
What Listeners Actually Hear When a Voice Impression Lands
Take 17. The Morgan Freeman impression is close — the cadence is there, the Mississippi drawl is almost convincing — but the gravity is missing. Your listener says "almost," which in voice work is the same word as "no." You delete the take. You try again. Forty minutes later you have nothing usable for the YouTube voiceover and your throat is starting to tire.
This is the trap that swallows creators trying to build a multilingual channel: nailing a character voice in English, then watching it collapse the moment a Spanish or Hindi dub enters the production plan — because the impression was phonetic memorization, not internalized vocal signature. Studio hours pile up. Takes get rejected. Localization plans quietly get shelved. Content that should ship doesn't.
This guide breaks down what makes voice impressions actually land on a listener's ear, the four drills that build the underlying craft, and where AI voice cloning slots into the workflow as a scaling tool — not a replacement for the skill underneath.

Table of Contents
- What Listeners Actually Hear When a Voice Impression Lands
- The Five Vocal Building Blocks Every Impression Rests On
- Four Drills That Build Voice Impression Muscle Memory
- Where Manual Voice Impression Practice Hits a Hard Ceiling
- How AI Voice Cloning Amplifies a Skilled Impressionist's Range
- Build Your Voice Impression Toolkit — Match Your Bottleneck to the Right Path
- FAQ
Listeners do not identify voices by pitch alone. They identify them by spectral fingerprint — the formant structure, vibratory patterns, and timing signatures that a specific vocal-tract anatomy produces. According to voice scientist Ingo R. Titze in Principles of Voice Production, voice quality is shaped primarily by vocal-tract configuration and resonance, not fundamental frequency. Two people can hum the exact same note and still sound nothing alike, because their throats, mouths, and sinuses act as different filters on that same vibration.
That is the unlock for voice impressions. The job isn't matching one variable. It's reproducing a five-layer signature:
- Pitch contour — not just average pitch, but where it rises and falls inside a sentence
- Resonance placement — chest, mask, nasal, head
- Breath pattern and pacing — where the speaker inhales and how long their pauses sit
- Articulation signature — consonant attack and vowel shape
- Emotional subtext — the feeling driving every word, the layer amateurs skip
A full diagnostic table comes in the next section. For now, hold the frame: signature, not surface.
Sounding Like Versus Performing As
There is a distinction the working voice acting world treats as non-negotiable: sounding like someone and performing as them are different skills. Dee Bradley Baker — the character voice actor behind much of Star Wars: The Clone Wars and Avatar: The Last Airbender — has built his entire teaching practice around the argument that character voices only work when the performer understands the character's emotional life, intention, and physicality. Not just accent. Not just tone. According to his educational materials in I Want to Be a Voice Actor!, an impression that targets the sound without the intention produces something the listener registers as mechanical, even when they can't articulate why.
Two Deconstructions That Make the Theory Concrete
Consider amateur Darth Vader impressions. They sound thin because they target the wrong two variables: pitch (low) and breath effect (heavy exhale). What they miss is the chest resonance where James Earl Jones' voice actually lives. The breath effect is a layer painted on top of a chest-grounded fundamental — not a substitute for it. Without that resonant anchor, the impression sounds like someone whispering with effort instead of speaking from inside a cathedral.
A softer voice flips the priority. With David Attenborough, pacing carries roughly 70% of the load. The slow inhale before key adjectives. The lift on wonder-words. The descending phrase endings. Copying the received-pronunciation accent without the rhythm produces documentary parody — not Attenborough.
Why This Matters for AI Cloning
The same perceptual breakdown that builds better human impressions also produces better AI voice clones. The model learns signature, not surface. So a creator who has internalized resonance placement and pacing isn't just better at performing the character — they're recording better training data when they sit down to clone that character voice. The skill transfers. The deeper part of the article covers how.
The Five Vocal Building Blocks Every Impression Rests On
The previous section named the layers. This section turns them into a diagnostic tool you can apply to any reference audio in under five minutes.
| Element | What It Is | How to Identify in Reference | Common Amateur Mistake |
|---|---|---|---|
| Pitch & Register | Natural fundamental frequency and the range the speaker moves within | Hum along; find the lowest sustained note and the typical "home" note | Locking to one pitch instead of tracking contour |
| Resonance & Tone | Where the voice physically vibrates — chest, mask, nasal, head | Place a hand on chest, throat, cheekbones while playing reference; feel which area would buzz | Copying timbre from the throat instead of the right cavity |
| Breath & Pacing | Inhale points, pause length, words-per-minute, phrasing rhythm | Mark every breath in a 30-second clip; count syllables between breaths | Speaking too fast, collapsing the character's pace |
| Articulation & Clarity | Consonant attack strength, vowel openness, dialect tongue placement | Slow the reference to 0.5x speed; isolate consonant onsets | Generic "good diction" instead of the character's specific choices |
| Emotional Subtext | The underlying feeling coloring every line | Ask: what does this character want in this moment? | Performing words instead of the intention beneath them |
The order on the table is not cosmetic. Pitch and resonance are anatomical — they get set by where you place the voice inside your body. Get those wrong and no amount of pacing or articulation can rescue the impression downstream. Pacing and articulation are behavioral — adjustable through repetition. Emotional subtext is interpretive — the layer that elevates a technically accurate impression into a believable one.
Try the diagnostic on a concrete target. A creator attempting Cate Blanchett's Galadriel finds pitch quickly: medium-low, breathy. The trap is resonance. Her voice sits in the mask — the area behind the cheekbones — not in the throat. Most amateur attempts pull the resonance down into the throat, which sounds smaller and younger. Once the resonance is correctly placed in the mask, the slow pacing and elongated vowels follow naturally, because the cavity itself dictates the rhythm. Fix the anatomical layer and the behavioral layers self-correct.
A Note for Anyone Planning to Clone Their Impression
The diagnostic above also applies in reverse. When you record training audio for a voice clone, the model captures whatever signature is most consistent across the dataset. According to the Voiceover Masterclass cloning guide, creators should record in a consistent, neutral style throughout one continuous session — unless the explicit goal is to clone a stylized character voice. Translation: if you want a clone of your character impression rather than your everyday speaking voice, you must stay in character for the entire training recording. Drifting in and out of it produces a mushy clone that sounds like neither.
This is also why Section 1's perceptual layers matter operationally. A drifting performer produces drifting data. A performer with internalized resonance placement produces stable data. The clone is only as good as the consistency of the signature it learns.
Four Drills That Build Voice Impression Muscle Memory
Knowing the five vocal elements is diagnosis. These four drills are treatment. Each targets a specific failure mode and takes 15 minutes or less.
Drill 1 — The Isolation Loop
Targets: pitch and resonance accuracy.
- Pick a 5-word phrase from your reference (e.g., "I have been expecting you")
- Loop the reference 10 times to embed the target sound in your ear
- Record your version focused on pitch only — ignore resonance, ignore character, just match the melodic contour
- Re-record focused on resonance only — same phrase, target the right cavity
- Re-record focused on pace and breath — same phrase, match the timing exactly
- Time: 15 minutes daily
Why it works: motor-learning principles in voice pedagogy support blocked practice (one variable at a time) over variable practice when learning new coordinations, a position consistent with Titze's framework in Principles of Voice Production. Isolating one variable trains the muscle group responsible for it without the cognitive load of juggling all five.
Drill 2 — The Blind Reference Test
Targets: ear training, self-deception.
- Record three takes of a 15-second passage in character
- Wait at least 4 hours — fresh ears
- Play the reference, then your best take, alternating without looking at waveforms
- Rate honestly: which one sounds more like them?
Most creators discover their "best take" wasn't the closest one. They were rewarding the take where they felt the most effort instead of the take that landed most accurately. The blind test breaks that bias. Run it weekly.
Drill 3 — The Emotional Anchor
Targets: emotional subtext, performance authenticity.
Before recording, name the character's emotional state in the scene. Gandalf shouting "You shall not pass!" isn't anger — it's protective resolve under exhaustion. The two states sound completely different even when the words are identical. Physically embody it: stance, breath depth, where you hold tension in your body. Dee Bradley Baker's repeated point in I Want to Be a Voice Actor! is that character voice without character intention sounds mechanical. Record only after the anchor is set. Every session.
Drill 4 — The Cross-Language Pressure Test
Targets: signature internalization vs. phonetic memorization.
Take your impression and perform it on a completely different script — a grocery list, a weather report, your favorite song lyrics — in the same voice. If the impression collapses the moment the words change, you've memorized a phonetic sequence rather than internalized a vocal signature.
This drill is the gatekeeper for localization work. If your impression cannot hold up against a grocery list in English, it will not hold up dubbed into Portuguese. Weekly cadence.
If your impression can't survive being applied to a grocery list, it won't survive being dubbed into a second language.
Your Weekly Voice Impression Training Schedule
- Daily 15-minute isolation loop on one vocal element (rotate: pitch → resonance → pace → articulation)
- Establish an emotional anchor before every recording session
- One blind reference test per week with 4+ hours of separation between takes and review
- One cross-language pressure test per week using non-script material
- Record a 30-second "signature take" every Friday — same passage, same character — to track week-over-week progress
- Maintain a noise floor of −60 dB or lower in your recording space (acoustic panels, no HVAC, no fans), per the Voiceover Masterclass standard — this matters for both human ear training and any future cloning use
Where Manual Voice Impression Practice Hits a Hard Ceiling
The drills above build real skill that no tool can fake. They also have a ceiling. A single skilled performer has finite throughput — the bottleneck isn't talent, it's biology and the clock. Four scenarios show where that ceiling becomes a business constraint.
The 30-minute video problem. A creator holding a character voice across 30 minutes of dialogue fatigues vocally. Take 40 doesn't match take 4. Pitch drifts upward, breath shortens, the chest resonance migrates into the throat. Edit-room fixes cost hours.
The 6-language localization problem. Even a creator fluent in Spanish cannot necessarily perform their English character voice convincingly in Spanish. Multiply that by six target languages and the localization plan becomes a year of voice work — assuming the multilingual performance skill exists at all.
The client revision problem. A line change at week 8 means re-recording in the same vocal state — same room, same time of day, same throat hydration. Practically impossible to match perfectly.
The multi-character problem. A creator voicing four characters in a single dialogue scene needs four separate recording passes minimum, and the vocal transitions exhaust the larynx fast.
Voice Impression Production Methods Compared
| Factor | Self-Recorded Impressions | Hiring a Voice Actor | AI Voice Cloning |
|---|---|---|---|
| Time to first usable take | Weeks to months of distributed practice | 1–3 days (casting + recording) | Seconds for a beginner clone from a 10-second sample; 30–120 min recording for prosumer-grade |
| Recording sample needed | N/A — live performance | N/A — live performance | 30–120 sec (turnkey); 10–15 min (RVC); 30 min–2 hr (professional) |
| Take-to-take consistency | Variable — drifts with fatigue | High within a session; variable across sessions | Perfectly repeatable for given text and parameters |
| Multilingual scaling | Requires fluency + impression skill in each | Multilingual actor or multiple actors | Cross-lingual AI Dubbing preserves timbre across targets |
| Best fit | Live performance, short-form, ear-training | Premium one-off productions | Long-form, multilingual, iterative content |
Sources for the figures above: ElevenLabs tutorial, DeepReel, CloudPano, Kukarella, and the RVC tutorial.
This is not a verdict that AI wins. Manual practice produces skills that transfer to live performance, podcasting, theater, and the ear training that makes every other method better. The table isolates the specific production scenarios where biology becomes a constraint.
The counter-evidence matters too. Voice actors and SAG-AFTRA have publicly noted that current AI clones still struggle with complex emotional nuance, subtext, and dynamic scene work — particularly in drama and comedy where microtiming carries meaning. For a creator producing a six-language explainer video, that limitation is acceptable. For a creator producing a narrative animation with three emotional turns per scene, it isn't yet. The honest synthesis: the question is not "manual or AI." It's "where does each method belong in the workflow?"
The bottleneck in voice impression work isn't talent — it's biology and the clock.
How AI Voice Cloning Amplifies a Skilled Impressionist's Range
What Cloning Actually Captures
A voice clone is not a recording. It is a learned model of vocal signature. The model captures the resonance profile, pitch contour patterns, breath rhythm, and articulation tendencies from the training audio, then applies them to new text. Speech scientist Rupal Patel, founder of VocaliD, has argued in her TED talk and related interviews that authentic synthetic voices must capture idiosyncratic prosody, not just average pitch, to read as real rather than generic.
That is precisely why a well-executed impression is a better clone candidate than a flat neutral take. The signature the model learns is the character signature. A creator who has done the Section 3 drills walks into a voice cloning session with cleaner, more consistent data than someone who hasn't — and the resulting clone reflects that difference directly.
The Dataset Reality
There are three quality tiers, each with specific sample requirements.
- Beginner / instant clone: ~10 seconds of clear speech yields a basic test clone you can experiment with in seconds, per the ElevenLabs tutorial.
- Creator-grade narrator clone: 30–120 seconds of clean audio produces a stable narrator-style clone, per DeepReel and CloudPano.
- Professional-grade clone: 30 minutes to 2 hours of recordings, with results getting noticeably better closer to the 2-hour mark; processing time on provider infrastructure runs roughly 2–6 hours, per the ElevenLabs tutorial.
- Open-source RVC stack: 10–15 minutes of clean audio is the practitioner sweet spot; 2–10 minutes is possible with quality trade-offs; 40 kHz sample rate is the practitioner default, per the RVC tutorial.
The technical floor is non-negotiable: a noise floor of ≤ −60 dB, and no compression, EQ, de-essing, or noise reduction applied to the raw training files, per the Voiceover Masterclass standard. Garbage in, garbage out applies twice over — the model amplifies whatever artifacts exist in the source.

Two Workflow Case Studies
Case A — The 30-Minute YouTuber. A creator nails a character impression for 30 seconds but loses consistency across a long-form episode. The workflow: record one perfect 90-second take of the character voice. Clone it. Generate the background dialogue with the clone using Text to Speech, while reserving live performance energy for the five or six key emotional beats that carry the episode. The result: consistent voice across 30 minutes, performance peaks where they matter, recording session compressed from roughly 8 hours to about 90 minutes.
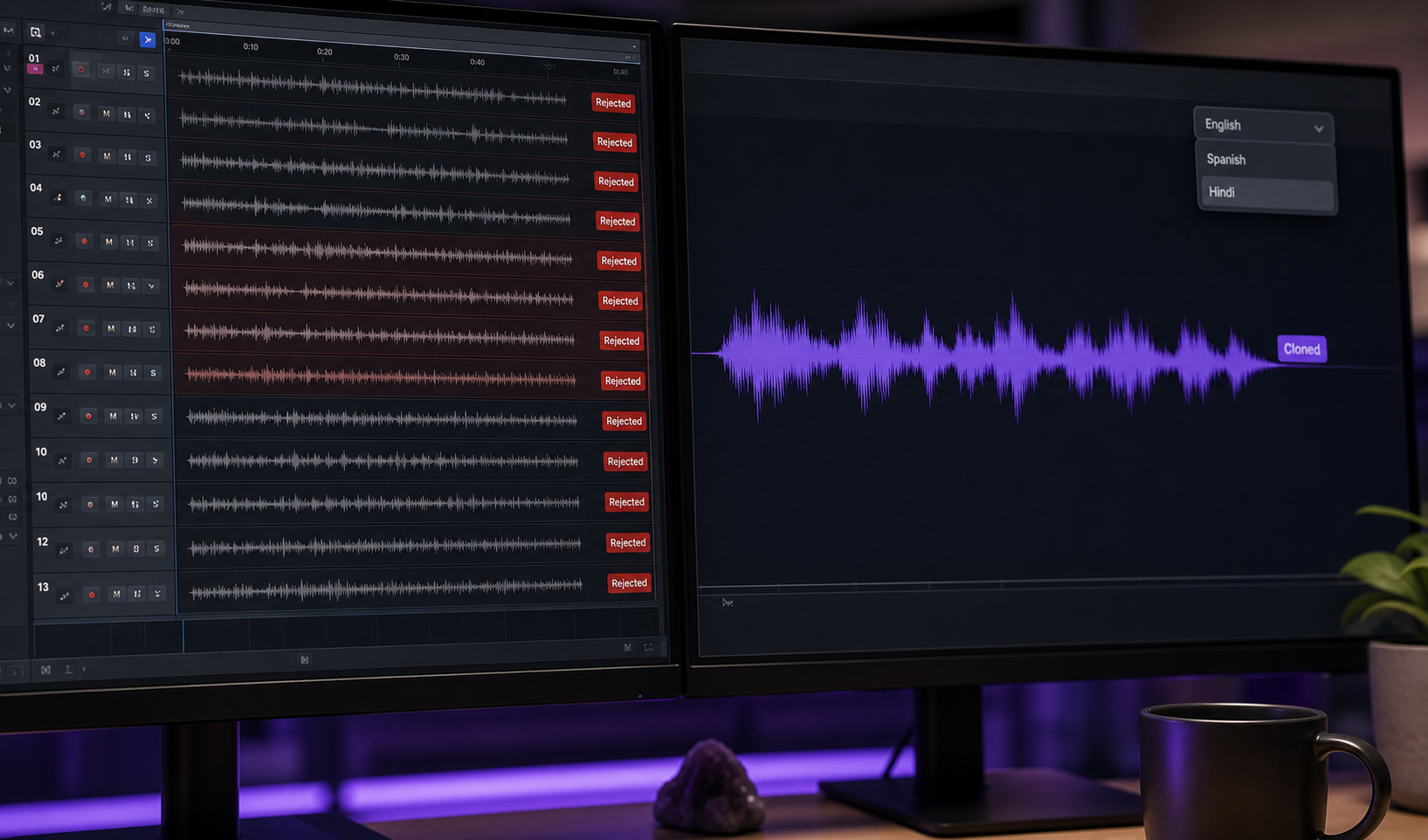
Case B — The 6-Language Training Video. A small business produces a 15-minute internal training module narrated in a warm, authoritative character voice. The workflow: record the English version once with the live impression. Clone the voice. Use cross-lingual cloning via a Voice Cloning API to render Spanish, Portuguese, French, German, Hindi, and Japanese versions while preserving the character timbre across languages, per DeepReel and Kukarella. The same character "speaks" all six languages because the signature transfers, even though the language doesn't.
Voice cloning doesn't replace the skill of nailing an impression — it amplifies it. The hard part is still getting the character right; the technology just removes the repetition.
Ethics and the Legitimacy Boundary
Synthetic voice can be weaponized. Law professor Danielle Citron, in The Fight for Privacy and related deepfake scholarship, has documented how unconsented voice cloning enables impersonation, fraud, and political misinformation — and has argued for both legal safeguards and design-level guardrails on commercial tools.
The ethical line for creators is straightforward. Cloning your own voice for your own content is unambiguously fine. Cloning a fictional character voice you've developed yourself is fine. Cloning a real public figure, or anyone, without explicit consent is not. Disclosure in credits when AI dubbing is used is becoming standard practice and is the safer default for any commercial work.
Build Your Voice Impression Toolkit — Match Your Bottleneck to the Right Path
The choice isn't manual practice or AI cloning. It's identifying which bottleneck is actually blocking your work right now, and applying the matching path. The matrix below maps four common creator situations to specific first actions.
Which Voice Impression Path Fits Your Bottleneck?
| Your Situation | Primary Bottleneck | Tool Priority | First Action This Week |
|---|---|---|---|
| Impressions aren't convincing yet — building craft for YouTube or Twitch | Skill gap | Drills from Section 3 + peer feedback | Pick one character; run the daily isolation loop for 14 days before assessing |
| Strong impression, but exhausted re-recording long videos | Vocal fatigue, consistency drift | Voice cloning on your own performed impression | Record one clean 90-second take in character at −60 dB; clone it; test on a 2-minute generated passage |
| Localizing existing English content into multiple languages | Multilingual performance gap | Cross-lingual cloning + AI dubbing | Clone your reference impression once; dub a 2-minute sample into your highest-priority target language; review for character preservation |
| Team producing branded multilingual content at volume | Pipeline scalability | Cloning + API integration | Prototype the AI Dubbing API workflow on one production project |
Three working principles for using this matrix honestly.
The matrix isn't permanent. A creator in row one today moves to row three in eighteen months. The bottleneck shifts as the work shifts. Re-evaluate quarterly.
Cloning amplifies; it does not originate. The repeated finding across cloning tutorials — Voiceover Masterclass, the ElevenLabs guide, the RVC tutorial — is that audio quality and performance quality in the source determine clone quality. A creator who skips Section 3's drills and tries to clone a sloppy impression gets a clone of a sloppy impression. The technology is faithful to its input.
The 30-second floor matters operationally. Several turnkey platforms can produce a working voice profile from roughly 20–30 seconds of clean audio. That means a creator who already has one good take of their character voice is one upload away from a reusable production asset. The barrier isn't the technology — it's having that one good take.
Address the counter-pressure too. Some vocal coaches caution that leaning hard on cloning early can cap foundational skill development: breath support, resonance control, articulation. The pragmatic middle path is to keep doing the drills even when you're using the clone for production, because the drills make every future clone better.
Your Two-Week Action Plan
- Identify which row of the matrix describes your current bottleneck — be honest; most creators sit in two rows at once. Pick the more painful one.
- If your row is "skill gap": commit to the daily 15-minute isolation loop and one weekly blind reference test for the full 14 days before re-evaluating.
- If your row involves cloning: record a clean 30–90 second reference take with a noise floor at or below −60 dB, in character, in one continuous session, with no EQ or compression applied.
- Run a low-stakes clone test before any client or revenue work — use it on an internal video, a personal channel test, or a draft script.
- If localizing: pick your highest-priority target language and dub a 2-minute sample. Review specifically for character preservation, not just translation accuracy.
- If integrating into a production pipeline: prototype the API workflow on one project before standardizing. Test the Text to Speech API and Voice Cloning API on a representative content type.
- Set a 14-day checkpoint to re-assess your bottleneck — it may have moved.
The creators who win at multilingual content in 2025 are not the ones who picked the right tool. They're the ones who built a real impression first, then let the tools do what tools do best — repeat it, scale it, and preserve it across languages they don't speak.
FAQ
Can I use AI voice cloning to do impressions of real public figures?
Legally and ethically: not without explicit consent, and even then, disclose it. Danielle Citron's scholarship on deepfakes and synthetic media documents how unconsented voice cloning of real people enables fraud, harassment, and political misinformation. For a fictional character you've developed, or your own voice, cloning is unambiguous. For an impression of a living public figure, the safest answer is no — and reputable platforms enforce policies aligned with this principle. Disclosure in credits is becoming standard practice for any commercial work that uses synthetic voice.
How long does it really take to clone a usable voice?
It depends on the quality tier. A 10-second sample produces an experimental clone you can test with in seconds, per the ElevenLabs tutorial. A 30–120 second sample produces a stable creator-grade clone suitable for narration and explainer content, per DeepReel and CloudPano. A professional-grade clone wants 30 minutes to 2 hours of source recording plus roughly 2–6 hours of processing time on provider infrastructure. Most creator platforms sit comfortably at the fast end of the creator tier, accepting roughly 20–30 seconds of clean audio as the working floor.
Do I need to disclose that I used AI voice cloning in my content?
There's no universal legal requirement yet, but disclosure is becoming standard practice and is the safer default. If you cloned your own voice for efficiency, a simple credit line — "Voice cloned via [platform] for multi-language versions" — protects audience trust. If the content represents a real person, even with their consent, disclosure is essential. SAG-AFTRA's ongoing position around AI voice usage in commercial work is pushing the broader industry toward clear labeling, and aligning your practice with that direction early avoids both reputational and legal exposure later.