
Sie haben sich durch vierzig Stimmproben gescrollt. Kopfhörer auf, Sie tippen auf Vorschau, hören drei Sekunden lang zu, tippen auf die nächste, und die nächste, bis jede Probe in dasselbe undeutliche Summen verschwimmt. Ist diese „warm" oder einfach nur „weich"? Sollte der Erklärfilm „autoritär" oder „freundlich" klingen? Das Problem ist kein Mangel an Auswahl — moderne Bibliotheken halten über 300 Stimmen bereit, und Sie können sie eine Stunde lang vorhören, ohne sich für eine zu entscheiden. Das Problem sind Stimmdeskriptoren: der präzise Wortschatz, den Sie brauchen, um eine Stimme von einer anderen zu unterscheiden und sie gezielt an Ihren Inhalt anzupassen. Ohne diesen Wortschatz wird die Stimmauswahl zum Ratespiel und die Synchronisation zu teurem Trial-and-Error. Laut WP SEO AI sind Einwort-Bezeichnungen wie „natürlich" oder „ansprechend" zu vage, um umsetzbar zu sein — ein klares Stimmporträt erfordert die gleichzeitige Angabe mehrerer zusammenwirkender Dimensionen. Am Ende dieses Artikels werden Sie in der Lage sein, jede Stimme präzise über Ton, Tonhöhe und Stil hinweg zu beschreiben, sodass Sie Stimmtools durchsuchen, filtern und ansteuern — oder ein Klonprojekt briefen — können, mit Zuversicht statt mit Glück.

Inhaltsverzeichnis
- Die vier Dimensionen, unter die jeder Stimmdeskriptor fällt
- Tondeskriptoren entschlüsselt — von „warm" bis „autoritär"
- Tonhöhe und Tempo — die technischen Deskriptoren, die Menschen falsch machen
- Stil und Register — die Stimme an den Inhaltskontext anpassen
- Deskriptoren zu einer präzisen Stimmsuche oder einem Prompt stapeln
- Deskriptor-Fallen — wo die Stimmauswahl unbemerkt scheitert
- Ihre Copy-Paste-Briefing-Vorlage für Stimmdeskriptoren
- Fragen zu Stimmdeskriptoren, die Creator wirklich stellen
Die vier Dimensionen, unter die jeder Stimmdeskriptor fällt
Jeder Stimmdeskriptor, den Sie je gelesen haben — egal wie poetisch — fällt in vier messbare Dimensionen zusammen. Sobald Sie sie benennen können, hört der Wortschatz auf, subjektiv zu wirken, und beginnt, sich wie ein Satz von Reglern zu verhalten, die Sie unabhängig voneinander anpassen können.
Ton ist die emotionale Färbung oder Haltung der Stimme. Warm, kalt, enthusiastisch, distanziert — das ist der emotionale Charakter, den ein Zuhörer wahrnimmt, bevor er die Bedeutung eines einzigen Wortes verarbeitet. Es ist die Dimension, die entscheidet, ob sich Ihr Publikum hineinlehnt oder abschaltet.
Tonhöhe ist die wahrgenommene Höhe oder Tiefe des Klangs. Ein tiefer, resonanter Bariton liegt am einen Ende; ein heller, leichter, jugendlicher Klang am anderen. Tonhöhe ist im Grunde eine Frequenzeigenschaft, was sie zu einem der objektivsten der vier Deskriptoren macht — und doch wird sie auch am häufigsten mit dem Tempo verwechselt.
Tempo und Rhythmus beschreiben die Sprechgeschwindigkeit und ihre Kadenz. Schnell, gemessen, gemächlich, bedächtig — Tempo umfasst die Pausen zwischen Phrasen und die Betonungsmuster, die darüber liegen. Zwei Stimmen, die identische Skripte in unterschiedlichem Tempo lesen, können sich wie völlig verschiedene Darbietungen anfühlen.
Stil und Register bestimmen den Darbietungskontext und die Formalität. Erzählung, gesprächig, Rundfunk, E-Learning — formell versus locker. Das ist die Dimension, die entscheidet, welche Rolle die Stimme für den Zuhörer spielt.
Diese Taxonomie ist keine persönliche Meinung. Die Nielsen Norman Group formalisiert den Ton entlang vier unabhängiger Achsen — formell vs. locker, ernst vs. lustig, respektvoll vs. respektlos und sachlich vs. enthusiastisch — und zeigt damit, dass Ton mehrachsig ist, nicht ein einzelner Schieberegler, den Sie von „langweilig" zu „spaßig" ziehen. Kommerzielle Plattformen setzen dieselbe Logik in die Praxis um. Der Stimmmarktplatz Voices.com gruppiert die Stimmbeschreibung in vier Qualitäten: Tonhöhe und Ton, Lautstärke und Projektion, Artikulation und Aussprache sowie Geschwindigkeit und Betonung. Andere Bezeichnungen, dieselbe zugrundeliegende Struktur.

Warum ist das Trennen der Dimensionen so wichtig? Der Kommunikationscoach Robin Kermode versteht Ton, Tonhöhe und Tempo als die drei Hebel, die gemeinsam „stimmliche Vielfalt" erzeugen — er definiert Ton als emotionalen Charakter, Tonhöhe als die wahrgenommene Frequenz, die die emotionale Bedeutung verändern kann, und Tempo als die Liefergeschwindigkeit. Stil und Register bilden den vierten Hebel, und er sitzt über den anderen dreien und bestimmt den Kontext, in dem sie operieren. Einfach gesagt: Ton, Tonhöhe und Tempo beschreiben, wie die Stimme klingt; Stil und Register beschreiben, welche Rolle sie spielt.
Jeder Stimmdeskriptor, den Sie je gelesen haben, fällt in vier Hebel zusammen — Ton, Tonhöhe, Tempo und Stil. Beherrschen Sie die Hebel, und Sie hören auf zu raten.
Behalten Sie dieses Modell im Kopf. Jeder folgende Abschnitt taucht in genau eine dieser vier Dimensionen ein, und keiner davon wird das Framework neu definieren. Wenn Ihnen irgendwo ein Deskriptor begegnet — ein Marktplatzfilter, ein KI-Prompt-Feld, ein Agenturbriefing — besteht Ihre erste Aufgabe darin, ihn in einen der vier Eimer einzuordnen. Diese eine Gewohnheit verwandelt eine Wand aus Adjektiven in ein organisiertes Bedienfeld.
Tondeskriptoren entschlüsselt — von „warm" bis „autoritär"
Ton ist die Dimension, die das Publikum zuerst registriert, und es ist diejenige, die am häufigsten falsch gebrieft wird, weil sie sich auf subjektive Adjektive stützt. Die Forschung der Nielsen Norman Group zeigt, dass der Ton über mehrere unabhängige Achsen operiert — Humor, Formalität, Respekt und Enthusiasmus sind separate Hebel —, was bedeutet, dass ein einzelnes Tonwort selten erfasst, was Sie tatsächlich wollen. Bündeln Sie stattdessen Ihre Tondeskriptoren, und Sie erhalten sowohl Präzision als auch eine praktische Möglichkeit zu filtern.
Vertrauensbildend (warm, freundlich, beruhigend). Dieses Cluster baut emotionale Sicherheit auf, bevor die Bedeutung ankommt. Es ist die richtige Wahl für Gesundheits-Erklärfilme, Kundensupport-IVR und Onboarding-Videos, bei denen ein Zuhörer sich gehalten fühlen muss, bevor er Anweisungen aufnimmt. WP SEO AI führt „warm" unter den am häufigsten verwendeten emotionalen Tonadjektiven auf, und das aus gutem Grund — es ist die Grundlinie, der die meisten Zuhörer standardmäßig vertrauen.
Energetisch (schwungvoll, enthusiastisch, lebhaft). Dieses Cluster signalisiert Schwung und Aufregung. Es eignet sich am besten für Produkteinführungen, Werbespots und Social Shorts, bei denen die ersten zwei Sekunden entscheiden, ob jemand weiterschaut. Die „enthusiastisch"-Achse der NN/g passt direkt hierher — und beachten Sie, dass sie unabhängig von der Formalität ist, sodass Sie gleichzeitig energetisch und professionell sein können.
Ernst (autoritär, professionell, gedämpft). Dieses Cluster vermittelt Glaubwürdigkeit und Gewicht. Greifen Sie darauf zurück bei Unternehmensschulungen, Finanz-Erklärfilmen und Dokumentar-Erzählungen, bei denen das Publikum darauf vertrauen muss, dass der Sprecher mehr weiß als sie. „Autoritär" ist ein Aushängeschild-Deskriptor in der Stimmporträt-Liste von WP SEO AI — spezifisch genug, um darauf zu filtern, und breit genug, um über Formate hinweg anwendbar zu sein.
Intim (sanft, beruhigend, gesprächig). Dieses Cluster erzeugt Nähe und Ruhe. Es ist gemacht für Meditations-Apps, Podcast-Intros und ASMR-artige Inhalte, bei denen der Zuhörer oft allein ist und sich die Stimme anfühlt, als spräche sie direkt zu ihm. Die Intimität entsteht ebenso sehr aus Zurückhaltung wie aus Wärme — dieses Cluster zieht sich zurück, anstatt zu projizieren.
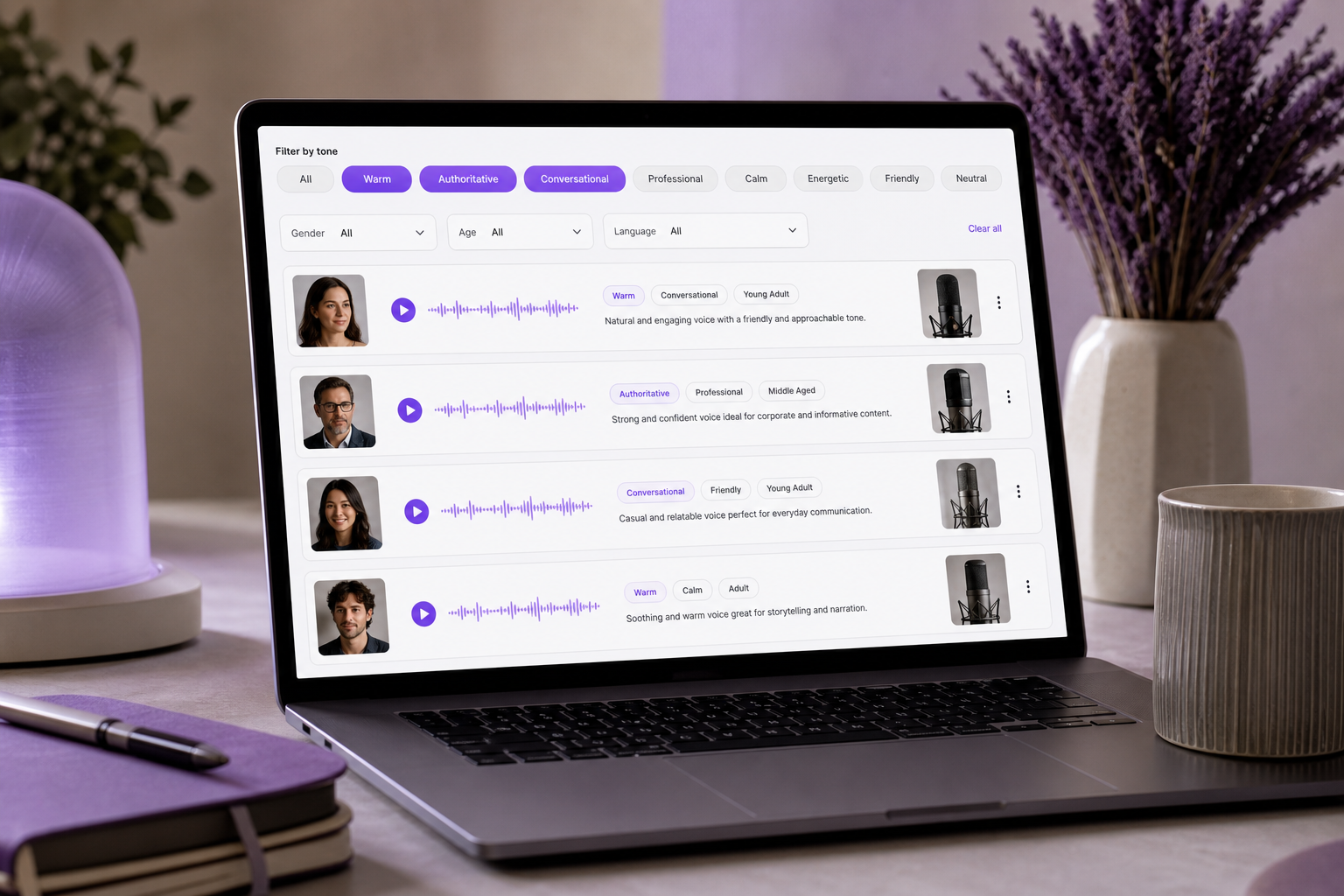
Ton ist die einzige Dimension, die das Publikum zuerst bemerkt und zuletzt vergisst — sie schafft emotionales Vertrauen, bevor die Bedeutung eines einzigen Wortes ankommt.
Diese Cluster sind nicht nur ein mentales Modell — sie sind die Art, wie moderne Tools Sie suchen lassen. Eine TTS-Plattform wie SymTrain dokumentiert das Filtern von Stimmen nach Ton wie „artikuliert, locker, ängstlich" und engt eine große Bibliothek ein, bevor Sie überhaupt auf Vorschau drücken. Das ist der praktische Nutzen des Bündelns Ihrer Stimmdeskriptoren: So wie eine Text-to-Speech-Bibliothek Sie vor dem Vorhören nach Ton filtern lässt, verwandelt ein klares Toncluster eine Stunde Vorhören in eine fokussierte Auswahlliste von drei.
Tonhöhe und Tempo — die technischen Deskriptoren, die Menschen falsch machen
Tonhöhe und Tempo sind die beiden am häufigsten verwechselten Dimensionen in jedem Stimmbriefing, und die Verwechslung kostet Creator echte Zeit. Tonhöhe ist Frequenz — die wahrgenommene Höhe oder Tiefe einer Stimme. Tempo ist Geschwindigkeit und Rhythmus — Wörter pro Minute, Kadenz und die Platzierung von Pausen. Robin Kermodes Dreiteilung hält sie sauber getrennt: Ton ist emotionaler Charakter, Tonhöhe ist wahrgenommene Frequenz, Tempo ist Sprechgeschwindigkeit. Drei getrennte Dinge.
Der klassische Fehler ist das Vertauschen des Wortschatzes. Creator sagen „schnell", wenn sie „hochtonig" meinen, oder „tief", wenn sie „langsam" meinen. Das sind unabhängige Regler. Eine tiefe Stimme kann zügig sein. Eine hohe Stimme kann gemessen sein. Sie als ein einziges verschwommenes Adjektiv zu behandeln, ist die Art, wie Briefings schiefgehen, bevor überhaupt eine Silbe aufgenommen wird.
| Deskriptor | Was er steuert | Klingt wie | Am besten für |
|---|---|---|---|
| Tief | Tonhöhe (niedrige Frequenz) | Bariton, resonant | Dokumentation, Luxusmarke |
| Hell | Tonhöhe (hohe Frequenz) | Leicht, luftig, jugendlich | Kinderinhalte, schwungvolle Werbung |
| Gemessen | Tempo (langsam/gleichmäßig) | Bedächtig, geräumig | E-Learning, Tutorials |
| Zügig | Tempo (schnell) | Energetisch, dringlich | Nachrichten, Promos |
| Abgehackt | Tempo + Artikulation | Knackig, präzise Stopps | Technisch, instruktiv |
| Schleppend | Tempo (langsam/entspannt) | Gedehnt, locker | Erzählung, Charakter |
Die interessante Arbeit passiert, wenn Tonhöhe und Tempo sich kombinieren, denn der zusammengesetzte Eindruck ist fast immer stärker als jeder Deskriptor allein. Tiefe Tonhöhe mit zügigem Tempo liest sich als selbstbewusste Dringlichkeit — die Stimme von jemandem, der das Material kennt und Ihre Zeit nicht verschwendet. Helle Tonhöhe mit gemessenem Tempo liest sich als freundliche Geduld — ideal, wenn Sie einen nervösen Nutzer durch eine Ersteinrichtung führen. Vertauschen Sie die Kombinationen, und die Bedeutung kippt komplett, was genau der Grund ist, warum Sie die beiden Felder nicht in eines zusammenfassen können.
Diese Trennung ist fest darin verankert, wie ernsthafte Plattformen ihre Anleitung strukturieren. Voices.com behandelt Tonhöhe/Ton und Geschwindigkeit/Betonung als zwei seiner vier eigenständigen Qualitäten, niemals als eine einzige Einstellung. Die Hamsa-API-Dokumentation listet ebenso Sprechtempo und Aussprache/Klarheit als separate Auswahlkriterien, die jeweils einzeln bewertet werden, bevor eine Stimme in Produktion geht. Die Erkenntnis für Praktiker ist direkt: Geben Sie in jedem Briefing Tonhöhe und Tempo ihre eigenen Felder. Schreiben Sie „tiefe Tonhöhe, zügiges Tempo", nicht „eine pointierte tiefe Stimme" und hoffen, dass der Leser es entwirrt. Und denken Sie daran, dass dieselben Tonhöhen- und Tempomerkmale, die Sie hier angeben, das sind, was ein Voice-Cloning-Modell aus einer Quellprobe bewahrt — den Wortschatz in der Briefing-Phase richtig hinzubekommen, trägt also bis hin zum geklonten Ergebnis.
Stil und Register — die Stimme an den Inhaltskontext anpassen
Die Fähigkeit mit dem höchsten Hebel bei der Stimmauswahl besteht nicht darin, die beeindruckendste Stimme auszuwählen. Es geht darum, den richtigen Stil und das richtige Register für den Liefer-Kontext zu wählen — die Stimme, die Ihr Publikum erwartet und nie hinterfragt. Die Anleitung des Designsystems von PatternFly trennt Stil (Grammatik- und Syntaxwahl), Stimme (Markenpersönlichkeit) und Ton (den emotionalen Zustand des Nutzers), und die Parallele zur gesprochenen Stimme bildet sich sauber ab: Stil und Register auf der einen Seite, emotionaler Ton auf der anderen. Treffen Sie das Register falsch, und selbst eine schöne Stimme fühlt sich fehl am Platz an.
Die Hamsa-Dokumentation macht die Stilunterscheidung mit expliziter Anwendungsfall-Begründung greifbar. „Gesprächig" ist natürlich und freundlich — am besten für Kundenservice und Support. „Erzähler" ist klar und artikuliert — geeignet für Erklärungen. Diese „klingt wie / am besten für"-Rahmung ist genau das, was Stil in eine Entscheidung verwandelt, die Sie in Sekunden treffen können, statt einen Nachmittag lang zu debattieren.
| Inhaltstyp | Empfohlener Stildeskriptor | Warum es funktioniert |
|---|---|---|
| YouTube-Erklärfilm | Gesprächig | Natürlich, freundlich — hält lockere Zuschauer bei der Stange |
| Unternehmensschulung | Erzähler | Klar, artikuliert — geeignet für Erklärungen |
| Podcast-Intro | Gesprächig / Rundfunk | Schafft warme, vertraute Moderatorenpräsenz |
| Hörbuch | Erzähler | Anhaltende Klarheit beim Langform-Hören |
| Werbung / Promo | Energetischer Rundfunk | Projiziert Schwung und einen Handlungsaufruf |
Unter dem Stil sitzt das Register — die Wahl zwischen formell und locker, die alles darüber prägt. Die formell↔locker-Achse der NN/g ist der sauberste Weg, darüber nachzudenken: Derselbe gesprächige Stil kann sich als polierter Rundfunkmoderator oder als Freund am Tisch lesen, je nachdem, wo Sie den Registerregler einstellen. Ein Schulungs-Erzähler in lockerem Register fühlt sich zugänglich an; derselbe Erzähler in formellem Register fühlt sich institutionell an. Keines ist falsch — sie sind Antworten auf unterschiedliche Briefings.
Zwei weitere Schichten stapeln sich darüber. Akzent und Dialekt sind Kernauswahlkriterien in Hamsas Checkliste, und sie tragen ein kulturelles Gewicht, das kein Tondeskriptor überschreiben kann — eine „neutrale US"-Stimme und eine „britische RP"-Stimme können identischen Ton, identische Tonhöhe und identisches Tempo teilen und trotzdem bei einem Publikum völlig anders ankommen. SymTrain empfiehlt Altersgruppenfilter — jung, erwachsen, älter — neben dem Ton, weil das wahrgenommene Alter verändert, wie autoritär oder nahbar sich eine Stimme anfühlt.
Der richtige Stildeskriptor ist nicht die beeindruckendste Stimme — es ist die, die Ihr Publikum in diesem Moment zu hören erwartet und nie hinterfragt.
PatternFlys schärfster Punkt ist, dass Stil und Ton auf den emotionalen Zustand des Publikums reagieren müssen, nicht auf einen markenweiten Standard. Fehlerbehebungsinhalte brauchen ein neutrales, hilfreiches Register; eine Ankündigung braucht ein enthusiastisches. Der Kontext diktiert jedes Mal das Register. Und Registerentscheidungen bleiben nicht an Ort und Stelle, wenn Ihr Inhalt reist — ein lockeres, gesprächiges Register, das im Englischen perfekt ankommt, kann sich in einem anderen Markt frech oder unprofessionell lesen. Das ist eine Registerwahl, die standhalten muss, wenn Sie den Inhalt durch KI-Synchronisation in andere Sprachen schieben, und genau da zahlt sich die nächste Schicht der Disziplin aus.
Deskriptoren zu einer präzisen Stimmsuche oder einem Prompt stapeln
Wortschatz zählt nur, wenn Sie ihn in eine wiederholbare Methode verwandeln können. Die Forschung ist beim Kernprinzip konsistent: Gestapelte Deskriptoren schlagen einzelne Bezeichnungen jedes Mal. WP SEO AI empfiehlt, emotionale Tonadjektive wie „warm", „knackig" oder „autoritär" mit konkreten Details zu Tempo, Tonhöhenvariation, Resonanz und Klarheit zu kombinieren, um ein klares Stimmporträt aufzubauen. Voices.com formalisiert eine dreistufige Pipeline — den Charakter definieren (Alter, Geschlecht, Stil), den Ton festlegen, dann passende Schlüsselwörter wählen. Hier ist diese Logik in sieben Schritte aufgeteilt, die Sie jedes Mal durchlaufen können.
- Das emotionale Ziel definieren. Benennen Sie das Gefühl, mit dem das Publikum gehen soll — Vertrauen, Aufregung, Ruhe. Alles Nachgelagerte dient dieser einen Entscheidung.
- Ein Toncluster wählen. Wählen Sie aus den vier Clustern: vertrauensbildend, energetisch, ernst oder intim. Widerstehen Sie dem Drang, widersprüchliche Cluster zu mischen — da fallen Briefings auseinander.
- Den Tonhöhenbereich festlegen. Tief, mittel oder hell. Ein Wort, kein Absatz.
- Das Tempo festlegen. Gemessen, zügig oder abgehackt. Halten Sie es von der Tonhöhe getrennt.
- Stil und Register fixieren. Gesprächig, Erzähler oder Rundfunk — dann formell oder locker.
- Demografie und Akzent schichten. Fügen Sie Altersgruppe und Dialekt hinzu, so wie es die SymTrain- und Hamsa-Filter erwarten.
- Gegen 2–3 Proben testen. Hamsas Checkliste — Aussprache, Klarheit, Tempo, Ton, Akzent — ist Ihr finales Validierungstor, bevor irgendetwas in die Produktion geht.

So sieht der fertige Stapel als einzelne Zeichenkette aus: warm + mittlere Tonhöhe + gemessenes Tempo + gesprächiger Stil + weiblich + Mitte 30 + neutraler US-Akzent. Diese eine Zeile leistet doppelte Arbeit. Lassen Sie sie in eine Suchleiste fallen, und sie verkürzt Ihre Filterzeit über eine Bibliothek mit über 300 Stimmen auf eine Handvoll Kandidaten. Geben Sie dieselbe gestapelte Zeichenkette in ein TTS-Preset ein, und sie wird zu einem Generierungs-Prompt. Die Disziplin, sie einmal aufzuschreiben, ist das, was Sie davor bewahrt, den gesamten Katalog erneut vorzuhören. Und weil das Format konsistent ist, kann dieselbe gestapelte Zeichenkette, die Sie einem TTS-Preset zuführen würden, direkt an einen Voice Cloning API-Aufruf übergehen — ein Briefing, mehrere Ziele, null Neuübersetzung zwischen Tools.
Deskriptor-Fallen — wo die Stimmauswahl unbemerkt scheitert
Die meisten Stimmprojekte scheitern nicht in der Aufnahmephase. Sie scheitern am Briefing, auf eine Weise, die unsichtbar ist, bis Sie eine fertige Datei hören, die irgendwie falsch ist. Das sind die Fehlerarten, die nicht auftauchen, bis die Behebung teuer ist.
Überstapeln widersprüchlicher Deskriptoren. „Energetisch, aber beruhigend" hebt sich selbst auf — die Stimme kann nicht gleichzeitig sprinten und flüstern. Die Forschung der NN/g ist hier nützlich: Humor, Respekt und Enthusiasmus sind unabhängige Hebel, sodass viele Kombinationen gut funktionieren, aber einige wirklich kollidieren. Die Lösung ist, ein dominantes Toncluster zu wählen und innerhalb davon zu verfeinern, statt clusterübergreifend nach Vielfalt zu greifen, die Sie nicht brauchen.
„Natürlich" als Richtungsangabe behandeln. „Natürlich" und „ansprechend" fühlen sich wie Anweisungen an, sind es aber nicht. WP SEO AI argumentiert, dass solche Allzweckbegriffe für KI-Tools und Remote-Talente gleichermaßen versagen, weil sie keine der zusammenwirkenden Dimensionen spezifizieren. Die Lösung ist, jeden Allzweckbegriff durch den Vier-Dimensionen-Stapel zu ersetzen — Ton, Tonhöhe, Tempo, Stil — plus Demografie. Wenn sich ein Deskriptor nicht in einen dieser Eimer einordnet, ist er keine Richtungsangabe.
Annehmen, dass Deskriptoren über Sprachen hinweg übersetzbar sind. Der wahrgenommene Ton verschiebt sich, wenn Sie in eine andere Sprache und Kultur synchronisieren — ein Register, das sich im Englischen warm liest, kann andernorts als allzu vertraut ankommen. Die Lösung ist, den Ton pro Zielsprache neu zu validieren, statt darauf zu vertrauen, dass der Quelldeskriptor überträgt. Wenn Sie in 33 Zielsprachen synchronisieren, sind sprachspezifische Tonprüfungen kein optionaler Schliff; sie sind der Unterschied zwischen Inhalt, der verbindet, und Inhalt, der subtil entfremdet. Deshalb prüfen Teams, die Inhalte durch eine KI-Synchronisations-API laufen lassen, den Ton pro Zielsprache erneut, statt anzunehmen, dass das ursprüngliche Briefing noch gilt.
Den emotionalen Kontext des Publikums ignorieren. PatternFly warnt, dass ein Einheits-Ton danebengeht — ein Fehlerbehebungsablauf braucht eine neutrale, hilfreiche Stimme, während eine Ankündigung eine enthusiastische braucht. Die Lösung ist, Deskriptoren für den Moment zu wählen, in dem sich Ihr Publikum befindet, nicht für den markenweiten Standard, den Sie vor sechs Monaten festgelegt haben.
Das Briefing überspringen und der Intuition vertrauen. Ed Gandias Ton-Leitfaden-Ansatz kritisiert vage Anweisungen, indem er konkrete Parameter fordert — Publikum, Tonspezifika wie „warm, aber nicht geschwätzig", Formalität, Satzlänge und wiederkehrende Muster. Die Lösung ist die einfachste von allen: Schreiben Sie das gestapelte Briefing, bevor Sie eine einzige Stimme vorhören. Intuition ist in Ordnung, um zwischen zwei Finalisten zu wählen. Sie ist schrecklich, um 300 auf 3 einzuengen.

„Natürlich" beschreibt nichts — es ist die Standarderwartung, keine kreative Richtungsangabe.
Ihre Copy-Paste-Briefing-Vorlage für Stimmdeskriptoren
Hier ist die operative Version von allem oben — eine Lückentext-Struktur, die Sie in jedes Stimmtool, Agenturbriefing oder jede Klonanfrage einfügen können. Es ist das Vier-Dimensionen-Modell plus Demografie, so formatiert, dass Sie es nie von Grund auf neu aufbauen müssen. Behandeln Sie es als die einzige Quelle der Wahrheit für die Stimmdeskriptoren eines Projekts.
STIMMDESKRIPTOR-BRIEFING
----------------------------------------
Emotionales Ziel: ____ (was das Publikum fühlen soll)
Toncluster: ____ (vertrauensbildend / energetisch / ernst / intim)
Tonhöhe: ____ (tief / mittel / hell)
Tempo: ____ (gemessen / zügig / abgehackt)
Stil / Register: ____ (gesprächig / Erzähler / Rundfunk; formell / locker)
Demografie: ____ (Geschlecht, Altersgruppe)
Akzent / Sprache: ____ (Dialekt + Zielsprachen)
Referenzstimme: ____ (optional — eine bekannte Stimme zur Verankerung der Erwartungen)
Diese Struktur ist nicht willkürlich. Sie spiegelt Ed Gandias prägnante 3–5-Satz-Stimmzusammenfassung, gepaart mit spezifischen Ton-, Formalitäts- und Rhythmusparametern, wider und folgt der Charakter → Ton → Schlüsselwort-Pipeline von Voices.com in der Reihenfolge, in der Sie die Entscheidungen tatsächlich treffen. Füllen Sie sie von oben nach unten aus, und jedes Feld engt das nächste ein.
Hier ist die Vorlage für ein reales Szenario ausgefüllt — Das mehrsprachige YouTube-Kanal-Intro:
- Emotionales Ziel: selbstbewusste Begrüßung
- Toncluster: vertrauensbildend / warm
- Tonhöhe: mittel
- Tempo: zügig
- Stil / Register: gesprächiger Rundfunk
- Demografie: weiblich, Mitte 30
- Akzent / Sprache: neutrales US-Englisch, synchronisiert in Spanisch + Portugiesisch
- Referenzstimme: keine
Dieses eine Stimmbriefing erledigt drei Aufgaben ohne Änderung. Es engt Ihre Bibliothekssuche auf eine Auswahlliste ein. Es wird zum Prompt, der die TTS-Generierung antreibt. Und es trägt sich in den Synchronisationsschritt, wo dieselben Deskriptoren pro Zielsprache neu validiert statt von Grund auf neu aufgebaut werden. Ein Briefing, drei Ausgaben, kein erneutes Briefing.
Der praktische Vorteil dieses Ansatzes zeigt sich, wenn Ihre Tools an einem Ort leben. Wenn Text-to-Speech, Voice Cloning und Synchronisation einen Workflow teilen, kann dasselbe Deskriptor-Briefing, das eine Vorschau antreibt, direkt in eine Text-to-Speech-API-Anfrage übergehen — und dann weiter zur Synchronisation — statt in jeder Phase neu getippt und neu interpretiert zu werden. Schreiben Sie das Briefing einmal. Nutzen Sie es überall.
Fragen zu Stimmdeskriptoren, die Creator wirklich stellen
Was ist der Unterschied zwischen Ton und Klangfarbe bei Stimmdeskriptoren?
Ton ist der emotionale Charakter einer Stimme — warm, ernst, distanziert. Klangfarbe ist die einzigartige Textur oder Qualität des Klangs selbst — glatt, kratzig, seidig, hart. WP SEO AI führt Textur als eine vom emotionalen Ton getrennte Deskriptor-Dimension auf, und die Unterscheidung ist in der Praxis wichtig: Zwei Stimmen können genau denselben Ton teilen und trotzdem völlig unterschiedliche Klangfarben haben. Wenn sich eine Stimme emotional richtig anfühlt, aber irgendwie falsch ist, ist Klangfarbe meist die Variable, die Sie noch nicht benannt haben.
Werden Stimmdeskriptoren bei der Synchronisation in andere Sprachen genau übersetzt?
Nicht automatisch. Der wahrgenommene Ton kann sich über Sprachen und Kulturen hinweg verschieben, sodass das warme, lockere Register, das im Englischen funktioniert, in einem anderen Markt anders ankommen kann. Der zuverlässige Schritt ist, den Deskriptor pro Zielsprache neu zu validieren, statt anzunehmen, dass er überträgt. Mit verfügbarer Synchronisation in 33 Zielsprachen ist es keine zusätzliche Arbeit, eine sprachspezifische Tonprüfung in Ihren Workflow einzubauen — es ist das, was ein einzelnes Briefing über jeden Markt, in dem Sie veröffentlichen, hinweg ehrlich hält.
Wie viele Deskriptoren sollte ich verwenden, wenn ich eine KI-Stimme oder ein Klontool ansteuere?
Zielen Sie auf die vier Kerndimensionen plus Demografie — etwa 5–7 gestapelte Deskriptoren. WP SEO AI zeigt, dass gestapelte Deskriptoren einzelne Bezeichnungen übertreffen, und die Pipeline von Voices.com bestätigt Charakter plus Ton plus Schlüsselwörter als das funktionierende Minimum. Bleiben Sie in diesem Bereich. Weniger als fünf, und Sie sind zurück bei vagen Allzweckbegriffen; mehr als sieben, und Sie riskieren Widersprüche, die sich gegenseitig aufheben.
Kann ich eine Stimme beschreiben, indem ich auf eine bekannte oder Prominentenstimme verweise, statt Deskriptoren zu verwenden?
Eine Referenzstimme ist ein nützlicher Anker — deshalb ist „Referenzstimme" ein optionales Feld in der Briefing-Vorlage. Aber sie ersetzt keine Deskriptoren. Eine Referenz sagt einem Tool oder einem Menschen ungefähr, wo es starten soll; Ton, Tonhöhe, Tempo und Stil sagen ihnen, wo es landen soll. Eine Referenz mit expliziten Deskriptoren zu kombinieren, liefert das zuverlässigste Ergebnis, weil die Deskriptoren die Mehrdeutigkeit auflösen, die die Referenz offenlässt.