
Was Hörer wirklich hören, wenn eine Stimmennachahmung aufgeht
Take 17. Die Morgan-Freeman-Nachahmung ist nah dran — der Rhythmus ist da, der Mississippi-Akzent ist fast überzeugend — aber die Schwerkraft fehlt. Dein Hörer sagt „fast", was in der Spracharbeit das gleiche Wort wie „nein" ist. Du löschst den Take. Du versuchst es erneut. Vierzig Minuten später hast du nichts Brauchbares für das YouTube-Voiceover und dein Hals fängt an zu ermüden.
Dies ist die Falle, die Creator verschlingt, die einen mehrsprachigen Kanal aufbauen: eine Charakterstimme im Englischen perfekt hinbekommen, dann zusehen, wie sie zusammenbricht, sobald eine spanische oder Hindi-Synchronfassung in den Produktionsplan kommt – weil die Nachahmung phonetische Auswendiglernerei war, keine internalisierte Stimmensignatur. Studio-Stunden häufen sich an. Takes werden abgelehnt. Lokalisierungspläne werden stillschweigend zu den Akten gelegt. Content, der veröffentlicht werden sollte, wird es nicht.
Dieser Leitfaden zeigt auf, was Stimmennachahmungen wirklich beim Ohr des Hörers ankommen lässt, die vier Übungen, die das zugrundeliegende Handwerk aufbauen, und wo KI-Stimmenclonings als Skalierungswerkzeug – nicht als Ersatz für die Fähigkeit darunter – in den Workflow passt.

Inhaltsverzeichnis
- Was Hörer wirklich hören, wenn eine Stimmennachahmung aufgeht
- Die fünf stimmlichen Bausteine, auf denen jede Nachahmung ruht
- Vier Übungen, die Muskelgedächtnis für Stimmennachahmungen aufbauen
- Wo manuelle Stimmennachahmungs-Praxis an eine harte Grenze stößt
- Wie KI-Stimmenclonings die Reichweite eines erfahrenen Nachahmers verstärkt
- Baue dein Stimmennachahmungs-Toolkit auf – Ordne deinen Engpass dem richtigen Weg zu
- Häufig gestellte Fragen
Hörer identifizieren Stimmen nicht allein nach Tonhöhe. Sie identifizieren sie nach spektraler Fingerabdruck – der Formanten-Struktur, Vibrationsmuster und Zeitmuster, die eine spezifische Stimmtrakt-Anatomie erzeugt. Nach Stimmenforscherin Ingo R. Titze in Principles of Voice Production wird Stimmqualität hauptsächlich durch Stimmtrakt-Konfiguration und Resonanz geprägt, nicht durch Grundfrequenz. Zwei Menschen können die exakt gleiche Note summen und klingen immer noch völlig unterschiedlich, weil ihre Kehlen, Münder und Nebenhöhlen als unterschiedliche Filter auf diese gleiche Vibration wirken.
Das ist der Durchbruch für Stimmennachahmungen. Der Job ist nicht, eine Variable zu treffen. Es geht darum, eine fünfschichtige Signatur zu reproduzieren:
- Tonhöhenkontur – nicht nur die durchschnittliche Tonhöhe, sondern wo sie in einem Satz ansteigt und fällt
- Resonanzplatzierung – Brust, Maske, Nase, Kopf
- Atemmuster und Tempo – wo der Sprecher einatmet und wie lange ihre Pausen sind
- Artikulationssignatur – Konsonanten-Einsatz und Vokalform
- Emotionaler Subtext – das Gefühl, das jedes Wort antreibt, die Schicht, die Anfänger überspringen
Eine vollständige Diagnosetabelle kommt im nächsten Abschnitt. Behalte vorerst den Rahmen: Signatur, nicht Oberfläche.
Ähnlich klingen im Vergleich zu Als sie spielen
Es gibt einen Unterschied, den die arbeitende Voice-Acting-Welt als unverzichtbar behandelt: jemandem ähnlich zu klingen und als jemand zu spielen sind unterschiedliche Fähigkeiten. Dee Bradley Baker – der Charakterstimmen-Schauspieler hinter vielem von Star Wars: The Clone Wars und Avatar: The Last Airbender – hat seine gesamte Lehrpraxis auf der Argumentation aufgebaut, dass Charakterstimmen nur funktionieren, wenn der Performer das emotionale Leben, die Intention und die Körperlichkeit des Charakters versteht. Nicht nur Akzent. Nicht nur Tonfall. Nach seinen Unterrichtsmaterialien in I Want to Be a Voice Actor! erzeugt eine Nachahmung, die nur auf den Klang abzielt, ohne die Intention, etwas, das der Hörer als mechanisch registriert, selbst wenn er nicht artikulieren kann warum.
Zwei Dekonstruktionen, die die Theorie konkret machen
Betrachte Amateur-Darth-Vader-Nachahmungen. Sie klingen dünn, weil sie die falschen zwei Variablen anvisieren: Tonhöhe (tief) und Atemeffekt (schweres Ausatmen). Was sie verpassen, ist die Brustsonanz, wo die Stimme von James Earl Jones wirklich lebt. Der Atemeffekt ist eine Schicht, die auf einem brustgestützten Grundton aufgetragen ist – kein Ersatz dafür. Ohne diesen resonanten Anker klingt die Nachahmung wie jemand, der angestrengt flüstert, anstatt von innen eines Doms zu sprechen.
Eine sanftere Stimme dreht die Priorität um. Bei David Attenborough trägt das Tempo ungefähr 70% der Last. Das langsame Einatmen vor Schlüssel-Adjektiven. Der Auftritt bei Wunder-Wörtern. Die absteigenden Satzenden. Das Received-Pronunciation-Akzent zu kopieren, ohne den Rhythmus, erzeugt Dokumentarfilm-Parodie – nicht Attenborough.
Warum das für KI-Cloning wichtig ist
Die gleiche Wahrnehmungszerteilung, die bessere menschliche Nachahmungen aufbaut, erzeugt auch bessere KI-Stimmklone. Das Modell lernt Signatur, nicht Oberfläche. Ein Creator, der Resonanzplatzierung und Tempo internalisiert hat, ist also nicht nur besser im Spielen des Charakters – er zeichnet bessere Trainingsdaten auf, wenn er sich hinsetzt, um die Stimme dieses Charakters zu klonen. Die Fähigkeit überträgt sich. Der tiefere Teil des Artikels zeigt wie.
Die fünf stimmlichen Bausteine, auf denen jede Nachahmung ruht
Der vorherige Abschnitt benannte die Schichten. Dieser Abschnitt verwandelt sie in ein Diagnosewerkzeug, das du auf jedes Referenz-Audio in weniger als fünf Minuten anwenden kannst.
| Element | Was es ist | Wie man es in der Referenz identifiziert | Häufiger Anfänger-Fehler |
|---|---|---|---|
| Tonhöhe & Register | Natürliche Grundfrequenz und der Bereich, in dem sich der Sprecher bewegt | Summe mit; finde die niedrigste gehaltene Note und die typische „Heim"-Note | Auf eine Tonhöhe festlegen, anstatt die Kontur zu verfolgen |
| Resonanz & Ton | Wo die Stimme physisch vibriert – Brust, Maske, Nase, Kopf | Lege deine Hand auf Brust, Kehle, Wangenknochen, während du die Referenz abspielst; spüre, welcher Bereich summen würde | Timbre aus der Kehle kopieren, anstatt aus der richtigen Höhle |
| Atem & Tempo | Einatempunkte, Pausenlänge, Wörter pro Minute, Phrasing-Rhythmus | Markiere jeden Atem in einem 30-Sekunden-Clip; zähle Silben zwischen Atemzügen | Zu schnell sprechen, das Tempo des Charakters kollabieren lassen |
| Artikulation & Klarheit | Konsonanten-Einsatzstärke, Vokalopenness, Dialekt-Zungenplatzierung | Verlangsame die Referenz auf 0,5x Geschwindigkeit; isoliere Konsonanten-Einsätze | Generische „gute Diktion" anstatt der spezifischen Wahlmöglichkeiten des Charakters |
| Emotionaler Subtext | Das zugrundeliegende Gefühl, das jede Zeile färbt | Frage: Was will dieser Charakter in diesem Moment? | Wörter aufführen anstatt der Intention darunter |
Die Reihenfolge in der Tabelle ist nicht kosmetisch. Tonhöhe und Resonanz sind anatomisch – sie werden dadurch gesetzt, wo du die Stimme in deinem Körper platzierst. Wenn du diese falsch machst, kann kein Maß an Tempo oder Artikulation die Nachahmung später retten. Tempo und Artikulation sind behavioral – anpassbar durch Wiederholung. Emotionaler Subtext ist interpretativ – die Schicht, die eine technisch genaue Nachahmung in eine glaubwürdige verwandelt.
Probiere die Diagnose auf einem konkreten Ziel. Ein Creator, der Cate Blanchetts Galadriel versucht, findet schnell Tonhöhe: mittel-tief, hauchig. Die Falle ist Resonanz. Ihre Stimme sitzt in der Maske – dem Bereich hinter den Wangenknochen – nicht in der Kehle. Die meisten Amateur-Versuche ziehen die Resonanz hinunter in die Kehle, was kleiner und jünger klingt. Wenn die Resonanz erst korrekt in der Maske platziert ist, folgen das langsame Tempo und die verlängerten Vokale natürlich, weil die Höhle selbst den Rhythmus diktiert. Repariere die anatomische Schicht und die behavioral-Schichten korrigieren sich selbst.
Ein Hinweis für alle, die planen, ihre Nachahmung zu klonen
Die obige Diagnose gilt auch umgekehrt. Wenn du Trainingsaudio für einen Stimmenklon aufzeichnest, erfasst das Modell, was die konsistenteste Signatur im gesamten Datensatz ist. Nach dem Voiceover Masterclass Cloning Guide sollten Creator in einem konsistenten, neutralen Stil während einer durchgehenden Sitzung aufzeichnen – es sei denn, das ausdrückliche Ziel ist, eine stilisierte Charakterstimme zu klonen. Übersetzung: Wenn du einen Klon deiner Charakternachahmung anstatt deiner alltäglichen Sprechstimme möchtest, musst du für die gesamte Trainingsaufzeichnung im Charakter bleiben. Dazwischen hin- und herzuwechseln erzeugt einen matschigen Klon, der wie keiner von beiden klingt.
Dies ist auch der Grund, warum die Wahrnehmungsschichten aus Abschnitt 1 operativ wichtig sind. Ein driftender Performer erzeugt driftende Daten. Ein Performer mit internalisierter Resonanzplatzierung erzeugt stabile Daten. Der Klon ist nur so gut wie die Konsistenz der Signatur, die er lernt.
Vier Übungen, die Muskelgedächtnis für Stimmennachahmungen aufbauen
Die fünf stimmlichen Elemente zu kennen ist Diagnose. Diese vier Übungen sind Behandlung. Jede zielt auf einen bestimmten Fehlermodus ab und dauert 15 Minuten oder weniger.
Übung 1 – Die Isolationsschleife
Zielt ab: Tonhöhen- und Resonanzgenauigkeit.
- Wähle eine 5-Wort-Phrase aus deiner Referenz (z. B. „I have been expecting you")
- Schleife die Referenz 10-mal, um den Zielklang in dein Ohr einzubetten
- Zeichne deine Version auf, konzentriert auf nur Tonhöhe – ignoriere Resonanz, ignoriere Charakter, treffe einfach die melodische Kontur
- Zeichne erneut auf, konzentriert auf nur Resonanz – gleiche Phrase, ziele auf die richtige Höhle
- Zeichne erneut auf, konzentriert auf Tempo und Atem – gleiche Phrase, treffe das Timing genau
- Zeit: 15 Minuten täglich
Warum es funktioniert: Motorisches Lernprinzipien in der Stimmenpädagogik unterstützen blockierte Praxis (eine Variable gleichzeitig) gegenüber variabler Praxis beim Lernen neuer Koordinationen, eine Position, die konsistent mit Titzes Framework in Principles of Voice Production ist. Eine Variable zu isolieren trainiert die für sie verantwortliche Muskelgruppe, ohne die kognitive Last, alle fünf zu jonglieren.
Übung 2 – Der blinde Referenztest
Zielt ab: Gehörtraining, Selbstbetrug.
- Zeichne drei Takes einer 15-Sekunden-Passage im Charakter auf
- Warte mindestens 4 Stunden – frische Ohren
- Spiele die Referenz ab, dann deinen besten Take, abwechselnd ohne auf Wellenformen zu schauen
- Bewerte ehrlich: Welcher klingt mehr wie sie?
Die meisten Creator entdecken, dass ihr „bester Take" nicht der nächste war. Sie belohnten den Take, in dem sie die meiste Anstrengung spürten, anstatt den Take, der am genauesten landete. Der blinde Test bricht diese Vorspannung. Führe ihn wöchentlich durch.
Übung 3 – Der emotionale Anker
Zielt ab: Emotionaler Subtext, Performance-Authentizität.
Bevor du aufzeichnest, benenne den emotionalen Zustand des Charakters in der Szene. Gandalfs Schrei „You shall not pass!" ist kein Zorn – es ist schützende Entschlossenheit unter Erschöpfung. Die zwei Zustände klingen völlig unterschiedlich, auch wenn die Wörter identisch sind. Verkörpere es physisch: Haltung, Atemtiefe, wo du Spannung in deinem Körper hältst. Dee Bradley Bakers wiederholter Punkt in I Want to Be a Voice Actor! ist, dass Charakterstimme ohne Charakterintention mechanisch klingt. Zeichne nur auf, nachdem der Anker gesetzt ist. Bei jeder Sitzung.
Übung 4 – Der Mehrsprachen-Drucktest
Zielt ab: Signatur-Internalisierung vs. phonetische Auswendiglernerei.
Nimm deine Nachahmung und führe sie in einem völlig anderen Skript auf – einer Einkaufsliste, einem Wetterbericht, deinen liebsten Liedtexten – mit der gleichen Stimme. Wenn die Nachahmung zusammenbricht, sobald die Wörter sich ändern, hast du eine phonetische Sequenz auswendig gelernt, anstatt eine Stimmensignatur zu internalisieren.
Diese Übung ist die Torwächterin für Lokalisierungsarbeit. Wenn deine Nachahmung eine Einkaufsliste auf Englisch nicht aushalten kann, hält sie nicht bei der Synchronisierung ins Portugiesische. Wöchentlicher Rhythmus.
Wenn deine Nachahmung eine Einkaufsliste nicht überstehen kann, wird sie es nicht überstehen, in eine zweite Sprache synchronisiert zu werden.
Dein wöchentlicher Stimmennachahmungs-Trainingsplan
- Tägliche 15-Minuten-Isolationsschleife auf einem stimmlichen Element (rotieren: Tonhöhe → Resonanz → Tempo → Artikulation)
- Lege einen emotionalen Anker vor jeder Aufnahmesitzung fest
- Ein blinder Referenztest pro Woche mit 4+ Stunden Abstand zwischen Takes und Überprüfung
- Ein Mehrsprachen-Drucktest pro Woche mit Nicht-Skript-Material
- Zeichne jeden Freitag einen 30-Sekunden-„Signatur-Take" auf – gleiche Passage, gleicher Charakter – um Fortschritt von Woche zu Woche zu verfolgen
- Halte einen Rauschpegel von −60 dB oder niedriger in deinem Aufnahmeraum (Schallschaumdämung, keine Heizungslüftung, keine Ventilatoren), nach dem Voiceover Masterclass-Standard – das ist wichtig für Ohrentraining und jeden zukünftigen Cloning-Einsatz
Wo manuelle Stimmennachahmungs-Praxis an eine harte Grenze stößt
Die obigen Übungen bauen echte Fähigkeit auf, die kein Werkzeug vortäuschen kann. Sie haben auch eine Grenze. Ein einzelner erfahrener Performer hat einen endlichen Durchsatz – der Engpass ist nicht Talent, sondern Biologie und die Uhr. Vier Szenarien zeigen, wo diese Grenze zu einer Geschäftsbeschränkung wird.
Das 30-Minuten-Video-Problem. Ein Creator, der eine Charakterstimme über 30 Minuten Dialog hält, ermüdet stimmlich. Take 40 passt nicht zu Take 4. Tonhöhe driftet nach oben, Atem verkürzt sich, die Brustsonanz wandert in die Kehle. Schnitte im Edit-Zimmer kosten Stunden.
Das 6-Sprachen-Lokalisierungs-Problem. Selbst ein Creator, der Spanisch fließend spricht, kann seine englische Charakterstimme nicht unbedingt überzeugend auf Spanisch aufführen. Multipliziere das mit sechs Zielsprachen und der Lokalisierungsplan wird zu einem Jahr Stimmarbeit – angenommen, die mehrsprachige Aufführungsfähigkeit existiert überhaupt.
Das Kundenrevisions-Problem. Eine Zeilenänderung in Woche 8 bedeutet Neuaufnahmen im gleichen Stimmzustand – gleicher Raum, gleiche Tageszeit, gleiche Halstrockenheit. Praktisch unmöglich, es perfekt zu treffen.
Das Multi-Charakter-Problem. Ein Creator, der vier Charaktere in einer einzelnen Dialog-Szene spricht, braucht mindestens vier separate Aufnahmepässe, und die stimmlichen Übergänge erschöpfen den Kehlkopf schnell.
Stimmennachahmungs-Produktionsmethoden im Vergleich
| Faktor | Selbst aufgezeichnete Nachahmungen | Einstellung eines Voice Actors | KI-Stimmenclonings |
|---|---|---|---|
| Zeit bis zur ersten brauchbaren Aufnahme | Wochen bis Monate verteilte Praxis | 1–3 Tage (Casting + Aufnahme) | Sekunden für einen Anfänger-Klon aus einer 10-Sekunden-Probe; 30–120 min Aufnahme für Prosumer-Qualität |
| Erforderliche Aufnahmebasis | N/A – Live-Performance | N/A – Live-Performance | 30–120 sec (Schlüsselfertig); 10–15 min (RVC); 30 min–2 Stunden (Professionell) |
| Take-zu-Take-Konsistenz | Variabel – driftet mit Ermüdung | Hoch innerhalb einer Sitzung; variabel zwischen Sitzungen | Perfekt wiederholbar für gegebenen Text und Parameter |
| Mehrsprachige Skalierung | Erfordert Fließend + Nachahmungsfähigkeit in jeder | Mehrsprachiger Actor oder mehrere Actors | Cross-linguale KI Synchronisierung bewahrt Timbre über Ziele |
| Beste Eignung | Live-Performance, Kurzform, Ohrentraining | Premium einmalige Produktionen | Langform, mehrsprachig, iterativer Content |
Quellen für die obigen Zahlen: ElevenLabs-Tutorial, DeepReel, CloudPano, Kukarella und das RVC-Tutorial.
Dies ist kein Urteil, dass KI gewinnt. Manuelle Praxis erzeugt Fähigkeiten, die auf Live-Performance, Podcasting, Theater und das Ohrentraining übertragen, das jede andere Methode besser macht. Die Tabelle isoliert die spezifischen Produktionsszenarien, wo Biologie zu einem Engpass wird.
Die Gegenbeweise sind auch wichtig. Voice Actors und SAG-AFTRA haben öffentlich vermerkt, dass aktuelle KI-Klone noch mit komplexer emotionaler Nuance, Subtext und dynamischer Szenenbarbeit kämpfen – besonders in Drama und Komödie, wo Mikrotiming Bedeutung trägt. Für einen Creator, der ein sechssprachiges Erklärvideo produziert, ist diese Limitation akzeptabel. Für einen Creator, der eine narrative Animation mit drei emotionalen Wendepunkten pro Szene produziert, ist es noch nicht. Die ehrliche Synthese: Die Frage ist nicht „manuell oder KI." Es ist „wo gehört jede Methode im Workflow?"
Der Engpass in der Stimmennachahmungs-Arbeit ist nicht Talent – es ist Biologie und die Uhr.
Wie KI-Stimmenclonings die Reichweite eines erfahrenen Nachahmers verstärkt
Was Cloning wirklich erfasst
Ein Stimmenklon ist keine Aufnahme. Es ist ein gelerntes Modell einer Stimmensignatur. Das Modell erfasst Resonanzprofil, Tonhöhen-Kontourmuster, Atemrhythmus und Artikulationstendenzen aus dem Trainingsaudio, dann wendet sie auf neuen Text an. Stimmenforscherin Rupal Patel, Gründerin von VocaliD, hat in ihrem TED-Talk und zugehörigen Interviews argumentiert, dass authentische synthetische Stimmen idiosynkratische Prosodie erfassen, nicht nur durchschnittliche Tonhöhe, müssen, um als real anstatt generisch zu lesen.
Das ist genau der Grund, warum eine gut ausgeführte Nachahmung ein besserer Klon-Kandidat ist als eine flache neutrale Aufnahme. Die Signatur, die das Modell lernt, ist die Charaktersignatur. Ein Creator, der die Übungen aus Abschnitt 3 gemacht hat, geht in eine Stimmenklon-Sitzung mit saubereren, konsistenteren Daten als jemand, der nicht – und der resultierende Klon spiegelt diesen Unterschied direkt.
Die Datensatz-Realität
Es gibt drei Qualitätsstufen, jede mit spezifischen Beispielanforderungen.
- Anfänger / Instant-Klon: ~10 Sekunden klare Rede erzeugt einen grundlegenden Test-Klon, mit dem du in Sekunden experimentieren kannst, nach dem ElevenLabs-Tutorial.
- Creator-Qualität Erzähler-Klon: 30–120 Sekunden sauberes Audio erzeugen einen stabilen Erzähler-Stil-Klon, nach DeepReel und CloudPano.
- Professioneller Qualität-Klon: 30 Minuten bis 2 Stunden Aufnahmen, mit Ergebnissen, die näher bei der 2-Stunden-Marke deutlich besser werden; Verarbeitungszeit auf Provider-Infrastruktur beträgt ungefähr 2–6 Stunden, nach dem ElevenLabs-Tutorial.
- Open-Source-RVC-Stack: 10–15 Minuten sauberes Audio ist der Praktiker-Sweet-Spot; 2–10 Minuten sind möglich mit Qualitäts-Trade-offs; 40 kHz Abtastrate ist der Praktiker-Standard, nach dem RVC-Tutorial.
Der technische Mindeststandard ist nicht verhandelbar: ein Rauschpegel von ≤ −60 dB und keine Kompression, EQ, De-Essing oder Rauschunterdrückung auf den rohen Trainingsdateien angewendet, nach dem Voiceover Masterclass-Standard. Garbage in, Garbage out gilt doppelt – das Modell verstärkt alle Artefakte, die in der Quelle existieren.

Zwei Workflow-Fallstudien
Fall A – Der 30-Minuten-YouTuber. Ein Creator knackt eine Charakternachahmung für 30 Sekunden, verliert aber über eine Langform-Episode Konsistenz. Der Workflow: Zeichne einen perfekten 90-Sekunden-Take der Charakterstimme auf. Klone ihn. Generiere den Hintergrund-Dialog mit dem Klon unter Verwendung von Text-zu-Sprache, während du die Live-Performance-Energie für die fünf oder sechs wichtigen emotionalen Wendepunkte aufbewahrst, die die Episode tragen. Das Ergebnis: Konsistente Stimme über 30 Minuten, Performance-Spitzen wo sie wichtig sind, Aufnahmesitzung von ungefähr 8 Stunden auf etwa 90 Minuten komprimiert.
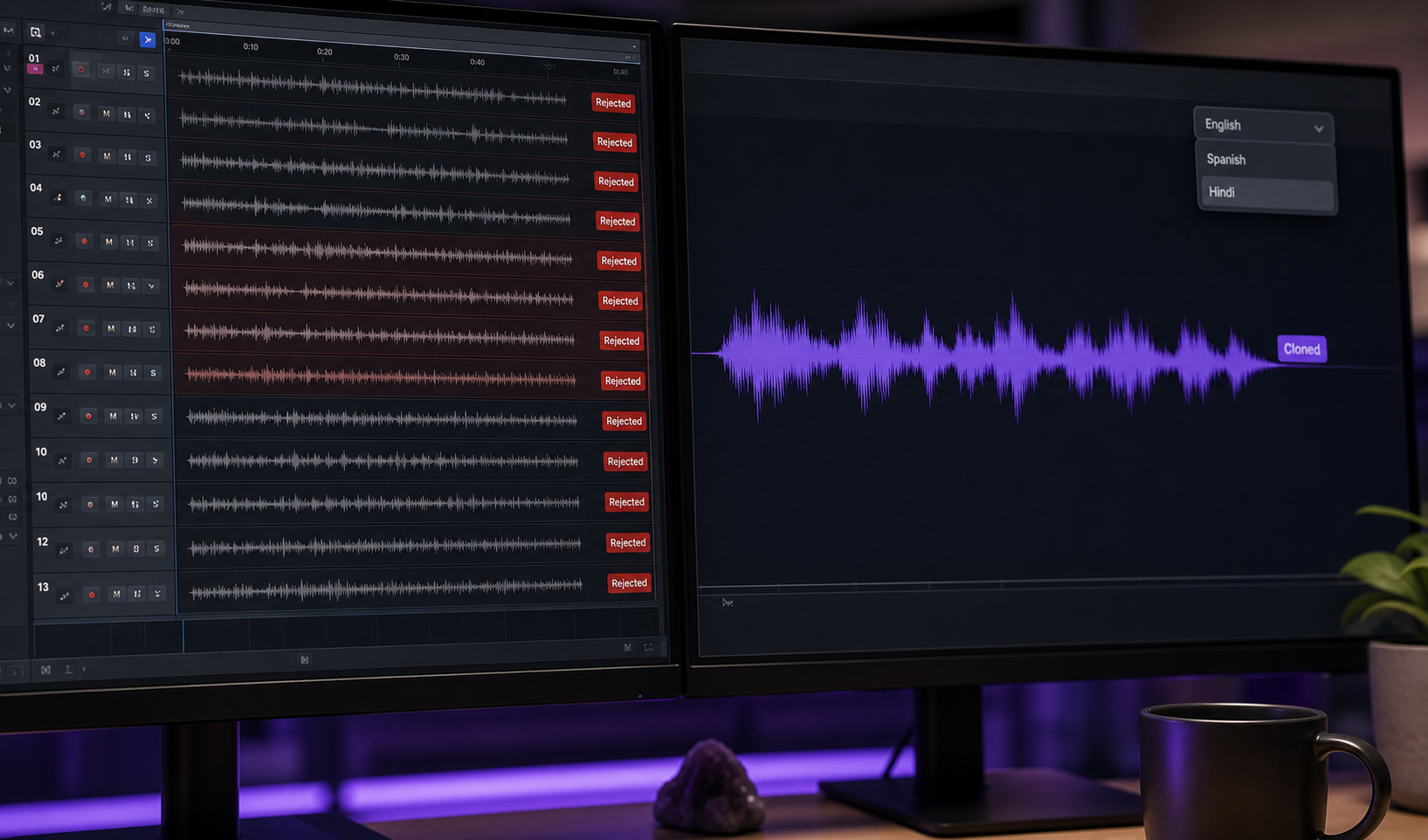
Fall B – Das 6-Sprachen-Trainings-Video. Ein kleines Unternehmen produziert ein 15-Minuten internes Trainingsmodul mit Erzählung in einer warmen, autoritären Charakterstimme. Der Workflow: Zeichne die englische Version einmal mit der Live-Nachahmung auf. Klone die Stimme. Nutze Cross-linguale Klonung über eine Stimmenklon-API, um Spanisch, Portugiesisch, Französisch, Deutsch, Hindi und Japanisch-Versionen zu rendern und dabei die Charakter-Timbre über Sprachen zu bewahren, nach DeepReel und Kukarella. Der gleiche Charakter „spricht" alle sechs Sprachen, weil die Signatur überträgt, auch wenn die Sprache es nicht tut.
Stimmenclonings ersetzen nicht die Fähigkeit, eine Nachahmung zu knacken – es verstärkt sie. Der schwierige Teil ist immer noch, den Charakter richtig hinzubekommen; die Technologie entfernt nur die Wiederholung.
Ethik und die Legitimitäts-Grenze
Synthetische Stimme kann als Waffe verwendet werden. Juraprofessorin Danielle Citron, in The Fight for Privacy und zugehörigen Deepfake-Materialien, dokumentiert, wie nicht zugestimmtes Stimmenclonings von echten Menschen Identitätsdiebstahl, Betrug und politische Desinformation ermöglicht – und argumentiert für sowohl rechtliche Schutzmaßnahmen als auch Design-Level-Guardrails auf kommerziellen Werkzeugen.
Die ethische Linie für Creator ist einfach. Deine eigene Stimme für deinen eigenen Content zu klonen ist eindeutig in Ordnung. Eine fiktive Charakterstimme zu klonen, die du selbst entwickelt hast, ist in Ordnung. Eine echte öffentliche Person zu klonen, oder irgendjemand, ohne ausdrückliche Zustimmung ist es nicht. Offenlegung in Credits, wenn KI-Synchronisierung verwendet wird, wird Standard-Praxis und ist das sicherere Standard für jede kommerzielle Arbeit.
Baue dein Stimmennachahmungs-Toolkit auf – Ordne deinen Engpass dem richtigen Weg zu
Die Wahl ist nicht manuelle Praxis oder KI-Clonings. Es geht darum, zu identifizieren, welcher Engpass deine Arbeit wirklich gerade blockiert, und den passenden Weg anzuwenden. Die Matrix unten ordnet vier häufige Creator-Situationen zu spezifischen ersten Aktionen.
Welcher Stimmennachahmungs-Weg passt zu deinem Engpass?
| Deine Situation | Primärer Engpass | Werkzeug-Priorität | Erste Aktion diese Woche |
|---|---|---|---|
| Nachahmungen sind noch nicht überzeugend – Handwerk bauen für YouTube oder Twitch | Fähigkeitslücke | Übungen aus Abschnitt 3 + Peer-Feedback | Wähle einen Charakter; führe täglich die Isolationsschleife für 14 Tage aus, bevor du bewertest |
| Starke Nachahmung, aber erschöpft bei Neuaufnahmen von Langvideos | Stimmermüdung, Konsistenz-Drift | Stimmenclonings deiner eigenen aufgeführten Nachahmung | Zeichne einen sauberen 90-Sekunden-Take im Charakter bei −60 dB auf; klone ihn; teste auf einer 2-Minuten-generierten Passage |
| Lokalisierung existierenden englischen Contents in mehrere Sprachen | Mehrsprachige Performance-Lücke | Cross-linguale Klonung + KI-Synchronisierung | Klone deine Referenznachahmung einmal; synchronisiere eine 2-Minuten-Probe in deine wichtigste Zielsprache; überprüfe auf Charakter-Bewahrung |
| Team produziert mehrsprachigen Branded-Content im großen Stil | Pipeline-Skalierbarkeit | Klonings + API-Integration | Prototypisiere den KI-Synchronisierungs-API-Workflow auf einem Produktionsprojekt |
Drei arbeitende Prinzipien für die ehrliche Anwendung dieser Matrix.
Die Matrix ist nicht permanent. Ein Creator in Zeile eins heute bewegt sich in Zeile drei in achtzehn Monaten. Der Engpass verschiebt sich, wenn die Arbeit sich verschiebt. Evaluiere quartalsweise neu.
Clonings verstärkt; es stammt nicht ab. Das wiederholte Ergebnis über Clonings-Tutorials – Voiceover Masterclass, der ElevenLabs-Anleitung, das RVC-Tutorial – ist, dass Audio-Qualität und Performance-Qualität in der Quelle Klon-Qualität bestimmen. Ein Creator, der Abschnitt 3 überspringt und versucht, eine schludrige Nachahmung zu klonen, bekommt einen Klon einer schludrigen Nachahmung. Die Technologie ist treu zu ihrer Eingabe.
Die 30-Sekunden-Grenze ist operativ wichtig. Mehrere Schlüsselfertig-Plattformen können ein arbeitendes Stimmprofil aus ungefähr 20–30 Sekunden sauberes Audio erzeugen. Das bedeutet, ein Creator, der bereits einen guten Take seiner Charakterstimme hat, ist eine Hochladung entfernt von einem wiederverwendbaren Produktions-Asset. Die Barriere ist nicht die Technologie – es ist, einen guten Take zu haben.
Adressiere auch den Gegendruck. Einige Stimmcoachs warnen, dass frühes hartes Anlehnen an Clonings die grundlegende Fähigkeitsentwicklung begrenzen kann: Atemstütze, Resonanzkontrolle, Artikulation. Der pragmatische Mittelweg ist, die Übungen weiter zu machen, selbst wenn du den Klon für die Produktion verwendest, weil die Übungen jeden zukünftigen Klon besser machen.
Dein 14-Tage-Aktionsplan
- Identifiziere, welche Zeile der Matrix deinen aktuellen Engpass beschreibt – sei ehrlich; die meisten Creator sitzen in zwei Zeilen gleichzeitig. Wähle die schmerzhaftere.
- Wenn deine Zeile „Fähigkeitslücke" ist: Verpflichte dich zur täglichen 15-Minuten-Isolationsschleife und einem wöchentlichen blinden Referenztest für die vollen 14 Tage, bevor du neu evaluierst.
- Wenn deine Zeile Cloning involviert: Zeichne einen sauberen 30–90 Sekunden-Referenz-Take mit einem Rauschpegel bei oder unter −60 dB auf, im Charakter, in einer durchgehenden Sitzung, ohne EQ oder Kompression angewendet.
- Führe einen Low-Stakes-Klon-Test durch, bevor du Client- oder Revenue-Arbeit machst – verwende ihn auf einem internen Video, einem persönlichen Kanal-Test oder einem Entwurf-Skript.
- Wenn du lokalisierst: Wähle deine wichtigste Zielsprache und synchronisiere eine 2-Minuten-Probe. Überprüfe speziell auf Charakter-Bewahrung, nicht nur Übersetzungsgenauigkeit.
- Wenn du in eine Produktions-Pipeline integrierst: Prototypisiere den API-Workflow auf einem Projekt, bevor du standardisierst. Teste die Text-zu-Sprache-API und Stimmenklon-API auf einem repräsentativen Content-Typ.
- Lege einen 14-Tage-Checkpoint fest, um deinen Engpass neu zu bewerten – er könnte sich bewegt haben.
Die Creator, die 2025 bei mehrsprachigem Content gewinnen, sind nicht diejenigen, die das richtige Werkzeug gewählt haben. Sie sind diejenigen, die erst eine echte Nachahmung aufgebaut haben, dann die Werkzeuge tun lassen, was Werkzeuge am besten tun – sie wiederholen, skalieren und über Sprachen bewahren, die sie nicht sprechen.
Häufig gestellte Fragen
Kann ich KI-Stimmenclonings verwenden, um Nachahmungen echter öffentlicher Personen zu machen?
Rechtlich und ethisch: nicht ohne ausdrückliche Zustimmung, und selbst dann, offenbaren. Danielle Citrons Materialien zu Deepfakes und synthetischen Medien dokumentieren, wie nicht zugestimmtes Stimmenclonings von echten Menschen Betrug, Belästigung und politische Desinformation ermöglicht. Für einen fiktiven Charakter, den du entwickelt hast, oder deine eigene Stimme, ist Clonings eindeutig. Für eine Nachahmung einer lebenden öffentlichen Person ist die sicherste Antwort nein – und seriöse Plattformen durchsetzen Richtlinien, die mit diesem Prinzip ausgerichtet sind. Offenlegung in Credits wird Praxis-Standard und ist die sicherere Voreinstellung für jede kommerzielle Arbeit, die synthetische Stimme nutzt.
Wie lange dauert es wirklich, eine nutzbare Stimme zu klonen?
Das hängt von der Qualitätsstufe ab. Eine 10-Sekunden-Probe erzeugt einen experimentellen Klon, den du in Sekunden testen kannst, nach dem ElevenLabs-Tutorial. Eine 30–120 Sekunden-Probe erzeugt einen stabilen Creator-Qualität-Klon geeignet für Erzählung und Erklärvideo-Content, nach DeepReel und CloudPano. Ein professioneller Klon braucht 30 Minuten bis 2 Stunden Quellaufnahme plus ungefähr 2–6 Stunden Verarbeitungszeit auf Provider-Infrastruktur. Die meisten Creator-Plattformen sitzen komfortabel am schnellen Ende der Creator-Stufe und akzeptieren ungefähr 20–30 Sekunden sauberes Audio als Arbeits-Mindeststandard.
Muss ich offenlegen, dass ich KI-Stimmenclonings in meinem Content verwendet habe?
Es gibt noch keine universelle rechtliche Anforderung, aber Offenlegung wird Praxis-Standard und ist die sicherere Voreinstellung. Wenn du deine eigene Stimme für Effizienz geklont hast, schützt eine einfache Zeile in den Credits – „Stimme geklont via [Plattform] für Multi-Language-Versionen" – Publikums-Vertrauen. Wenn der Content eine echte Person darstellt, auch mit ihrer Zustimmung, ist Offenlegung essentiell. SAG-AFTRAs fortlaufende Position zu KI-Stimmeneinsatz in kommerzieller Arbeit treibt die breitere Industrie zu klarer Kennzeichnung, und Alignment deiner Praxis damit früh vermeidet Ruf- und rechtliche Belastung später.