
Hai scorso oltre quaranta campioni vocali. Cuffie indossate, tocchi anteprima, ascolti per tre secondi, tocchi il successivo, e poi quello dopo, finché ogni campione si confonde nello stesso ronzio indistinto. Questo è "caldo" o semplicemente "morbido"? Lo spiegatore dovrebbe suonare "autorevole" o "amichevole"? Il problema non è la scarsità di scelte — le librerie moderne contengono oltre 300 voci, e puoi ascoltarle per un'ora senza decidere. Il problema sono i descrittori vocali: il vocabolario preciso di cui hai bisogno per distinguere una voce da un'altra e abbinarla ai tuoi contenuti con intenzione. Senza quel vocabolario, la selezione vocale si trasforma in congetture e il doppiaggio diventa un costoso processo per tentativi ed errori. Secondo WP SEO AI, etichette di una sola parola come "naturale" o "coinvolgente" sono troppo vaghe per essere utilizzabili — un ritratto vocale chiaro richiede di specificare più dimensioni interagenti contemporaneamente. Alla fine di questo articolo, sarai in grado di descrivere qualsiasi voce con precisione attraverso tono, altezza e stile, così potrai cercare, filtrare e dare istruzioni agli strumenti vocali — o impostare un progetto di clonazione — con sicurezza invece che con fortuna.

Indice
- Le Quattro Dimensioni in cui Ricade Ogni Descrittore Vocale
- Descrittori di Tono Decodificati — Da "Caldo" ad "Autorevole"
- Altezza e Ritmo — I Descrittori Tecnici che le Persone Sbagliano
- Stile e Registro — Abbinare la Voce al Contesto del Contenuto
- Combinare i Descrittori in una Ricerca o Prompt Vocale Preciso
- Insidie dei Descrittori — Dove la Selezione Vocale si Rompe in Silenzio
- Il Tuo Modello di Briefing per Descrittori Vocali da Copia-Incolla
- Domande sui Descrittori Vocali che i Creator Fanno Davvero
Le Quattro Dimensioni in cui Ricade Ogni Descrittore Vocale
Ogni descrittore vocale che hai mai letto — per quanto poetico — si riduce a quattro dimensioni misurabili. Una volta che riesci a nominarle, il vocabolario smette di sembrare soggettivo e inizia a comportarsi come un insieme di controlli che puoi regolare in modo indipendente.
Il tono è il colore emotivo o l'atteggiamento della voce. Caldo, freddo, entusiasta, distante — è il carattere emotivo che un ascoltatore percepisce prima di elaborare il significato di una singola parola. È la dimensione che decide se il tuo pubblico si avvicina o si disconnette.
L'altezza è la percezione di quanto sia acuto o grave il suono. Un baritono profondo e risonante si trova a un'estremità; un suono brillante, leggero e giovanile all'altra. L'altezza è fondamentalmente una proprietà di frequenza, il che la rende uno dei descrittori più oggettivi dei quattro — eppure è anche uno dei più frequentemente confusi con il ritmo.
Ritmo e cadenza descrivono la velocità del parlato e la sua cadenza. Rapido, misurato, pacato, deliberato — il ritmo include le pause tra le frasi e i pattern di inflessione che vi si sovrappongono. Due voci che leggono copioni identici a ritmi diversi possono sembrare interpretazioni completamente differenti.
Stile e registro governano il contesto della performance e la formalità. Narrazione, conversazionale, broadcast, e-learning — formale contro informale. È la dimensione che decide quale ruolo sta interpretando la voce per l'ascoltatore.
Questa tassonomia non è un'opinione personale. Il Nielsen Norman Group formalizza il tono lungo quattro assi indipendenti — formale vs. informale, serio vs. divertente, rispettoso vs. irriverente, e pragmatico vs. entusiasta — dimostrando che il tono è multi-asse, non un singolo cursore che trascini da "noioso" a "divertente". Le piattaforme commerciali rendono operativa la stessa logica. Il marketplace vocale Voices.com raggruppa la descrizione vocale in quattro qualità: altezza e tono, volume e proiezione, articolazione ed enunciazione, e velocità e inflessione. Etichette diverse, stessa struttura sottostante.

Perché separare le dimensioni è così importante? Il coach di comunicazione Robin Kermode inquadra tono, altezza e ritmo come le tre leve che insieme creano la "varietà vocale" — definendo il tono come carattere emotivo, l'altezza come la frequenza percepita che può alterare il significato emotivo, e il ritmo come la velocità di erogazione. Stile e registro formano la quarta leva, e si trova sopra le altre tre, governando il contesto in cui operano. In poche parole: tono, altezza e ritmo descrivono come suona la voce; stile e registro descrivono quale ruolo sta interpretando.
Ogni descrittore vocale che hai mai letto si riduce a quattro leve — tono, altezza, ritmo e stile. Padroneggia le leve e smetterai di tirare a indovinare.
Tieni a mente questo modello. Ogni sezione che segue approfondisce esattamente una di queste quattro dimensioni, e nessuna di esse ridefinirà il framework. Quando incontri un descrittore in qualsiasi luogo — un filtro di marketplace, un campo di prompt AI, un brief di agenzia — il tuo primo compito è inserirlo in uno dei quattro contenitori. Quella singola abitudine converte un muro di aggettivi in un pannello di controllo organizzato.
Descrittori di Tono Decodificati — Da "Caldo" ad "Autorevole"
Il tono è la dimensione che il pubblico registra per prima, ed è quella più comunemente impostata male nei brief perché si appoggia ad aggettivi soggettivi. La ricerca del Nielsen Norman Group mostra che il tono opera attraverso più assi indipendenti — umorismo, formalità, rispettosità ed entusiasmo sono leve separate — il che significa che una singola parola di tono cattura raramente ciò che vuoi davvero. Raggruppa invece i tuoi descrittori di tono, e otterrai sia precisione sia un modo pratico per filtrare.
Costruzione di fiducia (caldo, amichevole, rassicurante). Questo gruppo costruisce sicurezza emotiva prima che il significato arrivi. È la scelta giusta per spiegatori sanitari, IVR di assistenza clienti e video di onboarding in cui l'ascoltatore ha bisogno di sentirsi accolto prima di assorbire le istruzioni. WP SEO AI elenca "caldo" tra gli aggettivi di tono emotivo più usati, e per una buona ragione — è il punto di partenza a cui la maggior parte del pubblico si fida per impostazione predefinita.
Energico (vivace, entusiasta, brioso). Questo gruppo segnala slancio ed eccitazione. È il migliore per lanci di prodotto, letture pubblicitarie e brevi contenuti social dove i primi due secondi decidono se qualcuno continua a guardare. L'asse "entusiasta" di NN/g si mappa direttamente qui — e nota che è indipendente dalla formalità, quindi puoi essere energico e professionale allo stesso tempo.
Serio (autorevole, professionale, solenne). Questo gruppo trasmette credibilità e peso. Ricorri ad esso nella formazione aziendale, negli spiegatori finanziari e nella narrazione documentaristica dove il pubblico ha bisogno di fidarsi che chi parla ne sappia più di loro. "Autorevole" è un descrittore di punta nell'elenco di ritratti vocali di WP SEO AI — è abbastanza specifico da filtrare e abbastanza ampio da applicarsi a tutti i formati.
Intimo (soffice, rilassante, conversazionale). Questo gruppo crea vicinanza e calma. È costruito per app di meditazione, intro di podcast e contenuti in stile ASMR dove l'ascoltatore è spesso solo e la voce sembra parlargli direttamente. L'intimità deriva tanto dalla moderazione quanto dal calore — questo gruppo si ritrae piuttosto che proiettarsi.
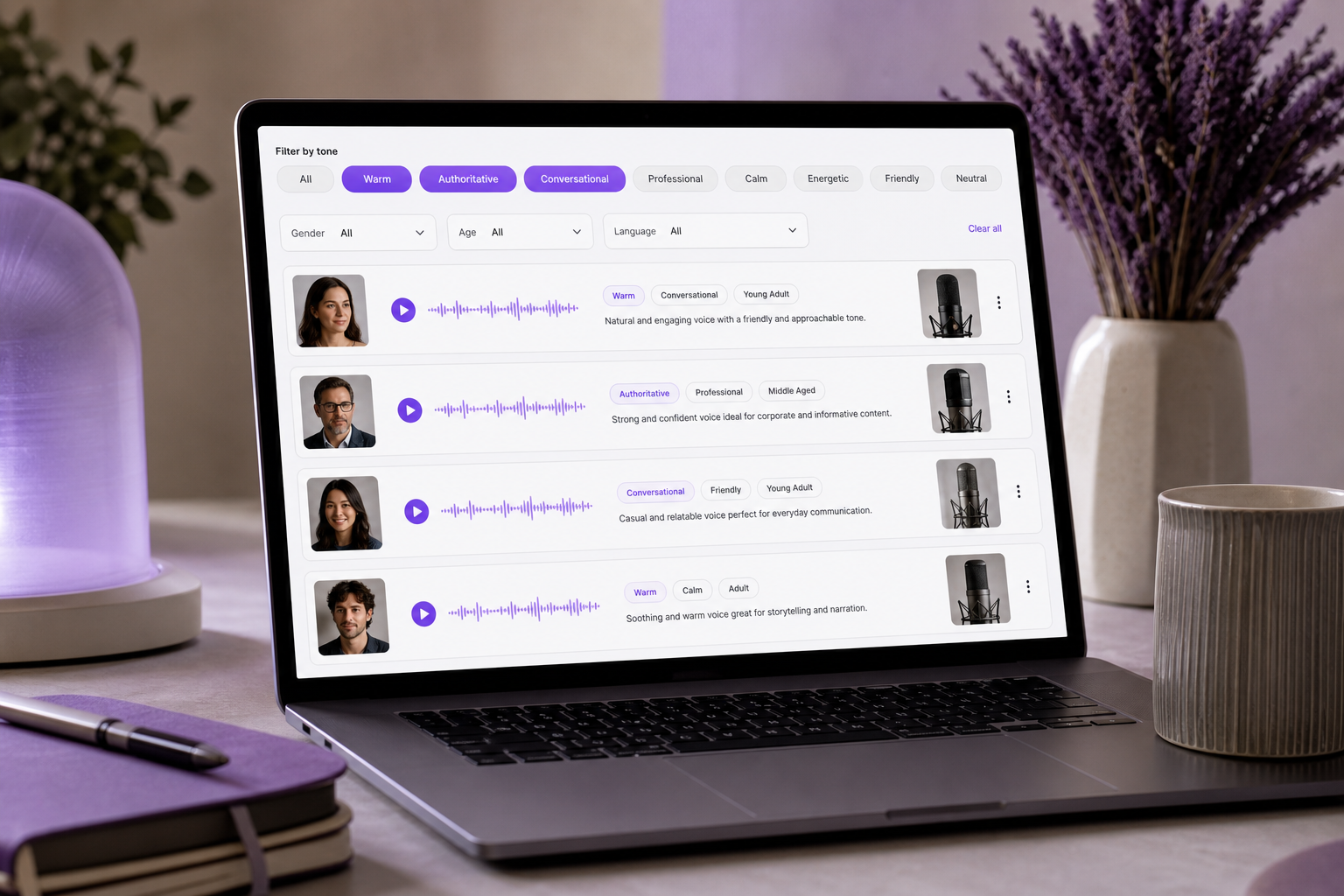
Il tono è l'unica dimensione che il pubblico nota per prima e dimentica per ultima — stabilisce la fiducia emotiva prima che il significato di una singola parola arrivi.
Questi gruppi non sono solo un modello mentale — sono il modo in cui gli strumenti moderni ti permettono di cercare. Una piattaforma TTS come SymTrain documenta il filtraggio delle voci per tono come "articolata, casuale, ansiosa", restringendo una grande libreria prima ancora di premere anteprima. È il vantaggio pratico del raggruppamento dei tuoi descrittori vocali: allo stesso modo in cui una libreria Text to Speech ti permette di filtrare per tono prima dell'anteprima, un gruppo di tono chiaro trasforma un'ora di ascolto in una shortlist mirata di tre.
Altezza e Ritmo — I Descrittori Tecnici che le Persone Sbagliano
Altezza e ritmo sono le due dimensioni più confuse in qualsiasi brief vocale, e la confusione costa ai creator tempo reale. L'altezza è frequenza — la percezione di quanto sia acuta o grave una voce. Il ritmo è velocità e cadenza — parole al minuto, cadenza e collocazione delle pause. La divisione in tre parti di Robin Kermode li mantiene distinti: il tono è carattere emotivo, l'altezza è frequenza percepita, il ritmo è velocità del parlato. Tre cose separate.
L'errore classico è scambiare il vocabolario. I creator dicono "veloce" quando intendono "acuto", o "profondo" quando intendono "lento". Questi sono controlli indipendenti. Una voce profonda può essere rapida. Una voce acuta può essere misurata. Trattarli come un unico aggettivo confuso è il modo in cui i brief vanno storti prima che qualcuno registri una sillaba.
| Descrittore | Cosa Controlla | Come Suona | Ideale Per |
|---|---|---|---|
| Profondo | Altezza (bassa frequenza) | Baritono, risonante | Documentario, brand di lusso |
| Brillante | Altezza (alta frequenza) | Leggero, ariosa, giovanile | Contenuti per bambini, pubblicità vivaci |
| Misurato | Ritmo (lento/uniforme) | Deliberato, spazioso | E-learning, tutorial |
| Rapido | Ritmo (veloce) | Energico, urgente | Notizie, promo |
| Scandito | Ritmo + articolazione | Nitido, stop precisi | Tecnico, didattico |
| Strascicato | Ritmo (lento/rilassato) | Allungato, casuale | Narrazione, personaggio |
Il lavoro interessante avviene quando altezza e ritmo si combinano, perché l'impressione composita è quasi sempre più forte di entrambi i descrittori da soli. Altezza profonda con ritmo rapido si legge come urgenza sicura — la voce di qualcuno che conosce la materia e non ti fa perdere tempo. Altezza brillante con ritmo misurato si legge come pazienza amichevole — ideale quando stai guidando un utente nervoso attraverso una prima configurazione. Scambia le combinazioni e il significato si capovolge completamente, ed è proprio per questo che non puoi unire i due campi in uno.
Questa separazione è integrata nel modo in cui le piattaforme serie strutturano le loro indicazioni. Voices.com tratta altezza/tono e velocità/inflessione come due delle sue quattro qualità distinte, mai come una singola impostazione. La documentazione dell'API Hamsa elenca allo stesso modo il ritmo del parlato e la pronuncia/chiarezza come criteri di selezione separati, ciascuno valutato a sé prima che una voce vada in produzione. La conclusione pratica è diretta: in qualsiasi brief, dai ad altezza e ritmo i loro campi specifici. Scrivi "altezza profonda, ritmo rapido", non "una voce profonda incisiva" sperando che il lettore la districhi. E ricorda che gli stessi tratti di altezza e ritmo che specifichi qui sono ciò che un modello di Clonazione Vocale preserva da un campione sorgente — quindi azzeccare il vocabolario nella fase di brief si propaga fino all'output clonato.
Stile e Registro — Abbinare la Voce al Contesto del Contenuto
L'abilità a maggiore leva nella selezione vocale non è scegliere la voce più impressionante. È scegliere lo stile e il registro giusti per il contesto di erogazione — la voce che il tuo pubblico si aspetta e non mette mai in discussione. Le indicazioni del design-system di PatternFly separano stile (scelte grammaticali e sintattiche), voce (personalità del brand) e tono (lo stato emotivo dell'utente), e il parallelo con la voce parlata si mappa in modo pulito: stile e registro da un lato, tono emotivo dall'altro. Sbaglia il registro e anche una bella voce sembra fuori posto.
La documentazione di Hamsa rende concreta la distinzione di stile con una motivazione esplicita per caso d'uso. "Conversazionale" è naturale e amichevole — ideale per servizio clienti e assistenza. "Narratore" è chiaro e articolato — adatto alle spiegazioni. Quell'inquadramento "come suona / ideale per" è esattamente ciò che trasforma lo stile in una decisione che puoi prendere in pochi secondi invece di dibattere per un pomeriggio.
| Tipo di Contenuto | Descrittore di Stile Consigliato | Perché Funziona |
|---|---|---|
| Spiegatore YouTube | Conversazionale | Naturale, amichevole — mantiene gli spettatori casuali coinvolti |
| Formazione aziendale | Narratore | Chiaro, articolato — adatto alle spiegazioni |
| Intro di podcast | Conversazionale / broadcast | Stabilisce una presenza di host calda e familiare |
| Audiolibro | Narratore | Chiarezza sostenuta per ascolti di lunga durata |
| Pubblicità / promo | Broadcast energico | Proietta slancio e una call to action |
Sotto lo stile si trova il registro — la scelta formale-contro-casuale che dà sapore a tutto ciò che vi sta sopra. L'asse formale↔casuale di NN/g è il modo più pulito per pensarci: lo stesso stile conversazionale può leggersi come un host broadcast raffinato o un amico che parla dall'altra parte di un tavolo, a seconda di dove imposti il selettore del registro. Un narratore di formazione aziendale con un registro casuale risulta accessibile; lo stesso narratore con un registro formale risulta istituzionale. Nessuno dei due è sbagliato — sono risposte a brief diversi.
Due ulteriori livelli si sovrappongono. Accento e dialetto sono criteri di selezione fondamentali nella checklist di Hamsa, e portano un peso culturale che nessun descrittore di tono può superare — una voce "US neutra" e una voce "British RP" possono condividere tono, altezza e ritmo identici e arrivare comunque in modo completamente diverso a un pubblico. SymTrain consiglia filtri per fascia d'età — giovane, adulto, anziano — accanto al tono, perché l'età percepita cambia quanto autorevole o riconoscibile risulti una voce.
Il descrittore di stile giusto non è la voce più impressionante — è quella che il tuo pubblico si aspetta di sentire in quel momento e non mette mai in discussione.
Il punto più acuto di PatternFly è che stile e tono devono rispondere allo stato emotivo del pubblico, non a un default valido per tutto il brand. Il contenuto di troubleshooting necessita di un registro neutro e disponibile; un annuncio ne necessita uno entusiasta. Il contesto detta il registro ogni volta. E le decisioni sul registro non restano fisse quando il tuo contenuto viaggia — un registro casuale e conversazionale che arriva perfettamente in inglese può risultare frivolo o poco professionale in un altro mercato. È una scelta di registro che deve reggere quando spingi il contenuto attraverso l'AI Dubbing in altre lingue, che è esattamente dove ripaga il prossimo livello di disciplina.
Combinare i Descrittori in una Ricerca o Prompt Vocale Preciso
Il vocabolario conta solo se riesci a trasformarlo in un metodo ripetibile. La ricerca è coerente sul principio fondamentale: i descrittori combinati battono ogni volta le etichette singole. WP SEO AI consiglia di combinare aggettivi di tono emotivo come "caldo", "nitido" o "autorevole" con dettagli concreti su ritmo, variazione di altezza, risonanza e chiarezza per costruire un ritratto vocale chiaro. Voices.com formalizza una pipeline in tre fasi — definire il personaggio (età, genere, stile), impostare il tono, poi scegliere le parole chiave adatte. Ecco quella logica suddivisa in sette passaggi che puoi eseguire ogni volta.
- Definisci l'obiettivo emotivo. Nomina la sensazione con cui il pubblico dovrebbe andarsene — fiducia, eccitazione, calma. Tutto ciò che segue serve questa singola decisione.
- Scegli un gruppo di tono. Scegli tra i quattro gruppi: costruzione di fiducia, energico, serio o intimo. Resisti alla tentazione di mescolare gruppi in conflitto — è lì che i brief si disfano.
- Imposta il range di altezza. Profondo, medio o brillante. Una parola, non un paragrafo.
- Imposta il ritmo. Misurato, rapido o scandito. Tienilo separato dall'altezza.
- Fissa stile e registro. Conversazionale, narratore o broadcast — poi formale o casuale.
- Sovrapponi demografia e accento. Aggiungi fascia d'età e dialetto, come si aspettano i filtri di SymTrain e Hamsa.
- Testa con 2–3 campioni. La checklist di Hamsa — pronuncia, chiarezza, ritmo, tono, accento — è la tua barriera di validazione finale prima che qualsiasi cosa venga rilasciata.

Ecco come appare la combinazione finita come singola stringa: caldo + altezza media + ritmo misurato + stile conversazionale + femminile + 30 anni + accento US neutro. Quella singola riga svolge un doppio compito. Inseriscila in una barra di ricerca e taglia il tuo tempo di filtraggio attraverso una libreria di oltre 300 voci a una manciata di candidati. Inserisci la stessa stringa combinata in un preset TTS e diventa un prompt di generazione. La disciplina di scriverla una volta è ciò che ti salva dal dover riascoltare l'intero catalogo. E poiché il formato è coerente, la stessa stringa combinata che daresti a un preset TTS può passare direttamente a una chiamata Voice Cloning API — un brief, più destinazioni, zero ritraduzione tra gli strumenti.
Insidie dei Descrittori — Dove la Selezione Vocale si Rompe in Silenzio
La maggior parte dei progetti vocali non fallisce nella fase di registrazione. Falliscono nel brief, in modi invisibili finché non stai ascoltando un file finito che è in qualche modo sbagliato. Queste sono le modalità di fallimento che non emergono finché non è costoso correggerle.
Sovraccaricare descrittori contraddittori. "Energico ma rilassante" si annulla da solo — la voce non può scattare e sussurrare allo stesso tempo. La ricerca di NN/g è utile qui: umorismo, rispetto ed entusiasmo sono leve indipendenti, quindi molte combinazioni funzionano bene, ma alcune sono genuinamente in conflitto. La soluzione è scegliere un gruppo di tono dominante e raffinare al suo interno piuttosto che attraversare i gruppi cercando una varietà di cui non hai bisogno.
Trattare "naturale" come una direzione. "Naturale" e "coinvolgente" sembrano istruzioni, ma non sono utilizzabili. WP SEO AI sostiene che tali termini generici falliscono sia per gli strumenti AI sia per i talenti da remoto perché non specificano nessuna delle dimensioni interagenti. La soluzione è sostituire ogni termine generico con la combinazione a quattro dimensioni — tono, altezza, ritmo, stile — più la demografia. Se un descrittore non si inserisce in uno di quei contenitori, non è una direzione.
Presumere che i descrittori si traducano tra le lingue. Il tono percepito cambia quando doppi in un'altra lingua e cultura — un registro che si legge come caldo in inglese può arrivare come eccessivamente familiare altrove. La soluzione è ri-validare il tono per ogni lingua di destinazione piuttosto che fidarsi che il descrittore sorgente si trasferisca. Quando stai doppiando in 33 lingue di destinazione, i controlli del tono per lingua non sono una rifinitura facoltativa; sono la differenza tra contenuti che si connettono e contenuti che alienano sottilmente. Ecco perché i team che fanno passare i contenuti attraverso un'AI Dubbing API ricontrollano il tono per ogni lingua di destinazione invece di presumere che il brief originale regga ancora.
Ignorare il contesto emotivo del pubblico. PatternFly avverte che un tono valido per tutti fallisce — un flusso di troubleshooting necessita di una voce neutra e disponibile, mentre un annuncio ne necessita una entusiasta. La soluzione è scegliere i descrittori per il momento in cui si trova il tuo pubblico, non il default valido per tutto il brand che hai impostato sei mesi fa.
Saltare il brief e fidarsi dell'intuizione. L'approccio della guida al tono di Ed Gandia critica le direttive vaghe esigendo parametri concreti — pubblico, specifiche di tono come "caldo ma non chiacchierone", formalità, lunghezza delle frasi e pattern ricorrenti. La soluzione è la più semplice di tutte: scrivi il brief combinato prima di ascoltare in anteprima una singola voce. L'intuizione va bene per scegliere tra due finalisti. È pessima per restringere 300 a 3.

"Naturale" non descrive nulla — è l'aspettativa predefinita, non una direzione creativa.
Il Tuo Modello di Briefing per Descrittori Vocali da Copia-Incolla
Ecco la versione operativa di tutto quanto sopra — una struttura da riempire che puoi incollare in qualsiasi strumento vocale, brief di agenzia o richiesta di clonazione. È il modello a quattro dimensioni più la demografia, formattato in modo che tu non debba mai ricostruirlo da zero. Trattalo come l'unica fonte di verità per i descrittori vocali di un progetto.
BRIEF DESCRITTORE VOCALE
----------------------------------------
Obiettivo emotivo: ____ (cosa dovrebbe sentire il pubblico)
Gruppo di tono: ____ (costruzione di fiducia / energico / serio / intimo)
Altezza: ____ (profondo / medio / brillante)
Ritmo: ____ (misurato / rapido / scandito)
Stile / registro: ____ (conversazionale / narratore / broadcast; formale / casuale)
Demografia: ____ (genere, fascia d'età)
Accento / lingua: ____ (dialetto + lingue di destinazione)
Voce di riferimento: ____ (facoltativo — una voce nota per ancorare le aspettative)
Questa struttura non è arbitraria. Rispecchia il conciso riepilogo vocale di 3–5 frasi di Ed Gandia abbinato a parametri specifici di tono, formalità e cadenza, e segue la pipeline personaggio → tono → parola chiave di Voices.com nell'ordine in cui prendi effettivamente le decisioni. Riempila dall'alto verso il basso e ogni campo restringe il successivo.
Ecco il modello compilato per uno scenario reale — L'Intro di un Canale YouTube Multilingue:
- Obiettivo emotivo: benvenuto sicuro
- Gruppo di tono: costruzione di fiducia / caldo
- Altezza: media
- Ritmo: rapido
- Stile / registro: broadcast conversazionale
- Demografia: femminile, 30 anni
- Accento / lingua: inglese US neutro, doppiato in spagnolo + portoghese
- Voce di riferimento: nessuna
Quel singolo brief vocale svolge tre compiti senza modifiche. Restringe la ricerca nella tua libreria a una shortlist. Diventa il prompt che guida la generazione TTS. E si porta nella fase di doppiaggio, dove gli stessi descrittori vengono ri-validati per ogni lingua di destinazione invece che ricostruiti da zero. Un brief, tre output, nessun re-briefing.
Il vantaggio pratico di questo approccio emerge quando i tuoi strumenti vivono in un unico posto. Quando Text to Speech, clonazione vocale e doppiaggio condividono un flusso di lavoro, lo stesso brief di descrittori che guida un'anteprima può passare direttamente in una richiesta Text to Speech API — e poi avanti al doppiaggio — invece di essere ridigitato e reinterpretato a ogni fase. Scrivi il brief una volta. Usalo ovunque.
Domande sui Descrittori Vocali che i Creator Fanno Davvero
Qual è la differenza tra tono e timbro nei descrittori vocali?
Il tono è il carattere emotivo di una voce — caldo, serio, distante. Il timbro è la texture o qualità unica del suono stesso — liscio, gracchiante, setoso, aspro. WP SEO AI elenca la texture come una dimensione descrittiva separata dal tono emotivo, e la distinzione conta nella pratica: due voci possono condividere esattamente lo stesso tono e avere comunque timbri completamente diversi. Quando una voce sembra giusta emotivamente ma in qualche modo sbagliata, il timbro è di solito la variabile che non hai ancora nominato.
I descrittori vocali si traducono accuratamente quando si doppia in altre lingue?
Non automaticamente. Il tono percepito può cambiare tra lingue e culture, quindi il registro caldo e casuale che funziona in inglese può arrivare in modo diverso in un altro mercato. La mossa affidabile è ri-validare il descrittore per ogni lingua di destinazione invece di presumere che si trasferisca. Con il doppiaggio in 33 lingue di destinazione disponibile, inserire un controllo del tono per lingua nel tuo flusso di lavoro non è lavoro extra — è ciò che mantiene onesto un singolo brief in ogni mercato in cui pubblichi.
Quanti descrittori dovrei usare quando do istruzioni a uno strumento di voce AI o di clonazione?
Punta alle quattro dimensioni fondamentali più la demografia — circa 5–7 descrittori combinati. WP SEO AI mostra che i descrittori combinati superano le etichette singole, e la pipeline di Voices.com conferma personaggio più tono più parole chiave come il minimo funzionante. Resta in quel range. Meno di cinque e torni ai vaghi termini generici; più di sette e inizi a rischiare contraddizioni che si annullano a vicenda.
Posso descrivere una voce facendo riferimento a una voce nota o di una celebrità invece di usare i descrittori?
Una voce di riferimento è un'ancora utile — è il motivo per cui "voce di riferimento" è un campo facoltativo nel modello di briefing. Ma non sostituisce i descrittori. Un riferimento indica a uno strumento o a un essere umano grosso modo da dove partire; tono, altezza, ritmo e stile indicano loro dove arrivare. Abbinare un riferimento a descrittori espliciti dà il risultato più affidabile, perché i descrittori risolvono l'ambiguità che il riferimento lascia aperta.