
Du hast eine halbfertige Track-Idee herumliegen — vielleicht ein Fan-Dub, ein Meme-Edit oder ein Gesangs-Cover — und du möchtest, dass dieser unverkennbar helle, schwerelose Hatsune-Miku-Sound es trägt. Doch der Weg dorthin ist mit schlechten Optionen verstellt. Offizielle Vocaloid- und Synthesizer-V-Software kostet Geld und verlangt eine Note-für-Note-Lernkurve. Die „kostenlosen Miku-Stimme"-Seiten, die du findest, liefern flaches, schiefes Audio aus. Und generische KI-Tools klingen entweder robotisch oder bewegen sich in trübem Urheberrechtsgebiet. Der richtige Miku Voice Generator-Workflow durchschneidet all das, aber nur, wenn du zuerst die beiden echten Reibungspunkte verstehst: Authentizität (etwas zu bekommen, das wirklich als „Miku" durchgeht, nicht nur als hochtoniger TTS-Clip) und Legalität (zu wissen, ob du überhaupt veröffentlichen darfst, was du erstellst).
Dieser Leitfaden gibt dir einen klaren, praktischen Weg — die rechtliche Linie, die du nicht überschreiten darfst, wie du zwischen Stimmauswahl und Cloning wählst, der Unterschied zwischen Sprech- und Gesangsausgabe, wie du das charakteristische Timbre abstimmst und wie du Audio exportierst, das du tatsächlich verwenden kannst. Kein Hype. Nur die funktionierende Methode, um eine KI-Miku-Stimme zu bauen, die standhält.

Inhaltsverzeichnis
- Vocaloid vs. KI-Voice-Generator: Welcher Weg passt zu deinem Miku-Projekt
- Die rechtliche und ethische Grenze, bevor du eine einzige Note generierst
- Deine Miku-Stimme in DubSmart AI generieren: Schritt für Schritt
- Den charakteristischen Sound einstellen: Tonhöhe, Klang und Stimmcharakter
- Vom Sprechen zum Singen: Eine generierte Stimme in einen Gesangstrack verwandeln
- Exportieren, Lokalisieren und Skalieren deiner Miku-Style-Inhalte
- Deine Pre-Flight-Checkliste für die Miku-Stimmgenerierung
- Häufig gestellte Fragen
Vocaloid vs. KI-Voice-Generator: Welcher Weg passt zu deinem Miku-Projekt
Es gibt zwei grundlegend unterschiedliche Wege zu einer Miku-Style-Stimme, und den falschen zu wählen verschwendet Stunden. Deine Wahl hängt vollständig davon ab, was du baust.
Weg A — Lizenzierte Gesangs-Synthesesoftware (Vocaloid / Synthesizer V). Vocaloid synthetisiert Gesang, indem es vorab aufgenommene Stimmsamples eines Sprechers mit der vom Nutzer eingegebenen Melodie und dem Text kombiniert. Das macht es zu einer text- und partiturbasierten Gesangs-Engine, nicht zu einem Text-to-Speech-Tool. Du gibst die Noten eine nach der anderen ein und stimmst dann Phoneme und Dynamik von Hand ab. Die Rohsynthese ist nur ein erster Durchgang — detailliertes Tuning ist für ein überzeugendes Ergebnis zwingend erforderlich, wie VSynth- und Vocaloid-Erstellungstutorials immer wieder betonen. Der Vorteil ist die vollständige melodische Kontrolle innerhalb eines einzigen Editors. Yamahas VOCALOID:AI-Forschung merkt an, dass moderne Systeme maschinelle Lernmodelle nutzen, die auf großen Stimmdatensätzen trainiert wurden, um ein natürlicheres Timbre als ältere konkatenative Engines zu erzeugen, laut Yamahas AI Sound Synthesis-Übersicht.
Weg B — KI-Voice-Generatoren (TTS + Voice Cloning). Diese konzentrieren sich auf gesprochene Prosodie und unterstützen von Haus aus keine musikalische Tonhöhensteuerung. Zum Singen leitest du die Ausgabe durch Tonhöhenkorrektur-Tools wie eine DAW oder Melodyne. Der Kompromiss ist Geschwindigkeit: keine Noteneingabe, schnelles Cloning aus kurzem Referenzaudio und breite mehrsprachige Ausgabe direkt ab Werk.

| Kriterium | Vocaloid / Synth V | Generische KI-TTS | KI-Voice-Cloning |
|---|---|---|---|
| Typische Kosten | Kostenpflichtige Lizenz | Kostenlos bis kostenpflichtig | Kostenlos bis kostenpflichtig |
| Lernkurve | Hoch | Niedrig | Niedrig–mittel |
| Native Tonhöhensteuerung | Ja | Nein (DAW erforderlich) | Nein (DAW erforderlich) |
| Sprechausgabe | Begrenzt | Ja | Ja |
| Einrichtung vor Audio | Melodie + Text + Tuning | Text eingeben | 20 Sek. Referenz |
(Kosten, Lernkurve, Gesang und Einrichtung gehen auf die technische Beschreibung im Wikipedia-Artikel „Vocaloid" und das VSynth-Covers-Tutorial zurück; die Klarheit zur kommerziellen Nutzung geht auf das Crypton/Vocaloid-Wiki und das Berkeley Technology Law Journal zurück. Keine Urteilsspalte — die richtige Wahl hängt von deinem Anwendungsfall ab.)
Welcher Weg passt also zu dir? Wenn du eine schnelle gesprochene Zeile möchtest — ein Meme, einen Fan-Dub von Dialog, einen kurzen vertonten Clip — nimm KI-Text-to-Speech. Es ist der schnellste Weg zu nutzbarem Audio, und du kannst in unter einer Minute einen Clip haben. Wenn du ein vollständiges gesungenes Cover produzierst und Kontrolle über jede Note möchtest, gibt dir der lizenzierte Vocaloid- oder Synthesizer-V-Weg diese Präzision, um den Preis eines steileren Einstiegs.
Wenn du Geschwindigkeit plus ein individuelles Timbre möchtest — etwa eine hellere oder markantere Stimme, als die Standardbibliothek bietet — ist der Cloning-Workflow gepaart mit einer DAW für die Tonhöhe dein Mittelweg. Du klonst eine helle Referenzstimme, generierst schnell gesprochene Phrasen und mappst sie dann in deiner DAW für den Gesang per Tonhöhe.
Der ehrliche Kompromiss ist dieser: Der schnellste Weg ist selten der musikalisch präziseste. Vocaloid gibt dir Kontrolle auf Notenebene, verlangt aber Geduld. KI-Generatoren liefern sofortige Ausgabe, überlassen dir aber die Tonhöhenarbeit danach. Es gibt auch eine IP-Unterscheidung, die all dem zugrunde liegt — Cryptons Materialien trennen das Urheberrecht an Mikus Namen und Maskottchen-Bild von der synthetisierten Gesangsausgabe. Diese Trennung ist enorm wichtig dafür, was du veröffentlichen kannst, und ist Gegenstand des nächsten Abschnitts.
Der schnellste Weg zu einer Miku-Style-Stimme ist selten der authentischste — passe das Werkzeug daran an, ob du sprichst oder singst.
Die rechtliche und ethische Grenze, bevor du eine einzige Note generierst
Dies ist der Abschnitt, den die meisten Kreativen überspringen und später bereuen. Bevor du einen Miku Voice Generator anrührst, musst du verstehen, was du tun darfst — und die Regeln sind spezifischer als „Fan-Inhalte sind in Ordnung".
Charaktergrafik und Stimme sind unterschiedlich lizenziert. Crypton Future Media übernahm 2012 eine Creative-Commons-Lizenz Namensnennung–Nicht kommerziell 3.0 (CC BY-NC 3.0) für originale Piapro-Charakterillustrationen, laut Cryptons offizieller Hatsune-Miku-Seite und den Piapro-Lizenzbedingungen. Diese Lizenz deckt die Bilder für die nicht kommerzielle Nutzung mit Namensnennung ab. Sie ist kein pauschales Recht, ihre Stimme mit KI kommerziell nachzuahmen oder zu monetarisieren. Die Kunstlizenz und die Stimme sind getrennte Fragen.
Was die Piapro-Lizenz tatsächlich abdeckt. Sie gilt für sechs Kerncharaktere — Hatsune Miku, Kagamine Rin, Kagamine Len, Megurine Luka, MEIKO und KAITO. Ihre originalen Illustrationen dürfen für nicht kommerzielle Nutzung kopiert, angepasst und verbreitet werden, sofern du die erforderliche Quellenangabe wie „Hatsune Miku, © Crypton Future Media, Inc. 2007, lizenziert unter CC BY-NC" einfügst, gemäß den Piapro-Lizenz-FAQ. Lass die Namensnennung weg und du fällst aus der Lizenz heraus.
Die Software-Lizenz der Character Vocal Series hat ihre eigenen Regeln. Unter Cryptons CV-Series-Lizenz dürfen Nutzer Gesang für die kommerzielle und nicht kommerzielle Nutzung synthetisieren — aber mit harten Grenzen. Du darfst keine abwertenden oder verstörenden Texte generieren, du darfst keine Songs kommerziell vertreiben, die explizit als „gesungen vom Charakter" vermarktet werden, und du darfst das Maskottchen-Bild ohne Cryptons Zustimmung nicht auf kommerzielle Produkte setzen, wie vom Vocaloid-Wiki zusammengefasst. Die „gesungen vom Charakter"-Beschränkung bringt viele Leute zu Fall, die annehmen, jede Gesangsausgabe sei Freiwild.
Das Klonen einer echten Stimme löst eine völlig andere Rechtsmaterie aus. Eine rechtliche Analyse von Skadden, Arps, Slate, Meagher & Flom LLP erklärt, dass das Bundesurheberrecht eine fixierte Tonaufnahme schützt, aber nicht die abstrakten Qualitäten einer Stimme — die Stimmidentität fällt stattdessen unter bundesstaatliche Right-of-Publicity-Gesetze und Vertragsrecht. Das Team der Voice-Firma Respeecher bringt es klar auf den Punkt: „Du kannst eine rohe KI-Stimme nicht urheberrechtlich schützen… Wenn sie jedoch wie eine echte Person klingt, kannst du sie aufgrund deren Right of Publicity dennoch nicht ohne Erlaubnis verwenden." Eine rohe KI-Stimmdatei ist im Allgemeinen nicht urheberrechtlich schützbar, weil ihr menschliche Urheberschaft fehlt — aber wenn sie wie eine bestimmte echte Person klingt, kontrollieren deren Persönlichkeitsrechte weiterhin ihre Nutzung.
„Miku-Style" versus ein direkter Klon ist die sicherere Linie. Das Training auf lizenzierten, nicht-prominenten Daten erzeugt „neue" Stimmen, bei denen die Rechte von Datenlizenzverträgen abhängen statt von der Identität einer bestimmten Person, laut dem Berkeley Technology Law Journal. Eine originale Miku-inspirierte helle synthetische Stimme zu bauen, stellt dich auf weit verteidigungsfähigeren Boden, als die offizielle Voicebank direkt zu klonen.
Monetarisierung ist die klare Grenze. Nicht kommerzielle Fan-Inhalte unter CC BY-NC sind breit und großzügig. In dem Moment, in dem du in die kommerzielle Nutzung übergehst — Produkte verkaufen, monetarisierte Kampagnen betreiben — brauchst du eine separate Erlaubnis von Crypton. Das ist der Entscheidungspunkt, um den du planen solltest.
Der verteidigungsfähige Ansatz ist einfach: Baue eine originale Miku-inspirierte helle Stimme für nicht kommerzielle Fan-Arbeit, gib die Charaktergrafik korrekt an und hole vor jeder kommerziellen Veröffentlichung eine Lizenz ein.
Technische Fähigkeit ist keine rechtliche Erlaubnis — dass ein Tool dir erlaubt, eine Stimme zu klonen, sagt nichts darüber aus, ob du sie veröffentlichen darfst.
Deine Miku-Stimme in DubSmart AI generieren: Schritt für Schritt
Mit der geklärten rechtlichen Grundlage hier der eigentliche Miku Voice Generator-Workflow innerhalb von DubSmart AI, von der Kontoerstellung bis zu einem vorab angehörten Clip. Der ganze Sinn ist, vor dem Ausgeben zu testen, sodass jeder Schritt deine Zeit und deine Credits schützt.

1. Erstelle ein Konto und wähle die kostenlose Stufe. Starte mit der kostenlosen Stufe, damit du experimentieren kannst, bevor du etwas ausgibst. Die Plattform läuft auf einem creditbasierten Modell mit übertragbaren Credits, was bedeutet, dass ungenutzte Credits am Ende eines Abrechnungszyklus nicht verfallen — sie werden übertragen, sodass frühes Testen dich später nicht bestraft.
2. Wähle dein Tool: Text to Speech oder Voice Cloning. Verwende Text to Speech für schnelle gesprochene Miku-Style-Zeilen — Dialog, Meme-Reads, vertonte Fan-Inhalte. Verwende Voice Cloning, wenn du eine individuelle helle Stimme aus einer bestimmten Referenz statt aus einem Standardprofil bauen möchtest.
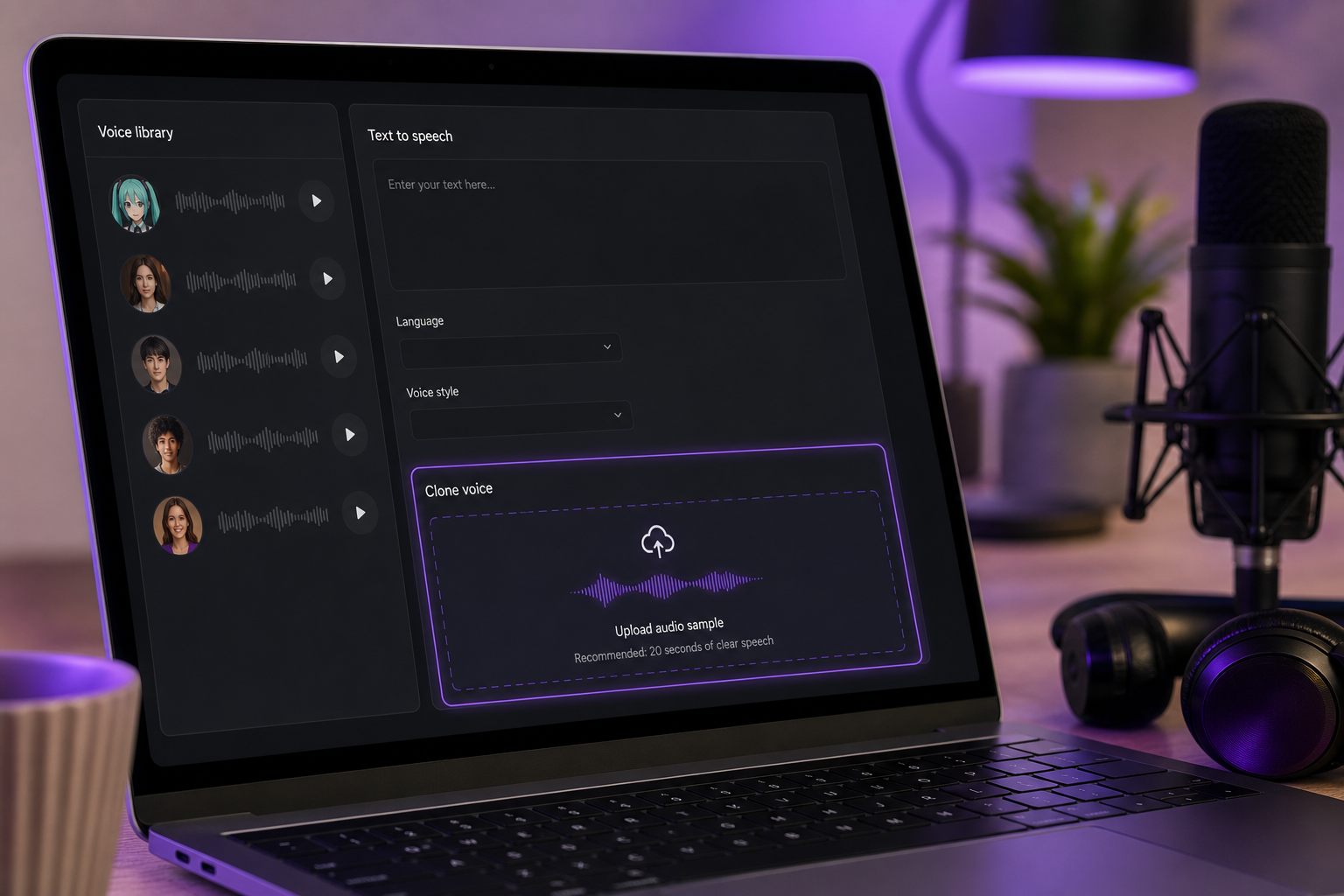
3. Wähle ein Stimmprofil oder klone aus einer Referenz. Wähle eine hochtonige, helle Stimme aus der Bibliothek mit über 300 Stimmen oder baue deine eigene durch Voice Cloning aus etwa 20 Sekunden sauberem Referenzaudio. Wenn du klonst, muss die Referenz ein sauberer, isolierter Gesang sein — keine Begleitmusik, kein Raumgeräusch. Der Klon ist nur so gut wie die Quelle.
4. Gib deinen Text oder Dialog ein. Füge deinen Text in das Eingabefeld ein. Für gesprochene Inhalte ist dies dein finaler Text. Für gesungene Zeilen füge die Textphrasen ein — die eigentliche Melodie handhabst du später in einer DAW, was weiter unten behandelt wird.
5. Stimme Tonhöhe, Geschwindigkeit und Klang in Richtung der charakteristischen Miku-Lage ab. Drücke die Stimme in Richtung hell, hoch und klar. Der Maßstab hier ist Yamahas VOCALOID:AI-Forschung, die moderne synthetische Gesänge so einordnet, dass sie eher auf natürliche Artikulation und helles Timbre als auf schwere robotische Einstellungen abzielen, laut Yamahas AI Sound Synthesis-Übersicht. Ziele auf sauber und klar, nicht auf schwirrend. Die genauen Zielwerte folgen als Nächstes.

6. Generiere und höre dir die Vorschau an, bevor du volle Credits ausgibst. Rendere immer zuerst einen kurzen Clip. Höre ihn dir an, beurteile, ob die Lage als Miku durchgeht, passe an, und verpflichte dich erst dann zur vollständigen Generierung. Diese einzelne Gewohnheit spart mehr Credits als jede andere.
Eine weitere Fähigkeit, die für später wissenswert ist: Das AI Dubbing der Plattform unterstützt das Dubbing von über 60 Quellsprachen in 33 Zielsprachen, was nützlich wird, wenn du fertige Fan-Inhalte für internationale Zielgruppen lokalisieren möchtest.
Den charakteristischen Sound einstellen: Tonhöhe, Klang und Stimmcharakter
Hier scheitern die meisten Versuche. Leute drehen die Tonhöhe hoch, hören etwas Hohes und nehmen an, sie seien fertig — aber ein hochtoniger TTS-Clip ist keine Hatsune-Miku-KI-Stimme. Der Charakter lebt in einer bestimmten Kombination aus Lage, Artikulation und Gewicht. Bring die richtig hin, und die Stimme liest sich als Miku, noch bevor jemand ein einziges erkennbares Wort hört.
Ziele auf das richtige Timbre. Yamahas VOCALOID:AI-Forschung ordnet moderne synthetische Gesänge so ein, dass sie eher auf natürliche Artikulation und helles Timbre als auf schwere robotische Einstellungen abzielen. Orientiere dich an einer sauberen, hochtonigen, präzise artikulierten Stimme — niemals an einem schwirrenden Monoton. Der zeitgenössische synthetische Sound ist hell und klar, nicht mechanisch. Wenn deine Ausgabe wie ein Roboter klingt, der ein Telefonmenü vorliest, hast du sie überflacht.
Drücke die Tonhöhe in Richtung Obergrenze, aber halt vor dem Artefaktieren an. Die „Miku"-Qualität lebt in der Tonhöhen-Obergrenze kombiniert mit knackigen Konsonanten, nicht in der Lautstärke. Hebe die Lage an, bis du an die Grenze hörbarer Artefakte stößt — diese dünne, glitchige, digital gedehnte Qualität — und ziehe dann leicht zurück. Der Sweet Spot ist hoch und hell, aber dennoch sauber. Eine Stimme, die zu tief gestimmt ist, klingt einfach wie gewöhnliches TTS, was der häufigste Fehler überhaupt ist.
Geschwindigkeit und Artikulation tragen mehr, als du erwarten würdest. Eine etwas schnellere, sauberere Aussprache liest sich als synthetisch-niedlich, was zum Kern des Charakters gehört. Über-natürliche Behauchtheit zieht die Stimme zurück in Richtung „generischer Erzähler". Zieh die Artikulation an. Lass die Konsonanten knackig landen. Diese Präzision ist Teil dessen, was dein Ohr als Vocal-Synth statt als Mensch erkennt.
Kontrolliere die Behauchtheit aggressiv. Reduziere Atem und Wärme. Miku liest sich als nahezu schwerelos — ihr fehlt die brustige Resonanz einer natürlichen erwachsenen Stimme. Wenn du Atem, Luft und Lunge in der Ausgabe hörst, entfernst du dich vom Charakter. Die synthetische Kante hängt von dieser Schwerelosigkeit ab. Zu behaucht und du verlierst sie vollständig.
Miku lebt nicht in den Worten — sie lebt in der Tonhöhen-Obergrenze und der knackigen, nahezu schwerelosen Artikulation.
Japanische versus englische Ausgabe verhält sich unterschiedlich. Japanische Phoneme landen tendenziell so, dass sie sich als „klassischer Miku" lesen, teils weil das der Sound ist, den die meisten Hörer mit dem Charakter verbinden. Englische Ausgabe braucht eine straffere Artikulation, um nicht ins generische TTS-Territorium abzurutschen. Wenn du auf Englisch arbeitest und es flach klingt, ist die Lösung meist knackigere Konsonanten und eine höhere Lage, nicht mehr Lautstärke.
Bereite eine saubere Klon-Referenz vor, bevor du irgendetwas anderes tust. Wenn du klonst statt eine Standardstimme zu wählen, bestimmt die Referenzqualität alles. Stelle sicher, dass die Klarheit hoch genug für eine saubere Transkription ist — wenn die KI Mühe hat, sie zu transkribieren, wird dein Klon ebenfalls matschig sein. Verwende einen Speech Separator, um vor dem Klonen einen sauberen Gesang aus jeglicher Begleitmusik zu isolieren. Müll rein erzeugt jedes Mal einen matschigen Klon. Für Kreative, die viele Referenzen auf einmal vorbereiten, macht der programmatische Zugriff über die Voice Cloning API die Batch-Vorbereitung weit weniger mühsam.
Die Fehler gruppieren sich in drei Muster. Zu tiefe Tonhöhe klingt wie gewöhnliches TTS. Zu behaucht verliert die synthetische Kante. Robotisches Monoton überflacht die Stimme, was direkt dem VOCALOID:AI-Benchmark für helle Artikulation widerspricht. Vermeide alle drei und du bist den größten Teil des Weges dort.
Akzeptiere schließlich, dass die Rohsynthese ein erster Durchgang ist. Vocaloid-Erstellungsanleitungen betonen, dass das Tuning von Phonemen, Timing und Dynamik für ein überzeugendes Ergebnis zwingend ist — und dieselbe Disziplin gilt für KI-Generatoren. Sowohl das VSynth-Covers-Tutorial als auch der Vocaloid-Einsteigerleitfaden behandeln das erste Rendering als Beginn der Arbeit, nicht als deren Ende. Generiere, höre kritisch zu, passe an, generiere neu. Die Stimme, die sich als Miku liest, ist fast nie die erste, die du machst.
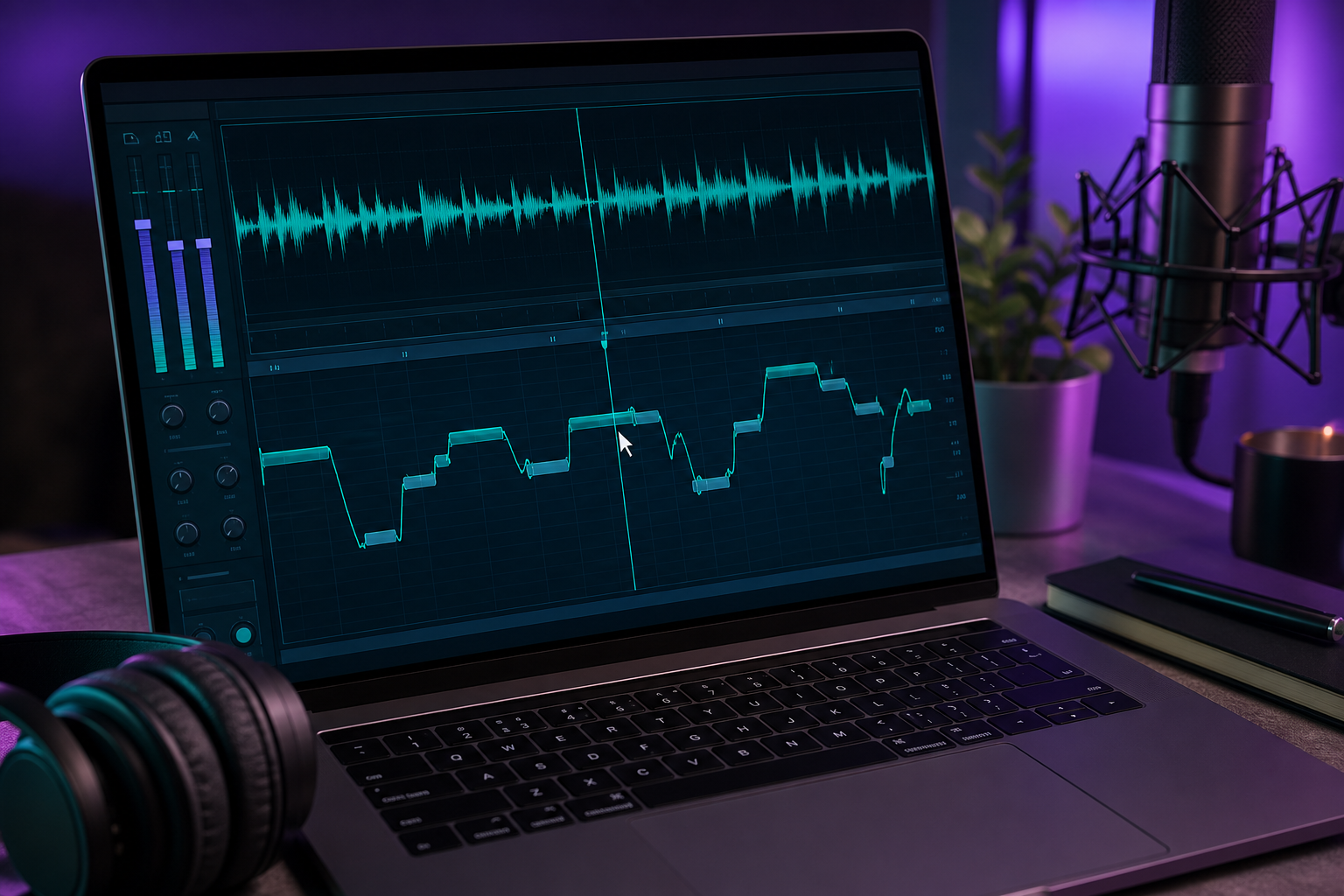
Vom Sprechen zum Singen: Eine generierte Stimme in einen Gesangstrack verwandeln
Hier ist die ehrliche Lücke: Die meisten KI-Generatoren sprechen, aber Miku ist fürs Singen berühmt. Diese Lücke zu überbrücken erfordert ein paar gezielte Schritte und eine DAW. So verwandelst du gesprochene Phrasen aus einem Miku Voice Generator in einen gesungenen Gesangstrack für ein Miku-KI-Cover.
1. Generiere saubere Gesangsphrasen. Produziere kurze, gut artikulierte Zeilen statt eines langen Textblocks. Kurze Phrasen sind weit einfacher per Tonhöhe zu mappen und an einer Melodie auszurichten. Eine Vier-Takt-Phrase, die du an ihren Platz schieben kannst, schlägt einen 30-sekündigen Monolog, den du chirurgisch zerschneiden musst.
2. Bestimme das BPM des Songs. Verwende ein BPM-Counter-Tool in deinem Browser, klopfe mit, bis sich das durchschnittliche Tempo stabilisiert, und stelle dann die nächstgelegene ganzzahlige BPM in deiner DAW ein. Das VSynth-Covers-Tutorial merkt an, dass „du in 99,9 % der Fälle nur die ganze Zahl der BPM brauchst", weil Songs selten in Dezimalstellen getaktet sind. Mach es dir nicht zu schwer — ein sauberes ganzzahliges Tempo ist fast immer richtig.
3. Importiere die Phrasen in eine DAW in ein gitterquantisiertes Projekt. Richte dein Projekt so ein, dass die Gesangsclips zeitlich am Backing-Track einrasten. Die Gitterquantisierung ist das, was den synthetisierten Gesang mit dem Instrumental verriegelt hält — ohne sie driftet alles. Diese Gitter-und-Tempo-Disziplin ist die Standardvoraussetzung, bevor jegliche Tuning-Arbeit beginnt.
4. Richte die Phrasen per Tonhöhe an der Melodie aus. Verwende Melodyne oder Auto-Tune, um jede Phrase auf die korrekten Noten zu biegen. Dieser Schritt ist erforderlich, nicht optional, weil generische KI-TTS von Haus aus keine musikalische Tonhöhensteuerung unterstützt. Der Generator gab dir das Timbre und die Worte; die DAW gibt dir die Melodie. Dies ist der mit Abstand arbeitsintensivste Teil des gesamten Prozesses, und hier wird ein gesungenes Cover tatsächlich gemacht.
5. Schichte mit dem Backing-Track und mische. Lege den getuneten Gesang über das Instrumental, passe Timing und Dynamik an und füge leichte Effekte hinzu — Reverb, eine Prise Kompression, vielleicht einen Doubler für Fülle. Achte auf Phrasen, die zu weit vorne oder hinten sitzen, und balanciere sie gegen den Mix.
Genau hier endet auch KI-TTS und dedizierte Gesangs-Synth-Tools beginnen. Wenn du echte Note-für-Note-Melodiekontrolle innerhalb eines einzigen Editors möchtest — ohne die Export-Import-Neutuning-Schleife — ist der lizenzierte Vocaloid- oder Synthesizer-V-Weg direkter, wie zuvor behandelt. Der KI-plus-DAW-Weg tauscht diese Integration gegen Geschwindigkeit und ein individuelles Timbre. Keiner ist falsch; sie dienen unterschiedlichen Produzenten.
Exportieren, Lokalisieren und Skalieren deiner Miku-Style-Inhalte
Du hast eine Stimme, die sich als Miku liest, und einen Track, der zusammenkommt. So lieferst du ihn gut aus und streckst deine Ressourcen.
Exportformate und Qualität. Höre die Vorschau in Entwurfsqualität an, während du iterierst, und exportiere dann dein finales Audio in voller Qualität, sobald du zufrieden bist. Die Entwurf-dann-Final-Gewohnheit hält deine Renderings während der unordentlichen Mitte günstig und gibt nur für die Version, die du tatsächlich behältst, Premiumqualität aus. Bestätige immer, dass das Exportformat dem entspricht, was deine DAW oder dein Videoeditor erwartet, bevor du dich festlegst.
Nutze übertragbare Credits effizient. Weil das Credit-Modell ungenutzte Credits überträgt, kannst du deine Generierungsarbeit bündeln und Credits über Sitzungen hinweg wiederverwenden, statt sie auf wiederholten Voll-Render-Tests zu verbrennen. Generiere mehrere Phrasen in einer fokussierten Sitzung, höre sie alle in der Vorschau an und verfeinere dann — statt über Tage hinweg eine Zeile nach der anderen zu rendern, anzuhören und neu zu rendern.
Lokalisiere Fan-Inhalte in andere Sprachen. Verwende AI Dubbing, um eine fertige Miku-Style-Zeile in andere Sprachen zu bringen. Mit Unterstützung für über 60 Quellsprachen und 33 Zielsprachen kann ein einzelner Fan-Track internationale Zielgruppen erreichen, ohne dass du von Grund auf neu aufnehmen oder neu tunen musst. Für einen Charakter mit globaler Fanbase ist diese Reichweite bedeutend.
Nutze API-Zugriff für Entwickler. Teams, die Miku-Style-Stimmfunktionen in ihre eigenen Apps einbauen, können direkt über die Text to Speech API, die Voice Cloning API und die AI Dubbing API integrieren. Das verwandelt einen manuellen kreativen Workflow in einen programmatischen — nützlich für Agenturen, App-Entwickler und alle, die Stimmcontent in Mengen generieren.
Paare die Stimme mit Visuals. Für Fan-Videos und Musikvideo-artige Inhalte generierst du passendes Artwork mit dem KI-Bildgenerator und animierst Standbilder mit Image to Video. Eine Warnung trägt aus dem rechtlichen Abschnitt herüber: Die CC-BY-NC-Grenzen für offizielle Charaktergrafik gelten weiterhin, also halten dich originale oder korrekt zugeschriebene Visuals auf sicherem Boden.
Vermeide Monetarisierungsfallen beim Export. Bevor du etwas monetarisierst, bestätige, dass dein Projekt innerhalb der zuvor festgelegten nicht kommerziellen und Charakter-Marketing-Grenzen bleibt. Kommerzielle Nutzung — Verkauf, monetarisierte Kampagnen, gebrandete Produkte — erfordert eine separate Erlaubnis von Crypton, gemäß Cryptons offiziellen Bedingungen und der Piapro-Lizenz. Dies zu prüfen, bevor du auf Veröffentlichen drückst, ist weit günstiger, als es danach zu entwirren.
Deine Pre-Flight-Checkliste für die Miku-Stimmgenerierung
Geh diese durch, bevor du irgendetwas generierst. Jeder Punkt ist eine schnelle Bauchgefühl-Prüfung, die später Nacharbeit spart.
- Sprechen vs. Singen entschieden — TTS für Dialog; Cloning plus eine DAW für ein gesungenes Cover.
- Deinen rechtlichen/Nutzungsansatz bestätigt — nicht kommerzielle Fan-Nutzung, oder brauchst du Cryptons Erlaubnis für eine kommerzielle Veröffentlichung?
- Ein helles Stimmprofil ausgewählt ODER eine saubere ~20-sekündige Klon-Referenz vorbereitet — isoliere zuerst den Gesang, wenn du klonst.
- Tonhöhe und Klang auf die Miku-Lage abgestimmt — hoch, knackig, geringe Behauchtheit, niemals robotisch.
- Kurze Clips in der Vorschau angehört, bevor du volle Credits ausgibst — schütze dein Credit-Guthaben.
- Ganzzahlige BPM und ein gitterquantisiertes DAW-Projekt eingestellt — wenn du singst, tu das vor dem Tonhöhen-Mapping.
- Dein Exportformat und deine Qualität gewählt — Entwurf beim Iterieren, volle Qualität fürs Finale.
- Lokalisierung geplant — wenn du mehrsprachige Fan-Reichweite möchtest, stelle deine Zielsprachen zusammen.
Der schnelle Entscheidungsleitfaden: Wähle TTS, wenn du schnellen Dialog brauchst; wähle Cloning plus eine DAW, wenn du einen Song produzierst.
Bereit, eine zu bauen? Starte mit DubSmart AIs kostenloser Stufe mit Text to Speech, generiere einen kurzen Clip und stimme die Lage ab, bevor du einen einzigen Voll-Render-Credit einsetzt. Erst Vorschau, dann verfeinern, dann ausliefern — das ist die ganze Disziplin hinter einem Miku-Voice-Generator-Workflow, der tatsächlich richtig klingt.
Häufig gestellte Fragen
Ist es legal, einen Hatsune-Miku-Voice-Generator für YouTube zu verwenden?
Es hängt von der kommerziellen versus nicht kommerziellen Absicht ab. Cryptons CC-BY-NC-3.0-Lizenz deckt die nicht kommerzielle Nutzung von Charaktergrafik mit Namensnennung ab, aber monetarisierte oder kommerzielle Nutzung braucht eine separate Erlaubnis, und du darfst einen Song nicht als „gesungen von" dem Charakter vermarkten, gemäß Crypton und dem Vocaloid-Wiki. Baue eine Miku-inspirierte originale Stimme für sicherere Fan-Inhalte.
Kann ich Miku singen lassen, oder nur sprechen?
KI-TTS generiert gesprochene Ausgabe und hat keine native musikalische Tonhöhensteuerung. Zum Singen leitest du deine Phrasen durch eine DAW und richtest sie per Tonhöhe mit Melodyne oder Auto-Tune aus, wie im VSynth-Covers-Tutorial gezeigt. Für eingebaute Noteneingabe innerhalb eines Editors ist lizenziertes Vocaloid oder Synthesizer V der direktere Weg.
Wie viel Audio brauche ich, um eine Miku-Style-Stimme zu klonen?
Du kannst aus etwa 20 Sekunden sauberem Referenzaudio klonen. Isoliere den Gesang zuerst aus jeglicher Begleitmusik für das sauberste Ergebnis — und denke daran, dass das Klonen der Stimme einer echten, identifizierbaren Person Right-of-Publicity-Fragen aufwirft, gemäß Respeecher. Verwende Voice Cloning mit einer gut vorbereiteten Referenz.
In welchen Sprachen kann eine Miku-KI-Stimme generiert werden?
Die Plattform unterstützt das Dubbing von über 60 Quellsprachen in 33 Zielsprachen, sodass eine fertige Zeile für internationale Fan-Zielgruppen lokalisiert werden kann. Das macht ein einzelnes Miku-KI-Cover über mehrere regionale Versionen hinweg wiederverwendbar, ohne neu aufzunehmen.
Gibt es eine kostenlose Möglichkeit, einen Miku Voice Generator auszuprobieren?
Ja — es gibt eine kostenlose Stufe plus ein