
Wyeksportowałeś plik dziennika ze starego systemu i otworzyłeś go, aby znaleźć linie takie jak 72 101 108 108 111 32 87 111 114 108 100 zamiast czytelnych słów. Lub developer przekazał ci zrzut konfiguracji pełny par szesnastkowych (48 65 6C 6C 6F) i powiedział "po prostu to odkoduj." W takim miejscu generator ASCII na tekst pokazuje swoją wartość — bierze te surowe kody numeryczne i zamienia je z powrotem na znaki, które może przeczytać człowiek.
Ten przewodnik wyjaśnia, jak dekodowanie ASCII faktycznie działa, porównuje pięć darmowych narzędzi obok siebie, przeprowadza konwersję szesnastkową na tekst i pokazuje, gdy ASCII nie jest kodowaniem, które powinieneś wybierać.

Spis treści
- Co kodowanie ASCII faktycznie przechowuje (i dlaczego pojawia się jako liczby)
- Jak generator ASCII na tekst dekoduje kody numeryczne pod spodem
- Pięć darmowych generatorów ASCII na tekst — porównanie
- Przewodnik krok po kroku — konwersja szesnastkowego ASCII na czytelny tekst
- Rozwiązywanie problemów, gdy konwersja ASCII zwraca bigos
- Automatyzacja dekodowania ASCII za pomocą Pythona, JavaScriptu i arkuszy kalkulacyjnych
- ASCII vs Unicode — dlaczego przepływy pracy "tylko ASCII" po cichu łamią nowoczesną zawartość
- Lista kontrolna przed startem — potwierdź, że dekodowanie ASCII jest właściwą poprawką przed rozpoczęciem
Co kodowanie ASCII faktycznie przechowuje (i dlaczego pojawia się jako liczby)
ASCII to kodowanie 7-bitowe z dokładnie 128 punktami kodowymi (0–127). Według referencji ASCII z Wikipedii, te 128 kodów dzielą się na 95 znaków drukowanych (spacja na kodzie 32 przez tyldę ~ na kodzie 126) i 33 znaki sterujące (kody 0–31 plus 127). Znaki sterujące to nie widoczne glify — to funkcjonalne instrukcje takie jak NUL (0), dzwonek (7), przesunięcie wiersza (10) i powrót karetki (13). Zestaw drukowany obejmuje alfabet angielski wielkie i małe litery, dziesięć cyfr, wspólną interpunkcję i kilka symboli.
Każdy kod mapuje się do dokładnie jednego znaku. 65 = 'A'. 97 = 'a'. 48 = '0'. 32 = spacja. 10 = przesunięcie wiersza. Te mapowania są ustalone standardem ANSI X3.4 i nie zmieniły się od 1968 roku.
Kody ASCII są przechowywane na 7 bitach, ale przesyłane w 8-bitowych bajtach z wysokim bitem ustawionym na 0, zgodnie z referencją ASCII dCode. Ten jeden nieużywany bit to dlaczego istnieje wiele schematów „rozszerzonego ASCII" — Latin-1, Windows-1252, strony kodowe IBM — wszyscy twierdzą, że kody 128–255 należą do nich, ale żaden z nich to nie ASCII.
Kiedy widzisz liczby zamiast liter, patrzysz na surowe kody. Plik lub strumień wyjścia został serializowany jako wartości numeryczne — szesnastkowo jak 0x48, dziesiętnie jak 72, binarnie jak 01001000 lub ósemkowo jak 110 — zamiast być renderowanym jako glify. Generator ASCII na tekst odwraca tę serializację. Niczego nie dekryptuje. Niczego nie naprawia. Po prostu wyszukuje każdą liczbę w tej samej stałej tabeli mapowania.
To jest część, którą większość początkujących źle rozumie: ASCII to nie „uszkodzony tekst" — to tekst, który nie został jeszcze renderowany. Konwerter nie naprawia uszkodzenia. Interpretuje reprezentację numeryczną zgodnie ze znanym standardem.
Oto przewodnik w jednej linii. Weź 72 101 108 108 111. Wyszukaj każdą wartość: 72='H', 101='e', 108='l', 108='l', 111='o'. Złącz. Dostajesz "Hello." To cały algorytm.
Użyteczny kontekst dla każdego pracującego z kodowaniem tekstu: Konsorcjum Unicode definiuje swoje pierwsze 128 punktów kodowych (U+0000 przez U+007F) jako identyczne z ASCII. To nie był wypadek — to była celowa kompatybilność wsteczna. Każdy plik tekstu w czystym ASCII to automatycznie ważny plik UTF-8. Nie potrzeba konwersji. To dlatego problem ASCII-na-tekst to fundamentalnie starszy problem: spotykasz go tylko, gdy coś gdzieś wybrało serializować tekst jako nagie liczby zamiast standardowych bajtów.
Gdzie faktycznie pojawiają się te zrzuty numeryczne? Zrzuty szesnastkowe z xxd lub hexdump, ciągi zakodowane w URL, wyzwania CTF, dzienniki urządzeń wbudowanych, przechwycenia pakietów (eksporty Wiresharka), ekstrakcje BLOB bazy danych, ślady protokołu sieciowego i materiały edukacyjne. Wszędzie tam, gdzie developer lub narzędzie wybrało wyświetlać bajty jako liczby czytelne zamiast próbowania ich renderowania.

Jak generator ASCII na tekst dekoduje kody numeryczne pod spodem
To, co wygląda jak „konwersja", to technicznie dekodowanie: narzędzie czyta każdy token numeryczny, analizuje go zgodnie z zadeklarowaną bazą (szesnastkowo, dziesiętnie, binarnie, ósemkowo), mapuje go na punkt kodowy i wykonuje wyszukiwanie znaku. W JavaScripcie to wyszukiwanie to String.fromCharCode(). W Pythonie to chr(). W Excelu to =CHAR(). Ta sama operacja, trzy składnie.
Implementacja ma znaczenie, ponieważ różne wyszukiwania mają różne limity. Według dokumentacji konwertera ASCII CodeShack, ich narzędzie używa String.fromCharCode() na jednostkach kodowych UTF-16. To obsługuje ASCII (0–127) i większość Unicode Podstawowej Płaszczyzny Wielojęzycznej (do 0xFFFF), ale dyskretnie zawodzi na znakach płaszczyzny dodatkowej, które wymagają par zastępczych — większość emoji, na przykład, nie przetrwa ten podход.
Wiele narzędzi internetowych akceptuje kody 0–255 (tzw. „rozszerzone ASCII"), mimo że kody 128–255 nie są częścią standardu ASCII. Według dokumentacji narzędzia Code Beautify, ich konwerter pracuje w tym zakresie 0–255. Górne 128 kodów jest interpretowanych przy użyciu niezależnie od tego, jaką domyślną stronę kodową narzędzie zakłada — zwykle Latin-1 lub Windows-1252 — dlatego wklejenie 255 do jednego narzędzia daje ÿ, podczas gdy wklejenie go do ścisłego dekodera ASCII wyrzuca błąd.
Istnieje również kwestia formatu wejściowego. Szesnastkowo (48 65 6C 6C 6F), dziesiętnie (72 101 108 108 111), binarnie (01001000 01100101 01101100 01101100 01101111) i ósemkowo (110 145 154 154 157) kodują to samo słowo: „Hello." Narzędzie po prostu musi wiedzieć, którą bazę mu dajesz.
| Metoda dekodowania | Wejście akceptowane | Co się dzieje wewnętrznie | Ograniczenie |
|---|---|---|---|
| Generator ASCII sieciowy | Szesnastkowo, dziesiętnie, binarnie, ósemkowo | JS String.fromCharCode() na tokenach parsowanych | Brak par zastępczych; ufa zadeklarowanej bazie |
Python bytes.fromhex().decode('ascii') | Ciąg szesnastkowy | Obiekt bajtów → kodek ASCII | Błędy na kodach >127 bez errors='replace' |
Arkusz kalkulacyjny =CHAR(code) | Jedna wartość dziesiętna na komórkę | Wbudowane wyszukiwanie punktu kodowego | Jedna komórka na raz; bez parsowania wsadowego |
Linia poleceń xxd -r -p | Strumień szesnastkowy | Odwróć zrzut szesnastkowy na surowe bajty | Wyświetla bajty; pipe do terminala, aby wyświetlić |
Każda metoda wyżej wykonuje tę samą operację logiczną: token → punkt kodowy → glyf. Różnice są interfejsem, rozmiarem wsadu i jak ściśle każda wymusza zakres ASCII. Generator sieciowy wybacza ci nieuporządkowany ograniczniki; bytes.fromhex() Pythona odrzuci cokolwiek, co nie jest czystą parą cyfr szesnastkowych. =CHAR() Excela obsługuje jedną wartość na raz, ale żyje w arkuszu kalkulacyjnym, gdzie już masz swoje dane. Podejście wiersza poleceń skaluje się do gigabajtów, ale zakłada, że czujesz się komfortowo w terminalu.
Wybierz miejsce, gdzie twoje dane już żyją, a nie które narzędzie wygląda najładniej. Jeśli masz ciąg szesnastkowy na karcie przeglądarki, użyj narzędzia sieciowego. Jeśli masz kolumnę kodów CSV, użyj formuły arkusza kalkulacyjnego. Jeśli masz zrzut szesnastkowy 200 MB, użyj Pythona lub xxd. Ścisła granica ASCII (kod >127 błędy) ma największe znaczenie, gdy audytujesz, czy twoje dane to faktycznie ASCII czy tylko oznakowzanie jako ASCII. Ścisła wersja mówi ci prawdę. Wybaczająca wersja udaje, że wszystko jest w porządku. Więcej na temat relacji UTF-8 do ASCII jako jednobajowego podzbioru, patrz RFC 3629.
Generator ASCII na tekst nie naprawia uszkodzonych danych — interpretuje reprezentację numeryczną. Jeśli liczby weszły źle, litery wyjdą źle.
Pięć darmowych generatorów ASCII na tekst — porównanie (co każdy robi najlepiej)
Pięć narzędzi, wszystkie darmowe, wszystkie żyją w przeglądarce. Każde ma jeden scenariusz, w którym bije inne.
Konwerter ASCII CodeShack akceptuje dziesiętne, szesnastkowe, binarne i ósemkowe w jednym interfejsie i używa String.fromCharCode() pod spodem. UI ujawnia mechanizm konwersji, co czyni go właściwym wyborem dla developerów, którzy chcą sprawdzić, co się dzieje, zamiast traktować to jako czarną skrzynkę. Źródło: codeshack.io/ascii-to-text-converter.
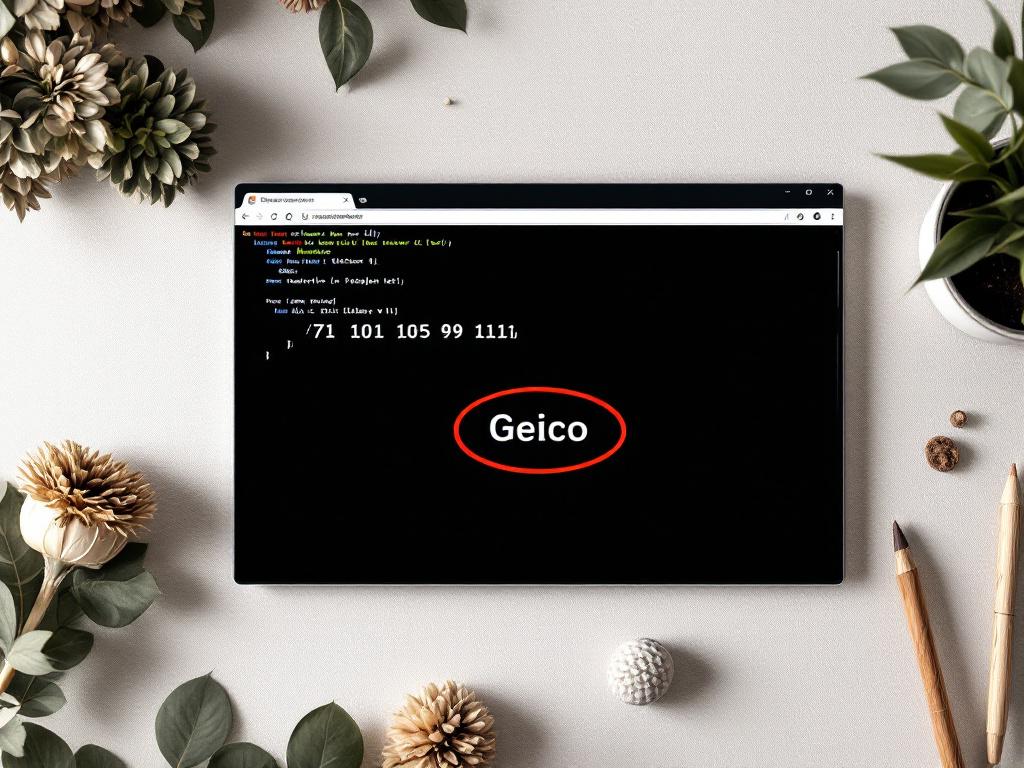
Code Beautify ASCII na tekst akceptuje kody numeryczne w zakresie 0–255, obsługuje URL i przesyłanie pliku, oraz demonstruje konwersję z przykładowymi danymi — 71 101 105 99 111 → "Geico". Przesyłanie pliku to to, co je wyróżnia: kiedy zrzut szesnastkowy ma 50 MB, wklejenie do pola tekstowego nie jest wykonalne. Źródło: codebeautify.org/ascii-to-text.
Browserling Text na ASCII domyślnie działa w przeciwnym kierunku (tekst → kody ASCII), co czyni go przydatnym do weryfikacji pełnej pętli. Zakoduj znany ciąg, odkoduj go gdzie indziej, potwierdź, że odzyskujesz oryginał. UI jest minimalny i skoncentrowany na developerach. Źródło: browserling.com/tools/text-to-ascii.
Duplichecker ASCII na tekst używa dwuetapowego przepływu wklejania i klikania oraz tworzy pobieranie .txt. Pobieranie to różnica — kiedy niespecjalistyczny kolega pyta "konwertuj to i prześlij mi plik", Duplichecker to ścieżka najmniejszego oporu. Źródło: duplichecker.com/ascii-to-text.php.
Utilities-Online ASCII na tekst wyświetla wyniki inline bez kroku pobierania. To najszybsze narzędzie do wyszukiwań „co oznacza kod 65" — zasadniczo cyfrowe zastąpienie wydrukowanej tabeli ASCII, która kiedyś żyła obok monitora każdego programisty. Źródło: utilities-online.info/ascii-to-text.
| Narzędzie | Szesnastkowo | Dziesiętnie | Binarnie | Ósemkowo | Przesyłanie pliku |
|---|---|---|---|---|---|
| CodeShack | Tak | Tak | Tak | Tak | Nie |
| Code Beautify | Tak | Tak | Tak | Tak | Tak |
| Browserling | Nie | Tak | Nie | Nie | Nie |
| Duplichecker | Tak | Tak | Nie | Nie | Nie |
| Utilities-Online | Tak | Tak | Nie | Nie | Nie |
CodeShack wygrywają dla developerów, którzy chcą elastyczności formatu na jednej karcie — szesnastkowy dziś rano, binarny dziś po południu, ósemkowy w następnym tygodniu, wszystko bez przełączania narzędzi. Code Beautify wygrywa, gdy dane źródłowe istnieją jako plik i nie chcesz wklejać megabajta do textarea. Browserling wygrywa pracę weryfikacyjną: koduj w jednym kierunku, dekoduj w innym, potwierdź integralność pełnej pętli. Duplichecker wygrywa, gdy wymagane jest dostarczenie i odbiorca nie zaakceptuje "wyślę ci kody, po prostu sam je odkoduj". Utilities-Online wygrywa wyszukiwanie jednorazowe — pojedyncza wartość, natychmiastowa odpowiedź, bez ceremonii.
Jedno krytyczne zastrzeżenie przed wklejeniem czegokolwiek: nie umieszczaj wrażliwych danych w żadnym z tych narzędzi. Klucze API, dane osobowe klientów, poświadczenia bazy danych, wewnętrzne dane dziennika, cokolwiek podlegające HIPAA, GDPR lub PCI-DSS — nic z tego nie należy do narzędzia przeglądarki strony trzeciej. Arkusz tematyczny ochrony danych OWASP jest jasny na ten temat: dane wysłane do usług zewnętrznych to dane poza twoją kontrolą, niezależnie od tego, co twierdzi polityka prywatności dostawcy. Dla czegokolwiek wrażliwego, użyj podejścia Python w sekcji 6 — twoje bajty nigdy nie opuszczą twojego laptopa.
Przewodnik krok po kroku — konwersja szesnastkowego ASCII na czytelny tekst
Ciąg testowy dla tego przewodnika: 48 65 6C 6C 6F 20 57 6F 72 6C 64. Prawidłowe odkodowane wyjście: "Hello World." Użyj tego jako linii bazowej walidacji — jeśli nie dostajesz "Hello World," coś w twoim procesie jest źle.
- Zidentyfikuj format wejściowy. Spójrz na dane. Litery A–F mieszane z cyframi? To szesnastkowo. Tylko cyfry, idące do ~127? Dziesiętnie. Tylko 0 i 1 w grupach 7 lub 8 znaków? Binarnie. Cyfry 0–7 tylko, bez 8 lub 9? Ósemkowo. Złe zgadywanie daje mojibake — zła baza mapuje każdy token na zupełnie inny znак. Powiedz narzędziu wprost, które masz.
- Wybierz właściwe narzędzie z porównania powyżej. W tym przykładzie użyj CodeShack — obsługuje wszystkie cztery bazy w jednym UI. Dla plików większych niż ~1 MB, przejdź do Pythona (omówiono w sekcji 6). Dla szybkiego wyszukiwania pojedynczej wartości, Utilities-Online jest szybsze.
- Wklej swoje wejście. Upuść
48 65 6C 6C 6F 20 57 6F 72 6C 64do pola wejściowego. Upewnij się, że rozwijaną stronę formatów ustawiono na "Szesnastkowo." Potwierdź ogranicznik, którego narzędzie oczekuje — większość akceptuje spacje, niektóre akceptują przecinki, kilka wymaga braku ogranicznika. - Kliknij Convert. Wyjście powinno brzmieć "Hello World." Jeśli tak nie jest, najczęstsze przyczyny (w kolejności): wybrana nieprawidłowa baza, nieprawidłowy ogranicznik (spacje vs przecinki vs nic), lub przedrostek
0xjest obecny, gdy narzędzie oczekuje go usuniętego (lub vice versa). - Waliduj względem znanej referencji. Zawsze sprawdzaj co najmniej jeden odkodowany znak względem znanego mapowania. 65 = 'A', 97 = 'a', 48 = '0', 32 = spacja, 10 = przesunięcie wiersza. Jeśli te nie dekodują się prawidłowo w twoim teście, narzędzie, wejście lub deklarowana baza są źle. Nie ufaj pozostałemu wyjściu, dopóki wartości referencyjne się nie zgadzają.
- Skopiuj wyjście do docelowego miejsca. Przy wklejaniu do Excela lub Arkuszy Google, użyj Wklej specjalnie → Wartości (Ctrl+Shift+V), aby uniknąć interpretacji przez arkusz odkodowanego tekstu jako formuły. Wiodące
=lub+w odkodowanym wyjściu inaczej wyzwoli ocenę formuły i zepsuje komórkę.
Częste pułapki. Mieszane ograniczniki kąsają najcieżej — wklejenie zawierające zarówno przecinki jak i spacje będzie parsować niespójnie na większości narzędzi. Przesunięcia wierszy z kopii-wklejenia dają niewidoczne znaki w wyjściu (dekodują się do kodów sterujących 10 lub 13). Przedrostek 0x to moneta — narzędzie Duplichecker chce go usuniętego; niektóre ścieżki Pythona go wymagają; Utilities-Online toleruje oba. Gdy masz wątpliwości, znormalizuj swoje wejście do jednego spójnego formatu (ogranicznik jednej spacji, bez przedrostka, szesnastkowo małe litery) przed wklejeniem.
Rozwiązywanie problemów, gdy konwersja ASCII zwraca bigos
Pięć trybów awarii, mniej więcej w kolejności, jak często je napotkasz.
- "Moje wyjście ma dziwne symbole, takie jak é, ’ lub ÿ zamiast liter." Twoje dane to nie czysty ASCII — to prawie na pewno UTF-8 dekodowany jako Latin-1 lub vice versa. ASCII definiuje tylko kody 0–127. Cokolwiek powyżej tego to nie ASCII, niezależnie od tego, co twierdzi system źródłowy. Uruchom bajty przez dekoder UTF-8 zamiast tego, lub użyj
chardet(Python) do auto-wykrycia faktycznego kodowania. Esej Joela Spolskiego'ego na temat tego dokładnego trybu awarii jest obowiązkową lekturą: Absolutne minimum, które każdy developer musi wiedzieć o Unicode i zestawach znaków. - "Konwerter mówi „nieprawidłowe wejście" lub „błąd parsowania"." Zmieszałeś bazy — tokeny szesnastkowe i tokeny dziesiętne w jednym wklejeniu — lub włączyłeś przedrostek
0x, gdy narzędzie go nie oczekuje, lub pozostawiłeś znaki nie-numeryczne, takie jak przecinki, nawiasy lub cudzysłowy z zrzutu JSON. Usuń wejście do jednego spójnego formatu z jednym spójnym ogranicznikiem. Jedna spacja między tokenami to najbezpieczniejsze domyślne ustawienie na wszystkich narzędziach. - "Wyjście jest puste lub tylko przesunięcia wiersza." Twoje wejście zawiera tylko znaki sterujące (kody 0–31). LF (10), CR (13), TAB (9) i NUL (0) nie renderują się jako widoczne glify — to funkcjonalne instrukcje dla terminala lub wyświetlacza. Dekodowanie się powiodło; wyjście po prostu nie jest widoczne. Otwórz wynik w przeglądarce szesnastkowej, aby potwierdzić istnienie bajtów, lub pipe przez
cat -Ana Linuksie, aby uczynić nie-drukowalne widoczne. - "To zadziałało, ale brakuje moim emoji lub akcentowanym znakom." ASCII nie może reprezentować emoji ani żadnego skryptu nie-angielskiego. Konsorcjum Unicode definiuje 149 186 znaków w 161 skryptach w wersji 15.0 — ASCII obejmuje 95 drukowanych angielsko-centrycznych. Jeśli twój oryginalny tekst zawierał ñ, ü, ç, mandaryński, cyrylicę, arabski lub 😀, te znaki nigdy nie były reprezentowalne w 7-bitowym ASCII. Kody numeryczne, które trzymasz, to bajty UTF-8, które potrzebują dekodera UTF-8, nie narzędzia ASCII.
- "Niektóre znaki w moim rzekomo-ASCII pliku odkodowały się źle." Prawdopodobnie znaki płaszczyzny dodatkowej Unicode wymagające obsługi par zastępczych, którą większość prostych generatorów ASCII (w tym CodeShack) nie implementuje. Według dokumentacji CodeShack, ich podejście
String.fromCharCode()obsługuje znaki BMP do 0xFFFF, ale nie punkty kodowe płaszczyzny dodatkowej. Zamiast tego użyjbytes.decode('utf-8')Pythona — obsługuje pełny zakres Unicode prawidłowo.
Jeśli twoje wyjście ma akcentowane znaki, które wyszły źle, nie masz problemu ASCII — masz problem UTF-8 w kostiumie ASCII.
Automatyzacja dekodowania ASCII za pomocą Pythona, JavaScriptu i arkuszy kalkulacyjnych
Kiedy dekodują ASCII więcej niż raz w tygodniu, narzędzia sieciowe kosztują czas i tworzą ekspozycję prywatności. Czteroliniowy skrypt Pythona lub formuła arkusza kalkulacyjnego obsługuje konwersję wsadową lokalnie bez pośrednika trzeciej strony. Te trzy opcje poniżej obejmują developerów, środowiska sieciowe i analityków mieszkających w Excelu — wybierz tę, która pasuje do tego, gdzie twoje dane już są.
Python (ciąg szesnastkowy na ASCII):
hex_data = "48 65 6C 6C 6F 20 57 6F 72 6C 64"
text = bytes.fromhex(hex_data.replace(" ", "")).decode("ascii")
print(text) # → Hello World
bytes.fromhex() wymaga brak spacji w swoim wejściu, więc usuwamy je za pomocą .replace(). .decode("ascii") wyrzuci UnicodeDecodeError na każdym bajcie większym niż 127, co jest dokładnie tym, czego chcesz przy walidowaniu ścisłego ASCII — błąd to informacja diagnostyczna, a nie porażka. Aby tolerować rozszerzone znaki, zamień na .decode("utf-8") na nowoczesny tekst lub .decode("latin-1") dla danych starszych Europy Zachodniej.
JavaScript (tablica dziesiętna na tekst):
const codes = [72, 101, 108, 108, 111, 32, 87, 111, 114, 108, 100];
const text = String.fromCharCode(...codes);
console.log(text); // → Hello World
String.fromCharCode() akceptuje jednostki kodowe aż do ~65,535 (limit BMP). Dla punktów kodowych poza tym, użyj String.fromCodePoint() do prawidłowego obsługiwania par zastępczych — to jest luka, którą UI narzędzia CodeShack nie wypełnia, zgodnie z ich własną dokumentacją. Jeśli przetwarzasz zawartość generowaną przez użytkownika, która może zawierać emoji lub skrypty płaszczyzny dodatkowej, domyślnie wybierz String.fromCodePoint() niezależnie od tego, czy twoje dane testowe tego potrzebują.
Formuła Google Sheets / Excel:
=CHAR(72)&CHAR(101)&CHAR(108)&CHAR(108)&CHAR(111)
CHAR() akceptuje jeden kod dziesiętny na wywołanie. Dla kolumny kodów w A2:A12, użyj =CONCAT(CHAR(A2:A12)) w Arkuszach Google (który automatycznie obsługuje rozlewanie tablic) lub =TEXTJOIN("",TRUE,IF(A2:A12<>"",CHAR(A2:A12),"")) jako formuła tablicowa w Excelu. Najlepiej dla małych zestawów danych pod ~100 wartościami — poza tym, formuła staje się niewygodna i Python jest szybszy do napisania i uruchomienia.
Jedna uwaga na temat kiedy nie automatyzować: pojedyncza migracja starszych systemów jednorazowo rzadko uzasadnia napisanie skryptu. Narzędzia sieciowe z sekcji porównania są szybsze dla pracy jednorazowej. Automatyzuj, gdy (a) dane przepływają powtarzalnie, (b) zawierają wrażliwe wartości, które nie powinny opuszczać twojej maszyny, lub (c) systemy downstream potrzebują odkodowanego tekstu jako części istniejącego potoku. Ten sam kod może być zawinięty w punkt końcowy API — w taki sam sposób, w jaki usługi skierowane do developerów, takie jak Text to Speech API i Voice Cloning API ujawniają logikę przetwarzania tekstu innym aplikacjom. Po tym, jak dekodowanie staje się usługą, reszta twojego stosu przestaje dbać, czy wejście przybyło jako szesnastkowo, dziesiętnie czy już odkodowane jako UTF-8.
ASCII vs Unicode — dlaczego przepływy pracy "tylko ASCII" po cichu łamią nowoczesną zawartość
Nauczyłeś się teraz, jak dekodować ASCII. Ta sekcja wyjaśnia, kiedy to jest zły cel całkowicie.
| Własność | ASCII | Unicode (UTF-8) |
|---|---|---|
| Zdefiniowane punkty kodowe | 128 (0–127) | 149 186 przypisanych z 1 114 112 możliwych |
| Bity na znak | 7 | 8–32 (zmienna, 1–4 bajty) |
| Obsługiwane skrypty | Tylko angielska łacina | 161 skryptów |
| Obsługa emoji | Brak | Pełna |
| Użycie w sieci | <5% jako główne | >95% stron internetowych |
Źródła: Wikipedia ASCII, Unicode 15.0 Konsorcjum, sondaż kodowania znaków W3Techs.
dCode wyjaśnia jasno, że ASCII to "zabytek i zastąpiony przez Unicode." To nie historyczne machanie rękami — to praktyczne ostrzeżenie. Wielu developerów buduje potoki, które działają doskonale w testowaniu (dane ASCII tylko w języku angielskim) i łamią w produkcji pierwszy raz, gdy użytkownik przesyła akcentowane imię, emoji lub skrypt nie-łaciński. Klasyczny esej Joela Spolskiego'ego ujmuje to dokładnie: traktowanie bajtów jako będących w konkretnym kodowaniu bez weryfikacji założenia, a następnie obserwowanie, jak dane bezgłośnie się psują.
Pułapka polega na tym, że tryb awarii jest cichy. Kod obsługujący bajty zakresu ASCII z przyjemnością przetwarzał podzbiór ASCII UTF-8 bez błędu — aż do momentu, gdy natrafi na sekwencję wielobajtową, w którym punkcie albo robi awarię, albo mieszą znaki, albo (w najgorszym przypadku) pisze uszkodzone bajty z powrotem do magazynu. Zanim ktoś to zauważy, zła dana rozprzestrzeniła się przez kopie zapasowe.
Unicode został specjalnie zaprojektowany dla kompatybilności wstecznej: każdy tekst w czystym ASCII to już ważny UTF-8 bez konieczności konwersji. Według RFC 3629, podzbiór ASCII UTF-8 używa dokładnie jednego bajtu identycznego z oryginalnym bajtem ASCII. Oznacza to, że pytanie "ASCII na tekst" to prawie zawsze znak, że gdzieś w górnym potoku tekst został serializowany jako kody numeryczne — nie że masz rzeczywistą niedopasowanie kodowania. Znajdź punkt serializacji, napraw go, aby wyświetlać UTF-8 bezpośrednio, i problem dekodowania downstream znika.
Praktyczna wskazówka: przy budowaniu czegokolwiek, co obsługuje zawartość generowaną przez użytkownika, używaj UTF-8 od końca do końca. Oszczędź dekoder ASCII na inspekcję danych starszych, systemów wbudowanych, wyzwań CTF i sesji debugowania. To rzeczywiste przypadki użycia — ale to przypadki użycia inspekcji, a nie ścieżki danych produkcji.
Staje się to szczególnie ostre, gdy zawartość porusza się między językami. Napisy, scenariusze dubbingu, nagrania transkrybowane, tłumaczenia kopii — cokolwiek wielojęzyczne zawiera akcenty, znaki tonacyjne, znaki ideograficzne lub skrypty od prawej do lewej, których ASCII po prostu nie może kodować. Każdy nowoczesny potok zawartości — transkrypcja, tłumaczenie, AI Dubbing na ponad 33 językami docelowymi — wymaga świadomości Unicode z poziomu bajtowego w górę, ponieważ ASCII nie może reprezentować skryptów, które czyta większość świata. Potok, który bezgłośnie upuszcza wietnamski znak tonacyjny lub japoński kanji, to nie potok, który działa dla 95% użytkowników i łamie dla 5% — to potok, który tworzy bezgłośnie uszkodzoną zawartość dla większości języków ludzkich.
ASCII obsługuje 128 znaków. Unicode obsługuje 149 186. Jeśli twoja zawartość dotyka więcej niż jednego języka, ta luka to cała gra.
Lista kontrolna przed startem — potwierdź, że dekodowanie ASCII jest właściwą poprawką przed rozpoczęciem
Przed wklejeniem czegokolwiek do konwertera, przejdź przez tę siedmiopunktową listę kontrolną. Każda odpowiedź "nie" kieruje cię do innego rozwiązania — sekcja rozwiązywania problemów dla niedopasowań kodowania, sekcja automatyzacji dla powtarzających się przepływów pracy, sekcja ASCII-vs-Unicode dla czegokolwiek wielojęzycznego. Trzy lub więcej odpowiedzi "nie" oznacza, że dekodowanie ASCII to nie twój rzeczywisty problem.
- Moje dane składają się z tokenów numerycznych (szesnastkowo, dziesiętnie, binarnie lub ósemkowo) — nie z liter ani symboli. Jeśli widzisz rzeczywisty czytelny tekst mieszany z liczbami, masz częściowo odkodowany strumień. Wyciągnij tylko część numeryczną przed wklejeniem do generatora, lub twoje narzędzie się zadławi na znakach nie-numerycznych i odmówi przetwarzania reszty.
- Wszystkie moje wartości numeryczne mają od 0 do 127. Cokolwiek 128 lub wyższe to nie standardowe ASCII. Jeśli masz wartości do 255, jesteś na terenie Latin-1 lub Windows-1252; zamiast tego użyj dekodera świadomego strony kodowej. Jeśli wartości przekraczają 255, prawie na pewno masz surowe punkty kodowe Unicode, a nie kody ASCII — inny dekoder, inne podejście.
- Znam bazę mojego wejścia (szesnastkowo vs dziesiętnie vs binarnie vs ósemkowo). Zgadywanie marnuje czas i tworzy bezgłośnie nieprawidłowe wyniki. Szesnastkowo zawiera znaki A–F mieszane z cyframi. Binarnie to tylko 0 i 1 pogrupowane w 7- lub 8-bitowe grupy. Ósemkowo używa cyfr 0–7 tylko — żaden 8 lub 9 się nie pojawia. Dziesiętnie to wszystko inne poniżej 128.
- Moja zawartość źródłowa jest tylko w języku angielskim. ASCII nie może reprezentować francuskich akcentów, niemieckich znaków diakrytycznych, liter cyrylicy, ideografów CJK ani emoji. Jeśli twój oryginalny tekst kiedykolwiek zawierał któreś z tych, kody numeryczne, które trzymasz, to nie ASCII — to bajty UTF-8, które potrzebują dekodera UTF-8. Zmuszenie ich przez narzędzie ASCII spowoduje albo błąd, albo zamieszanie znaków. To samo ograniczenie kształtuje dowolny krok lokalizacji w dół, w tym przepływy pracy AI Dubbing API, które muszą zachować każdy znak, jaki zawiera scenariusz.
- Dane nie są wrażliwe (bez poświadczeń, danych osobowych lub zawartości podlegającej regulacjom). Konwertery sieciowe przetwarzają twoje wklejenie na serwerach stron trzecich bez wyraźnych gwarancji przechowywania danych. Wytyczne OWASP zalecają dekodowanie tylko lokalne dla każdych danych podlegających zasadom przechowywania, regulacjom prywatności lub poufności umownej. Gdy masz wątpliwości, użyj skryptu Python — twoje bajty pozostają na twojej maszynie.
- Robię to raz, lub rzadko. Powtarzające się dekodowanie należy do czteroliniowego skryptu Pythona, a nie karty przeglądarki. Automatyzacja eliminuje powierzchnię błędu kopii-wklejenia, usuwa ekspozycję prywatności strony trzeciej i uruchamia się szybciej niż czas potrzebny do otworzenia narzędzia przeglądarki. Jeśli to trzeci raz w tym tygodniu, że dekodują ten sam rodzaj danych, zatrzymaj się i scriptuj.
- Mam znaną wartość referencyjną do walidacji. Potwierdź co najmniej jeden odkodowany znak pasuje do znanego mapowania: 65 = 'A', 32 = spacja, 48 = '0', 10 = przesunięcie wiersza. Jeśli te się nie dekodują prawidłowo w teście, narzędzie, wejście lub założona baza jest źle — nie ufaj reszcie wyjścia. Pojedyncza kontrola walidacji kosztuje dziesięć sekund i zapobiega godzinie debugowania w dół.
Siedem tak oznacza, że dekodują prawdziwe ASCII i dowolne narzędzie z sekcji porównania będzie działać w mniej niż minutę. Cokolwiek innego oznacza zatrzymanie, diagnozę za pomocą listy kontrolnej rozwiązywania problemów, lub przebudowę wokół Unicode — tej samej podstawy, która sprawia, że nowoczesne narzędzia takie jak Text to Speech, Voice Cloning i generator obrazów AI pracują niezawodnie na każdym języku, który generator ASCII na tekst nigdy nie był zaprojektowany do obsługi.