
Masz pomysł na utwór leżący w połowie ukończony — może fan-dub, edit z memem albo vocal cover — i chcesz, żeby ten niepowtarzalny, jasny, nieważki dźwięk Hatsune Miku go poprowadził. Ale droga do tego jest zaśmiecona złymi opcjami. Oficjalne oprogramowanie Vocaloid i Synthesizer V kosztuje pieniądze i wymaga nauki nuta po nucie. Strony z „darmowym głosem Miku", które znajdziesz, generują płaskie, fałszywe audio. A ogólne narzędzia AI brzmią albo robotycznie, albo plasują się w niejasnym obszarze praw autorskich. Właściwy przepływ pracy z generatorem głosu miku przecina to wszystko, ale tylko jeśli najpierw zrozumiesz dwa prawdziwe utrudnienia: autentyczność (uzyskanie czegoś, co naprawdę odbiera się jako „Miku", a nie tylko wysoki klip TTS) i legalność (wiedza, czy w ogóle wolno ci publikować to, co tworzysz).
Ten przewodnik daje ci czystą, praktyczną drogę — granicę prawną, której nie możesz przekroczyć, jak wybierać między doborem głosu a klonowaniem, różnicę między mową a śpiewem, jak dostroić charakterystyczną barwę i jak wyeksportować audio, którego naprawdę możesz użyć. Bez szumu. Tylko sprawdzona metoda budowy głosu AI Miku, który się broni.

Spis treści
- Vocaloid vs. generator głosu AI: która ścieżka pasuje do twojego projektu Miku
- Granica prawna i etyczna, zanim wygenerujesz choćby jedną nutę
- Generowanie głosu Miku w DubSmart AI: krok po kroku
- Dostrajanie charakterystycznego brzmienia: wysokość, ton i charakter głosu
- Od mowy do śpiewu: zamiana wygenerowanego głosu w ścieżkę wokalną
- Eksport, lokalizacja i skalowanie treści w stylu Miku
- Twoja lista kontrolna przed generowaniem głosu Miku
- Najczęściej zadawane pytania
Vocaloid vs. generator głosu AI: która ścieżka pasuje do twojego projektu Miku
Istnieją dwie zupełnie różne drogi do głosu w stylu Miku, a wybór niewłaściwej marnuje godziny. Twój wybór zależy całkowicie od tego, co budujesz.
Droga A — licencjonowane oprogramowanie do syntezy śpiewu (Vocaloid / Synthesizer V). Vocaloid syntetyzuje śpiew, łącząc wcześniej nagrane próbki głosu aktora głosowego z wprowadzoną przez użytkownika melodią oraz tekstem. To czyni z niego silnik śpiewu napędzany tekstem i partyturą, a nie narzędzie text-to-speech. Wprowadzasz nuty pojedynczo, a następnie ręcznie dostrajasz fonemy i dynamikę. Surowa synteza to tylko pierwsze podejście — szczegółowe strojenie jest obowiązkowe dla przekonującego efektu, co wielokrotnie podkreślają tutoriale tworzenia VSynth i Vocaloid. Zaletą jest pełna kontrola melodyczna w jednym edytorze. Badania VOCALOID:AI firmy Yamaha zauważają, że nowoczesne systemy wykorzystują modele uczenia maszynowego trenowane na dużych zbiorach danych głosowych, aby wytworzyć bardziej naturalną barwę niż starsze silniki konkatenacyjne, zgodnie z przeglądem AI Sound Synthesis firmy Yamaha.
Droga B — generatory głosu AI (TTS + klonowanie głosu). Skupiają się na prozodii mowy i nie obsługują natywnie kontroli wysokości muzycznej. Aby zaśpiewać, kierujesz wynik przez narzędzia korekcji wysokości, takie jak DAW lub Melodyne. Kompromisem jest szybkość: brak wprowadzania nut, szybkie klonowanie z krótkiego nagrania referencyjnego i szeroki, wielojęzyczny wynik od razu po wyjęciu z pudełka.

| Kryterium | Vocaloid / Synth V | Ogólny AI TTS | Klonowanie głosu AI |
|---|---|---|---|
| Typowy koszt | Płatna licencja | Od darmowego do płatnego | Od darmowego do płatnego |
| Krzywa nauki | Wysoka | Niska | Niska–średnia |
| Natywna kontrola wysokości | Tak | Nie (wymaga DAW) | Nie (wymaga DAW) |
| Wynik mówiony | Ograniczony | Tak | Tak |
| Przygotowanie przed audio | Melodia + tekst + strojenie | Wpisz tekst | 20s referencji |
(Koszt, krzywa nauki, śpiew i przygotowanie wywodzą się z technicznego opisu „Vocaloid" na Wikipedii i tutoriala coverów VSynth; jasność komercyjnego wykorzystania wywodzi się z Crypton/Vocaloid Wiki oraz Berkeley Technology Law Journal. Brak kolumny z werdyktem — właściwy wybór zależy od twojego przypadku użycia.)
Więc która droga ci pasuje? Jeśli chcesz szybką wypowiedź mówioną — mem, fan-dub dialogu, krótki klip głosowy — wybierz AI Text to Speech. To najszybsza droga do użytecznego audio, a klip możesz mieć w mniej niż minutę. Jeśli produkujesz pełny śpiewany cover i chcesz panować nad każdą nutą, licencjonowana droga Vocaloid lub Synthesizer V daje ci tę precyzję, kosztem stromszej krzywej nauki.
Jeśli chcesz szybkości oraz niestandardowej barwy — powiedzmy jaśniejszego lub bardziej wyrazistego głosu niż oferuje standardowa biblioteka — przepływ klonowania w połączeniu z DAW do wysokości to twoja droga pośrednia. Klonujesz jasny głos referencyjny, szybko generujesz frazy mówione, a następnie mapujesz ich wysokość w DAW do śpiewu.
Uczciwy kompromis jest taki: najszybsza droga rzadko jest najbardziej muzycznie precyzyjna. Vocaloid daje ci kontrolę na poziomie nuty, ale wymaga cierpliwości. Generatory AI dają natychmiastowy wynik, ale pozostawiają pracę nad wysokością tobie później. Pod tym wszystkim kryje się też rozróżnienie własności intelektualnej — materiały Crypton oddzielają prawa autorskie do imienia Miku i wizerunku maskotki od syntetyzowanego wyniku wokalnego. To oddzielenie ma ogromne znaczenie dla tego, co możesz publikować, i jest tematem następnej sekcji.
Najszybsza droga do głosu w stylu Miku rzadko jest najbardziej autentyczna — dopasuj narzędzie do tego, czy mówisz, czy śpiewasz.
Granica prawna i etyczna, zanim wygenerujesz choćby jedną nutę
To sekcja, którą większość twórców pomija, a później żałuje. Zanim sięgniesz po generator głosu miku, musisz zrozumieć, co wolno ci robić — a zasady są bardziej szczegółowe niż „treści fanowskie są w porządku".
Sztuka postaci i głos są licencjonowane odmiennie. Crypton Future Media przyjął licencję Creative Commons Attribution–NonCommercial 3.0 (CC BY-NC 3.0) dla oryginalnych ilustracji postaci Piapro w 2012 roku, zgodnie z oficjalną stroną Hatsune Miku firmy Crypton oraz warunkami licencji Piapro. Ta licencja obejmuje obrazy do użytku niekomercyjnego z podaniem autorstwa. Nie jest to ogólne prawo do komercyjnego naśladowania lub monetyzowania jej głosu za pomocą AI. Licencja na sztukę i głos to odrębne kwestie.
Co faktycznie obejmuje licencja Piapro. Stosuje się do sześciu głównych postaci — Hatsune Miku, Kagamine Rin, Kagamine Len, Megurine Luka, MEIKO i KAITO. Ich oryginalne ilustracje mogą być kopiowane, adaptowane i rozpowszechniane do użytku niekomercyjnego, pod warunkiem dołączenia wymaganej informacji o autorstwie, takiej jak „Hatsune Miku, © Crypton Future Media, Inc. 2007, licencjonowane na CC BY-NC", zgodnie z FAQ licencji Piapro. Pomiń przypisanie autorstwa, a wypadasz poza licencję.
Licencja oprogramowania Character Vocal Series ma własne zasady. Na mocy licencji CV Series firmy Crypton użytkownicy mogą syntetyzować wokale do użytku komercyjnego i niekomercyjnego — ale z twardymi ograniczeniami. Nie możesz generować obraźliwych lub niepokojących tekstów, nie możesz komercyjnie rozpowszechniać piosenek wyraźnie reklamowanych jako „śpiewane przez postać" i nie możesz umieszczać wizerunku maskotki na produktach komercyjnych bez zgody Crypton, jak podsumowuje Vocaloid Wiki. Ograniczenie „śpiewane przez postać" potyka wiele osób, które zakładają, że każdy wynik wokalny jest dozwolony.
Klonowanie prawdziwego głosu uruchamia zupełnie inny zbiór prawa. Analiza prawna od Skadden, Arps, Slate, Meagher & Flom LLP wyjaśnia, że federalne prawo autorskie chroni ustalone nagranie dźwiękowe, ale nie abstrakcyjne cechy głosu — tożsamość wokalna podlega zamiast tego stanowym ustawom o prawie do wizerunku i prawu umów. Zespół firmy głosowej Respeecher ujmuje to wprost: „Nie możesz objąć prawami autorskimi surowego głosu AI… Jednak jeśli brzmi on jak prawdziwa osoba, nadal nie możesz go użyć bez pozwolenia ze względu na jej prawo do wizerunku". Surowy plik głosu AI generalnie nie podlega prawom autorskim, ponieważ brakuje mu ludzkiego autorstwa — ale jeśli brzmi jak konkretna prawdziwa osoba, jej prawa do wizerunku nadal kontrolują jego użycie.
„Styl Miku" kontra bezpośredni klon to bezpieczniejsza granica. Trenowanie na licencjonowanych danych nie-celebrytów tworzy „nowe" głosy, gdzie prawa zależą od umów licencyjnych na dane, a nie od tożsamości konkretnej osoby, zgodnie z Berkeley Technology Law Journal. Budowanie oryginalnego inspirowanego Miku jasnego syntetycznego głosu stawia cię na znacznie bardziej obronnym gruncie niż bezpośrednie klonowanie oficjalnego banku głosu.
Monetyzacja to wyraźna granica. Niekomercyjne treści fanowskie na licencji CC BY-NC są szerokie i hojne. W chwili, gdy przekraczasz do użytku komercyjnego — sprzedaży produktów, prowadzenia zmonetyzowanych kampanii — potrzebujesz osobnego pozwolenia od Crypton. To moment decyzyjny, wokół którego należy planować.
Obronne podejście jest proste: zbuduj oryginalny, inspirowany Miku jasny głos do niekomercyjnej pracy fanowskiej, prawidłowo przypisz autorstwo sztuki postaci i szukaj licencji przed jakimkolwiek wydaniem komercyjnym.
Możliwość techniczna to nie pozwolenie prawne — narzędzie pozwalające ci sklonować głos nie mówi nic o tym, czy wolno ci go opublikować.
Generowanie głosu Miku w DubSmart AI: krok po kroku
Po ustaleniu podstaw prawnych, oto faktyczny przepływ pracy z generatorem głosu miku w DubSmart AI, od utworzenia konta po podglądowy klip. Cały sens polega na testowaniu przed wydaniem pieniędzy, więc każdy krok chroni twój czas i twoje kredyty.

1. Utwórz konto i wybierz darmowy poziom. Zacznij od darmowego poziomu, abyś mógł eksperymentować przed wydaniem czegokolwiek. Platforma działa w oparciu o model kredytowy z kredytami przenoszonymi, co oznacza, że niewykorzystane kredyty nie znikają na koniec cyklu rozliczeniowego — przechodzą dalej, więc wczesne testowanie nie karze cię później.
2. Wybierz narzędzie: Text to Speech lub Voice Cloning. Użyj Text to Speech do szybkich mówionych linii w stylu Miku — dialogów, odczytów memów, treści fanowskich z głosem. Użyj Voice Cloning, gdy chcesz niestandardowy jasny głos zbudowany z konkretnej referencji, a nie standardowy profil.
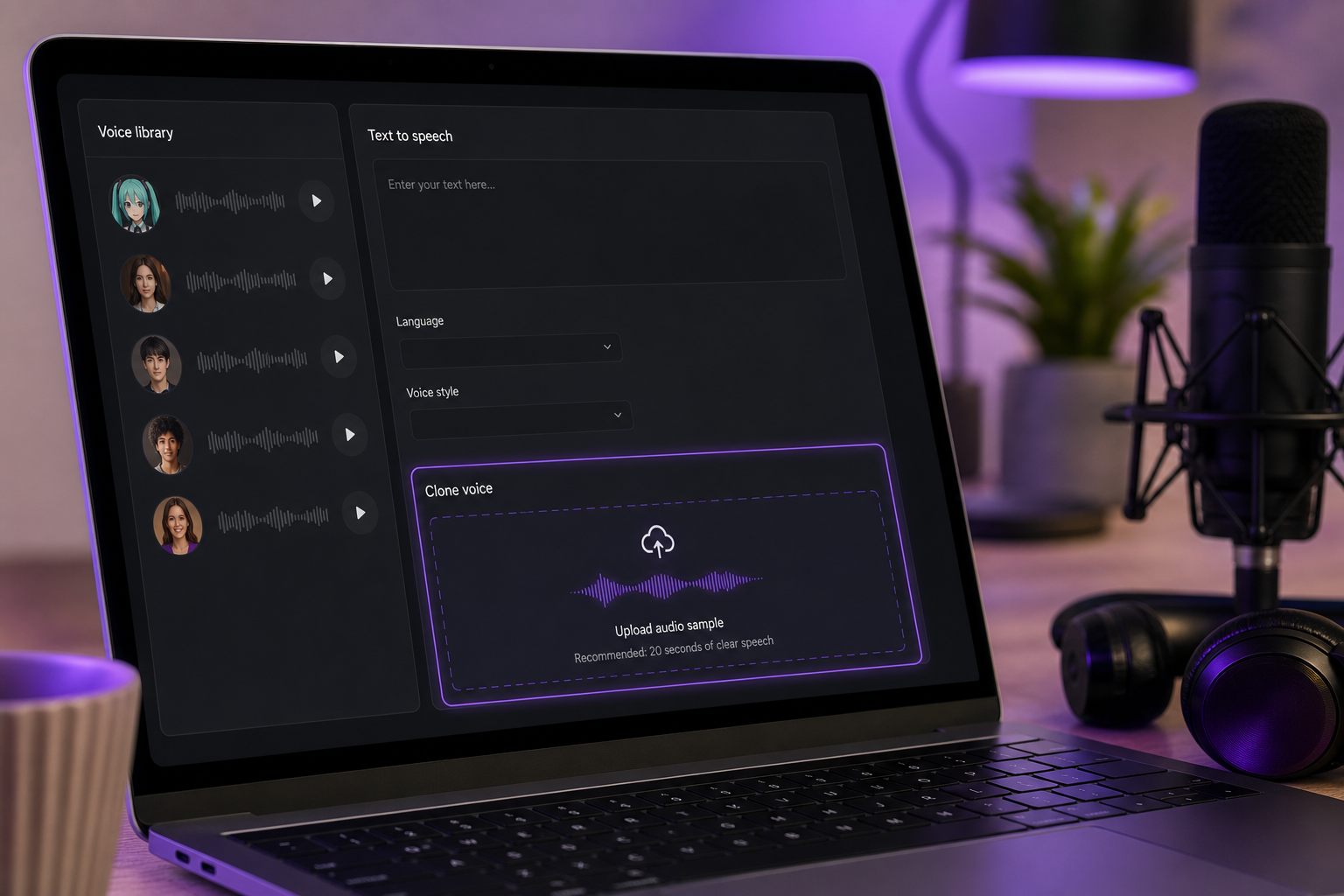
3. Wybierz profil głosu lub sklonuj z referencji. Wybierz wysoki, jasny głos z biblioteki ponad 300 głosów albo zbuduj własny przez klonowanie głosu z około 20 sekund czystego nagrania referencyjnego. Jeśli klonujesz, referencja musi być czystym, wyizolowanym wokalem — bez muzyki w tle, bez szumu pomieszczenia. Klon jest tylko tak dobry jak źródło.
4. Wprowadź swój tekst lub dialog. Wklej tekst do pola wprowadzania. Dla treści mówionych jest to twój ostateczny tekst. Dla śpiewanych linii wklej frazy tekstu — faktyczną melodią zajmiesz się później w DAW, omówioną dalej.
5. Dostrój wysokość, prędkość i ton w kierunku charakterystycznego rejestru Miku. Pchnij głos w stronę jasnego, wysokiego i wyraźnego. Punktem odniesienia są tu badania VOCALOID:AI firmy Yamaha, które przedstawiają nowoczesne syntetyczne wokale jako dążące do naturalnej artykulacji i jasnej barwy, a nie ciężkich robotycznych ustawień, zgodnie z przeglądem AI Sound Synthesis firmy Yamaha. Celuj w czysty i przejrzysty, a nie brzęczący. Dokładne cele są dalej.

6. Wygeneruj i wyświetl podgląd przed wydaniem pełnych kredytów. Zawsze renderuj najpierw krótki klip. Wyświetl jego podgląd, oceń, czy rejestr odbiera się jako Miku, dostosuj i dopiero wtedy zatwierdź pełną generację. Ten jeden nawyk oszczędza więcej kredytów niż jakikolwiek inny.
Jeszcze jedna możliwość warta poznania na później: AI Dubbing platformy obsługuje dubbing z ponad 60 języków źródłowych na 33 języki docelowe, co staje się przydatne, gdy chcesz zlokalizować gotowe treści fanowskie dla międzynarodowej publiczności.
Dostrajanie charakterystycznego brzmienia: wysokość, ton i charakter głosu
Tutaj większość prób się rozpada. Ludzie podkręcają wysokość, słyszą coś wysokiego i zakładają, że skończyli — ale wysoki klip TTS to nie głos AI Hatsune Miku. Postać żyje w konkretnej kombinacji rejestru, artykulacji i ciężaru. Trafisz w nie, a głos odbiera się jako Miku jeszcze zanim ktokolwiek usłyszy choćby jedno rozpoznawalne słowo.
Celuj we właściwą barwę. Badania VOCALOID:AI firmy Yamaha przedstawiają nowoczesne syntetyczne wokale jako dążące do naturalnej artykulacji i jasnej barwy, a nie ciężkich robotycznych ustawień. Celuj w kierunku czystego, wysokiego, precyzyjnie artykułowanego głosu — nigdy brzęczącego monotonu. Współczesny syntetyczny dźwięk jest jasny i przejrzysty, a nie mechaniczny. Jeśli twój wynik brzmi jak robot czytający menu telefoniczne, za bardzo go spłaszczyłeś.
Pchnij wysokość w stronę sufitu, ale zatrzymaj się przed artefaktami. Jakość „Miku" żyje w suficie wysokości połączonym z wyraźnymi spółgłoskami, a nie w głośności. Podnoś rejestr, aż dojdziesz do krawędzi słyszalnych artefaktów — tej cienkiej, glitchowatej, cyfrowo rozciągniętej jakości — a następnie cofnij się lekko. Optymalny punkt jest wysoki i jasny, ale wciąż czysty. Głos, który jest zbyt nisko nastrojony, brzmi po prostu jak zwykły TTS, co jest najczęstszym pojedynczym błędem.
Prędkość i artykulacja niosą więcej, niż byś się spodziewał. Nieco szybsza, czystsza wymowa odbiera się jako syntetyczno-słodka, co jest rdzeniem postaci. Nadmiernie znaturalizowana zadyszka ściąga głos z powrotem ku „ogólnemu narratorowi". Zacieśnij artykulację. Spraw, by spółgłoski wyraźnie wybrzmiewały. Ta precyzja jest częścią tego, co twoje ucho rozpoznaje jako syntezator wokalny, a nie człowieka.
Kontroluj zadyszkę agresywnie. Zmniejsz oddech i ciepło. Miku odbiera się jako niemal nieważka — brakuje jej piersiowego rezonansu naturalnego dorosłego głosu. Jeśli słyszysz oddech, powietrze i płuca w wyniku, oddalasz się od postaci. Syntetyczna krawędź zależy od tej nieważkości. Zbyt zadyszane, a tracisz ją całkowicie.
Miku nie żyje w słowach — żyje w suficie wysokości i wyraźnej, niemal nieważkiej artykulacji.
Wynik japoński kontra angielski zachowuje się inaczej. Japońskie fonemy mają tendencję do wybrzmiewania w sposób, który odbiera się jako bardziej „klasyczna Miku", częściowo dlatego, że to dźwięk, który większość słuchaczy kojarzy z postacią. Wynik angielski potrzebuje ściślejszej artykulacji, aby uniknąć ześlizgnięcia się w terytorium ogólnego TTS. Jeśli pracujesz po angielsku i brzmi to płasko, naprawą są zwykle wyraźniejsze spółgłoski i wyższy rejestr, a nie więcej głośności.
Przygotuj czystą referencję klonu, zanim cokolwiek zrobisz. Jeśli klonujesz, a nie wybierasz standardowego głosu, jakość referencji decyduje o wszystkim. Sprawdź, czy przejrzystość jest wystarczająco wysoka dla czystej transkrypcji — jeśli AI ma trudność z transkrypcją, twój klon też będzie zamglony. Użyj Speech Separator, aby wyizolować czysty wokal z dowolnej muzyki w tle przed klonowaniem. Śmieci na wejściu produkują zamglony klon, za każdym razem. Dla twórców przygotowujących wiele referencji naraz, programowy dostęp przez Voice Cloning API czyni przygotowanie wsadowe znacznie mniej żmudnym.
Błędy grupują się w trzy wzorce. Wysokość zbyt niska brzmi jak zwykły TTS. Zbyt zadyszane traci syntetyczną krawędź. Robotyczny monoton nadmiernie spłaszcza głos, co bezpośrednio przeczy punktowi odniesienia jasnej artykulacji VOCALOID:AI. Unikaj wszystkich trzech, a jesteś w większości u celu.
Wreszcie, zaakceptuj, że surowa synteza to pierwsze podejście. Przewodniki tworzenia Vocaloid podkreślają, że strojenie fonemów, czasu i dynamiki jest obowiązkowe dla przekonującego efektu — i ta sama dyscyplina dotyczy generatorów AI. Tutorial coverów VSynth i przewodnik dla początkujących Vocaloid traktują pierwsze renderowanie jako początek pracy, a nie jej koniec. Generuj, słuchaj krytycznie, dostosuj, generuj ponownie. Głos, który odbiera się jako Miku, prawie nigdy nie jest pierwszym, który zrobisz.
Od mowy do śpiewu: zamiana wygenerowanego głosu w ścieżkę wokalną
Oto uczciwa luka: większość generatorów AI mówi, ale Miku jest sławna ze śpiewu. Przerzucenie mostu nad tą luką wymaga kilku celowych kroków i DAW. Oto jak zamienić mówione frazy z generatora głosu miku w śpiewaną ścieżkę wokalną dla covera AI Miku.
1. Wygeneruj czyste frazy wokalne. Twórz krótkie, dobrze artykułowane linie, a nie jeden długi blok tekstu. Krótkie frazy są znacznie łatwiejsze do mapowania wysokości i dopasowania do melodii. Czterotaktowa fraza, którą możesz wepchnąć na miejsce, bije trzydziestosekundowy monolog, który musisz chirurgicznie ciąć na kawałki.
2. Określ BPM utworu. Użyj narzędzia do liczenia BPM w przeglądarce, stukając razem, aż średnie tempo się ustabilizuje, a następnie ustaw najbliższy całkowity BPM w swoim DAW. Tutorial coverów VSynth zauważa, że „w 99,9% przypadków potrzebujesz tylko liczby całkowitej BPM", ponieważ piosenki rzadko są mierzone w dziesiętnych. Nie kombinuj za bardzo — czyste całkowite tempo jest prawie zawsze poprawne.
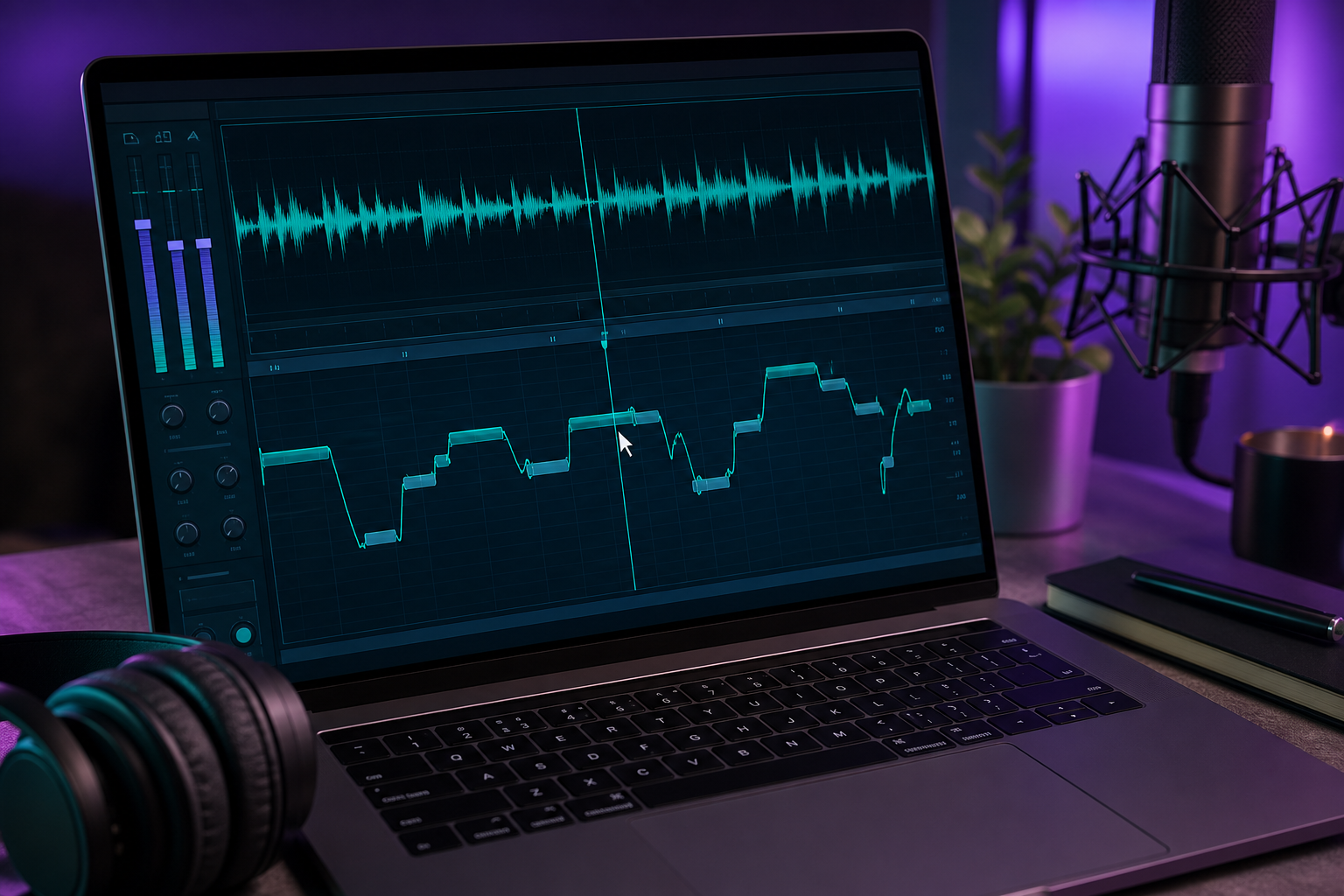
3. Zaimportuj frazy do DAW w projekcie z kwantyzacją siatki. Skonfiguruj projekt tak, aby klipy wokalne przyciągały się do czasu względem ścieżki podkładowej. Kwantyzacja siatki to to, co utrzymuje syntetyzowany wokal zsynchronizowany z instrumentalem — bez niej wszystko dryfuje. Ta dyscyplina siatki i tempa jest standardowym warunkiem wstępnym przed rozpoczęciem jakiejkolwiek pracy nad strojeniem.
4. Dopasuj wysokość fraz do melodii. Użyj Melodyne lub auto-tune, aby naginać każdą frazę na właściwe nuty. Ten krok jest wymagany, a nie opcjonalny, ponieważ ogólny AI TTS nie obsługuje natywnie kontroli wysokości muzycznej. Generator dał ci barwę i słowa; DAW daje ci melodię. To najbardziej pracochłonna część całego procesu i to tutaj śpiewany cover jest faktycznie tworzony.
5. Nałóż na ścieżkę podkładową i zmiksuj. Połóż nastrojony wokal na instrumentalu, dostosuj czas i dynamikę oraz dodaj lekkie efekty — pogłos, odrobinę kompresji, może doubler dla pogrubienia. Słuchaj fraz, które siedzą zbyt daleko z przodu lub z tyłu i zrównoważ je względem miksu.
To także dokładnie to miejsce, gdzie AI TTS się kończy, a dedykowane narzędzia do syntezy śpiewu zaczynają. Jeśli chcesz prawdziwej kontroli melodycznej nuta po nucie w jednym edytorze — bez pętli eksport-import-ponowne strojenie — licencjonowana droga Vocaloid lub Synthesizer V jest bardziej bezpośrednia, jak omówiono wcześniej. Droga AI-plus-DAW wymienia tę integrację na szybkość i niestandardową barwę. Żadna nie jest zła; służą różnym producentom.
Eksport, lokalizacja i skalowanie treści w stylu Miku
Masz głos, który odbiera się jako Miku, i utwór, który się składa. Oto jak dobrze go wydać i rozciągnąć swoje zasoby.
Formaty eksportu i jakość. Wyświetlaj podgląd w jakości roboczej podczas iterowania, a następnie wyeksportuj swoje finalne audio w pełnej jakości, gdy będziesz zadowolony. Nawyk roboczy-potem-finalny utrzymuje twoje renderowania tanimi podczas chaotycznego środka i wydaje jakość premium tylko na wersję, którą faktycznie zachowujesz. Zawsze potwierdź, że format eksportu odpowiada temu, czego oczekuje twój DAW lub edytor wideo, zanim zatwierdzisz.
Wykorzystuj kredyty przenoszone efektywnie. Ponieważ model kredytowy przenosi niewykorzystane kredyty, możesz grupować pracę generacyjną i ponownie wykorzystywać kredyty między sesjami, zamiast spalać je na powtarzające się testy pełnego renderowania. Wygeneruj kilka fraz w jednej skupionej sesji, wyświetl ich podgląd, a następnie dopracuj — zamiast renderować, słuchać i ponownie renderować po jednej linii naraz przez wiele dni.
Lokalizuj treści fanowskie na inne języki. Użyj AI Dubbing, aby przenieść gotową linię w stylu Miku na inne języki. Z obsługą ponad 60 języków źródłowych i 33 języków docelowych, pojedyncza ścieżka fanowska może dotrzeć do międzynarodowej publiczności bez ponownego nagrywania lub ponownego strojenia od zera. Dla postaci z globalną bazą fanów ten zasięg jest znaczący.
Skorzystaj z dostępu API dla deweloperów. Zespoły budujące funkcje głosu w stylu Miku w swoich własnych aplikacjach mogą integrować bezpośrednio przez Text to Speech API, Voice Cloning API i AI Dubbing API. To zamienia ręczny kreatywny przepływ pracy w programowy — przydatny dla agencji, twórców aplikacji i każdego generującego treści głosowe na dużą skalę.
Połącz głos z wizualizacjami. Dla filmów fanowskich i treści w stylu teledysków wygeneruj pasującą grafikę za pomocą generatora obrazów AI i animuj zdjęcia za pomocą Image to Video. Jedno ostrzeżenie przenosi się z sekcji prawnej: ograniczenia CC BY-NC dla oficjalnej sztuki postaci nadal obowiązują, więc oryginalne lub prawidłowo przypisane wizualizacje utrzymują cię na bezpiecznym gruncie.
Unikaj pułapek monetyzacji przy eksporcie. Zanim cokolwiek zmonetyzujesz, potwierdź, że twój projekt pozostaje w obrębie ustanowionych wcześniej ograniczeń niekomercyjnych i marketingu postaci. Użycie komercyjne — sprzedaż, zmonetyzowane kampanie, produkty markowe — wymaga osobnego pozwolenia od Crypton, zgodnie z oficjalnymi warunkami Crypton i licencją Piapro. Sprawdzenie tego przed kliknięciem publikuj jest znacznie tańsze niż rozplątywanie tego po fakcie.
Twoja lista kontrolna przed generowaniem głosu Miku
Przejrzyj to, zanim cokolwiek wygenerujesz. Każdy element to szybkie sprawdzenie, które oszczędza poprawki później.
- Zdecydowano: mowa czy śpiew — TTS do dialogu; klonowanie plus DAW do śpiewanego coveru.
- Potwierdzono twoje podejście prawne/użytkowe — niekomercyjne użycie fanowskie, czy potrzebujesz pozwolenia Crypton na wydanie komercyjne?
- Wybrano jasny profil głosu LUB przygotowano czystą ~20-sekundową referencję klonu — wyizoluj wokal najpierw, jeśli klonujesz.
- Dostrojono wysokość i ton do rejestru Miku — wysoki, wyraźny, niska zadyszka, nigdy robotyczny.
- Wyświetlono podgląd krótkich klipów przed wydaniem pełnych kredytów — chroń swój bilans kredytów.
- Ustawiono całkowity BPM i projekt DAW z kwantyzacją siatki — jeśli śpiewasz, zrób to przed mapowaniem wysokości.
- Wybrano format eksportu i jakość — roboczy podczas iterowania, pełna jakość dla finału.
- Zaplanowano lokalizację — jeśli chcesz wielojęzycznego zasięgu fanowskiego, ustaw swoje języki docelowe.
Szybki przewodnik decyzyjny: Wybierz TTS, jeśli potrzebujesz szybkiego dialogu; wybierz klonowanie plus DAW, jeśli produkujesz piosenkę.
Gotowy, by jeden zbudować? Zacznij na darmowym poziomie DubSmart AI z Text to Speech, wygeneruj krótki klip i dostrój rejestr, zanim zatwierdzisz choćby jeden kredyt pełnego renderowania. Najpierw podgląd, dopracuj, potem wydaj — to cała dyscyplina stojąca za przepływem pracy generatora głosu Miku, który faktycznie brzmi dobrze.
Najczęściej zadawane pytania
Czy legalne jest używanie generatora głosu Hatsune Miku na YouTube?
To zależy od intencji komercyjnej kontra niekomercyjnej. Licencja CC BY-NC 3.0 firmy Crypton obejmuje niekomercyjne użycie sztuki postaci z przypisaniem autorstwa, ale zmonetyzowane lub komercyjne użycie wymaga osobnego pozwolenia, a nie możesz reklamować piosenki jako „śpiewanej przez" postać, zgodnie z Crypton i Vocaloid Wiki. Zbuduj oryginalny głos inspirowany Miku dla bezpieczniejszych treści fanowskich.
Czy mogę sprawić, by Miku śpiewała, czy tylko mówiła?
AI TTS generuje wynik mówiony i nie ma natywnej kontroli wysokości muzycznej. Aby śpiewać, kieruj swoje frazy przez DAW i dopasuj ich wysokość za pomocą Melodyne lub auto-tune, jak pokazano w tutorialu coverów VSynth. Dla wbudowanego wprowadzania nut w jednym edytorze, licencjonowany Vocaloid lub Synthesizer V to bardziej bezpośrednia droga.
Ile audio potrzebuję, aby sklonować głos w stylu Miku?
Możesz klonować z około 20 sekund czystego nagrania referencyjnego. Wyizoluj wokal z dowolnej muzyki podkładowej najpierw dla najczystszego wyniku — i pamiętaj, że klonowanie głosu prawdziwej, możliwej do zidentyfikowania osoby budzi kwestie prawa do wizerunku, zgodnie z Respeecher. Użyj klonowania głosu z dobrze przygotowaną referencją.
W jakich językach można wygenerować głos AI Miku?
Platforma obsługuje dubbing z ponad 60 języków źródłowych na 33 języki docelowe, więc gotowa linia może być zlokalizowana dla międzynarodowej publiczności fanowskiej. To czyni pojedynczy cover AI Miku możliwym do ponownego użycia w wielu wersjach regionalnych bez ponownego nagrywania.
Czy istnieje darmowy sposób, aby wypróbować generator głosu miku?
Tak — istnieje darmowy poziom plus model kredytowy z kredytami przenoszonymi, więc niewykorzystane kredyty przechodzą dalej, a nie wygasają. Wyświetlaj podgląd krótkich klipów przed zatwierdzeniem pełnych kredytów, a możesz przetestować cały przepływ pracy przed podjęciem decyzji o skalowaniu.