
Vous avez fait défiler plus de quarante échantillons de voix. Casque sur les oreilles, vous appuyez sur aperçu, écoutez pendant trois secondes, passez au suivant, puis encore au suivant, jusqu'à ce que chaque échantillon se fonde dans le même bourdonnement indistinct. Celle-ci est-elle « chaleureuse » ou simplement « douce » ? L'explication devrait-elle sonner « autoritaire » ou « amicale » ? Le problème n'est pas le manque de choix — les bibliothèques modernes contiennent plus de 300 voix, et vous pouvez les auditionner pendant une heure sans en arrêter une. Le problème, ce sont les descripteurs de voix : le vocabulaire précis dont vous avez besoin pour distinguer une voix d'une autre et l'associer à votre contenu avec intention. Sans ce vocabulaire, la sélection de voix se transforme en devinette et le doublage devient un coûteux processus d'essais et d'erreurs. Selon WP SEO AI, les étiquettes d'un seul mot comme « naturelle » ou « engageante » sont trop vagues pour être exploitables — un portrait vocal clair nécessite de spécifier plusieurs dimensions qui interagissent à la fois. À la fin de cet article, vous saurez décrire n'importe quelle voix avec précision selon le ton, la hauteur et le style, afin de pouvoir rechercher, filtrer et solliciter des outils vocaux — ou rédiger un brief pour un projet de clonage — avec confiance plutôt qu'avec chance.

Table des matières
- Les quatre dimensions dont relève chaque descripteur de voix
- Les descripteurs de ton décodés — de « chaleureux » à « autoritaire »
- Hauteur et débit — les descripteurs techniques que les gens confondent
- Style et registre — associer la voix au contexte du contenu
- Empiler les descripteurs pour une recherche ou une invite vocale précise
- Pièges des descripteurs — là où la sélection de voix échoue discrètement
- Votre modèle de brief de descripteur de voix à copier-coller
- Questions sur les descripteurs de voix que les créateurs posent vraiment
Les quatre dimensions dont relève chaque descripteur de voix
Chaque descripteur de voix que vous avez jamais lu — aussi poétique soit-il — se résume à quatre dimensions mesurables. Une fois que vous savez les nommer, le vocabulaire cesse de paraître subjectif et se met à se comporter comme un ensemble de commandes que vous pouvez ajuster indépendamment.
Le ton est la couleur émotionnelle ou l'attitude de la voix. Chaleureux, froid, enthousiaste, distant — c'est le caractère émotionnel qu'un auditeur ressent avant même de traiter le sens d'un seul mot. C'est la dimension qui décide si votre public se penche en avant ou décroche.
La hauteur est l'aigu ou le grave perçu du son. Un baryton profond et résonnant se situe à une extrémité ; un son clair, léger et juvénile se situe à l'autre. La hauteur est fondamentalement une propriété de fréquence, ce qui en fait l'un des descripteurs les plus objectifs des quatre — pourtant c'est aussi l'un de ceux qu'on confond le plus souvent avec le débit.
Le débit et le rythme décrivent la vitesse de la parole et sa cadence. Rapide, mesuré, posé, délibéré — le débit inclut les pauses entre les phrases et les motifs d'inflexion qui s'y superposent. Deux voix lisant des scripts identiques à des débits différents peuvent sembler être des performances entièrement différentes.
Le style et le registre régissent le contexte de performance et le niveau de formalité. Narration, conversationnel, radiodiffusion, e-learning — formel ou décontracté. C'est la dimension qui décide du rôle que joue la voix pour l'auditeur.
Cette taxonomie n'est pas une opinion personnelle. Le Nielsen Norman Group formalise le ton selon quatre axes indépendants — formel ou décontracté, sérieux ou drôle, respectueux ou irrévérencieux, et terre-à-terre ou enthousiaste — démontrant que le ton est multi-axes, et non un simple curseur que vous faites glisser de « ennuyeux » à « amusant ». Les plateformes commerciales opérationnalisent la même logique. La place de marché de voix Voices.com regroupe la description vocale en quatre qualités : hauteur et ton, volume et projection, articulation et prononciation, et débit et inflexion. Étiquettes différentes, même structure sous-jacente.

Pourquoi est-il si important de séparer les dimensions ? Le coach en communication Robin Kermode présente le ton, la hauteur et le débit comme les trois leviers qui créent ensemble la « variété vocale » — définissant le ton comme le caractère émotionnel, la hauteur comme la fréquence perçue qui peut altérer le sens émotionnel, et le débit comme la vitesse d'élocution. Le style et le registre forment le quatrième levier, et il se situe au-dessus des trois autres, régissant le contexte dans lequel ils opèrent. En clair : le ton, la hauteur et le débit décrivent comment la voix sonne ; le style et le registre décrivent quel rôle elle joue.
Chaque descripteur de voix que vous avez jamais lu se résume à quatre leviers — ton, hauteur, débit et style. Maîtrisez les leviers et vous arrêtez de deviner.
Retenez ce modèle. Chaque section qui suit explore exactement l'une de ces quatre dimensions, et aucune ne redéfinira le cadre. Lorsque vous rencontrez un descripteur n'importe où — un filtre de place de marché, un champ d'invite IA, un brief d'agence — votre première tâche est de le classer dans l'une des quatre catégories. Cette seule habitude convertit un mur d'adjectifs en un panneau de commande organisé.
Les descripteurs de ton décodés — de « chaleureux » à « autoritaire »
Le ton est la dimension que le public enregistre en premier, et c'est celle qui est le plus souvent mal briefée parce qu'elle s'appuie sur des adjectifs subjectifs. Les recherches du Nielsen Norman Group montrent que le ton opère selon plusieurs axes indépendants — l'humour, la formalité, le respect et l'enthousiasme sont des leviers distincts — ce qui signifie qu'un seul mot de ton capture rarement ce que vous voulez vraiment. Regroupez plutôt vos descripteurs de ton en grappes, et vous obtenez à la fois de la précision et un moyen pratique de filtrer.
Construction de confiance (chaleureux, amical, rassurant). Cette grappe instaure une sécurité émotionnelle avant que le sens ne s'installe. C'est le bon choix pour les explications de santé, les SVI du support client et les vidéos d'intégration où un auditeur a besoin de se sentir accompagné avant d'assimiler les instructions. WP SEO AI place « chaleureux » parmi les adjectifs de ton émotionnel les plus utilisés, et pour cause — c'est le repère par défaut auquel la plupart des publics font confiance.
Énergique (dynamique, enthousiaste, animé). Cette grappe signale l'élan et l'excitation. Elle est idéale pour les lancements de produits, les lectures publicitaires et les courtes vidéos sociales où les deux premières secondes décident si quelqu'un continue à regarder. L'axe « enthousiaste » de NN/g correspond directement ici — et notez qu'il est indépendant de la formalité, vous pouvez donc être énergique et professionnel en même temps.
Sérieux (autoritaire, professionnel, sombre). Cette grappe transmet la crédibilité et le poids. Faites-y appel pour la formation en entreprise, les explications financières et la narration documentaire où le public doit faire confiance au fait que le locuteur en sait plus que lui. « Autoritaire » est un descripteur phare de la liste de portrait vocal de WP SEO AI — il est assez spécifique pour filtrer et assez large pour s'appliquer à tous les formats.
Intime (doux, apaisant, conversationnel). Cette grappe crée la proximité et le calme. Elle est conçue pour les applications de méditation, les introductions de podcasts et le contenu de style ASMR où l'auditeur est souvent seul et où la voix donne l'impression de s'adresser directement à lui. L'intimité provient autant de la retenue que de la chaleur — cette grappe se retire plutôt qu'elle ne projette.
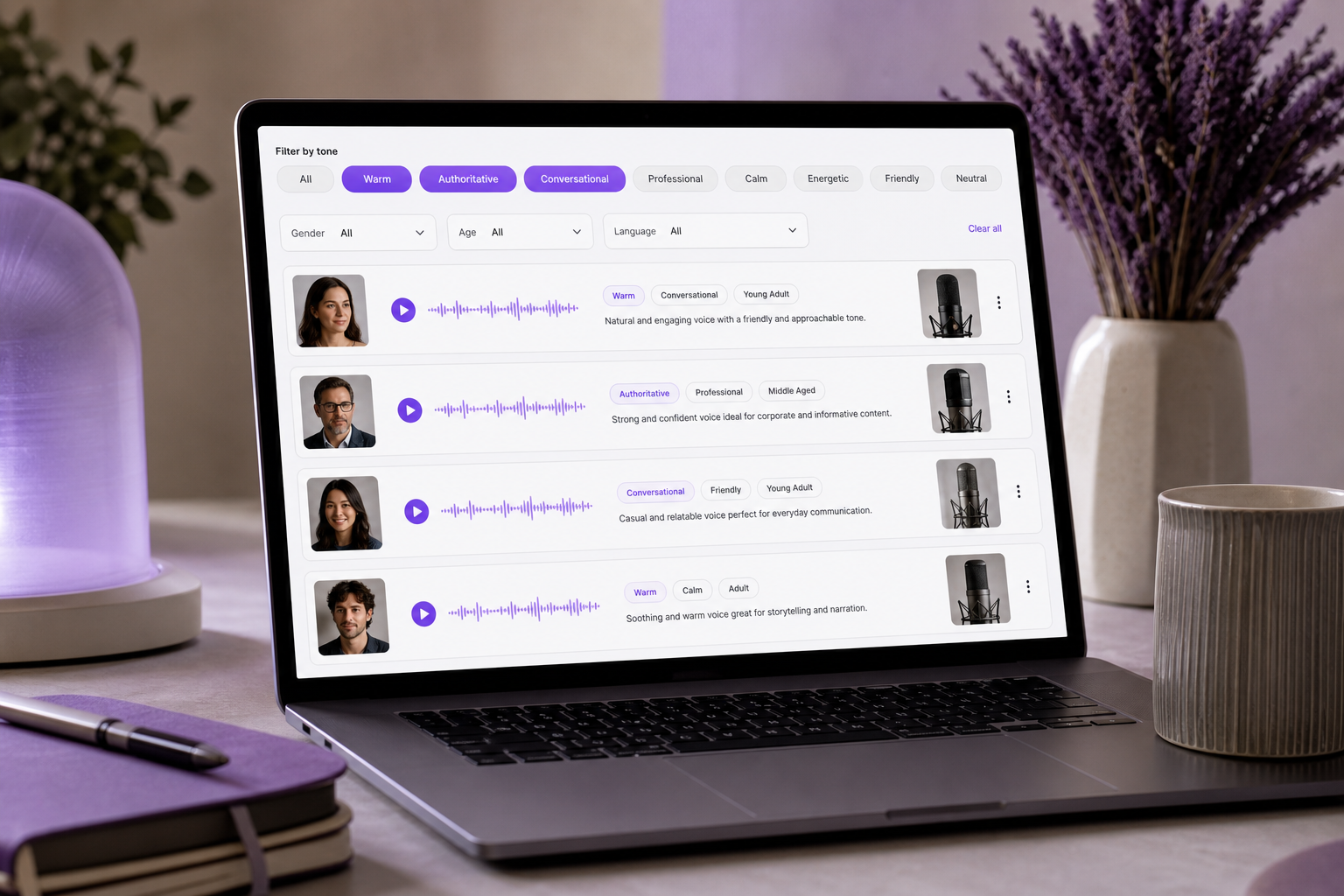
Le ton est la seule dimension que le public remarque en premier et oublie en dernier — il établit la confiance émotionnelle avant que le sens d'un seul mot ne s'installe.
Ces grappes ne sont pas qu'un modèle mental — c'est ainsi que les outils modernes vous permettent de rechercher. Une plateforme de synthèse vocale comme SymTrain documente le filtrage des voix par ton, par exemple « articulée, décontractée, anxieuse », réduisant une grande bibliothèque avant même que vous n'appuyiez sur aperçu. C'est le bénéfice pratique du regroupement de vos descripteurs de voix : de la même manière qu'une bibliothèque de synthèse vocale vous permet de filtrer par ton avant l'aperçu, une grappe de ton claire transforme une heure d'audition en une liste restreinte et ciblée de trois voix.
Hauteur et débit — les descripteurs techniques que les gens confondent
La hauteur et le débit sont les deux dimensions les plus confondues dans tout brief vocal, et cette confusion coûte aux créateurs un temps réel. La hauteur est la fréquence — l'aigu ou le grave perçu d'une voix. Le débit est la vitesse et le rythme — les mots par minute, la cadence et le placement des pauses. La division en trois de Robin Kermode les garde distincts : le ton est le caractère émotionnel, la hauteur est la fréquence perçue, le débit est la vitesse d'élocution. Trois choses distinctes.
L'erreur classique consiste à intervertir le vocabulaire. Les créateurs disent « rapide » quand ils veulent dire « aigu », ou « profond » quand ils veulent dire « lent ». Ce sont des commandes indépendantes. Une voix grave peut être vive. Une voix aiguë peut être mesurée. Les traiter comme un seul adjectif flou, c'est ainsi que les briefs partent de travers avant que quiconque n'enregistre une syllabe.
| Descripteur | Ce qu'il contrôle | Sonne comme | Idéal pour |
|---|---|---|---|
| Profond | Hauteur (basse fréquence) | Baryton, résonnant | Documentaire, marque de luxe |
| Clair | Hauteur (haute fréquence) | Léger, aérien, juvénile | Contenu pour enfants, pubs dynamiques |
| Mesuré | Débit (lent/régulier) | Délibéré, spacieux | E-learning, tutoriels |
| Vif | Débit (rapide) | Énergique, urgent | Actualités, promos |
| Saccadé | Débit + articulation | Net, arrêts précis | Technique, instructif |
| Traînant | Débit (lent/détendu) | Étiré, décontracté | Récit, personnage |
Le travail intéressant se produit lorsque la hauteur et le débit se combinent, car l'impression composée est presque toujours plus forte que l'un ou l'autre descripteur pris seul. Une hauteur profonde avec un débit vif se lit comme une urgence assurée — la voix de quelqu'un qui connaît le sujet et ne vous fait pas perdre votre temps. Une hauteur claire avec un débit mesuré se lit comme une patience amicale — idéale lorsque vous guidez un utilisateur nerveux à travers une première configuration. Inversez les combinaisons et le sens bascule entièrement, ce qui est exactement pourquoi vous ne pouvez pas fusionner les deux champs en un seul.
Cette séparation est intégrée dans la manière dont les plateformes sérieuses structurent leurs conseils. Voices.com traite la hauteur/ton et le débit/inflexion comme deux de ses quatre qualités distinctes, jamais comme un seul réglage. La documentation de l'API Hamsa liste de même le débit de parole et la prononciation/clarté comme des critères de sélection distincts, chacun évalué à part avant qu'une voix ne passe en production. Le constat pour le praticien est direct : dans tout brief, donnez à la hauteur et au débit leurs propres champs. Écrivez « hauteur profonde, débit vif », et non « une voix profonde percutante » en espérant que le lecteur démêle tout cela. Et rappelez-vous que les mêmes traits de hauteur et de débit que vous spécifiez ici sont ce qu'un modèle de clonage de voix préserve d'un échantillon source — donc bien choisir le vocabulaire à l'étape du brief se répercute jusqu'au résultat cloné.
Style et registre — associer la voix au contexte du contenu
La compétence la plus déterminante dans la sélection de voix n'est pas de choisir la voix la plus impressionnante. C'est de choisir le bon style et le bon registre pour le contexte de diffusion — la voix que votre public attend et ne remet jamais en question. Les conseils du système de design PatternFly séparent le style (choix de grammaire et de syntaxe), la voix (personnalité de la marque) et le ton (l'état émotionnel de l'utilisateur), et le parallèle avec la voix parlée se transpose nettement : le style et le registre d'un côté, le ton émotionnel de l'autre. Trompez-vous de registre et même une belle voix sonnera faux.
La documentation de Hamsa concrétise la distinction de style avec une justification explicite par cas d'usage. « Conversationnel » est naturel et amical — idéal pour le service et le support client. « Narrateur » est clair et articulé — adapté aux explications. Ce cadrage « sonne comme / idéal pour » est exactement ce qui transforme le style en une décision que vous pouvez prendre en quelques secondes plutôt que d'en débattre tout un après-midi.
| Type de contenu | Descripteur de style recommandé | Pourquoi ça fonctionne |
|---|---|---|
| Vidéo explicative YouTube | Conversationnel | Naturel, amical — garde les spectateurs occasionnels engagés |
| Formation en entreprise | Narrateur | Clair, articulé — adapté aux explications |
| Introduction de podcast | Conversationnel / radiodiffusion | Établit une présence d'animateur chaleureuse et familière |
| Livre audio | Narrateur | Clarté soutenue sur une écoute de longue durée |
| Pub / promo | Radiodiffusion énergique | Projette l'élan et un appel à l'action |
Sous le style se trouve le registre — le choix formel ou décontracté qui assaisonne tout ce qui le surmonte. L'axe formel↔décontracté de NN/g est la manière la plus claire d'y réfléchir : le même style conversationnel peut se lire comme un animateur de radiodiffusion soigné ou comme un ami parlant à travers une table, selon l'endroit où vous réglez le curseur du registre. Un narrateur de formation en entreprise à un registre décontracté semble accessible ; le même narrateur à un registre formel semble institutionnel. Aucun n'est mauvais — ce sont des réponses à des briefs différents.
Deux couches supplémentaires se superposent. L'accent et le dialecte sont des critères de sélection essentiels dans la liste de contrôle de Hamsa, et ils portent un poids culturel qu'aucun descripteur de ton ne peut annuler — une voix « US neutre » et une voix « RP britannique » peuvent partager un ton, une hauteur et un débit identiques tout en produisant un effet complètement différent sur un public. SymTrain recommande des filtres par tranche d'âge — jeune, adulte, plus âgé — aux côtés du ton, car l'âge perçu modifie le degré d'autorité ou de proximité d'une voix.
Le bon descripteur de style n'est pas la voix la plus impressionnante — c'est celle que votre public s'attend à entendre à ce moment-là et ne remet jamais en question.
Le point le plus tranchant de PatternFly est que le style et le ton doivent répondre à l'état émotionnel du public, et non à une valeur par défaut à l'échelle de la marque. Le contenu de dépannage a besoin d'un registre neutre et utile ; une annonce a besoin d'un registre enthousiaste. Le contexte dicte le registre à chaque fois. Et les décisions de registre ne restent pas figées lorsque votre contenu voyage — un registre décontracté et conversationnel qui fonctionne parfaitement en anglais peut se lire comme désinvolte ou peu professionnel sur un autre marché. C'est un choix de registre qui doit tenir lorsque vous passez le contenu par le doublage IA vers d'autres langues, ce qui est exactement là où la prochaine couche de discipline porte ses fruits.
Empiler les descripteurs pour une recherche ou une invite vocale précise
Le vocabulaire n'a d'importance que si vous pouvez le transformer en une méthode reproductible. La recherche est cohérente sur le principe fondamental : les descripteurs empilés battent les étiquettes uniques à chaque fois. WP SEO AI recommande de combiner des adjectifs de ton émotionnel comme « chaleureux », « net » ou « autoritaire » avec des détails concrets sur le débit, la variation de hauteur, la résonance et la clarté pour bâtir un portrait vocal clair. Voices.com formalise un pipeline en trois étapes — définir le personnage (âge, genre, style), fixer le ton, puis choisir des mots-clés adaptés. Voici cette logique décomposée en sept étapes que vous pouvez exécuter à chaque fois.
- Définissez l'objectif émotionnel. Nommez le sentiment avec lequel le public devrait repartir — confiance, excitation, calme. Tout ce qui suit sert cette seule décision.
- Choisissez une grappe de ton. Choisissez parmi les quatre grappes : construction de confiance, énergique, sérieuse ou intime. Résistez à l'envie de mélanger des grappes conflictuelles — c'est là que les briefs se défont.
- Réglez la plage de hauteur. Profonde, moyenne ou claire. Un mot, pas un paragraphe.
- Réglez le débit. Mesuré, vif ou saccadé. Gardez-le séparé de la hauteur.
- Verrouillez le style et le registre. Conversationnel, narrateur ou radiodiffusion — puis formel ou décontracté.
- Ajoutez la démographie et l'accent. Ajoutez la tranche d'âge et le dialecte, comme l'attendent les filtres de SymTrain et de Hamsa.
- Testez face à 2 ou 3 échantillons. La liste de contrôle de Hamsa — prononciation, clarté, débit, ton, accent — est votre dernier filtre de validation avant toute livraison.

Voici à quoi ressemble la pile finie sous forme de chaîne unique : chaleureuse + hauteur moyenne + débit mesuré + style conversationnel + femme + la trentaine + accent US neutre. Cette seule ligne remplit une double fonction. Déposez-la dans une barre de recherche et elle réduit votre temps de filtrage sur une bibliothèque de plus de 300 voix à une poignée de candidates. Introduisez la même chaîne empilée dans un préréglage de synthèse vocale et elle devient une invite de génération. La discipline de l'écrire une seule fois est ce qui vous épargne de réauditionner tout le catalogue. Et parce que le format est cohérent, la même chaîne empilée que vous fourniriez à un préréglage de synthèse vocale peut passer directement à un appel d'API de clonage de voix — un seul brief, plusieurs destinations, aucune retraduction entre les outils.
Pièges des descripteurs — là où la sélection de voix échoue discrètement
La plupart des projets vocaux n'échouent pas à l'étape de l'enregistrement. Ils échouent au brief, de manières invisibles jusqu'à ce que vous écoutiez un fichier fini qui sonne d'une certaine façon faux. Voici les modes de défaillance qui n'apparaissent que lorsqu'il est coûteux de les corriger.
Empiler des descripteurs contradictoires. « Énergique mais apaisante » s'annule de lui-même — la voix ne peut pas sprinter et chuchoter en même temps. La recherche de NN/g est utile ici : l'humour, le respect et l'enthousiasme sont des leviers indépendants, donc de nombreuses combinaisons fonctionnent bien, mais certaines sont véritablement en conflit. La solution est de choisir une grappe de ton dominante et d'affiner à l'intérieur de celle-ci plutôt que de chercher à travers les grappes une variété dont vous n'avez pas besoin.
Traiter « naturelle » comme une direction. « Naturelle » et « engageante » donnent l'impression d'être des instructions, mais elles ne sont pas exploitables. WP SEO AI soutient que de tels fourre-tout échouent autant pour les outils d'IA que pour les talents à distance, car ils ne spécifient aucune des dimensions en interaction. La solution est de remplacer chaque fourre-tout par la pile à quatre dimensions — ton, hauteur, débit, style — plus la démographie. Si un descripteur ne se range pas dans l'une de ces catégories, ce n'est pas une direction.
Supposer que les descripteurs se traduisent d'une langue à l'autre. Le ton perçu change lorsque vous doublez dans une autre langue et une autre culture — un registre qui se lit comme chaleureux en anglais peut être trop familier ailleurs. La solution est de revalider le ton par langue cible plutôt que de faire confiance au descripteur source pour se transposer. Lorsque vous doublez dans 33 langues cibles, les vérifications de ton par langue ne sont pas une fioriture facultative ; elles sont la différence entre un contenu qui crée du lien et un contenu qui aliène subtilement. C'est pourquoi les équipes qui font passer leur contenu par une API de doublage IA revérifient le ton par langue cible au lieu de supposer que le brief d'origine tient toujours.
Ignorer le contexte émotionnel du public. PatternFly avertit qu'un ton uniforme rate sa cible — un parcours de dépannage a besoin d'une voix neutre et utile, tandis qu'une annonce a besoin d'une voix enthousiaste. La solution est de choisir des descripteurs pour le moment dans lequel se trouve votre public, et non la valeur par défaut à l'échelle de la marque que vous avez fixée il y a six mois.
Sauter le brief et se fier à l'intuition. L'approche du guide de ton d'Ed Gandia critique les directives vagues en exigeant des paramètres concrets — public, spécificités de ton comme « chaleureux mais pas bavard », formalité, longueur de phrase et motifs récurrents. La solution est la plus simple de toutes : écrivez le brief empilé avant de prévisualiser une seule voix. L'intuition convient pour choisir entre deux finalistes. Elle est terrible pour réduire 300 voix à 3.

« Naturelle » ne décrit rien — c'est l'attente par défaut, pas une direction créative.
Votre modèle de brief de descripteur de voix à copier-coller
Voici la version opérationnelle de tout ce qui précède — une structure à remplir que vous pouvez coller dans n'importe quel outil vocal, brief d'agence ou demande de clonage. C'est le modèle à quatre dimensions plus la démographie, formaté pour que vous n'ayez jamais à le reconstruire à partir de zéro. Considérez-le comme la source unique de vérité pour les descripteurs de voix d'un projet.
BRIEF DE DESCRIPTEUR DE VOIX
----------------------------------------
Objectif émotionnel : ____ (ce que le public devrait ressentir)
Grappe de ton : ____ (construction de confiance / énergique / sérieuse / intime)
Hauteur : ____ (profonde / moyenne / claire)
Débit : ____ (mesuré / vif / saccadé)
Style / registre : ____ (conversationnel / narrateur / radiodiffusion ; formel / décontracté)
Démographie : ____ (genre, tranche d'âge)
Accent / langue : ____ (dialecte + langues cibles)
Voix de référence : ____ (optionnel — une voix connue pour ancrer les attentes)
Cette structure n'est pas arbitraire. Elle reflète le résumé vocal concis de 3 à 5 phrases d'Ed Gandia associé à des paramètres spécifiques de ton, de formalité et de rythme, et elle suit le pipeline personnage → ton → mot-clé de Voices.com dans l'ordre où vous prenez réellement les décisions. Remplissez-la de haut en bas et chaque champ affine le suivant.
Voici le modèle rempli pour un scénario réel — L'introduction d'une chaîne YouTube multilingue :
- Objectif émotionnel : accueil assuré
- Grappe de ton : construction de confiance / chaleureuse
- Hauteur : moyenne
- Débit : vif
- Style / registre : radiodiffusion conversationnelle
- Démographie : femme, la trentaine
- Accent / langue : anglais US neutre, doublé en espagnol + portugais
- Voix de référence : aucune
Ce seul brief vocal accomplit trois tâches sans modification. Il réduit votre recherche de bibliothèque à une liste restreinte. Il devient l'invite qui pilote la génération de synthèse vocale. Et il se transpose à l'étape de doublage, où les mêmes descripteurs sont revalidés par langue cible plutôt que reconstruits à partir de zéro. Un seul brief, trois résultats, aucun rebriefing.
L'avantage pratique de cette approche apparaît lorsque vos outils se trouvent au même endroit. Lorsque la synthèse vocale, le clonage de voix et le doublage partagent un même flux de travail, le même brief de descripteur qui pilote un aperçu peut passer directement dans une requête d'API de synthèse vocale — puis vers le doublage — au lieu d'être retapé et réinterprété à chaque étape. Écrivez le brief une seule fois. Utilisez-le partout.
Questions sur les descripteurs de voix que les créateurs posent vraiment
Quelle est la différence entre le ton et le timbre dans les descripteurs de voix ?
Le ton est le caractère émotionnel d'une voix — chaleureux, sérieux, distant. Le timbre est la texture ou la qualité unique du son lui-même — lisse, rauque, soyeux, dur. WP SEO AI répertorie la texture comme une dimension de descripteur distincte du ton émotionnel, et la distinction compte en pratique : deux voix peuvent partager exactement le même ton tout en ayant des timbres complètement différents. Lorsqu'une voix semble juste émotionnellement mais d'une certaine façon fausse, le timbre est généralement la variable que vous n'avez pas encore nommée.
Les descripteurs de voix se traduisent-ils fidèlement lors du doublage dans d'autres langues ?
Pas automatiquement. Le ton perçu peut changer d'une langue et d'une culture à l'autre, donc le registre chaleureux et décontracté qui fonctionne en anglais peut produire un effet différent sur un autre marché. La démarche fiable consiste à revalider le descripteur par langue cible plutôt que de supposer qu'il se transpose. Avec le doublage dans 33 langues cibles disponible, intégrer une vérification de ton par langue dans votre flux de travail n'est pas un travail supplémentaire — c'est ce qui garde un seul brief honnête sur chaque marché où vous publiez.
Combien de descripteurs devrais-je utiliser pour solliciter une voix IA ou un outil de clonage ?
Visez les quatre dimensions fondamentales plus la démographie — environ 5 à 7 descripteurs empilés. WP SEO AI montre que les descripteurs empilés surpassent les étiquettes uniques, et le pipeline de Voices.com confirme personnage plus ton plus mots-clés comme le minimum fonctionnel. Restez dans cette fourchette. Moins de cinq et vous revenez aux fourre-tout vagues ; plus de sept et vous commencez à risquer des contradictions qui s'annulent mutuellement.
Puis-je décrire une voix en faisant référence à une voix connue ou de célébrité au lieu d'utiliser des descripteurs ?
Une voix de référence est un ancrage utile — c'est pourquoi « voix de référence » est un champ optionnel dans le modèle de brief. Mais elle ne remplace pas les descripteurs. Une référence indique à un outil ou à un humain où commencer à peu près ; le ton, la hauteur, le débit et le style leur indiquent où atterrir. Associer une référence à des descripteurs explicites donne le résultat le plus fiable, car les descripteurs résolvent l'ambiguïté que la référence laisse ouverte.