci — nagrywają lepsze dane treningowe, gdy siadają do klonowania tego głosu postaci. Umiejętność się przenosi. Głębsza część artykułu wyjaśnia, jak.
Pięć Vokalno-Budujących Elementów, Na Których Opiera Się Każda Imitacja
Poprzednia sekcja nazwała warstwy. Ta sekcja zmienia je w narzędzie diagnostyczne, które możesz zastosować do dowolnego audio referencyjnego w mniej niż pięć minut.
| Element | Co To Jest | Jak Zidentyfikować w Referencji | Częsty Błąd Amatora |
|---|---|---|---|
| Wysokość i Register | Naturalna częstotliwość podstawowa i zakres, w którym porusza się mówca | Nucaj razem; znajdź najniższą notę utrzymywaną i typową notę „domową" | Blokowanie się na jedną wysokość zamiast śledzenia konturu |
| Rezonans i Ton | Gdzie głos fizycznie wibruje — pierś, maska, nosowy, głowa | Połóż rękę na piersi, gardle, kościach policzkowych podczas odtwarzania referencji; czuj, który obszar by brzęczał | Kopiowanie barwy z gardła zamiast właściwej komorze |
| Oddychanie i Tempo | Punkty wdechu, długość pauzy, słowa na minutę, rytm frazowania | Zaznacz każdy oddech w klipu 30-sekundowym; policz sylaby między oddechami | Mówienie zbyt szybko, zapaść tempa postaci |
| Artykulacja i Czystość | Siła ataku spółgłoski, otwartość samogłoski, umiejscowienie języka dialektu | Spowolnij referencję do 0,5x prędkości; wyodrębnij początki spółgłosek | Generyczna „dobra dykcja" zamiast konkretnych wyborów postaci |
| Podtekst Emocjonalny | Podstawowe uczucie kolorujące każdą linię | Zapytaj: czego chce ta postać w tym momencie? | Granie słów zamiast intencji pod nimi |
Kolejność w tabeli nie jest kosmetyczna. Wysokość i rezonans są anatomiczne — są ustawiane przez to, gdzie umieszczasz głos w ciele. Jeśli źle je umieścisz, żaden sposób nie może uratować imitację w dalszej części. Tempo i artykulacja są behawioralne — regulowane poprzez powtarzanie. Podtekst emocjonalny jest interpretacyjny — warstwa, która podnosi technicznie dokładną imitację do wiarygodnej.
Spróbuj diagnostyki na konkretnym celu. Twórca próbujący imitować Cate Blanchett jako Galadriel znajduje wysokość szybko: średnio-niska, oddechowa. Pułapką jest rezonans. Jej głos siedzi w masce — obszarze za kościami policzkowymi — a nie w gardle. Większość amatorkiego podejścia pociąga rezonans w dół do gardła, co brzmmi mniejsze i młodsze. Po prawidłowym umiejscowieniu rezonansu w masce, powolne tempo i wydłużone samogłoski następują naturalnie, ponieważ sama komora dyktuje rytm. Naprawiasz warstwę anatomiczną i warstwy behawioralne się samonaprawiają.
Uwaga Dla Wszystkich Planujących Klonowanie Swojej Imitacji
Powyższa diagnostyka działa również w odwrocie. Kiedy nagrywasz audio treningowe dla klonu głosu, model przechwyca niezależnie od tego, jakie podpisy są najbardziej spójne w zestawie danych. Według przewodnika Voiceover Masterclass po klonowaniu, twórcy powinni nagrywać w spójnym, neutralnym stylu w całej ciągłej sesji — chyba że wyraźnym celem jest klonowanie stylizowanego głosu postaci. Tłumaczenie: jeśli chcesz klona swojej imitacji postaci zamiast codziennego głosu, musisz pozostać w charakterze przez całe nagranie treningowe. Wychodzenie i wchodzenie do niego produkuje miękki klon, który nie brzmmi ani tak, ani tak.
To jest również powód, dla którego perceptualne warstwy Sekcji 1 mają znaczenie operacyjne. Twórca, który się zmienia, produkuje zmienne dane. Twórca z internalizowanym umiejscowieniem rezonansu produkuje stabilne dane. Klon jest tylko tak dobry, jak konsystencja podpisu, który się uczy.
Cztery Ćwiczenia, Które Budują Pamięć Mięśniową Imitacji Głosu
Znanie pięciu elementów głosu to diagnoza. Te cztery ćwiczenia to leczenie. Każde doceluje określony tryb awarii i zajmuje 15 minut lub mniej.
Ćwiczenie 1 — Pętla Izolacji
Doceluje: dokładność wysokości i rezonansu.
- Wybierz frazę 5-wyrazową z referencji (np. „I have been expecting you")
- Pętli referencji 10 razy, aby osadzić docelowy dźwięk w uchu
- Nagrywaj swoją wersję skupioną na wysokości tylko — ignoruj rezonans, ignoruj postać, just match the melodic contour
- Ponownie nagraj skupioną na rezonansie tylko — ta sama fraza, celuj w właściwą komorę
- Ponownie nagraj skupioną na tempie i oddechu — ta sama fraza, dokładnie dopasuj czas
- Czas: 15 minut dziennie
Dlaczego to działa: zasady motor-learning w pedagogice głosu wspierają ćwiczenia blokowe (jedna zmienna na raz) nad ćwiczeniami zmiennymi podczas nauki nowych koordynacji, stanowisko spójne z ramy Titze w Principles of Voice Production. Izolacja jednej zmiennej trenuje grupę mięśni za nią odpowiedzialną bez obciążenia kognitywnego żonglowania wszystkimi pięcioma.
Ćwiczenie 2 — Test Ślepej Referencji
Doceluje: trening słuchu, samo-złudzenie.
- Nagrywaj trzy próby fragmentu 15-sekundowego w charakterze
- Czekaj przynajmniej 4 godzin — świeże uszy
- Odtwarzaj referencję, potem swoją najlepszą próbę, na zmianę bez patrzenia na przebiegi
- Oceniaj szczerze: który brzmmi bardziej jak oni?
Większość twórców odkrywa, że ich „najlepsza próba" nie była tą najbliższą. Nagradzali próbę, gdzie czuli najwięcej wysiłku zamiast próby, która trafiła najdokładniej. Test ślepy przerywa ten błąd. Uruchamiaj go co tydzień.
Ćwiczenie 3 — Kotwica Emocjonalna
Doceluje: podtekst emocjonalny, autentyczność grania.
Przed nagrywaniem nazwij stan emocjonalny postaci w scenie. Gandalf krzyczący „You shall not pass!" nie jest gniewem — to ochronna determinacja pod zmęczeniem. Dwa stany brzmią zupełnie inaczej, nawet gdy słowa są identyczne. Ucieleśnij fizycznie: postawa, głębokość oddechu, gdzie trzymasz napięcie w ciele. Powtarzający się punkt Dee Bradley Bakera w I Want to Be a Voice Actor! jest taki, że głos postaci bez intencji postaci brzmmi mechanicznie. Nagraj tylko po ustaleniu kotwicy. Każda sesja.
Ćwiczenie 4 — Test Ciśnienia Wielojęzycznego
Doceluje: internalizacja podpisu versus fonetyczne zapamiętywanie.
Weź swoją imitację i wykonaj ją na zupełnie innym skrypcie — lista zakupów, raport pogodowy, teksty Twoich ulubionych piosenek — w tym samym głosie. Jeśli imitacja się zapada w momencie, gdy słowa się zmieniają, zapamiętałeś sekwencję fonetyczną, a nie internalizowałeś podpisu głosu.
To ćwiczenie jest strażnikiem pracy lokalizacyjnej. Jeśli Twoja imitacja nie przetrwa zastosowania na liście zakupów w angielskim, nie przetrwa dubbingu do portugalskiego. Cotygodniowy rytm.
Jeśli Twoja imitacja nie może przetrwać zastosowania na liście zakupów, nie przetrwa dubbingu do drugiego języka.
Twój Tygodniowy Harmonogram Treningowy Imitacji Głosu
- Codzienne 15-minutowe pętle izolacji na jeden element głosu (rotacja: wysokość → rezonans → tempo → artykulacja)
- Ustal kotwicę emocjonalną przed każdą sesją nagrywania
- Jeden test ślepej referencji na tydzień z 4+ godzinami rozdzielenia między próbami i przeglądem
- Jeden test ciśnienia wielojęzycznego na tydzień przy użyciu materiału nieskryptowego
- Nagrywaj „podpis take" 30-sekundowy każdy piątek — ten sam fragment, ta sama postać — aby śledzić postęp z tygodnia na tydzień
- Utrzymuj sufitowe hałasy na poziomie −60 dB lub poniżej w swojej przestrzeni nagrywania (panele akustyczne, brak HVAC, brak wentylatorów), zgodnie ze standardem Voiceover Masterclass — to ma znaczenie zarówno dla treningu ucha człowieka, jak i dla każdego przyszłego klonowania
Gdzie Ręczna Praktyka Imitacji Głosu Napotyka Twardy Sufit
Powyższe ćwiczenia budują rzeczywistą umiejętność, którą żadne narzędzie nie może zaślepić. Mają również sufit. Jeden doświadczony performer ma ograniczoną przepustowość — wąskie gardło nie jest talent, to biologia i zegar. Cztery scenariusze pokazują, gdzie ten sufit staje się ograniczeniem biznesowym.
Problem wideo 30 minut. Twórca utrzymujący głos postaci przez 30 minut dialogu zmęczony się wokalisem. Próba 40 nie odpowiada próbie 4. Wysokość dryfuje w górę, oddech się skraca, rezonans piersi migruje do gardła. Naprawy w pokoju edycji kosztują godziny.
Problem 6-języka lokalizacja. Nawet twórca biegły w języku hiszpańskim nie może koniecznie wykonać swojego angielskiego głosu postaci przekonującą w języku hiszpańskim. Pomnóż to przez sześć docelowych języków, a plan lokalizacji staje się rokiem pracy głosowej — zakładając, że wielojęzyczna umiejętność grania w ogóle istnieje.
Problem rewizji klienta. Zmiana linii w tygodniu 8 oznacza ponowne nagranie w tym samym stanie głosu — ten sam pokój, ta sama pora dnia, ta sama wilgotność gardła. Praktycznie niemożliwe do idealnego dopasowania.
Problem wielopostaci. Twórca głosujący cztery postacie w jednej scenie dialogowej potrzebuje minimum czterech oddzielnych przejść nagrywania, a przejścia głosowe wyczerpują krtań szybko.
Metody Produkcji Imitacji Głosu Porównane
| Czynnik | Imitacje Nagrane Samodzielnie | Zatrudnienie Aktora Głosowego | Klonowanie Głosu AI |
|---|---|---|---|
| Czas do pierwszej użytecznej próby | Tygodnie do miesięcy rozproszonej praktyki | 1–3 dni (casting + nagrywanie) | Sekundy dla początkującego klona z 10-sekundowej próbki; 30–120 min dla klasy prosumer |
| Próbka nagrywania potrzebna | N/A — wykonanie na żywo | N/A — wykonanie na żywo | 30–120 sec (turnkey); 10–15 min (RVC); 30 min–2 hr (profesjonalne) |
| Spójność próba-do-próby | Zmienna — dryf z zmęczeniem | Wysoka w sesji; zmienna między sesjami | Idealnie powtarzalna dla danego tekstu i parametrów |
| Skalowanie Wielojęzyczne | Wymaga płynności + umiejętności imitacji w każdym | Aktor wielojęzyczny lub wielu aktorów | Klonowanie wielojęzyczne AI Dubbing zachowuje barwę na docelowych |
| Najlepsze dopasowanie | Granie na żywo, krótkie formy, trening ucha | Produkcje jednorazowe premium | Długie formy, wielojęzyczne, iteracyjne treści |
Źródła liczb powyżej: tutorial ElevenLabs, DeepReel, CloudPano, Kukarella, i tutorial RVC.
To nie jest werdykt, że AI wygrywa. Ręczna praktyka produkuje umiejętności, które przenoszą się do grania na żywo, podcastów, teatru i treningu ucha, który czyni każdą inną metodę lepszą. Tabela izoluje konkretne scenariusze produkcji, gdzie biologia staje się ograniczeniem.
Dowody kontrowe również mają znaczenie. Aktorzy głosu i SAG-AFTRA publicznie zauważyli, że obecne klony AI nadal mają trudności z złożonymi niuansami emocjonalnymi, podtekstem i dynamiczną pracą sceniczną — szczególnie w dramie i komedii, gdzie mikroczas niesie znaczenie. Dla twórcy produkującego sześciojęzyczne wideo objaśniające, to ograniczenie jest dopuszczalne. Dla twórcy produkującego animację narracyjną z trzema emocjonalnymi zwrotami na scenę, to nie jest jeszcze. Uczczona synteza: pytanie to nie „ręczna lub AI". To „gdzie każda metoda należy do przepływu pracy?"
Wąskim gardłem w pracy imitacji głosu nie jest talent — to biologia i zegar.
Jak Klonowanie Głosu AI Wzmacnia Zasięg Doświadczonego Imitatora
Co Klonowanie Rzeczywiście Przechwyca
Klon głosu nie jest nagraniem. Jest to oprendowywany model podpisu głosu. Model przechwyca profil rezonansu, wzorce konturu wysokości, rytm oddechu i tendencje artykulacji z audio treningowego, następnie aplikuje je do nowego tekstu. Naukowca mowy Rupal Patel, założycielka VocaliD, argumentowała w swoim wykładzie TED i powiązanych wywiadach, że autentyczne głosy syntetyczne muszą przechwyć idiosynkratyczną prozodię, a nie tylko średnią wysokość, aby brzmieć rzeczywiście niż generycznie.
To jest dokładnie dlatego, że dobrze zrobiona imitacja jest lepszym kandydatem do klonowania niż płaska, neutralna próba. Podpis, który model się uczy, to podpis postaci. Twórca, który zrobił ćwiczenia z Sekcji 3, wchodzi do sesji klonowania głosu z czystszymi, bardziej spójnymi danymi niż ktoś, kto tego nie zrobił — i wynikowy klon bezpośrednio to odzwierciedla.
Rzeczywistość Zestawu Danych
Istnieją trzy warstwy jakości, każda z konkretnymi wymaganiami próbki.
- Klonowanie początkujące / natychmiastowe: ~10 sekund czystej mowy daje klon testowy, z którym możesz eksperymentować w sekundach, zgodnie z tutorialem ElevenLabs.
- Klon narracyjny klasy twórcy: 30–120 sekund czystego audio produkuje stabilny klon w stylu naratora, zgodnie z DeepReel i CloudPano.
- Klon klasy profesjonalnej: 30 minut do 2 godzin nagrań, z wynikami wyraźnie lepszymi bliżej znaku 2 godzin; czas przetwarzania na infrastrukturze dostawcy wynosi mniej więcej 2–6 godzin, zgodnie z tutorialem ElevenLabs.
- Stos open-source RVC: 10–15 minut czystego audio to sweet spot praktyka; 2–10 minut jest możliwe z kompromisami jakości; 40 kHz tempo próbkowania to default praktyka, zgodnie z tutorialem RVC.
Techniczny floor jest nie do negocjowania: sufitowe hałasy ≤ −60 dB, i żadna kompresja, EQ, de-essing lub redukcja hałasu zastosowana do surowych plików treningowych, zgodnie ze standardem Voiceover Masterclass. Śmieci na wejściu, śmieci na wyjściu stosuje się dwa razy — model amplifikuje whatever artifacts istnieją w źródle.

Dwie Studia Przypadków Przepływu Pracy
Przypadek A — YouTuber 30 Minut. Twórca opanowuje imitację postaci na 30 sekund ale traci spójność przez długoformowy odcinek. Przepływ pracy: nagraj jedną doskonałą 90-sekundową próbę głosu postaci. Sklonuj to. Generuj dialog tła z klonem używając Text to Speech, rezerwując energię grania na żywo dla pięciu lub sześciu kluczowych emocjonalnych tonów, które niosą odcinek. Rezultat: spójny głos przez 30 minut, szczyty grania gdzie mają znaczenie, sesja nagrywania ścieśnięta z mniej więcej 8 godzin do około 90 minut.
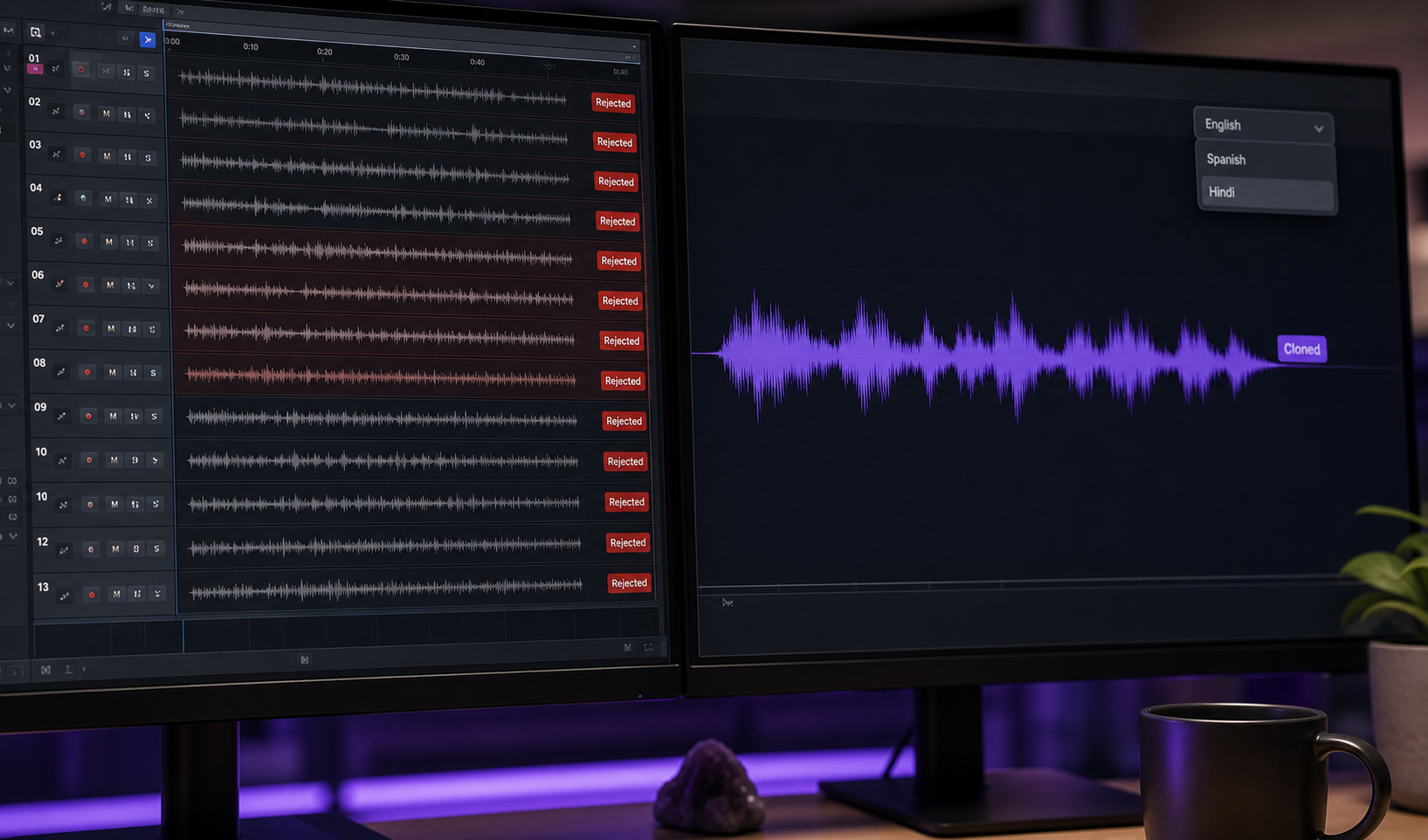
Przypadek B — 6-Języka Wideo Treningowe. Mała firma produkuje 15-minutowy wewnętrzny moduł treningowy narracją w ciepłym, autorytatywnym głosie postaci. Przepływ pracy: nagraj wersję angielską raz z imitacją na żywo. Sklonuj głos. Użyj klonowania wielojęzycznego via Voice Cloning API aby renderować wersje hiszpańskiej, portugalskiej, francuskiej, niemieckiej, hindi i japońskiej zachowując timbre postaci na docelowych, zgodnie z DeepReel i Kukarella. Ta sama postać „mówi" wszystkich sześć języków, ponieważ podpis się przenosi, nawet jeśli język się nie przenosi.
Klonowanie głosu nie zamienia umiejętności opanowania imitacji — ją wzmacnia. Trudna część to wciąż dostanie postaci prawo; technologia po prostu usuwa powtórzenie.
Etyka i Granica Legalności
Syntetyczny głos może być bronią. Profesor prawa Danielle Citron, w The Fight for Privacy i powiązanym badaniu deepfake, dokumentowała, jak niezgodne klonowanie głosu rzeczywistych osób umożliwia impersonację, oszustwo i polityczne dezinformację — i argumentowała zarówno za zabezpieczeniami prawnymi, jak i ochroną na poziomie designu na narzędziach komercyjnych.
Etyczna linia dla twórców jest prosta. Klonowanie własnego głosu dla własnej treści jest jednoznacznie OK. Klonowanie fikcyjnego głosu postaci, który sam opracowałeś, jest OK. Klonowanie rzeczywistej osoby publicznej, lub kogokolwiek, bez wyraźnej zgody nie jest. Ujawnianie w napisach, gdy dubbing AI jest używany, staje się standardową praktyką i jest bezpieczniejszym defaultem dla każdej pracy komercyjnej.
Zbuduj Swój Zestaw Narzędzi do Imitacji Głosu — Dopasuj Wąskie Gardło do Właściwej Ścieżki
Wybór nie jest ręczna praktyka lub klonowanie głosu AI. To zidentyfikowanie, które wąskie gardło faktycznie blokuje twoją pracę teraz, i zastosowanie zgodnej ścieżki. Poniższa matryca mapuje cztery powszechne sytuacje twórcy do konkretnych pierwszych działań.
Która Ścieżka Imitacji Głosu Pasuje Do Twojego Wąskiego Gardła?
| Twoja Sytuacja | Podstawowe Wąskie Gardło | Priorytet Narzędziowy | Pierwsze Działanie Ten Tydzień |
|---|---|---|---|
| Imitacje nie są jeszcze przekonujące — budowanie rzemiosła dla YouTube lub Twitch | Luka umiejętności | Ćwiczenia z Sekcji 3 + informacja zwrotna od kolegów | Wybierz jedną postać; uruchom codzienną pętlę izolacji na 14 dni przed oceną |
| Silna imitacja, ale wyczerpana ponownym nagrywaniem długich wideo | Zmęczenie głosowe, dryfujemy | Klonowanie głosu na twojej własnej wykonanej imitacji | Nagraj jedną czystą 90-sekundową próbę w charakterze na −60 dB; sklonuj ją; testuj na 2-minutowym generowanym fragmencie |
| Lokalizowanie istniejącej angielskiej treści na wiele języków | Luka wielojęzycznego grania | Klonowanie wielojęzyczne + dubbing AI | Sklonuj swoją imitację referencji raz; dubbuj 2-minutową próbkę do swojego najwyższego priorytetu docelowego języka; przegląd dla zachowania postaci |
| Zespół produkujący treści wielojęzyczne marki na dużą skalę | Skalowalność potoku | Klonowanie + integracja API | Prototypuj przepływ pracy AI Dubbing API na jednym projekcie produkcji |
Trzy działające zasady dla uczciwego użytku tej matrycy.
Matryca nie jest trwała. Twórca w rzędzie jeden dziś przesuwa się do rzędu trzy w osiemnaście miesięcy. Wąskie gardło zmienia się w miarę zmiany pracy. Ponownie oceń kwartalnie.
Klonowanie amplifikuje; nie inicjuje. Powtarzane zjawisko na wszystkich tutorialach klonowania — Voiceover Masterclass, przewodnik ElevenLabs, tutorial RVC — to że jakość audio i jakość grania w źródle determinują jakość klona. Twórca, który pomija ćwiczenia Sekcji 3 i próbuje sklonować niedojrzałą imitację, dostaje klona niedojrzałej imitacji. Technologia jest wierna swojemu wejściu.
Sufit 30-sekundowy ma znaczenie operacyjnie. Kilka platform turnkey może produkować pracujący profil głosu z mniej więcej 20–30 sekund czystego audio. To oznacza, że twórca, który ma już jedną dobrą próbę swojego głosu postaci, jest jednym uploadem od ponownie użytecznego zasobu produkcji. Bariera to nie technologia — to posiadanie tej jednej dobrej próby.
Zaadresuj również przeciwpresję. Niektórzy trenerzy głosowe ostrzegają, że silne poleganie na klonowaniu wcześnie może ograniczyć rozwój umiejętności fundamentalnych: wsparcie oddechu, kontrola rezonansu, artykulacja. Pragmatyczna ścieżka środka to utrzymanie ćwiczeń nawet gdy używasz klona dla produkcji, ponieważ ćwiczenia czynią każdy przyszły klon lepszym.
Twój Plan Działania Dwa Tygodnie
- Zidentyfikuj, który rząd matrycy opisuje twoje obecne wąskie gardło — bądź szczery; większość twórców siedzi w dwóch rzędach naraz. Wybierz bardziej bolesny.
- Jeśli twój rząd to „luka umiejętności": zobowiąż się do codziennej 15-minutowej pętli izolacji i jednego tygodniowego testu ślepej referencji na pełne 14 dni przed ponowną oceną.
- Jeśli twój rząd obejmuje klonowanie: nagraj czystą 30–90 sekundową próbę referencji z sufitami hałasu na lub poniżej −60 dB, w charakterze, w jednej ciągłej sesji, bez EQ lub kompresji zastosowanej.
- Uruchom niskorizykowy test klona przed jakąkolwiek pracą klienta lub przychodową — użyj go do wewnętrznego wideo, testowego kanału osobistego, lub projektowego skryptu.
- Jeśli lokalizujesz: wybierz swój najwyżej priorytetowy docelowy język i dubbuj 2-minutową próbkę. Przegląd specjalnie dla zachowania postaci, nie tylko dokładności tłumaczenia.
- Jeśli integrujesz do potoku produkcji: prototypuj przepływ pracy API na jednym projekcie przed standaryzacją. Testuj Text to Speech API i Voice Cloning API na reprezentacyjnym typie treści.
- Ustaw 14-dniowy punkt kontrolny do ponownej oceny wąskiego gardła — mogło się poruszyć.
Twórcy, którzy wygrywają treść wielojęzyczną w 2025, to nie ci, którzy wybrali właściwe narzędzie. To ci, którzy zbudowali rzeczywistą imitację najpierw, następnie pozwolili narzędziom robić to, co narzędzia robią najlepiej — powtarzać to, skalować to, i zachowywać to na wszystkich językach, których nie mówią.
FAQ
Czy mogę użyć klonowania głosu AI do imitacji rzeczywistych osób publicznych?
Prawnie i etycznie: nie bez wyraźnej zgody, i nawet wtedy, ujawnij to. Wiedza Danielle Citron o deepfake'ach i mediach syntetycznych dokumentuje, jak niezgodne klonowanie głosu rzeczywistych osób umożliwia oszustwo, nękanie i polityczną dezinformację. Dla fikcyjnej postaci, którą sam opracowałeś, lub twojego własnego głosu, klonowanie jest jednoznaczne. Dla imitacji żyjącej osoby publicznej, bezpieczniejsza odpowiedź to nie — i reputacyjne platformy egzekwują polity zbieżne z tą zasadą. Ujawnianie w napisach jest standardową praktyką dla każdej pracy komercyjnej, która używa głosu syntetycznego.
Jak długo naprawdę trwa sklonowanie użytecznego głosu?
To zależy od warstwy jakości. Próbka 10-sekundowa produkuje eksperymentalny klon, którym możesz testować w sekundach, zgodnie z tutorialem ElevenLabs. Próbka 30–120 sekund produkuje stabilny klon klasy twórcy odpowiedni dla narracji i treści objaśniającej, zgodnie z DeepReel i CloudPano. Klon klasy profesjonalnej chce 30 minut do 2 godzin nagrywania źródła plus mniej więcej 2–6 godzin czasu przetwarzania na infrastrukturze dostawcy. Większość platform twórcy siedzi wygodnie na szybkim końcu warstwy twórcy, akceptując mniej więcej 20–30 sekund czystego audio jako działający floor.
Czy muszę ujawniać, że użyłem klonowania głosu AI w mojej treści?
Nie ma jeszcze powszechnego wymagania prawnego, ale ujawnianie staje się standardową praktyką i jest bezpieczniejszym defaultem. Jeśli sklonowałeś swój własny głos dla efektywności, prosty wiersz napisów — „Głos sklonowany via [platforma] dla wersji wielojęzycznych" — chroni zaufanie odbiorców. Jeśli treść reprezentuje rzeczywistą osobę, nawet z jej zgodą, ujawnianie jest niezbędne. Stanowisko SAG-AFTRA wokół użytku głosu AI w pracy komercyjnej pchnął szerszą branżę w kierunku jasnego etykietowania, a wyrównanie Twojej praktyki z tym kierunkiem wcześnie unika zarówno reputacyjnego, jak i późniejszego ekspozycji prawnej.