
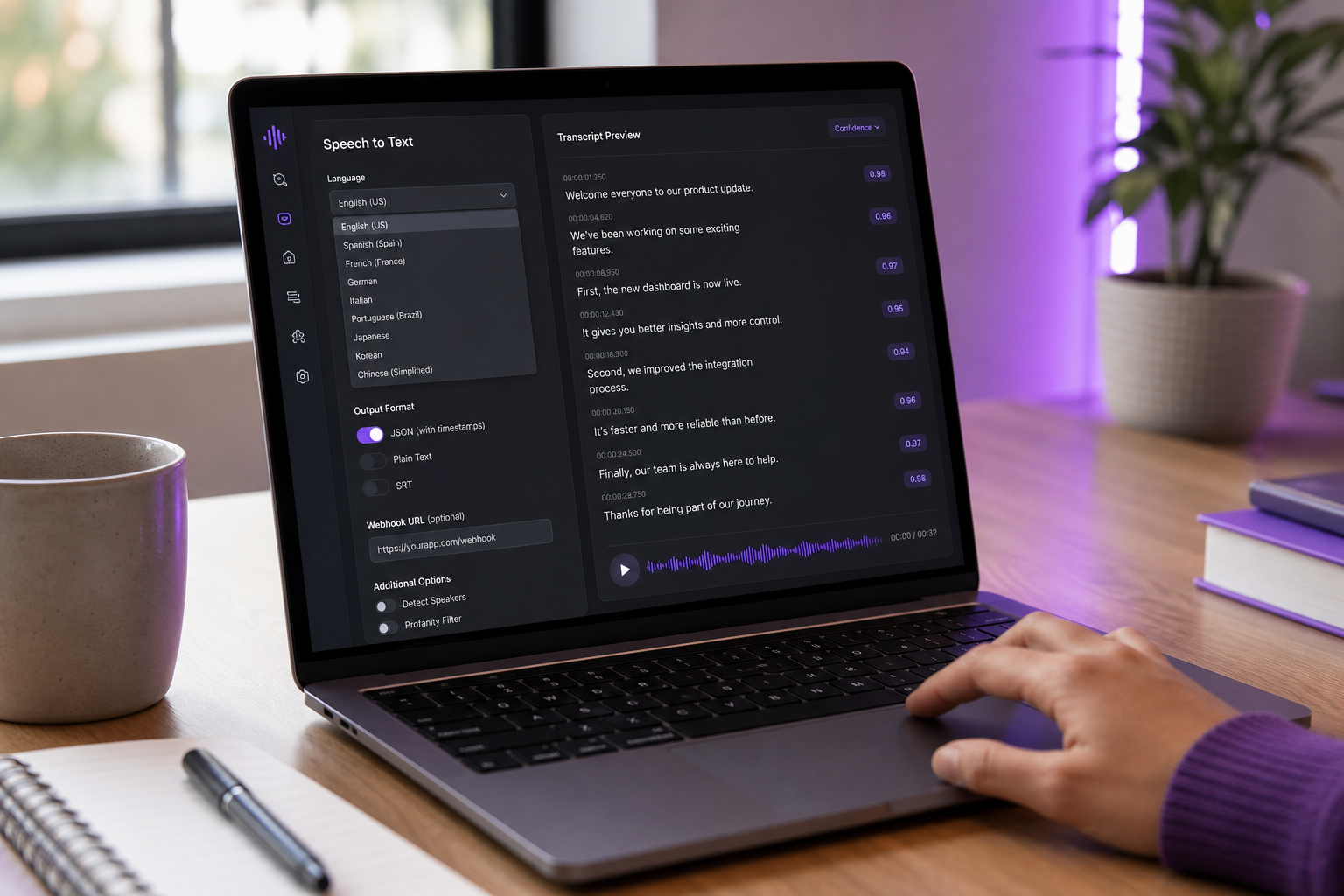
API Ucapan ke Teks: Cara Memilih yang Tepat di 2025
Anda telah membangun aplikasi yang pengguna cintai — tetapi permintaan fitur terus berdatangan: "Bisakah saya berbicara daripada mengetik?" Jadi Anda mulai mengevaluasi API ucapan ke teks. Dalam satu jam pertama, Anda telah menemui setidaknya empat model penetapan harga yang saling bertentangan, klaim akurasi yang berkisar dari "95%" hingga "99%+" tanpa definisi bersama tentang apa yang diukur, dan kualitas SDK yang berkisar dari drop-in-tiga-baris hingga habiskan-seminggu-membaca-dokumentasi-buruk.
Taruhannya nyata di kedua ujung. Pilih salah pada skala dan Anda akan kehilangan $3.000–$8.000/bulan pada pengurasan streaming, atau Anda akan meluncurkan fitur suara yang salah pada 1 dari 5 pengucapan. Menurut Koenecke et al. dalam PNAS (2020), tingkat kesalahan pada lima sistem pengenalan suara komersial utama mencapai 35% untuk penutur Bahasa Inggris Vernakular Afrika Amerika vs. 19% untuk penutur kulit putih — celah yang mengubah "masalah akurasi" menjadi masalah "30%-pengguna-tidak-bisa-menggunakan-produk-Anda".
Panduan ini memberi Anda kerangka kerja keputusan, metode perhitungan harga, protokol pilot, dan perbandingan kepala-ke-kepala dari enam penyedia — termasuk bagaimana model berbasis kredit cocok dengan build yang memiliki beban kerja variabel.

Daftar Isi
- Lima Sumbu Keputusan Yang Benar-Benar Mendorong Pilihan API Ucapan ke Teks
- Akurasi Dalam Konteks — Mengapa "Benchmark 99%" Berbohong Tentang Audio Produksi Anda
- Latensi, Streaming, dan Pengganda Biaya Real-Time
- Model Biaya Dijelaskan — Per-Menit vs. Serentak vs. Kumpulan Kredit
- Realitas Integrasi — Audit SDK & API 9 Pertanyaan
- Snapshot Penyedia Kepala-ke-Kepala — Kapan Memilih Setiap API Ucapan ke Teks
- Daftar Periksa Pemilihan API Ucapan ke Teks Anda
Lima Sumbu Keputusan Yang Benar-Benar Mendorong Pilihan API Ucapan ke Teks
Sebagian besar posting perbandingan mencantumkan 30+ fitur dan menyebutnya penelitian. Tolak itu. Hanya enam sumbu yang menentukan apakah API ucapan ke teks akan berfungsi untuk build spesifik Anda — dan pada proyek apa pun, hanya dua atau tiga yang benar-benar penting.
Akurasi di domain Anda. Aplikasi perekam medis yang menggunakan API tujuan umum akan salah merender "metoprolol" sebagai "meta peral". Tingkat Kesalahan Kata Agregat menyembunyikan jenis kegagalan ini. Seperti yang diargumentasikan Dan Jurafsky dalam Speech and Language Processing, WER memperlakukan semua kesalahan secara sama — tetapi dalam konteks klinis atau hukum, satu nama obat yang salah atau satu negasi yang terlewat memiliki dampak yang besar. Yang penting adalah WER khusus domain pada audio Anda, bukan headline benchmark.
Profil latensi. Alat aksesibilitas live-captioning membutuhkan respons end-to-end di bawah 1 detik. Pipeline transkrip podcast dapat menunggu 10 menit. Menurut "Waktu Respons: Tiga Batas Penting" Nielsen Norman Group, respons di bawah 100 ms terasa instan, di bawah 1 detik mempertahankan aliran, dan lebih dari 10 detik menyebabkan pengabaian tugas. Petakan kasus penggunaan Anda ke tingkat sebelum berbelanja.
Kemampuan offline / di perangkat. Aplikasi penelitian lapangan di daerah terpencil tidak dapat bergantung pada round-trip cloud. API SpeechAnalyzer Apple (WWDC 2025) adalah opsi di-perangkat tingkat platform untuk iOS/macOS. Whisper atau Vosk yang self-hosted memberikan Anda kontrol offline penuh jika Anda bersedia mengelola GPU.
Cakupan bahasa dan code-switching. Whisper mendukung 50+ bahasa dengan kualitas sebanding setelah pelatihan pada 680.000 jam audio multibahasa (Radford et al., OpenAI 2022). Google dan AWS menggunakan kelompok bahasa bertingkat di mana bahasa Tier B mendapat akurasi lebih rendah dan terkadang penetapan harga terpisah.
Arsitektur model biaya. Bayar per menit, koneksi serentak, dan kumpulan kredit masing-masing rusak berbeda pada skala. YouTuber yang mengunggah 4 jam satu minggu dan 40 jam minggu berikutnya dihukum oleh penagihan per menit di minggu lambat dan minggu lonjakan. Kumpulan kredit dengan rollover menyerap varians itu.
Area permukaan integrasi. Kualitas SDK, webhook vs. polling, default penanganan kesalahan. Di sinilah "API mudah" berubah menjadi tiga minggu yang hilang.
Lima sumbu mendorong setiap keputusan API ucapan ke teks yang layak dibuat — dan hanya dua atau tiga yang berlaku untuk build Anda.
| Sumbu Keputusan | Mengapa Penting | Jebakan Umum | Kasus Penggunaan Terbaik |
|---|---|---|---|
| Akurasi domain | Klaim "99%" vendor menggunakan pidato bersih yang dibaca | Mempercayai LibriSpeech untuk audio mobile yang bising | Aplikasi medis, hukum, keuangan |
| Profil latensi | Streaming biaya 3–5x batch | Membeli streaming untuk kasus toleran batch | Keterangan langsung vs. unggahan podcast |
| Kemampuan offline | Privasi + lingkungan terbatas konektivitas | Mengasumsikan Web Speech API adalah offline | Aplikasi lapangan kesehatan, mobile-first |
| Cakupan bahasa | Bahasa Tier B = akurasi lebih rendah | Deteksi otomatis pada audio multibahasa | SaaS multibahasa, konten global |
| Model biaya | Per-menit terlihat murah sampai streaming dimulai | Mengabaikan penyimpanan, egress, biaya retry | Alur kerja kreator dengan volume variabel |
| Permukaan integrasi | SDK buruk menghabiskan minggu dev | "Sederhana di dokumentasi" ≠ pengiriman mudah | Semua pembangun |
Tabel ini adalah filter, bukan putusan. Pembuat YouTube yang mengunggah 10 pekerjaan batch per minggu peduli tentang model biaya dan cakupan bahasa. Aplikasi kesehatan peduli tentang akurasi dan kemampuan offline. Alat pertemuan real-time peduli tentang latensi dan permukaan integrasi.
Sebelum membaca lebih lanjut, lingkari dua atau tiga sumbu yang paling penting untuk build spesifik Anda. Bagian biaya (perbedaan $ ribuan) dan snapshot penyedia di akhir akan terlihat sangat berbeda tergantung pada sumbu mana yang Anda prioritaskan. Mencoba mengoptimalkan semua enam dalam satu keputusan akan membawa Anda, setiap kali, ke penyedia paling mahal dengan fitur yang tidak akan pernah Anda gunakan.
Akurasi Dalam Konteks — Mengapa "Benchmark 99%" Berbohong Tentang Audio Produksi Anda
Setiap vendor API ucapan ke teks menerbitkan angka akurasi. Hampir tidak ada yang memprediksi bagaimana API akan melakukan pada audio produksi Anda. Inilah mengapa, dan cara menguji apa yang benar-benar penting.
Audio benchmark bersih; audio produksi tidak. Benchmark publik seperti LibriSpeech terdiri dari pidato buku audio yang dibaca — pembicara tunggal, aksen netral, rekaman bersih. Model besar Whisper melaporkan sekitar 4,7% WER pada tes-bersih LibriSpeech dan kira-kira 8–9% WER pada tes-lainnya, rangkaian yang lebih menantang (Radford et al., OpenAI 2022). Celah pada audio produksi nyata — bising, beraksen, pembicara yang tumpang tindih — lebih lebar lagi. Jika vendor mengutip WER tanpa menentukan dataset dan kondisi rekaman, perlakukan angka sebagai copy marketing, bukan data teknik.
WER adalah metrik yang salah untuk banyak aplikasi. Definisi standar dari panduan Evaluasi ASR NIST adalah (Substitusi + Penghapusan + Penyisipan) / kata Referensi. Ini memperlakukan setiap kata sebagai sama pentingnya. Tetapi salah merender nama obat pasien, angka keuangan, atau nama saksi pengadilan memiliki konsekuensi yang tidak dimiliki oleh penurunan kata pengisi. Argumen Jurafsky: evaluasi dengan metrik khusus tugas — akurasi pengisian slot untuk asisten suara, penarikan istilah penting untuk penggunaan medis dan hukum, akurasi entitas bernama untuk jurnalisme. WER agregat mungkin 7%; WER istilah penting mungkin 22%. Hanya satu dari angka-angka itu yang penting bagi pengguna Anda.
Kinerja aksen dan dialek bervariasi secara dramatis. Studi PNAS yang dikutip di atas menguji lima sistem komersial utama dan menemukan WER untuk penutur Bahasa Inggris Vernakular Afrika Amerika rata-rata 0,35 vs. 0,19 untuk penutur kulit putih — kira-kira dua kali lebih buruk. Ini bukan catatan keadilan. Ini adalah risiko bisnis: aplikasi yang gagal untuk sepertiga dari basis pengguna potensial karena hanya diproduksi QA pada American English netral sedang mengirim rusak. Perbaikannya bukan memilih vendor yang berbeda (sebagian besar memiliki celah yang sama). Perbaikannya adalah menguji pada audio yang mewakili pengguna aktual Anda sebelum Anda menandatangani apa pun.
Klaim akurasi 99% pada benchmark tidak memberi tahu Anda apa pun tentang bagaimana API menangani pengguna Anda — yang penting adalah kinerja pada audio Anda, aksen Anda, dan kosakata domain Anda.
Akurasi streaming lebih buruk daripada akurasi batch. Sistem streaming memancarkan kata-kata sementara ("sebagian") yang ditulis ulang saat lebih banyak audio tiba. Sistem batch menunggu seluruh ujaran dan menyempurnakan. Streaming WER biasanya 5–15% lebih buruk daripada batch untuk konten yang sama pada mesin yang sama. Celah ini hampir tidak pernah diungkapkan dalam pemasaran vendor. Jika Anda membangun produk transkrip langsung, faktorkan itu.
Code-switching menghancurkan sebagian besar API. Code-switching berarti pergantian bahasa di tengah ujaran: Spanglish, Hinglish, Tagalog-Inggris. Whisper menanganinya lebih baik daripada kebanyakan karena dilatih pada 680.000 jam audio multibahasa (Radford et al., 2022). Sebagian besar API cloud memerlukan Anda mendeklarasikan bahasa di muka dan menurun keras ketika pembicara beralih di tengah kalimat. Jika pengguna Anda berbicara lebih dari satu bahasa dalam sesi yang sama, uji kasus ini secara eksplisit. Untuk alur kerja multibahasa yang juga memerlukan lokalisasi hilir, platform dengan AI Dubbing bawaan di 33 bahasa dapat mengalihkan transkrips, terjemahan, dan dubbing menjadi satu pipeline.
Protokol Pilot 7 Hari
Daripada mempercayai klaim akurasi vendor, jalankan bukti konsep satu minggu.
- Hari 1–2: Kumpulkan 30 menit audio gaya produksi nyata. Sertakan kasus terburuk Anda: lingkungan bising, pembicara beraksen, jargon domain, pidato yang tumpang tindih.
- Hari 3–4: Transkripsikan dengan 3 API kandidat. Koreksi secara manual satu versi untuk digunakan sebagai transkrips referensi Anda.
- Hari 5: Ukur WER secara keseluruhan, kemudian uraikan berdasarkan pembicara, aksen, dan penarikan istilah domain.
- Hari 6: Uji streaming vs. batch pada file yang sama. Ukur delta akurasi.
- Hari 7: Dokumentasikan biaya yang terjadi dan gesekan integrasi — kompleksitas auth, masalah SDK, kualitas respons kesalahan.
Satu insinyur yang menulis di ITNEXT melaporkan bahwa setelah menyetel pengaturan mikrofon dan kosakata khusus, ucapan ke teks modern menghasilkan lebih sedikit kesalahan daripada pengetikan mereka sendiri untuk penulisan teknis. Pengambilan itu bukan bahwa API apa pun adalah keajaiban. Itu pilihan API penting, tetapi pipeline audio di sekitar API penting setidaknya sama besarnya. API hebat pada audio buruk kalah dari API layak pada audio yang disesuaikan.
Latensi, Streaming, dan Pengganda Biaya Real-Time
Latensi adalah sumbu di mana insinyur paling sering overspend. Transkrips real-time terasa ajaib dalam demo dan biaya 3–5x lebih dari batch dalam produksi. Putuskan apa yang pengguna Anda benar-benar butuhkan sebelum mendaftar untuk infrastruktur streaming.
- Latensi streaming sinkron (keterangan langsung, asisten suara). Target di bawah 1 detik end-to-end untuk keterangan aksesibilitas, round-trip 300–800 ms untuk chatbot suara agar terasa percakapan. Di atas 2 detik dan ilusi real-time pecah. Ambang batas ini memetakan ke penelitian UX yang ditetapkan tentang persepsi waktu respons (Nielsen Norman Group). API streaming mencapainya melalui koneksi WebSocket persisten yang memancarkan hasil interim saat audio tiba.
- Latensi batch asinkron (unggahan podcast, review panggilan dukungan, subtitle YouTube). Menit hingga jam waktu pemrosesan dapat diterima. Batch kira-kira 3–5x lebih murah per menit audio daripada streaming pada penyedia yang sama, karena infrastruktur tidak menahan koneksi terbuka (Google Cloud dan dokumentasi penetapan harga AWS Transcribe). Untuk alur kerja kreator yang mengunggah konten yang direkam, batch hampir selalu benar.
- Hybrid / near-real-time (penyusunan langsung dengan koreksi tertunda). Beberapa alur kerja menerima latensi 2–5 detik sebagai imbalan akurasi lebih tinggi dan biaya lebih rendah. Alat transkrip pertemuan mungkin menampilkan teks kasar dalam 3 detik dan menyempurnakannya dalam 30. Pola ini menggunakan streaming untuk tampilan langsung dan pemrosesan ulang batch untuk transkrips yang disimpan — sering kali melalui callback webhook daripada polling. Platform yang dibangun khusus untuk alur kerja media, seperti AI Dubbing API DubSmart, menggunakan callback webhook untuk pekerjaan yang selesai daripada memaksa backend Anda untuk polling status (Thread komunitas Make.com tentang integrasi webhook AudioPen).
- Faktor Real-Time (RTF) — metrik insinyur. Sistem produksi menargetkan RTF < 1,0 untuk penggunaan interaktif: pemrosesan 1 detik audio dalam waktu dinding kurang dari 1 detik. Deployment Whisper GPU-akselerasi atau di-perangkat mencapai kira-kira RTF 0,5–0,9 untuk model medium pada GPU konsumen. Jika pengaturan self-hosted Anda menjalankan RTF > 1,0, streaming tidak mungkin tanpa antrean.

Segitiga latensi-biaya-akurasi tidak dapat dinegosiasikan: Anda dapat memilih dua. Streaming mengorbankan akurasi dan anggaran untuk segera. Batch mengorbankan keadaan segera untuk akurasi dan biaya. Arsitektur hibrida semakin umum tetapi menambah kompleksitas integrasi. Sebelum memilih, tanyakan satu pertanyaan: apakah pengguna saya akan benar-benar memperhatikan penundaan 5 detik? Jika jawabannya tidak, batch adalah arsitektur yang tepat dan Anda baru saja menghemat 70% dari pengeluaran API tahunan Anda.
Model Biaya Dijelaskan — Per-Menit vs. Serentak vs. Kumpulan Kredit
Ada tiga arsitektur penetapan harga di pasar API ucapan ke teks, dan membingungkan mereka adalah kesalahan pengadaan paling umum.
Bayar per menit (standar batch). Anda ditagih per menit audio yang dikirimkan, sering kali dalam kenaikan 15 detik. Sederhana untuk memproyeksikan untuk beban kerja yang dapat diprediksi. OpenAI Whisper API kira-kira $0,006/menit (halaman penetapan harga OpenAI) — sering kali 3–5x lebih murah daripada penyedia ASR cloud tradisional, yang berkumpul di sekitar $0,02–0,03/menit untuk model batch Inggris standar.
Koneksi serentak (streaming real-time). Anda membayar per aliran terbuka simultan, sering kali ditagih per koneksi-menit atau per slot serentak. Di sinilah tagihan lonjakan: jika 50 pengguna mulai streaming sekaligus, Anda membayar 50 koneksi — bukan 50 menit audio. Google Cloud dan AWS menerbitkan tarif yang berbeda dan lebih tinggi untuk sesi streaming vs. pekerjaan batch offline.
Kumpulan kredit dengan rollover (beban kerja fleksibel). Anda membeli kumpulan kredit yang mengonsumsi pada tingkat variabel tergantung pada fitur mana yang Anda gunakan (transkrips, dubbing, kloning suara, text-to-speech). Kredit yang tidak digunakan dialihkan. Model ini cocok untuk beban kerja variabel — YouTuber yang mengunggah 4 jam satu minggu dan 40 minggu berikutnya tidak dihukum untuk lonjakan atau terdampar dengan menit yang tidak digunakan. DubSmart AI menggunakan model ini, membundel transkrips dengan Voice Cloning dan Text to Speech di bawah satu saldo kredit.
Contoh yang bekerja — Pembuat YouTube:
- 10 video/minggu × 30 menit masing-masing = 300 menit/minggu audio sumber
- Transkrips batch di $0,006/menit = $1,80/minggu, atau sekitar $94/tahun
- Tambahkan demo live-captioned streaming (5 jam/bulan) pada tarif 4x batch = kira-kira $72/tahun tambahan
- Jika kreator menggandakan ke 3 bahasa, kebutuhan kredit transkrips + dub bulanan total adalah sekitar 5.000 kredit — sesuai dalam rencana kumpulan kredit tingkat menengah
Pada volume apa pun di bawah 5.000 jam per bulan, membangun tumpukan transkrips Anda sendiri lebih murah dalam fantasi daripada dalam kenyataan — tingkat API $50 dikirim dalam sehari, sementara deployment Whisper self-hosted dikirim dalam kuartal.
| Penyedia | Model Penetapan Harga | Tarif Diterbitkan | Tingkat Gratis |
|---|---|---|---|
| Google Cloud STT | Per 15-detik; surcharge streaming | Variabel; berjenjang | 60 menit/bulan |
| AWS Transcribe | Batch per-detik + SKU streaming | Variabel menurut region/model | 60 menit/bulan, 12 bulan |
| OpenAI Whisper API | Datar per-menit | ~$0,006/menit | Tidak diterbitkan |
| Rev.com (Mesin) | Per-menit | $0,25/menit | Tidak ada |
| Rev.com (Manusia) | Per-menit | $1,50/menit | Tidak ada |
| DubSmart AI | Kumpulan kredit w/ rollover | Rencana berjenjang | Tingkat gratis tersedia |
Sumber: OpenAI, Google Cloud, AWS Transcribe, halaman penetapan harga vendor Rev.com.

Tiga biaya tersembunyi hampir tidak pernah muncul di kalkulator vendor.
Penyimpanan dan egress. Jika Anda menyimpan transkrips dan audio sumber di S3 atau GCS, Anda membayar penyimpanan plus bandwidth pada pengambilan. Pada skala ini menjadi item baris non-trivial. Arsip 1 TB pada tarif standar dengan pembacaan sering dapat menambahkan ratusan dolar per bulan sebelum panggilan API apa pun terkena.
Diarization pembicara biasanya diukur secara terpisah. AWS Transcribe dan AssemblyAI keduanya menagih identifikasi pembicara sebagai item baris terpisah di atas tingkat transkrips dasar (dokumentasi AWS Transcribe; dokumen AssemblyAI). Anggaran hanya pada tingkat dasar per-menit meremehkan biaya nyata Anda sekitar 20–40% jika Anda memerlukan label pembicara.
Biaya percobaan dan kesalahan. Permintaan yang gagal masih menggunakan kuota pada beberapa penyedia. Jika pipeline audio Anda memiliki tingkat kesalahan 2% pada 100.000 menit/bulan, itu adalah 2.000 menit percobaan berbayar — kira-kira $12/bulan pada tarif Whisper, tetapi dengan mudah $60/bulan pada STT cloud tradisional.
Break-even bangun vs. beli. Pengalaman teknik dari tim di Mozilla (DeepSpeech), Descript, dan AssemblyAI menunjukkan self-hosting ASR dengan Whisper atau Kaldi hanya masuk akal pada >5.000 jam/bulan dengan tenaga kerja ML dan DevOps khusus. Di bawah volume itu, infrastruktur, pemeliharaan model, biaya GPU, dan overhead on-call melebihi tagihan API $50–$500/bulan — sering kali dengan faktor lima atau lebih.
Realitas Integrasi — Audit SDK & API 9 Pertanyaan
"Mudah diintegrasikan" adalah frasa paling kelebihan beban dalam ekonomi API. API dapat mudah dipanggil dalam permintaan curl dan mengerikan untuk dikirim dalam produksi. Sebelum menandatangani kontrak, jalankan setiap kandidat melalui sembilan pertanyaan ini. Jawaban buruk di sini memprediksi minggu logika penanganan kesalahan dan logika percobaan khusus yang akan Anda tulis nanti.
- Apakah API mendukung streaming dan batch dalam satu SDK? Beberapa penyedia memaksa Anda memilih arsitektur di muka, kemudian menagih untuk beralih. API terbaik mengekspos keduanya melalui lapisan auth yang sama dan membiarkan Anda bermigrasi beban kerja saat perilaku pengguna berkembang. Jika kasus penggunaan awal Anda adalah batch tetapi Anda mungkin menambahkan live captioning dalam enam bulan, ini penting sekarang.
- Apa yang terjadi ketika API tidak aktif atau dibatasi kecepatan? Uji. Kirim 200 permintaan dalam 1 detik ke tingkat gratis. Apakah SDK mengantre, mengungkap 429 dengan bersih, atau menggantung? Vendor yang menerbitkan semantik SLA dan percobaan dalam bahasa biasa menghemat Anda minggu respons insiden. Vendor yang tidak akan akhirnya membangunkan Anda di jam 3 pagi.
- Bisakah Anda menentukan bahasa audio secara eksplisit, atau apakah itu deteksi otomatis? Deteksi otomatis terdengar ramah tetapi memecah pada audio multibahasa atau code-switched. Untuk build produksi, selalu tentukan bahasa dan kembalikan ke deteksi otomatis hanya ketika kepercayaan rendah. API yang tidak membiarkan Anda menetapkan bahasa secara eksplisit adalah pre-engineered untuk gagal pada kasus tepi Anda.
- Apakah mendukung diarization pembicara di luar kotak? Diarization sering kali add-on terpisah yang dibayar. AssemblyAI dan AWS Transcribe keduanya menagih secara terpisah. Periksa apakah penyedia Anda mengembalikan label pembicara tingkat segmen atau tingkat kata — perbedaannya penting untuk analitik, pencarian, dan ringkasan hilir apa pun.
- Bisakah Anda menandai atau menyensor PII (nomor kartu kredit, SSN, nama)? Sebagian besar API yang berfokus pada perusahaan (AWS Transcribe, AssemblyAI) mendukung penyensoran PII. Whisper dan Web Speech API tidak. Untuk aplikasi kesehatan atau keuangan, ini bukan nice-to-have.
- Callback webhook atau polling untuk pekerjaan async? Webhook adalah standar modern. Polling menghasilkan panggilan API yang tidak perlu dan biaya. Platform matang memancarkan peristiwa webhook pada penyelesaian pekerjaan — pola yang ditunjukkan dalam thread komunitas Make.com tentang integrasi AudioPen di mana penyelesaian transkrips memicu otomasi hilir.
- Apa batas ukuran file dan durasi maksimal per permintaan? Banyak API cloud menutup permintaan individual pada 15 menit atau kira-kira 1 jam dengan batas ukuran file dalam puluhan hingga ratusan MB (dokumentasi Google Cloud Speech-to-Text; dokumentasi AWS Transcribe). Audio panjang — podcast dua jam, deposisi, rekaman konferensi — harus dipotong. Gateway HTTP sering kali memberlakukan batas waktu 15 menit secara independen dari batas API itu sendiri.
- Apakah skor kepercayaan diekspos pada tingkat kata? Kepercayaan tingkat kata memungkinkan Anda menandai wilayah kepercayaan rendah untuk tinjauan manusia atau koreksi interaktif. API yang mengembalikan teks mentah tanpa kepercayaan memaksa Anda untuk mempercayai semuanya atau mentranskrips ulang. Untuk alur kerja apa pun dengan tinjauan manusia dalam loop, fitur ini adalah perbedaan antara antrian QA yang dapat digunakan dan dinding teks yang tidak dapat dibaca.
- Apa kualitas SDK dalam bahasa Anda? SDK Node.js atau Python dengan pengetikan kuat, logika percobaan, dan kelas kesalahan bersih bernilai 30% premi harga daripada API yang harus Anda raw-HTTP dalam produksi. Uji SDK sebelum Anda berkomitmen pada API. Tulis integrasi kecil. Waktu itu. SDK yang benar-benar Anda sukai bekerja akan menghemat lebih banyak jam teknik daripada tarif per-menit yang lebih murah pernah menghemat Anda dalam dolar.
Open-source vs. proprietary tetap menjadi percabangan integrasi terbesar.
Open-source (Whisper, Vosk). Biaya per-panggilan nol, kontrol penuh, berjalan offline. Anda memiliki hosting, penskalaan, penyediaan GPU, pembaruan model, observabilitas, dan insiden jam 3 pagi. Deployment realistis untuk tim 5+ dengan kemampuan ML dan DevOps.
Cloud proprietary (Google, AWS, AssemblyAI, OpenAI Whisper API, DubSmart). Anda menukar biaya per-menit untuk keandalan, SLA, versioning, dan dukungan SDK. Untuk sebagian besar tim di bawah 5.000 jam/bulan, proprietary menang pada total cost of ownership. Platform yang bundel speech to text dengan API Text to Speech dan API Voice Cloning di bawah satu SDK mengurangi area permukaan integrasi lebih lanjut — satu alur auth, satu model kesalahan, satu dashboard penagihan untuk pipeline media penuh.
Tingkat platform on-device (Apple SpeechAnalyzer, WWDC 2025). Kategori yang lebih baru. Preservasi privasi, offline-capable, tetapi akurasi dan cakupan bahasa mungkin tertinggal model cloud. Terbaik untuk aplikasi mobile-first di mana privasi adalah aset pemasaran, bukan hanya kotak centang kepatuhan.
Pertanyaan integrasi yang mengalahkan semua orang lainnya: seberapa cepat Anda dapat mengirim? API berbasis kredit yang terdokumentasi dengan baik yang bundel speech to text, voice cloning, dan dubbing di bawah satu SDK sering kali mengalahkan API STT standalone yang lebih murah setelah Anda mempertimbangkan fitur kedua dan ketiga yang akan Anda butuhkan dalam enam bulan.
Snapshot Penyedia Kepala-ke-Kepala — Kapan Memilih Setiap API Ucapan ke Teks
Ini adalah pemindaian referensi cepat, bukan tinjauan lengkap. Setiap entri mencakup kasus penggunaan terbaik, kelemahan utama, pengemudi biaya dominan, dan karakter integrasi. Sumber untuk penetapan harga dan klaim fitur adalah dokumentasi vendor per akhir 2024.
Google Cloud Speech-to-Text
- Terbaik untuk: Transkrips Inggris akurasi tinggi, tim sudah di GCP, beban kerja perusahaan dengan volume yang dapat diprediksi.
- Kelemahan: Penetapan harga streaming meningkat dengan cepat; tingkatan bahasa menciptakan ketidakkonsistenan akurasi untuk audio non-Inggris.
- Pengemudi biaya: Kenaikan per-15-detik dengan SKU streaming terpisah (lebih tinggi); tingkat gratis 60 menit/bulan.
- Integrasi: Auth GCP native melalui akun layanan. Aplikasi non-GCP menghadapi overhead IAM. SDK matang untuk semua bahasa utama.
AWS Transcribe
- Terbaik untuk: Beban kerja berat batch pada skala, tim AWS-native, pipeline konten multi-bahasa, analitik pusat panggilan.
- Kelemahan: Latensi streaming sedikit lebih tinggi daripada pesaing spesialis streaming. Diarization dan model medis dihargai secara terpisah.
- Pengemudi biaya: Durasi audio dalam detik, dengan SKU terpisah untuk streaming, medis, dan add-on analitik panggilan.
- Integrasi: IAM-berat. Mudah jika Anda sudah AWS-native. Terdokumentasi dengan baik tetapi verbose.
OpenAI Whisper API
- Terbaik untuk: Build yang sadar anggaran, konten multibahasa dengan code-switching, tim yang menginginkan tanpa penguncian vendor di luar OpenAI itu sendiri.
- Kelemahan: Tidak ada dukungan streaming native. Tidak ada diskon volume. Tidak ada komitmen SLA yang sebanding dengan AWS atau GCP.
- Pengemudi biaya: Flat $0,006/menit tanpa biaya koneksi serentak dan tidak ada diskon volume terpisah yang diterbitkan.
- Integrasi: API HTTP paling sederhana di pasar. Multibahasa tanpa deklarasi bahasa berkat 680.000 jam data pelatihan yang terdokumentasi dalam makalah Whisper.
AssemblyAI
- Terbaik untuk: Tim yang berpusat pada pengembang, streaming real-time dengan latensi minimal, output terstruktur dengan timestamps tingkat kata, label pembicara, dan skor kepercayaan.
- Kelemahan: Penetapan harga premium. Kepadatan fitur berlebihan untuk kasus penggunaan batch sederhana.
- Pengemudi biaya: Koneksi streaming serentak ditambah item baris diarization.
- Integrasi: SDK yang sangat baik dan dokumentasi. Arsitektur webhook-first. Alat observabilitas yang kuat.
Rev.com (Mesin + Hibrid Manusia)
- Terbaik untuk: Alur kerja di mana akurasi tidak dapat dinegosiasikan dan waktu tunggu dapat menunggu jam — deposisi hukum, jurnalisme, konten penting aksesibilitas.
- Kelemahan: Bukan real-time. Tinjauan manusia memerlukan jam. Mahal pada skala.
- Pengemudi biaya: $0,25/menit untuk mesin, $1,50/menit untuk human-reviewed.
- Integrasi: REST API sederhana. Gesekan adalah waktu tunggu, bukan integrasi itu sendiri.
DubSmart AI API Ucapan ke Teks
- Terbaik untuk: Pembuat konten dan tim yang membangun alur kerja multibahasa di mana transkrips adalah satu langkah dalam pipeline yang lebih panjang — transkrips, terjemah, dub, publikasi. Penetapan harga berbasis kredit menyerap beban kerja variabel.
- Kelemahan: Platform lebih muda daripada hyperscaler warisan. Syarat SLA perusahaan mungkin tidak cocok dengan AWS atau GCP untuk tim pengadaan yang averse risiko.
- Pengemudi biaya: Kumpulan kredit dengan rollover. Bundel transkrips dengan kloning suara dari sampel 20 detik, 300+ suara TTS, dan AI Dubbing di 60+ bahasa sumber ke 33 bahasa target.
- Integrasi: Dibangun untuk alur kerja media. SDK tunggal mencakup transkrips + TTS + kloning + dubbing. Callback webhook untuk pekerjaan async. Dipercaya oleh 500.000+ pengguna.
Daftar Periksa Pemilihan API Ucapan ke Teks Anda
Ini adalah alur kerja untuk dijalankan sebelum menandatangani kontrak apa pun. Ini mengompresi semuanya di atas menjadi delapan langkah yang dapat dieksekusi. Blok empat jam untuk pass pertama; harapkan seminggu pengujian pilot di langkah 4.
- Tentukan kasus penggunaan dominan Anda dalam satu kalimat. Tuliskan: "Saya perlu mentranskripsikan podcast" atau "keterangan live stream" atau "analisis panggilan penjualan" atau "dub video yang diunggah pengguna." Jika Anda tidak dapat menulisnya dalam satu kalimat, Anda memiliki dua produk dan memerlukan dua evaluasi. Cocokkan kasus penggunaan dengan tingkat latensi dari Bagian 3 dan permintaan akurasi dari Bagian 2 sebelum Anda melihat penetapan harga vendor apa pun.
- Lingkari dua atau tiga sumbu keputusan yang paling penting. Dari kerangka kerja: akurasi, latensi, offline, cakupan bahasa, model biaya, permukaan integrasi. Jika Anda mencoba mengoptimalkan semua enam, Anda akan memilih penyedia paling mahal dengan fitur yang tidak akan pernah Anda gunakan. Sebagian besar pembangun harus memberi peringkat model biaya dan permukaan integrasi terlebih dahulu. Akurasi dan latensi menjadi tiebreaker antara finalis.
- Proyeksikan volume 12 bulan dengan buffer lonjakan 3x. Estimasi menit bulanan untuk bulan 1, bulan 6, dan bulan 12. Kalikan angka bulan 12 dengan 3 untuk menangani lonjakan peluncuran dan pertumbuhan viral. Angka ini menentukan apakah Anda memerlukan kumpulan kredit, penetapan harga per-menit, atau kontrak perusahaan dengan diskon volume — dan ini adalah angka yang akan Anda kutipkan vendor selama negosiasi.
- Jalankan pilot 7 hari. Tiga puluh menit audio nyata Anda, tiga API kandidat, skor manual terhadap transkrips referensi yang dikoreksi manusia tunggal. Ukur WER menurut pembicara, menurut aksen, dan menurut istilah domain — bukan hanya agregat. Uji streaming vs. batch pada file yang sama. Dokumentasikan gesekan SDK dalam dokumen bersama saat Anda pergi, saat rasa sakitnya masih segar.
- Stress-test penanganan kesalahan. Kirim audio yang salah bentuk, token yang kedaluwarsa, semburan pembatas kecepatan-busting, dan file berukuran berlebihan. Apakah SDK gagal dengan bersih dengan kesalahan yang dapat ditindaklanjuti, atau apakah itu menggantung? API yang gagal buruk di bawah stres terkontrol akan gagal buruk dalam produksi di jam 3 pagi, dan biaya pembersihan akan mengerdilkan penghematan per-menit apa pun yang Anda kunci di penandatanganan.
- Hitung total biaya kepemilikan nyata. Sertakan biaya per-menit dasar, surcharge streaming, item baris diarization, penyimpanan, egress, overhead percobaan, dan jam teknik yang disimpan atau hilang oleh kualitas SDK. Bandingkan dengan model berbasis kredit jika beban kerja Anda variabel — rencana kredit kira-kira $99/bulan sering mengalahkan penetapan harga $0,006/menit ketika lalu lintas berlonjak dan bundel fitur media berganda di bawah satu tagihan.
- Audit default privasi dan retensi data. Konfirmasi apakah penyedia menahan audio dan transkrips untuk perbaikan model, dan apakah Anda dapat memilih keluar secara kontraktual. Persyaratan GDPR, HIPAA, dan SOC 2 dapat menghilangkan penyedia terlepas dari harga. Menurut panduan Dewan Perlindungan Data Eropa tentang asisten suara, penyedia STT cloud dapat membuat "dataset bayangan" data suara kecuali secara eksplisit dibatasi dalam kontrak — ini adalah pertanyaan pengadaan, bukan pertanyaan fitur.
- Negosiasikan sebelum Anda berkomitmen. Sebagian besar penyedia menawarkan diskon 15–30% pada komitmen 12 bulan di atas 500 jam/bulan. Jika Anda telah menyelesaikan langkah 1–7 dengan percaya diri, Anda memiliki leverage. Minta penetapan harga terkunci, kontak dukungan khusus, tingkat gratis yang diperluas untuk lingkungan staging, dan klausa keluar jika akurasi menurun di bawah ambang batas yang disepakati. Jika roadmap Anda mencakup lokalisasi, evaluasi API seperti API AI Dubbing yang menerjemahkan dan menggandakan dalam satu panggilan.
Daftar periksa ini adalah pertahanan Anda terhadap pemasaran vendor dan serangan Anda terhadap penundaan pengiriman. Tim yang mengirim fitur suara dengan cepat bukan yang memilih API termurah — mereka yang menjalankan pilot nyata, menghitung TCO nyata, dan memilih permukaan integrasi yang ingin dikerjakan pengembang mereka. Jika build Anda juga melibatkan dubbing, kloning suara, atau menghasilkan pidato sintetis, evaluasi platform yang menggabungkan Text to Speech, kloning suara, dan dubbing di bawah satu saldo kredit dan satu SDK — fitur kedua dan ketiga yang Anda butuhkan dalam enam bulan akan menelan biaya lebih sedikit dan pengiriman lebih cepat.