
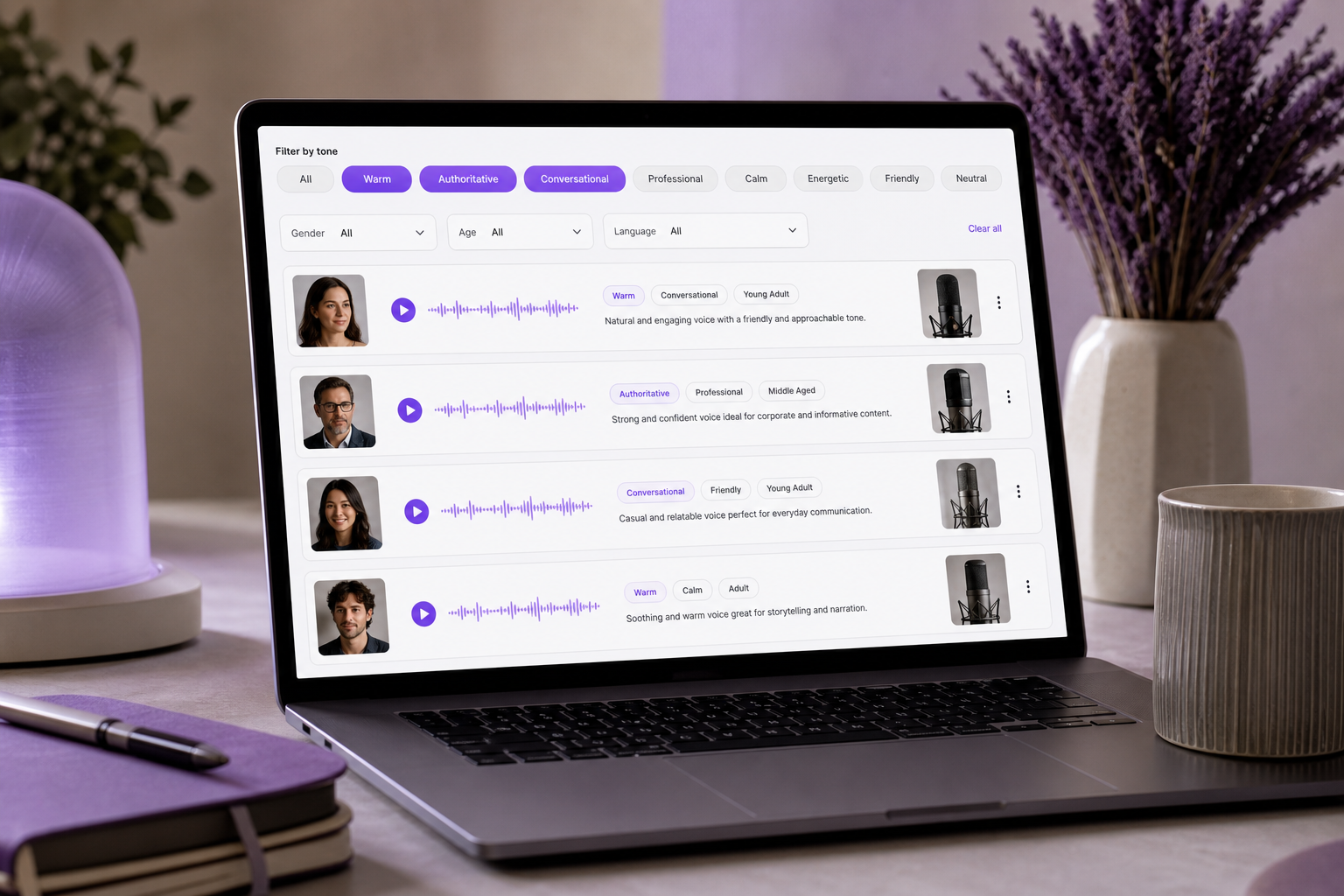
Has pasado de largo cuarenta muestras de voz. Con los auriculares puestos, tocas la vista previa, escuchas durante tres segundos, tocas la siguiente, y la siguiente, hasta que todas las muestras se difuminan en el mismo zumbido indistinto. ¿Esta es "cálida" o simplemente "suave"? ¿El explicativo debería sonar "autoritario" o "amigable"? El problema no es la falta de opciones — las bibliotecas modernas tienen más de 300 voces, y puedes audicionarlas durante una hora sin decidirte por ninguna. El problema son los descriptores de voz: el vocabulario preciso que necesitas para distinguir una voz de otra y adecuarla a tu contenido con intención. Sin ese vocabulario, la selección de voz se convierte en adivinanza y el doblaje se vuelve un costoso ensayo y error. Según WP SEO AI, las etiquetas de una sola palabra como "natural" o "atractiva" son demasiado vagas para ser accionables — un retrato vocal claro requiere especificar múltiples dimensiones que interactúan a la vez. Al final de este artículo, podrás describir cualquier voz con precisión a través del tono, el timbre (pitch) y el estilo, para que puedas buscar, filtrar y guiar herramientas de voz — o redactar un briefing de un proyecto de clonación — con confianza en lugar de con suerte.

Índice de contenidos
- Las cuatro dimensiones bajo las que cae todo descriptor de voz
- Descriptores de tono descifrados — De "cálido" a "autoritario"
- Pitch y ritmo — Los descriptores técnicos que la gente confunde
- Estilo y registro — Adecuar la voz al contexto del contenido
- Apilar descriptores en una búsqueda o prompt de voz preciso
- Errores de descriptores — Dónde la selección de voz falla silenciosamente
- Tu plantilla de briefing de descriptores de voz para copiar y pegar
- Preguntas sobre descriptores de voz que los creadores realmente hacen
Las cuatro dimensiones bajo las que cae todo descriptor de voz
Todo descriptor de voz que hayas leído alguna vez — por poético que sea — se reduce a cuatro dimensiones medibles. Una vez que puedes nombrarlas, el vocabulario deja de parecer subjetivo y empieza a comportarse como un conjunto de controles que puedes ajustar de forma independiente.
El tono es el color emocional o la actitud de la voz. Cálido, frío, entusiasta, distante — es el carácter emocional que siente el oyente antes de procesar el significado de una sola palabra. Es la dimensión que decide si tu audiencia se inclina hacia adelante o desconecta.
El pitch es la percepción de agudeza o gravedad del sonido. Un barítono profundo y resonante se sitúa en un extremo; un sonido brillante, ligero y juvenil se sitúa en el otro. El pitch es fundamentalmente una propiedad de frecuencia, lo que lo convierte en uno de los descriptores más objetivos de los cuatro — pero también es uno de los que se confunden más a menudo con el ritmo.
El ritmo y la cadencia describen la velocidad del habla y su compás. Rápido, mesurado, pausado, deliberado — el ritmo incluye las pausas entre frases y los patrones de inflexión que cabalgan sobre ellas. Dos voces leyendo guiones idénticos a distintos ritmos pueden sentirse como interpretaciones completamente diferentes.
El estilo y el registro gobiernan el contexto de interpretación y la formalidad. Narración, conversacional, locución radiofónica, e-learning — formal frente a casual. Esta es la dimensión que decide qué papel está interpretando la voz para el oyente.
Esta taxonomía no es una opinión personal. Nielsen Norman Group formaliza el tono a lo largo de cuatro ejes independientes — formal vs. casual, serio vs. divertido, respetuoso vs. irreverente, y objetivo vs. entusiasta — demostrando que el tono es multieje, no un único deslizador que arrastras de "aburrido" a "divertido". Las plataformas comerciales operacionalizan la misma lógica. El mercado de voces Voices.com agrupa la descripción vocal en cuatro cualidades: pitch y tono, volumen y proyección, articulación y enunciación, y velocidad e inflexión. Etiquetas diferentes, misma estructura subyacente.

¿Por qué importa tanto separar las dimensiones? El coach de comunicación Robin Kermode plantea el tono, el pitch y el ritmo como las tres palancas que juntas crean "variedad vocal" — definiendo el tono como carácter emocional, el pitch como la frecuencia percibida que puede alterar el significado emocional, y el ritmo como la velocidad de entrega. El estilo y el registro forman la cuarta palanca, y se sitúa por encima de las otras tres, gobernando el contexto en el que operan. Dicho de forma simple: el tono, el pitch y el ritmo describen cómo suena la voz; el estilo y el registro describen qué papel está desempeñando.
Todo descriptor de voz que hayas leído alguna vez se reduce a cuatro palancas — tono, pitch, ritmo y estilo. Domina las palancas y dejarás de adivinar.
Aférrate a este modelo. Cada sección que sigue profundiza en exactamente una de estas cuatro dimensiones, y ninguna de ellas redefinirá el marco. Cuando te encuentres con un descriptor en cualquier lugar — un filtro de un mercado, un campo de prompt de IA, un briefing de agencia — tu primera tarea es encajarlo en uno de los cuatro cubos. Ese único hábito convierte un muro de adjetivos en un panel de control organizado.
Descriptores de tono descifrados — De "cálido" a "autoritario"
El tono es la dimensión que las audiencias registran primero, y es la que más comúnmente se redacta mal en los briefings porque se apoya en adjetivos subjetivos. La investigación de Nielsen Norman Group muestra que el tono opera a través de múltiples ejes independientes — el humor, la formalidad, la cortesía y el entusiasmo son palancas separadas — lo que significa que una sola palabra de tono rara vez captura lo que realmente quieres. En su lugar, agrupa tus descriptores de tono en clústeres, y obtendrás tanto precisión como una forma práctica de filtrar.
Generador de confianza (cálido, amigable, tranquilizador). Este clúster construye seguridad emocional antes de que aterrice el significado. Es la opción correcta para explicativos de salud, IVR de atención al cliente y vídeos de onboarding donde el oyente necesita sentirse acogido antes de absorber instrucciones. WP SEO AI incluye "cálido" entre los adjetivos de tono emocional más usados, y por buena razón — es la base que la mayoría de las audiencias confía por defecto.
Enérgico (animado, entusiasta, vivaz). Este clúster señala impulso y emoción. Es el mejor para lanzamientos de producto, lecturas de anuncios y cortos de redes sociales donde los dos primeros segundos deciden si alguien sigue viendo. El eje "entusiasta" de NN/g se corresponde directamente aquí — y fíjate en que es independiente de la formalidad, así que puedes ser enérgico y profesional al mismo tiempo.
Serio (autoritario, profesional, sombrío). Este clúster transmite credibilidad y peso. Recurre a él en formación corporativa, explicativos financieros y narración de documentales donde la audiencia necesita confiar en que quien habla sabe más que ellos. "Autoritario" es un descriptor estrella en la lista de retratos vocales de WP SEO AI — es lo suficientemente específico para filtrar y lo suficientemente amplio para aplicarse en todos los formatos.
Íntimo (suave, relajante, conversacional). Este clúster crea cercanía y calma. Está hecho para apps de meditación, intros de pódcast y contenido estilo ASMR donde el oyente suele estar solo y la voz se siente como si le hablara directamente. La intimidad proviene tanto de la contención como de la calidez — este clúster se retrae en lugar de proyectar.
El tono es la única dimensión que las audiencias notan primero y olvidan al final — establece la confianza emocional antes de que aterrice el significado de una sola palabra.
Estos clústeres no son solo un modelo mental — son la forma en que las herramientas modernas te permiten buscar. Una plataforma de TTS como SymTrain documenta el filtrado de voces por tono como "articulado, casual, ansioso", reduciendo una biblioteca grande antes de que siquiera toques la vista previa. Esa es la ventaja práctica de agrupar tus descriptores de voz: de la misma forma en que una biblioteca de Texto a Voz te permite filtrar por tono antes de previsualizar, un clúster de tono claro convierte una hora de audición en una lista corta y enfocada de tres.
Pitch y ritmo — Los descriptores técnicos que la gente confunde
El pitch y el ritmo son las dos dimensiones más confundidas en cualquier briefing de voz, y la confusión les cuesta tiempo real a los creadores. El pitch es frecuencia — la percepción de agudeza o gravedad de una voz. El ritmo es velocidad y cadencia — palabras por minuto, compás y la colocación de las pausas. La división de tres vías de Robin Kermode los mantiene claros: el tono es carácter emocional, el pitch es frecuencia percibida, el ritmo es velocidad del habla. Tres cosas distintas.
El error clásico es intercambiar el vocabulario. Los creadores dicen "rápido" cuando quieren decir "agudo", o "profundo" cuando quieren decir "lento". Estos son controles independientes. Una voz profunda puede ser ágil. Una voz aguda puede ser mesurada. Tratarlos como un adjetivo difuso único es como los briefings salen mal antes de que nadie grabe una sílaba.
| Descriptor | Qué controla | Cómo suena | Mejor para |
|---|---|---|---|
| Profundo | Pitch (frecuencia baja) | Barítono, resonante | Documental, marca de lujo |
| Brillante | Pitch (frecuencia alta) | Ligero, etéreo, juvenil | Contenido infantil, anuncios animados |
| Mesurado | Ritmo (lento/uniforme) | Deliberado, espacioso | E-learning, tutoriales |
| Ágil | Ritmo (rápido) | Enérgico, urgente | Noticias, promos |
| Cortante | Ritmo + articulación | Nítido, paradas precisas | Técnico, instructivo |
| Arrastrado | Ritmo (lento/relajado) | Estirado, casual | Narración, personaje |
El trabajo interesante ocurre cuando el pitch y el ritmo se combinan, porque la impresión compuesta es casi siempre más fuerte que cualquiera de los descriptores por separado. Un pitch profundo con un ritmo ágil se lee como urgencia segura — la voz de alguien que conoce el material y no te hace perder el tiempo. Un pitch brillante con un ritmo mesurado se lee como paciencia amigable — ideal cuando estás guiando a un usuario nervioso a través de una primera configuración. Intercambia las combinaciones y el significado se invierte por completo, que es exactamente por lo que no puedes colapsar los dos campos en uno.
Esta separación está integrada en cómo las plataformas serias estructuran sus directrices. Voices.com trata el pitch/tono y la velocidad/inflexión como dos de sus cuatro cualidades distintas, nunca como un único ajuste. La documentación de la API de Hamsa lista de forma similar el ritmo de habla y la pronunciación/claridad como criterios de selección separados, cada uno evaluado por sí mismo antes de que una voz entre en producción. La conclusión para el profesional es directa: en cualquier briefing, dale al pitch y al ritmo sus propios campos. Escribe "pitch profundo, ritmo ágil", no "una voz profunda con garra" esperando que el lector lo desenrede. Y recuerda que los mismos rasgos de pitch y ritmo que especificas aquí son los que un modelo de Clonación de Voz preserva de una muestra de origen — así que acertar con el vocabulario en la etapa del briefing se traslada hasta el resultado clonado.
Estilo y registro — Adecuar la voz al contexto del contenido
La habilidad de mayor apalancamiento en la selección de voz no es elegir la voz más impresionante. Es elegir el estilo y el registro adecuados para el contexto de entrega — la voz que tu audiencia espera y nunca cuestiona. La guía del sistema de diseño de PatternFly separa el estilo (elecciones de gramática y sintaxis), la voz (personalidad de marca) y el tono (el estado emocional del usuario), y el paralelismo con la voz hablada se mapea limpiamente: el estilo y el registro por un lado, el tono emocional por el otro. Equivócate con el registro e incluso una voz hermosa se sentirá fuera de lugar.
La documentación de Hamsa concreta la distinción de estilo con justificación explícita de casos de uso. "Conversacional" es natural y amigable — mejor para atención al cliente y soporte. "Narrador" es claro y articulado — adecuado para explicaciones. Ese encuadre de "cómo suena / mejor para" es exactamente lo que convierte el estilo en una decisión que puedes tomar en segundos en lugar de debatir durante una tarde.
| Tipo de contenido | Descriptor de estilo recomendado | Por qué funciona |
|---|---|---|
| Explicativo de YouTube | Conversacional | Natural, amigable — mantiene enganchados a los espectadores casuales |
| Formación corporativa | Narrador | Claro, articulado — adecuado para explicaciones |
| Intro de pódcast | Conversacional / locución | Establece una presencia de anfitrión cálida y familiar |
| Audiolibro | Narrador | Claridad sostenida durante la escucha de formato largo |
| Anuncio / promo | Locución enérgica | Proyecta impulso y una llamada a la acción |
Bajo el estilo se asienta el registro — la elección de formal frente a casual que sazona todo lo que tiene por encima. El eje formal↔casual de NN/g es la forma más limpia de pensarlo: el mismo estilo conversacional puede leerse como un pulido anfitrión de locución o como un amigo hablando al otro lado de la mesa, según dónde sitúes el dial del registro. Un narrador de formación corporativa en un registro casual se siente accesible; el mismo narrador en un registro formal se siente institucional. Ninguno está mal — son respuestas a briefings diferentes.
Dos capas más se apilan encima. El acento y el dialecto son criterios de selección fundamentales en la lista de verificación de Hamsa, y cargan con un peso cultural que ningún descriptor de tono puede anular — una voz "US neutro" y una voz "RP británico" pueden compartir un tono, pitch y ritmo idénticos y aun así aterrizar de forma completamente diferente en una audiencia. SymTrain recomienda filtros por grupo de edad — joven, adulto, mayor — junto con el tono, porque la edad percibida cambia lo autoritaria o cercana que se siente una voz.
El descriptor de estilo adecuado no es la voz más impresionante — es la que tu audiencia espera escuchar en ese momento y nunca cuestiona.
El punto más afilado de PatternFly es que el estilo y el tono deben responder al estado emocional de la audiencia, no a un valor por defecto a nivel de marca. El contenido de resolución de problemas necesita un registro neutral y servicial; un anuncio necesita uno entusiasta. El contexto dicta el registro siempre. Y las decisiones de registro no se quedan quietas cuando tu contenido viaja — un registro casual y conversacional que aterriza perfectamente en inglés puede leerse como frívolo o poco profesional en otro mercado. Esa es una elección de registro que tiene que aguantar cuando empujas el contenido a través de Doblaje con IA a otros idiomas, que es exactamente donde la siguiente capa de disciplina da sus frutos.
Apilar descriptores en una búsqueda o prompt de voz preciso
El vocabulario solo importa si puedes convertirlo en un método repetible. La investigación es consistente en el principio fundamental: los descriptores apilados superan a las etiquetas individuales todas las veces. WP SEO AI recomienda combinar adjetivos de tono emocional como "cálido", "nítido" o "autoritario" con detalles concretos sobre ritmo, variación de pitch, resonancia y claridad para construir un retrato vocal claro. Voices.com formaliza un proceso de tres pasos — definir el personaje (edad, género, estilo), establecer el tono y luego elegir palabras clave adecuadas. Aquí tienes esa lógica desglosada en siete pasos que puedes ejecutar cada vez.
- Define el objetivo emocional. Nombra el sentimiento con el que la audiencia debería marcharse — confianza, emoción, calma. Todo lo que viene después sirve a esta única decisión.
- Elige un clúster de tono. Escoge entre los cuatro clústeres: generador de confianza, enérgico, serio o íntimo. Resiste la tentación de mezclar clústeres en conflicto — ahí es donde los briefings se desmoronan.
- Establece el rango de pitch. Profundo, medio o brillante. Una palabra, no un párrafo.
- Establece el ritmo. Mesurado, ágil o cortante. Mantenlo separado del pitch.
- Fija el estilo y el registro. Conversacional, narrador o locución — luego formal o casual.
- Añade capas de demografía y acento. Agrega el grupo de edad y el dialecto, tal como esperan los filtros de SymTrain y Hamsa.
- Pruébalo contra 2 o 3 muestras. La lista de verificación de Hamsa — pronunciación, claridad, ritmo, tono, acento — es tu última puerta de validación antes de que se publique cualquier cosa.

Así es como se ve el stack terminado como una sola cadena: cálido + pitch medio + ritmo mesurado + estilo conversacional + femenino + treintañera + acento US neutro. Esa única línea cumple una doble función. Colócala en una barra de búsqueda y reduce drásticamente tu tiempo de filtrado en una biblioteca de más de 300 voces a un puñado de candidatas. Alimenta esa misma cadena apilada en un preset de TTS y se convierte en un prompt de generación. La disciplina de escribirla una vez es lo que te ahorra tener que re-audicionar todo el catálogo. Y como el formato es consistente, la misma cadena apilada que alimentarías a un preset de TTS puede pasar directamente a una llamada a una API de Clonación de Voz — un briefing, múltiples destinos, cero retraducción entre herramientas.
Errores de descriptores — Dónde la selección de voz falla silenciosamente
La mayoría de los proyectos de voz no fallan en la etapa de grabación. Fallan en el briefing, de formas que son invisibles hasta que estás escuchando un archivo terminado que, de algún modo, está mal. Estos son los modos de fallo que no aparecen hasta que es caro arreglarlos.
Sobreapilar descriptores contradictorios. "Enérgico pero relajante" se cancela a sí mismo — la voz no puede esprintar y susurrar al mismo tiempo. La investigación de NN/g es útil aquí: el humor, el respeto y el entusiasmo son palancas independientes, así que muchas combinaciones funcionan bien, pero algunas genuinamente entran en conflicto. La solución es elegir un clúster de tono dominante y refinar dentro de él en lugar de cruzar entre clústeres buscando una variedad que no necesitas.
Tratar "natural" como una dirección. "Natural" y "atractivo" parecen instrucciones, pero no son accionables. WP SEO AI argumenta que esos términos genéricos fallan tanto para las herramientas de IA como para el talento remoto porque no especifican ninguna de las dimensiones que interactúan. La solución es reemplazar cada cajón de sastre con el stack de cuatro dimensiones — tono, pitch, ritmo, estilo — más la demografía. Si un descriptor no encaja en uno de esos cubos, no es una dirección.
Asumir que los descriptores se traducen entre idiomas. El tono percibido cambia cuando doblas a otro idioma y cultura — un registro que se lee como cálido en inglés puede aterrizar como excesivamente familiar en otro lugar. La solución es re-validar el tono por cada idioma de destino en lugar de confiar en que el descriptor de origen se traslade. Cuando estás doblando a 33 idiomas de destino, las verificaciones de tono por idioma no son un pulido opcional; son la diferencia entre contenido que conecta y contenido que aliena sutilmente. Por eso los equipos que pasan contenido a través de una API de Doblaje con IA revuelven a comprobar el tono por cada idioma de destino en lugar de asumir que el briefing original sigue siendo válido.
Ignorar el contexto emocional de la audiencia. PatternFly advierte que un tono de talla única falla — un flujo de resolución de problemas necesita una voz neutral y servicial, mientras que un anuncio necesita una entusiasta. La solución es elegir descriptores para el momento en el que está tu audiencia, no el valor por defecto a nivel de marca que estableciste hace seis meses.
Saltarse el briefing y confiar en la intuición. El enfoque de guía de tono de Ed Gandia critica las directivas vagas exigiendo parámetros concretos — audiencia, especificidades de tono como "cálido pero no charlatán", formalidad, longitud de las frases y patrones recurrentes. La solución es la más simple de todas: escribe el briefing apilado antes de previsualizar una sola voz. La intuición está bien para elegir entre dos finalistas. Es terrible para reducir 300 a 3.

"Natural" no describe nada — es la expectativa por defecto, no una dirección creativa.
Tu plantilla de briefing de descriptores de voz para copiar y pegar
Aquí tienes la versión operativa de todo lo anterior — una estructura para rellenar los espacios en blanco que puedes pegar en cualquier herramienta de voz, briefing de agencia o solicitud de clonación. Es el modelo de cuatro dimensiones más la demografía, formateado para que nunca tengas que reconstruirlo desde cero. Trátalo como la única fuente de verdad para los descriptores de voz de un proyecto.
BRIEFING DE DESCRIPTORES DE VOZ
----------------------------------------
Objetivo emocional: ____ (qué debería sentir la audiencia)
Clúster de tono: ____ (generador de confianza / enérgico / serio / íntimo)
Pitch: ____ (profundo / medio / brillante)
Ritmo: ____ (mesurado / ágil / cortante)
Estilo / registro: ____ (conversacional / narrador / locución; formal / casual)
Demografía: ____ (género, grupo de edad)
Acento / idioma: ____ (dialecto + idiomas de destino)
Voz de referencia: ____ (opcional — una voz conocida para anclar expectativas)
Esta estructura no es arbitraria. Refleja el conciso resumen de voz de 3 a 5 frases de Ed Gandia emparejado con parámetros específicos de tono, formalidad y cadencia, y sigue el proceso personaje → tono → palabra clave de Voices.com en el orden en que realmente tomas las decisiones. Rellénalo de arriba abajo y cada campo estrecha al siguiente.
Aquí tienes la plantilla rellenada para un escenario real — La intro de un canal de YouTube multilingüe:
- Objetivo emocional: bienvenida confiada
- Clúster de tono: generador de confianza / cálido
- Pitch: medio
- Ritmo: ágil
- Estilo / registro: locución conversacional
- Demografía: femenina, treintañera
- Acento / idioma: inglés US neutro, doblado a español + portugués
- Voz de referencia: ninguna
Ese único briefing de voz cumple tres trabajos sin modificación. Estrecha tu búsqueda en la biblioteca a una lista corta. Se convierte en el prompt que impulsa la generación de TTS. Y se traslada al paso de doblaje, donde los mismos descriptores se re-validan por cada idioma de destino en lugar de reconstruirse desde cero. Un briefing, tres resultados, sin re-briefing.
La ventaja práctica de este enfoque aparece cuando tus herramientas viven en un solo lugar. Cuando Texto a Voz, clonación de voz y doblaje comparten un flujo de trabajo, el mismo briefing de descriptores que impulsa una vista previa puede pasar directamente a una solicitud de API de Texto a Voz — y luego adelante hacia el doblaje — en lugar de ser re-escrito y re-interpretado en cada etapa. Escribe el briefing una vez. Úsalo en todas partes.
Preguntas sobre descriptores de voz que los creadores realmente hacen
¿Cuál es la diferencia entre tono y timbre en los descriptores de voz?
El tono es el carácter emocional de una voz — cálido, serio, distante. El timbre es la textura o cualidad única del sonido en sí — suave, áspero, sedoso, duro. WP SEO AI lista la textura como una dimensión de descriptor separada del tono emocional, y la distinción importa en la práctica: dos voces pueden compartir exactamente el mismo tono y aun así tener timbres completamente diferentes. Cuando una voz se siente bien emocionalmente pero de algún modo está mal, el timbre suele ser la variable que aún no has nombrado.
¿Se traducen con precisión los descriptores de voz al doblar a otros idiomas?
No automáticamente. El tono percibido puede cambiar entre idiomas y culturas, así que el registro cálido y casual que funciona en inglés puede aterrizar de forma diferente en otro mercado. La jugada fiable es re-validar el descriptor por cada idioma de destino en lugar de asumir que se traslada. Con el doblaje a 33 idiomas de destino disponible, integrar una verificación de tono por idioma en tu flujo de trabajo no es trabajo extra — es lo que mantiene honesto un único briefing en cada mercado en el que publicas.
¿Cuántos descriptores debería usar al guiar una herramienta de voz o clonación con IA?
Apunta a las cuatro dimensiones fundamentales más la demografía — aproximadamente de 5 a 7 descriptores apilados. WP SEO AI muestra que los descriptores apilados superan a las etiquetas individuales, y el proceso de Voices.com confirma personaje más tono más palabras clave como el mínimo de trabajo. Mantente en ese rango. Menos de cinco y vuelves a los términos genéricos vagos; más de siete y empiezas a arriesgarte a contradicciones que se cancelan entre sí.
¿Puedo describir una voz haciendo referencia a una voz conocida o de celebridad en lugar de usar descriptores?
Una voz de referencia es un ancla útil — es por eso que "voz de referencia" es un campo opcional en la plantilla de briefing. Pero no reemplaza a los descriptores. Una referencia le dice a una herramienta o a una persona aproximadamente por dónde empezar; el tono, el pitch, el ritmo y el estilo les dicen dónde aterrizar. Emparejar una referencia con descriptores explícitos da el resultado más fiable, porque los descriptores resuelven la ambigüedad que la referencia deja abierta.