
API da Voce a Testo: Come Scegliere Quello Giusto nel 2025
Hai creato un'app che gli utenti amano — ma le richieste di funzionalità continuano ad arrivare: "Posso semplicemente parlare invece di scrivere?" Allora inizi a valutare le API da voce a testo. Nel corso della prima ora, hai già incontrato almeno quattro modelli di prezzo contraddittori, affermazioni di precisione che oscillano da "95%" a "99%+" senza una definizione condivisa di ciò che viene misurato, e qualità dell'SDK che va da tre righe a una settimana di lettura di documentazione scadente.
Le puntate sono reali su entrambi i lati. Scegli male su larga scala e avrai una perdita di $3.000–$8.000/mese su sovraccarichi di streaming, oppure distribuirai una funzione vocale che non funziona in 1 su 5 pronunciamenti. Secondo Koenecke et al. in PNAS (2020), i tassi di errore nei cinque principali sistemi commerciali di riconoscimento vocale raggiungono il 35% per gli altoparlanti dell'inglese vernacolare afroamericano rispetto al 19% per gli altoparlanti bianchi — un divario che trasforma un "problema di precisione" in un problema di "il 30% degli utenti non può usare il tuo prodotto".
Questa guida ti fornisce il framework decisionale, il metodo di calcolo dei prezzi, il protocollo pilota e un confronto testa a testa di sei provider — incluso come un modello basato su crediti si adatta ai progetti con carichi di lavoro variabili.

Indice
- I Cinque Assi Decisionali che Guidano Realmente la Scelta dell'API da Voce a Testo
- Precisione nel Contesto — Perché il "99% Benchmark" Mente Riguardo al Tuo Audio di Produzione
- Latenza, Streaming e il Moltiplicatore di Costo in Tempo Reale
- Modelli di Costo Demistificati — Per Minuto vs. Concorrente vs. Pool di Crediti
- Realtà di Integrazione — L'Audit SDK e API a 9 Domande
- Confronto Provider Testa a Testa — Quando Scegliere Ogni API da Voce a Testo
- La Tua Lista di Controllo per la Selezione dell'API da Voce a Testo
I Cinque Assi Decisionali che Guidano Realmente la Scelta dell'API da Voce a Testo
La maggior parte dei post di confronto elenca 30+ funzionalità e la chiama ricerca. Rifiuta questo. Solo sei assi determinano se un'API da voce a testo funzionerà per il tuo build specifico — e su qualsiasi progetto dato, solo due o tre di loro contano davvero.
Precisione nel tuo dominio. Un'app di trascrizione medica che utilizza un'API per scopi generici renderà "metoprolol" come "meta peral". Il Word Error Rate aggregato nasconde questo tipo di fallimento. Come sostiene Dan Jurafsky in Speech and Language Processing, il WER tratta tutti gli errori in modo uguale — ma in un contesto clinico o legale, un nome di farmaco sbagliato o una negazione mancata hanno un impatto sproporzionato. Quello che conta è il WER specifico del dominio sul tuo audio, non il titolo di un benchmark.
Profilo di latenza. Uno strumento di sottotitoli in tempo reale per l'accessibilità ha bisogno di una risposta end-to-end sotto 1 secondo. Una pipeline di trascrizione di podcast può aspettare 10 minuti. Secondo il Nielsen Norman Group's "Response Times: The 3 Important Limits", le risposte sotto 100 ms si sentono istantanee, sotto 1 secondo preservano il flusso, e oltre 10 secondi causano l'abbandono dell'attività. Mappa il tuo caso d'uso a un livello prima di iniziare a cercare.
Capacità offline / su dispositivo. Un'app di ricerca sul campo in aree rurali non può dipendere da round-trip cloud. L'API SpeechAnalyzer di Apple (WWDC 2025) è un'opzione su dispositivo a livello di piattaforma per iOS/macOS. Whisper self-hosted o Vosk ti offre il controllo completamente offline se sei disposto a gestire GPU.
Copertura linguistica e code-switching. Whisper supporta 50+ lingue con qualità comparabile dopo l'addestramento su 680.000 ore di audio multilingue (Radford et al., OpenAI 2022). Google e AWS utilizzano gruppi linguistici a livelli in cui le lingue di Tier B ottengono una precisione inferiore e talvolta prezzi separati.
Architettura del modello di costo. Pay-per-minute, connessioni concorrenti e pool di crediti si rompono diversamente su larga scala. Un YouTuber che carica 4 ore una settimana e 40 la successiva è penalizzato dalla fatturazione per minuto sia nelle settimane lente che in quelle di picco. I pool di crediti con rollover assorbono quella varianza.
Area di integrazione. Qualità dell'SDK, webhook vs. polling, impostazioni predefinite di gestione degli errori. Questo è il punto in cui l'"API facile" si trasforma in tre settimane perse.
Cinque assi guidano ogni decisione sull'API da voce a testo che vale la pena prendere — e solo due o tre di loro si applicano al tuo build.
| Asse Decisionale | Perché Conta | Trappola Comune | Caso d'Uso Più Idoneo |
|---|---|---|---|
| Precisione del dominio | Le affermazioni "99%" dei fornitori utilizzano il discorso di lettura pulita | Fiducia in LibriSpeech per audio mobile rumoroso | App mediche, legali, finanziarie |
| Profilo di latenza | Lo streaming costa 3–5x il batch | Acquistare streaming per casi tolleranti il batch | Sottotitoli in tempo reale vs. caricamento podcast |
| Capacità offline | Privacy + ambienti con connettività limitata | Presumere che Web Speech API sia offline | App di ricerca sanitaria, mobile-first |
| Copertura linguistica | Lingue Tier B = precisione inferiore | Auto-rilevamento su audio multilingue | SaaS multilingue, contenuto globale |
| Modello di costo | Il pay-per-minute sembra economico finché non inizia lo streaming | Ignorare archiviazione, egress, costi di ripetizione | Flussi di lavoro variabili dei creatori |
| Area di integrazione | Gli SDK scadenti costano settimane di sviluppo | "Semplice in docs" ≠ si spedisce facilmente | Tutti i costruttori |
Questa tabella è un filtro, non un verdetto. Un creatore YouTube che carica 10 lavori batch a settimana si preoccupa del modello di costo e della copertura linguistica. Un'app sanitaria si preoccupa della precisione e della capacità offline. Uno strumento di riunione in tempo reale si preoccupa della latenza e della superficie di integrazione.
Prima di leggere ulteriormente, sottolinea i due o tre assi che contano di più per il tuo build specifico. La sezione sui costi (migliaia di dollari di differenza) e il confronto dei provider alla fine appariranno completamente diversi a seconda di quali assi hai prioritizzato. Tentare di ottimizzare tutti e sei in un'unica decisione ti consegnerà, ogni volta, al provider più costoso con funzionalità che non userai mai.
Precisione nel Contesto — Perché il "99% Benchmark" Mente Riguardo al Tuo Audio di Produzione
Ogni fornitore di API da voce a testo pubblica numeri di precisione. Quasi nessuno di loro prevede come l'API si comporterà sul tuo audio di produzione. Ecco il perché, e come testare ciò che conta davvero.
L'audio benchmark è pulito; l'audio di produzione non lo è. I benchmark pubblici come LibriSpeech consistono in discorsi di lettura di audiolibri — un singolo altoparlante, accento neutro, registrazione pulita. Il grande modello di Whisper riporta approssimativamente 4,7% WER su LibriSpeech test-clean e approssimativamente 8–9% WER su test-other, il set più impegnativo (Radford et al., OpenAI 2022). Il divario su audio di produzione reale — rumoroso, con accento, con altoparlanti sovrapposti — è ancora più ampio. Se un fornitore cita il WER senza specificare il dataset e le condizioni di registrazione, tratta il numero come copia di marketing, non come dato di ingegneria.
Il WER è la metrica sbagliata per molte app. La definizione standard dalle linee guida di valutazione ASR del NIST è (Sostituzioni + Cancellazioni + Inserimenti) / Parole di riferimento. Tratta ogni parola come ugualmente importante. Ma il rendering errato del nome di un farmaco di un paziente, di una cifra finanziaria o del nome di un testimone in tribunale ha conseguenze che l'omissione di una parola di riempimento non ha. L'argomento di Jurafsky: valutare con metriche specifiche del compito — precisione di riempimento slot per assistenti vocali, richiamo di termini critici per uso medico e legale, precisione di entità nominate per il giornalismo. Il WER aggregato potrebbe essere del 7%; il WER su termini critici potrebbe essere del 22%. Solo uno di quei numeri conta per i tuoi utenti.
Le prestazioni di accento e dialetto variano notevolmente. Lo studio PNAS citato in cima a questa guida ha testato cinque sistemi commerciali principali e ha scoperto che il WER per gli altoparlanti dell'inglese vernacolare afroamericano è in media 0,35 vs. 0,19 per gli altoparlanti bianchi — all'incirca il doppio. Non è una nota a piè di pagina sulla correttezza. È un rischio commerciale: un'app che fallisce per un terzo della sua potenziale base di utenti perché è stata testata QA solo su inglese americano neutro è rotta. La soluzione non è scegliere un fornitore diverso (la maggior parte ha lo stesso divario). La soluzione è testare su audio che rappresenta i tuoi utenti effettivi prima di firmare qualsiasi cosa.
Un'affermazione di precisione del 99% su un benchmark non ti dice nulla su come l'API gestisce i tuoi utenti — quello che conta è la prestazione sul tuo audio, i tuoi accenti e il tuo vocabolario di dominio.
La precisione dello streaming è peggiore della precisione del batch. I sistemi di streaming emettono parole provvisorie ("parziali") che vengono riscritte mentre arriva più audio. I sistemi batch aspettano l'intera pronuncia e si affinano. Il WER dello streaming è tipicamente 5–15% peggiore che il batch per lo stesso contenuto sullo stesso motore. Questo divario non è quasi mai divulgato nel marketing del fornitore. Se stai costruendo un prodotto di trascrizione dal vivo, fattore questo.
Il code-switching rompe la maggior parte delle API. Il code-switching significa alternare lingue a metà dell'enunciato: Spanglish, Hinglish, Tagalog-Inglese. Whisper lo gestisce meglio della maggior parte perché è stato addestrato su 680.000 ore di audio multilingue (Radford et al., 2022). La maggior parte delle API cloud richiede di dichiarare in anticipo la lingua e si degrada duramente quando l'altoparlante cambia a metà frase. Se i tuoi utenti parlano più di una lingua nella stessa sessione, testa questo caso esplicitamente. Per i flussi di lavoro multilingui che hanno anche bisogno di localizzazione a valle, le piattaforme con AI Dubbing integrato in 33 lingue possono comprimere trascrizione, traduzione e doppiaggio in una sola pipeline.
Il Protocollo Pilota di 7 Giorni
Invece di fidarti delle affermazioni di precisione dei fornitori, esegui una prova di concetto di una settimana.
- Giorno 1–2: Raccogli 30 minuti di audio in stile produzione reale. Includi il tuo caso peggiore: ambienti rumorosi, altoparlanti con accento, gergo di dominio, discorso sovrapposto.
- Giorno 3–4: Trascrivi con 3 API candidate. Correggi manualmente una versione per usarla come trascrizione di riferimento.
- Giorno 5: Misura il WER complessivo, quindi suddividilo per altoparlante, accento e richiamo di termini di dominio.
- Giorno 6: Testa streaming vs. batch sugli stessi file. Misura il delta di precisione.
- Giorno 7: Documenta i costi sostenuti e l'attrito di integrazione — complessità dell'autenticazione, problemi dell'SDK, qualità della risposta agli errori.
Un ingegnere che ha scritto in ITNEXT ha riferito che dopo aver sintonizzato la configurazione del microfono e il vocabolario personalizzato, il moderno da voce a testo ha prodotto meno errori della sua stessa dattilografia per la scrittura tecnica. Il takeaway non è che una singola API è magica. È che la scelta dell'API conta, ma la pipeline audio intorno all'API conta almeno altrettanto. Un'ottima API su audio scadente perde contro un'API decente su audio sintonizzato.
Latenza, Streaming e il Moltiplicatore di Costo in Tempo Reale
La latenza è l'asse in cui gli ingegneri più spesso spendono troppo. La trascrizione in tempo reale sembra magica in una demo e costa 3–5x di più rispetto al batch in produzione. Decidi cosa i tuoi utenti realmente hanno bisogno prima di iscriversi all'infrastruttura di streaming.
- Latenza di streaming sincrono (sottotitoli dal vivo, assistenti vocali). Target under 1 secondo end-to-end per i sottotitoli di accessibilità, 300–800 ms round-trip per i chatbot vocali per sentirsi conversazionali. Sopra 2 secondi e l'illusione del tempo reale si rompe. Questi soglie mappano alla ricerca UX affermata sulla percezione del tempo di risposta (Nielsen Norman Group). Le API di streaming raggiungono questi tramite connessioni WebSocket persistenti che emettono risultati provvisori mentre l'audio arriva.
- Latenza batch asincrona (caricamenti podcast, revisione di chiamate di supporto, sottotitoli YouTube). Minuti di elaborazione fino a ore è accettabile. Il batch è approssimativamente 3–5x più economico per minuto di audio rispetto allo streaming sullo stesso fornitore, perché l'infrastruttura non mantiene aperte le connessioni (Google Cloud e AWS Transcribe pagine di prezzo). Per i flussi di lavoro dei creatori che caricano contenuto registrato, il batch è quasi sempre corretto.
- Ibrido / near-real-time (bozza dal vivo con correzione ritardata). Alcuni flussi di lavoro accettano latenza di 2–5 secondi in cambio di precisione superiore e costo inferiore. Uno strumento di trascrizione di riunioni potrebbe mostrare testo grezzo entro 3 secondi e affinarlo entro 30. Questo modello utilizza lo streaming per la visualizzazione in tempo reale e la rielaborazione batch per la trascrizione salvata — spesso tramite callback webhook piuttosto che polling. Le piattaforme costruite per scopi nel flusso di lavoro dei media, come l'API di AI Dubbing di DubSmart, utilizzano callback webhook per i lavori completati piuttosto che forzare il tuo backend a eseguire il polling dello stato (thread della comunità Make.com sull'integrazione webhook di AudioPen).
- Real-Time Factor (RTF) — la metrica dell'ingegnere. I sistemi di produzione mirano a RTF < 1,0 per l'uso interattivo: elaborare 1 secondo di audio in meno di 1 secondo di tempo reale. I deploy su dispositivo o accelerati da GPU di Whisper raggiungono approssimativamente RTF 0,5–0,9 per modelli medi su GPU consumer. Se la tua configurazione self-hosted funziona RTF > 1,0, lo streaming è impossibile senza accodamento.

Il triangolo latenza-costo-precisione è non negoziabile: puoi scegliere due. Lo streaming sacrifica la precisione e il budget per l'immediatezza. Il batch sacrifica l'immediatezza per la precisione e il costo. Le architetture ibride stanno diventando sempre più comuni ma aggiungono complessità di integrazione. Prima di scegliere, poni una domanda: i miei utenti noterebbero davvero un ritardo di 5 secondi? Se la risposta è no, il batch è l'architettura corretta e hai appena risparmiato il 70% della tua spesa annuale per API.
Modelli di Costo Demistificati — Per Minuto vs. Concorrente vs. Pool di Crediti
Ci sono tre architetture di prezzo nel mercato delle API da voce a testo, e confonderle è l'errore di approvvigionamento più comune.
Pay-per-minute (standard batch). Ti viene addebitato per minuto di audio inviato, spesso in incrementi di 15 secondi. Semplice da prevedere per carichi di lavoro prevedibili. L'API OpenAI Whisper è approssimativamente $0,006/minuto (pagina dei prezzi di OpenAI) — spesso 3–5x più economico rispetto ai tradizionali provider cloud ASR, che si raggruppano intorno a $0,02–0,03/minuto per i modelli batch inglese standard.
Connessioni concorrenti (streaming in tempo reale). Paghi per stream aperto simultaneo, spesso addebitato per connessione-minuto o per slot concorrente. Questo è il punto in cui le fatture aumentano: se 50 utenti iniziano lo streaming contemporaneamente, stai pagando per 50 connessioni — non 50 minuti di audio. Google Cloud e AWS pubblicano tariffe distinte e più elevate per le sessioni di streaming rispetto ai lavori batch offline.
Pool di crediti con rollover (carichi di lavoro flessibili). Compri un pool di crediti che vengono consumati a tassi variabili a seconda di quali funzionalità usi (trascrizione, doppiaggio, clonazione vocale, sintesi vocale). I crediti inutilizzati si rinnovano. Questo modello si adatta ai carichi di lavoro variabili — uno YouTuber che carica 4 ore una settimana e 40 la successiva non è penalizzato dal picco o bloccato da minuti inutilizzati. DubSmart AI utilizza questo modello, raggruppando trascrizione con Clonazione Vocale e Sintesi Vocale sotto un unico saldo di crediti.
Esempio elaborato — Creatore YouTube:
- 10 video/settimana × 30 min ciascuno = 300 min/settimana di audio sorgente
- Trascrizione batch a $0,006/min = $1,80/settimana, o circa $94/anno
- Aggiungi una demo live con didascalie in streaming (5 ore/mese) a 4x il tasso batch = approssimativamente $72/anno aggiuntivi
- Se il creatore doppia in 3 lingue, il fabbisogno totale di crediti di trascrizione + doppio mensile è di circa 5.000 crediti — rientra in un piano di pool di crediti di fascia media
A qualsiasi volume inferiore a 5.000 ore al mese, costruire il tuo stack di trascrizione è più economico in fantasia che in realtà — un livello API di $50 si spedisce in un giorno, mentre un deploy Whisper self-hosted si spedisce in un trimestre.
| Fornitore | Modello di Prezzo | Tariffa Pubblicata | Livello Gratuito |
|---|---|---|---|
| Google Cloud STT | Per incremento di 15 sec; surcharge di streaming | Variabile; a livelli | 60 min/mese |
| AWS Transcribe | SKU batch per secondo + streaming | Variabile per regione/modello | 60 min/mese, 12 mesi |
| OpenAI Whisper API | Flat per minuto | ~$0,006/min | Nessuno pubblicato |
| Rev.com (Machine) | Per minuto | $0,25/min | Nessuno |
| Rev.com (Human) | Per minuto | $1,50/min | Nessuno |
| DubSmart AI | Pool di crediti con rollover | Piani a livelli | Livello gratuito disponibile |
Fonti: Pagine dei prezzi dei fornitori OpenAI, Google Cloud, AWS Transcribe, Rev.com.

Tre costi nascosti quasi mai compaiono nei calcolatori dei fornitori.
Archiviazione e egress. Se archivi trascrizioni e audio sorgente in S3 o GCS, paghi archiviazione più larghezza di banda al recupero. Su larga scala questi diventano voci di riga non banali. Un archivio di 1 TB a tariffe standard con riletture frequenti può aggiungere centinaia di dollari al mese prima di qualsiasi chiamata API.
La diarizzazione dell'altoparlante è solitamente misurata separatamente. AWS Transcribe e AssemblyAI entrambi addebitano l'identificazione dell'altoparlante come voce separata in aggiunta alla trascrizione base (documentazione AWS Transcribe; docs AssemblyAI). Budgetare solo sulla tariffa base per minuto sottostima il tuo costo reale di approssimativamente 20–40% se hai bisogno di etichette dell'altoparlante.
Costi di ripetizione e errore. Le richieste non riuscite consumano ancora quota su alcuni fornitori. Se la tua pipeline audio ha un tasso di errore del 2% a 100.000 minuti/mese, sono 2.000 minuti di tentativi pagati — approssimativamente $12/mese a tariffe Whisper, ma facilmente $60/mese su STT cloud tradizionali.
Break-even costruire vs. acquistare. L'esperienza di ingegneria dai team in Mozilla (DeepSpeech), Descript e AssemblyAI suggerisce che l'ASR self-hosting con Whisper o Kaldi ha senso solo a >5.000 ore/mese con DevOps e ML dedicati. Al di sotto di quel volume, l'infrastruttura, la manutenzione del modello, i costi GPU e il sovraccarico on-call superano il conto $50–$500/mese della API — spesso di un fattore cinque o più.
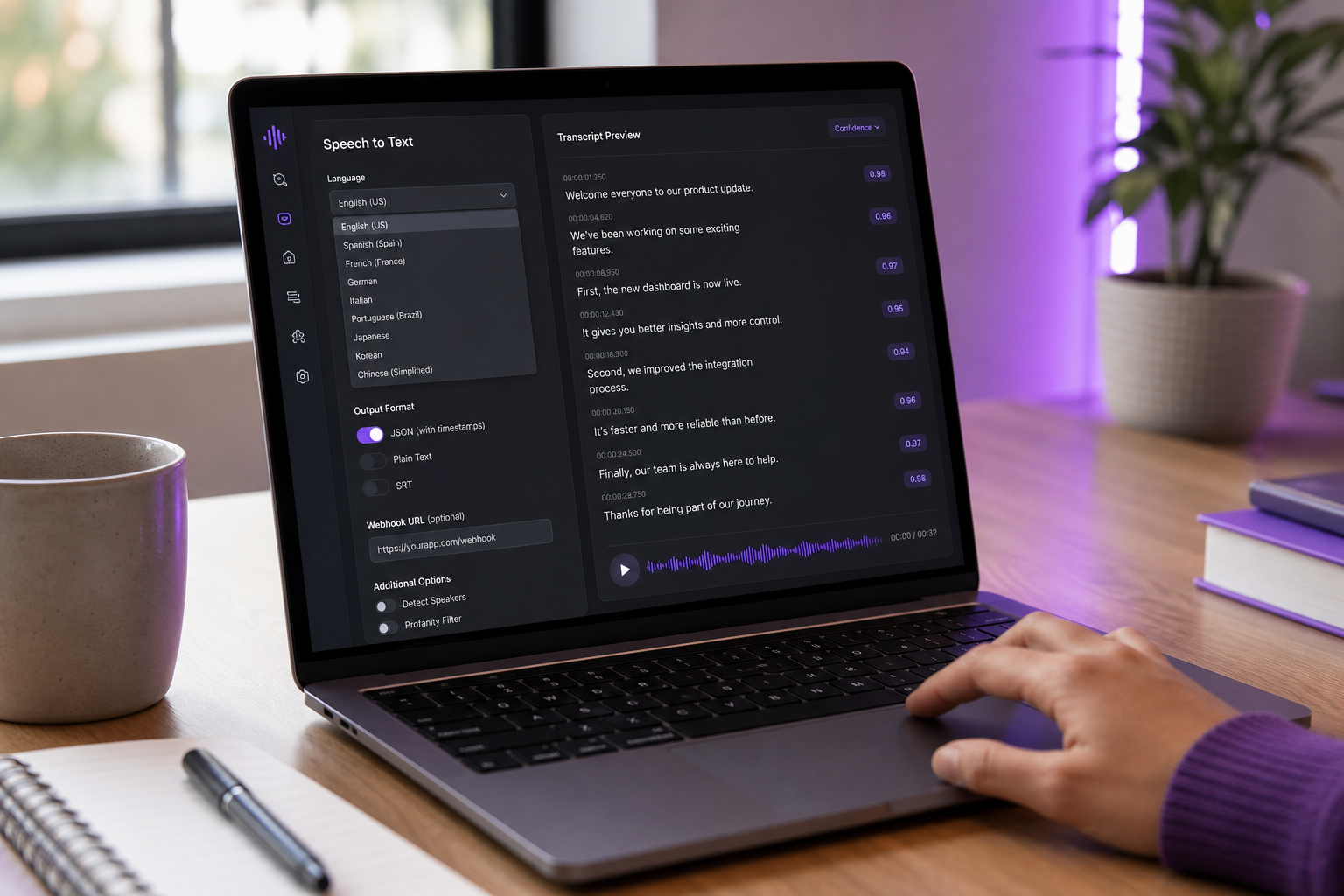
Realtà di Integrazione — L'Audit SDK e API a 9 Domande
"Facile da integrare" è la frase più sovraccarica nell'economia delle API. Un'API può essere facile da chiamare in una richiesta curl e infernale da spedire in produzione. Prima di firmare un contratto, esegui ogni candidato attraverso queste nove domande. Le risposte scadenti qui prevedono le settimane di gestione degli errori personalizzata e logica di ripetizione che scriverai in seguito.
- L'API supporta sia streaming che batch in un SDK? Alcuni fornitori ti forzano a scegliere l'architettura in anticipo, quindi addebitano il cambio. Le migliori API espongono entrambi tramite lo stesso strato di autenticazione e ti permettono di migrare i carichi di lavoro mentre il comportamento dell'utente evolve. Se il tuo caso d'uso iniziale è batch ma potresti aggiungere sottotitoli dal vivo tra sei mesi, questo conta ora.
- Cosa succede quando l'API è inattiva o ha limiti di velocità? Testalo. Invia 200 richieste in 1 secondo a un livello gratuito. L'SDK le mette in coda, visualizza un 429 in modo pulito, o si blocca? I fornitori che pubblicano SLA e semantica di ripetizione in linguaggio semplice ti risparmiano settimane di risposta agli incidenti. I fornitori che non lo fanno alla fine ti sveglieranno alle 3 del mattino.
- Puoi specificare esplicitamente la lingua dell'audio, o si auto-rileva? L'auto-rilevamento suona amichevole ma si rompe su audio multilingue o code-switched. Per i build di produzione, specifica sempre la lingua e ricadi sull'auto-rilevamento solo quando la confidenza è bassa. Le API che non ti permettono di impostare esplicitamente la lingua sono pre-ingegnerizzate per fallire sui tuoi casi limite.
- Supporta la diarizzazione dell'altoparlante fuori dalla scatola? La diarizzazione è spesso un componente aggiuntivo a prezzo separato. AssemblyAI e AWS Transcribe entrambi la misurano separatamente. Controlla se il tuo fornitore restituisce etichette dell'altoparlante a livello di segmento o di parola — la differenza conta per l'analitiche, la ricerca e qualsiasi riepilogo a valle.
- Può contrassegnare o redarre PII (numeri di carta di credito, SSN, nomi)? La maggior parte delle API focalizzate sull'azienda (AWS Transcribe, AssemblyAI) supportano la redazione di PII. Whisper e Web Speech API no. Per app sanitarie o finanziarie, questo non è un bel avere.
- Callback webhook o polling per lavori asincroni? I webhook sono lo standard moderno. Il polling genera chiamate API non necessarie e costi. Le piattaforme mature emettono eventi webhook al completamento del lavoro — il modello mostrato nel thread della comunità Make.com sull'integrazione di AudioPen dove il completamento della trascrizione attiva l'automazione a valle.
- Quali sono i limiti di dimensione del file e durata massima per richiesta? Molte API cloud limitano le richieste individuali a 15 minuti o approssimativamente 1 ora con limiti di dimensione del file in decine o centinaia di MB (documentazione Google Cloud Speech-to-Text; documentazione AWS Transcribe). L'audio di lunga forma — podcast di due ore, deposizioni, registrazioni di conferenze — deve essere suddiviso. I gateway HTTP spesso applicano timeout di 15 minuti indipendentemente dai propri limiti dell'API.
- I punteggi di confidenza sono esposti a livello di parola? La confidenza a livello di parola ti permette di contrassegnare regioni a bassa confidenza per la revisione umana o la correzione interattiva. Le API che restituiscono testo grezzo senza confidenza ti forzano a fidarti di tutto o a ritrascrivere. Per qualsiasi flusso di lavoro con revisione umana nel ciclo, questa funzionalità è la differenza tra una coda QA utilizzabile e un muro di testo illeggibile.
- Qual è la qualità dell'SDK nella tua lingua? Un SDK Node.js o Python con tipizzazione forte, logica di ripetizione e classi di errore pulite vale un premio di prezzo del 30% rispetto a un'API che devi HTTP grezzo in produzione. Testa l'SDK prima di impegnarti nell'API. Scrivi una piccola integrazione. Misuralo. L'SDK che ti piace effettivamente usare ti farà risparmiare più ore di ingegneria di quante il tasso per minuto più economico non ti salvi mai in dollari.
Open-source vs. proprietario rimane il più grande fork di integrazione.
Open-source (Whisper, Vosk). Costo zero per chiamata, controllo totale, funziona offline. Possiedi hosting, scaling, provisioning GPU, aggiornamenti del modello, osservabilità e l'incidente alle 3 del mattino. Deployment realistico per un team di 5+ con capacità ML e DevOps.
Cloud proprietario (Google, AWS, AssemblyAI, OpenAI Whisper API, DubSmart). Scambi il costo per minuto per affidabilità, SLA, versioning e supporto SDK. Per la maggior parte dei team al di sotto di 5.000 ore/mese, il proprietario vince sul costo totale di proprietà. Le piattaforme che raggruppano da voce a testo con l'API di Sintesi Vocale e l'API di Clonazione Vocale sotto un SDK riduce ulteriormente l'area di integrazione — un flusso di autenticazione, un modello di errore, un dashboard di fatturazione per l'intera pipeline media.
A livello di piattaforma su dispositivo (Apple SpeechAnalyzer, WWDC 2025). Una categoria più nuova. Preservante della privacy, offline-capace, ma la precisione e la copertura linguistica potrebbero rimanere indietro rispetto ai modelli cloud. Migliore per app mobile-first dove la privacy è un asset di marketing, non solo una casella di spunta di conformità.
La domanda di integrazione che batte tutte le altre: quanto velocemente puoi spedire? Un'API basata su crediti ben documentata che raggruppa da voce a testo, clonazione vocale e doppiaggio sotto un SDK spesso batte un'API STT autonoma più economica una volta che consideri il secondo e il terzo feature che avrai bisogno entro sei mesi.
Confronto Provider Testa a Testa — Quando Scegliere Ogni API da Voce a Testo
Questo è un'analisi rapida di riferimento, non una revisione esaustiva. Ogni voce copre il caso d'uso più idoneo, la debolezza primaria, il driver di costo dominante e il carattere di integrazione. Le fonti per le affermazioni di prezzo e funzionalità sono la documentazione del fornitore da fine 2024.
Google Cloud Speech-to-Text
- Migliore per: Trascrizione inglese ad alta precisione, team già in GCP, carichi di lavoro aziendali con volume prevedibile.
- Debolezza: Il prezzo dello streaming accelera velocemente; i livelli linguistici creano incoerenza di precisione per audio non inglese.
- Driver di costo: Per incrementi di 15 secondi con SKU di streaming separato (più elevato); livello gratuito di 60 min/mese.
- Integrazione: Autenticazione GCP nativa tramite account di servizio. Le app non GCP affrontano il sovraccarico IAM. SDK maturo per tutte le principali lingue.
AWS Transcribe
- Migliore per: Carichi di lavoro batch-heavy su larga scala, team nativi AWS, pipeline di contenuto multilingue, analitiche di call center.
- Debolezza: La latenza dello streaming è leggermente più alta rispetto ai concorrenti specializzati in streaming. Diarizzazione e modelli medici a prezzo separato.
- Driver di costo: Durata audio in secondi, con SKU separati per streaming, medico e componenti aggiuntivi di analisi delle chiamate.
- Integrazione: Pesante IAM. Diretto se sei già nativo AWS. Documentato bene ma prolisso.
OpenAI Whisper API
- Migliore per: Build consapevoli del budget, contenuto multilingue con code-switching, team che desiderano nessun vendor lock-in al di là di OpenAI stesso.
- Debolezza: Nessun supporto di streaming nativo. Nessuno sconto di volume. Nessun impegno SLA paragonabile a AWS o GCP.
- Driver di costo: Flat $0,006/minuto senza carica per connessione concorrente e nessuno sconto di azienda a livelli pubblicato.
- Integrazione: L'API HTTP più semplice sul mercato. Multilingue senza dichiarazione di lingua grazie ai 680.000 ore di dati di addestramento documentati nel documento Whisper.
AssemblyAI
- Migliore per: Team incentrati sugli sviluppatori, streaming in tempo reale con latenza minima, output strutturato con timestamp a livello di parola, etichette dell'altoparlante e punteggi di confidenza.
- Debolezza: Prezzo premium. La densità delle funzionalità è eccessiva per casi di utilizzo batch semplici.
- Driver di costo: Connessioni di streaming concorrenti più voci di linea di diarizzazione.
- Integrazione: SDK eccellenti e documentazione. Architettura incentrata su webhook. Strumenti di osservabilità forti.
Rev.com (Machine + Ibrido Umano)
- Migliore per: Flussi di lavoro in cui la precisione è non negoziabile e il turnaround può aspettare ore — deposizioni legali, giornalismo, contenuto critico per l'accessibilità.
- Debolezza: Non in tempo reale. La revisione umana richiede ore. Costoso su larga scala.
- Driver di costo: $0,25/minuto per machine, $1,50/minuto per revisione umana.
- Integrazione: API REST semplice. L'attrito è il tempo di turnaround, non l'integrazione stessa.
DubSmart AI Speech to Text API
- Migliore per: Creatori di contenuti e team che costruiscono flussi di lavoro multilingui in cui la trascrizione è un passo in una pipeline più lunga — trascrivi, traduci, doppia, pubblica. I prezzi basati su crediti assorbono carichi di lavoro variabili.
- Debolezza: Piattaforma più giovane rispetto agli iperscalatori legacy. I termini SLA aziendali potrebbero non corrispondere ad AWS o GCP per i team di approvvigionamento consapevoli del rischio.
- Driver di costo: Pool di crediti con rollover. Raggruppa trascrizione con clonazione vocale da un campione di 20 secondi, 300+ voci TTS e AI Dubbing in 60+ lingue sorgente verso 33 lingue target.
- Integrazione: Costruita per scopi nel flusso di lavoro dei media. Un SDK copre trascrizione + TTS + clonazione + doppiaggio. Callback webhook per lavori asincroni. Trusted da 500.000+ utenti.
La Tua Lista di Controllo per la Selezione dell'API da Voce a Testo
Questo è il flusso di lavoro da eseguire prima di firmare qualsiasi contratto. Comprime tutto quanto sopra in otto passaggi eseguibili. Blocca quattro ore per il primo passaggio; aspettati una settimana di test pilota al passaggio 4.
- Definisci il tuo caso d'uso dominante in una frase. Scrivilo: "Devo trascrivere podcast" o "sottotitolare stream dal vivo" o "analizzare chiamate di vendita" o "doppiare video caricati dall'utente". Se non riesci a scriverlo in una frase, hai due prodotti e hai bisogno di due valutazioni. Abbina il caso d'uso al livello di latenza dalla Sezione 3 e alla domanda di precisione dalla Sezione 2 prima di guardare qualsiasi prezzo del fornitore.
- Sottolinea i due o tre assi decisionali che contano di più. Dal framework: precisione, latenza, offline, copertura linguistica, modello di costo, area di integrazione. Se tenti di ottimizzare tutti e sei, sceglierai il provider più costoso con funzionalità che non userai mai. La maggior parte dei costruttori dovrebbe classificare il modello di costo e l'area di integrazione per prima. La precisione e la latenza diventano tiebreaker tra i finalisti.
- Progetta il volume di 12 mesi con un buffer di aumento di 3x. Stima minuti mensili per il mese 1, mese 6 e mese 12. Moltiplica il numero del mese 12 per 3 per gestire i picchi di lancio e la crescita virale. Questo numero determina se hai bisogno di un pool di crediti, prezzi per minuto o un contratto di volume aziendale con sconto — ed è il numero che citerai ai fornitori durante la negoziazione.
- Esegui il pilota di 7 giorni. Trenta minuti del tuo audio reale, tre API candidate, punteggio manuale rispetto a una singola trascrizione di riferimento corretta da un umano. Misura il WER per altoparlante, per accento e per termine di dominio — non solo aggregato. Testa streaming vs. batch sugli stessi file. Documenta l'attrito dell'SDK in un doc condiviso mentre procedi, mentre il dolore è fresco.
- Stress-test la gestione degli errori. Invia audio malformato, token scaduti, raffiche che sfidano il limite di velocità e file sovradimensionati. L'SDK fallisce in modo pulito con errori fruibili, o si blocca? Un'API che fallisce male sotto stress controllato fallirà male in produzione alle 3 del mattino, e il costo della pulizia oscurerà il risparmio per minuto che hai bloccato alla firma.
- Calcola il vero costo totale di proprietà. Includi costo base per minuto, sovraccarichi di streaming, voci di linea di diarizzazione, archiviazione, egress, sovraccarico di ripetizione e ore di ingegneria salvate o perse per qualità dell'SDK. Confronta con un modello di pool di crediti se il tuo carico di lavoro è variabile — un piano di crediti di approssimativamente $99/mese spesso batte i prezzi di $0,006/minuto quando il traffico è irregolare e raggruppa più funzionalità media sotto un conto.
- Controlla gli impostazioni predefinite di privacy e conservazione dei dati. Conferma se il fornitore conserva audio e trascrizioni per il miglioramento del modello, e se puoi non acconsentire contrattualmente. I requisiti GDPR, HIPAA e SOC 2 possono eliminare i fornitori indipendentemente dal prezzo. Secondo la guida del Consiglio Europeo della Protezione dei Dati sui assistenti vocali, i fornitori di STT cloud possono creare "dataset ombra" di dati vocali a meno che non esplicitamente limitati nel contratto — questa è una domanda di approvvigionamento, non una domanda di funzionalità.
- Negozia prima di impegnarti. La maggior parte dei fornitori offre sconti del 15–30% su impegni di 12 mesi sopra 500 ore/mese. Se hai completato i passaggi 1–7 con sicurezza, hai leva. Chiedi prezzi bloccati, un contatto di supporto dedicato, livello gratuito espanso per ambienti di staging e una clausola di uscita se la precisione si degrada sotto una soglia concordata. Se la tua roadmap include localizzazione, valuta le API come l'API di AI Dubbing che traducono e doppiato in una sola chiamata.
Questa lista di controllo è la tua difesa contro il marketing dei fornitori e la tua offensiva contro i ritardi di spedizione. I team che spediscono funzionalità vocali più velocemente non sono quelli che hanno scelto l'API più economica — sono quelli che hanno eseguito un pilota reale, calcolato il vero TCO e scelto una superficie di integrazione che i loro sviluppatori volevano usare. Se il tuo build coinvolge anche doppiaggio, clonazione vocale o generazione di discorso sintetico, valuta le piattaforme che raggruppano Sintesi Vocale, clonazione vocale e doppiaggio sotto un unico saldo di crediti e un SDK — il secondo e il terzo feature che avrai bisogno entro sei mesi costeranno meno e si spediranno più velocemente.