
Apa yang Benar-benar Didengar Pendengar Ketika Imitasi Suara Berhasil
Take 17. Imitasi Morgan Freeman sudah dekat — cadence-nya ada, logat Mississippi-nya hampir meyakinkan — tetapi gravitasi-nya hilang. Pendengar Anda mengatakan "hampir," yang dalam pekerjaan suara adalah kata yang sama dengan "tidak." Anda menghapus take. Anda mencoba lagi. Empat puluh menit kemudian Anda tidak memiliki apa pun yang dapat digunakan untuk voiceover YouTube dan tenggorokan Anda mulai lelah.
Ini adalah jebakan yang menelan kreator yang mencoba membangun saluran multibahasa: menguasai suara karakter dalam bahasa Inggris, lalu melihatnya runtuh saat dub Spanyol atau Hindi masuk ke rencana produksi — karena imitasi itu adalah menghafal fonetik, bukan tanda tangan vokal yang terinternalisasi. Jam studio menumpuk. Take ditolak. Rencana lokalisasi diam-diam ditunda. Konten yang seharusnya diluncurkan tidak diluncurkan.
Panduan ini menguraikan apa yang membuat imitasi suara benar-benar terdengar di telinga pendengar, empat latihan yang membangun keahlian dasar, dan di mana kloning suara AI masuk ke alur kerja sebagai alat penskalaan — bukan pengganti keterampilan yang mendasari.

Daftar Isi
- Apa yang Benar-benar Didengar Pendengar Ketika Imitasi Suara Berhasil
- Lima Blok Bangunan Vokal yang Setiap Imitasi Andalkan
- Empat Latihan yang Membangun Memori Otot Imitasi Suara
- Di Mana Praktik Imitasi Suara Manual Mencapai Batas Keras
- Bagaimana Kloning Suara AI Memperkuat Jangkauan Imitator Berbakat
- Bangun Toolkit Imitasi Suara Anda — Cocokkan Hambatan Anda dengan Jalur yang Tepat
- FAQ
Pendengar tidak mengidentifikasi suara hanya dengan pitch. Mereka mengidentifikasinya dengan sidik jari spektral — struktur formant, pola vibrasi, dan tanda tangan waktu yang dihasilkan oleh anatomi saluran vokal tertentu. Menurut ilmuwan suara Ingo R. Titze dalam Principles of Voice Production, kualitas suara dibentuk terutama oleh konfigurasi dan resonansi saluran vokal, bukan frekuensi fundamental. Dua orang dapat bersenandung nada yang persis sama dan tetap terdengar tidak sama sekali, karena tenggorokan, mulut, dan sinus mereka bertindak sebagai filter berbeda pada getaran yang sama.
Itulah unlock untuk imitasi suara. Pekerjaannya bukan mencocokkan satu variabel. Ini adalah mereproduksi tanda tangan lima lapis:
- Kontur pitch — bukan hanya pitch rata-rata, tetapi tempat pitch naik dan turun dalam kalimat
- Penempatan resonansi — dada, topeng, hidung, kepala
- Pola napas dan kecepatan — di mana pembicara menghirup dan berapa lama jeda mereka
- Tanda tangan artikulasi — serangan konsonan dan bentuk vokal
- Subteks emosional — perasaan yang mendorong setiap kata, lapisan yang dilompati amatir
Tabel diagnostik lengkap ada di bagian berikutnya. Untuk sekarang, pertahankan kerangka: tanda tangan, bukan permukaan.
Terdengar Seperti Versus Berkinerja Sebagai
Ada perbedaan yang dunia voice acting profesional anggap sebagai hal yang tidak dapat dinegosiasikan: terdengar seperti seseorang dan berkinerja sebagai mereka adalah keterampilan yang berbeda. Dee Bradley Baker — aktor karakter suara di balik banyak Star Wars: The Clone Wars dan Avatar: The Last Airbender — telah membangun seluruh praktik pengajarannya di sekitar argumen bahwa suara karakter hanya berfungsi ketika pemain memahami kehidupan emosional, niat, dan fisikitas karakter. Bukan hanya aksen. Bukan hanya nada. Menurut bahan pendidikannya dalam I Want to Be a Voice Actor!, imitasi yang menargetkan suara tanpa niat menghasilkan sesuatu yang didengar pendengar sebagai mekanis, bahkan ketika mereka tidak dapat mengartikulasikan mengapa.
Dua Dekonstruksi yang Membuat Teori Konkret
Pertimbangkan imitasi Darth Vader amatir. Mereka terdengar tipis karena menargetkan dua variabel yang salah: pitch (rendah) dan efek napas (exhale berat). Apa yang mereka lewatkan adalah resonansi dada di mana suara James Earl Jones benar-benar hidup. Efek napas adalah lapisan yang dilukis di atas fundamental yang berakar di dada — bukan penggantinya. Tanpa jangkar resonan itu, imitasi terdengar seperti seseorang membisik dengan usaha daripada berbicara dari dalam katedral.
Suara yang lebih lembut membalik prioritas. Dengan David Attenborough, pacing membawa kira-kira 70% dari beban. Tarikan napas lambat sebelum kata sifat kunci. Kenaikan pada kata-kata keajaiban. Akhir frasa menurun. Menyalin aksen received-pronunciation tanpa ritme menghasilkan parafrase dokumenter — bukan Attenborough.
Mengapa Ini Penting untuk Kloning AI
Rincian persepsi yang sama yang membangun imitasi manusia yang lebih baik juga menghasilkan klon suara AI yang lebih baik. Model belajar tanda tangan, bukan permukaan. Jadi kreator yang telah menginternalisasi penempatan resonansi dan pacing bukan hanya lebih baik dalam berkinerja sebagai karakter — mereka merekam data pelatihan yang lebih baik ketika mereka duduk untuk mengkloning suara karakter itu. Keterampilan ditransfer. Bagian lebih dalam dari artikel mencakup bagaimana.
Lima Blok Bangunan Vokal yang Setiap Imitasi Andalkan
Bagian sebelumnya menyebutkan lapisan. Bagian ini mengubahnya menjadi alat diagnostik yang dapat Anda terapkan pada audio referensi apa pun dalam waktu kurang dari lima menit.
| Elemen | Apa Itu | Cara Mengidentifikasi dalam Referensi | Kesalahan Amatir Umum |
|---|---|---|---|
| Pitch & Register | Frekuensi fundamental alami dan kisaran yang pembicara bergerak di dalamnya | Bersenandung bersama; temukan nada berkelanjutan terendah dan nada "rumah" tipikal | Terkunci pada satu pitch daripada melacak kontur |
| Resonansi & Tone | Di mana suara secara fisik bergetar — dada, topeng, hidung, kepala | Letakkan tangan di dada, tenggorokan, pipi sambil memutar referensi; rasakan area mana yang akan berdengung | Menyalin timbre dari tenggorokan daripada rongga yang tepat |
| Napas & Kecepatan | Poin inhalasi, panjang jeda, kata per menit, ritme frasa | Tandai setiap napas dalam klip 30 detik; hitung suku kata antara napas | Berbicara terlalu cepat, meruntuhkan kecepatan karakter |
| Artikulasi & Kejelasan | Kekuatan serangan konsonan, keterbukaan vokal, penempatan lidah dialek | Perlambat referensi ke kecepatan 0,5x; isolasi awal konsonan | "Diktion baik" generik daripada pilihan spesifik karakter |
| Subteks Emosional | Perasaan mendasar yang mewarnai setiap baris | Tanya: apa yang karakter ini inginkan pada saat ini? | Berkinerja kata daripada niat di bawahnya |
Urutan pada tabel bukan kosmetik. Pitch dan resonansi adalah anatomi — mereka ditetapkan oleh tempat Anda menempatkan suara di dalam tubuh Anda. Dapatkan yang salah dan tidak ada jumlah pacing atau artikulasi yang dapat menyelamatkan imitasi di hilir. Pacing dan artikulasi adalah perilaku — dapat disesuaikan melalui pengulangan. Subteks emosional adalah interpretatif — lapisan yang mengangkat imitasi yang akurat secara teknis menjadi yang dapat dipercaya.
Coba diagnostik pada target konkret. Kreator yang mencoba Galadriel Cate Blanchett menemukan pitch dengan cepat: menengah-rendah, bernafas. Jebakan adalah resonansi. Suaranya duduk di topeng — area di belakang pipi — bukan di tenggorokan. Sebagian besar upaya amatir menarik resonansi turun ke tenggorokan, yang terdengar lebih kecil dan lebih muda. Setelah resonansi ditempatkan dengan benar di topeng, pacing lambat dan vokal yang memanjang mengikuti secara alami, karena rongga itu sendiri mendikte ritme. Perbaiki lapisan anatomi dan lapisan perilaku memperbaiki diri mereka sendiri.
Catatan untuk Siapa Pun yang Merencanakan untuk Mengkloning Imitasi Mereka
Diagnostik di atas juga berlaku sebaliknya. Ketika Anda merekam audio pelatihan untuk kloning suara, model menangkap tanda tangan apa pun yang paling konsisten di seluruh dataset. Menurut panduan kloning Voiceover Masterclass, kreator harus merekam dalam gaya yang konsisten dan netral sepanjang satu sesi berkelanjutan — kecuali tujuan eksplisitnya adalah mengkloning suara karakter bergaya. Terjemahan: jika Anda ingin klon dari imitasi karakter Anda daripada suara bicara sehari-hari Anda, Anda harus tetap berada di karakter selama seluruh rekaman pelatihan. Bergerak masuk dan keluar darinya menghasilkan klon berlumpur yang terdengar seperti tidak ada yang lain.
Ini juga mengapa lapisan persepsi Bagian 1 penting secara operasional. Pemain yang bergerak menghasilkan data yang bergerak. Pemain dengan penempatan resonansi yang terinternalisasi menghasilkan data yang stabil. Klon semata-mata sebaik konsistensi tanda tangan yang dipelajarinya.
Empat Latihan yang Membangun Memori Otot Imitasi Suara
Mengetahui lima elemen vokal adalah diagnosis. Empat latihan ini adalah pengobatan. Masing-masing menargetkan mode kegagalan spesifik dan memakan waktu 15 menit atau kurang.
Latihan 1 — Loop Isolasi
Target: akurasi pitch dan resonansi.
- Pilih frase 5 kata dari referensi Anda (misalnya, "I have been expecting you")
- Loop referensi 10 kali untuk menanamkan suara target di telinga Anda
- Rekam versi Anda fokus pada pitch saja — abaikan resonansi, abaikan karakter, cukup cocokkan kontur melodi
- Rekam ulang fokus pada resonansi saja — frase yang sama, targetkan rongga yang tepat
- Rekam ulang fokus pada kecepatan dan napas — frase yang sama, cocokkan waktunya dengan tepat
- Waktu: 15 menit setiap hari
Mengapa ini bekerja: prinsip motor-learning dalam pedagogi suara mendukung praktik terblokir (satu variabel pada satu waktu) daripada praktik variabel ketika mempelajari koordinasi baru, posisi yang konsisten dengan kerangka Titze dalam Principles of Voice Production. Mengisolasi satu variabel melatih kelompok otot yang bertanggung jawab untuk itu tanpa beban kognitif mengguncang semua lima.
Latihan 2 — Tes Referensi Buta
Target: pelatihan telinga, self-deception.
- Rekam tiga take dari bagian 15 detik dalam karakter
- Tunggu setidaknya 4 jam — telinga segar
- Putar referensi, kemudian take terbaik Anda, bergantian tanpa melihat gelombang
- Nilai dengan jujur: mana yang terdengar lebih seperti mereka?
Sebagian besar kreator menemukan "take terbaik" mereka bukan yang paling dekat. Mereka memberi penghargaan pada take di mana mereka merasakan usaha paling banyak daripada take yang mendarat paling akurat. Tes buta memecah bias itu. Jalankan setiap minggu.
Latihan 3 — Jangkar Emosional
Target: subteks emosional, keaslian pertunjukan.
Sebelum merekam, namai keadaan emosional karakter dalam adegan. Gandalf berteriak "You shall not pass!" bukan kemarahan — itu resolusi perlindungan dalam kelelahan. Dua negara terdengar benar-benar berbeda bahkan ketika kata-katanya identik. Secara fisik mewujudkannya: postur, kedalaman napas, di mana Anda memegang ketegangan di tubuh Anda. Poin berulang Dee Bradley Baker dalam I Want to Be a Voice Actor! adalah bahwa suara karakter tanpa niat karakter terdengar mekanis. Rekam hanya setelah jangkar ditetapkan. Setiap sesi.
Latihan 4 — Tes Tekanan Lintas Bahasa
Target: internalisasi tanda tangan vs. menghafal fonetik.
Ambil imitasi Anda dan lakukannya pada skrip yang benar-benar berbeda — daftar belanja, laporan cuaca, lirik lagu favorit Anda — dengan suara yang sama. Jika imitasi runtuh saat kata-kata berubah, Anda telah menghafal urutan fonetik daripada menginternalisasi tanda tangan vokal.
Latihan ini adalah penjaga untuk pekerjaan lokalisasi. Jika imitasi Anda tidak dapat bertahan diaplikasikan pada daftar belanja dalam bahasa Inggris, itu tidak akan bertahan didubbing ke Portugis. Kadensi mingguan.
Jika imitasi Anda tidak dapat bertahan diterapkan pada daftar belanja, itu tidak akan bertahan didubbing ke bahasa kedua.
Jadwal Pelatihan Imitasi Suara Mingguan Anda
- Loop isolasi 15 menit harian pada satu elemen vokal (putar: pitch → resonansi → pace → artikulasi)
- Tetapkan jangkar emosional sebelum setiap sesi perekaman
- Satu tes referensi buta per minggu dengan pemisahan 4+ jam antara take dan review
- Satu tes tekanan lintas bahasa per minggu menggunakan materi non-skrip
- Rekam "take tanda tangan" 30 detik setiap Jumat — bagian yang sama, karakter yang sama — untuk melacak kemajuan minggu ke minggu
- Pertahankan noise floor −60 dB atau lebih rendah di ruang perekaman Anda (panel akustik, tanpa HVAC, tanpa kipas), per standar Voiceover Masterclass — ini penting untuk pelatihan telinga manusia dan penggunaan kloning di masa depan apa pun
Di Mana Praktik Imitasi Suara Manual Mencapai Batas Keras
Latihan di atas membangun keterampilan nyata yang tidak ada alat yang dapat meniru. Mereka juga memiliki batas. Seorang pemain terampil tunggal memiliki throughput terbatas — hambatan bukan bakat, tetapi biologi dan jam. Empat skenario menunjukkan di mana batas itu menjadi kendala bisnis.
Masalah video 30 menit. Kreator yang mempertahankan suara karakter selama 30 menit dialog kelelahan vokal. Take 40 tidak cocok dengan take 4. Pitch meluncur ke atas, napas memendek, resonansi dada bermigrasi ke tenggorokan. Perbaikan kamar edit memakan biaya jam.
Masalah lokalisasi 6 bahasa. Bahkan kreator yang lancar dalam bahasa Spanyol tidak dapat tentu berkinerja suara karakter bahasa Inggris mereka dengan meyakinkan dalam bahasa Spanyol. Kalikan dengan enam bahasa target dan rencana lokalisasi menjadi setahun pekerjaan suara — dengan asumsi keterampilan pertunjukan multibahasa ada sama sekali.
Masalah revisi klien. Perubahan baris di minggu 8 berarti merekam ulang dalam keadaan vokal yang sama — ruang yang sama, waktu hari yang sama, hidrasi tenggorokan yang sama. Praktis tidak mungkin untuk cocok dengan sempurna.
Masalah multi-karakter. Kreator yang memberi suara pada empat karakter dalam adegan dialog tunggal membutuhkan minimal empat pass perekaman terpisah, dan transisi vokal menguras laring dengan cepat.
Metode Produksi Imitasi Suara Dibandingkan
| Faktor | Imitasi Terekam Sendiri | Menyewa Aktor Suara | Kloning Suara AI |
|---|---|---|---|
| Waktu ke take pertama yang dapat digunakan | Minggu hingga bulan praktik terdistribusi | 1–3 hari (casting + perekaman) | Detik untuk pemula kloning dari sampel 10 detik; 30–120 menit untuk tingkat prosumer |
| Sampel perekaman yang diperlukan | N/A — pertunjukan langsung | N/A — pertunjukan langsung | 30–120 detik (turnkey); 10–15 menit (RVC); 30 menit–2 jam (profesional) |
| Konsistensi Take-to-take | Variabel — bergeser dengan kelelahan | Tinggi dalam sesi; variabel antar sesi | Sempurna dapat diulang untuk teks dan parameter yang diberikan |
| Penskalaan Multibahasa | Memerlukan kelancaran + keahlian imitasi dalam setiap | Aktor multibahasa atau aktor ganda | Dubbing AI lintas bahasa melestarikan timbre di seluruh target |
| Kesesuaian Terbaik | Pertunjukan langsung, bentuk pendek, pelatihan telinga | Produksi one-off premium | Bentuk panjang, multibahasa, konten iteratif |
Sumber untuk gambar di atas: tutorial ElevenLabs, DeepReel, CloudPano, Kukarella, dan tutorial RVC.
Ini bukan keputusan bahwa AI menang. Praktik manual menghasilkan keterampilan yang ditransfer ke pertunjukan langsung, podcasting, teater, dan pelatihan telinga yang membuat setiap metode lain lebih baik. Tabel mengisolasi skenario produksi spesifik di mana biologi menjadi kendala.
Bukti tandingannya juga penting. Aktor suara dan SAG-AFTRA telah secara terbuka mencatat bahwa klon AI saat ini masih berjuang dengan nuansa emosional kompleks, subteks, dan pekerjaan adegan dinamis — terutama dalam drama dan komedi di mana microtiming membawa makna. Untuk kreator yang memproduksi video penjelasan enam bahasa, batasan itu dapat diterima. Untuk kreator yang memproduksi animasi naratif dengan tiga putaran emosional per adegan, itu belum sepenuhnya. Sintesis jujur: pertanyaannya bukan "manual atau AI." Pertanyaannya adalah "di mana setiap metode milik dalam alur kerja?"
Hambatan dalam pekerjaan imitasi suara bukan bakat — tetapi biologi dan jam.
Bagaimana Kloning Suara AI Memperkuat Jangkauan Imitator Berbakat
Apa yang Benar-benar Ditangkap Kloning
Klon suara bukanlah rekaman. Ini adalah model yang dipelajari dari tanda tangan vokal. Model menangkap profil resonansi, pola kontur pitch, ritme napas, dan kecenderungan artikulasi dari audio pelatihan, kemudian menerapkannya pada teks baru. Ahli pidato Rupal Patel, pendiri VocaliD, telah berpendapat dalam pembicaraan TED-nya dan wawancara terkait bahwa suara sintetik yang autentik harus menangkap prosodi idiosinkratis, bukan hanya pitch rata-rata, untuk dibaca sebagai nyata daripada generik.
Itulah tepat mengapa imitasi yang dijalankan dengan baik adalah calon klon yang lebih baik daripada take netral datar. Tanda tangan yang dipelajari model adalah tanda tangan karakter. Kreator yang telah melakukan latihan Bagian 3 masuk ke sesi kloning suara dengan data yang lebih bersih dan lebih konsisten daripada seseorang yang belum — dan klon yang dihasilkan mencerminkan perbedaan itu secara langsung.
Realitas Dataset
Ada tiga tingkatan kualitas, masing-masing dengan persyaratan sampel spesifik.
- Pemula / klon instan: ~10 detik pidato yang jelas menghasilkan klon tes dasar yang dapat Anda eksperimen dalam hitungan detik, per tutorial ElevenLabs.
- Klon narator tingkat kreator: 30–120 detik audio bersih menghasilkan klon narator yang stabil, per DeepReel dan CloudPano.
- Klon tingkat profesional: 30 menit hingga 2 jam perekaman, dengan hasil menjadi nyata lebih baik lebih dekat ke tanda 2 jam; waktu pemrosesan pada infrastruktur penyedia berjalan kira-kira 2–6 jam, per tutorial ElevenLabs.
- Stack RVC sumber terbuka: 10–15 menit audio bersih adalah titik manis praktisi; 2–10 menit dimungkinkan dengan kompromi kualitas; 40 kHz sample rate adalah standar praktisi, per tutorial RVC.
Lantai teknis tidak dapat ditawar: noise floor ≤ −60 dB, dan tanpa kompresi, EQ, de-essing, atau pengurangan noise diterapkan pada file pelatihan mentah, per standar Voiceover Masterclass. Sampah masuk, sampah keluar berlaku dua kali — model memperkuat artefak apa pun yang ada dalam sumber.

Dua Studi Kasus Alur Kerja
Kasus A — YouTuber 30 Menit. Kreator menguasai imitasi karakter selama 30 detik tetapi kehilangan konsistensi di seluruh episode panjang bentuk. Alur kerja: rekam satu take sempurna 90 detik dari suara karakter. Kloningnya. Hasilkan dialog latar dengan klon menggunakan Text to Speech, sambil mereservasi energi pertunjukan langsung untuk lima atau enam beat emosional kunci yang membawa episode. Hasilnya: suara konsisten di seluruh 30 menit, puncak pertunjukan tempat mereka penting, sesi perekaman dikompresi dari kira-kira 8 jam menjadi tentang 90 menit.
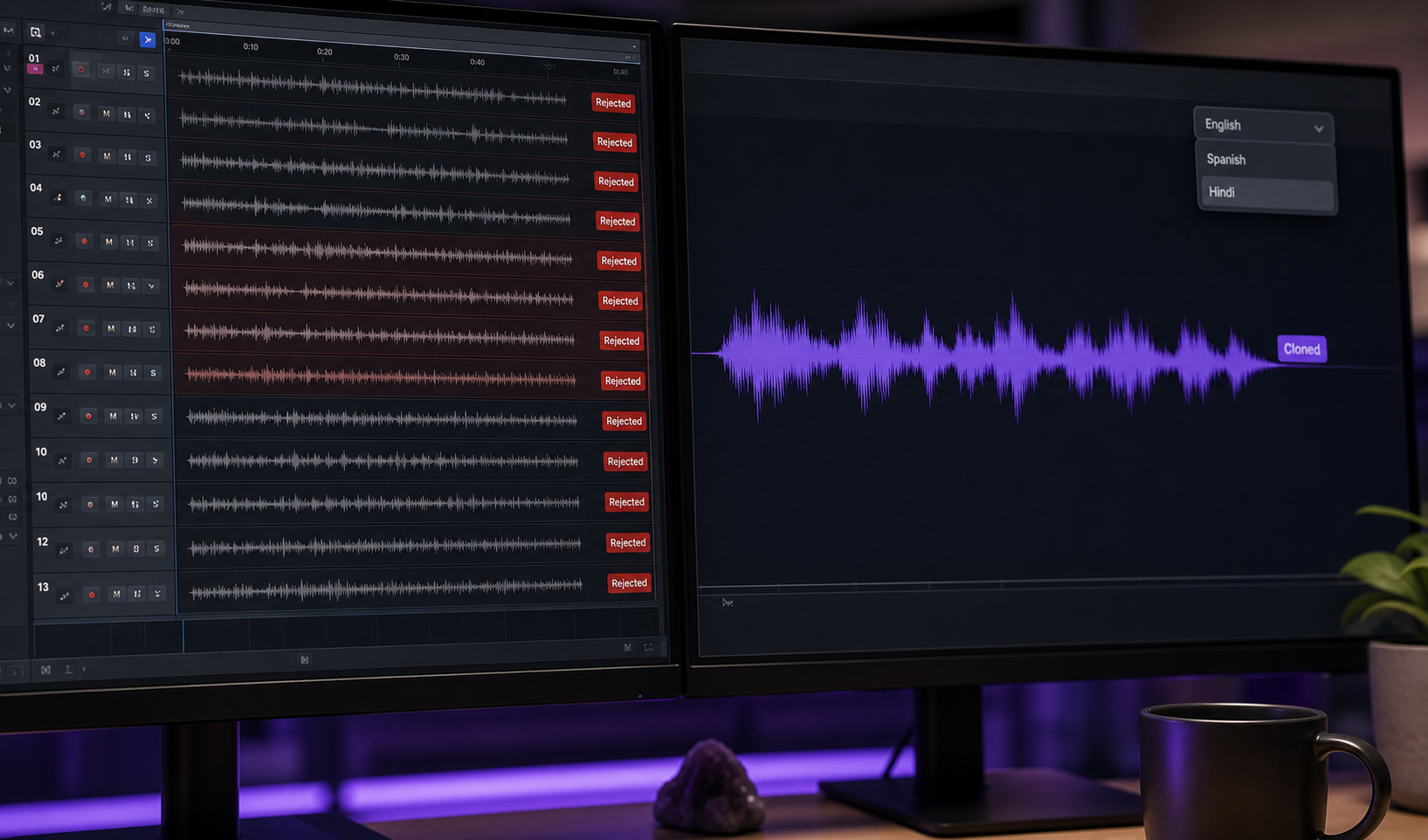
Kasus B — Video Pelatihan 6 Bahasa. Bisnis kecil memproduksi modul pelatihan internal 15 menit yang dinarasikan dalam suara karakter yang hangat dan berwibawa. Alur kerja: rekam versi bahasa Inggris sekali dengan imitasi langsung. Kloningnya. Gunakan kloning lintas bahasa melalui API Kloning Suara untuk merender versi Spanyol, Portugis, Prancis, Jerman, Hindi, dan Jepang sambil melestarikan timbre karakter di seluruh bahasa, per DeepReel dan Kukarella. Karakter yang sama "berbicara" semua enam bahasa karena tanda tangan ditransfer, bahkan meskipun bahasanya tidak.
Kloning suara tidak menggantikan keterampilan menguasai imitasi — itu memperkuat. Bagian yang sulit masih mendapatkan karakter yang tepat; teknologi hanya menghilangkan pengulangan.
Etika dan Batas Legitimasi
Suara sintetis dapat digunakan sebagai senjata. Profesor hukum Danielle Citron, dalam The Fight for Privacy dan cendekiawan deepfake terkait, telah mendokumentasikan bagaimana kloning suara tanpa persetujuan dari orang asli memungkinkan penyamaran, penipuan, dan misinformasi politik — dan telah berpendapat untuk penjaga hukum dan penjaga tingkat desain pada alat komersial.
Garis etika untuk kreator sederhana. Mengkloning suara Anda sendiri untuk konten Anda sendiri jelas baik-baik saja. Mengkloning suara karakter fiksi yang Anda kembangkan sendiri baik-baik saja. Mengkloning sosok publik nyata, atau siapa pun, tanpa persetujuan eksplisit tidak. Pengungkapan dalam kredit ketika dubbing AI digunakan menjadi praktik standar dan merupakan default yang lebih aman untuk pekerjaan komersial apa pun.
Bangun Toolkit Imitasi Suara Anda — Cocokkan Hambatan Anda dengan Jalur yang Tepat
Pilihan bukan praktik manual atau kloning suara AI. Ini mengidentifikasi hambatan mana yang benar-benar memblokir pekerjaan Anda sekarang, dan menerapkan jalur yang sesuai. Matriks di bawah memetakan empat situasi kreator umum untuk tindakan pertama spesifik.
Jalur Imitasi Suara Mana yang Sesuai Hambatan Anda?
| Situasi Anda | Hambatan Utama | Prioritas Alat | Tindakan Pertama Minggu Ini |
|---|---|---|---|
| Imitasi belum meyakinkan — membangun keahlian untuk YouTube atau Twitch | Kesenjangan keterampilan | Latihan dari Bagian 3 + umpan balik rekan | Pilih satu karakter; jalankan loop isolasi harian selama 14 hari sebelum menilai |
| Imitasi kuat, tetapi lelah merekam ulang video panjang | Kelelahan vokal, pergeseran konsistensi | Kloning suara pada imitasi yang Anda lakukan sendiri | Rekam satu take bersih 90 detik dalam karakter di −60 dB; kloningnya; uji pada bagian 2 menit yang dihasilkan |
| Melokalisasi konten bahasa Inggris yang ada ke berbagai bahasa | Kesenjangan kinerja multibahasa | Kloning lintas bahasa + Dubbing AI | Kloningkan imitasi referensi Anda sekali; dubbing sampel 2 menit ke bahasa target prioritas tertinggi Anda; tinjau untuk pelestarian karakter |
| Tim memproduksi konten bermerek multibahasa dengan volume | Skalabilitas pipeline | Kloning + integrasi API | Prototyp alur kerja API Dubbing AI pada satu proyek produksi |
Tiga prinsip kerja untuk menggunakan matriks ini dengan jujur.
Matriks bukan permanen. Kreator di baris satu hari ini pindah ke baris tiga dalam delapan belas bulan. Hambatan bergeser saat pekerjaan bergeser. Evaluasi ulang setiap kuartal.
Kloning memperkuat; itu tidak berasal. Temuan berulang di seluruh tutorial kloning — Voiceover Masterclass, panduan ElevenLabs, tutorial RVC — adalah bahwa kualitas audio dan kualitas pertunjukan dalam sumber menentukan kualitas klon. Kreator yang melewatkan latihan Bagian 3 dan mencoba mengkloning imitasi ceroboh mendapat klon dari imitasi ceroboh. Teknologi setia terhadap inputnya.
Lantai 30 detik penting secara operasional. Beberapa platform turnkey dapat menghasilkan profil suara yang berfungsi dari kira-kira 20–30 detik audio bersih. Itu berarti kreator yang sudah memiliki satu take bagus dari suara karakter mereka adalah satu unggahan dari aset produksi yang dapat digunakan kembali. Hambatan bukan teknologi — itu memiliki take yang satu bagus.
Tujukan tekanan tandingan juga. Beberapa pelatih suara berhati-hati bahwa mengandalkan kloning berat-berat di awal dapat menghentikan pengembangan keterampilan dasar: dukungan napas, kontrol resonansi, artikulasi. Jalur tengah pragmatis adalah terus melakukan latihan bahkan ketika Anda menggunakan klon untuk produksi, karena latihan membuat setiap klon masa depan lebih baik.
Rencana Tindakan Dua Minggu Anda
- Identifikasi baris mana dari matriks yang menjelaskan hambatan saat ini Anda — jujur; sebagian besar kreator duduk di dua baris sekaligus. Pilih yang lebih menyakitkan.
- Jika baris Anda adalah "kesenjangan keterampilan": berkomitmen pada loop isolasi 15 menit harian dan satu tes referensi buta mingguan selama 14 hari penuh sebelum mengevaluasi ulang.
- Jika baris Anda melibatkan kloning: rekam referensi bersih 30–90 detik dengan noise floor di atau di bawah −60 dB, dalam karakter, dalam satu sesi berkelanjutan, tanpa EQ atau kompresi diterapkan.
- Jalankan tes klon skala rendah sebelum pekerjaan klien atau pendapatan apa pun — gunakan pada video internal, tes saluran pribadi, atau skrip draf.
- Jika melokalisasi: pilih bahasa target prioritas tertinggi Anda dan dubbing sampel 2 menit. Tinjau khusus untuk pelestarian karakter, bukan hanya akurasi terjemahan.
- Jika mengintegrasikan ke dalam pipeline produksi: prototyp alur kerja API pada satu proyek sebelum menstandardisasi. Uji API Text to Speech dan API Kloning Suara pada jenis konten yang mewakili.
- Tetapkan checkpoint 14 hari untuk menilai ulang hambatan Anda — itu mungkin telah bergeser.
Kreator yang menang pada konten multibahasa pada 2025 bukanlah yang memilih alat yang tepat. Mereka adalah yang membangun imitasi nyata terlebih dahulu, kemudian membiarkan alat melakukan apa yang alat lakukan terbaik — ulangi, skalakan, dan lestarikan di seluruh bahasa yang mereka tidak berbicara.
FAQ
Bisakah saya menggunakan kloning suara AI untuk melakukan imitasi figur publik nyata?
Secara hukum dan etis: tidak tanpa persetujuan eksplisit, dan bahkan kemudian, ungkapkan itu. Cendekiawan Danielle Citron tentang deepfake dan media sintetis mendokumentasikan bagaimana kloning suara tanpa persetujuan dari orang asli memungkinkan penyamaran, penipuan, dan misinformasi politik. Untuk karakter fiksi yang Anda kembangkan, atau suara Anda sendiri, kloning jelas tidak ambigu. Untuk imitasi dari figur publik yang hidup, jawaban teraman adalah tidak — dan platform terkemuka memberlakukan kebijakan selaras dengan prinsip ini. Pengungkapan dalam kredit menjadi praktik standar untuk pekerjaan komersial apa pun yang menggunakan suara sintetis.
Berapa lama sebenarnya waktu untuk mengkloning suara yang dapat digunakan?
Itu tergantung pada tingkatan kualitas. Sampel 10 detik menghasilkan klon eksperimental yang dapat Anda uji dalam hitungan detik, per tutorial ElevenLabs. Sampel 30–120 detik menghasilkan klon tingkat kreator yang stabil cocok untuk narasi dan konten penjelasan, per DeepReel dan CloudPano. Klon tingkat profesional menginginkan 30 menit hingga 2 jam perekaman sumber ditambah kira-kira 2–6 jam waktu pemrosesan pada infrastruktur penyedia. Sebagian besar platform kreator duduk dengan nyaman di ujung cepat tingkatan kreator, menerima kira-kira 20–30 detik audio bersih sebagai lantai kerja.
Apakah saya perlu mengungkapkan bahwa saya menggunakan kloning suara AI dalam konten saya?
Belum ada persyaratan hukum universal, tetapi pengungkapan menjadi praktik standar dan merupakan default yang lebih aman. Jika Anda mengkloning suara Anda sendiri untuk efisiensi, baris kredit sederhana — "Suara dikloningkan melalui [platform] untuk versi multibahasa" — melindungi kepercayaan audiens. Jika konten mewakili orang nyata, bahkan dengan persetujuan mereka, pengungkapan sangat penting. Posisi berkelanjutan SAG-AFTRA di sekitar penggunaan suara AI dalam pekerjaan komersial mendorong industri yang lebih luas menuju pelabelan yang jelas, dan menyelaraskan praktik Anda dengan arah itu di awal menghindari keduanya reputasi dan paparan hukum kemudian.