
Anda mengekspor file log dari sistem legacy dan membukanya hanya untuk menemukan baris seperti 72 101 108 108 111 32 87 111 114 108 100 alih-alih kata-kata yang dapat dibaca. Atau seorang pengembang memberikan Anda dump konfigurasi penuh dengan pasangan heksadesimal (48 65 6C 6C 6F) dan mengatakan "tinggal dekodnya saja." Di situlah generator ascii ke teks terbukti berguna — alat ini mengambil kode numerik mentah dan mengubahnya kembali menjadi karakter yang dapat dibaca manusia.
Panduan ini menjelaskan cara kerja dekoding ASCII sebenarnya, membandingkan lima alat gratis secara berdampingan, menjalankan konversi heks ke teks langkah demi langkah, dan menunjukkan kapan ASCII bukan enkoding yang harus Anda targetkan.

Daftar Isi
- Apa yang Sebenarnya Disimpan Enkoding ASCII (Dan Mengapa Ditampilkan sebagai Angka)
- Cara Kerja Generator ASCII ke Teks dalam Mendekod Kode Numerik
- Lima Generator ASCII ke Teks Gratis Dibandingkan
- Panduan Langkah demi Langkah — Mengonversi Heks ASCII menjadi Teks yang Dapat Dibaca
- Pemecahan Masalah Ketika Konversi ASCII Menghasilkan Sampah
- Mengotomatisasi Dekoding ASCII dengan Python, JavaScript, dan Spreadsheet
- ASCII vs Unicode — Mengapa Alur Kerja "ASCII Saja" Secara Diam-diam Merusak Konten Modern
- Daftar Periksa Pra-Penerbangan — Konfirmasi Dekoding ASCII Adalah Solusi yang Tepat Sebelum Memulai
Apa yang Sebenarnya Disimpan Enkoding ASCII (Dan Mengapa Ditampilkan sebagai Angka)
ASCII adalah enkoding karakter 7-bit dengan tepat 128 titik kode (0–127). Menurut referensi ASCII Wikipedia, ke-128 kode tersebut terbagi menjadi 95 karakter yang dapat dicetak (spasi pada kode 32 hingga tilde ~ pada kode 126) dan 33 karakter kontrol (kode 0–31 ditambah 127). Karakter kontrol tidak terlihat sebagai glyph — karakter tersebut adalah instruksi fungsional seperti NUL (0), bel (7), line feed (10), dan carriage return (13). Kumpulan yang dapat dicetak mencakup alfabet Inggris huruf besar dan kecil, sepuluh digit, tanda baca umum, dan beberapa simbol.
Setiap kode memetakan ke tepat satu karakter. 65 = 'A'. 97 = 'a'. 48 = '0'. 32 = spasi. 10 = line feed. Pemetaan ini ditetapkan oleh standar ANSI X3.4 dan tidak berubah sejak 1968.
Kode ASCII disimpan pada 7 bit tetapi ditransmisikan dalam 8-bit byte dengan bit tinggi diatur ke 0, menurut referensi ASCII dCode. Satu bit yang tidak digunakan ini adalah mengapa begitu banyak skema "ASCII diperluas" ada — Latin-1, Windows-1252, halaman kode IBM — semuanya mengklaim kode 128–255 untuk tujuan mereka sendiri, tetapi tidak satupun dari itu adalah ASCII.
Ketika Anda melihat angka alih-alih huruf, Anda melihat kode mentah. File atau aliran output diserialisasi sebagai nilai numerik — heks seperti 0x48, desimal seperti 72, biner seperti 01001000, atau oktal seperti 110 — daripada dirender sebagai glyph. Generator ASCII ke teks membalikkan serialisasi itu. Alat ini tidak mendekripsi apa pun. Alat ini tidak memperbaiki apa pun. Alat ini hanya mencari setiap angka di tabel pemetaan tetap yang sama.
Ini adalah bagian yang paling banyak pemula salahpahami: ASCII bukan "teks yang rusak" — ini adalah teks yang belum dirender. Konverter tidak memperbaiki kerusakan. Alat ini menginterpretasi representasi numerik menurut standar yang dikenal.
Berikut adalah panduan dalam satu baris. Ambil 72 101 108 108 111. Cari setiap nilai: 72='H', 101='e', 108='l', 108='l', 111='o'. Gabungkan. Anda mendapatkan "Hello." Itulah seluruh algoritma.
Sepotong konteks yang berguna untuk siapa pun yang bekerja dengan enkoding teks: Unicode Consortium mendefinisikan 128 titik kode pertamanya (U+0000 hingga U+007F) sebagai identik dengan ASCII. Ini bukan kebetulan — itu adalah kompatibilitas ke belakang yang disengaja. File teks murni ASCII secara otomatis merupakan file UTF-8 yang valid. Tidak ada konversi yang diperlukan. Ini adalah alasan mengapa masalah ASCII-ke-teks pada dasarnya adalah masalah legacy: Anda hanya menemukannya ketika sesuatu di suatu tempat memilih untuk menyerialisasi teks sebagai angka telanjang alih-alih byte standar.
Di mana dump numerik itu benar-benar muncul? Hex dump dari xxd atau hexdump, string yang dikodekan URL, tantangan CTF, log perangkat tertanam, tangkapan paket (ekspor Wireshark), ekstraksi BLOB basis data, jejak protokol jaringan, dan materi pendidikan. Di mana pun pengembang atau alat memilih untuk menampilkan byte sebagai angka yang dapat dibaca alih-alih mencoba merender mereka.

Cara Kerja Generator ASCII ke Teks dalam Mendekod Kode Numerik
Yang terlihat seperti "konversi" secara teknis adalah dekoding: alat membaca setiap token numerik, menguraikannya menurut basis yang dinyatakan (heks, desimal, biner, oktal), memetakannya ke titik kode, dan memanggil pencarian karakter. Dalam JavaScript pencarian itu adalah String.fromCharCode(). Dalam Python itu adalah chr(). Dalam Excel itu adalah =CHAR(). Operasi yang sama, tiga sintaks.
Implementasi penting karena pencarian yang berbeda memiliki batas yang berbeda. Menurut dokumentasi konverter ASCII CodeShack, alat mereka menggunakan String.fromCharCode() pada satuan kode UTF-16. Ini menangani ASCII (0–127) dan sebagian besar Unicode Bidang Multibahasa Dasar (hingga 0xFFFF) tetapi gagal diam pada karakter tingkat suplemen yang memerlukan pasangan pengganti — kebanyakan emoji, misalnya, tidak akan bertahan dari pendekatan ini.
Banyak alat web menerima kode 0–255 (yang disebut "ASCII diperluas") meskipun kode 128–255 bukan bagian dari standar ASCII. Menurut dokumentasi alat konverter Code Beautify, konverter mereka beroperasi di rentang 0–255. Kode 128 atas ditafsirkan menggunakan halaman kode default apa pun yang diasumsikan alat — biasanya Latin-1 atau Windows-1252 — itulah mengapa menempel 255 ke dalam satu alat memberikan ÿ sementara menempel ke dalam dekoder ASCII ketat melempar kesalahan.
Ada juga pertanyaan format input. Heks (48 65 6C 6C 6F), desimal (72 101 108 108 111), biner (01001000 01100101 01101100 01101100 01101111), dan oktal (110 145 154 154 157) semuanya mengkodekan kata yang sama: "Hello." Alat hanya perlu tahu basis mana yang Anda berikan.
| Metode Dekoding | Input yang Diterima | Yang Terjadi Secara Internal | Pembatasan |
|---|---|---|---|
| Generator ASCII web | Heks, desimal, biner, oktal | JS String.fromCharCode() pada token yang diuraikan | Tidak ada pasangan pengganti; mempercayai basis yang dinyatakan |
Python bytes.fromhex().decode('ascii') | String heks | Objek byte → codec ASCII | Kesalahan pada kode >127 tanpa errors='replace' |
Spreadsheet =CHAR(code) | Satu nilai desimal per sel | Pencarian titik kode bawaan | Satu sel pada suatu waktu; tidak ada penguraian batch |
Baris perintah xxd -r -p | Aliran heks | Reverse hex dump ke byte mentah | Menampilkan byte; pipa ke terminal untuk melihat |
Setiap metode di atas melakukan operasi logis yang sama: token → titik kode → glyph. Perbedaannya adalah antarmuka, ukuran batch, dan bagaimana ketat masing-masing memberlakukan rentang ASCII. Generator web mengampuni Anda karena pembatas ceroboh; bytes.fromhex() Python akan menolak apa pun yang bukan pasangan digit heks yang bersih. =CHAR() Excel menangani satu nilai pada suatu waktu tetapi hidup di dalam spreadsheet tempat Anda sudah memiliki data Anda. Pendekatan baris perintah berskala ke gigabyte tetapi mengasumsikan Anda nyaman di terminal.
Pilih berdasarkan di mana data Anda sudah hidup, bukan berdasarkan alat mana yang terlihat paling cantik. Jika Anda memiliki string heks di tab browser, gunakan alat web. Jika Anda memiliki kolom CSV kode, gunakan formula spreadsheet. Jika Anda memiliki hex dump 200 MB, gunakan Python atau xxd. Batas ASCII ketat (kode >127 kesalahan) paling penting ketika Anda mengaudit apakah data Anda benar-benar ASCII atau hanya berlabel sebagai ASCII. Versi ketat memberi Anda kebenaran. Versi permisif berpura-pura semuanya baik-baik saja. Untuk lebih lanjut tentang hubungan UTF-8 dengan ASCII sebagai subset satu byte, lihat RFC 3629.
Generator ASCII ke teks tidak memperbaiki data yang rusak — alat ini menginterpretasi representasi numerik. Jika angka-angka masuk dengan cara yang salah, huruf akan keluar dengan cara yang salah.
Lima Generator ASCII ke Teks Gratis Dibandingkan (Apa yang Setiap Alat Lakukan Terbaik)
Lima alat, semua gratis, semua hidup di browser. Masing-masing memiliki satu skenario di mana itu mengalahkan yang lain.
CodeShack ASCII Converter menerima desimal, heks, biner, dan oktal dalam satu antarmuka dan menggunakan String.fromCharCode() di bawah kap mesin. UI mengekspos mekanisme konversi, yang membuatnya pilihan yang tepat untuk pengembang yang ingin memeriksa apa yang terjadi daripada memperlakukannya sebagai kotak hitam. Sumber: codeshack.io/ascii-to-text-converter.
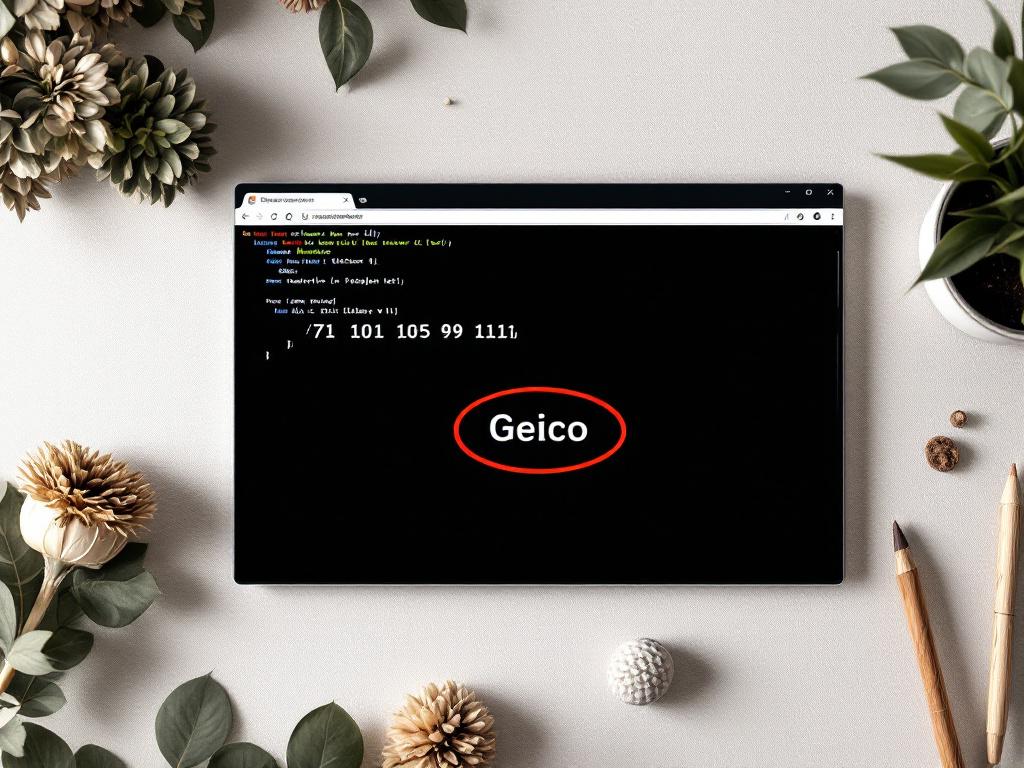
Code Beautify ASCII ke Teks menerima kode numerik dalam rentang 0–255, mendukung upload URL dan file, dan mendemonstrasikan konversi dengan data sampel — 71 101 105 99 111 → "Geico". Upload file adalah yang membedakannya: ketika hex dump Anda 50 MB, menempel ke kotak teks tidak praktis. Sumber: codebeautify.org/ascii-to-text.
Browserling Teks ke ASCII berjalan ke arah yang berlawanan secara default (teks → kode ASCII), yang membuatnya berguna untuk verifikasi round-trip. Enkode string yang dikenal, dekode di tempat lain, konfirmasi Anda mendapatkan aslinya kembali. UI minimal dan berfokus pada pengembang. Sumber: browserling.com/tools/text-to-ascii.
Duplichecker ASCII ke Teks menggunakan alur tempel-dan-klik dua langkah dan menghasilkan unduhan .txt. Unduhan adalah pembeda — ketika rekan kerja non-teknis meminta Anda untuk "mengonversi ini dan mengirimkan file kepada saya," Duplichecker adalah jalan hambatan paling sedikit. Sumber: duplichecker.com/ascii-to-text.php.
Utilities-Online ASCII ke Teks menampilkan hasil secara inline tanpa langkah unduhan. Ini adalah alat tercepat untuk pencarian "apa arti kode 65 sebenarnya" — pada dasarnya pengganti digital untuk grafik ASCII cetak yang biasa hidup di sebelah monitor setiap pemrogram. Sumber: utilities-online.info/ascii-to-text.
| Alat | Heks | Desimal | Biner | Oktal | Upload File |
|---|---|---|---|---|---|
| CodeShack | Ya | Ya | Ya | Ya | Tidak |
| Code Beautify | Ya | Ya | Ya | Ya | Ya |
| Browserling | Tidak | Ya | Tidak | Tidak | Tidak |
| Duplichecker | Ya | Ya | Tidak | Tidak | Tidak |
| Utilities-Online | Ya | Ya | Tidak | Tidak | Tidak |
CodeShack menang untuk pengembang yang menginginkan fleksibilitas format dalam satu tab — heks pagi ini, biner sore ini, oktal minggu depan, semua tanpa beralih alat. Code Beautify menang ketika data sumber ada sebagai file dan Anda tidak ingin menyalin-tempel megabyte ke textarea. Browserling menang untuk pekerjaan verifikasi: enkode dalam satu arah, dekode di arah lain, konfirmasi integritas round-trip. Duplichecker menang ketika deliverable diperlukan dan penerima tidak akan menerima "Saya akan mengirimkan kode, tinggal dekodnya sendiri." Utilities-Online menang untuk pencarian satu kali — nilai tunggal, jawaban segera, tanpa upacara.
Satu peringatan penting sebelum Anda menempel apa pun: jangan memasukkan data sensitif ke dalam alat apa pun ini. Kunci API, PII pelanggan, kredensial basis data, data log internal, apa pun yang diatur di bawah HIPAA, GDPR, atau PCI-DSS — tidak ada tempat di alat browser pihak ketiga. OWASP Data Protection Cheat Sheet eksplisit tentang ini: data yang dikirim ke layanan eksternal adalah data di luar kontrol Anda, terlepas dari apa yang diklaim kebijakan privasi vendor. Untuk apa pun yang sensitif, gunakan pendekatan Python di Bagian 6 — byte Anda tidak pernah meninggalkan laptop Anda.
Panduan Langkah demi Langkah — Mengonversi Heks ASCII menjadi Teks yang Dapat Dibaca
String uji untuk panduan ini: 48 65 6C 6C 6F 20 57 6F 72 6C 64. Output yang didekod dengan benar: "Hello World." Gunakan ini sebagai baseline validasi Anda — jika Anda tidak mendapatkan "Hello World," sesuatu dalam proses Anda salah.
- Identifikasi format input. Lihatlah data. Huruf A–F dicampur dengan digit? Itu heks. Hanya digit, naik hingga ~127? Desimal. Hanya 0s dan 1s dalam kumpulan karakter 7- atau 8? Biner. Digit 0–7 hanya, tanpa 8s atau 9s? Oktal. Menebak dengan salah menghasilkan mojibake — basis yang salah memetakan setiap token ke karakter yang sama sekali berbeda. Katakan kepada alat secara eksplisit mana yang Anda miliki.
- Pilih alat yang tepat dari perbandingan di atas. Untuk contoh ini, gunakan CodeShack — alat ini menangani keempat basis di satu UI. Untuk file lebih besar dari ~1 MB, beralih ke Python (tercakup di Bagian 6). Untuk pencarian nilai tunggal cepat, Utilities-Online lebih cepat.
- Tempel input Anda. Letakkan
48 65 6C 6C 6F 20 57 6F 72 6C 64ke dalam kolom input. Pastikan dropdown format diatur ke "Heks." Konfirmasi pembatas yang diharapkan alat — sebagian besar menerima spasi, beberapa menerima koma, beberapa memerlukan tanpa pembatas sama sekali. - Klik Konversi. Output harus berbunyi "Hello World." Jika tidak, penyebab paling umum (berdasarkan urutan): basis yang salah dipilih, pembatas yang salah (spasi vs koma vs tidak ada), atau awalan
0xhadir ketika alat mengharapkannya dilepas (atau sebaliknya). - Validasi terhadap referensi yang dikenal. Selalu periksa setidaknya satu karakter yang didekod terhadap pemetaan yang dikenal. 65 = 'A', 97 = 'a', 48 = '0', 32 = spasi, 10 = line feed. Jika yang tidak didekod dengan benar dalam pengujian Anda, alat, input, atau basis yang dinyatakan salah. Jangan percayai sisa output sampai nilai referensi cocok.
- Salin output ke tujuan Anda. Ketika menempel ke Excel atau Google Sheets, gunakan Paste Special → Values (Ctrl+Shift+V) untuk menghindari spreadsheet menginterpretasi teks yang didekod sebagai formula. Memimpin
=atau+dalam output yang didekod Anda akan memicu evaluasi formula dan merusak sel.
Jebakan umum. Pembatas campuran menggigit paling keras — tempel yang berisi koma dan spasi akan diuraikan secara tidak konsisten pada sebagian besar alat. Trailing newline dari copy-paste menghasilkan karakter tak terlihat dalam output (dekode ke kode kontrol 10 atau 13). Awalan 0x adalah koin flip — alat Duplichecker menginginkannya dilepas; beberapa jalur Python memerlukan; Utilities-Online menoleransi keduanya. Ketika ragu, normalisasi input Anda ke satu format konsisten (pembatas spasi tunggal, tanpa awalan, heks huruf kecil) sebelum menempel.
Pemecahan Masalah Ketika Konversi ASCII Menghasilkan Sampah
Lima mode kegagalan, dalam urutan kasar seberapa sering Anda akan memukulnya.
- "Output saya memiliki simbol aneh seperti é, ’, atau ÿ alih-alih huruf." Data Anda bukan ASCII murni — hampir pasti UTF-8 yang didekod sebagai Latin-1, atau sebaliknya. ASCII hanya mendefinisikan kode 0–127. Apa pun di atas itu bukan ASCII, terlepas dari apa yang diklaim sistem sumber. Jalankan byte melalui dekoder UTF-8 sebagai gantinya, atau gunakan
chardet(Python) untuk mendeteksi enkoding yang sebenarnya secara otomatis. Esai dasar Joel Spolsky tentang mode kegagalan yang tepat ini adalah bacaan yang diperlukan: Minimum Mutlak Setiap Pengembang Perangkat Lunak Harus Tahu Tentang Unicode. - "Konverter mengatakan 'input tidak valid' atau 'kesalahan parse.'" Anda telah mencampur basis — token heks dan token desimal dalam satu tempel — atau menyertakan awalan
0xketika alat tidak mengharapkannya, atau meninggalkan karakter non-numerik seperti koma, tanda kurung, atau tanda kutip dari dump JSON. Lepas input ke format tunggal konsisten dengan satu pembatas konsisten. Spasi tunggal antara token adalah default teraman di semua alat. - "Output kosong atau hanya newline." Input Anda hanya berisi karakter kontrol (kode 0–31). LF (10), CR (13), TAB (9), dan NUL (0) tidak dirender sebagai glyph terlihat — karakter tersebut adalah instruksi fungsional ke terminal atau tampilan. Dekod berhasil; output hanya tidak terlihat. Buka hasilnya di penampil heks untuk mengkonfirmasi byte ada, atau pipa melalui
cat -Apada Linux untuk membuat non-cetak terlihat. - "Itu berhasil, tetapi emoji atau karakter aksen saya hilang." ASCII tidak dapat mewakili emoji atau skrip non-Inggris apa pun. Unicode Consortium mendefinisikan 149,186 karakter di seluruh 161 skrip dalam versi 15.0 — ASCII mencakup 95 karakter yang dapat dicetak dengan berfokus pada Inggris. Jika teks asli Anda berisi ñ, ü, ç, Mandarin, Sirilisasi, Arab, atau 😀, karakter-karakter itu tidak pernah dapat direpresentasikan dalam ASCII 7-bit. Kode numerik yang Anda pegang adalah byte UTF-8 yang memerlukan dekoder UTF-8, bukan alat ASCII.
- "Beberapa karakter dalam file 'ASCII' saya yang seharusnya didekod dengan salah." Kemungkinan karakter tingkat suplemen Unicode yang memerlukan penanganan pasangan pengganti, yang sebagian besar generator ASCII sederhana (CodeShack termasuk) tidak menerapkan. Menurut dokumentasi CodeShack, pendekatan
String.fromCharCode()mereka menangani karakter BMP hingga 0xFFFF tetapi bukan titik kode tingkat suplemen. Gunakanbytes.decode('utf-8')Python sebagai gantinya — alat ini menangani rentang Unicode lengkap dengan benar.
Jika output Anda memiliki karakter aksen yang keluar dengan cara yang salah, Anda tidak memiliki masalah ASCII — Anda memiliki masalah UTF-8 yang memakai kostum ASCII.
Mengotomatisasi Dekoding ASCII dengan Python, JavaScript, dan Spreadsheet
Ketika Anda mendekod ASCII lebih dari sekali seminggu, alat web menghabiskan waktu dan menciptakan paparan privasi. Skrip Python 4 baris atau formula spreadsheet menangani konversi batch secara lokal tanpa round-trip pihak ketiga. Ketiga opsi di bawah mencakup pengembang, lingkungan web, dan analis yang tinggal di Excel — pilih yang cocok dengan tempat data Anda sudah berada.
Python (string heks ke ASCII):
hex_data = "48 65 6C 6C 6F 20 57 6F 72 6C 64"
text = bytes.fromhex(hex_data.replace(" ", "")).decode("ascii")
print(text) # → Hello World
bytes.fromhex() memerlukan tidak ada spasi dalam inputnya, jadi kami melepasnya dengan .replace(). .decode("ascii") akan menaikkan UnicodeDecodeError pada byte apa pun lebih besar dari 127, yang tepat ketika memvalidasi ASCII ketat — kesalahan adalah informasi diagnostik, bukan kegagalan. Untuk menoleransi karakter yang diperluas, tukar dengan .decode("utf-8") untuk teks modern atau .decode("latin-1") untuk data Eropa Barat legacy.
JavaScript (array desimal ke teks):
const codes = [72, 101, 108, 108, 111, 32, 87, 111, 114, 108, 100];
const text = String.fromCharCode(...codes);
console.log(text); // → Hello World
String.fromCharCode() menerima satuan kode hingga ~65.535 (batas BMP). Untuk titik kode di atas itu, gunakan String.fromCodePoint() untuk menangani pasangan pengganti dengan benar — ini adalah kesenjangan alat UI CodeShack tidak diisi, menurut dokumentasi mereka sendiri. Jika Anda memproses konten yang dihasilkan pengguna yang mungkin berisi emoji atau skrip tingkat suplemen, default ke String.fromCodePoint() terlepas dari apakah data uji Anda membutuhkannya.
Google Sheets / Excel formula:
=CHAR(72)&CHAR(101)&CHAR(108)&CHAR(108)&CHAR(111)
CHAR() menerima satu kode desimal per panggilan. Untuk kolom kode dalam A2:A12, gunakan =CONCAT(CHAR(A2:A12)) di Google Sheets (yang menangani array spilling secara otomatis) atau =TEXTJOIN("",TRUE,IF(A2:A12<>"",CHAR(A2:A12),"")) sebagai formula array di Excel. Terbaik untuk kumpulan data kecil di bawah ~100 nilai — di luar itu, formula menjadi tidak praktis dan Python lebih cepat untuk ditulis dan dijalankan.
Satu catatan tentang kapan tidak mengotomatisasi: migrasi legacy satu kali jarang membenarkan menulis skrip. Alat web dari bagian perbandingan lebih cepat untuk pekerjaan satu kali. Otomatisasi ketika (a) data mengalir masuk berulang kali, (b) itu berisi nilai sensitif yang tidak boleh meninggalkan mesin Anda, atau (c) sistem hilir memerlukan teks yang didekod sebagai bagian dari pipeline yang ada. Kode yang sama dapat dibungkus dalam endpoint API — serupa dengan cara layanan yang menghadap pengembang seperti Text to Speech API dan Voice Cloning API mengekspos logika pemrosesan teks ke aplikasi lain. Setelah dekoding menjadi layanan, sisa stack Anda berhenti peduli apakah input tiba sebagai heks, desimal, atau UTF-8 yang sudah didekod.
ASCII vs Unicode — Mengapa Alur Kerja "ASCII Saja" Secara Diam-diam Merusak Konten Modern
Anda sekarang telah belajar cara mendekod ASCII. Bagian ini menjelaskan kapan itu adalah tujuan yang salah sama sekali.
| Properti | ASCII | Unicode (UTF-8) |
|---|---|---|
| Titik kode yang didefinisikan | 128 (0–127) | 149.186 ditugaskan dari 1.114.112 yang mungkin |
| Bit per karakter | 7 | 8–32 (variabel, 1–4 byte) |
| Skrip yang didukung | Latin Inggris saja | 161 skrip |
| Dukungan Emoji | Tidak ada | Penuh |
| Penggunaan web | <5% sebagai primer | >95% situs web |
Sumber: ASCII Wikipedia, Unicode 15.0 Consortium, survei enkoding karakter W3Techs.
Penyedia kemasan dCode menyatakan dengan jelas bahwa ASCII adalah "usang dan digantikan oleh Unicode." Itu bukan penggelengan tangan historis — itu adalah peringatan praktis. Banyak pengembang membangun pipeline yang bekerja sempurna dalam pengujian (data ASCII saja Inggris) dan rusak dalam produksi pertama kali pengguna mengirimkan nama aksen, emoji, atau skrip non-Latin. Esai klasik Joel Spolsky membingkai kegagalan yang tepat: memperlakukan byte seolah-olah mereka dalam enkoding spesifik tanpa memverifikasi asumsi, lalu menonton korupsi data secara diam-diam.
Jebakan adalah mode kegagalan diam-diam. Kode yang menangani byte rentang ASCII dengan senang hati akan memproses subset ASCII dari UTF-8 tanpa kesalahan — sampai itu menabrak urutan multi-byte, di mana titik itu baik crash, mangles karakter, atau (kasus terburuk) menulis byte yang rusak kembali ke penyimpanan. Pada saat seseorang memperhatikan, data buruk telah merambat melalui backup.
Unicode dirancang khusus untuk kompatibilitas ke belakang: teks murni ASCII apa pun sudah merupakan UTF-8 yang valid tanpa konversi yang diperlukan. Menurut RFC 3629, subset ASCII dari UTF-8 menggunakan tepat satu byte identik dengan byte ASCII asli. Ini berarti pertanyaan "ASCII ke teks" hampir selalu merupakan tanda bahwa di suatu tempat upstream, teks mendapat serialisasi sebagai kode numerik — bukan bahwa Anda memiliki ketidaksesuaian enkoding yang genuine. Temukan titik serialisasi, perbaiki untuk menampilkan UTF-8 langsung, dan masalah dekoding hilir menghilang.
Ini menjadi sangat tajam ketika konten bergerak lintas bahasa. Subtitle, skrip dubbing, audio yang ditranskripsikan, salinan yang diterjemahkan — apa pun yang multibahasa berisi aksen, tanda nada, karakter ideografis, atau skrip kanan-ke-kiri yang ASCII tidak dapat dikodekan. Pipeline konten modern apa pun — transkripsi, terjemahan, AI Dubbing di seluruh 33+ bahasa target — memerlukan kesadaran Unicode dari level byte ke atas, karena ASCII tidak dapat mewakili skrip yang dibaca sebagian besar dunia. Pipeline yang secara diam-diam menghilangkan tanda nada Vietnam atau kanji Jepang bukan pipeline yang bekerja untuk 95% pengguna dan rusak untuk 5% — alat ini adalah pipeline yang menghasilkan keluaran yang diam-diam rusak untuk mayoritas bahasa manusia.
ASCII menangani 128 karakter. Unicode menangani 149.186. Jika konten Anda menyentuh lebih dari satu bahasa, kesenjangan itu adalah seluruh permainan.
Daftar Periksa Pra-Penerbangan — Konfirmasi Dekoding ASCII Adalah Solusi yang Tepat Sebelum Memulai
Sebelum menempel apa pun ke dalam konverter, jalankan melalui pemeriksaan tujuh item ini. Setiap jawaban "tidak" mengarahkan ulang Anda ke solusi yang berbeda — bagian pemecahan masalah untuk ketidaksesuaian enkoding, bagian otomasi untuk alur kerja berulang, bagian ASCII-vs-Unicode untuk apa pun yang multibahasa. Tiga atau lebih jawaban "tidak" berarti dekoding ASCII bukan masalah nyata Anda.
- Data saya terdiri dari token numerik (heks, desimal, biner, atau oktal) — bukan huruf atau simbol. Jika Anda melihat teks yang dapat dibaca secara aktual dicampur dengan angka, Anda memiliki aliran yang sebagian didekod. Ekstrak hanya bagian numerik sebelum menempel ke generator, atau alat Anda akan tersedak pada karakter non-numerik dan menolak untuk memproses sisanya.
- Semua nilai numerik saya berada di antara 0 dan 127. Apa pun 128 atau lebih tinggi bukan ASCII standar. Jika Anda memiliki nilai hingga 255, Anda berada di wilayah Latin-1 atau Windows-1252; gunakan dekoder yang sadar halaman kode sebagai gantinya. Jika nilai melebihi 255, Anda hampir pasti memiliki titik kode Unicode mentah, bukan kode ASCII — dekoder berbeda, pendekatan berbeda.
- Saya tahu basis input saya (heks vs desimal vs biner vs oktal). Menebak membuang waktu dan menghasilkan hasil yang diam-diam salah. Heks berisi karakter A–F dicampur dengan digit. Biner hanya 0s dan 1s yang dikelompokkan dalam kumpulan 7 atau 8 bit. Oktal menggunakan digit 0–7 hanya — tidak ada 8s atau 9s muncul. Desimal adalah segala sesuatu yang lain di bawah 128.
- Konten sumber saya adalah Inggris saja. ASCII tidak dapat mewakili aksen Prancis, umlaut Jerman, huruf Cyrillic, ideograf CJK, atau emoji. Jika teks asli Anda pernah berisi salah satu dari itu, kode numerik yang Anda pegang bukan ASCII — karakter tersebut adalah byte UTF-8 yang memerlukan dekoder UTF-8. Memaksa mereka melalui alat ASCII akan salah satu kesalahan atau menghasilkan mojibake. Batasan yang sama membentuk langkah lokalisasi hilir apa pun, termasuk alur kerja API AI Dubbing yang harus mempertahankan setiap karakter yang berisi skrip.
- Data tidak sensitif (tidak ada kredensial, PII, atau konten yang diatur). Konverter web memproses paste Anda pada server pihak ketiga tanpa jaminan retensi data yang eksplisit. Panduan OWASP merekomendasikan dekoding hanya lokal untuk data apa pun yang tunduk pada aturan retensi, peraturan privasi, atau kerahasiaan kontraktual. Ketika ragu, gunakan skrip Python — byte Anda tetap di mesin Anda.
- Saya melakukan ini sekali, atau jarang. Dekoding berulang milik skrip Python 4 baris, bukan tab browser. Otomasi menghilangkan permukaan kesalahan copy-paste, menghilangkan paparan privasi pihak ketiga, dan berjalan lebih cepat daripada waktu yang diperlukan untuk membuka alat browser. Jika ini adalah ketiga kalinya minggu ini Anda mendekod jenis data yang sama, berhenti dan buat skrip.
- Saya memiliki nilai referensi yang dikenal untuk divalidasi. Konfirmasi setidaknya satu karakter yang didekod cocok dengan pemetaan yang dikenal: 65 = 'A', 32 = spasi, 48 = '0', 10 = line feed. Jika yang tidak didekod dengan benar dalam pengujian Anda, alat, input, atau basis yang diasumsikan salah — jangan percayai sisa output. Pemeriksaan validasi tunggal menghabiskan sepuluh detik dan mencegah jam debugging hilir.
Tujuh ya berarti Anda mendekod ASCII genuine dan alat apa pun dari bagian perbandingan akan bekerja dalam waktu kurang dari satu menit. Apa pun yang lain berarti berhenti, diagnosa dengan daftar periksa pemecahan masalah, atau membangun kembali di sekitar Unicode — fondasi yang sama yang membuat alat modern seperti Text to Speech, Voice Cloning, dan AI image generator bekerja secara andal di setiap bahasa generator ascii ke teks tidak pernah dirancang untuk ditangani.