
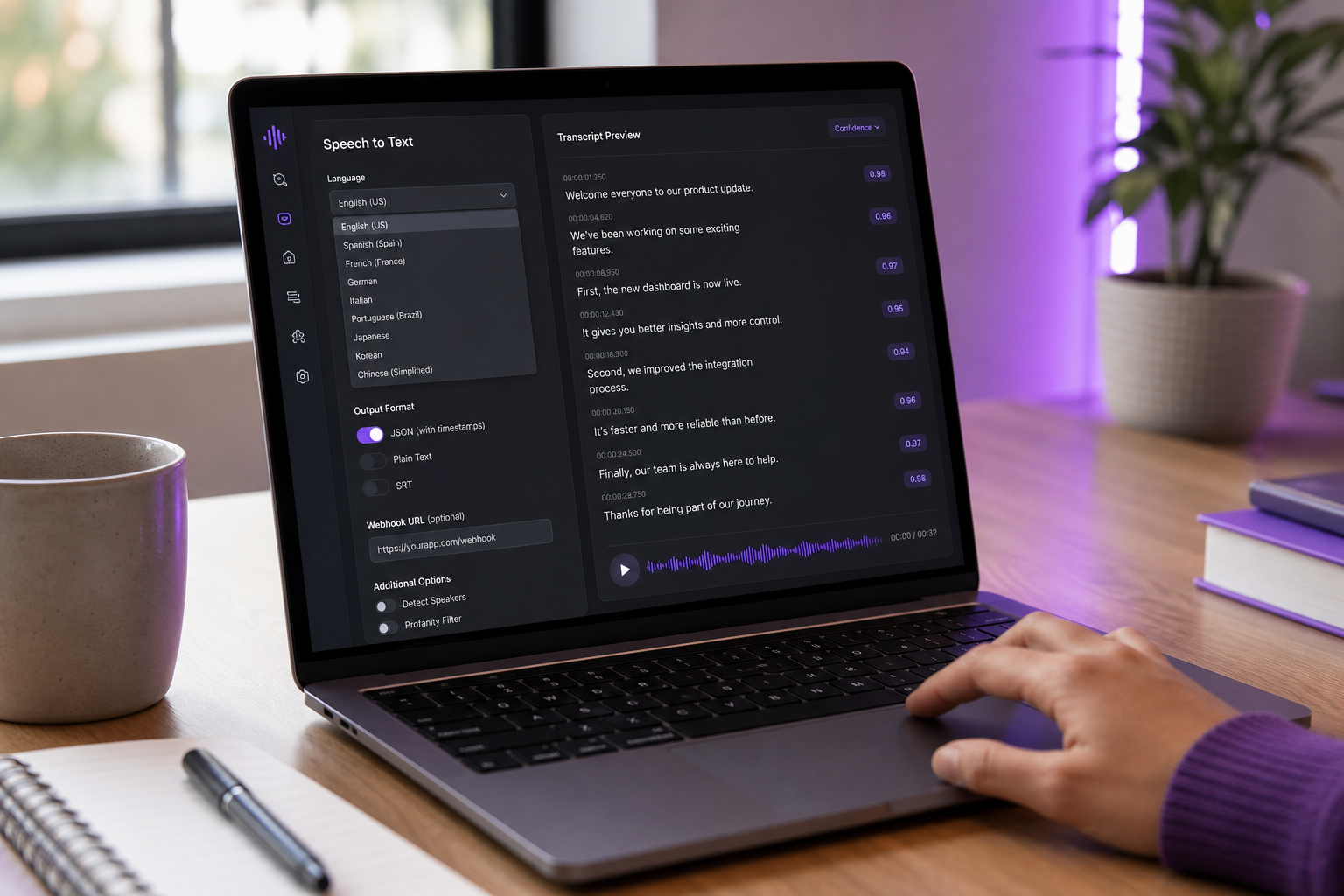
API de reconnaissance vocale : Comment choisir la bonne en 2025
Vous avez construit une application que les utilisateurs adorent — mais les demandes de fonctionnalités continuent d'arriver : « Est-ce que je peux juste parler au lieu de taper ? » Vous commencez donc à évaluer les API de reconnaissance vocale. En moins d'une heure, vous avez rencontré au moins quatre modèles de tarification contradictoires, des affirmations de précision qui oscillent entre « 95 % » et « 99 %+ » sans définition commune de ce qui est mesuré, et une qualité de SDK qui varie de trois lignes à une semaine de lecture de mauvaise documentation.
Les enjeux sont réels des deux côtés. Si vous faites le mauvais choix à grande échelle, vous allez soit perdre 3 000–8 000 $/mois en frais de streaming supplémentaires, soit lancer une fonctionnalité vocale qui dysfonctionnera sur 1 énoncé sur 5. Selon Koenecke et al. dans PNAS (2020), les taux d'erreur sur les cinq principaux systèmes commerciaux de reconnaissance vocale atteignent 35 % pour les locuteurs de l'anglais vernaculaire afro-américain contre 19 % pour les locuteurs blancs — un écart qui transforme un « problème de précision » en un « un tiers de vos utilisateurs ne peuvent pas utiliser votre produit » problème.
Ce guide vous donne le cadre de décision, la méthode de calcul des prix, le protocole pilote, et une comparaison tête-à-tête de six fournisseurs — y compris comment un modèle basé sur les crédits s'adapte aux constructions avec des charges de travail variables.

Table des matières
- Les cinq axes de décision qui déterminent réellement le choix de l'API de reconnaissance vocale
- La précision en contexte — Pourquoi le « benchmark 99 % » ment sur votre audio de production
- Latence, streaming et le multiplicateur de coût en temps réel
- Modèles de coûts démystifiés — Par minute vs. Connexions concurrentes vs. Pools de crédits
- Réalités d'intégration — L'audit SDK et API à 9 questions
- Comparaison tête-à-tête des fournisseurs — Quand choisir chaque API de reconnaissance vocale
- Votre liste de contrôle pour la sélection de l'API de reconnaissance vocale
Les cinq axes de décision qui déterminent réellement le choix de l'API de reconnaissance vocale
La plupart des articles de comparaison énumèrent plus de 30 fonctionnalités et l'appellent une recherche. Rejetez cela. Seulement six axes déterminent si une API de reconnaissance vocale fonctionnera pour votre construction spécifique — et sur n'importe quel projet, seulement deux ou trois d'entre eux importent vraiment.
Précision dans votre domaine. Une application de scribe médical utilisant une API à usage général affichera « metoprolol » sous la forme « meta peral ». Le Word Error Rate global masque ce type d'échec. Comme Dan Jurafsky l'affirme dans Speech and Language Processing, le WER traite toutes les erreurs de la même manière — mais dans un contexte clinique ou juridique, un mauvais nom de médicament ou une négation manquée a un impact disproportionné. Ce qui compte, c'est le WER spécifique au domaine sur votre audio, pas un titre de benchmark.
Profil de latence. Un outil d'accessibilité de sous-titrage en direct a besoin d'une réponse de bout en bout de moins d'une seconde. Un pipeline de transcription de podcast peut attendre 10 minutes. Selon le groupe Nielsen Norman « Response Times: The 3 Important Limits », les réponses inférieures à 100 ms semblent instantanées, moins d'une seconde préservent le flux, et plus de 10 secondes causent l'abandon de la tâche. Mappez votre cas d'utilisation à un niveau avant de faire vos achats.
Capacité hors ligne / sur l'appareil. Une application de recherche sur le terrain dans les zones rurales ne peut pas dépendre des aller-retours cloud. L'API SpeechAnalyzer d'Apple (WWDC 2025) est une option de niveau plateforme sur l'appareil pour iOS/macOS. Whisper auto-hébergé ou Vosk vous donne un contrôle hors ligne complet si vous êtes prêt à gérer les GPU.
Couverture de langue et code-switching. Whisper supporte 50+ langues avec une qualité comparable après un entraînement sur 680 000 heures d'audio multilingue (Radford et al., OpenAI 2022). Google et AWS utilisent des groupes de langues hiérarchisés où les langues de niveau B obtiennent une précision inférieure et parfois une tarification séparée.
Architecture du modèle de coût. Payer par minute, connexions concurrentes et pools de crédits se brisent différemment à grande échelle. Un YouTubeur téléchargeant 4 heures une semaine et 40 la semaine suivante est pénalisé par la facturation par minute dans les semaines lentes et les semaines de pics. Les pools de crédits avec report absorbent cette variance.
Zone de surface d'intégration. Qualité du SDK, webhooks vs. polling, comportements de gestion des erreurs. C'est là que l'« API facile » se transforme en trois semaines perdues.
Cinq axes déterminent chaque décision d'API de reconnaissance vocale qui vaut la peine d'être prise — et seulement deux ou trois d'entre eux s'appliquent à votre construction.
| Axe de décision | Pourquoi cela importe | Piège courant | Cas d'utilisation idéal |
|---|---|---|---|
| Précision du domaine | Les affirmations « 99 % » des fournisseurs utilisent la parole nettement lue | Faire confiance à LibriSpeech pour l'audio mobile bruyant | Applications médicales, juridiques, financières |
| Profil de latence | Le streaming coûte 3–5x le batch | Acheter du streaming pour les cas tolérants au batch | Sous-titres en direct vs. upload de podcast |
| Capacité hors ligne | Confidentialité + environnements avec connectivité restreinte | Supposer que l'API Web Speech est hors ligne | Applications médicales sur le terrain, mobile d'abord |
| Couverture de langue | Langues de niveau B = précision inférieure | Détection automatique sur audio multilingue | SaaS multilingue, contenu global |
| Modèle de coût | Par minute semble bon marché jusqu'à ce que le streaming démarre | Ignorer le stockage, l'egress, les coûts de retry | Flux de travail de créateur à volume variable |
| Zone de surface d'intégration | Les mauvais SDK coûtent des semaines de développement | « Simple dans les docs » ≠ s'expédie facilement | Tous les constructeurs |
Ce tableau est un filtre, pas un verdict. Un créateur YouTube téléchargeant 10 tâches batch par semaine se préoccupe du modèle de coût et de la couverture des langues. Une application médicale se préoccupe de la précision et de la capacité hors ligne. Un outil de réunion en temps réel se préoccupe de la latence et de la zone de surface d'intégration.
Avant de continuer la lecture, encerclez les deux ou trois axes qui importent le plus pour votre construction spécifique. La section de coût (différence de $ milliers) et l'instantané du fournisseur à la fin sembleront entièrement différents selon les axes que vous avez priorisés. Essayer d'optimiser les six dans une seule décision vous livrera, à chaque fois, au fournisseur le plus cher avec des fonctionnalités que vous ne utiliserez jamais.
La précision en contexte — Pourquoi le « benchmark 99 % » ment sur votre audio de production
Chaque fournisseur d'API de reconnaissance vocale publie des numéros de précision. Presque aucun d'eux ne prédit comment l'API fonctionnera sur votre audio de production. Voici pourquoi, et comment tester ce qui compte vraiment.
L'audio de benchmark est propre ; l'audio de production ne l'est pas. Les benchmarks publics comme LibriSpeech se composent de parole de livre audio lue — un seul locuteur, accent neutre, enregistrement propre. Le grand modèle de Whisper signale approximativement 4,7 % WER sur le test-clean de LibriSpeech et environ 8–9 % WER sur test-other, l'ensemble le plus difficile (Radford et al., OpenAI 2022). L'écart sur l'audio réel de production — bruyant, accentué, avec des locuteurs qui se chevauchent — est encore plus large. Si un fournisseur cite le WER sans spécifier le jeu de données et les conditions d'enregistrement, traitez le nombre comme du copié-collé marketing, pas comme des données d'ingénierie.
Le WER est la mauvaise métrique pour de nombreuses applications. La définition standard des directives d'évaluation ASR du NIST est (Substitutions + Suppressions + Insertions) / Mots de référence. Elle traite chaque mot comme également important. Mais mal rendre le nom du médicament d'un patient, un chiffre financier ou le nom d'un témoin au tribunal a des conséquences que supprimer un mot de remplissage n'a pas. L'argument de Jurafsky : évaluer avec des métriques spécifiques à la tâche — précision du remplissage des emplacements pour les assistants vocaux, rappel des termes critiques pour les utilisations médicales et juridiques, précision des entités nommées pour le journalisme. Le WER global peut être de 7 % ; le WER des termes critiques peut être de 22 %. Seul l'un de ces chiffres importe pour vos utilisateurs.
Les performances d'accent et de dialecte varient considérablement. L'étude PNAS citée en haut de ce guide a testé cinq systèmes commerciaux majeurs et a constaté que le WER pour les locuteurs de l'anglais vernaculaire afro-américain était en moyenne 0,35 contre 0,19 pour les locuteurs blancs — à peu près deux fois pire. Ce n'est pas une note de bas de page sur l'équité. C'est un risque commercial : une application qui échoue pour un tiers de sa base d'utilisateurs potentiels parce qu'elle a été QA'd uniquement sur l'anglais américain neutre expédie du brisé. La correction n'est pas de choisir un fournisseur différent (la plupart ont le même écart). La correction est de tester sur l'audio qui représente vos utilisateurs réels avant de signer quoi que ce soit.
Une affirmation de précision de 99 % sur un benchmark vous dit rien sur la façon dont l'API gère vos utilisateurs — ce qui importe est la performance sur votre audio, vos accents et votre vocabulaire de domaine.
La précision du streaming est pire que celle du batch. Les systèmes de streaming émettent des mots provisoires (« partiels ») qui sont réécrits à mesure que plus d'audio arrive. Les systèmes batch attendent l'énoncé complet et affinent. Le WER du streaming est généralement 5–15 % pire que le batch pour le même contenu sur le même moteur. Cet écart n'est presque jamais divulgué dans le marketing du fournisseur. Si vous construisez un produit de transcription en direct, tenez-en compte.
Le code-switching casse la plupart des API. Le code-switching signifie alterner les langues au milieu d'un énoncé : Spanglish, Hinglish, Tagalog-English. Whisper le gère mieux que la plupart parce qu'il a été entraîné sur 680 000 heures d'audio multilingue (Radford et al., 2022). La plupart des API cloud vous obligent à déclarer la langue à l'avance et se dégradent durement quand le locuteur bascule au milieu de la phrase. Si vos utilisateurs parlent plus d'une langue dans la même session, testez ce cas explicitement. Pour les flux de travail multilingues qui nécessitent également une localisation en aval, les plateformes avec IA Dubbing intégré dans 33 langues peuvent réduire la transcription, la traduction et le doublage en un seul pipeline.
Le protocole pilote de 7 jours
Au lieu de faire confiance aux affirmations de précision des fournisseurs, exécutez une épreuve de concept d'une semaine.
- Jours 1–2 : Rassemblez 30 minutes d'audio réel de style production. Incluez votre pire cas : environnements bruyants, locuteurs accentués, jargon de domaine, parole qui se chevauche.
- Jours 3–4 : Transcrivez avec 3 API candidates. Corrigez manuellement une version pour l'utiliser comme transcript de référence.
- Jour 5 : Mesurez le WER global, puis décomposez-le par locuteur, accent et rappel de terme de domaine.
- Jour 6 : Testez le streaming vs. batch sur les mêmes fichiers. Mesurez le delta de précision.
- Jour 7 : Documentez les coûts encourus et la friction d'intégration — complexité de l'authentification, problèmes de SDK, qualité de la réponse aux erreurs.
Un ingénieur écrivant dans ITNEXT a rapporté qu'après avoir ajusté la configuration du microphone et le vocabulaire personnalisé, la reconnaissance vocale moderne produisait moins d'erreurs que leur propre saisie pour la rédaction technique. Le point clé n'est pas qu'une seule API soit magique. C'est que le choix de l'API importe, mais le pipeline audio autour de l'API importe au moins autant. Une excellente API sur un mauvais audio perd contre une API décente sur un audio ajusté.
Latence, streaming et le multiplicateur de coût en temps réel
La latence est l'axe sur lequel les ingénieurs dépensent le plus souvent trop. La transcription en temps réel semble magique dans une démo et coûte 3–5x plus cher que le batch en production. Décidez de ce que vos utilisateurs veulent réellement avant de vous inscrire à une infrastructure de streaming.
- Latence de streaming synchrone (sous-titres en direct, assistants vocaux). Ciblez moins de 1 seconde de bout en bout pour les sous-titres d'accessibilité, 300–800 ms aller-retour pour que les chatbots vocaux semblent conversationnels. Au-delà de 2 secondes et l'illusion du temps réel disparaît. Ces seuils correspondent à la recherche établie sur la perception du temps de réponse par UX (Nielsen Norman Group). Les API de streaming les atteignent via des connexions WebSocket persistantes qui émettent des résultats provisoires à mesure que l'audio arrive.
- Latence de batch asynchrone (uploads de podcast, examen d'appels support, sous-titres YouTube). Des minutes à des heures de temps de traitement est acceptable. Le batch est approximativement 3–5x moins cher par minute d'audio que le streaming chez le même fournisseur, parce que l'infrastructure ne tient pas les connexions ouvertes (documentation de tarification Google Cloud et AWS Transcribe). Pour les flux de travail de créateur téléchargeant du contenu enregistré, le batch est presque toujours correct.
- Hybride / quasi temps réel (brouillon en direct avec correction retardée). Certains flux de travail acceptent une latence de 2–5 secondes en échange d'une précision et d'un coût plus élevés. Un outil de transcription de réunion pourrait afficher du texte brut en 3 secondes et l'affiner en 30. Ce motif utilise le streaming pour la vue en direct et le retraitement batch pour la transcript sauvegardée — souvent via un rappel webhook plutôt que du polling. Les plateformes conçues spécialement pour les flux de travail de médias, comme l'API AI Dubbing de DubSmart, utilisent des rappels webhook pour les travaux terminés plutôt que de forcer votre backend à faire du polling pour l'état (Thread communautaire Make.com sur l'intégration webhook AudioPen).
- Real-Time Factor (RTF) — la métrique de l'ingénieur. Les systèmes de production ciblent RTF < 1,0 pour l'utilisation interactive : traiter 1 seconde d'audio en moins d'1 seconde de temps réel. Les déploiements Whisper sur l'appareil ou accélérés par GPU atteignent approximativement RTF 0,5–0,9 pour les modèles moyens sur les GPU de consommateur. Si votre configuration auto-hébergée s'exécute à RTF > 1,0, le streaming est impossible sans file d'attente.

Le triangle latence-coût-précision est non négociable : vous pouvez en choisir deux. Le streaming sacrifie la précision et le budget pour l'immédiateté. Le batch sacrifie l'immédiateté pour la précision et le coût. Les architectures hybrides deviennent de plus en plus courantes mais ajoutent de la complexité d'intégration. Avant de choisir, posez-vous une question : mes utilisateurs remarqueraient-ils réellement un délai de 5 secondes ? Si la réponse est non, le batch est la bonne architecture et vous venez d'économiser 70 % de vos dépenses annuelles d'API.
Modèles de coûts démystifiés — Par minute vs. Connexions concurrentes vs. Pools de crédits
Il y a trois architectures de tarification sur le marché des API de reconnaissance vocale, et les confondre est l'erreur d'approvisionnement la plus courante.
Paiement par minute (standard batch). Vous êtes facturé par minute d'audio soumis, souvent par incréments de 15 secondes. Simple à prévoir pour les charges de travail prévisibles. L'API Whisper d'OpenAI est approximativement 0,006 $/minute (page de tarification OpenAI) — souvent 3–5x moins cher que les fournisseurs ASR cloud traditionnels, qui se situent autour de 0,02–0,03 $/minute pour les modèles batch anglais standard.
Connexions concurrentes (streaming temps réel). Vous payez par flux ouvert simultané, souvent facturé par minute de connexion ou par emplacement concurrent. C'est là que les factures montent en flèche : si 50 utilisateurs commencent à faire du streaming en même temps, vous payez pour 50 connexions — pas 50 minutes d'audio. Google Cloud et AWS publient des tarifs distincts et plus élevés pour les sessions de streaming vs. les travaux batch hors ligne.
Pools de crédits avec report (charges de travail flexibles). Vous achetez un pool de crédits qui se consomme à des tarifs variables selon les fonctionnalités que vous utilisez (transcription, doublage, clonage vocal, synthèse vocale). Les crédits inutilisés se reportent. Ce modèle s'adapte aux charges de travail variables — un YouTubeur qui télécharge 4 heures une semaine et 40 la semaine suivante n'est pas pénalisé par le pic ou bloqué avec des minutes inutilisées. DubSmart AI utilise ce modèle, regroupant la transcription avec le clonage vocal et la synthèse vocale sous un solde de crédit unique.
Exemple concret — Créateur YouTube :
- 10 vidéos/semaine × 30 min chacune = 300 min/semaine d'audio source
- Transcription batch à 0,006 $/min = 1,80 $/semaine, ou environ 94 $/an
- Ajouter une démo live avec sous-titres en direct (5 heures/mois) à 4x le tarif batch = environ 72 $/an supplémentaires
- Si le créateur double dans 3 langues, le besoin de crédit de transcription + doublage mensuel total est d'environ 5 000 crédits — s'adapte à un plan de pool de crédits de niveau moyen
À tout volume inférieur à 5 000 heures par mois, construire votre propre stack de transcription est moins cher en fantasy qu'en réalité — un niveau API de 50 $ s'expédie en un jour, tandis qu'un déploiement Whisper auto-hébergé s'expédie en un trimestre.
| Fournisseur | Modèle de tarification | Tarif publié | Niveau gratuit |
|---|---|---|---|
| Google Cloud STT | Par incrément de 15 sec ; surcharge streaming | Variable ; hiérarchisé | 60 min/mois |
| AWS Transcribe | Batch par seconde + SKU streaming | Variable par région/modèle | 60 min/mois, 12 mois |
| OpenAI Whisper API | Fixe par minute | ~0,006 $/min | Aucun publié |
| Rev.com (Machine) | Par minute | 0,25 $/min | Aucun |
| Rev.com (Human) | Par minute | 1,50 $/min | Aucun |
| DubSmart AI | Pool de crédits w/ report | Plans hiérarchisés | Niveau gratuit disponible |
Sources : Pages de tarification des fournisseurs OpenAI, Google Cloud, AWS Transcribe, Rev.com.

Trois coûts cachés n'apparaissent presque jamais dans les calculateurs de fournisseur.
Stockage et egress. Si vous stockez les transcriptions et l'audio source dans S3 ou GCS, vous payez le stockage plus la bande passante lors de la récupération. À grande échelle, ceux-ci deviennent des postes non triviaux. Une archive de 1 TB aux tarifs standard avec des relecures fréquentes peut ajouter des centaines de dollars par mois avant que tout appel API ne soit frappé.
La diarisation du locuteur est généralement facturée séparément. AWS Transcribe et AssemblyAI facturent tous les deux l'identification du locuteur comme un poste séparé en plus de la tarification de transcription de base (documentation AWS Transcribe ; documents AssemblyAI). Budgéter uniquement sur le tarif de base par minute sous-estime votre coût réel d'environ 20–40 % si vous avez besoin d'étiquettes de locuteur.
Retry et coûts d'erreur. Les demandes échouées consomment toujours le quota sur certains fournisseurs. Si votre pipeline audio a un taux d'erreur de 2 % à 100 000 minutes/mois, c'est 2 000 minutes de retry facturé — environ 12 $/mois aux tarifs Whisper, mais facilement 60 $/mois sur la STT cloud traditionnelle.
Seuil de rentabilité build vs. buy. L'expérience d'ingénierie des équipes de Mozilla (DeepSpeech), Descript et AssemblyAI suggère que l'auto-hébergement ASR avec Whisper ou Kaldi n'a de sens que > 5 000 heures/mois avec une équipe dédiée ML et DevOps. En dessous de ce volume, l'infrastructure, la maintenance du modèle, les coûts GPU et les frais on-call dépassent la facture API de 50–500 $/mois — souvent par un facteur de cinq ou plus.
Réalités d'intégration — L'audit SDK et API à 9 questions
« Facile à intégrer » est la phrase la plus surchargée de l'économie API. Une API peut être facile à appeler dans une demande curl et infernale à expédier en production. Avant de signer un contrat, exécutez chaque candidat à travers ces neuf questions. Les mauvaises réponses ici prédisent les semaines de gestion des erreurs personnalisée et la logique de retry que vous écrirez plus tard.
- L'API supporte-t-elle à la fois le streaming et le batch dans un SDK ? Certains fournisseurs vous obligent à choisir l'architecture à l'avance, puis facturent pour basculer. Les meilleures API exposent les deux via la même couche d'authentification et vous laissent migrer les charges de travail à mesure que le comportement des utilisateurs évolue. Si votre cas d'utilisation initial est batch mais vous pourriez ajouter des sous-titres en direct dans six mois, cela importe maintenant.
- Que se passe-t-il quand l'API est hors ligne ou limitée en débit ? Testez-le. Envoyez 200 demandes en 1 seconde à un niveau gratuit. Le SDK les met-il en file d'attente, surface-t-il un 429 proprement, ou se bloque-t-il ? Les fournisseurs qui publient les SLA et la sémantique de retry en langage clair vous économisent des semaines de réponse aux incidents. Les fournisseurs qui ne le font pas vous réveilleront à 3 heures du matin.
- Pouvez-vous spécifier la langue audio explicitement, ou utilise-t-elle la détection automatique ? La détection automatique semble amicale mais casse sur l'audio multilingue ou avec code-switching. Pour les constructions de production, spécifiez toujours la langue et retombez sur la détection automatique uniquement quand la confiance est basse. Les API qui ne vous laissent pas définir la langue explicitement sont pré-conçues pour échouer sur vos cas limites.
- Supporte-t-elle la diarisation du locuteur prêt à l'emploi ? La diarisation est souvent un module complémentaire à prix séparé. AssemblyAI et AWS Transcribe facturent tous les deux séparément. Vérifiez si votre fournisseur retourne des étiquettes de locuteur au niveau du segment ou au niveau du mot — la différence importe pour l'analyse, la recherche et tout résumé en aval.
- Peut-elle signaler ou rédiger les PII (numéros de carte de crédit, numéros de sécurité sociale, noms) ? La plupart des API orientées entreprise (AWS Transcribe, AssemblyAI) supportent la rédaction PII. Whisper et Web Speech API ne le font pas. Pour les applications healthcare ou financières, ce n'est pas un nice-to-have.
- Webhooks callbacks ou polling pour les travaux async ? Les webhooks sont la norme moderne. Le polling génère des appels API inutiles et des coûts. Les plateformes matures émettent des événements webhook à la fin du travail — le motif montré dans le thread communautaire Make.com sur l'intégration AudioPen où la fin de transcription déclenche l'automation en aval.
- Quelles sont les limites maximales de taille de fichier et de durée par demande ? De nombreuses API cloud limitent les demandes individuelles à 15 minutes ou à peu près 1 heure avec des limites de taille de fichier dans les dizaines à centaines de MB (documentation Google Cloud Speech-to-Text ; documentation AWS Transcribe). L'audio de longue durée — podcasts de deux heures, dépôts, enregistrements de conférence — doit être divisé. Les passerelles HTTP appliquent souvent des délais d'expiration de 15 minutes indépendamment des limites propres de l'API.
- Les scores de confiance sont-ils exposés au niveau du mot ? La confiance au niveau du mot vous permet de signaler les régions de basse confiance pour examen humain ou correction interactive. Les API qui retournent du texte brut sans confiance vous obligent soit à faire confiance à tout, soit à re-transcrire. Pour tout flux de travail avec examen humain en boucle, cette fonction est la différence entre une file d'attente QA utilisable et un mur de texte illisible.
- Quelle est la qualité du SDK dans votre langage ? Un SDK Node.js ou Python avec typage fort, logique de retry et classes d'erreur propres vaut une prime de 30 % de prix sur une API que vous devez HTTP brut en production. Testez le SDK avant de vous engager sur l'API. Écrivez une petite intégration. Mesurez-la. Le SDK que vous aimez vraiment utiliser économisera plus d'heures d'ingénierie que le tarif par minute moins cher ne vous en économise jamais en dollars.
L'open-source vs. propriétaire reste le plus grand fork d'intégration.
Open-source (Whisper, Vosk). Coût zéro par appel, contrôle total, fonctionnement hors ligne. Vous possédez l'hébergement, la mise à l'échelle, l'approvisionnement GPU, les mises à jour du modèle, l'observabilité et l'incident 3 heures du matin. Déploiement réaliste pour une équipe de 5+ avec capacité ML et DevOps.
Cloud propriétaire (Google, AWS, AssemblyAI, OpenAI Whisper API, DubSmart). Vous échangez le coût par minute contre la fiabilité, SLA, versioning et support SDK. Pour la plupart des équipes en dessous de 5 000 heures/mois, le propriétaire gagne sur le coût total de possession. Les plateformes qui regroupent la reconnaissance vocale avec l'API Text to Speech et l'API Voice Cloning sous un SDK réduisent davantage la zone de surface d'intégration — un flux d'authentification, un modèle d'erreur, un tableau de bord de facturation pour le pipeline médias complet.
Niveau plateforme sur l'appareil (Apple SpeechAnalyzer, WWDC 2025). Une catégorie plus nouvelle. Préservation de la confidentialité, capable hors ligne, mais la précision et la couverture de langue peuvent être à la traîne des modèles cloud. Meilleur pour les applications mobile-first où la confidentialité est un actif marketing, pas seulement une case de conformité.
La question d'intégration qui bat tous les autres : à quelle vitesse pouvez-vous expédier ? Une API basée sur les crédits bien documentée qui regroupe la reconnaissance vocale, le clonage vocal et le doublage sous un SDK bat souvent une API STT autonome moins chère une fois que vous tenez compte de la deuxième et de la troisième fonctionnalités dont vous aurez besoin dans six mois.
Comparaison tête-à-tête des fournisseurs — Quand choisir chaque API de reconnaissance vocale
Ceci est un scan de référence rapide, pas un examen exhaustif. Chaque entrée couvre le cas d'utilisation idéal, la faiblesse principale, le moteur de coût dominant et le caractère d'intégration. Les sources pour les réclamations de tarification et de fonctionnalités sont la documentation des fournisseurs à partir de fin 2024.
Google Cloud Speech-to-Text
- Meilleur pour : Transcription en anglais de haute précision, équipes déjà dans GCP, charges de travail d'entreprise avec volume prévisible.
- Faiblesse : La tarification du streaming s'escalade rapidement ; les niveaux de langue créent une incohérence de précision pour l'audio non-anglais.
- Moteur de coût : Par incréments de 15 secondes avec un SKU de streaming séparé (plus élevé) ; 60 min/mois niveau gratuit.
- Intégration : Authentification GCP native via comptes de service. Les applications non-GCP font face à une surcharge IAM. Les SDK matures pour tous les langages majeurs.
AWS Transcribe
- Meilleur pour : Charges de travail batch à grande échelle, équipes natives AWS, pipelines de contenu multi-langues, analyse de centres d'appels.
- Faiblesse : La latence du streaming est légèrement plus élevée que les concurrents spécialistes du streaming. Diarisation et modèles médicaux facturés séparément.
- Moteur de coût : Durée audio en secondes, avec SKU séparés pour streaming, modèles médicaux et modules complémentaires d'analyse d'appels.
- Intégration : Lourd en IAM. Direct si vous êtes déjà natif AWS. Bien documenté mais verbeux.
OpenAI Whisper API
- Meilleur pour : Constructions conscientes du budget, contenu multilingue avec code-switching, équipes qui veulent pas de verrouillage de fournisseur au-delà d'OpenAI lui-même.
- Faiblesse : Pas de support natif de streaming. Pas de remises de volume. Pas d'engagements SLA comparables à AWS ou GCP.
- Moteur de coût : Fixe 0,006 $/minute sans frais de connexion concurrente et sans remise d'entreprise hiérarchisée publiée.
- Intégration : API HTTP la plus simple du marché. Multilingue sans déclaration de langue grâce aux 680 000 heures de données d'entraînement documentées dans l'article Whisper.
AssemblyAI
- Meilleur pour : Équipes orientées développeur, streaming temps réel avec latence minimale, sortie structurée avec horodatages au niveau du mot, étiquettes de locuteur et scores de confiance.
- Faiblesse : Tarification premium. La densité de fonctionnalités est exagérée pour les cas d'utilisation batch simple.
- Moteur de coût : Connexions streaming concurrentes plus modules complémentaires de diarisation.
- Intégration : Excellents SDK et documentation. Architecture webhook-first. Outils d'observabilité forts.
Rev.com (Hybrid Machine + Human)
- Meilleur pour : Flux de travail où la précision est non négociable et le délai d'exécution peut attendre des heures — dépôts juridiques, journalisme, contenu critique d'accessibilité.
- Faiblesse : Pas en temps réel. L'examen humain prend des heures. Cher à grande échelle.
- Moteur de coût : 0,25 $/minute pour machine, 1,50 $/minute pour examen humain.
- Intégration : API REST simple. La friction est le délai d'exécution, pas l'intégration elle-même.
DubSmart AI Speech to Text API
- Meilleur pour : Créateurs de contenu et équipes construisant des flux de travail multilingues où la transcription est une étape dans un pipeline plus long — transcrire, traduire, doubler, publier. La tarification basée sur les crédits absorbe les charges de travail variables.
- Faiblesse : Plateforme plus jeune que les hyperscalers hérités. Les termes SLA d'entreprise peuvent ne pas correspondre à AWS ou GCP pour les équipes de procurement averses aux risques.
- Moteur de coût : Pool de crédits avec report. Regroupe transcription avec clonage vocal à partir d'un échantillon de 20 secondes, 300+ voix TTS et AI Dubbing dans 60+ langues sources vers 33 langues cibles.
- Intégration : Conçue spécialement pour les flux de travail médias. Un SDK couvre transcription + TTS + clonage + doublage. Callbacks webhook pour travaux async. De confiance pour 500 000+ utilisateurs.
Votre liste de contrôle pour la sélection de l'API de reconnaissance vocale
Ceci est le flux de travail à exécuter avant de signer un contrat. Il comprime tout ce qui précède en huit étapes exécutables. Bloquez quatre heures pour la première passe ; attendez une semaine de tests pilotes à l'étape 4.
- Définissez votre cas d'utilisation dominant en une phrase. Écrivez-la : « J'ai besoin de transcrire des podcasts » ou « sous-titrer des flux en direct » ou « analyser des appels de vente » ou « doubler des vidéos téléchargées par l'utilisateur ». Si vous ne pouvez pas l'écrire en une phrase, vous avez deux produits et avez besoin de deux évaluations. Faites correspondre le cas d'utilisation au niveau de latence de la Section 3 et à la demande de précision de la Section 2 avant de regarder la tarification d'un fournisseur.
- Encerclez les deux ou trois axes de décision qui importent le plus. Du cadre : précision, latence, hors ligne, couverture de langue, modèle de coût, zone de surface d'intégration. Si vous essayez d'optimiser les six, vous choisirez le fournisseur le plus cher avec des fonctionnalités que vous ne utiliserez jamais. La plupart des constructeurs devraient classer le modèle de coût et la zone de surface d'intégration en premier. La précision et la latence deviennent des brise-égalité entre les finalistes.
- Projetez le volume sur 12 mois avec un tampon de surge 3x. Estimez les minutes mensuelles pour le mois 1, le mois 6 et le mois 12. Multipliez le nombre du mois 12 par 3 pour gérer les pics de lancement et la croissance virale. Ce nombre détermine si vous avez besoin d'un pool de crédits, d'une tarification par minute ou d'un contrat d'entreprise à prix réduit — et c'est le nombre que vous citerez aux fournisseurs lors de la négociation.
- Exécutez le pilote de 7 jours. Trente minutes de votre vrai audio, trois API candidates, noté manuellement par rapport à une transcription de référence unique corrigée par humain. Mesurez le WER par locuteur, par accent et par terme de domaine — pas seulement en agrégé. Testez le streaming vs. batch sur les mêmes fichiers. Documentez la friction du SDK dans un document partagé en chemin, tandis que la douleur est fraîche.
- Stress-testez la gestion des erreurs. Envoyez audio malformé, jetons expirés, rafales qui dépassent les limites de débit et fichiers surdimensionnés. Le SDK échoue-t-il proprement avec des erreurs actionnables, ou se bloque-t-il ? Une API qui échoue mal sous stress contrôlé échouera mal en production à 3 heures du matin, et le coût du nettoyage dépassera infiniment tout économie par minute que vous avez verrouillée à la signature.
- Calculez le coût total réel de possession. Incluez le coût par minute de base, les surcharges de streaming, les modules complémentaires de diarisation, le stockage, l'egress, la surcharge de retry et les heures d'ingénierie économisées ou perdues par la qualité du SDK. Comparez à un modèle de pool de crédits si votre charge de travail est variable — un plan de crédits approximativement à 99 $/mois bat souvent la tarification de 0,006 $/minute quand le trafic est saccadé et regroupe plusieurs fonctionnalités médias sous une seule facture.
- Auditez la confidentialité et les paramètres par défaut de rétention des données. Confirmez si le fournisseur retient l'audio et les transcriptions pour l'amélioration du modèle, et si vous pouvez refuser contractuellement. Les exigences GDPR, HIPAA et SOC 2 peuvent éliminer les fournisseurs indépendamment du prix. Selon les directives du Conseil européen de la protection des données sur les assistants vocaux, les fournisseurs STT cloud peuvent créer des « ensembles de données fantômes » de données vocales sauf s'ils sont explicitement restreints par contrat — c'est une question d'approvisionnement, pas une question de fonctionnalité.
- Négociez avant de vous engager. La plupart des fournisseurs offrent des remises de 15–30 % aux engagements de 12 mois au-dessus de 500 heures/mois. Si vous avez complété les étapes 1–7 avec confiance, vous avez du levier. Demandez une tarification verrouillée, un contact d'assistance dédié, un niveau gratuit étendu pour les environnements de staging, et une clause de sortie si la précision se dégrade en dessous d'un seuil convenu. Si votre feuille de route inclut la localisation, évaluez les API comme l'API AI Dubbing qui traduisent et doublent en un appel.
Cette liste de contrôle est votre défense contre le marketing des fournisseurs et votre attaque contre les délais d'expédition. Les équipes qui expédient les fonctionnalités vocales le plus rapidement ne sont pas celles qui ont choisi l'API la moins chère — ce sont celles qui ont exécuté un pilote réel, calculé le TCO réel et choisi une zone de surface d'intégration avec laquelle leurs développeurs voulaient travailler. Si votre construction implique également le doublage, le clonage vocal ou la génération de parole synthétique, évaluez les plateformes qui regroupent Text to Speech, le clonage vocal et le doublage sous un solde de crédit unique et un SDK unique — la deuxième et la troisième fonctionnalités dont vous aurez besoin dans six mois coûteront moins cher et s'expédieront plus vite.