
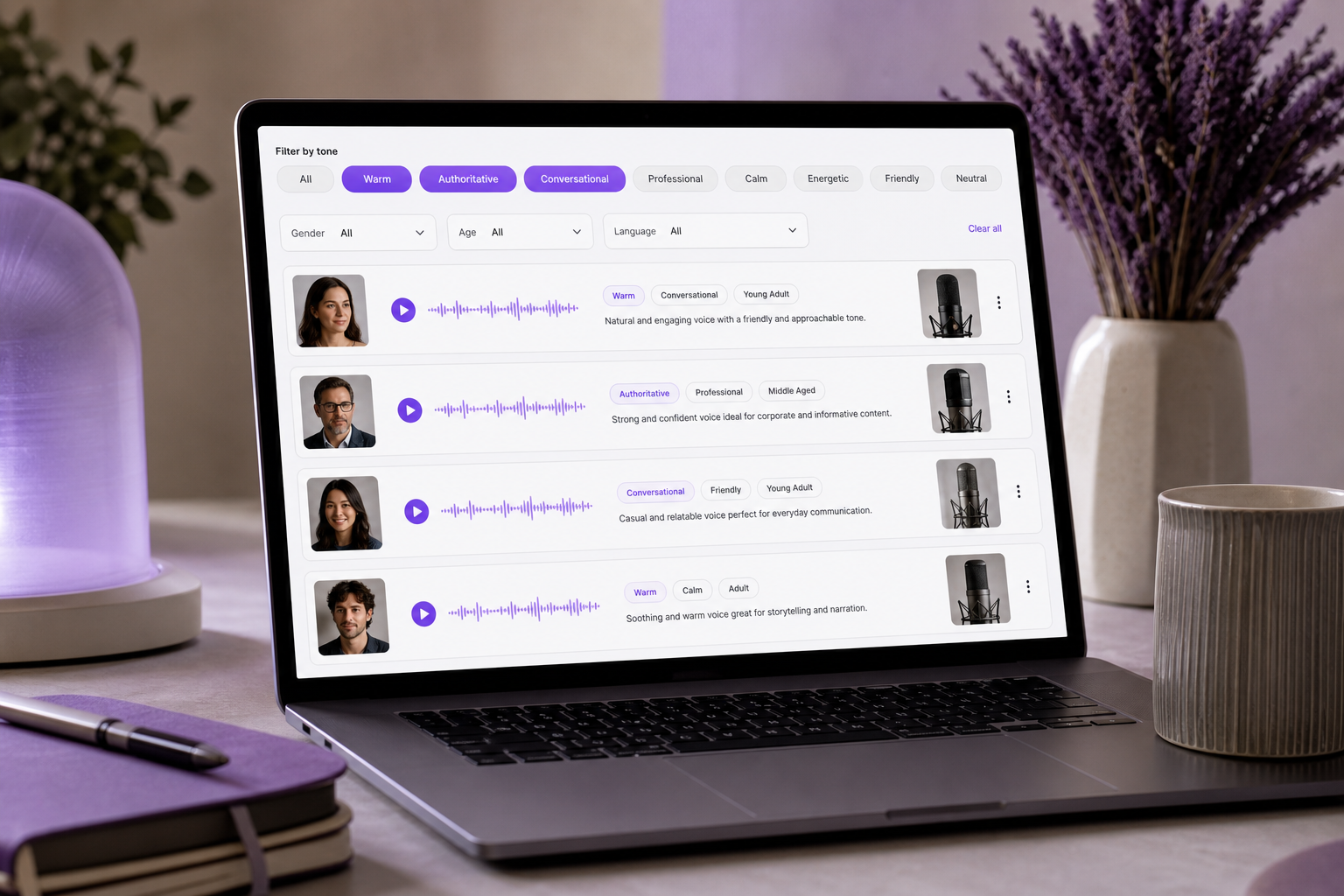
Anda telah menggulir melewati empat puluh sampel suara. Headphone terpasang, Anda mengetuk pratinjau, mendengarkan selama tiga detik, mengetuk yang berikutnya, dan yang berikutnya, hingga setiap sampel berbaur menjadi dengungan samar yang sama. Apakah yang ini "hangat" atau hanya "lembut"? Haruskah penjelasan itu terdengar "berwibawa" atau "ramah"? Masalahnya bukanlah kurangnya pilihan — pustaka modern menyimpan 300+ suara, dan Anda bisa menyimaknya selama satu jam tanpa menemukan satu pun. Masalahnya adalah deskriptor suara: kosakata tepat yang Anda butuhkan untuk membedakan satu suara dari yang lain dan mencocokkannya dengan konten Anda secara sengaja. Tanpa kosakata itu, pemilihan suara berubah menjadi tebak-tebakan dan dubbing menjadi coba-coba yang mahal. Menurut WP SEO AI, label satu kata seperti "natural" atau "menarik" terlalu samar untuk ditindaklanjuti — potret vokal yang jelas memerlukan penentuan beberapa dimensi yang saling berinteraksi sekaligus. Di akhir artikel ini, Anda akan mampu mendeskripsikan suara apa pun dengan presisi mencakup nada, pitch, dan gaya, sehingga Anda bisa mencari, memfilter, dan memprompt alat suara — atau membuat brief proyek kloning — dengan percaya diri alih-alih mengandalkan keberuntungan.

Daftar Isi
- Empat Dimensi yang Mencakup Setiap Deskriptor Suara
- Deskriptor Nada Diuraikan — Dari "Hangat" hingga "Berwibawa"
- Pitch dan Tempo — Deskriptor Teknis yang Salah Dipahami Orang
- Gaya dan Register — Mencocokkan Suara dengan Konteks Konten
- Menyusun Deskriptor menjadi Pencarian atau Prompt Suara yang Presisi
- Jebakan Deskriptor — Di Mana Pemilihan Suara Diam-Diam Gagal
- Template Briefing Deskriptor Suara Salin-Tempel Anda
- Pertanyaan Deskriptor Suara yang Benar-Benar Ditanyakan Kreator
Empat Dimensi yang Mencakup Setiap Deskriptor Suara
Setiap deskriptor suara yang pernah Anda baca — sepuitis apa pun — runtuh menjadi empat dimensi yang dapat diukur. Begitu Anda bisa menamainya, kosakata itu berhenti terasa subjektif dan mulai berperilaku seperti sekumpulan kontrol yang dapat Anda atur secara independen.
Nada adalah warna emosional atau sikap dari suara. Hangat, dingin, antusias, jauh — inilah karakter emosional yang dirasakan pendengar sebelum mereka memproses makna satu kata pun. Inilah dimensi yang menentukan apakah audiens Anda condong mendekat atau menyetel keluar.
Pitch adalah tinggi atau rendahnya suara yang dipersepsikan. Bariton yang dalam dan beresonansi berada di satu ujung; suara yang cerah, ringan, dan muda berada di ujung lainnya. Pitch pada dasarnya adalah properti frekuensi, yang menjadikannya salah satu deskriptor paling objektif dari keempatnya — namun juga salah satu yang paling sering dikacaukan dengan tempo.
Tempo dan ritme menggambarkan kecepatan ucapan dan iramanya. Cepat, terukur, santai, terencana — tempo mencakup jeda antar frasa dan pola infleksi yang menyertainya. Dua suara yang membaca naskah identik dengan tempo berbeda bisa terasa seperti penampilan yang sama sekali berbeda.
Gaya dan register mengatur konteks penampilan dan formalitas. Narasi, percakapan, siaran, e-learning — formal versus santai. Inilah dimensi yang menentukan peran apa yang dimainkan suara bagi pendengar.
Taksonomi ini bukan opini pribadi. Nielsen Norman Group memformalkan nada di sepanjang empat poros independen — formal vs. santai, serius vs. lucu, hormat vs. tak hormat, dan apa adanya vs. antusias — menunjukkan bahwa nada bersifat multi-poros, bukan satu penggeser tunggal yang Anda tarik dari "membosankan" ke "menyenangkan". Platform komersial mengoperasionalkan logika yang sama. Pasar suara Voices.com mengelompokkan deskripsi vokal menjadi empat kualitas: pitch dan nada, volume dan proyeksi, artikulasi dan pengucapan, serta laju dan infleksi. Label berbeda, struktur dasar yang sama.

Mengapa memisahkan dimensi itu begitu penting? Pelatih komunikasi Robin Kermode membingkai nada, pitch, dan tempo sebagai tiga tuas yang bersama-sama menciptakan "variasi vokal" — mendefinisikan nada sebagai karakter emosional, pitch sebagai frekuensi yang dipersepsikan yang dapat mengubah makna emosional, dan tempo sebagai kecepatan penyampaian. Gaya dan register membentuk tuas keempat, dan ia berada di atas ketiga yang lain, mengatur konteks tempat mereka beroperasi. Sederhananya: nada, pitch, dan tempo menggambarkan bagaimana suara terdengar; gaya dan register menggambarkan peran apa yang dimainkannya.
Setiap deskriptor suara yang pernah Anda baca runtuh menjadi empat tuas — nada, pitch, tempo, dan gaya. Kuasai tuasnya dan Anda berhenti menebak.
Pegang model ini. Setiap bagian yang mengikuti menggali tepat satu dari empat dimensi ini, dan tidak ada yang akan mendefinisikan ulang kerangkanya. Ketika Anda menemukan deskriptor di mana pun — filter pasar, kolom prompt AI, brief agensi — tugas pertama Anda adalah memasukkannya ke salah satu dari empat kategori tersebut. Kebiasaan tunggal itu mengubah deretan kata sifat menjadi panel kontrol yang teratur.
Deskriptor Nada Diuraikan — Dari "Hangat" hingga "Berwibawa"
Nada adalah dimensi yang pertama kali ditangkap audiens, dan yang paling umum salah dibrief karena bersandar pada kata sifat subjektif. Riset Nielsen Norman Group menunjukkan nada beroperasi di sepanjang beberapa poros independen — humor, formalitas, kesopanan, dan antusiasme adalah tuas yang terpisah — yang berarti satu kata nada jarang menangkap apa yang sebenarnya Anda inginkan. Kelompokkan deskriptor nada Anda sebagai gantinya, dan Anda mendapatkan presisi sekaligus cara praktis untuk memfilter.
Membangun kepercayaan (hangat, ramah, menenangkan). Kelompok ini membangun rasa aman emosional sebelum makna mendarat. Ini pilihan yang tepat untuk penjelasan layanan kesehatan, IVR dukungan pelanggan, dan video onboarding di mana pendengar perlu merasa didukung sebelum mereka menyerap instruksi. WP SEO AI mencantumkan "hangat" di antara kata sifat nada emosional yang paling sering digunakan, dan dengan alasan yang baik — ini adalah dasar yang secara default dipercayai sebagian besar audiens.
Energik (bersemangat, antusias, hidup). Kelompok ini menandakan momentum dan kegembiraan. Ini terbaik untuk peluncuran produk, baca iklan, dan video pendek media sosial di mana dua detik pertama menentukan apakah seseorang terus menonton. Poros "antusias" NN/g langsung memetakan ke sini — dan perhatikan bahwa ia independen dari formalitas, sehingga Anda bisa energik dan profesional pada saat yang sama.
Serius (berwibawa, profesional, muram). Kelompok ini menyampaikan kredibilitas dan bobot. Gunakan untuk pelatihan korporat, penjelasan keuangan, dan narasi dokumenter di mana audiens perlu percaya bahwa pembicara tahu lebih banyak daripada mereka. "Berwibawa" adalah deskriptor unggulan dalam daftar potret vokal WP SEO AI — cukup spesifik untuk difilter dan cukup luas untuk diterapkan di berbagai format.
Intim (lembut, menenangkan, percakapan). Kelompok ini menciptakan kedekatan dan ketenangan. Ini dibuat untuk aplikasi meditasi, intro podcast, dan konten bergaya ASMR di mana pendengar sering sendirian dan suara terasa seperti berbicara langsung kepada mereka. Keintiman itu datang sebanyak dari pengendalian seperti dari kehangatan — kelompok ini menarik diri alih-alih memproyeksikan.
Nada adalah satu-satunya dimensi yang pertama kali diperhatikan audiens dan terakhir dilupakan — ia menetapkan kepercayaan emosional sebelum makna satu kata pun mendarat.
Kelompok-kelompok ini bukan sekadar model mental — itulah cara alat modern memungkinkan Anda mencari. Platform TTS seperti SymTrain mendokumentasikan pemfilteran suara berdasarkan nada seperti "artikulatif, santai, cemas," mempersempit pustaka besar sebelum Anda menekan pratinjau. Itulah manfaat praktis dari mengelompokkan deskriptor suara Anda: sama seperti pustaka Text to Speech memungkinkan Anda memfilter berdasarkan nada sebelum pratinjau, kelompok nada yang jelas mengubah satu jam penyimakan menjadi daftar pendek terfokus berisi tiga pilihan.
Pitch dan Tempo — Deskriptor Teknis yang Salah Dipahami Orang
Pitch dan tempo adalah dua dimensi yang paling sering dikacaukan dalam brief suara mana pun, dan kebingungan itu memakan waktu nyata para kreator. Pitch adalah frekuensi — tinggi atau rendahnya suara yang dipersepsikan. Tempo adalah kecepatan dan ritme — kata per menit, irama, dan penempatan jeda. Pembagian tiga arah Robin Kermode menjaganya tetap jernih: nada adalah karakter emosional, pitch adalah frekuensi yang dipersepsikan, tempo adalah kecepatan ucapan. Tiga hal terpisah.
Kesalahan klasik adalah menukar kosakatanya. Kreator mengatakan "cepat" ketika mereka maksudkan "ber-pitch tinggi," atau "dalam" ketika mereka maksudkan "lambat". Ini adalah kontrol independen. Suara yang dalam bisa cekatan. Suara yang tinggi bisa terukur. Memperlakukannya sebagai satu kata sifat yang kabur adalah cara brief menjadi salah sebelum siapa pun merekam satu suku kata.
| Deskriptor | Apa yang Dikontrol | Terdengar Seperti | Terbaik Untuk |
|---|---|---|---|
| Dalam | Pitch (frekuensi rendah) | Bariton, beresonansi | Dokumenter, merek mewah |
| Cerah | Pitch (frekuensi tinggi) | Ringan, lapang, muda | Konten anak, iklan bersemangat |
| Terukur | Tempo (lambat/rata) | Terencana, lapang | E-learning, tutorial |
| Cekatan | Tempo (cepat) | Energik, mendesak | Berita, promo |
| Tegas | Tempo + artikulasi | Renyah, berhenti presisi | Teknis, instruksional |
| Berlarut | Tempo (lambat/santai) | Memanjang, kasual | Bercerita, karakter |
Pekerjaan menarik terjadi ketika pitch dan tempo dikombinasikan, karena kesan gabungannya hampir selalu lebih kuat daripada deskriptor mana pun secara terpisah. Pitch dalam dengan tempo cekatan terbaca sebagai urgensi percaya diri — suara seseorang yang menguasai materi dan tidak membuang waktu Anda. Pitch cerah dengan tempo terukur terbaca sebagai kesabaran yang ramah — ideal ketika Anda menuntun pengguna yang gugup melalui penyiapan pertama. Tukar kombinasinya dan maknanya berbalik sepenuhnya, yang justru menjadi alasan mengapa Anda tidak bisa menggabungkan kedua kolom menjadi satu.
Pemisahan ini tertanam dalam cara platform serius menyusun panduan mereka. Voices.com memperlakukan pitch/nada dan laju/infleksi sebagai dua dari empat kualitas berbedanya, tidak pernah sebagai satu pengaturan tunggal. Dokumentasi Hamsa API serupa mencantumkan tempo bicara dan pengucapan/kejelasan sebagai kriteria pemilihan terpisah, masing-masing dievaluasi sendiri sebelum suara masuk ke produksi. Kesimpulan praktisnya langsung: dalam brief mana pun, beri pitch dan tempo kolom mereka sendiri. Tulis "pitch dalam, tempo cekatan," bukan "suara dalam yang punchy" dan berharap pembaca mengurainya. Dan ingat sifat pitch dan tempo yang sama yang Anda tentukan di sini adalah yang dipertahankan model Voice cloning dari sampel sumber — jadi mendapatkan kosakata yang tepat di tahap brief membawa dampaknya sepanjang jalan hingga ke keluaran kloning.
Gaya dan Register — Mencocokkan Suara dengan Konteks Konten
Keterampilan dengan pengaruh terbesar dalam pemilihan suara bukanlah memilih suara yang paling mengesankan. Itu adalah memilih gaya dan register yang tepat untuk konteks penyampaian — suara yang diharapkan audiens Anda dan tidak pernah mereka pertanyakan. Panduan sistem desain PatternFly memisahkan gaya (pilihan tata bahasa dan sintaksis), suara (kepribadian merek), dan nada (keadaan emosional pengguna), dan paralel suara lisan memetakan dengan rapi: gaya dan register di satu sisi, nada emosional di sisi lain. Salah register dan bahkan suara yang indah pun terasa janggal.
Dokumentasi Hamsa membuat perbedaan gaya menjadi konkret dengan alasan kasus penggunaan yang eksplisit. "Percakapan" bersifat natural dan ramah — terbaik untuk layanan dan dukungan pelanggan. "Narator" jelas dan artikulatif — cocok untuk penjelasan. Pembingkaian "terdengar seperti / terbaik untuk" itu persis yang mengubah gaya menjadi keputusan yang bisa Anda buat dalam hitungan detik alih-alih diperdebatkan sepanjang sore.
| Jenis Konten | Deskriptor Gaya yang Direkomendasikan | Mengapa Berhasil |
|---|---|---|
| Penjelasan YouTube | Percakapan | Natural, ramah — menjaga penonton kasual tetap terlibat |
| Pelatihan korporat | Narator | Jelas, artikulatif — cocok untuk penjelasan |
| Intro podcast | Percakapan / siaran | Menetapkan kehadiran pembawa acara yang hangat dan akrab |
| Buku audio | Narator | Kejelasan berkelanjutan untuk mendengarkan format panjang |
| Iklan / promo | Siaran energik | Memproyeksikan momentum dan ajakan bertindak |
Di bawah gaya terdapat register — pilihan formal-versus-santai yang memberi rasa pada segala sesuatu di atasnya. Poros formal↔santai NN/g adalah cara terbersih untuk memikirkannya: gaya percakapan yang sama dapat terbaca sebagai pembawa acara siaran yang dipoles atau teman yang berbicara di seberang meja, tergantung di mana Anda menyetel kenop register. Narator pelatihan korporat pada register santai terasa mudah didekati; narator yang sama pada register formal terasa institusional. Tidak ada yang salah — keduanya adalah jawaban untuk brief yang berbeda.
Dua lapisan lebih lanjut bertumpuk di atasnya. Aksen dan dialek adalah kriteria pemilihan inti dalam daftar periksa Hamsa, dan keduanya membawa bobot budaya yang tidak dapat ditimpa oleh deskriptor nada mana pun — suara "AS netral" dan suara "RP Inggris" dapat berbagi nada, pitch, dan tempo yang identik namun tetap mendarat dengan sangat berbeda pada audiens. SymTrain merekomendasikan filter kelompok usia — muda, dewasa, lebih tua — bersama dengan nada, karena usia yang dipersepsikan menggeser seberapa berwibawa atau relatable suatu suara terasa.
Deskriptor gaya yang tepat bukanlah suara yang paling mengesankan — melainkan yang diharapkan audiens Anda dengar pada momen itu dan tidak pernah mereka pertanyakan.
Poin tertajam PatternFly adalah bahwa gaya dan nada harus merespons keadaan emosional audiens, bukan default yang berlaku di seluruh merek. Konten pemecahan masalah membutuhkan register yang netral dan membantu; pengumuman membutuhkan yang antusias. Konteks mendikte register setiap saat. Dan keputusan register tidak tinggal diam ketika konten Anda bepergian — register santai dan percakapan yang mendarat sempurna dalam bahasa Inggris dapat terbaca sebagai sembrono atau tidak profesional di pasar lain. Itu adalah pilihan register yang harus bertahan ketika Anda mendorong konten melalui AI Dubbing ke bahasa lain, yang justru di situlah lapisan disiplin berikutnya membuahkan hasil.
Menyusun Deskriptor menjadi Pencarian atau Prompt Suara yang Presisi
Kosakata hanya berarti jika Anda dapat mengubahnya menjadi metode yang dapat diulang. Riset konsisten dalam prinsip intinya: deskriptor bertumpuk mengalahkan label tunggal setiap saat. WP SEO AI merekomendasikan menggabungkan kata sifat nada emosional seperti "hangat," "renyah," atau "berwibawa" dengan detail konkret tentang tempo, variasi pitch, resonansi, dan kejelasan untuk membangun potret vokal yang jelas. Voices.com memformalkan alur tiga langkah — definisikan karakter (usia, gender, gaya), tetapkan nada, lalu pilih kata kunci yang sesuai. Berikut logika itu diuraikan menjadi tujuh langkah yang dapat Anda jalankan setiap saat.
- Definisikan tujuan emosional. Sebutkan perasaan yang harus dibawa pulang audiens — kepercayaan, kegembiraan, ketenangan. Segala sesuatu di hilir melayani keputusan tunggal ini.
- Pilih satu kelompok nada. Pilih dari empat kelompok: membangun kepercayaan, energik, serius, atau intim. Tahan dorongan untuk mencampur kelompok yang bertentangan — di situlah brief terurai.
- Tetapkan rentang pitch. Dalam, sedang, atau cerah. Satu kata, bukan satu paragraf.
- Tetapkan tempo. Terukur, cekatan, atau tegas. Jaga tetap terpisah dari pitch.
- Kunci gaya dan register. Percakapan, narator, atau siaran — lalu formal atau santai.
- Lapisi demografi dan aksen. Tambahkan kelompok usia dan dialek, seperti yang diharapkan filter SymTrain dan Hamsa.
- Uji terhadap 2–3 sampel. Daftar periksa Hamsa — pengucapan, kejelasan, tempo, nada, aksen — adalah gerbang validasi akhir Anda sebelum apa pun dikirim.

Berikut tampilan tumpukan akhir sebagai satu string tunggal: hangat + pitch sedang + tempo terukur + gaya percakapan + perempuan + usia 30-an + aksen AS netral. Satu baris itu melakukan tugas ganda. Masukkan ke bilah pencarian dan ia memangkas waktu pemfilteran Anda di seluruh pustaka 300+ suara menjadi segelintir kandidat. Masukkan string bertumpuk yang sama ke preset TTS dan ia menjadi prompt generasi. Disiplin menulisnya satu kali itulah yang menyelamatkan Anda dari menyimak ulang seluruh katalog. Dan karena formatnya konsisten, string bertumpuk yang sama yang Anda masukkan ke preset TTS dapat diteruskan langsung ke panggilan Voice Cloning API — satu brief, banyak tujuan, nol penerjemahan ulang antar alat.
Jebakan Deskriptor — Di Mana Pemilihan Suara Diam-Diam Gagal
Sebagian besar proyek suara tidak gagal di tahap perekaman. Mereka gagal di brief, dengan cara yang tak terlihat sampai Anda mendengarkan file jadi yang entah bagaimana salah. Inilah mode kegagalan yang tidak muncul sampai mahal untuk diperbaiki.
Menumpuk deskriptor yang bertentangan secara berlebihan. "Energik tapi menenangkan" membatalkan dirinya sendiri — suara tidak bisa berlari dan berbisik pada saat yang sama. Riset NN/g berguna di sini: humor, kesopanan, dan antusiasme adalah tuas independen, jadi banyak kombinasi berfungsi dengan baik, tetapi beberapa benar-benar bertentangan. Solusinya adalah memilih satu kelompok nada dominan dan menyempurnakan di dalamnya alih-alih menjangkau antar kelompok untuk variasi yang tidak Anda butuhkan.
Memperlakukan "natural" sebagai arahan. "Natural" dan "menarik" terasa seperti instruksi, tetapi keduanya tidak dapat ditindaklanjuti. WP SEO AI berpendapat bahwa istilah serbaguna semacam itu gagal untuk alat AI maupun talenta jarak jauh karena tidak menentukan satu pun dimensi yang berinteraksi. Solusinya adalah mengganti setiap istilah serbaguna dengan tumpukan empat dimensi — nada, pitch, tempo, gaya — ditambah demografi. Jika sebuah deskriptor tidak masuk ke salah satu kategori itu, ia bukanlah arahan.
Mengasumsikan deskriptor diterjemahkan lintas bahasa. Nada yang dipersepsikan bergeser ketika Anda mendub ke bahasa dan budaya lain — register yang terbaca sebagai hangat dalam bahasa Inggris dapat mendarat sebagai terlalu akrab di tempat lain. Solusinya adalah memvalidasi ulang nada per bahasa target alih-alih memercayai deskriptor sumber untuk terbawa. Ketika Anda mendub ke 33 bahasa target, pemeriksaan nada per bahasa bukanlah pemolesan opsional; itulah perbedaan antara konten yang terhubung dan konten yang secara halus mengasingkan. Inilah sebabnya tim yang menjalankan konten melalui AI Dubbing API memeriksa ulang nada per bahasa target alih-alih mengasumsikan brief asli masih berlaku.
Mengabaikan konteks emosional audiens. PatternFly memperingatkan bahwa nada satu-ukuran-untuk-semua salah sasaran — alur pemecahan masalah membutuhkan suara yang netral dan membantu, sementara pengumuman membutuhkan yang antusias. Solusinya adalah memilih deskriptor untuk momen yang sedang dialami audiens Anda, bukan default berlaku-seluruh-merek yang Anda tetapkan enam bulan lalu.
Melewatkan brief dan memercayai intuisi. Pendekatan panduan nada Ed Gandia mengkritik arahan yang samar dengan menuntut parameter konkret — audiens, spesifik nada seperti "hangat tapi tidak banyak bicara," formalitas, panjang kalimat, dan pola berulang. Solusinya adalah yang paling sederhana dari semuanya: tulis brief bertumpuk sebelum Anda memratinjau satu suara pun. Intuisi baik untuk memilih di antara dua finalis. Ia buruk untuk mempersempit 300 menjadi 3.

"Natural" tidak menggambarkan apa pun — ia adalah ekspektasi default, bukan arahan kreatif.
Template Briefing Deskriptor Suara Salin-Tempel Anda
Berikut versi operasional dari semua yang di atas — struktur isian yang dapat Anda tempel ke alat suara, brief agensi, atau permintaan kloning mana pun. Ini adalah model empat dimensi ditambah demografi, diformat sehingga Anda tidak perlu membangunnya ulang dari awal. Perlakukan sebagai satu-satunya sumber kebenaran untuk deskriptor suara suatu proyek.
BRIEF DESKRIPTOR SUARA
----------------------------------------
Tujuan emosional: ____ (apa yang harus dirasakan audiens)
Kelompok nada: ____ (membangun kepercayaan / energik / serius / intim)
Pitch: ____ (dalam / sedang / cerah)
Tempo: ____ (terukur / cekatan / tegas)
Gaya / register: ____ (percakapan / narator / siaran; formal / santai)
Demografi: ____ (gender, kelompok usia)
Aksen / bahasa: ____ (dialek + bahasa target)
Suara referensi: ____ (opsional — suara yang dikenal untuk menambatkan ekspektasi)
Struktur ini tidak sembarangan. Ia mencerminkan ringkasan suara ringkas 3–5 kalimat Ed Gandia yang dipadukan dengan parameter nada, formalitas, dan ritme spesifik, dan mengikuti alur karakter → nada → kata kunci Voices.com dalam urutan Anda sebenarnya membuat keputusan. Isi dari atas ke bawah dan setiap kolom mempersempit yang berikutnya.
Berikut template diisi untuk skenario nyata — Intro Saluran YouTube Multibahasa:
- Tujuan emosional: sambutan yang percaya diri
- Kelompok nada: membangun kepercayaan / hangat
- Pitch: sedang
- Tempo: cekatan
- Gaya / register: siaran percakapan
- Demografi: perempuan, usia 30-an
- Aksen / bahasa: bahasa Inggris AS netral, didub ke bahasa Spanyol + Portugis
- Suara referensi: tidak ada
Satu brief suara itu melakukan tiga pekerjaan tanpa modifikasi. Ia mempersempit pencarian pustaka Anda menjadi daftar pendek. Ia menjadi prompt yang menggerakkan generasi TTS. Dan ia terbawa ke langkah dubbing, di mana deskriptor yang sama divalidasi ulang per bahasa target alih-alih dibangun ulang dari awal. Satu brief, tiga keluaran, tanpa pembriefan ulang.
Keunggulan praktis dari pendekatan ini muncul ketika alat Anda berada di satu tempat. Ketika Text to Speech, kloning suara, dan dubbing berbagi alur kerja, brief deskriptor yang sama yang menggerakkan pratinjau dapat diteruskan langsung ke permintaan Text to Speech API — dan kemudian terus ke dubbing — alih-alih diketik ulang dan ditafsirkan ulang di setiap tahap. Tulis brief sekali. Gunakan di mana-mana.
Pertanyaan Deskriptor Suara yang Benar-Benar Ditanyakan Kreator
Apa perbedaan antara nada dan timbre dalam deskriptor suara?
Nada adalah karakter emosional dari suara — hangat, serius, jauh. Timbre adalah tekstur atau kualitas unik dari suara itu sendiri — halus, serak, sutra, kasar. WP SEO AI mencantumkan tekstur sebagai dimensi deskriptor yang terpisah dari nada emosional, dan perbedaan itu penting dalam praktik: dua suara dapat berbagi nada yang persis sama namun tetap memiliki timbre yang sama sekali berbeda. Ketika suara terasa tepat secara emosional tetapi entah bagaimana salah, timbre biasanya adalah variabel yang belum Anda namai.
Apakah deskriptor suara diterjemahkan secara akurat ketika mendub ke bahasa lain?
Tidak otomatis. Nada yang dipersepsikan dapat bergeser lintas bahasa dan budaya, jadi register yang hangat dan santai yang berfungsi dalam bahasa Inggris mungkin mendarat berbeda di pasar lain. Langkah yang andal adalah memvalidasi ulang deskriptor per bahasa target alih-alih mengasumsikan ia terbawa. Dengan tersedianya dubbing ke 33 bahasa target, membangun pemeriksaan nada per bahasa ke dalam alur kerja Anda bukanlah pekerjaan ekstra — itulah yang menjaga satu brief tetap jujur di setiap pasar tempat Anda mempublikasikan.
Berapa banyak deskriptor yang harus saya gunakan saat memprompt suara AI atau alat kloning?
Targetkan empat dimensi inti ditambah demografi — kira-kira 5–7 deskriptor bertumpuk. WP SEO AI menunjukkan bahwa deskriptor bertumpuk mengungguli label tunggal, dan alur Voices.com mengonfirmasi karakter ditambah nada ditambah kata kunci sebagai minimum yang berfungsi. Tetap dalam rentang itu. Kurang dari lima dan Anda kembali ke istilah serbaguna yang samar; lebih dari tujuh dan Anda mulai berisiko kontradiksi yang saling membatalkan.
Bisakah saya mendeskripsikan suara dengan merujuk pada suara yang dikenal atau selebriti alih-alih menggunakan deskriptor?
Suara referensi adalah penambat yang berguna — itulah sebabnya "suara referensi" adalah kolom opsional dalam template briefing. Tetapi ia tidak menggantikan deskriptor. Referensi memberi tahu alat atau manusia kira-kira di mana harus memulai; nada, pitch, tempo, dan gaya memberi tahu mereka di mana harus mendarat. Memadukan referensi dengan deskriptor eksplisit memberikan hasil yang paling andal, karena deskriptor menyelesaikan ambiguitas yang ditinggalkan referensi terbuka.