
API de Conversión de Voz a Texto: Cómo Elegir el Correcto en 2025
Has creado una aplicación que los usuarios aman — pero las solicitudes de funciones no dejan de llegar: "¿Puedo simplemente hablar en lugar de escribir?" Así que comienzas a evaluar APIs de conversión de voz a texto. En la primera hora, ya te has encontrado con al menos cuatro modelos de precios contradictorios, afirmaciones de precisión que van desde "95%" a "99%+" sin una definición compartida de lo que se está midiendo, y calidad de SDK que va desde insertar-tres-líneas hasta pasar-una-semana-leyendo-documentación-mala.
Los riesgos son reales en ambos extremos. Si eliges mal a escala, ya sea sangrarás $3,000–$8,000/mes en sobrecostos de transmisión, o enviarás una función de voz que falla en 1 de cada 5 enunciados. Según Koenecke et al. en PNAS (2020), las tasas de error en los cinco principales sistemas comerciales de reconocimiento de voz alcanzaron 35% para hablantes de inglés vernacular afroamericano frente a 19% para hablantes blancos — una brecha que convierte un "problema de precisión" en un problema de "el 30% de tus usuarios no pueden usar tu producto".
Esta guía te proporciona el marco de decisión, el método de cálculo de precios, el protocolo piloto, y una comparación directa de seis proveedores — incluyendo cómo un modelo basado en créditos se ajusta a proyectos con cargas de trabajo variables.

Tabla de Contenidos
- Los Cinco Ejes de Decisión Que Realmente Impulsan la Elección de API de Conversión de Voz a Texto
- Precisión en Contexto — Por Qué "99% de Precisión en Pruebas" Miente Sobre Tu Audio en Producción
- Latencia, Transmisión y el Multiplicador de Costo en Tiempo Real
- Modelos de Costo Desmitificados — Por Minuto vs. Conexiones Simultáneas vs. Fondos de Crédito
- Realidades de Integración — La Auditoría de SDK y API de 9 Preguntas
- Comparación Directa de Proveedores — Cuándo Elegir Cada API de Conversión de Voz a Texto
- Tu Lista de Verificación de Selección de API de Conversión de Voz a Texto
Los Cinco Ejes de Decisión Que Realmente Impulsan la Elección de API de Conversión de Voz a Texto
La mayoría de posts de comparación listan 30+ características y lo llaman investigación. Rechaza eso. Solo seis ejes determinan si una API de conversión de voz a texto funcionará para tu construcción específica — y en cualquier proyecto dado, solo dos o tres de ellos realmente importan.
Precisión en tu dominio. Una aplicación de transcripción médica que usa una API de propósito general representará incorrectamente "metoprolol" como "meta peral". La Tasa de Error de Palabra agregada oculta este tipo de fallo. Como argumenta Dan Jurafsky en Procesamiento del Habla y del Lenguaje, WER trata todos los errores por igual — pero en un contexto clínico o legal, un nombre de medicamento incorrecto o una negación perdida tienen un impacto desproporcionado. Lo que importa es WER específico del dominio en tu audio, no un titular de prueba.
Perfil de latencia. Una herramienta de subtítulos en vivo para accesibilidad necesita una respuesta de extremo a extremo menor a 1 segundo. Un pipeline de transcripción de podcast puede esperar 10 minutos. Según la investigación de Nielsen Norman Group sobre "Tiempos de Respuesta: Los 3 Límites Importantes", las respuestas menores a 100 ms se sienten instantáneas, menores a 1 segundo preservan el flujo, y mayores a 10 segundos causan abandono de tareas. Mapea tu caso de uso a un nivel antes de comprar.
Capacidad sin conexión / en dispositivo. Una aplicación de investigación de campo en áreas rurales no puede depender de viajes redondos a la nube. La API de SpeechAnalyzer de Apple (WWDC 2025) es una opción sin conexión a nivel de plataforma para iOS/macOS. Whisper auto-hospedado o Vosk te da control sin conexión completo si estás dispuesto a gestionar GPUs.
Cobertura de idiomas y cambio de código. Whisper soporta 50+ idiomas con calidad comparable después del entrenamiento en 680,000 horas de audio multilingüe (Radford et al., OpenAI 2022). Google y AWS usan grupos de idiomas escalonados donde los idiomas de Nivel B obtienen menor precisión y a veces precios separados.
Arquitectura del modelo de costos. Pago por minuto, conexiones simultáneas, y fondos de crédito cada uno se quiebra de manera diferente a escala. Un YouTuber que sube 4 horas una semana y 40 la siguiente es penalizado por facturación por minuto en semanas lentas y semanas de pico por igual. Los fondos de crédito con acumulación absorben esa varianza.
Área de superficie de integración. Calidad de SDK, webhooks vs. polling, errores de manejo por defecto. Aquí es donde la "API fácil" se convierte en tres semanas perdidas.
Cinco ejes impulsan cada decisión de API de conversión de voz a texto que vale la pena tomar — y solo dos o tres de ellos se aplican a tu construcción.
| Eje de Decisión | Por Qué Importa | Trampa Común | Caso de Uso de Mejor Ajuste |
|---|---|---|---|
| Precisión del dominio | Las afirmaciones de "99%" de proveedores usan discurso limpio leído | Confiar en LibriSpeech para audio móvil ruidoso | Aplicaciones médicas, legales, financieras |
| Perfil de latencia | La transmisión cuesta 3–5x el lote | Comprar transmisión para casos tolerantes de lotes | Subtítulos en vivo vs. carga de podcast |
| Capacidad sin conexión | Privacidad + entornos con conectividad restringida | Asumir que Web Speech API está sin conexión | Aplicaciones de salud de campo, primero móvil |
| Cobertura de idiomas | Idiomas de Nivel B = menor precisión | Detección automática en audio multilingüe | SaaS multilingüe, contenido global |
| Modelo de costos | Por minuto se ve barato hasta que la transmisión comienza | Ignorar almacenamiento, salida, costos de reintento | Flujos de trabajo de creadores con volumen variable |
| Superficie de integración | SDKs malos cuesta semanas de desarrollo | "Simple en documentos" ≠ se envía fácilmente | Todos los constructores |
Esta tabla es un filtro, no un veredicto. Un creador de YouTube que sube 10 trabajos en lote por semana se preocupa por el modelo de costos y la cobertura de idiomas. Una aplicación de salud se preocupa por la precisión y la capacidad sin conexión. Una herramienta de reunión en tiempo real se preocupa por la latencia y la superficie de integración.
Antes de seguir leyendo, marca los dos o tres ejes que más importan para tu construcción específica. La sección de costos (diferencia de miles de dólares) y la comparación de proveedores al final se verán completamente diferentes dependiendo de qué ejes hayas priorizado. Intentar optimizar los seis en una decisión te entregará, cada vez, al proveedor más caro con características que nunca usarás.
Precisión en Contexto — Por Qué "99% de Precisión en Pruebas" Miente Sobre Tu Audio en Producción
Cada proveedor de API de conversión de voz a texto publica números de precisión. Casi ninguno de ellos predice cómo se comportará la API en tu audio en producción. Aquí está el por qué, y cómo probar lo que realmente importa.
El audio de prueba es limpio; el audio en producción no. Los puntos de referencia públicos como LibriSpeech consisten en discurso de audiolibros leído — hablante único, acento neutral, grabación limpia. El modelo grande de Whisper reporta aproximadamente 4.7% WER en la prueba limpia de LibriSpeech y aproximadamente 8–9% WER en la prueba-otra, el conjunto más desafiante (Radford et al., OpenAI 2022). La brecha en audio de producción real — ruidoso, acentuado, hablantes superpuestos — es aún más amplia. Si un proveedor cita WER sin especificar el conjunto de datos y las condiciones de grabación, trata el número como copia de marketing, no como datos de ingeniería.
WER es la métrica incorrecta para muchas aplicaciones. La definición estándar de las pautas de evaluación de ASR del NIST es (Sustituciones + Eliminaciones + Inserciones) / palabras de referencia. Trata cada palabra como igualmente importante. Pero representar incorrectamente el nombre de medicamento de un paciente, una cifra financiera, o el nombre del testigo de un tribunal tiene consecuencias que soltar una palabra de relleno no tiene. El argumento de Jurafsky: evaluar con métricas específicas de tareas — precisión de relleno para asistentes de voz, recuperación de términos críticos para uso médico y legal, precisión de entidades nombradas para periodismo. El WER agregado podría ser 7%; el WER de términos críticos podría ser 22%. Solo uno de esos números importa a tus usuarios.
El rendimiento del acento y dialecto varía dramáticamente. El estudio de PNAS citado en la parte superior de esta guía probó cinco sistemas comerciales principales y encontró WER para hablantes de inglés vernacular afroamericano en promedio 0.35 vs. 0.19 para hablantes blancos — aproximadamente el doble de malo. Esto no es una nota de equidad. Es un riesgo empresarial: una aplicación que falla para un tercio de su base de usuarios potencial porque fue QA'd solo en inglés estadounidense neutral está enviando algo roto. La solución no es elegir un proveedor diferente (la mayoría tienen la misma brecha). La solución es probar en audio que representa tus usuarios reales antes de firmar cualquier cosa.
Una afirmación de precisión del 99% en una prueba te dice nada sobre cómo la API maneja a tus usuarios — lo que importa es el rendimiento en tu audio, tus acentos, y tu vocabulario de dominio.
La precisión en transmisión es peor que la precisión en lote. Los sistemas de transmisión emiten palabras provisionales ("parciales") que se reescriben a medida que llega más audio. Los sistemas por lotes esperan la enunciación completa y refinan. WER de transmisión es típicamente 5–15% peor que por lotes para el mismo contenido en el mismo motor. Esta brecha casi nunca se divulga en el marketing de proveedores. Si estás construyendo un producto de transcripción en vivo, factorízalo.
El cambio de código rompe la mayoría de APIs. El cambio de código significa alternar idiomas en medio de un enunciado: Spanglish, Hinglish, Tagalo-Inglés. Whisper lo maneja mejor que la mayoría porque fue entrenado en 680,000 horas de audio multilingüe (Radford et al., 2022). La mayoría de APIs en la nube requieren que declares el idioma por adelantado y se degradan fuertemente cuando el hablante cambia de idioma a mitad de oración. Si tus usuarios hablan más de un idioma en la misma sesión, prueba este caso explícitamente. Para flujos de trabajo multilingües que también necesitan localización posterior, plataformas con Doblaje de IA incorporado en 33 idiomas pueden colapsar transcripción, traducción y doblaje en un pipeline.
El Protocolo Piloto de 7 Días
En lugar de confiar en afirmaciones de precisión de proveedores, ejecuta una prueba de concepto de una semana.
- Días 1–2: Reúne 30 minutos de audio de estilo de producción real. Incluye tu peor caso: entornos ruidosos, hablantes acentuados, jerga de dominio, habla superpuesta.
- Días 3–4: Transcribe con 3 APIs candidatas. Corrige manualmente una versión para usar como tu transcripción de referencia.
- Día 5: Mide WER en general, luego desglosalo por hablante, acento, y recuperación de términos de dominio.
- Día 6: Prueba transmisión vs. lote en los mismos archivos. Mide el delta de precisión.
- Día 7: Documenta costos incurridos y fricción de integración — complejidad de autenticación, problemas de SDK, calidad de respuesta de error.
Un ingeniero escribiendo en ITNEXT reportó que después de ajustar la configuración del micrófono y el vocabulario personalizado, la conversión de voz a texto moderna produjo menos errores que su propio mecanografiado para escribir técnico. La conclusión no es que ninguna API individual sea mágica. Es que la elección de API importa, pero el pipeline de audio alrededor de la API importa al menos tanto. Una API excelente en audio malo pierde contra una API decente en audio ajustado.
Latencia, Transmisión y el Multiplicador de Costo en Tiempo Real
La latencia es el eje donde los ingenieros más a menudo gastan en exceso. La transcripción en tiempo real se ve mágica en una demostración y cuesta 3–5x más que el lote en producción. Decide lo que tus usuarios realmente necesitan antes de registrarse en infraestructura de transmisión.
- Latencia de transmisión síncrona (subtítulos en vivo, asistentes de voz). Objetivo menor a 1 segundo de extremo a extremo para subtítulos de accesibilidad, 300–800 ms de ida y vuelta para chatbots de voz para sentirse conversacionales. Arriba de 2 segundos y la ilusión del tiempo real se quiebra. Estos umbrales se mapean a investigación de UX establecida sobre la percepción del tiempo de respuesta (Nielsen Norman Group). Las APIs de transmisión logran esto a través de conexiones WebSocket persistentes que emiten resultados provisionales mientras llega el audio.
- Latencia de lote asíncrona (carga de podcast, revisión de llamada de soporte, subtítulos de YouTube). Minutos a horas de tiempo de procesamiento es aceptable. El lote es aproximadamente 3–5x más barato por minuto de audio que la transmisión en el mismo proveedor, porque la infraestructura no está manteniendo conexiones abiertas (documentos de precios de Google Cloud y AWS Transcribe). Para flujos de trabajo de creadores cargando contenido grabado, el lote es casi siempre correcto.
- Híbrido / casi tiempo real (redacción en vivo con corrección retrasada). Algunos flujos de trabajo aceptan latencia de 2–5 segundos a cambio de mayor precisión y menor costo. Una herramienta de transcripción de reuniones podría mostrar texto aproximado dentro de 3 segundos y refinarlo dentro de 30. Este patrón usa transmisión para la vista en vivo y reprocesamiento en lote para la transcripción guardada — a menudo a través de callback de webhook en lugar de polling. Las plataformas construidas específicamente para flujos de trabajo de medios, como la API de Doblaje de IA de DubSmart, usan callbacks de webhook para trabajos completados en lugar de forzar a tu backend a hacer polling de estado (hilo de comunidad de Make.com sobre integración de webhook de AudioPen).
- Factor de Tiempo Real (RTF) — la métrica del ingeniero. Los sistemas en producción se dirigen a RTF < 1.0 para uso interactivo: procesar 1 segundo de audio en menos de 1 segundo de tiempo de pared. Los despliegues de Whisper acelerados con GPU o en dispositivo alcanzan aproximadamente RTF 0.5–0.9 para modelos medianos en GPUs de consumidor. Si tu configuración auto-hospedada ejecuta RTF > 1.0, la transmisión es imposible sin puesta en cola.

El triángulo de latencia-costo-precisión es no negociable: puedes elegir dos. La transmisión sacrifica precisión y presupuesto por inmediatez. El lote sacrifica inmediatez por precisión y costo. Las arquitecturas híbridas son cada vez más comunes pero añaden complejidad de integración. Antes de elegir, haz una pregunta: ¿realmente notarían mis usuarios un retraso de 5 segundos? Si la respuesta es no, el lote es la arquitectura correcta y acabas de ahorrar el 70% de tu gasto anual en API.
Modelos de Costo Desmitificados — Por Minuto vs. Conexiones Simultáneas vs. Fondos de Crédito
Hay tres arquitecturas de precios en el mercado de APIs de conversión de voz a texto, y confundirlas es el error de adquisición más común.
Pago por minuto (estándar de lote). Se te factura por minuto de audio enviado, a menudo en incrementos de 15 segundos. Simple de pronosticar para cargas de trabajo predecibles. La API de Whisper de OpenAI es aproximadamente $0.006/minuto (página de precios de OpenAI) — a menudo 3–5x más barato que proveedores de ASR en la nube tradicionales, que se agrupan alrededor de $0.02–0.03/minuto para modelos de lote estándar en inglés.
Conexiones simultáneas (transmisión en tiempo real). Pagas por flujo abierto simultáneo, a menudo facturado por minuto de conexión o por ranura de conexión simultánea. Aquí es donde las facturas se disparan: si 50 usuarios comienzan a transmitir a la vez, estás pagando por 50 conexiones — no 50 minutos de audio. Google Cloud y AWS publican tasas distintas y más altas para sesiones de transmisión vs. trabajos en lote sin conexión.
Fondos de crédito con acumulación (cargas de trabajo flexibles). Compras un fondo de créditos que se consumen a tasas variables dependiendo de qué características uses (transcripción, doblaje, clonación de voz, conversión de texto a voz). Los créditos no usados se acumulan. Este modelo se ajusta a cargas de trabajo variables — un YouTuber que carga 4 horas una semana y 40 la siguiente no es penalizado por el pico ni quedan minutos no usados. DubSmart AI usa este modelo, agrupando transcripción con Clonación de Voz y Conversión de Texto a Voz bajo un saldo de crédito único.
Ejemplo práctico — Creador de YouTube:
- 10 videos/semana × 30 min cada uno = 300 min/semana de audio fuente
- Transcripción en lote a $0.006/min = $1.80/semana, o aproximadamente $94/año
- Añade una demostración de subtítulos en vivo transmitida (5 horas/mes) a 4x la tasa de lote = aproximadamente $72/año adicional
- Si el creador dobla a 3 idiomas, la necesidad total de crédito de transcripción + doblaje mensual es aproximadamente 5,000 créditos — se ajusta dentro de un plan de fondo de crédito de nivel medio
A cualquier volumen por debajo de 5,000 horas por mes, construir tu propio stack de transcripción es más barato en fantasía que en realidad — un nivel de API de $50 se envía en un día, mientras que un despliegue auto-hospedado de Whisper se envía en un trimestre.
| Proveedor | Modelo de Precios | Tasa Publicada | Nivel Gratuito |
|---|---|---|---|
| Google Cloud STT | Por incremento de 15 seg; recargo de transmisión | Variable; escalonado | 60 min/mes |
| AWS Transcribe | SKUs de lote por segundo + transmisión | Variable por región/modelo | 60 min/mes, 12 meses |
| OpenAI Whisper API | Plano por minuto | ~$0.006/min | Ninguno publicado |
| Rev.com (Máquina) | Por minuto | $0.25/min | Ninguno |
| Rev.com (Humano) | Por minuto | $1.50/min | Ninguno |
| DubSmart AI | Fondo de crédito c/ acumulación | Planes escalonados | Nivel gratuito disponible |
Fuentes: Páginas de precios de OpenAI, Google Cloud, AWS Transcribe, Rev.com.

Tres costos ocultos casi nunca aparecen en las calculadoras de proveedores.
Almacenamiento y salida. Si almacenas transcriptos y audio fuente en S3 o GCS, pagas almacenamiento más ancho de banda en recuperación. A escala estos se convierten en elementos de línea no triviales. Un archivo de 1 TB a tasas estándar con lecturas frecuentes puede añadir cientos de dólares por mes antes de que ninguna llamada a API golpee.
La diarización de hablantes generalmente se mide por separado. AWS Transcribe y AssemblyAI ambos facturan la identificación de hablante como un elemento de línea separado además de la transcripción base (documentación de AWS Transcribe; documentos de AssemblyAI). Presupuestar solo en la tasa base por minuto subestima tu costo real en aproximadamente 20–40% si necesitas etiquetas de hablante.
Costos de reintento y error. Las solicitudes fallidas aún consumen cuota en algunos proveedores. Si tu pipeline de audio tiene una tasa de error del 2% en 100,000 minutos/mes, eso es 2,000 minutos de reintentos pagados — aproximadamente $12/mes a tasas de Whisper, pero fácilmente $60/mes en STT en la nube tradicional.
Punto de equilibrio de construcción vs. compra. La experiencia de ingeniería de equipos en Mozilla (DeepSpeech), Descript y AssemblyAI sugiere que auto-hospedar ASR con Whisper o Kaldi solo tiene sentido en >5,000 horas/mes con dedicada ML y DevOps. Por debajo de ese volumen, infraestructura, mantenimiento de modelo, costos de GPU, y sobrecarga de on-call exceden la factura de API de $50–$500/mes — a menudo por un factor de cinco o más.
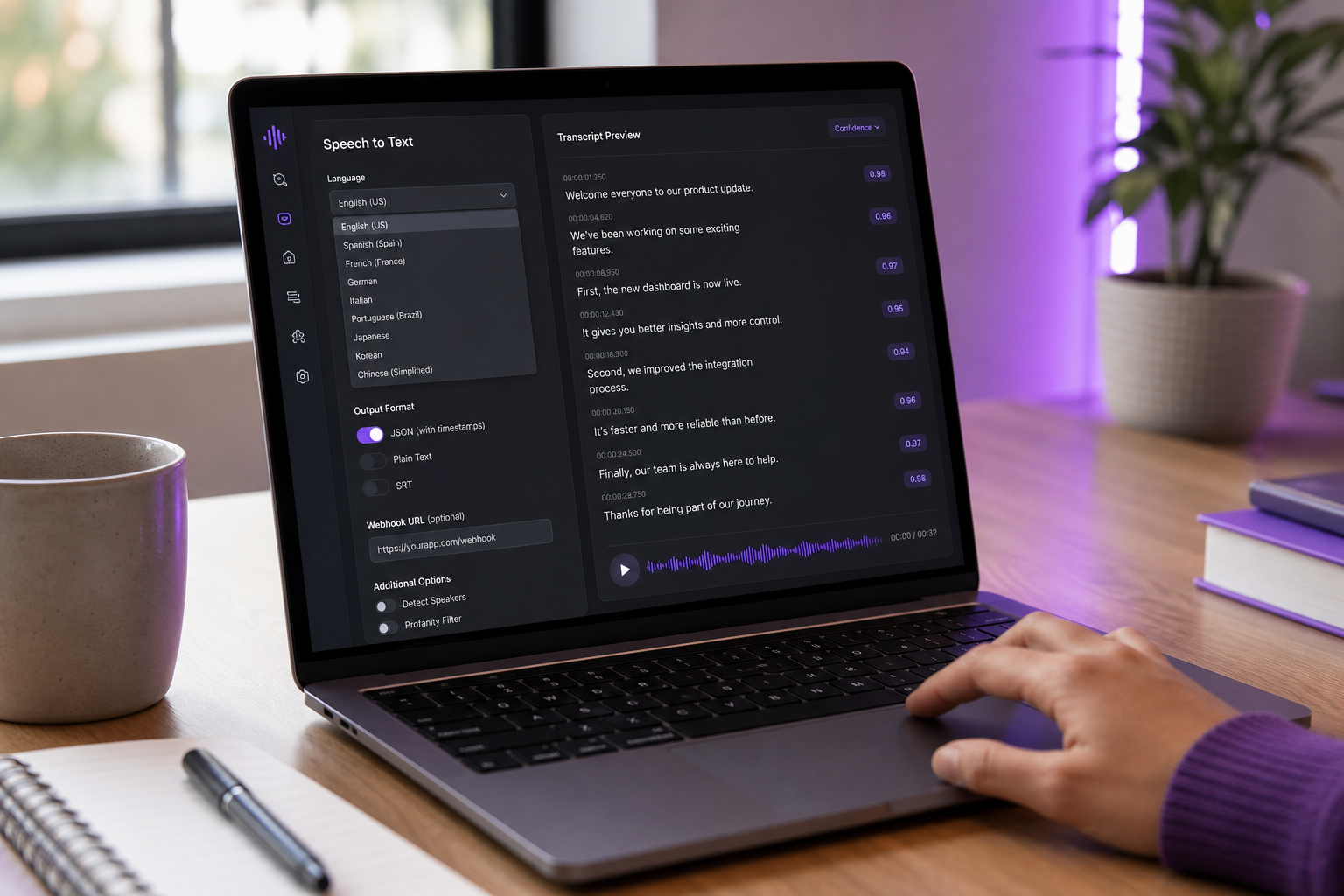
Realidades de Integración — La Auditoría de SDK y API de 9 Preguntas
"Fácil de integrar" es la frase más sobrecargada en la economía de APIs. Una API puede ser fácil de llamar en una solicitud curl e infernal de enviar en producción. Antes de firmar un contrato, ejecuta cada candidata a través de estas nueve preguntas. Las malas respuestas aquí predicen las semanas de manejo de errores personalizado y lógica de reintento que escribirás después.
- ¿La API soporta tanto transmisión como lote en un SDK? Algunos proveedores te fuerzan a elegir arquitectura por adelantado, luego cobran por cambiar. Las mejores APIs exponen ambas a través de la misma capa de autenticación y te permiten migrar cargas de trabajo mientras el comportamiento del usuario evoluciona. Si tu caso de uso inicial es lote pero podrías añadir subtítulos en vivo en seis meses, esto importa ahora.
- ¿Qué pasa cuando la API está caída o limitada por tasa? Pruébalo. Envía 200 solicitudes en 1 segundo a un nivel gratuito. ¿El SDK las pone en cola, expone un 429 limpiamente, o se cuelga? Los proveedores que publican SLA y semántica de reintento en lenguaje plano te ahorran semanas de respuesta a incidentes. Los que no, eventualmente te despertarán a las 3 AM.
- ¿Puedes especificar el idioma de audio explícitamente, o se auto-detecta? La auto-detección suena amigable pero se quiebra en audio multilingüe o con cambio de código. Para construcciones de producción, siempre especifica el idioma y vuelve a la auto-detección solo cuando la confianza es baja. APIs que no te dejan establecer el idioma explícitamente están pre-ingenieramente destinadas a fallar en tus casos de borde.
- ¿Soporta diarización de hablantes fuera de la caja? La diarización a menudo es un complemento de precio separado. AssemblyAI y AWS Transcribe ambos la miden por separado. Verifica si tu proveedor devuelve etiquetas de hablante a nivel de segmento o de palabra — la diferencia importa para análisis, búsqueda, y cualquier resumen posterior.
- ¿Puedes marcar o redactar PII (números de tarjeta de crédito, SSNs, nombres)? La mayoría de APIs enfocadas en empresas (AWS Transcribe, AssemblyAI) soportan redacción de PII. Whisper y Web Speech API no. Para aplicaciones de salud o financieras, esto no es un lujo.
- ¿Callbacks de webhook o polling para trabajos asíncronos? Los webhooks son el estándar moderno. El polling genera llamadas a API innecesarias y costos. Las plataformas maduras emiten eventos de webhook en finalización de trabajo — el patrón mostrado en el hilo de comunidad de Make.com sobre integración de AudioPen donde la finalización de transcripción dispara automatización posterior.
- ¿Cuáles son los límites de tamaño de archivo y duración máxima por solicitud? Muchas APIs en la nube capping solicitudes individuales en 15 minutos o aproximadamente 1 hora con límites de tamaño de archivo en decenas a cientos de MBs (documentos de Google Cloud Speech-to-Text; documentos de AWS Transcribe). El audio de forma larga — podcasts de dos horas, deposiciones, grabaciones de conferencias — debe ser dividido. Las puertas HTTP a menudo aplican tiempos de espera de 15 minutos independientemente de los propios límites de la API.
- ¿Se exponen puntuaciones de confianza a nivel de palabra? La confianza a nivel de palabra te permite marcar regiones de baja confianza para revisión humana o corrección interactiva. APIs que devuelven texto sin procesar sin confianza te fuerzan a confiar en todo o a re-transcribir. Para cualquier flujo de trabajo con revisión humana en el bucle, esta característica es la diferencia entre una cola de QA usable y una pared de texto ilegible.
- ¿Cuál es la calidad de SDK en tu idioma? Un SDK de Node.js o Python con tipificación fuerte, lógica de reintento, y clases de error limpias vale una prima de precio del 30% sobre una API que tienes que raw-HTTP en producción. Prueba el SDK antes de comprometerte con la API. Escribe una integración pequeña. Cronometra. El SDK que realmente disfrutas usar ahorrará más horas de ingeniería de lo que el rate de precio más barato por minuto nunca te ahorre en dólares.
El código abierto vs. propietario sigue siendo el mayor bifurcación de integración.
Código abierto (Whisper, Vosk). Costo cero por llamada, control total, funciona sin conexión. Posees hospedaje, escalado, provisión de GPU, actualizaciones de modelo, observabilidad, e el incidente de las 3 AM. Despliegue realista para un equipo de 5+ con capacidad ML y DevOps.
Nube propietaria (Google, AWS, AssemblyAI, OpenAI Whisper API, DubSmart). Cambias costo por minuto por confiabilidad, SLA, versionado y soporte de SDK. Para la mayoría de equipos por debajo de 5,000 horas/mes, lo propietario gana en costo total de propiedad. Las plataformas que agrupan conversión de voz a texto con la API de Conversión de Texto a Voz y la API de Clonación de Voz bajo un SDK reducen el área de superficie de integración aún más — un flujo de autenticación, un modelo de error, un panel de facturación para el pipeline de medios completo.
En dispositivo a nivel de plataforma (Apple SpeechAnalyzer, WWDC 2025). Una categoría más nueva. Preservadora de privacidad, capaz de funcionar sin conexión, pero la precisión y la cobertura de idiomas pueden estar rezagadas a los modelos en la nube. Mejor para aplicaciones primero móvil donde la privacidad es un activo de marketing, no solo una casilla de cumplimiento.
La pregunta de integración que supera a todas las demás: ¿qué tan rápido puedes enviar? Una API basada en crédito bien documentada que agrupa conversión de voz a texto, clonación de voz, y doblaje bajo un SDK a menudo vence a una API STT independiente más barata una vez que contabilizas la segunda y tercera características que necesitarás dentro de seis meses.
Comparación Directa de Proveedores — Cuándo Elegir Cada API de Conversión de Voz a Texto
Esta es una exploración rápida de referencia, no una revisión exhaustiva. Cada entrada cubre caso de uso de mejor ajuste, debilidad principal, impulsor de costo dominante, y carácter de integración. Las fuentes para afirmaciones de precios y características son documentación de proveedores a partir de finales de 2024.
Google Cloud Speech-to-Text
- Mejor para: Transcripción de inglés de alta precisión, equipos ya en GCP, cargas de trabajo empresariales con volumen predecible.
- Debilidad: El precio de transmisión escala rápidamente; los niveles de idioma crean inconsistencia de precisión para audio en idiomas que no son inglés.
- Impulsor de costo: Por incrementos de 15 segundos con un SKU de transmisión separado (más alto); nivel gratuito de 60 min/mes.
- Integración: Autenticación GCP nativa a través de cuentas de servicio. Las aplicaciones que no son GCP enfrentan sobrecarga de IAM. SDKs maduros para todos los idiomas principales.
AWS Transcribe
- Mejor para: Cargas de trabajo intensivas en lote a escala, equipos nativos de AWS, pipelines de contenido multilingües, análisis de centros de llamadas.
- Debilidad: La latencia de transmisión es ligeramente más alta que competidores especializados en transmisión. La diarización y modelos médicos se facturan por separado.
- Impulsor de costo: Duración de audio en segundos, con SKUs separados para transmisión, médico, y complementos de análisis de llamadas.
- Integración: Pesado en IAM. Directo si ya eres nativo de AWS. Bien documentado pero verboso.
OpenAI Whisper API
- Mejor para: Construcciones conscientes del presupuesto, contenido multilingüe con cambio de código, equipos que desean ningún bloqueo de proveedor más allá de OpenAI mismo.
- Debilidad: Sin soporte nativo de transmisión. Sin descuentos de volumen. Sin compromisos de SLA comparables a AWS o GCP.
- Impulsor de costo: Flat $0.006/minuto sin cargo por conexión simultánea y sin descuento empresarial escalonado publicado.
- Integración: La API HTTP más simple del mercado. Multilingüe sin declaración de idioma gracias a las 680,000 horas de datos de entrenamiento documentados en el papel de Whisper.
AssemblyAI
- Mejor para: Equipos primero desarrolladores, transmisión en tiempo real con latencia mínima, salida estructurada con marcas de tiempo a nivel de palabra, etiquetas de hablante, y puntuaciones de confianza.
- Debilidad: Precios premium. La densidad de características es excesiva para casos de uso simples de lote.
- Impulsor de costo: Conexiones de transmisión simultáneas más elementos de línea de diarización.
- Integración: Excelentes SDKs y documentación. Arquitectura primero de webhook. Herramientas de observabilidad fuertes.
Rev.com (Híbrido Máquina + Humano)
- Mejor para: Flujos de trabajo donde la precisión es innegociable y el tiempo de respuesta puede esperar horas — deposiciones legales, periodismo, contenido crítico de accesibilidad.
- Debilidad: No es tiempo real. La revisión humana toma horas. Caro a escala.
- Impulsor de costo: $0.25/minuto para máquina, $1.50/minuto para revisión humana.
- Integración: API REST simple. La fricción es el tiempo de respuesta, no la integración misma.
DubSmart AI Speech to Text API
- Mejor para: Creadores de contenido y equipos construyendo flujos de trabajo multilingües donde la transcripción es un paso en un pipeline más largo — transcribir, traducir, doblar, publicar. El precio basado en crédito absorbe cargas de trabajo variables.
- Debilidad: Plataforma más joven que hipercalculadores heredados. Los términos de SLA empresarial pueden no coincidir con AWS o GCP para equipos de adquisición con aversión al riesgo.
- Impulsor de costo: Fondo de crédito con acumulación. Agrupa transcripción con clonación de voz de una muestra de 20 segundos, 300+ voces de TTS, y Doblaje de IA en 60+ idiomas de origen a 33 idiomas de destino.
- Integración: Construida propósito para flujos de trabajo de medios. SDK único cubre transcripción + TTS + clonación + doblaje. Callbacks de webhook para trabajos asíncronos. Confiado por 500,000+ usuarios.
Tu Lista de Verificación de Selección de API de Conversión de Voz a Texto
Este es el flujo de trabajo a ejecutar antes de firmar cualquier contrato. Comprime todo lo anterior en ocho pasos ejecutables. Bloquea cuatro horas para el primer paso; espera una semana de pruebas piloto en el paso 4.
- Define tu caso de uso dominante en una oración. Escríbelo: "Necesito transcribir podcasts" o "subtítulos de streams en vivo" o "analizar llamadas de ventas" o "doblar videos cargados por usuarios". Si no puedes escribirlo en una oración, tienes dos productos y necesitas dos evaluaciones. Empareja el caso de uso con el nivel de latencia de la Sección 3 y la demanda de precisión de la Sección 2 antes de mirar cualquier precio de proveedor.
- Marca los dos o tres ejes de decisión que más importan. Del marco: precisión, latencia, sin conexión, cobertura de idiomas, modelo de costos, superficie de integración. Si intentas optimizar los seis, elegirás el proveedor más caro con características que nunca usarás. La mayoría de constructores deben clasificar el modelo de costos y la superficie de integración primero. La precisión y la latencia se convierten en desempates entre finalistas.
- Proyecta volumen de 12 meses con búfer de pico de 3x. Estima minutos mensuales para mes 1, mes 6, y mes 12. Multiplica el número del mes 12 por 3 para manejar picos de lanzamiento y crecimiento viral. Este número determina si necesitas un fondo de crédito, precios por minuto, o un contrato empresarial con descuento de volumen — y es el número que citarás a proveedores durante negociación.
- Ejecuta el piloto de 7 días. Treinta minutos de tu audio real, tres APIs candidatas, puntuadas manualmente contra una transcripción de referencia corregida por un solo humano. Mide WER por hablante, por acento, y por término de dominio — no solo agregado. Prueba transmisión vs. lote en los mismos archivos. Documenta fricción de SDK en un doc compartido mientras avanzas, mientras el dolor sea fresco.
- Prueba el manejo de errores bajo estrés. Envía audio malformado, tokens expirados, ráfagas que rompen límites de tasa, y archivos de tamaño excesivo. ¿Falla el SDK limpiamente con errores accionables, o se cuelga? Una API que falla mal bajo estrés controlado fallará mal en producción a las 3 AM, y el costo de limpieza superará cualquier ahorro por minuto que hayas asegurado en la firma.
- Calcula el costo total verdadero de propiedad. Incluye costo base por minuto, sobrecargas de transmisión, elementos de línea de diarización, almacenamiento, salida, sobrecarga de reintento, y horas de ingeniería ahorradas o perdidas por calidad de SDK. Compara contra un modelo de fondo de crédito si tu carga de trabajo es variable — un plan de crédito aproximadamente de $99/mes a menudo vence a precios de $0.006/minuto cuando el tráfico es pico y agrupa múltiples características de medios bajo una factura.
- Audita privacidad y retención de datos por defecto. Confirma si el proveedor retiene audio y transcriptos para mejora de modelo, y si puedes optar por no participar contractualmente. Los requisitos GDPR, HIPAA y SOC 2 pueden eliminar proveedores independientemente del precio. Según la guía de la Junta Europea de Protección de Datos sobre asistentes de voz, los proveedores STT en la nube pueden crear "conjuntos de datos de sombra" de datos de voz a menos que estén explícitamente restringidos en contrato — esto es una pregunta de adquisición, no una pregunta de característica.
- Negocia antes de comprometerte. La mayoría de proveedores ofrecen descuentos de 15–30% en compromisos de 12 meses arriba de 500 horas/mes. Si has completado los pasos 1–7 con confianza, tienes apalancamiento. Pide precios bloqueados, un contacto de soporte dedicado, nivel gratuito expandido para entornos de staging, y una cláusula de salida si la precisión se degrada por debajo de un umbral acordado. Si tu hoja de ruta incluye localización, evalúa APIs como la API de Doblaje de IA que traducen y doblan en una llamada.
Esta lista de verificación es tu defensa contra el marketing de proveedores y tu ofensiva contra retrasos de envío. Los equipos que envían características de voz más rápido no son los que eligieron la API más barata — son los que ejecutaron un piloto real, calcularon TCO verdadero, y eligieron una superficie de integración que sus desarrolladores querían trabajar. Si tu construcción también implica doblaje, clonación de voz, o generación de habla sintética, evalúa plataformas que agrupen Conversión de Texto a Voz, clonación de voz, y doblaje bajo un saldo de crédito único y un SDK único — la segunda y tercera características que necesitarás dentro de seis meses costará menos y se enviará más rápido.