
You have scrolled past forty voice samples. Headphones on, you tap preview, listen for three seconds, tap the next one, and the next, until every sample blurs into the same indistinct hum. Is this one "warm" or just "soft"? Should the explainer sound "authoritative" or "friendly"? The problem isn't a shortage of choices — modern libraries hold 300+ voices, and you can audition them for an hour without landing on one. The problem is voice descriptors: the precise vocabulary you need to tell one voice apart from another and match it to your content with intent. Without that vocabulary, voice selection turns into guesswork and dubbing becomes expensive trial-and-error. According to WP SEO AI, single-word labels like "natural" or "engaging" are too vague to be actionable — a clear vocal portrait requires specifying multiple interacting dimensions at once. By the end of this article, you will be able to describe any voice with precision across tone, pitch, and style, so you can search, filter, and prompt voice tools — or brief a cloning project — with confidence instead of luck.

Table of Contents
- The Four Dimensions Every Voice Descriptor Falls Under
- Tone Descriptors Decoded — From "Warm" to "Authoritative"
- Pitch and Pace — The Technical Descriptors People Get Wrong
- Style and Register — Matching Voice to the Content Context
- Stacking Descriptors Into a Precise Voice Search or Prompt
- Descriptor Pitfalls — Where Voice Selection Quietly Breaks
- Your Copy-Paste Voice Descriptor Briefing Template
- Voice Descriptor Questions Creators Actually Ask
The Four Dimensions Every Voice Descriptor Falls Under
Every voice descriptor you have ever read — no matter how poetic — collapses into four measurable dimensions. Once you can name them, the vocabulary stops feeling subjective and starts behaving like a set of controls you can adjust independently.
Tone is the emotional color or attitude of the voice. Warm, cold, enthusiastic, distant — this is the emotional character a listener feels before they process a single word's meaning. It's the dimension that decides whether your audience leans in or tunes out.
Pitch is the perceived highness or lowness of the sound. A deep, resonant baritone sits at one end; a bright, light, youthful sound sits at the other. Pitch is fundamentally a frequency property, which makes it one of the most objective descriptors of the four — yet it's also one of the most frequently confused with pace.
Pace and rhythm describe the speed of speech and its cadence. Rapid, measured, leisurely, deliberate — pace includes the pauses between phrases and the inflection patterns that ride on top of them. Two voices reading identical scripts at different paces can feel like entirely different performances.
Style and register govern the performance context and formality. Narration, conversational, broadcast, e-learning — formal versus casual. This is the dimension that decides what role the voice is playing for the listener.
This taxonomy isn't a personal opinion. Nielsen Norman Group formalizes tone along four independent axes — formal vs. casual, serious vs. funny, respectful vs. irreverent, and matter-of-fact vs. enthusiastic — demonstrating that tone is multi-axis, not a single slider you drag from "boring" to "fun." Commercial platforms operationalize the same logic. The voice marketplace Voices.com groups vocal description into four qualities: pitch and tone, volume and projection, articulation and enunciation, and rate and inflection. Different labels, same underlying structure.

Why does separating the dimensions matter so much? Communication coach Robin Kermode frames tone, pitch, and pace as the three levers that together create "vocal variety" — defining tone as emotional character, pitch as the perceived frequency that can alter emotional meaning, and pace as the speed of delivery. Style and register form the fourth lever, and it sits over the other three, governing the context in which they operate. Put simply: tone, pitch, and pace describe how the voice sounds; style and register describe what role it's playing.
Every voice descriptor you have ever read collapses into four levers — tone, pitch, pace, and style. Master the levers and you stop guessing.
Hold onto this model. Every section that follows drills into exactly one of these four dimensions, and none of them will re-define the framework. When you encounter a descriptor anywhere — a marketplace filter, an AI prompt field, an agency brief — your first job is to slot it into one of the four buckets. That single habit converts a wall of adjectives into an organized control panel.
Tone Descriptors Decoded — From "Warm" to "Authoritative"
Tone is the dimension audiences register first, and it's the one most commonly mis-briefed because it leans on subjective adjectives. Nielsen Norman Group's research shows tone operates across multiple independent axes — humor, formality, respectfulness, and enthusiasm are separate levers — which means a single tone word rarely captures what you actually want. Cluster your tone descriptors instead, and you get both precision and a practical way to filter.
Trust-building (warm, friendly, reassuring). This cluster builds emotional safety before meaning lands. It's the right call for healthcare explainers, customer-support IVR, and onboarding videos where a listener needs to feel held before they absorb instructions. WP SEO AI lists "warm" among the most-used emotional tone adjectives, and for good reason — it's the baseline most audiences default to trusting.
Energetic (upbeat, enthusiastic, lively). This cluster signals momentum and excitement. It's best for product launches, ad reads, and social shorts where the first two seconds decide whether someone keeps watching. NN/g's "enthusiastic" axis maps directly here — and notice it's independent of formality, so you can be energetic and professional at the same time.
Serious (authoritative, professional, somber). This cluster conveys credibility and weight. Reach for it in corporate training, financial explainers, and documentary narration where the audience needs to trust that the speaker knows more than they do. "Authoritative" is a flagship descriptor in WP SEO AI's vocal-portrait list — it's specific enough to filter on and broad enough to apply across formats.
Intimate (soft, soothing, conversational). This cluster creates closeness and calm. It's built for meditation apps, podcast intros, and ASMR-style content where the listener is often alone and the voice feels like it's speaking directly to them. The intimacy comes as much from restraint as from warmth — this cluster pulls back rather than projects.
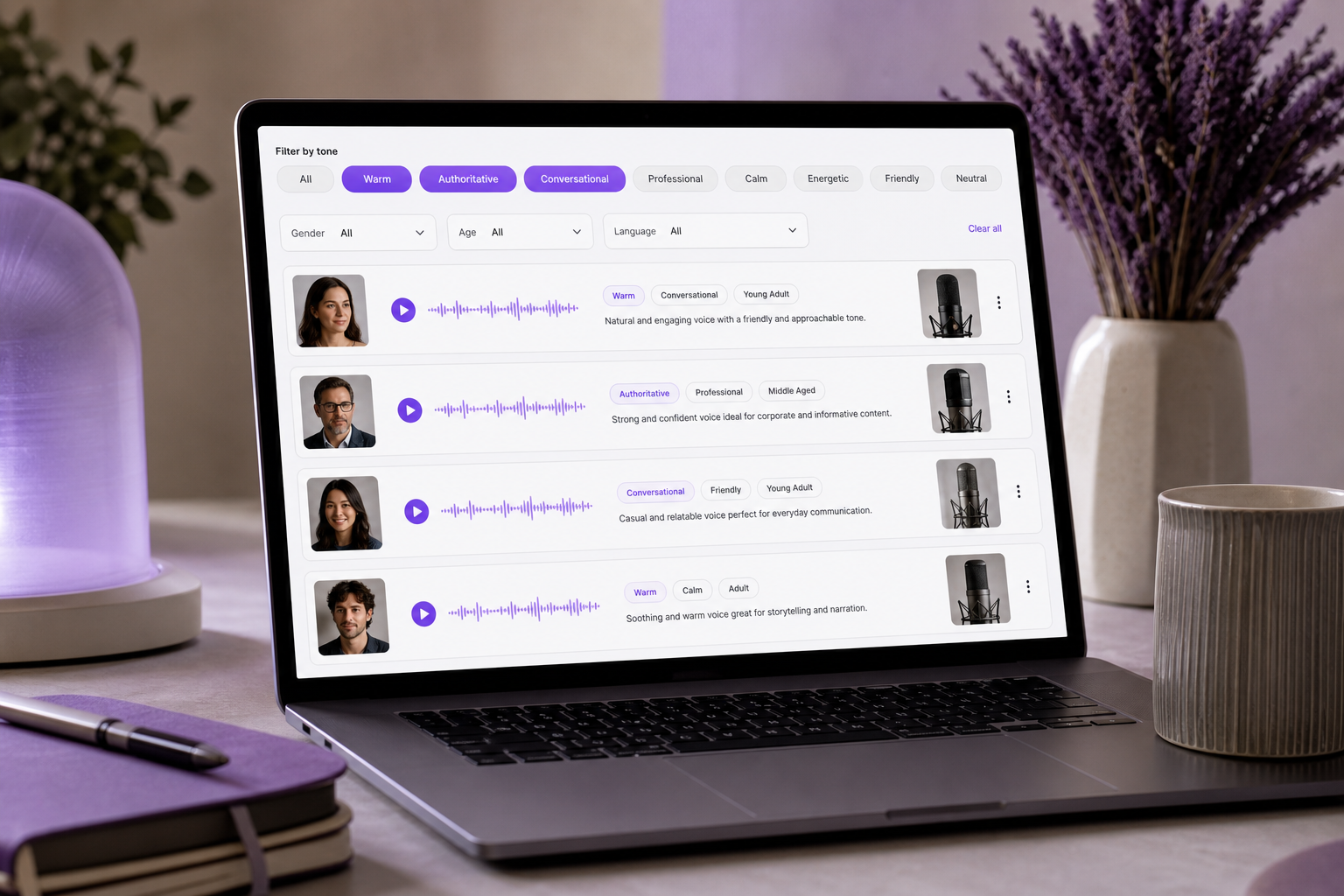
Tone is the single dimension audiences notice first and forget last — it sets emotional trust before a single word's meaning lands.
These clusters aren't just a mental model — they're how modern tools let you search. A TTS platform like SymTrain documents filtering voices by tone such as "articulate, casual, anxious," narrowing a large library before you ever hit preview. That's the practical payoff of clustering your voice descriptors: the same way a Text to Speech library lets you filter by tone before previewing, a clear tone cluster turns an hour of auditioning into a focused shortlist of three.
Pitch and Pace — The Technical Descriptors People Get Wrong
Pitch and pace are the two most-confused dimensions in any voice brief, and the confusion costs creators real time. Pitch is frequency — the perceived highness or lowness of a voice. Pace is speed and rhythm — words per minute, cadence, and the placement of pauses. Robin Kermode's three-way split keeps them clean: tone is emotional character, pitch is perceived frequency, pace is speed of speech. Three separate things.
The classic error is swapping the vocabulary. Creators say "fast" when they mean "high-pitched," or "deep" when they mean "slow." These are independent controls. A deep voice can be brisk. A high voice can be measured. Treating them as one blurred adjective is how briefs go wrong before anyone records a syllable.
| Descriptor | What It Controls | Sounds Like | Best For |
|---|---|---|---|
| Deep | Pitch (low frequency) | Baritone, resonant | Documentary, luxury brand |
| Bright | Pitch (high frequency) | Light, airy, youthful | Kids' content, upbeat ads |
| Measured | Pace (slow/even) | Deliberate, spacious | E-learning, tutorials |
| Brisk | Pace (fast) | Energetic, urgent | News, promos |
| Clipped | Pace + articulation | Crisp, precise stops | Technical, instructional |
| Drawling | Pace (slow/relaxed) | Stretched, casual | Storytelling, character |
The interesting work happens when pitch and pace combine, because the compound impression is almost always stronger than either descriptor alone. Deep pitch with a brisk pace reads as confident urgency — the voice of someone who knows the material and isn't wasting your time. Bright pitch with a measured pace reads as friendly patience — ideal when you're walking a nervous user through a first setup. Swap the combinations and the meaning flips entirely, which is exactly why you can't collapse the two fields into one.
This separation is baked into how serious platforms structure their guidance. Voices.com treats pitch/tone and rate/inflection as two of its four distinct qualities, never as a single setting. The Hamsa API documentation similarly lists speaking pace and pronunciation/clarity as separate selection criteria, each evaluated on its own before a voice goes into production. The practitioner takeaway is direct: in any brief, give pitch and pace their own fields. Write "deep pitch, brisk pace," not "a punchy deep voice" and hope the reader untangles it. And remember the same pitch and pace traits you specify here are what a Voice cloning model preserves from a source sample — so getting the vocabulary right at the brief stage carries all the way through to the cloned output.
Style and Register — Matching Voice to the Content Context
The highest-leverage skill in voice selection isn't picking the most impressive voice. It's choosing the right style and register for the delivery context — the voice your audience expects and never questions. PatternFly's design-system guidance separates style (grammar and syntax choices), voice (brand personality), and tone (the user's emotional state), and the spoken-voice parallel maps cleanly: style and register on one side, emotional tone on the other. Get the register wrong and even a beautiful voice feels off.
Hamsa's documentation makes the style distinction concrete with explicit use-case rationale. "Conversational" is natural and friendly — best for customer service and support. "Narrator" is clear and articulate — suited to explanations. That "sounds like / best for" framing is exactly what turns style into a decision you can make in seconds instead of debating for an afternoon.
| Content Type | Recommended Style Descriptor | Why It Works |
|---|---|---|
| YouTube explainer | Conversational | Natural, friendly — keeps casual viewers engaged |
| Corporate training | Narrator | Clear, articulate — suited to explanations |
| Podcast intro | Conversational / broadcast | Sets warm, familiar host presence |
| Audiobook | Narrator | Sustained clarity over long-form listening |
| Ad / promo | Energetic broadcast | Projects momentum and a call to action |
Underneath style sits register — the formal-versus-casual choice that flavors everything above it. NN/g's formal↔casual axis is the cleanest way to think about it: the same conversational style can read as a polished broadcast host or a friend talking across a table, depending on where you set the register dial. A corporate training narrator at a casual register feels approachable; the same narrator at a formal register feels institutional. Neither is wrong — they're answers to different briefs.
Two further layers stack on top. Accent and dialect are core selection criteria in Hamsa's checklist, and they carry cultural weight that no tone descriptor can override — a "neutral US" voice and a "British RP" voice can share identical tone, pitch, and pace and still land completely differently with an audience. SymTrain recommends age-group filters — young, adult, older — alongside tone, because perceived age shifts how authoritative or relatable a voice feels.
The right style descriptor isn't the most impressive voice — it's the one your audience expects to hear in that moment and never questions.
PatternFly's sharpest point is that style and tone must respond to the audience's emotional state, not a brand-wide default. Troubleshooting content needs a neutral, helpful register; an announcement needs an enthusiastic one. The context dictates the register every time. And register decisions don't stay put when your content travels — a casual, conversational register that lands perfectly in English can read as flippant or unprofessional in another market. That's a register choice that has to hold up when you push the content through AI Dubbing into other languages, which is exactly where the next layer of discipline pays off.
Stacking Descriptors Into a Precise Voice Search or Prompt
Vocabulary only matters if you can turn it into a repeatable method. The research is consistent on the core principle: stacked descriptors beat single labels every time. WP SEO AI recommends combining emotional tone adjectives like "warm," "crisp," or "authoritative" with concrete details on pace, pitch variation, resonance, and clarity to build a clear vocal portrait. Voices.com formalizes a three-step pipeline — define the character (age, gender, style), set the tone, then choose fitting keywords. Here's that logic broken into seven steps you can run every time.
- Define the emotional goal. Name the feeling the audience should walk away with — trust, excitement, calm. Everything downstream serves this single decision.
- Pick one tone cluster. Choose from the four clusters: trust-building, energetic, serious, or intimate. Resist the urge to mix conflicting clusters — that's where briefs unravel.
- Set the pitch range. Deep, mid, or bright. One word, not a paragraph.
- Set the pace. Measured, brisk, or clipped. Keep it separate from pitch.
- Lock style and register. Conversational, narrator, or broadcast — then formal or casual.
- Layer demographics and accent. Add age group and dialect, the way SymTrain and Hamsa filters expect.
- Test against 2–3 samples. Hamsa's checklist — pronunciation, clarity, pace, tone, accent — is your final validation gate before anything ships.

Here's what the finished stack looks like as a single string: warm + mid-pitch + measured pace + conversational style + female + 30s + neutral US accent. That one line does double duty. Drop it into a search bar and it slashes your filtering time across a 300+ voice library down to a handful of candidates. Feed the same stacked string into a TTS preset and it becomes a generation prompt. The discipline of writing it once is what saves you from re-auditioning the entire catalog. And because the format is consistent, the same stacked string you'd feed a TTS preset can pass straight to a Voice Cloning API call — one brief, multiple destinations, zero re-translation between tools.
Descriptor Pitfalls — Where Voice Selection Quietly Breaks
Most voice projects don't fail at the recording stage. They fail at the brief, in ways that are invisible until you're listening to a finished file that's somehow wrong. These are the failure modes that don't show up until it's expensive to fix.
Overstacking contradictory descriptors. "Energetic but soothing" cancels itself — the voice can't sprint and whisper at the same time. NN/g's research is useful here: humor, respect, and enthusiasm are independent levers, so many combinations work fine, but some genuinely conflict. The fix is to pick one dominant tone cluster and refine within it rather than reaching across clusters for variety you don't need.
Treating "natural" as a direction. "Natural" and "engaging" feel like instructions, but they're not actionable. WP SEO AI argues that such catch-alls fail for AI tools and remote talent alike because they don't specify any of the interacting dimensions. The fix is to replace every catch-all with the four-dimension stack — tone, pitch, pace, style — plus demographics. If a descriptor doesn't slot into one of those buckets, it isn't a direction.
Assuming descriptors translate across languages. Perceived tone shifts when you dub into another language and culture — a register that reads as warm in English can land as overly familiar elsewhere. The fix is to re-validate tone per target language rather than trusting the source descriptor to carry over. When you're dubbing into 33 target languages, per-language tone checks aren't optional polish; they're the difference between content that connects and content that subtly alienates. This is why teams running content through an AI Dubbing API re-check tone per target language instead of assuming the original brief still holds.
Ignoring the audience's emotional context. PatternFly warns that one-size-fits-all tone misfires — a troubleshooting flow needs a neutral, helpful voice, while an announcement needs an enthusiastic one. The fix is to pick descriptors for the moment your audience is in, not the brand-wide default you set six months ago.
Skipping the brief and trusting intuition. Ed Gandia's tone-guide approach critiques vague directives by demanding concrete parameters — audience, tone specifics like "warm but not chatty," formality, sentence length, and recurring patterns. The fix is the simplest of all: write the stacked brief before you preview a single voice. Intuition is fine for picking between two finalists. It's terrible for narrowing 300 down to 3.

"Natural" describes nothing — it's the default expectation, not a creative direction.
Your Copy-Paste Voice Descriptor Briefing Template
Here's the operational version of everything above — a fill-in-the-blank structure you can paste into any voice tool, agency brief, or cloning request. It's the four-dimension model plus demographics, formatted so you never have to rebuild it from scratch. Treat it as the single source of truth for a project's voice descriptors.
VOICE DESCRIPTOR BRIEF
----------------------------------------
Emotional goal: ____ (what the audience should feel)
Tone cluster: ____ (trust-building / energetic / serious / intimate)
Pitch: ____ (deep / mid / bright)
Pace: ____ (measured / brisk / clipped)
Style / register: ____ (conversational / narrator / broadcast; formal / casual)
Demographics: ____ (gender, age group)
Accent / language: ____ (dialect + target languages)
Reference voice: ____ (optional — a known voice to anchor expectations)
This structure isn't arbitrary. It mirrors Ed Gandia's concise 3–5 sentence voice summary paired with specific tone, formality, and rhythm parameters, and it follows Voices.com's character → tone → keyword pipeline in the order you actually make the decisions. Fill it top to bottom and each field narrows the next.
Here's the template filled in for a real scenario — The Multilingual YouTube Channel Intro:
- Emotional goal: confident welcome
- Tone cluster: trust-building / warm
- Pitch: mid
- Pace: brisk
- Style / register: conversational broadcast
- Demographics: female, 30s
- Accent / language: neutral US English, dubbed into Spanish + Portuguese
- Reference voice: none
That single voice brief does three jobs without modification. It narrows your library search to a shortlist. It becomes the prompt that drives TTS generation. And it carries into the dubbing step, where the same descriptors get re-validated per target language rather than rebuilt from scratch. One brief, three outputs, no re-briefing.
The practical advantage of this approach shows up when your tools live in one place. When Text to Speech, voice cloning, and dubbing share a workflow, the same descriptor brief that drives a preview can pass straight into a Text to Speech API request — and then onward to dubbing — instead of being re-typed and re-interpreted at every stage. Write the brief once. Use it everywhere.
Voice Descriptor Questions Creators Actually Ask
What's the difference between tone and timbre in voice descriptors?
Tone is the emotional character of a voice — warm, serious, distant. Timbre is the unique texture or quality of the sound itself — smooth, gravelly, silky, harsh. WP SEO AI lists texture as a separate descriptor dimension from emotional tone, and the distinction matters in practice: two voices can share the exact same tone and still have completely different timbres. When a voice feels right emotionally but somehow wrong, timbre is usually the variable you haven't named yet.
Do voice descriptors translate accurately when dubbing into other languages?
Not automatically. Perceived tone can shift across languages and cultures, so the warm, casual register that works in English may land differently in another market. The reliable move is to re-validate the descriptor per target language rather than assuming it carries over. With dubbing into 33 target languages available, building a per-language tone check into your workflow isn't extra work — it's what keeps a single brief honest across every market you publish in.
How many descriptors should I use when prompting an AI voice or cloning tool?
Aim for the four core dimensions plus demographics — roughly 5–7 stacked descriptors. WP SEO AI shows that stacked descriptors outperform single labels, and Voices.com's pipeline confirms character plus tone plus keywords as the working minimum. Stay in that range. Fewer than five and you're back to vague catch-alls; more than seven and you start risking contradictions that cancel each other out.
Can I describe a voice by referencing a known or celebrity voice instead of using descriptors?
A reference voice is a useful anchor — it's why "reference voice" is an optional field in the briefing template. But it doesn't replace descriptors. A reference tells a tool or a human roughly where to start; tone, pitch, pace, and style tell them where to land. Pairing a reference with explicit descriptors gives the most reliable result, because the descriptors resolve the ambiguity the reference leaves open.