
Los modelos de reconocimiento de voz se juzgan por la precisión con la que transcriben el habla y retienen el significado en diferentes condiciones. Las tres métricas principales utilizadas son:
- Tasa de Error de Palabras (WER): Mide errores de transcripción (inserciones, eliminaciones, sustituciones). Mejor para audio limpio, pero tiene dificultades con ruido o acentos.
- Tasa de Error de Caracteres (CER): Rastrea la precisión a nivel de caracteres, ideal para idiomas como el chino o el japonés.
- SeMaScore: Se enfoca en el significado semántico, funcionando bien en entornos ruidosos y con acentos diversos.
Comparación Rápida de Métricas
| Métrica | Enfoque | Mejor Para | Limitaciones |
|---|---|---|---|
| WER | Precisión a nivel de palabras | Habla limpia | Dificultades con ruido/acentos |
| CER | Precisión a nivel de caracteres | Idiomas asiáticos | Sin comprensión semántica |
| SeMaScore | Retención de significado semántico | Audio ruidoso, multilingüe | Mayor demanda computacional |
Métodos avanzados como el modelado acústico y el modelado unificado mejoran aún más las evaluaciones simulando condiciones del mundo real. Estas métricas son cruciales para mejorar herramientas como plataformas de transcripción multilingüe.
Métricas Clave para Evaluar el Reconocimiento de Voz
Los modelos de reconocimiento de voz utilizan métricas específicas para evaluar su rendimiento. Estas métricas ayudan a desarrolladores e investigadores a entender la eficacia de sus sistemas de Reconocimiento Automático de Voz (ASR) en varias condiciones y lenguajes.
Tasa de Error de Palabras (WER)
Tasa de Error de Palabras (WER) es una de las métricas más utilizadas para medir cuán preciso un sistema transcribe el habla. Identifica errores en tres categorías:
- Inserciones: Palabras añadidas que no deberían estar.
- Eliminaciones: Palabras que faltan en la transcripción.
- Sustituciones: Palabras incorrectas reemplazando a las correctas.
El objetivo es lograr un WER más bajo, ya que refleja mejor precisión. Dicho esto, el WER puede tener desventajas, especialmente en situaciones con ruido ambiental o patrones de habla inusuales.
Tasa de Error de Caracteres (CER)
Tasa de Error de Caracteres (CER) ofrece un análisis más detallado al enfocarse en caracteres individuales en lugar de palabras completas. Esto lo hace especialmente útil para idiomas como el chino o el japonés, donde los caracteres tienen un significado significativo.
CER es particularmente efectivo para sistemas multilingües o casos donde los límites de las palabras no son claros. Aunque proporciona un análisis lingüístico detallado, métricas más nuevas como el SeMaScore buscan abordar desafíos más amplios relacionados con el significado.
SeMaScore
SeMaScore va más allá de métricas tradicionales como WER y CER al incorporar una capa semántica en el proceso de evaluación. Mide cuán bien el sistema retiene el significado pretendido, no solo las palabras o caracteres exactos.
Así es como SeMaScore destaca en escenarios específicos:
| Tipo de Escenario | Cómo Ayuda SeMaScore |
|---|---|
| Entorno Ruidoso | Iguala la percepción humana en entornos ruidosos |
| Habla Atípica | Se alinea con evaluaciones expertas de significado |
| Dialectos Complejos | Preserva la precisión semántica a través de dialectos |
SeMaScore es particularmente útil para evaluar sistemas ASR en condiciones desafiantes, proporcionando una evaluación más amplia y significativa de su desempeño. Juntas, estas métricas ofrecen un marco bien redondeado para entender cómo los sistemas ASR actúan en diferentes situaciones.
Métodos Avanzados para Evaluar Modelos ASR
El proceso de evaluar modelos de Reconocimiento Automático de Voz (ASR) ha avanzado más allá de métricas básicas, utilizando técnicas más avanzadas para obtener ideas más profundas sobre cómo funcionan estos sistemas.
El Rol del Modelado Acústico
El modelado acústico conecta señales de audio con unidades lingüísticas mediante representaciones estadísticas de características del habla. Su rol en la evaluación ASR depende de varios factores técnicos:
| Factor | Efecto en la Evaluación |
|---|---|
| Tasa de Muestreo y Bits por Muestra | Valores más altos mejoran la precisión en el reconocimiento pero pueden ralentizar el procesamiento y aumentar el tamaño del modelo |
| Ruido Ambiental y Variaciones del Habla | Dificulta el reconocimiento; los modelos deben probarse con datos diversos y desafiantes |
Los modelos acústicos están diseñados para manejar una variedad de patrones de habla y desafíos ambientales, que a menudo se pasan por alto en métricas de evaluación tradicionales.
Modelado Unificado en ASR
A diferencia del modelado acústico, que se centra en características específicas del habla, el modelado unificado combina múltiples tareas de reconocimiento en un solo marco. Este enfoque mejora la evaluación ASR al reflejar casos de uso del mundo real, donde los sistemas a menudo manejan múltiples tareas al mismo tiempo.
Factores importantes para la evaluación incluyen:
- Equilibrio entre velocidad y precisión
- Mantener el rendimiento bajo uso intenso
- Garantizar resultados consistentes en diferentes ambientes
Plataformas como DubSmart usan estas técnicas avanzadas para mejorar el reconocimiento de voz para contenido multilingüe y clonación de voz.
Estos métodos proporcionan una base para comparar diferentes métricas de evaluación, arrojando luz sobre sus ventajas y limitaciones.
Aplicaciones y Desafíos de las Métricas de Evaluación
Las métricas de evaluación desempeñan un rol crítico en mejorar herramientas como DubSmart y enfrentar obstáculos continuos en sistemas de reconocimiento automático de voz (ASR).
Uso en Herramientas de IA como DubSmart
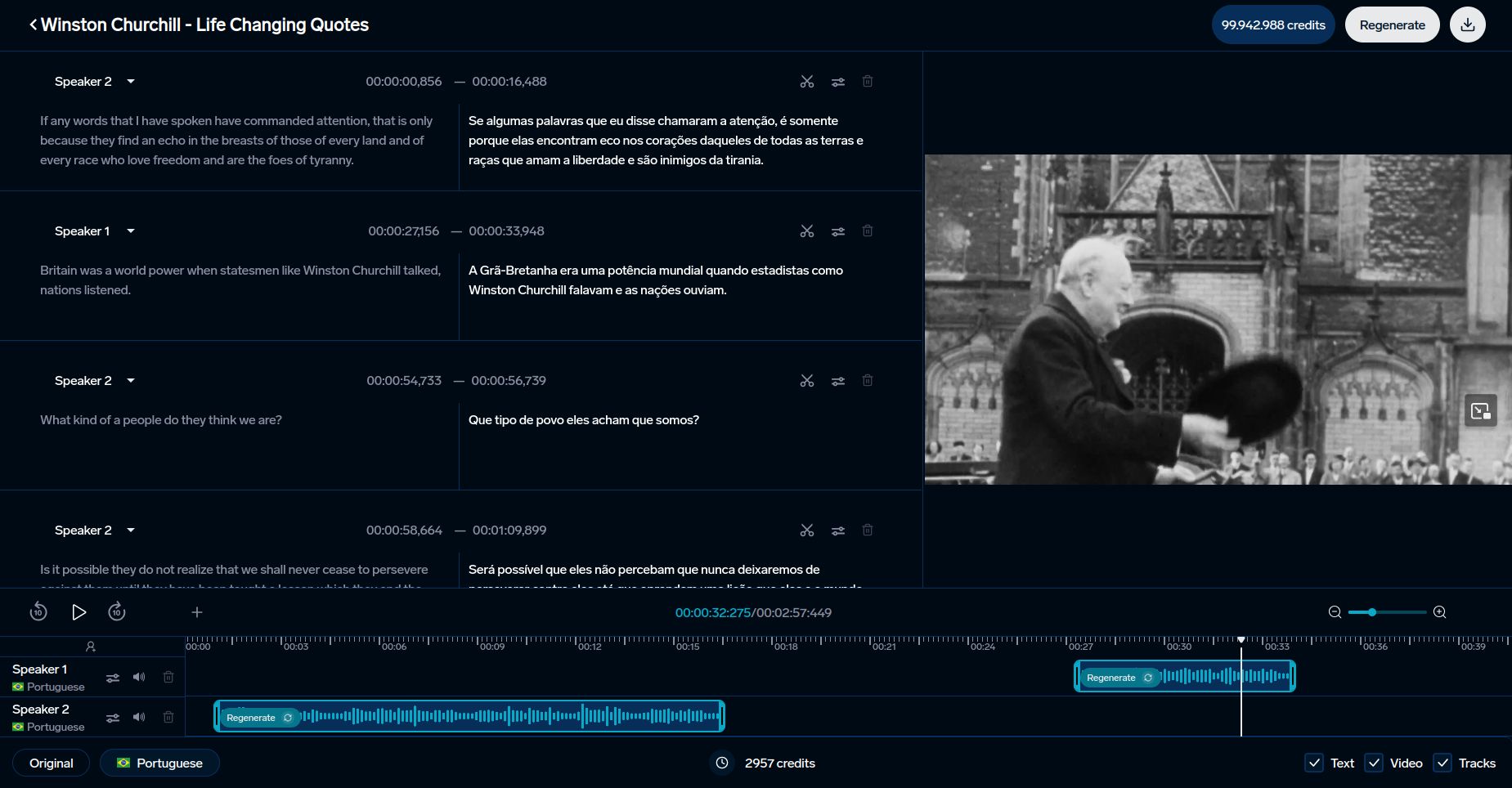
Las métricas de reconocimiento de voz son esenciales para mejorar herramientas de lenguaje impulsadas por IA. DubSmart aprovecha estas métricas para ofrecer servicios de doblaje y transcripción multilingüe en 33 idiomas. La plataforma integra tanto métricas tradicionales como avanzadas para asegurar calidad:
| Métrica | Aplicación | Impacto |
|---|---|---|
| SeMaScore | Entornos Multilingües y Ruidosos | Preserva la precisión semántica y retención de significado |
Esta combinación asegura alta precisión, incluso en escenarios desafiantes como procesar múltiples hablantes o manejar audio complejo. La precisión semántica es especialmente importante para tareas como la clonación de voz y la generación de contenido multilingüe.
Desafíos en la Evaluación ASR
Los métodos de evaluación tradicionales a menudo son insuficientes cuando se enfrentan a acentos, ruido de fondo o variaciones dialectales. Herramientas avanzadas como SeMaScore abordan estas brechas al incorporar análisis basados en el significado. SeMaScore, en particular, marca un progreso al combinar la evaluación de tasas de error con una comprensión semántica más profunda.
"Evaluar el reconocimiento de voz requiere equilibrar precisión, velocidad y adaptabilidad a través de idiomas, acentos y ambientes."
Para mejorar la evaluación ASR, entran en juego varios factores:
- Mejorar los modelos acústicos para lograr un equilibrio entre precisión y eficiencia
- Cumplir con las necesidades de procesamiento en tiempo real sin comprometer la precisión
- Garantizar un rendimiento constante en diversos contextos
Técnicas de evaluación más nuevas apuntan a proporcionar información más detallada sobre el rendimiento ASR, especialmente en situaciones exigentes. Estos avances ayudan a refinar herramientas para mejores comparaciones de sistemas y efectividad general.
sbb-itb-f4517a0
Comparación de Métricas de Evaluación
Evaluar sistemas de reconocimiento de voz a menudo se reduce a elegir la métrica adecuada. Cada una destaca diferentes aspectos del rendimiento, por lo que es crucial emparejar la métrica con el caso de uso específico.
Si bien WER (Tasa de Error de Palabras) y CER (Tasa de Error de Caracteres) están bien establecidos, opciones más recientes como SeMaScore ofrecen una perspectiva más amplia. Aquí está cómo se comparan:
Tabla de Comparación de Métricas
| Métrica | Rendimiento de Precisión | Comprensión Semántica | Escenarios de Uso | Velocidad de Procesamiento | Demandas Computacionales |
|---|---|---|---|---|---|
| WER | Alta para habla limpia, tiene dificultades con ruido | Contexto semántico limitado | Evaluación ASR estándar, audio limpio | Muy rápida | Mínima |
| CER | Excelente para análisis a nivel de caracteres | No hay análisis semántico | Idiomas asiáticos, evaluación fonética | Rápida | Baja |
| SeMaScore | Fuerte en condiciones variadas | Alta correlación semántica | Ambientes multiacento, ruidosos | Moderada | Media a alta |
WER funciona bien en escenarios de audio limpio, pero tiene dificultades con el habla ruidosa o con acentos debido a su falta de profundidad semántica. Por otro lado, SeMaScore cierra esa brecha al combinar análisis de errores con comprensión semántica, lo que lo hace más adecuado para condiciones de habla diversas y desafiantes.
A medida que herramientas como DubSmart integran sistemas ASR en transcripciones multilingües y clonación de voz, seleccionar la métrica correcta se vuelve crítico. La investigación muestra que SeMaScore rinde mejor en entornos ruidosos o complejos, ofreciendo una evaluación más confiable.
En última instancia, la elección depende de factores como la complejidad del habla, la diversidad de acentos y los recursos disponibles. WER y CER son excelentes para tareas más simples, mientras que SeMaScore es mejor para evaluaciones más matizadas, reflejando un cambio hacia métricas que se alinean más estrechamente con la interpretación humana.
Estas comparaciones muestran cómo está evolucionando la evaluación ASR, moldeando las herramientas y sistemas que dependen de estas tecnologías.
Conclusión
La comparación de métricas destaca cómo ha crecido y hacia dónde se dirige la evaluación ASR. Las métricas se han adaptado para satisfacer las demandas de sistemas ASR cada vez más complejos. Si bien Tasa de Error de Palabras (WER) y Tasa de Error de Caracteres (CER) siguen siendo puntos de referencia clave, medidas más recientes como SeMaScore reflejan un enfoque en combinar la comprensión semántica con el análisis de errores tradicional.
SeMaScore ofrece un equilibrio de velocidad y precisión, lo que lo convierte en una opción sólida para aplicaciones prácticas. Los sistemas ASR modernos, como los usados por plataformas como DubSmart, deben navegar en escenarios del mundo real desafiantes, incluidas condiciones acústicas diversas y necesidades multilingües. Por ejemplo, DubSmart admite reconocimiento de voz en 70 idiomas, demostrando la necesidad de métodos de evaluación avanzados. Estas métricas no solo mejoran la precisión del sistema, sino que también mejoran su capacidad para manejar desafíos lingüísticos y acústicos variados.
Mirando hacia el futuro, se espera que las métricas futuras combinen el análisis de errores con una comprensión más profunda del significado. A medida que la tecnología de reconocimiento de voz progresa, los métodos de evaluación deben afrontar el desafío de entornos ruidosos, acentos variados, y patrones de habla complejos. Este cambio influirá en cómo las empresas diseñan e implementan sistemas ASR, priorizando métricas que evalúen tanto la precisión como la comprensión.
Seleccionar la métrica apropiada es crucial, ya sea para audio limpio o escenarios multilingües complejos. A medida que la tecnología ASR continúa avanzando, estas métricas en evolución desempeñarán un papel clave en la configuración de sistemas que mejor satisfagan las necesidades de comunicación humana.
Preguntas Frecuentes
¿Qué métrica se utiliza para evaluar programas de reconocimiento de voz?
La métrica principal para evaluar sistemas de Reconocimiento Automático de Voz (ASR) es la Tasa de Error de Palabras (WER). Calcula la precisión de transcripción comparando el número de errores (inserciones, eliminaciones y sustituciones) con el total de palabras en el transcript original. Otro método, SeMaScore, se centra en la evaluación semántica, ofreciendo mejores perspectivas en escenarios desafiantes, como el habla con acento o ruidoso.
¿Cómo se evalúa un modelo ASR?
Evaluar un modelo ASR implica usar una mezcla de métricas para medir tanto la precisión de la transcripción como cuán bien se conserva el significado. Esto asegura que el sistema funcione de manera confiable en varias situaciones.
| Componente de Evaluación | Descripción | Mejor Práctica |
|---|---|---|
| Tasa de Error de Palabras (WER) | Rastrea la precisión a nivel de palabras comparado con transcripciones humanas | Calcular la proporción de errores (inserciones, eliminaciones, sustituciones) sobre total de palabras |
| Tasa de Error de Caracteres (CER) | Se enfoca en la precisión a nivel de caracteres | Mejor para idiomas como el chino o el japonés |
| Comprensión Semántica | Verifica si el significado se preserva | Usar SeMaScore para una evaluación semántica más profunda |
| Pruebas en el Mundo Real | Evalúa el rendimiento en escenarios diversos (e.g., ruidoso, multilingüe) | Probar en varios entornos acústicos |
"La evaluación ASR se ha basado tradicionalmente en métricas basadas en errores".
Al evaluar modelos ASR, considere estos factores prácticos además de las métricas de precisión:
- Rendimiento en diferentes entornos de sonido
- Manejo de acentos y dialectos
- Capacidad de procesamiento en tiempo real
- Robustez contra ruido de fondo
Ajuste el proceso de evaluación a su aplicación específica mientras se adhiere a los estándares de la industria. Por ejemplo, plataformas como DubSmart enfatizan la precisión semántica para contenido multilingüe, haciendo que estos métodos de evaluación sean especialmente relevantes.