
Speech to Text API: Jak wybrać właściwy w 2025 roku
Zbudowałeś aplikację, którą użytkownicy pokochali — ale wciąż pojawiają się prośby o funkcje: "Czy mogę po prostu mówić zamiast pisać?" Więc zaczynasz oceniać interfejsy API zamieniające mowę na tekst. W ciągu pierwszej godziny natrafiasz na co najmniej cztery sprzeczne modele cen, roszczenia dotyczące dokładności od "95%" do "99%+" bez wspólnej definicji tego, co się mierzy, oraz jakość SDK, która waha się od dodania trzech linijek do poświęcenia tygodnia czytaniu marnych dokumentów.
Stawki są realne na obu końcach. Jeśli wybierzesz źle w dużej skali, będziesz tracić 3000–8000 dolarów/miesiąc na dodatkach przesyłania strumieniowego, lub wyślesz funkcję głosu, która zawiedzie w 1 na 5 wypowiedziach. Według Koenecke i in. w PNAS (2020), wskaźniki błędów w pięciu głównych komercyjnych systemach rozpoznawania mowy osiągnęły 35% dla mówiących Afroamerykańskim Dialektem Angielskim vs. 19% dla białych mówiących — różnica, która zamienia "problem z dokładnością" w problem "30% twoich użytkowników nie może używać twojego produktu".
Ten przewodnik daje ci ramy decyzyjne, metodę obliczania cen, protokół pilotażowy oraz porównanie 6 dostawców rywalizujących ze sobą — łącznie z tym, jak model oparty na kredytach pasuje do budów o zmiennych obciążeniach.

Spis treści
- Pięć osi decyzyjnych, które naprawdę kierują wyborem Speech to Text API
- Dokładność w kontekście — Dlaczego "benchmark 99%" kłamie o twoim audio produkcyjnym
- Opóźnienie, przesyłanie strumieniowe i mnożnik kosztów rzeczywistego czasu
- Modele kosztów wyjaśnione — Za minutę vs. Równoczesne vs. Pule kredytów
- Rzeczywistości integracji — Audyt SDK i API z 9 pytaniami
- Migawka dostawcy — Kiedy wybrać każdy Speech to Text API
- Twoja lista kontrolna wyboru Speech to Text API
Pięć osi decyzyjnych, które naprawdę kierują wyborem Speech to Text API
Większość postów porównawczych wymienia 30+ funkcji i uważa to za badania. Odrzuć to. Tylko sześć osi określa, czy interfejs API zamieniający mowę na tekst będzie działać dla twojej konkretnej budowy — a w każdym projekcie tylko dwa lub trzy z nich naprawdę mają znaczenie.
Dokładność w twojej dziedzinie. Aplikacja transkrypcji medycznej wykorzystująca ogólne API błędnie renderuje "metoprolol" jako "meta peral". Zagregowany wskaźnik błędów wyrazów to kryje. Jak argumentuje Dan Jurafsky w Speech and Language Processing, WER traktuje wszystkie błędy jednakowo — ale w kontekście klinicznym lub prawnym jeden błędny kod leku lub jedna pominięta negacja ma znacznie większy wpływ. To, co ma znaczenie, to WER specyficzny dla domeny na twoim audio, nie nagłówek benchmarku.
Profil opóźnienia. Narzędzie podpisów na żywo do ułatwień dostępu wymaga odpowiedzi end-to-end poniżej 1 sekundy. Potok transkrypcji podkastów może czekać 10 minut. Według Nielsen Norman Group "Response Times: The 3 Important Limits", odpowiedzi poniżej 100 ms wydają się natychmiastowe, poniżej 1 sekundy zachowują przepływ, a powyżej 10 sekund powodują porzucenie zadania. Połącz swój przypadek użycia z warstwą zanim zaczniesz robić zakupy.
Możliwość offline / na urządzeniu. Aplikacja badań terenowych na obszarach wiejskich nie może zależeć od podróży w chmurze. SpeechAnalyzer API Apple (WWDC 2025) to opcja na urządzeniu dla iOS/macOS. Samodzielnie hostowany Whisper lub Vosk daje ci pełną kontrolę offline, jeśli chcesz zarządzać GPU.
Pokrycie językami i przełączanie kodu. Whisper obsługuje 50+ języków o porównywalnej jakości po treningu na 680 000 godzinach audio wielojęzycznego (Radford i in., OpenAI 2022). Google i AWS używają warstwowych grup języków, gdzie języki Tier B uzyskują niższą dokładność i czasami oddzielne ceny.
Architektura modelu kosztów. Płatność za minutę, połączenia równoczesne i pule kredytów każda z nich pęka inaczej w dużej skali. YouTuber przesyłający 4 godziny jeden tydzień i 40 godzin następny jest karany zarówno modelowaniem za minutę w wolnych tygodniach, jak i w tygodniach skoków. Pule kredytów z przeniesieniem absorbuję tę zmienność.
Obszar powierzchni integracji. Jakość SDK, webhooks vs. polling, domyślne obsługi błędów. To jest miejsce, gdzie "łatwy interfejs API" zamienia się w trzy stracone tygodnie.
Pięć osi napędza każdą decyzję Speech to Text API, która warta jest podjęcia — i tylko dwie lub trzy z nich mają zastosowanie do twojej budowy.
| Oś decyzji | Dlaczego to ma znaczenie | Częsta pułapka | Najlepszy przypadek użycia |
|---|---|---|---|
| Dokładność domeny | Roszczenia dostawcy "99%" używają czystej mowy czytanej | Ufanie LibriSpeech dla nośnego audio mobilnego | Aplikacje medyczne, prawne, finansowe |
| Profil opóźnienia | Przesyłanie strumieniowe kosztuje 3–5x partii | Kupowanie strumieniowania dla przypadków tolerujących partię | Napisy na żywo vs. przesyłanie podkastu |
| Możliwość offline | Prywatność + środowiska z ograniczoną łącznością | Założenie, że Web Speech API jest offline | Aplikacje zdrowotne, aplikacje skoncentrowane na urządzeniach mobilnych |
| Pokrycie językami | Języki Tier B = niższa dokładność | Auto-detekcja na audio wielojęzycznym | SaaS wielojęzyczne, globalna treść |
| Model kosztów | Za minutę wygląda tanio aż przesyłanie strumieniowe się pojawi | Ignorowanie przechowywania, wychodzenia, kosztów ponownych prób | Przepływy pracy twórców o zmiennej objętości |
| Powierzchnia integracji | Złe SDK kosztują tygodnie pracy inżynierskiej | "Proste w dokumentach" ≠ łatwe do wysłania | Wszyscy konstruktorzy |
Ta tabela jest filtrem, nie wyrokiem. Twórca YouTube przesyłający 10 zadań wsadowych na tydzień dba o model kosztów i pokrycie języków. Aplikacja zdrowotna dba o dokładność i możliwość offline. Narzędzie spotkań w czasie rzeczywistym dba o opóźnienie i powierzchnię integracji.
Zanim przeczytasz dalej, zakreśl dwie lub trzy osie, które mają największe znaczenie dla twojej konkretnej budowy. Sekcja kosztów (różnica w tysiącach dolarów) i migawka dostawcy na końcu będą wyglądać zupełnie inaczej w zależności od tego, które osie pierwszeństwo. Próba optymalizacji wszystkich sześciu w jednej decyzji zawsze cię doprowadzi do najdroższego dostawcy z funkcjami, których nigdy nie użyjesz.
Dokładność w kontekście — Dlaczego "benchmark 99%" kłamie o twoim audio produkcyjnym
Każdy dostawca interfejsu API zamieniający mowę na tekst publikuje liczby dotyczące dokładności. Prawie żaden z nich nie przewiduje, jak interfejs API będzie działać na twoim audio produkcyjnym. Oto dlaczego i jak testować to, co naprawdę ma znaczenie.
Audio benchmarku jest czysty; audio produkcyjne nie. Publiczne benchmarki takie jak LibriSpeech składają się z czystego audio z audiobooku — jeden mówca, neutralny akcent, czysty zapis. Duży model Whispera raportuje około 4,7% WER na teście LibriSpeech-clean i mniej więcej 8–9% WER na test-other, bardziej wyzywającym zestawie (Radford i in., OpenAI 2022). Różnica na rzeczywistym audio produkcyjnym — głośnym, z akcentem, nakładającymi się mówcami — jest jeszcze większa. Jeśli dostawca cytuje WER bez określenia zestawu danych i warunków nagrania, traktuj tę liczbę jako kopię marketingową, a nie dane inżynierskie.
WER to złuda metryka dla wielu aplikacji. Standardowa definicja z wytycznych NIST ASR Evaluation to (Substitucje + Usunięcia + Wstawienia) / Słowa referencyjne. Traktuje każde słowo jako równie ważne. Ale błędne renderowanie nazwy leku pacjenta, liczby finansowej czy nazwiska świadka ma konsekwencje, które upuszczenie słowa wypełniającego nie. Argument Jurafskiego'ego: oceniaj za pomocą metryk specyficznych dla zadania — dokładność wypełniania slotów dla asystentów głosowych, przypomnienie kluczowych warunków dla zastosowań medycznych i prawnych, dokładność jednostek nazw dla dziennikarstwa. Zagregowany WER może wynosić 7%; WER terminu krytycznego może wynosić 22%. Dla twoich użytkowników ma znaczenie tylko jedna z tych liczb.
Wydajność akcentu i dialektu zmienia się dramatycznie. Badanie PNAS cytowane na górze tego przewodnika testowało pięć głównych systemów komercyjnych i odkryło WER dla mówiących Afroamerykańskim Dialektem Angielskim średnio 0,35 vs. 0,19 dla białych mówiących — mniej więcej dwa razy gorzej. To nie jest przypis dotyczący sprawiedliwości. To jest ryzyko biznesowe: aplikacja, która zawiedzie dla trzeciej części potencjalnej bazy użytkowników, ponieważ została testowana jakości tylko na neutralnym angielskim amerykańskim, wysyła łamaną. Naprawa to nie wybór innego dostawcy (większość ma tę samą lukę). Naprawa to testowanie na audio, które reprezentuje twoich rzeczywistych użytkowników zanim coś podpiszesz.
Roszczenie o dokładności 99% na benchmarku nic ci nie mówi o tym, jak interfejs API obsługuje twoich użytkowników — to, co ma znaczenie, to wydajność na twoim audio, twoich akcentach i słownictwie domeny.
Dokładność przesyłania strumieniowego jest gorsza niż dokładność partii. Systemy przesyłające strumieniowo emitują prowizoryczne ("częściowe") słowa, które są przepisywane, gdy przychodzi więcej audio. Systemy wsadowe czekają na pełne wypowiedzenie i udoskonalają. Przesyłanie WER jest zwykle 5–15% gorsze niż wsad dla tej samej zawartości na tym samym silniku. Ta różnica prawie nigdy nie jest ujawniana w marketingu dostawcy. Jeśli budujesz produkt transkrypcji na żywo, uwzględnij to.
Przełączanie kodu łamie większość API. Przełączanie kodu oznacza alternowanie języków w obrębie wypowiadania: Spanglish, Hinglish, Tagalog-angielski. Whisper obsługuje to lepiej niż większość, ponieważ został wytrenowany na 680 000 godzinach audio wielojęzycznego (Radford i in., 2022). Większość interfejsów API w chmurze wymaga od ciebie zadeklarowania języka z góry i degrada się ciężko, gdy mówca przełącza się w środku zdania. Jeśli twoi użytkownicy mówią w więcej niż jednym języku w tej samej sesji, testuj ten przypadek jawnie. W przypadku wielojęzycznych przepływów pracy, które również wymagają lokalizacji w dół, platformy z wbudowanymi AI Dubbing w 33 językach mogą zwinąć transkrypcję, tłumaczenie i dubbing w jeden rurociąg.
Protokół pilotażowy 7 dni
Zamiast ufać roszczeniom dostawcy dotyczącym dokładności, uruchom proof of concept tygodnia.
- Dni 1–2: Zbierz 30 minut rzeczywistego audio w stylu produkcyjnym. Włącz swój najgorszy przypadek: głośne środowiska, mówcy z akcentem, żargon domeny, nakładające się mówcy.
- Dni 3–4: Transkrybuj za pomocą 3 kandydatów API. Ręcznie popraw jedną wersję, aby użyć jako transkrypcji referencyjnej.
- Dzień 5: Zmierz WER ogólnie, a następnie rozdziel go na mówcę, akcent i przypomnienie terminu domeny.
- Dzień 6: Testuj przesyłanie strumieniowe vs. partię na tych samych plikach. Zmierz deltę dokładności.
- Dzień 7: Udokumentuj koszty poniesione i tarcie integracji — złożoność autoryzacji, problemy SDK, jakość odpowiedzi na błędy.
Jeden inżynier piszący w ITNEXT zgłosił, że po dostrojeniu konfiguracji mikrofonu i niestandardowego słownika, nowoczesny zamiennik mowy na tekst produkował mniej błędów niż ich własne pisanie dla technicznych pisów. Wniosek nie jest taki, że jakiś pojedynczy interfejs API jest magiczny. To jest taki, że wybór interfejsu API ma znaczenie, ale rurociąg audio wokół interfejsu API ma co najmniej tyle samo znaczenia. Świetny interfejs API na złym audio przegrywa ze słusznym interfejsem API na dostrojonym audio.
Opóźnienie, przesyłanie strumieniowe i mnożnik kosztów rzeczywistego czasu
Opóźnienie to oś, na której inżynierowie najczęściej przepłacają. Transkrypcja w czasie rzeczywistym czuje się magicznie w demo i kosztuje 3–5x więcej niż partia w produkcji. Zdecyduj, czego twoi użytkownicy naprawdę potrzebują, zanim zarejestrujesz się w infrastrukturze przesyłającej strumieniowo.
- Opóźnienie przesyłania strumieniowego synchronicznego (napisy na żywo, asystenci głosowi). Cel poniżej 1 sekundy end-to-end dla podpisów dostępności, 300–800 ms round-trip dla chatbotów głosowych, aby czuć się konwersacyjnie. Powyżej 2 sekund iluzja czasu rzeczywistego pęka. Te progi mapują na ustalone badania UX dotyczące percepcji czasu odpowiedzi (Nielsen Norman Group). Interfejsy API przesyłające strumieniowo osiągają je poprzez trwałe połączenia WebSocket, które emitują wyniki pośrednie w miarę przychodzenia audio.
- Opóźnienie asynchronicznej partii (przesyłanie podkastów, przegląd wezwań obsługi, napisy YouTube). Minuty do godzin czasu przetwarzania są akceptowalne. Partia jest mniej więcej 3–5x tańsza na minutę audio niż przesyłanie strumieniowe na tym samym dostawcy, ponieważ infrastruktura nie utrzymuje otwartych połączeń (dokumentacja cen Google Cloud i AWS Transcribe). Dla przepływów pracy twórcy przesyłającego zarejestrowaną zawartość, partia jest prawie zawsze poprawna.
- Hybryd / bliski czas rzeczywisty (wdrażanie na żywo z opóźnioną korektą). Niektóre przepływy pracy akceptują opóźnienie 2–5 sekund w zamian za wyższą dokładność i niższe koszty. Narzędzie do transkrypcji spotkań może pokazać nieniszczący tekst w ciągu 3 sekund i udoskonalić go w ciągu 30. Ten wzorzec używa przesyłania strumieniowego dla widoku na żywo i przetwarzania wsadowego dla zapisanej transkrypcji — często poprzez webhook callback zamiast polling. Platformy stworzone dla przepływów pracy mediów, takie jak AI Dubbing API DubSmart, używają webhook callbacks dla ukończonych zadań zamiast zmuszania backend'u do odpytywania o status (wątek społeczności Make.com na temat integracji webhook AudioPen).
- Rzeczywisty współczynnik czasu (RTF) — metryka inżyniera. Systemy produkcyjne dążą do RTF < 1.0 dla interaktywnego użytku: przetwarzanie 1 sekundy audio w mniej niż 1 sekundzie czasu ściennego. Wdrożenia Whispera na urządzeniu lub przyspieszane GPU osiągają mniej więcej RTF 0,5–0,9 dla modeli średnich na konsumenckich GPU. Jeśli twoja konfiguracja hostowana samodzielnie działa RTF > 1.0, przesyłanie strumieniowe jest niemożliwe bez kolejki.

Trójkąt opóźnienia-kosztu-dokładności jest nie do negocjacji: możesz wybrać dwa. Przesyłanie strumieniowe poświęca dokładność i budżet za pilność. Partia poświęca pilność za dokładność i koszt. Architektury hybrydowe stają się coraz bardziej popularne, ale dodają złożoności integracji. Zanim wybierzesz, zadaj jedno pytanie: czy moi użytkownicy rzeczywiście zauważą opóźnienie 5 sekund? Jeśli odpowiedź brzmi nie, partia to właściwa architektura i właśnie zaoszczędziłeś 70% rocznych wydatków API.
Modele kosztów wyjaśnione — Za minutę vs. Równoczesne vs. Pule kredytów
Na rynku Speech to Text API istnieją trzy architektury cen, a ich mylenie jest najczęstszą błędem w zaopatrzeniu.
Płatność za minutę (standard wsadowy). Opłaty za minutę przesłanego audio, często w przyrostach 15-sekundowych. Proste do prognozowania dla przewidywalnych obciążeń. OpenAI Whisper API to około 0,006 dolara/minutę (strona z cennikami OpenAI) — często 3–5x tańsze niż tradycyjni dostawcy ASR w chmurze, którzy skupiają się wokół 0,02–0,03 dolara/minutę dla standardowych modelów angielskich w partii.
Równoczesne połączenia (przesyłanie strumieniowe w czasie rzeczywistym). Płacisz za każdy otwarty strumień równoczesnie, często pobierany za minutę połączenia lub za równoczesny gniazdo. To jest miejsce, gdzie rachunki skokiem: jeśli 50 użytkowników zaczyna przesyłać strumieniowo jednocześnie, płacisz za 50 połączeń — nie 50 minut audio. Google Cloud i AWS publikują odrębne i wyższe stawki dla sesji przesyłającej strumieniowo vs. offline batch.
Pule kredytów z przeniesieniem (elastyczne obciążenia). Kupujesz pulę kredytów, które zużywają się w zmiennych stawkach w zależności od funkcji, które używasz (transkrypcja, dubbing, klonowanie głosu, synteza mowy). Niewykorzystane kredyty są przenoszone. Ten model pasuje do zmiennych obciążeń — YouTuber, który przesyła 4 godziny jeden tydzień i 40 następny nie jest karany za skok lub pozostaje bez niewykorzystanych minut. DubSmart AI używa tego modelu, bundling transkrypcji z Voice Cloning i Text to Speech pod jednym saldem kredytów.
Przykład pracowały — twórca YouTube:
- 10 filmów/tydzień × 30 min każdy = 300 min/tydzień audio źródłowego
- Transkrypcja wsadowa za 0,006 dolara/min = 1,80 dolara/tydzień, czyli około 94 dolary/rok
- Dodaj demo transkrypcji na żywo przesyłające strumieniowo (5 godzin/miesiąc) przy 4x stawce wsadowej = mniej więcej 72 dolary/rok dodatkowe
- Jeśli twórca dubbing do 3 języków, całkowita miesięczna transkrypcja + dubbing potrzeba kredytów to około 5000 kredytów — pasuje w ramach planu puli kredytów średniego poziomu
Przy dowolnej głośności poniżej 5000 godzin miesięcznie, budowanie własnego stosu transkrypcji jest tańsze w fantazji niż w rzeczywistości — warstwa interfejsu API za 50 dolarów wysyła się w dzień, podczas gdy wdrożenie Whispera hostowane samodzielnie wysyła się w kwartał.
| Dostawca | Model cen | Opublikowana stawka | Bezpłatna warstwa |
|---|---|---|---|
| Google Cloud STT | Na przyrost 15-sekundowy; dopłata za przesyłanie strumieniowe | Zmienna; warstwowa | 60 min/miesiąc |
| AWS Transcribe | Batch za sekundę + SKU przesyłające strumieniowo | Zmienna wg regionu/modelu | 60 min/miesiąc, 12 miesięcy |
| OpenAI Whisper API | Flat za minutę | ~0,006 dolara/min | Brak opublikowanego |
| Rev.com (Machine) | Za minutę | 0,25 dolara/min | Brak |
| Rev.com (Human) | Za minutę | 1,50 dolara/min | Brak |
| DubSmart AI | Pula kredytów z przeniesieniem | Plany warstwowe | Bezpłatna warstwa dostępna |
Źródła: OpenAI, Google Cloud, AWS Transcribe, strony z cennikami dostawcy Rev.com.

Trzy ukryte koszty prawie nigdy nie pojawiają się w kalkulatorach dostawcy.
Przechowywanie i wyjście. Jeśli przechowujesz transkrypcje i źródłowe audio w S3 lub GCS, płacisz za przechowywanie plus przepustowość przy odzyskaniu. Na dużą skalę stają się one istotnymi pozycjami. Archiwum 1 TB w standardowych stawkach z częstymi ponownymi odczytami może dodać setki dolarów miesięcznie zanim którykolwiek wezwanie interfejsu API uderzy.
Diaryzacja mówcy jest zwykle mierzona oddzielnie. AWS Transcribe i AssemblyAI oba rozliczają identyfikację mówcy jako oddzielną pozycję oprócz transkrypcji bazowej (dokumentacja AWS Transcribe; docs AssemblyAI). Budżetowanie tylko na stawkę bazową za minutę nie szacuje twojego rzeczywistego kosztu o około 20–40%, jeśli potrzebujesz etykiet mówcy.
Koszty ponownych prób i błędów. Żądania, które nie powiodły się, nadal zużywają przydział u niektórych dostawców. Jeśli twój rurociąg audio ma wskaźnik błędu 2% przy 100 000 minut/miesiąc, to 2000 minut płatnych ponownych prób — mniej więcej 12 dolarów/miesiąc przy stawkach Whispera, ale łatwo 60 dolarów/miesiąc na tradycyjnym STT w chmurze.
Punkt równowagi budowania vs. kupowania. Doświadczenie inżynierskie od zespołów w Mozilla (DeepSpeech), Descript i AssemblyAI sugeruje, że samodzielne hostowanie ASR z Whisper lub Kaldi ma sens tylko przy >5000 godzin/miesiąc z dedykowanym ML i obsługą DevOps. Poniżej tej głośności infrastruktura, konserwacja modelu, koszty GPU i nadzór nad sobą przekraczają rachunek API $50–$500/miesiąc — często pięciokrotnie lub więcej.
Rzeczywistości integracji — Audyt SDK i API z 9 pytaniami
"Łatwe do integracji" to najczęściej przeciążona fraza w gospodarce API. Interfejs API może być łatwy do wezwania w żądaniu curl i piekielnie trudny do wysłania w produkcji. Zanim podpiszesz umowę, uruchom każdego kandydata przez te dziewięć pytań. Złe odpowiedzi tutaj przewidują tygodnie niestandardowej obsługi błędów i logiki ponownych prób, którą później napiszesz.
- Czy interfejs API obsługuje zarówno przesyłanie strumieniowe, jak i partię w jednym SDK? Niektórzy dostawcy zmuszają cię do wyboru architektury z góry, a następnie opłacają przełączenie. Najlepsze interfejsy API ujawniają oba za pomocą tej samej warstwy uwierzytelniania i pozwalają migrować obciążenia w miarę zmian zachowania użytkownika. Jeśli twój początkowy przypadek użycia to partia, ale za sześć miesięcy możesz dodać napisów na żywo, to ma znaczenie teraz.
- Co się dzieje, gdy interfejs API jest niedostępny lub jest ograniczony? Testuj go. Wyślij 200 żądań w 1 sekundę do bezpłatnej warstwy. Czy SDK je kolejkuje, powierzchni 429 czysto, czy zwisa? Dostawcy, którzy publikują SLA i semantykę ponownych prób w zwykłym języku, oszczędzają ci tygodnie reagowania na incydenty. Dostawcy, którzy nie robią, ostatecznie obudzą cię o 3 rano.
- Czy możesz wyraźnie określić język audio, czy auto-detekt? Auto-detekcja brzmi przyjaznie, ale łamie się na audio wielojęzycznym lub przełączającym kod. Dla budów produkcyjnych, zawsze określ język i wróć do auto-detekcji tylko wtedy, gdy pewność jest niska. Interfejsy API, które nie pozwalają wyraźnie ustawić języka, są wstępnie zaprojektowane do niepowodzenia na twoich przypadkach krawędziowych.
- Czy obsługuje diaryzację mówcy z pudełka? Diaryzacja jest często oddzielnie wycenianym dodatkiem. AssemblyAI i AWS Transcribe oba mierzą to oddzielnie. Sprawdź, czy twój dostawca zwraca etykiety mówcy na poziomie segmentu czy na poziomie słowa — różnica ma znaczenie dla analityki, wyszukiwania i wszelkich przetwarzania summaryzacji w dół.
- Czy możesz flagować lub redagować PII (numery kart kredytowych, SSN, nazwy)? Większość interfejsów API skoncentrowanych na przedsiębiorstwach (AWS Transcribe, AssemblyAI) obsługuje redakcję PII. Whisper i Web Speech API nie obsługują. Dla aplikacji zdrowotnych lub finansowych, to nie jest miła dla ciebie.
- Webhook callbacks czy polling dla zadań asynchronicznych? Webhoki to nowoczesny standard. Polling generuje niepotrzebne wezwania interfejsu API i koszty. Dojrzałe platformy emitują zdarzenia webhook przy ukończeniu zadania — wzorzec pokazany w wątku społeczności Make.com na temat integracji AudioPen, gdzie ukończenie transkrypcji wyzwala automatyzację w dół.
- Jakie są maksymalne limity rozmiaru pliku i czasu trwania na żądanie? Wiele interfejsów API w chmurze ogranicza poszczególne żądania do 15 minut lub mniej więcej 1 godziny z limitami rozmiaru pliku w dziesiątkach do setek MB (dokumenty Google Cloud Speech-to-Text; dokumenty AWS Transcribe). Audio długoformatowe — dwugodzinne podkasty, depositsy, nagrania konferencji — musi być podzielone. Bramy HTTP często wymuszają timeout 15 minut niezależnie od własnych limitów interfejsu API.
- Czy wyniki ufności są ujawnione na poziomie słowa? Wyniki ufności na poziomie słowa umożliwiają flagowanie regionów o niskiej pewności do przeglądu człowieka lub interaktywnej korekty. Interfejsy API, które zwracają surowy tekst bez pewności zmuszają cię do ufania wszystkiemu lub ponownego transkrypcji. Dla każdego przepływu pracy z przeglądem człowieka w pętli funkcja ta to różnica między użyteczną kolejką QA a ścianą niezrozumiałego tekstu.
- Jaka jest jakość SDK w twoim języku? SDK Node.js czy Python o silnym typowaniu, logice ponownych prób i czystych klasach błędów jest warte 30% premii ceny nad interfejsem API, który musisz surowy-HTTP w produkcji. Przetestuj SDK zanim będziesz zobowiązany do interfejsu API. Napisz małą integrację. Czas to. SDK, w którym naprawdę chcesz pracować, zaoszczędzi więcej godzin inżynierskich niż kiedykolwiek zaoszczędziłaś stawka za minutę.
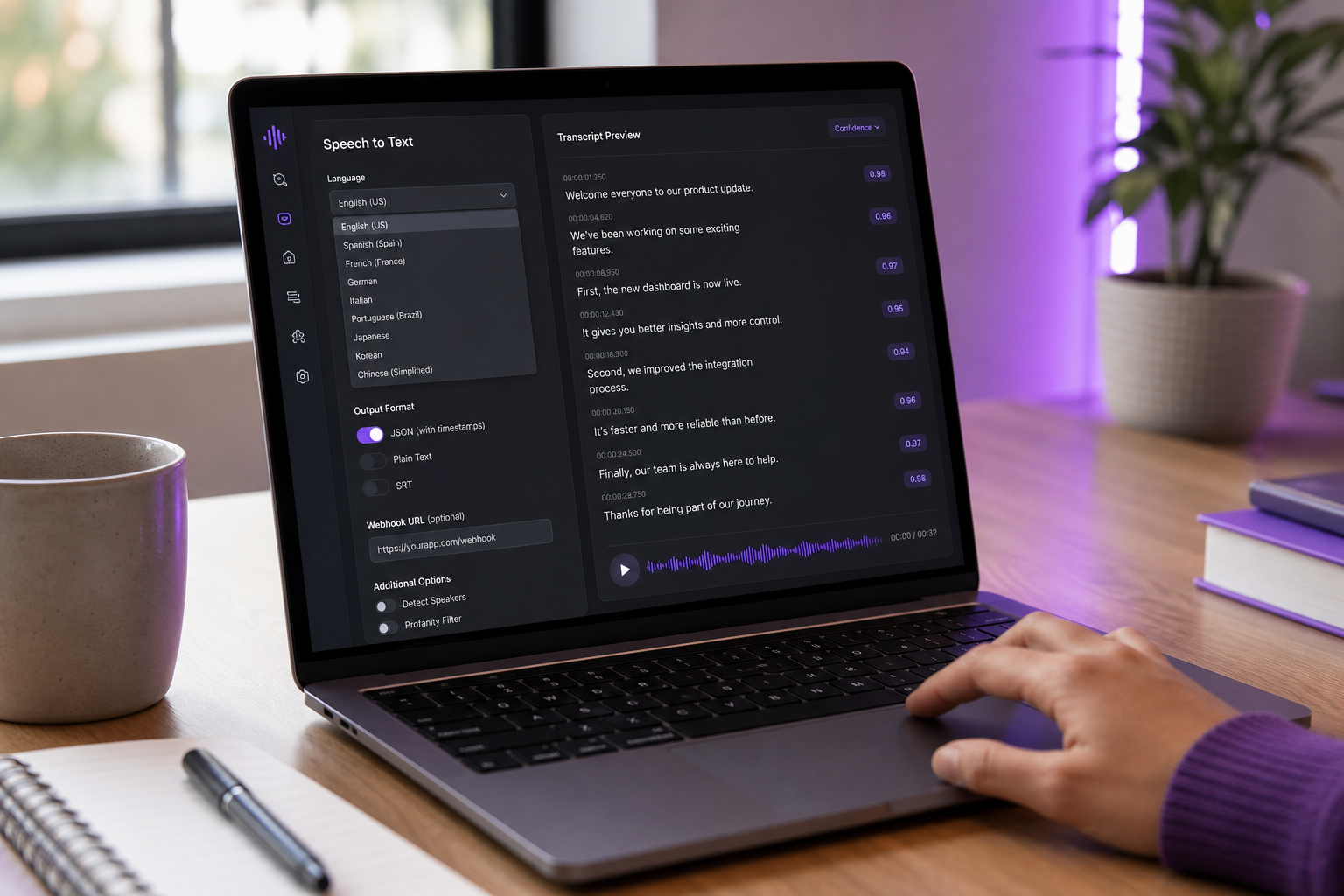
Open-source vs. proprietary pozostaje największym rozwidleniu integracji.
Open-source (Whisper, Vosk). Zero kosztów za wezwanie, pełna kontrola, uruchamia się offline. Jesteś właścicielem hostingu, skalowania, obsługi GPU, aktualizacji modelu, obserwowalności i incydentu o 3 rano. Realistyczne wdrożenie dla zespołu 5+ z możliwością ML i DevOps.
Proprietary cloud (Google, AWS, AssemblyAI, OpenAI Whisper API, DubSmart). Handlujesz kosztem za wezwanie za niezawodność, SLA, wersjonowanie i obsługę SDK. Dla większości zespołów poniżej 5000 godzin/miesiąc, proprietary wygrywa całkowity koszt posiadania. Platformy, które bundlują zamiennik mowy na tekst z Text to Speech API i Voice Cloning API pod jednym SDK zmniejszają powierzchnię integracji — jeden przepływ auth, jeden model błędu, jeden pulpit nawigacyjny rozliczeń dla pełnego rurociągu mediów.
Na poziomie platformy na urządzeniu (Apple SpeechAnalyzer, WWDC 2025). Nowsza kategoria. Zachowywająca prywatność, w stanie offline, ale dokładność i pokrycie języków mogą pozostać w tyle za modelami chmury. Najlepsze dla aplikacji skoncentrowanych na urządzeniach mobilnych, gdzie prywatność jest zasobem marketingowym, a nie tylko punktem kontrolnym zgodności.
Pytanie dotyczące integracji, które przebija wszystkie inne: jak szybko możesz wysłać? Dobrze udokumentowany interfejs API oparty na kredytach, który bundluje zamiennik mowy na tekst, klonowanie głosu i dubbing pod jednym SDK, często bije tańszy samodzielny interfejs API STT, gdy uwzględnisz drugą i trzecią funkcję, którą będziesz potrzebować w ciągu sześciu miesięcy.
Migawka dostawcy — Kiedy wybrać każdy Speech to Text API
To jest szybka, a nie wyczerpująca recenzja. Każdy wpis obejmuje najlepszy przypadek użycia, główną słabość, główny sterownik kosztów i charakter integracji. Źródła dla roszczeń cen i funkcji to dokumentacja dostawcy od końca 2024 roku.
Google Cloud Speech-to-Text
- Najlepsze dla: Transkrypcja angielska o wysokiej dokładności, zespoły już w GCP, obciążenia przedsiębiorstwa o przewidywalnej głośności.
- Słabość: Ceny przesyłania strumieniowego eskalują się szybko; warstwy językami tworzą niespójność dokładności dla audio angielskiego.
- Sterownik kosztów: Na przyrost 15-sekundowy ze oddzielnym (wyższym) SKU przesyłającym strumieniowo; bezpłatna warstwa 60 min/miesiąc.
- Integracja: Nativne uwierzytelnianie GCP poprzez konta usług. Aplikacje spoza GCP stają przed narzutem IAM. Dojrzałe SDK dla wszystkich głównych języków.
AWS Transcribe
- Najlepsze dla: Obciążenia wsadowe na dużą skalę, zespoły natywne AWS, potoki zawartości wielojęzycznej, analityka call center.
- Słabość: Opóźnienie przesyłania strumieniowego nieco wyższe niż specjaliści w przesyłaniu strumieniowym. Diaryzacja i modele medyczne wyceniane oddzielnie.
- Sterownik kosztów: Czas trwania audio w sekundach, ze oddzielnymi SKU dla przesyłania strumieniowego, medycyny i analityki wezwań dodatków.
- Integracja: Ciężki IAM. Proste, jeśli jesteś już natywny AWS. Dobrze udokumentowany, ale wielomowny.
OpenAI Whisper API
- Najlepsze dla: Budów świadomych budżetu, wielojęzycznej zawartości z przełączaniem kodu, zespołów, które chcą braku blokady dostawcy poza samym OpenAI.
- Słabość: Brak natywnego wsparcia przesyłania strumieniowego. Brak rabatów na głośność. Brak zobowiązań SLA porównywalnych z AWS czy GCP.
- Sterownik kosztów: Flat 0,006 dolara/minutę bez opłaty za równoczesne połączenie i bez opublikowanego rabatu przedsiębiorstwa tiered.
- Integracja: Najprostszy interfejs HTTP na rynku. Wielojęzyk bez deklaracji języka dzięki 680 000 godzinom danych treningowych udokumentowanych w artykule Whisper.
AssemblyAI
- Najlepsze dla: Zespoły skoncentrowane na programistach, przesyłanie strumieniowe w czasie rzeczywistym z minimalnym opóźnieniem, strukturalny wyjście ze znacznikami czasu na poziomie słowa, etykiety mówcy i wyniki ufności.
- Słabość: Ceny premii. Gęstość funkcji jest overkill dla prostych przypadków wsadowych.
- Sterownik kosztów: Równoczesne połączenia przesyłające strumieniowo plus pozycje diaryzacji.
- Integracja: Doskonałe SDK i dokumentacja. Architektura webbhook-first. Silne narzędzia obserwowalności.
Rev.com (Machine + Human Hybrid)
- Najlepsze dla: Przepływy pracy, w których dokładność jest niezmienna, a zwrot może czekać godziny — depozyty prawne, dziennikarstwo, zawartość krytyczna dla dostępu.
- Słabość: Nie w czasie rzeczywistym. Przegląd człowieka trwa godzin. Drogi na dużą skalę.
- Sterownik kosztów: 0,25 dolara/minutę dla maszyny, 1,50 dolara/minutę dla przeglądu człowieka.
- Integracja: Prosty interfejs REST API. Tarcie to czas zwrotu, a nie sama integracja.
DubSmart AI Speech to Text API
- Najlepsze dla: Twórcy zawartości i zespoły budujące przepływy pracy wielojęzyczne, w których transkrypcja jest jednym krokiem w dłuższym rurociągu — transkrypcja, tłumaczenie, dubbing, publikacja. Ceny oparte na kredytach absorbuję obciążenia zmienne.
- Słabość: Młodsza platforma niż starsze hiperskali. Terminy SLA przedsiębiorstwa mogą nie odpowiadać AWS czy GCP dla zespołów ostrożnych wobec ryzyka.
- Sterownik kosztów: Pula kredytów z przeniesieniem. Bundluje transkrypcję z klonowaniem głosu z próbki 20-sekundowej, 300+ głosy TTS i AI Dubbing przez 60+ językami źródłowymi do 33 językami celowymi.
- Integracja: Zabudowany dla przepływów pracy mediów. Jedno SDK obejmuje transkrypcję + TTS + klonowanie + dubbing. Webhook callbacks dla zadań asynchronicznych. Zaufane przez 500 000+ użytkowników.
Twoja lista kontrolna wyboru Speech to Text API
To jest przepływ pracy do uruchomienia zanim podpiszesz jakąkolwiek umowę. Kompresuje wszystko powyżej w osiem wykonalnych kroków. Blokuj cztery godziny do pierwszego przejścia; spodziewaj się tygodnia testów pilotażowych na etapie 4.
- Zdefiniuj swój dominujący przypadek użycia w jednym zdaniu. Napisz to: "Muszę transkrybować podkasty" lub "napisać live streamy" lub "analizować wezwania sprzedaży" lub "dubować filmy przesyłane przez użytkowników". Jeśli nie możesz napisać tego w jednym zdaniu, masz dwa produkty i potrzebujesz dwóch ocen. Dopasuj przypadek użycia do warstwy opóźnienia z Sekcji 3 i popytu na dokładność z Sekcji 2 zanim spojrzysz na ceny dostawcy.
- Zakreśl dwie lub trzy osie decyzyjne, które mają największe znaczenie. Z ramy: dokładność, opóźnienie, offline, pokrycie językami, model kosztów, powierzchnia integracji. Jeśli spróbujesz optymalizować wszystkie sześć, wybierzesz najdroższego dostawcę z funkcjami, których nigdy nie użyjesz. Większość konstruktorów powinna rangować model kosztów i powierzchnię integracji pierwszy. Dokładność i opóźnienie stają się tiebreaker między finalistami.
- Projekt 12-miesięcznej głośności z buforem 3x surge. Oszacuj minuty miesięczne za miesiąc 1, miesiąc 6 i miesiąc 12. Pomnóż liczbę miesiąca 12 przez 3, aby obsługiwać skoki uruchamiania i wzrost wirusowego. Ta liczba określa, czy potrzebujesz puli kredytów, ceny za minutę czy zdyskontowanej umowy przedsiębiorstwa — i jest to liczba, którą zacytujesz dostawcom podczas negocjacji.
- Uruchom 7-dniowy pilot. Trzydzieści minut twojego rzeczywistego audio, trzech kandydatów API, ręcznie punktowana względem jednej transkrypcji referencyjnej poprawionej człowiekiem. Zmierz WER na mówcę, na akcent i na termin domeny — nie tylko zagregowany. Testuj przesyłanie strumieniowe vs. partię na tych samych plikach. Dokumentuj tarcie SDK w udostępnionym dokumencie, gdy idziesz, podczas gdy ból jest świeży.
- Stress-test obsługa błędów. Wyślij audio zniekształcone, wygasłe tokeny, Rate-limit-busting bursts i pliki przeznaczone. Czy SDK zawiedzie czysto z działalnymi błędami, czy zwisa? Interfejs API, który zawodzi źle pod kontrolowaną stresem, zawiedzie źle w produkcji o 3 rano, i koszt sprzątania będzie karłować wszelkie oszczędności za minutę, które zablokowałeś przy podpisaniu.
- Oblicz rzeczywisty całkowity koszt posiadania. Wlicz koszt bazowy za minutę, surcharges przesyłania strumieniowego, pozycje diaryzacji, przechowywanie, wyjście, narzut ponownych prób i godziny inżynierskie zaoszczędzane lub tracone przez jakość SDK. Porównaj z modelem opartym na kredytach, jeśli twoje obciążenie jest zmienne — plan kredytów o wartości około 99 dolarów/miesiąc często przebija ceny 0,006 dolara/minutę, gdy ruch jest przerywisty i bundluje wiele funkcji mediów pod jednym rachunkiem.
- Audyt domyślnych ustawień prywatności i przechowywania danych. Potwierdź, czy dostawca zatrzymuje audio i transkrypcje dla ulepszenia modelu i czy możesz zrezygnować umownie. Wymogi GDPR, HIPAA i SOC 2 mogą wyeliminować dostawców niezależnie od ceny. Według wytycznych Europejskiej Rady Ochrony Danych dotyczących asystentów głosowych, dostawcy STT w chmurze mogą tworzyć "zestawy danych cienia" danych głosu, chyba że wyraźnie ograniczone w umowie — to pytanie zaopatrzenia, a nie pytanie funkcji.
- Negocjuj zanim się zatwierdź. Większość dostawców oferuje rabaty 15–30% przy zobowiązaniach 12-miesięcznych powyżej 500 godzin/miesiąc. Jeśli zakończyłeś kroki 1–7 z pewnością, masz dźwignię. Poproś o zablokowaną cenę, dedykowany kontakt wsparcia, rozszerzoną bezpłatną warstwę dla środowisk przejściowych i klauzulę wyjścia, jeśli dokładność spadnie poniżej uzgodnionego progu. Jeśli twoja roadmapa zawiera lokalizację, oceń interfejsy API, takie jak AI Dubbing API, który tłumaczy i dubbuje w jednym wezwaniu.
Ta lista kontrolna to twoja obrona przed marketingiem dostawcy i twoja ofiansywa przeciwko opóźnieniom wysyłkowym. Zespoły, które wysyłają funkcje głosowe najszybciej, to nie te, które wybrały najtańszy interfejs API — to te, które uruchomiły prawdziwy pilot, obliczyły rzeczywisty TCO i wybrały powierzchnię integracji, którą ich programiści chcieli w nim pracować. Jeśli twoja budowa obejmuje również dubbing, klonowanie głosu lub generowanie syntetycznej mowy, oceń platformy, które bundlują Text to Speech, klonowanie głosu i dubbing pod jednym saldem kredytów i jednym SDK — druga i trzecia funkcja, którą będziesz potrzebować w ciągu sześciu miesięcy, będzie kosztować mniej i wysłać szybciej.