
Speech to Text API: So wählen Sie die richtige im Jahr 2025
Sie haben eine App gebaut, die Benutzer lieben — aber die Feature-Anfragen werden immer lauter: „Kann ich einfach sprechen statt zu tippen?" Also beginnen Sie, Speech-to-Text-APIs zu bewerten. Innerhalb der ersten Stunde sind Sie auf mindestens vier widersprüchliche Preismodelle gestoßen, Genauigkeitsansprüche, die zwischen „95%" und „99%+" schwanken, ohne gemeinsame Definition, was gemessen wird, und SDK-Qualität, die von „in drei Zeilen einsatzbereit" bis „eine Woche schlechte Dokumentation lesen" reicht.
Die Einsätze sind auf beiden Seiten real. Wählen Sie falsch in großem Maßstab und Sie werden entweder $3.000–$8.000/Monat für Streaming-Übernutzung ausgeben, oder Sie versenden eine Sprachfunktion, die bei 1 von 5 Äußerungen fehlschlägt. Nach Koenecke et al. in PNAS (2020) erreichten Fehlerquoten bei den fünf großen kommerziellen Spracherkennnungssystemen 35% für Sprecher des Afroamerikanischen Englischen gegenüber 19% für weiße Sprecher — eine Lücke, die ein „Genauigkeitsproblem" in ein „30%-der-Nutzer-können-dein-Produkt-nicht-verwenden"-Problem verwandelt.
Dieser Leitfaden bietet Ihnen das Entscheidungsframework, die Preisberechnungsmethode, das Pilotprotokoll und einen direkten Vergleich von sechs Anbietern — einschließlich wie ein kreditbasiertes Modell in Builds mit variablen Arbeitslasten passt.

Inhaltsverzeichnis
- Die fünf Entscheidungsachsen, die die Speech-to-Text-API-Auswahl wirklich steuern
- Genauigkeit im Kontext — Warum „99%-Benchmark" über Ihre Produktionsaudio lügt
- Latenz, Streaming und der Echtzeit-Kostenmultiplikator
- Kostenmodelle entmystifiziert — Pro-Minute vs. Gleichzeitig vs. Kreditpools
- Integrationswirklichkeiten — Die 9-Frage-SDK- und API-Audit
- Direkter Anbietervergleich — Wann sollte jede Speech-to-Text-API ausgewählt werden
- Ihre Speech-to-Text-API-Auswahlcheckliste
Die fünf Entscheidungsachsen, die die Speech-to-Text-API-Auswahl wirklich steuern
Die meisten Vergleichsbeiträge listen 30+ Funktionen auf und nennen das Recherche. Lehnen Sie das ab. Nur sechs Achsen bestimmen, ob eine Speech-to-Text-API für Ihren spezifischen Build funktioniert — und bei jedem gegebenen Projekt sind nur zwei oder drei davon wirklich wichtig.
Genauigkeit in Ihrer Domäne. Eine medizinische Schreiber-App mit einer allgemeinen API wird „Metoprolol" als „Meta Peral" darstellen. Die aggregierte Word-Error-Rate verbirgt diese Art von Fehlern. Wie Dan Jurafsky in Speech and Language Processing argumentiert, behandelt WER alle Fehler gleich — aber in einem klinischen oder rechtlichen Kontext hat ein falscher Drogenname oder eine verpasste Negation übergroße Auswirkungen. Was zählt, ist domain-spezifische WER bei Ihrem Audio, nicht eine Benchmark-Schlagzeile.
Latenzprofil. Ein Live-Untertitel-Barrierefreiheitstool braucht eine End-to-End-Reaktion unter 1 Sekunde. Eine Podcast-Transkriptionspipeline kann 10 Minuten warten. Nach Nielsen Norman Group's „Response Times: The 3 Important Limits" fühlen sich Reaktionen unter 100 ms sofort an, unter 1 Sekunde bleibt der Fluss erhalten, und über 10 Sekunden verursachen Aufgabenabbruch. Ordnen Sie Ihren Use Case einer Kategorie zu, bevor Sie einkaufen.
Offline-/On-Device-Funktionalität. Eine Feldforschungs-App in ländlichen Gebieten kann sich nicht auf Cloud-Umkehrungen verlassen. Apples SpeechAnalyzer API (WWDC 2025) ist eine plattformgestützte On-Device-Option für iOS/macOS. Selbst gehostete Whisper oder Vosk gibt Ihnen volle Offline-Kontrolle, wenn Sie bereit sind, GPUs zu verwalten.
Sprachunterstützung und Code-Switching. Whisper unterstützt 50+ Sprachen mit vergleichbarer Qualität nach dem Training auf 680.000 Stunden mehrsprachiger Audio (Radford et al., OpenAI 2022). Google und AWS verwenden gestaffelte Sprachengruppen, bei denen Tier-B-Sprachen niedrigere Genauigkeit und manchmal separate Preise erhalten.
Kostenmodellarchitektur. Pay-per-Minute, gleichzeitige Verbindungen und Kreditpools brechen jeweils unterschiedlich in großem Maßstab. Ein YouTuber, der eine Woche 4 Stunden und die nächste 40 Stunden hochlädt, wird durch Pro-Minute-Abrechnung in langsamen Wochen und Spitzenwochenzeiten bestraft. Kreditpools mit Rollover absorbieren diese Varianz.
Integrations-Oberflächenbereich. SDK-Qualität, Webhook vs. Polling, Fehlerbehandlungs-Standardwerte. Hier wird die „einfache API" zu drei verlorenen Wochen.
Fünf Achsen steuern jede Speech-to-Text-API-Entscheidung, die es wert ist zu treffen — und nur zwei oder drei gelten für Ihren Build.
| Entscheidungsachse | Warum es wichtig ist | Häufliche Fallstricke | Best-Fit-Anwendungsfall |
|---|---|---|---|
| Domain-Genauigkeit | Vendor-„99%"-Ansprüche verwenden saubere gelesene Sprache | LibriSpeech für laute mobile Audiovertrauen | Medizin-, Rechts-, Finanz-Apps |
| Latenzprofil | Streaming kostet 3–5x Batch | Streaming für Batch-tolerante Fälle kaufen | Live-Untertitel vs. Podcast-Upload |
| Offline-Fähigkeit | Datenschutz + konnektivitätsbeschränkte Umgebungen | Web Speech API ist offline annehmen | Healthcare-Feldapps, mobil-zuerst |
| Sprachunterstützung | Tier-B-Sprachen = niedrigere Genauigkeit | Auto-Erkennung bei mehrsprachiger Audio | Mehrsprachige SaaS, globale Inhalte |
| Kostenmodell | Pro-Minute sieht billig aus, bis Streaming einsetzt | Speicher-, Ausgangs-, Wiederholungskosten ignorieren | Variable-Volumen-Creator-Workflows |
| Integrations-Oberflächenbereich | Schlechte SDKs kosten Dev-Wochen | „Einfach in Dokumenten" ≠ versendet leicht | Alle Builder |
Diese Tabelle ist ein Filter, kein Urteil. Ein YouTube-Creator, der 10 Batch-Jobs pro Woche hochlädt, kümmert sich um Kostenmodell und Sprachunterstützung. Eine Healthcare-App kümmert sich um Genauigkeit und Offline-Fähigkeit. Ein Echtzeit-Meeting-Tool kümmert sich um Latenz und Integrations-Oberflächenbereich.
Bevor Sie weiterlesen, unterstreichen Sie die zwei oder drei Achsen, die für Ihren spezifischen Build am wichtigsten sind. Der Kostenbereich (Tausende-Dollar-Unterschied) und der Anbietervergleich am Ende sehen je nachdem völlig unterschiedlich aus, welche Achsen Sie priorisiert haben. Wenn Sie versuchen, alle sechs in einer Entscheidung zu optimieren, wird Sie das immer zum teuersten Anbieter mit Features führen, die Sie nie verwenden werden.
Genauigkeit im Kontext — Warum „99%-Benchmark" über Ihre Produktionsaudio lügt
Jeder Speech-to-Text-API-Vendor veröffentlicht Genauigkeitsnummern. Fast keine davon sagen voraus, wie die API bei Ihrem Produktionsaudio funktioniert. Hier ist warum und wie man testet, was wirklich zählt.
Benchmark-Audio ist sauber; Produktionsaudio nicht. Öffentliche Benchmarks wie LibriSpeech bestehen aus gelesener Audiobuch-Sprache — einzelner Sprecher, neutraler Akzent, saubere Aufnahme. Whispers großes Modell meldet ungefähr 4,7% WER bei LibriSpeech test-clean und ungefähr 8–9% WER bei test-other, dem anspruchsvolleren Set (Radford et al., OpenAI 2022). Die Lücke bei echtem Produktionsaudio — laut, akzentuiert, sich überlappende Sprecher — ist noch größer. Wenn ein Vendor WER angibt, ohne den Datensatz und die Aufnahmebedingungen anzugeben, behandeln Sie die Zahl als Marketing-Copy, nicht als Engineering-Daten.
WER ist die falsche Metrik für viele Apps. Die Standarddefinition aus NISTIAs ASR-Evaluierungsrichtlinien ist (Substitutionen + Löschungen + Einfügungen) / Referenzwörter. Sie behandelt jedes Wort als gleich wichtig. Aber eine falsche Darstellung des Medikamentennamens eines Patienten, einer finanziellen Zahl oder des Namens eines Gerichtszeugen hat Konsequenzen, die das Löschen eines Füllworts nicht hat. Jurafskys Argument: Bewertung mit aufgabenspezifischen Metriken — Slot-Filling-Genauigkeit für Sprachassistenten, Critical-Term-Rückruf für medizinische und rechtliche Verwendung, Named-Entity-Genauigkeit für Journalismus. Die aggregierte WER könnte 7% sein; Critical-Term-WER könnte 22% sein. Nur eine dieser Zahlen hat Bedeutung für Ihre Benutzer.
Akzent- und Dialektleistung variiert dramatisch. Die am Anfang dieses Leitfadens zitierte PNAS-Studie testete fünf große kommerzielle Systeme und fand WER für afroamerikanische Englisch-Sprecher durchschnittlich 0,35 gegenüber 0,19 für weiße Sprecher — ungefähr doppelt so schlecht. Das ist keine Fairness-Fußnote. Es ist ein geschäftliches Risiko: Eine App, die für ein Drittel ihrer potenziellen Nutzerbasis fehlschlägt, weil sie nur auf neutralem amerikanischem Englisch getestet wurde, versendet einen Fehler. Die Lösung ist nicht, einen anderen Vendor zu wählen (die meisten haben die gleiche Lücke). Die Lösung ist das Testen mit Audio, das Ihre tatsächlichen Benutzer repräsentiert, bevor Sie etwas unterzeichnen.
Ein 99%-Genauigkeitsanspruch bei einem Benchmark sagt Ihnen nichts darüber, wie die API mit Ihren Benutzern umgeht — was zählt, ist die Leistung bei Ihrem Audio, Ihren Akzenten und Ihrem Domain-Wortschatz.
Streaming-Genauigkeit ist schlechter als Batch-Genauigkeit. Streaming-Systeme geben vorläufige („teilweise") Wörter aus, die umgeschrieben werden, wenn mehr Audio eintrifft. Batch-Systeme warten auf die vollständige Äußerung und verfeinern. Streaming-WER ist typischerweise 5–15% schlechter als Batch für den gleichen Inhalt auf der gleichen Engine. Diese Lücke wird in der Vendor-Vermarktung fast nie offengelegt. Wenn Sie ein Live-Transkriptionsproduk erstellen, berücksichtigen Sie dies.
Code-Switching bricht die meisten APIs. Code-Switching bedeutet, Sprachen innerhalb einer Äußerung zu wechseln: Spanglisch, Hinglisch, Tagalog-Englisch. Whisper handhabt es besser als die meisten, weil es auf 680.000 Stunden mehrsprachiger Audio trainiert wurde (Radford et al., 2022). Die meisten Cloud-APIs erfordern, dass Sie die Sprache im Voraus deklarieren, und verschlechtern sich hart, wenn der Sprecher mitten im Satz wechselt. Wenn Ihre Benutzer mehr als eine Sprache in der gleichen Sitzung sprechen, testen Sie diesen Fall explizit. Für mehrsprachige Workflows, die auch lokalisierung benötigen, können Plattformen mit eingebautem AI Dubbing über 33 Sprachen Transkription, Übersetzung und Dubbing in einer Pipeline zusammenfassen.
Das 7-Tage-Pilotprotokoll
Statt Vendor-Genauigkeitsansprüchen zu vertrauen, führen Sie einen einwöchigen Proof of Concept durch.
- Tag 1–2: Sammeln Sie 30 Minuten echtes produktionsstiliges Audio. Beziehen Sie Ihren schlimmsten Fall ein: laute Umgebungen, akzentuierte Sprecher, Domain-Jargon, sich überlappende Sprache.
- Tag 3–4: Transkribieren Sie mit 3 Kandidaten-APIs. Korrigieren Sie manuell eine Version, um sie als Referenzetranskript zu verwenden.
- Tag 5: Messen Sie WER insgesamt, dann brechen Sie es nach Sprecher, Akzent und Domain-Term-Rückruf auf.
- Tag 6: Testen Sie Streaming vs. Batch bei den gleichen Dateien. Messen Sie das Genauigkeits-Delta.
- Tag 7: Dokumentieren Sie entstanden Kosten und Integrations-Reibung — Auth-Komplexität, SDK-Probleme, Fehlerantwort-Qualität.
Ein Engineer, der in ITNEXT schrieb, berichtete, dass nach Abstimmung des Mikrofon-Setups und benutzerdefinierten Wortschatz modernes Speech-to-Text weniger Fehler produzierten als ihr eigenes Tippen für technisches Schreiben. Die Erkenntnis ist nicht, dass eine einzelne API magisch ist. Es ist, dass API-Auswahl zählt, aber die Audio-Pipeline rund um die API zählt mindestens genauso viel. Eine großartige API bei schlechtem Audio verliert gegenüber einer anständigen API bei gestimmtem Audio.
Latenz, Streaming und der Echtzeit-Kostenmultiplikator
Latenz ist die Achse, auf der Engineer am meisten überausgeben. Echtzeit-Transkription fühlt sich in einer Demo magisch an und kostet 3–5x mehr als Batch in der Produktion. Entscheiden Sie, was Ihre Benutzer tatsächlich brauchen, bevor Sie sich für Streaming-Infrastruktur anmelden.
- Synchrone Streaming-Latenz (Live-Untertitel, Sprachassistenten). Ziel unter 1 Sekunde End-to-End für Barrierefreiheits-Untertitelung, 300–800 ms Round-Trip für Sprachbots, um sich konversationell zu fühlen. Über 2 Sekunden und die Illusion von Echtzeit bricht zusammen. Diese Schwellwerte entsprechen etablierter UX-Forschung zur Wahrnehmung der Reaktionszeit (Nielsen Norman Group). Streaming-APIs erreichen sie über persistente WebSocket-Verbindungen, die Zwischenergebnisse ausgeben, während Audio eintrifft.
- Asynchrone Batch-Latenz (Podcast-Uploads, Support-Call-Überprüfung, YouTube-Untertitel). Minuten bis Stunden Verarbeitungszeit ist akzeptabel. Batch ist ungefähr 3–5x billiger pro Minute Audio als Streaming beim gleichen Provider, weil die Infrastruktur keine Verbindungen offen hält (Google Cloud und AWS Transcribe Preisdokumente). Für Creator-Workflows, die aufgezeichnete Inhalte hochladen, ist Batch fast immer richtig.
- Hybrid / Near-Real-Time (Live-Entwürfe mit verzögerter Korrektur). Einige Workflows akzeptieren 2–5 Sekunden Latenz im Austausch für höhere Genauigkeit und niedrigere Kosten. Ein Meeting-Transkriptions-Tool könnte ungefähren Text innerhalb von 3 Sekunden anzeigen und ihn innerhalb von 30 verfeinern. Dieses Muster verwendet Streaming für die Live-Ansicht und Batch-Wiederverarbeitung für das gespeicherte Transkript — oft über Webhook-Callback statt Polling. Plattformen, die speziell für Media-Workflows gebaut sind, wie DubSmarts AI Dubbing API, verwenden Webhook-Callbacks für abgeschlossene Jobs statt Ihren Backend zu zwingen, den Status abzufragen (Make.com-Community-Thread zur AudioPen-Webhook-Integration).
- Real-Time Factor (RTF) — die Engineer-Metrik. Produktionssysteme peilen RTF < 1,0 für interaktive Verwendung an: Verarbeitung 1 Sekunde Audio in weniger als 1 Sekunde Wall-Clock-Zeit. On-Device- oder GPU-beschleunigte Whisper-Bereitstellungen erreichen ungefähr RTF 0,5–0,9 für mittlere Modelle auf Consumer-GPUs. Wenn Ihr selbst gehostetes Setup RTF > 1,0 läuft, ist Streaming ohne Warteschlange unmöglich.

Das Latenz-Kosten-Genauigkeits-Dreieck ist nicht verhandelbar: Sie können zwei wählen. Streaming opfert Genauigkeit und Budget für Unmittelbarkeit. Batch opfert Unmittelbarkeit für Genauigkeit und Kosten. Hybrid-Architekturen werden zunehmend verbreitet, aber fügen Integrations-Komplexität hinzu. Bevor Sie wählen, stellen Sie eine Frage: Würden meine Benutzer tatsächlich eine 5-Sekunden-Verzögerung bemerken? Wenn die Antwort nein ist, ist Batch die richtige Architektur und Sie haben gerade 70% Ihrer jährlichen API-Ausgaben gespart.
Kostenmodelle entmystifiziert — Pro-Minute vs. Gleichzeitig vs. Kreditpools
Es gibt drei Preisarchitekturen auf dem Speech-to-Text-API-Markt, und ihre Verwechslung ist der häufigste Beschaffungsfehler.
Pay-per-Minute (Batch-Standard). Sie werden pro Minute eingereichten Audios berechnet, oft in 15-Sekunden-Inkrementen. Einfach für vorhersagbare Arbeitslasten zu prognostizieren. OpenAI Whisper API ist ungefähr $0,006/Minute (OpenAI-Preisseite) — oft 3–5x billiger als traditionelle Cloud-ASR-Provider, die rund $0,02–0,03/Minute für Standard-Englisch-Batch-Modelle gruppieren.
Gleichzeitige Verbindungen (Echtzeit-Streaming). Sie zahlen pro gleichzeitig offener Stream, oft berechnet pro Connection-Minute oder pro Concurrent-Slot. Das ist, wo die Rechnungen in die Höhe schnellen: Wenn 50 Benutzer gleichzeitig streamen, zahlen Sie für 50 Verbindungen — nicht 50 Minuten Audio. Google Cloud und AWS veröffentlichen unterschiedliche und höhere Raten für Streaming-Sessions vs. Offline-Batch-Jobs.
Kreditpools mit Rollover (Flexible Arbeitslasten). Sie kaufen einen Kreditpool, der zu variablen Raten verbraucht wird, je nachdem, welche Features Sie verwenden (Transkription, Dubbing, Voice-Cloning, Text-to-Speech). Ungenutzte Credits überrollen. Dieses Modell passt zu variablen Arbeitslasten — ein YouTuber, der eine Woche 4 Stunden und die nächste 40 hochlädt, wird nicht durch Pro-Minute-Abrechnung in langsamen Wochen und Spitzenwochenzeiten bestraft. DubSmart AI verwendet dieses Modell und bündelt Transkription mit Voice Cloning und Text to Speech unter einem Kreditguthaben.
Durchgerechnetes Beispiel — YouTube-Creator:
- 10 Videos/Woche × 30 Min jedes = 300 Min/Woche Quell-Audio
- Batch-Transkription bei $0,006/Min = $1,80/Woche, oder etwa $94/Jahr
- Fügen Sie eine Streaming-Live-Untertitel-Demo (5 Stunden/Monat) bei 4x Batch-Rate = ungefähr $72/Jahr zusätzlich hinzu
- Wenn der Creator in 3 Sprachen dubbt, ist das totale monatliche Transkript + Dub-Kreditbedarf ungefähr 5.000 Credits — passt in einen Mid-Tier-Kreditpool-Plan
Bei jedem Volumen unter 5.000 Stunden pro Monat ist der Bau Ihres eigenen Transkriptions-Stacks in der Fantasie billiger als in der Realität — ein $50 API-Tier versendet in einen Tag, während eine selbst gehostete Whisper-Bereitstellung in einem Quartal versendet.
| Anbieter | Preismodell | Veröffentlichter Satz | Kostenlos-Stufe |
|---|---|---|---|
| Google Cloud STT | Pro 15-Sek-Inkrement; Streaming-Aufschlag | Variabel; gestaffelt | 60 Min/Monat |
| AWS Transcribe | Pro-Sekunde Batch + Streaming SKUs | Variabel nach Region/Modell | 60 Min/Monat, 12 Monate |
| OpenAI Whisper API | Pauschal pro-Minute | ~$0,006/Min | Keine veröffentlicht |
| Rev.com (Maschine) | Pro-Minute | $0,25/Min | Keine |
| Rev.com (Mensch) | Pro-Minute | $1,50/Min | Keine |
| DubSmart AI | Kreditpool mit Rollover | Gestaffelte Pläne | Kostenlos-Stufe verfügbar |
Quellen: OpenAI, Google Cloud, AWS Transcribe, Rev.com Vendor-Preisseiten.

Drei versteckte Kosten zeigen sich fast nie in Vendor-Rechnern.
Speicherung und Ausgang. Wenn Sie Transkripte und Quell-Audio in S3 oder GCS speichern, zahlen Sie Speicherung plus Bandbreite beim Abrufen. In großem Maßstab werden diese zu nicht-trivialen Posten. Ein 1-TB-Archiv bei Standard-Raten mit häufigen Re-Reads kann Hunderte von Dollar pro Monat hinzufügen, bevor ein API-Aufruf trifft.
Speaker-Diarization wird normalerweise separat gemessen. AWS Transcribe und AssemblyAI berechnen Speaker-Identifikation als separaten Posten zusätzlich zur Basistranskription (AWS Transcribe-Dokumentation; AssemblyAI-Dokumente). Nur auf der Pro-Minute-Basisrate zu budgetieren unterschätzt Ihre echten Kosten um ungefähr 20–40%, wenn Sie Speaker-Labels brauchen.
Wiederholung und Fehlerkosten. Fehlgeschlagene Anfragen verbrauchen immer noch Quote bei einigen Anbietern. Wenn Ihre Audio-Pipeline eine 2%-Fehlerrate bei 100.000 Minuten/Monat hat, das sind 2.000 Minuten bezahlter Wiederholungen — ungefähr $12/Monat bei Whisper-Raten, aber leicht $60/Monat bei traditioneller Cloud-STT.
Build vs. Buy Break-Even. Engineering-Erfahrung aus Teams bei Mozilla (DeepSpeech), Descript und AssemblyAI deutet darauf hin, dass Self-Hosting ASR mit Whisper oder Kaldi nur Sinn macht bei >5.000 Stunden/Monat mit dediziertem ML- und DevOps-Personal. Unter diesem Volumen übersteigen Infrastruktur-, Modellwartungs-, GPU-Kosten und On-Call-Overhead die $50–$500/Monat API-Rechnung — oft um ein Fünffaches oder mehr.
Integrationswirklichkeiten — Die 9-Frage-SDK- und API-Audit
„Einfach zu integrieren" ist die am meisten übernutzte Phrase in der API-Wirtschaft. Eine API kann leicht in einer curl-Anfrage aufzurufen sein und höllisch zu versenden in der Produktion. Bevor Sie einen Vertrag unterzeichnen, führen Sie jeden Kandidaten durch diese neun Fragen. Schlechte Antworten hier sagen die Wochen benutzerdefinierten Fehlerbehandlung und Wiederholungslogik voraus, die Sie später schreiben werden.
- Unterstützt die API sowohl Streaming als auch Batch in einem SDK? Einige Anbieter zwingen Sie, die Architektur im Voraus zu wählen, berechnen dann zum Wechsel. Die besten APIs stellen beide über die gleiche Auth-Schicht bereit und lassen Sie Arbeitslasten migrieren, wenn sich Benutzerverhalten entwickelt. Wenn Ihr anfänglicher Anwendungsfall Batch ist, aber Sie in sechs Monaten vielleicht Live-Untertitelung hinzufügen, ist dies jetzt wichtig.
- Was passiert, wenn die API ausfällt oder Rate-Limit wird? Testen Sie es. Senden Sie 200 Anfragen in 1 Sekunde an eine kostenlos-Stufe. Stellt das SDK sie in die Warteschlange, zeigt es 429 sauber, oder hängt es? Anbieter, die SLA und Wiederholungs-Semantik in Klartext veröffentlichen, sparen Ihnen Wochen Incident-Response. Anbieter, die nicht, werden Sie irgendwann um 3 Uhr morgens wecken.
- Können Sie die Audio-Sprache explizit angeben, oder wird sie automatisch erkannt? Auto-Erkennung klingt freundlich, bricht aber bei mehrsprachigen oder Code-geschalteten Audio. Für Produktions-Builds, geben Sie immer die Sprache an und fallen nur auf Auto-Erkennung zurück, wenn das Vertrauen niedrig ist. APIs, die Ihnen nicht erlauben, die Sprache explizit einzustellen, sind vor-engineered, um bei Ihren Edge Cases zu fehlschlagen.
- Unterstützt es Speaker-Diarization ab Werk? Diarization ist oft ein separat bepreiste Zugabe. AssemblyAI und AWS Transcribe berechnen es beide separat. Überprüfen Sie, ob Ihr Anbieter Segment-Level- oder Word-Level-Speaker-Labels zurückgibt — der Unterschied zählt für Analytik, Suche und jede nachgelagerte Zusammenfassung.
- Können Sie PII (Kreditkartennummern, Sozialversicherungsnummern, Namen) kennzeichnen oder schwärzen? Die meisten unternehmensorientierten APIs (AWS Transcribe, AssemblyAI) unterstützen PII-Schwärzung. Whisper und Web Speech API nicht. Für Healthcare- oder Finanz-Apps ist dies kein Nice-to-Have.
- Webhook-Callbacks oder Polling für async Jobs? Webhooks sind der moderne Standard. Polling erzeugt unnötige API-Aufrufe und Kosten. Reife Plattformen geben Webhook-Events bei Job-Abschluss aus — das in der Make.com-Community-Thread zur AudioPen-Integration gezeigte Muster, wo Transkriptions-Abschluss nachgelagerte Automatisierung auslöst.
- Was sind die maximalen Dateigrößen- und Dauerbegrenzungen pro Anfrage? Viele Cloud-APIs begrenzen einzelne Anfragen auf 15 Minuten oder ungefähr 1 Stunde mit Dateigröße-Limits in den Tens zu Hundreds of MBs (Google Cloud Speech-to-Text Dokumente; AWS Transcribe Dokumente). Langform-Audio — zwei-Stunden-Podcasts, Aussagen, Konferenz-Aufnahmen — muss in Chunks aufgeteilt werden. HTTP-Gateways erzwingen oft unabhängig 15-Minuten-Timeouts von den API eigenen Limits.
- Werden Zuverlässigkeitswerte auf der Wort-Ebene freigelegt? Word-Level-Zuversicht lässt Sie niedrig-Zuversicht-Regionen für menschliche Überprüfung oder interaktive Korrektur kennzeichnen. APIs, die Rohtext ohne Zuversicht zurückgeben, zwingen Sie, entweder alles zu vertrauen oder umzuschreiben. Für jeden Workflow mit menschlicher Überprüfung in der Schleife ist diese Funktion der Unterschied zwischen einer verwendbaren QA-Warteschlange und einer Wand von unleserlichem Text.
- Wie ist die SDK-Qualität in Ihrer Sprache? Ein Node.js- oder Python-SDK mit starker Typisierung, Wiederholungslogik und sauberen Error-Klassen ist einen 30%-Preis-Premium wert über eine API, die Sie Raw-HTTP in der Produktion verwenden müssen. Testen Sie das SDK, bevor Sie sich an die API binden. Schreiben Sie eine kleine Integration. Zeitmessung. Das SDK, das Ihnen tatsächlich gefällt mit Ihnen zu arbeiten, spart mehr Engineering-Stunden als der billigere Pro-Minute-Satz Ihnen jemals in Dollar spart.
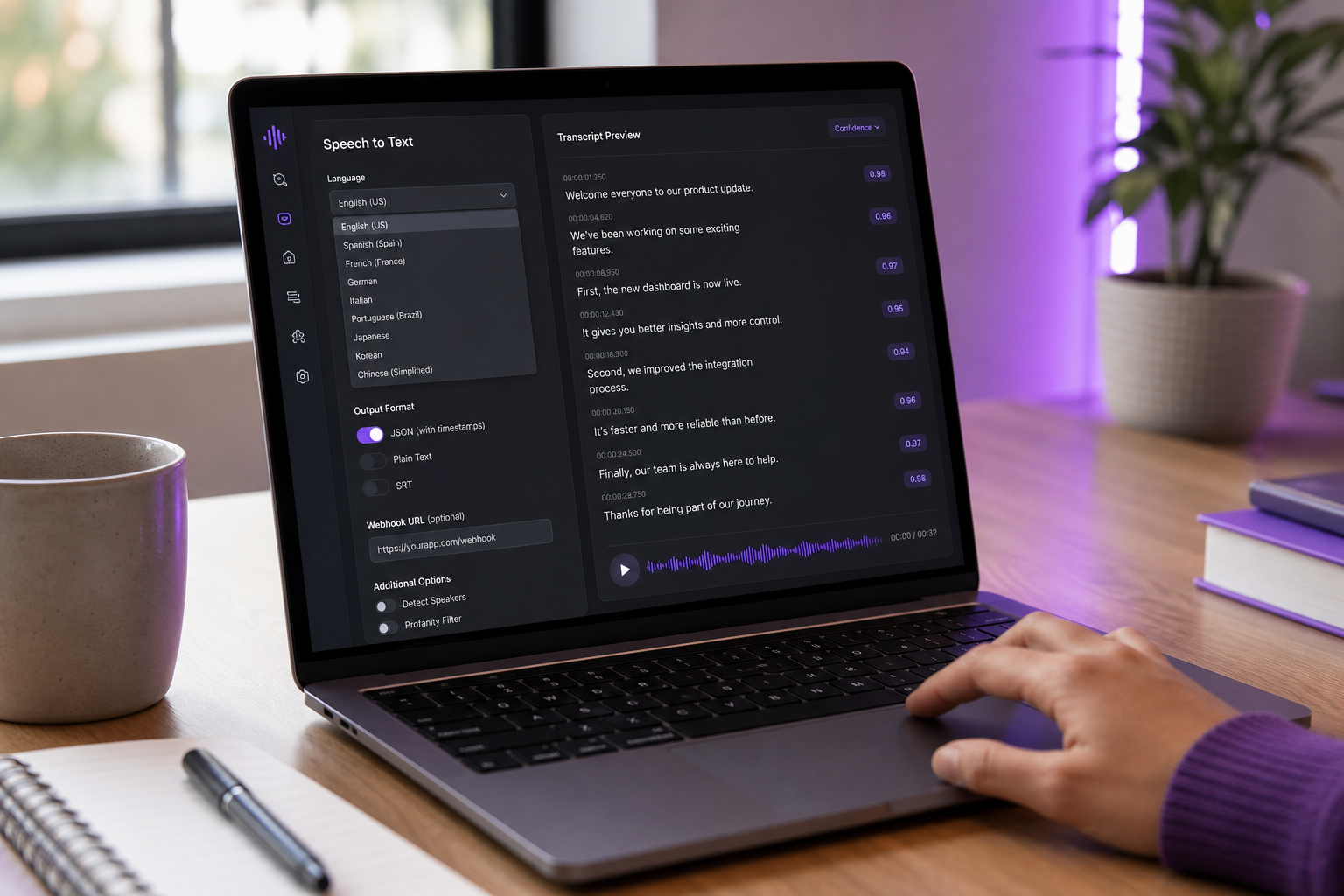
Open-Source vs. proprietär bleibt die größte Integrations-Gabel.
Open-Source (Whisper, Vosk). Null Pro-Anruf-Kosten, volle Kontrolle, läuft offline. Sie besitzen Hosting, Skalierung, GPU-Bereitstellung, Modellaktualisierungen, Observability und den 3-Uhr-Morgens-Incident. Realistische Bereitstellung für ein Team von 5+ mit ML- und DevOps-Fähigkeit.
Proprietäre Cloud (Google, AWS, AssemblyAI, OpenAI Whisper API, DubSmart). Sie tauschen Pro-Minute-Kosten gegen Zuverlässigkeit, SLA, Versioning und SDK-Support. Für die meisten Teams unter 5.000 Stunden/Monat gewinnt proprietär bei den Gesamtkosten des Eigentums. Plattformen, die Speech to Text mit Text to Speech API und Voice Cloning API unter einem SDK bündeln, reduzieren die Integrations-Oberflächenbereich weiter — ein Auth-Flow, ein Error-Modell, ein Billing-Dashboard für die gesamte Media-Pipeline.
Plattform-Level On-Device (Apple SpeechAnalyzer, WWDC 2025). Eine neuere Kategorie. Datenschutz-wahrend, offline-fähig, aber Genauigkeit und Sprachunterstützung könnten Cloud-Modellen hinterherhinken. Am besten für mobile-zuerst Apps, wo Datenschutz ein Marketing-Asset ist, nicht nur ein Compliance-Kontrollkästchen.
Die Integrationsfrage, die alle anderen schlägt: Wie schnell können Sie versenden? Eine gut dokumentierte kreditbasierte API, die Speech to Text, Voice Cloning und Dubbing unter einem SDK bündelt, schlägt oft eine billigere Standalone-STT-API, wenn Sie den zweiten und dritten Features berücksichtigen, die Sie in sechs Monaten brauchen werden.
Direkter Anbietervergleich — Wann sollte jede Speech-to-Text-API ausgewählt werden
Dies ist ein Quick-Reference-Scan, keine erschöpfende Überprüfung. Jeder Eintrag behandelt Best-Fit-Anwendungsfall, primäre Schwäche, dominanter Kostentreiber und Integrations-Charakter. Quellen für Preise und Feature-Ansprüche sind Vendor-Dokumentation ab späten 2024.
Google Cloud Speech-to-Text
- Am besten für: Hoch-Genauigkeits-Englisch-Transkription, Teams bereits in GCP, unternehmensweise Arbeitslasten mit vorhersagbarem Volumen.
- Schwäche: Streaming-Preise eskalieren schnell; Sprachstufen schaffen Genauigkeitsinkonsistenz für Non-English-Audio.
- Kostentreiber: Pro 15-Sekunden-Inkremente mit einer separaten (höheren) Streaming-SKU; 60 Min/Monat kostenlos-Stufe.
- Integration: Native GCP-Authentifizierung über Service-Konten. Nicht-GCP-Apps sehen IAM-Overhead. Reife SDKs für alle großen Sprachen.
AWS Transcribe
- Am besten für: Batch-schwere Arbeitslasten in großem Maßstab, AWS-native Teams, mehrsprachige Content-Pipelines, Call-Center-Analytik.
- Schwäche: Streaming-Latenz leicht höher als Streaming-Spezialist-Konkurrenten. Diarization und medizinische Modelle separat bepreist.
- Kostentreiber: Audio-Dauer in Sekunden, mit separaten SKUs für Streaming, Medical und Call-Analytics Add-Ons.
- Integration: IAM-schwer. Unkompliziert, wenn Sie bereits AWS-nativ sind. Gut dokumentiert, aber ausführlich.
OpenAI Whisper API
- Am besten für: Budget-bewusste Builds, mehrsprachige Inhalte mit Code-Switching, Teams, die keine Vendor-Lock-in über OpenAI selbst hinaus wollen.
- Schwäche: Keine native Streaming-Unterstützung. Keine Volumen-Rabatte. Keine SLA-Zusagen vergleichbar mit AWS oder GCP.
- Kostentreiber: Pauschal $0,006/Minute ohne Concurrent-Connection-Gebühr und keine veröffentlichte gestaffelte unternehmensweise Rabatt.
- Integration: Einfachste HTTP-API auf dem Markt. Mehrsprachig ohne Sprachdeklaration dank der 680.000 Stunden Trainingsdaten, die im Whisper-Paper dokumentiert sind.
AssemblyAI
- Am besten für: Developer-Zuerst-Teams, Echtzeit-Streaming mit minimaler Latenz, strukturierte Ausgabe mit word-Level-Zeitstempel, Speaker-Labels und Zuverlässigkeitswerte.
- Schwäche: Premium-Preise. Feature-Dichte ist Overkill für einfache Batch-Anwendungsfälle.
- Kostentreiber: Concurrent-Streaming-Verbindungen plus Diarization-Posten.
- Integration: Ausgezeichnete SDKs und Dokumentation. Webhook-First-Architektur. Starke Observability-Tools.
Rev.com (Maschine + Mensch Hybrid)
- Am besten für: Arbeitslasten, wo Genauigkeit nicht verhandelbar ist und Turnaround können Stunden warten — rechtliche Aussagen, Journalismus, Barrierefreiheit-kritischer Inhalt.
- Schwäche: Nicht Echtzeit. Menschliche Überprüfung dauert Stunden. Teuer in großem Maßstab.
- Kostentreiber: $0,25/Minute für Maschine, $1,50/Minute für menschlich überprüft.
- Integration: Einfache REST-API. Die Reibung ist Turnaround-Zeit, nicht die Integration selbst.
DubSmart AI Speech to Text API
- Am besten für: Content-Creator und Teams, die mehrsprachige Workflows aufbau, wo Transkription ein Schritt in einer längeren Pipeline ist — transkribieren, übersetzen, dubben, veröffentlichen. Kreditbasierte Preise absorbieren variable Arbeitslasten.
- Schwäche: Jüngere Plattform als Legacy-Hyperscaler. Unternehmensweise SLA-Bedingungen könnten nicht mit AWS oder GCP für risk-averse Beschaffungs-Teams übereinstimmen.
- Kostentreiber: Kreditpool mit Rollover. Bündelt Transkription mit Voice-Cloning aus einer 20-Sekunden-Probe, 300+ TTS-Stimmen und AI Dubbing über 60+ Quellsprachen in 33 Zielsprachen.
- Integration: Speziell für Media-Workflows gebaut. Single SDK deckt Transkription + TTS + Cloning + Dubbing ab. Webhook-Callbacks für async Jobs. Vertraut von 500.000+ Nutzern.
Ihre Speech-to-Text-API-Auswahlcheckliste
Dies ist der Workflow, den Sie ausführen müssen, bevor Sie einen Vertrag unterzeichnen. Es komprimiert alles oben in acht ausführbare Schritte. Buchen Sie vier Stunden für den ersten Durchgang; erwarten Sie eine Woche Pilot-Tests in Schritt 4.
- Definieren Sie Ihren dominanten Anwendungsfall in einem Satz. Schreiben Sie ihn auf: „Ich muss Podcasts transkribieren" oder „Live-Streams untertiteln" oder „Verkaufsgespräche analysieren" oder „von Benutzern hochgeladene Videos dubben." Wenn Sie es nicht in einem Satz schreiben können, haben Sie zwei Produkte und brauchen zwei Bewertungen. Ordnen Sie den Anwendungsfall der Latenz-Stufe aus Abschnitt 3 und der Genauigkeits-Anforderung aus Abschnitt 2 zu, bevor Sie sich irgendwelche Vendor-Preise ansehen.
- Unterstreichen Sie die zwei oder drei Entscheidungsachsen, die am meisten zählen. Aus dem Framework: Genauigkeit, Latenz, Offline, Sprachunterstützung, Kostenmodell, Integrations-Oberflächenbereich. Wenn Sie versuchen, alle sechs zu optimieren, werden Sie den teuersten Anbieter mit Features wählen, die Sie nie verwenden werden. Die meisten Builder sollten Kostenmodell und Integrations-Oberflächenbereich zuerst rangieren. Genauigkeit und Latenz werden Tiebreaker zwischen Finalisten.
- Prognostizieren Sie 12-Monats-Volumen mit einem 3x-Spitzen-Buffer. Schätzen Sie monatliche Minuten für Monat 1, Monat 6 und Monat 12. Multiplizieren Sie die Monat-12-Zahl mit 3, um Launch-Spitzen und virales Wachstum zu handhaben. Diese Zahl bestimmt, ob Sie einen Kreditpool, Pro-Minute-Preise oder einen Volumen-rabattierten unternehmensweise Vertrag brauchen — und es ist die Zahl, die Sie Anbietern während Verhandlung angeboten werden.
- Führen Sie den 7-Tage-Pilot durch. Dreißig Minuten Ihres echten Audios, drei Kandidaten-APIs, manuell gegen eine einzelne menschlich-korrigierte Referenz-Transkript bepunktet. Messen Sie WER nach Sprecher, nach Akzent und nach Domain-Term — nicht nur Gesamtheit. Testen Sie Streaming vs. Batch auf den gleichen Dateien. Dokumentieren Sie SDK-Reibung in einem freigegebenen Dokument während Sie gehen, während der Schmerz noch frisch ist.
- Stresstest Fehlerbehandlung. Senden Sie malformed Audio, abgelaufene Tokens, Rate-Limit-sprengend Bursts und übergroße Dateien. Fehlgeschlagen die SDK sauber mit umsetzbaren Fehlern oder hängt es? Eine API, die unter kontrolliertem Stress schlecht ausfällt, wird in der Produktion um 3 Uhr morgens schlecht ausfallen, und die Bereinigungs-Kosten werden jeden Pro-Minute-Ersparnisse übertrumpfen, die Sie bei der Unterzeichnung gesperrt haben.
- Berechnen Sie echte Gesamtkosten des Eigentums. Beziehen Sie Basis-Pro-Minute-Kosten, Streaming-Aufschläge, Diarization-Posten, Speicherung, Ausgang, Wiederholungs-Overhead und die Engineering-Stunden gespart oder verloren durch SDK-Qualität ein. Vergleichen Sie gegen ein Kreditpool-Modell, wenn Ihre Arbeitslast variabel ist — ein ungefähr $99/Monat-Kreditplan schlägt oft $0,006/Minute-Preise, wenn Verkehr spitz ist und mehrere Media-Features unter eine Rechnung bündelt.
- Audit Datenschutz und Daten-Aufbewahrungs-Defaults. Bestätigen Sie, ob der Anbieter Audio und Transkripts für Modell-Verbesserung aufbewahrt, und ob Sie vertraglich auswaehlen können. GDPR, HIPAA und SOC 2-Anforderungen könnten Anbieter unabhängig von Preis eliminieren. Nach European Data Protection Board-Anleitung zu Sprachassistenten können Cloud-STT-Anbieter „Shadow-Datensätze" von Sprachdaten erstellen, wenn nicht explizit vertraglich beschränkt — das ist eine Beschaffungs-Frage, nicht eine Feature-Frage.
- Verhandeln Sie vor dem Commit. Die meisten Anbieter bieten 15–30% Rabatte bei 12-Monats-Engagements über 500 Stunden/Monat. Wenn Sie Schritte 1–7 mit Zuversicht abgeschlossen haben, haben Sie Hebel. Bitten Sie um gesperrte Preise, einen dedizierten Support-Kontakt, erweiterte kostenlos-Stufe für Staging-Umgebungen und eine Exit-Klausel, wenn die Genauigkeit unter einen vereinbarten Schwellwert abfällt. Wenn Ihre Roadmap Lokalisierung enthält, bewerten Sie APIs wie die AI Dubbing API, die in einem Anruf übersetzen und dubben.
Diese Checkliste ist Ihre Verteidigung gegen Vendor-Marketing und Ihr Angriff gegen Versand-Verzögerungen. Die Teams, die Sprachfunktionen am schnellsten versenden, sind nicht diejenigen, die die billigste API wählten — sie sind diejenigen, die einen echten Pilot durchführten, echte TCO berechneten und eine Integrations-Oberflächenbereich wählten, mit der ihre Entwickler arbeiten wollten. Wenn Ihr Build auch Dubbing, Voice-Cloning oder Erzeugung synthetischer Sprache beinhaltet, bewerten Sie Plattformen, die Text to Speech, Voice-Cloning und Dubbing unter einer Kreditbilanz und einem SDK bündeln — die zweite und dritte Features, die Sie in sechs Monaten brauchen werden, kosten weniger und versenden schneller.