
あなたは今、また耳にしたはずです——あの明るく、シャープで、合成的でありながら感情豊かなボーカルが、楽曲やVTuberの配信、ゲームのリミックスを切り裂くように響き、何かがピンときた瞬間を。あなたはその音を自分で作りたいと思っています。来月、ソフトウェアを買って40本のチュートリアルを見終えた後ではなく。今すぐに。問題は、従来の道筋がライセンス版のVocaloidやSynthesizer Vエンジンを経由するもので、それらはお金がかかり、急な学習曲線を要求し、あの象徴的なボーカルキャラクターを何時間もの手描きピッチカーブの向こうに閉じ込めてしまうことです。現代のmikuボイスジェネレーターはその構図を覆し、入力した一行や短いオーディオクリップから、数分でエクスポート可能なボーカルトラックへとあなたを導きます。

安心できる点はこちらです:より簡単な道を求めることはズルではありません。Vocaloid文化は、訓練を受けたオーディオエンジニアではなく、コミュニティのチュートリアルから一歩ずつ学ぶ愛好家たちによって成長してきました——メディア研究者のハンス・コッペンスは、この現象全体を参加型でユーザー生成のエコシステムとして捉えています。そして摩擦は下がり続けています。オープンソースのReal-Time-Voice-Cloningプロジェクトは、約5秒のクリーンなオーディオから認識可能な声をクローンできると謳っています。つまり、本当の問いは、どのツールがあなたの作りたいものに合致するか——そして、それこそがこの解説の残りの部分で解き明かすことなのです。
目次
- 「Mikuボイスジェネレーター」が実際にできること(そしてできないこと)
- 方法を選ぶ:テキスト読み上げ vs. ボイスクローン vs. カバーモデル
- ステップバイステップ — AIボイスツールでMikuスタイルのボーカルを生成する
- 短いオーディオサンプルからカスタムMikuスタイルのボイスをクローンする
- 本物らしさへの調整 — ピッチ、トーン、そして「Vocaloid」のキャラクター
- ライセンス、使用権、そしてMikuスタイルコンテンツで合法的であり続けること
- あなたのMikuボーカル制作ツールキット — すぐ実行できるアクションチェックリスト
- Mikuボイスジェネレーター — よくある質問
「Mikuボイスジェネレーター」が実際にできること(そしてできないこと)
ツールを選ぶ前に、「Mikuボイスジェネレーター」が実際に何を指すのかを明確にしておきましょう——なぜなら、この用語は3つの異なる出力を生み出す3つの異なる技術を含んでいるからです。間違った選択は何時間も無駄にします。各アプローチの違いはこうなっています。
Vocaloid / Synthesizer Vエンジン。 これらはライセンス版のソフトウェア製品で、シンボリックな入力——MIDIノートと入力された歌詞——から直接歌声を生成し、ピッチ、タイミング、表現のノートレベルの制御を可能にします。これが公式のクリプトン・フューチャー・メディアの初音ミクのボイスバンクの道筋であり、あなたがメロディを描き、エンジンがそれを歌うのです(ハンス・コッペンス)。クリプトンは初音ミクを明確に「ピアプロキャラクター」——人間のパフォーマーではなく、ソフトウェアベースのボーカルツールである歌声合成製品のラインナップの一つ——と定義しています(piapro.net)。最大限の制御、最も高いスキルの上限。
AIボイスクローンとテキスト読み上げツール。 これらは入力されたテキストや短い参照クリップからMikuスタイルの音声や話し声のボーカルを生成します。一度声がクローンされると、Real-Time-Voice-Cloningのようなシステムはテキストから自然に聞こえる話し声のフレーズを生成しますが、Vocaloidエンジンのようにノートごとの歌唱制御に最適化されてはいません(Kaggleのボイスクローン議論)。話し言葉のMikuスタイルのラインにはテキスト読み上げエンジンを、あるいは自分が所有するカスタム音色を構築するにはボイスクローンを使用してください。
カバー / ボイス変換モデル(RVC、so-vits-svc)。 これらは既存のボーカルパフォーマンスを取り込み、元のピッチとタイミングを保持しながらその音色をMikuのような声に変換します(so-vits-svcチュートリアル)。これにより、すでに歌われた素材の「Mikuスタイルのカバー」に理想的になります——あなたが自分で歌うことでメロディを提供し、モデルが声を入れ替えるのです。これらはゼロから新しいメロディを生み出すことはありません。
Mikuスタイルのボーカルへの最速の道は、必ずしも公式のボイスバンクではありません——それは、話し声、歌、あるいは変換という、あなたの出力に合うツールを選ぶことです。
正直に期待値を設定しましょう:TTSとクローンは話し声または話し声のような出力を生成し、Vocaloidエンジンは真の歌声を生成し、カバーモデルは既存のテイクを変換します。公式のライセンス版Mikuと汎用的な「Mikuスタイル」の出力との境界線は、法的にも重要です——これについてはこの解説の後半で解決します。
方法を選ぶ:テキスト読み上げ vs. ボイスクローン vs. カバーモデル
では、方法をあなたの目標に合わせましょう。以下のマトリックスは、実際にあなたの決断に影響を与える基準にわたって4つのアプローチを整理しています——何が出てくるか、何を入力する必要があるか、どれくらい難しいか、そしてライセンスの状況がどう見えるか。
| 方法 | 出力タイプ | 必要な入力 | 最適な用途 | ライセンスの注意点 |
|---|---|---|---|---|
| テキスト読み上げ | 話し声 / 話し声のような | 入力されたテキスト | VTuberのイントロ、ナレーション、話し言葉のセリフ | 汎用的な「スタイル」を使用し、プラットフォームの規約を確認 |
| ボイスクローン | カスタムの話し声の音色 | 約5〜20秒のクリーンな参照音声 | 所有可能なカスタムMikuスタイルのボイス | 自分の/ライセンスされたソースをクローン |
| カバー / ボイス変換 | 変換された歌声 | 歌ったボーカル + モデル | 自分のテイクのMikuスタイルのカバー | ソースボーカルの権利 + キャラクターIPが適用 |
| Vocaloid / Synth Vエンジン | 真の歌声 | MIDI + 歌詞 | オリジナルのMiku楽曲、完全なノート制御 | 公式ボイスバンク;ピアプロ/PCLが適用 |
最終目標に応じて読んでください。明るい合成音声で話し言葉のVTuberイントロやナレーションが必要なら、テキスト読み上げが最も摩擦の少ない道です——セリフを入力し、生成、完了。誰も持っていないユニークで所有可能な音色が欲しいなら、短い参照クリップからのボイスクローンが手です。そして、すでにデモを歌っていて、それをMikuのように聞こえるようにしたいなら、カバー / ボイス変換モデルがまさにそのために作られています:so-vits-svcとRVCはあなたのパフォーマンスのピッチとタイミングを保持し、声だけを置き換えます(so-vits-svc)。
スキルの曲線は、表を下に進むにつれて上昇します。テキスト読み上げとクローンは低い端に位置します——現代のクローンシステムは数秒のオーディオから新しい話者に適応します(Real-Time-Voice-Cloning)。カバーモデルは、まずソースボーカルを準備してクリーンにする必要があるため、中程度の範囲に位置します。VocaloidエンジンはMIDIと歌詞から歌声を生成し(ハンス・コッペンス)、これは実質的にノートレベルで作曲・編集していることを意味します——強力ですが、4つの中で最も急な登りです。
ここでオールインワンのプラットフォームが効果を発揮します。なぜなら、最初の3つの方法は一つのワークフローの中に収まるからです。テキスト読み上げエンジンは話し言葉のMikuスタイルのラインをカバーします。短い参照クリップからのボイスクローンは、DAWに触れることなく素早くカスタム音色を手に入れます。そしてSpeech Separatorは、変換を実行する前に既存のトラックからボーカルを分離するという、地味だが必要なステップを処理します——だから、あなたのMikuテキスト読み上げの実験とカバーの実験は、5つのアプリに散らばるのではなく、同じツールキットを共有するのです。
マトリックスが意図的に省略している列が一つあります:「総合的なベスト」評価です。そんなものは存在しません。正しい方法は、あなたが求めている出力タイプ次第であり、ライセンスの列は、何かを商業的に公開する前に二度読むべきものです——ピアプロライセンスの規約は、任意で読むものではありません。
ステップバイステップ — AIボイスツールでMikuスタイルのボーカルを生成する
これがあなたが求めてやってきた部分です。mikuボイスジェネレーターを使った完全な生成・エクスポートのワークフローを、空白の画面からプロジェクトに投入できるクリーンなボーカルステムまでご紹介します。5つのステップ、DAWの曲芸は不要です。

- 入力を選ぶ。 話し言葉のラインには、歌詞やスクリプトをテキストフィールドに直接入力します。クローンされたボイスには、クリーンな参照ボーカルクリップを準備します。いずれにせよ、クリーンな入力は交渉の余地がありません——ゴミを入れればゴミが出ます。大量のラインを自動処理する開発者は、手で貼り付ける代わりにテキスト読み上げAPIを通してテキストを処理できます。
- ボイスプロファイルを選択またはクローンする。 ストックライブラリから明るく高音域のボイスを選ぶか、自分のものをクローンしてカスタムキャラクターのMikuスタイルのボーカルを手に入れます。現代のシステムは約5秒のクリーンなオーディオからクローンできますが、より長いクリップ——数十秒——はより安定した音色をもたらします(Real-Time-Voice-Cloning、Kaggle)。クローンの詳細は次のセクションで説明します。
- ピッチ、スピード、トーンを調整する。 ピッチをMikuのキャラクターを定義する高く合成的な明瞭さの音域に向けて引き上げ、それから出力が温かくではなくシャープに聞こえるまでスピードとトーンを調整します。この3つのスライダーがあなたの主要な表現レバーです——その調整についてはまもなく深く掘り下げます。
- 生成してプレビューする。 ボーカルをレンダリングし、批判的に聞きます。音色がぐらついたり、フレージングがおかしく感じたら、一つの設定を変えて再実行します。ここでは反復が安価なので、最初のレンダリングは最終版ではなく下書きとして扱いましょう。
- クリーンなボーカルステムをエクスポートする。 ステムをダウンロードして、DAWや動画エディタに投入します。それを中心に完成した動画を作るなら、画像から動画を使えば、ワークフローを離れることなくボーカルと生成されたビジュアルを組み合わせられます。
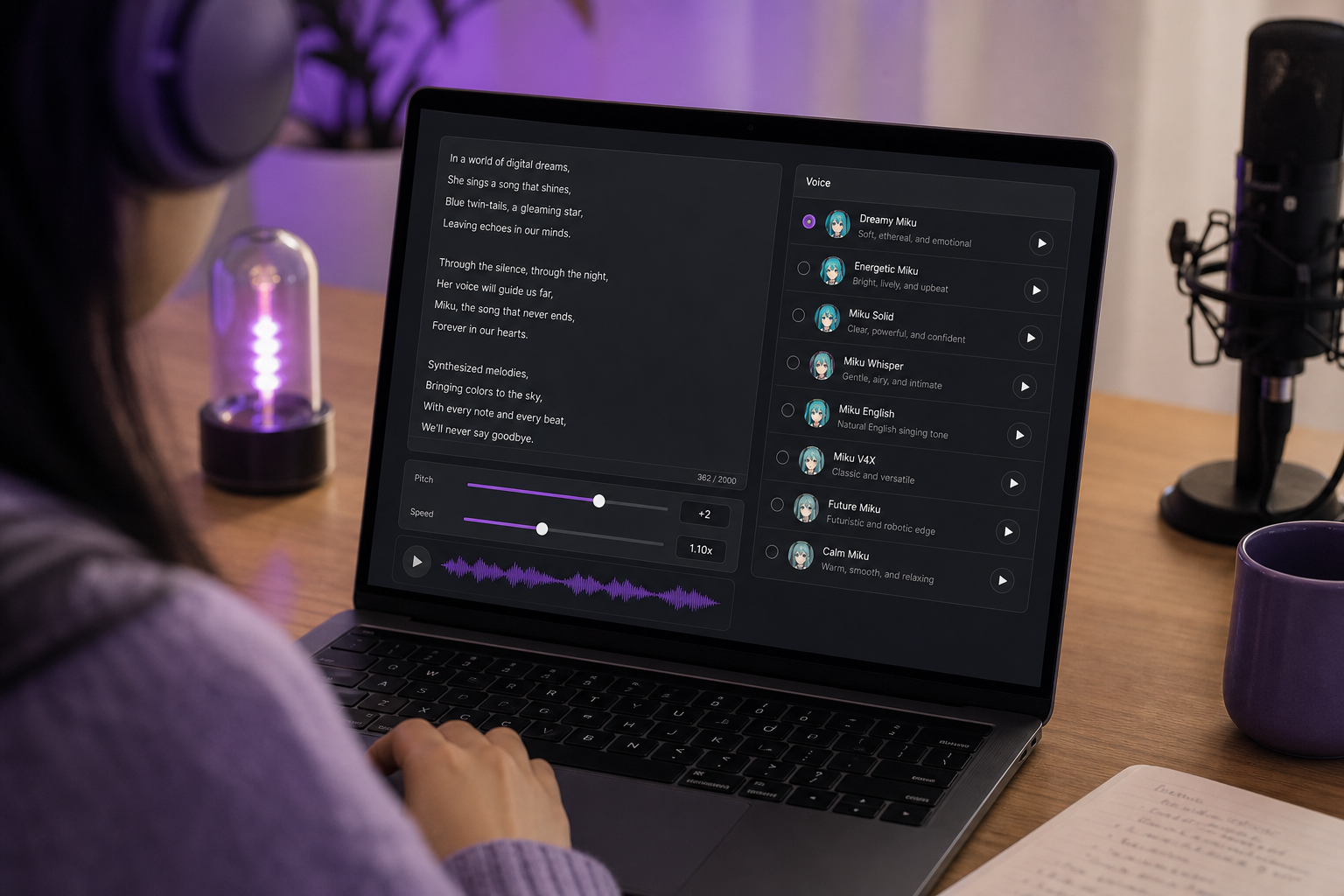
要点はアクセシビリティです。このワークフローは、ほとんどの初心者を完全に止めてしまうDAWの複雑さを取り除きます。これは、Vocaloidの愛好家が実際にどう学ぶか——正式なエンジニアリングの訓練ではなく、アクセスしやすいツールを通して一歩ずつ——を反映しています(ハンス・コッペンス)。
短いオーディオサンプルからカスタムMikuスタイルのボイスをクローンする
ストックボイスは素早く動き出させてくれますが、誰も持っていない音色——あなたのものと呼べるもの——が欲しいなら、短いサンプルからのMikuボイスクローンが手です。このチェックリストを順番に進めてください。準備のステップを飛ばすことが、ほとんどの人の結果が崩れる原因です。
- 十分なオーディオをキャプチャする。 少数ショットのクローンは約5秒から機能しますが、数十秒から数分はより安定した音色とプロソディをもたらします——そしてその安定性は歌声のような出力ではさらに重要になります(Real-Time-Voice-Cloning、Kaggle)。可能なら長めを目指してください;余分なクリーンなデータが忠実度を買ってくれます。大規模にクローンを行うエージェンシーは、これをボイスクローンAPIに組み込めます。
- まず背景音楽を取り除く。 クリーンで分離されたボイスが不可欠です。クローンモデルに入力する前に、Speech Separatorやソース分離ツールにサンプルを通して音楽とノイズを取り除いてください——成功するワークフローは、出力のアーティファクトや不安定な発音を避けるために、このステップを特に強調しています(so-vits-svc)。
- 高音域でクリアな参照を調達する。 明るく、クリアで、子音のシャープな、高い声域に位置するサンプルを録音または選んでください。あなたの参照がすでにそれらの特性に近づいているほど、AI Mikuボイスのキャラクターに到達するために後でピッチとトーンのコントロールがしなければならない仕事が少なくなります。
- 出力品質を確認して反復する。 自然さと音色の安定性を聞いてください。クローンの品質はより多くのクリーンなデータで向上します(Kaggle)。だから、声が特定の音節でぐらついたりにじんだりするなら、修正はたいていより良いサンプル——さらなるスライダー調整ではなく——です。再クローンして比較してください。
- 自分の、またはライセンスされたボイスを使う。 実際に所有しているか使用許可を得ているボイスをクローンしてください。Real-Time-Voice-Cloningプロジェクトのリーダーは、同意なしに声をクローンすることの倫理と潜在的な悪用について明確に警告しています(Real-Time-Voice-Cloning)。自分の声からオリジナルの音色を構築することは、そのカテゴリ全体のリスクを回避します——そしてライセンスへの影響については次のセクションで完全にカバーします。

本物らしさへの調整 — ピッチ、トーン、そして「Vocaloid」のキャラクター
誰でも平坦な合成音声のラインを生成できます。それを説得力のあるMikuスタイルのボーカルに変えるのは技巧であり、それはいくつかの具体的な決断の中に宿ります。実際に効果を生むのはこれです。
ピッチ音域と明るい音色。 Mikuの特徴は、明るくクリアな音色と組み合わさった高い音域です——温かさよりも明瞭さが優先されます。ピッチ設定を引き上げ、ボディを加えたい衝動に抗ってください。これもAIツールのアプローチが公式エンジンと分岐する点です:Vocaloidはノートレベルのピッチ制御を提供し、各ノートを個別に曲げて形作ることができます(ハンス・コッペンス)。AIジェネレーターでは、ノートごとの編集ではなく、グローバルなピッチとトーンの設定を通してそのキャラクターを近似します。きめ細かい制御をスピードと引き換えにするのです——ほとんどのプロジェクトにとっては公平な取引ですが、何を引き換えにしているか知っておきましょう。
アーティキュレーションと子音の明瞭さ。 あの「合成的な明瞭さ」の感覚は、主にシャープな子音とクリーンな発音から来ます。入力のフレージングをシンプルで直接的に保ち、モデルが各単語をクリーンにアーティキュレートできるようにしてください。長く、コンマの多い、扱いにくい子音クラスターを含む文は、出力を濁す傾向があります。短く断定的なラインはよりシャープにレンダリングされます——そしてここではシャープさが本物として読まれるものです。これらのラインをプログラム的に生成する開発者にとって、AI画像ジェネレーターはリリースを構築する際に、レンダリングされた各フレーズにマッチするカバーアートを組み合わせることができます。
管理すべき自然さのギャップ。 現在の上限について自分に正直になりましょう。5秒クローン研究を分析するコメンターたちは、生成された音声が、特にノイズの多い条件や感情的な内容では、本物の録音よりも明らかに自然さと表現力に欠けることを指摘しています(Redditのメディア合成議論)。arXivのVoice Cloning: Comprehensive Surveyはこれを補強し、システムはデータ効率を品質と引き換えにしており、少数ショットモデルは数秒のオーディオから適応する一方、より高忠実度の結果には数分から数時間のファインチューニングデータが必要だと指摘しています。あなたはギャップを管理するのであって、排除するのではありません:よりクリーンで長い入力を与え、感情的な要求を控えめに保ち、重い補正ではなく軽い処理を適用してください。
レイヤリングとミックスへの収まり。 むき出しのボーカルステムが完成されたように聞こえることはめったにありません。軽いリバーブ、微妙なダブリング、的を絞ったEQが、ボーカルをトラックの中で溺れさせることなく収まるのを助けます。ここでの規律は抑制です——過剰な処理は、ぎりぎり自然なボーカルをそのまま不気味の谷へと押しやります。各エフェクトを少し使うだけで大きな効果があります;積み重ねてもそうはなりません。
合成ボーカルの本物らしさは細部に宿ります——子音のスナップ、ピッチの音域、そして過剰に処理しない抑制。
あなたのコントロールに立ち返る。 スピード、ピッチ、トーンがあなたのレバーであり、このワークフローは完璧主義よりも反復を報います。生成し、聞き、一つの変数を調整し、再生成する。テキスト読み上げのようなツールはこのループを十分に速くし、単一のVocaloidフレーズを手編集するのにかかる時間で12のバリエーションをオーディションできます。一発で完璧を期待しないでください——それに収束していくことを期待してください。
調整する際に持ち続ける価値のある、より大きな枠組みがあります。Mikuは常にリミックス、カバー、再解釈の参加型エコシステムの中で繁栄してきました(ハンス・コッペンス)。あなたの調整の選択は、単一の固定された「正しい」サウンドを追いかけているのではありません——それは、すでに何千人もの人々が描いてきた創造的なキャンバスへのもう一つの寄稿なのです。キャラクターは出発点であって、ゴールラインではありません。そしてそれこそが、実験する価値があるものにしているのです。あなたが外している単一の公式Vocaloidキャラクターのターゲットなど存在しません;範囲があり、あなたは自分の選んだAIボーカルジェネレーターでその中の自分の場所を見つけることができるのです。
ライセンス、使用権、そしてMikuスタイルコンテンツで合法的であり続けること
公開を計画しているなら——そして特に収益化を計画しているなら——このセクションがあなたをトラブルから遠ざけるものです。初音ミクを取り巻くルールはほとんどのクリエイターが想定するよりも具体的なので、アップロードを押す前に注意深く読んでください。
公式キャラクター vs. 「スタイル」。 初音ミクはクリプトン・フューチャー・メディアが所有するライセンス版のピアプロキャラクターであり、ピアプロキャラクターライセンス(PCL)とキャラクター利用のガイドラインによって管理されています。これらの規約は、キャラクターの画像と名前の使用とボイスバンクの使用を区別し、二次創作、配布、表示の条件を定めています(piapro.net)。あなたが自分のクローンされた声から生成する汎用的な「Mikuスタイル」のAIボーカルは、公式ボイスバンクを使用したり、名前と肖像でライセンス版キャラクターを呼び出したりすることとはカテゴリ的に異なるものです。公式アセットから離れて位置するほど、あなたのリスクは低くなります。
商業利用とクリアランス。 公式ボイスバンクまたはキャラクターを使用する商業リリースについては、配信者は「ピアプロリンク」システムを通して許可を申請する必要がありますが、非商業利用は一般的に公開されたガイドライン内で許可されています(Tokyo Otaku ModeのOtapediaがピアプロのルールを要約したものによる)。公式のMiku楽曲を有料の文脈に合法的に出荷するためのプロフェッショナルな基準として、ピアプロリンクのクリアランスを扱ってください——それは飛ばして後で謝れるような形式的なものではありません。
包括的なクリエイティブ・コモンズの自由はない。 これは絶えず人々をつまずかせます:明示的に別途記載されていない限り、初音ミクに関連する音楽はクリエイティブ・コモンズ BY-NCの下でライセンスされていません。ピアプロは、クリエイターがそのようなトラックを標準的な著作権で保護された作品として扱う必要があり、包括的な非商業のCCの自由を想定できないことを明確にしています(ピアプロライセンスFAQ)。オンラインでMikuのトラックを見つけても、それを再利用できるという意味ではありません。
なぜ「インスパイアされた」クローンの方が安全なのか。 自分の——または適切にライセンスされた——声からオリジナルの音色を生成することは、クローン研究者が直接指摘する同意とアイデンティティの落とし穴を回避します。Real-Time-Voice-Cloningのドキュメントは、同意なしにクローンされた声の悪用について警告しており(Real-Time-Voice-Cloning)、Voice Cloning: Comprehensive Survey(arXiv)は、堅牢な同意フレームワークなしにキャラクターのような声を展開することを複雑にする、なりすまし、詐欺、非同意の偽装といったリスクを強調しています。「インスパイアされた」は、そのすべての安全な側にあなたを保ちます。
収益化する前にプラットフォームの規約を確認する。 どのAIツールを使うにしても、コンテンツに対して公開したり広告を出したりする前に、その商業利用規約を確認してください。多言語または商業配信を計画している場合——例えば、トラックのローカライズ版をリリースするなど——音声をAIダビングワークフローを通すかどうかにかかわらず、その計画を同じライセンスの注意深さと組み合わせてください。
Mikuスタイルはサウンドであり、初音ミクはライセンス版のキャラクターです——その違いを知ることが、安全な公開とテイクダウンの違いです。
あなたのMikuボーカル制作ツールキット — すぐ実行できるアクションチェックリスト
あなたは今、全体像を手にしています。これが今日実行できるチェックリストです——各ボックスを順番にチェックすれば、後戻りすることなくアイデアから公開して安全なボーカルへと進めます。
- 出力タイプを決める — 話し声、歌、または変換。この一つの選択が、後に続くすべてのツールの決定を決定します。
- 方法を選ぶ — 話し言葉のラインにはテキスト読み上げ、カスタム音色にはボイスクローン、または自分の歌ったテイクを変換するにはカバーモデル。マトリックスに合わせてください。
- クリーンな入力を準備する — TTSには歌詞を入力するか、クローンの前にSpeech Separatorで音楽を取り除いたクリーンな20秒以上の参照をキャプチャする。
- 生成し、それからピッチ、トーン、スピードを調整し、それからプレビューして反復する — 最初のレンダリングを下書きとして扱い、一度に一つの変数を変える。
- ボーカルステムをエクスポートする — DAWに投入してミックスするか、完成作品のために動画エディタでビジュアルと組み合わせる。
- ライセンスを確認する — 安全のために汎用的なスタイルか自分のクローンにこだわり、何かを収益化する前に公式ボイスバンクの使用をピアプロリンクを通してクリアする。
それがループ全体であり、そのどれもオーディオエンジニアリングの資格を必要としません。最も摩擦の少ない入り方は、無料ティアで始め、短いラインを一つ生成し、フルトラックにコミットする前に自分でそれを聞いてみることです。今日、mikuボイスジェネレーターを試してみてください。話し言葉のラインにはテキスト読み上げを、あるいは数秒ほどの短いサンプルから自分の音色を構築するにはボイスクローンを使って——最初のMikuスタイルのボーカルを数分で生成し、そこから反復してください。
Mikuボイスジェネレーター — よくある質問
MikuスタイルのAIボーカルでお金を稼ぐのは合法ですか?
何を使うかによります。公式の初音ミクのキャラクターとボイスバンクは、商業利用にピアプロリンクのクリアランスを必要とします(Otapedia)。自分のクローンされた声から作られた汎用的な「スタイル」ボーカルは、より低いリスクを伴います。いずれにせよ、クリエイティブ・コモンズの自由を想定しないでください——Mikuのトラックは包括的なCCではありません(ピアプロライセンス)。
Mikuスタイルのボーカルを歌わせることはできますか、それとも話すことしかできませんか?
TTSとクローンツールは主に話し声または話し声のような出力を生成します。真の歌声は、MIDIと歌詞からメロディを構築するVocaloidまたはSynthesizer Vエンジン(ハンス・コッペンス)、または既存の歌ったテイクを変換するカバー/変換モデル(so-vits-svc)から来ます。
Mikuボイスジェネレーターを試す最良の無料の方法は何ですか?
ストックボイスやクイッククローンを使って、無料ティアのあるプラットフォームで始めてください。まずテキスト読み上げを使って短い話し言葉のラインを一つ生成し、それからフルトラックの構築に時間を投資する前に、ピッチとトーンで反復してください。安価な下書き、それからコミット。
AI Mikuボイスジェネレーターを使うのにDAWは必要ですか?
いいえ。クリーンなステムを直接生成してエクスポートでき、そのまま使える状態になります。DAWは、後でレイヤー、EQ、またはリバーブを追加したい場合にのみ役立ちます。多くのVocaloid愛好家は、エンジニアリングの背景なしに一歩ずつ学んでいます(ハンス・コッペンス)。
これは公式のVocaloidソフトウェアとどう違うのですか?
公式のVocaloidは、ノートレベルの制御とライセンス版ボイスバンクで、MIDIと歌詞から歌声を生成します(piapro.net)。AIジェネレーターはテキストやオーディオからスタイルをクローンまたは合成します——より速く、はるかに低い学習曲線で、しかしあなたが依然として確認する必要のある、異なってより緩いライセンスへの影響を伴います。