")
Điểm quan trọng:
- Tại sao nó quan trọng: Chất lượng dịch ảnh hưởng đến sự tin tưởng, tuân thủ và doanh thu. Ngành như y tế (độ chính xác 99.9%) và pháp lý (độ chính xác 98%) yêu cầu độ chính xác cao.
-
Mục tiêu chính của kiểm tra:
- Độ chính xác ngữ nghĩa: Công cụ như COMET đồng bộ với đánh giá của con người 89% thời gian.
- Tính nhất quán thuật ngữ: Lĩnh vực pháp lý yêu cầu độ nhất quán thuật ngữ 99.5%.
- Thích nghi văn hóa: Nội dung được tuỳ chỉnh có thể tăng sự giữ chân người dùng lên 34%.
-
Chỉ số và công cụ:
- Truyền thống: BLEU, TER, ROUGE (ví dụ: BLEU ≥0.4 để sử dụng).
- Nâng cao: COMET (0.81 tương quan với điểm của con người) và MQM cho phân loại lỗi chi tiết.
-
Thách thức:
- Lỗi ngữ cảnh, ngôn ngữ ít tài nguyên và dữ liệu huấn luyện lỗi thời.
- Ví dụ: Thêm dữ liệu mạng xã hội cải thiện độ chính xác dịch tiếng Kurd lên 45%.
-
Giải pháp:
- Hệ thống học tập tích cực giảm lỗi bằng cách gắn cờ các đầu ra có độ tin cậy thấp.
- Kết hợp công cụ AI với giám sát của con người cải thiện tỷ lệ phát hiện lỗi lên 91%.
So sánh nhanh các chỉ số:
| Chỉ số | Khu vực tập trung | Trường hợp sử dụng & ngưỡng |
|---|---|---|
| BLEU | Độ chính xác N-gram | Kiểm tra nhanh, điểm số ≥0.4 |
| TER | Khoảng cách chỉnh sửa | Chuyên nghiệp, <9% pref |
| ROUGE | Đo lường hồi tưởng | Xác thực nội dung, 0.3-0.5 |
| COMET | Đánh giá ngữ nghĩa | Tương quan mạnh (0.81) |
| MQM | Phân loại lỗi | Chi tiết cấp doanh nghiệp |
Hướng dẫn này giải thích cách các doanh nghiệp có thể kết hợp tự động hóa và chuyên môn của con người để đạt được dịch thuật mở rộng quy mô, chính xác và phù hợp văn hóa.
Chỉ số đo lường chất lượng
Các công cụ hiện đại kết hợp tự động hóa với chuyên môn của con người để cung cấp các bản dịch chính xác và nhận biết ngữ cảnh. Những chỉ số này được thiết kế để đáp ứng các mục tiêu chính như độ chính xác ngữ nghĩa, tính nhất quán thuật ngữ và thích nghi với yếu tố văn hóa.
Chỉ số cơ bản: BLEU, TER, ROUGE
Ba chỉ số cốt lõi hình thành nền tảng của thử nghiệm chất lượng dịch thuật:
| Chỉ số | Khu vực tập trung | Trường hợp sử dụng & ngưỡng |
|---|---|---|
| BLEU | Độ chính xác N-gram | Kiểm tra nhanh, điểm số ≥0.4 sử dụng được |
| TER | Khoảng cách chỉnh sửa | Chuyên nghiệp, <9% ưa thích |
| ROUGE | Đo lường hồi tưởng | Xác thực nội dung, phạm vi 0.3-0.5 |
Bản dịch có điểm số trên 0.6 trên BLEU thường vượt trung bình chất lượng của con người. Tuy nhiên, một nghiên cứu năm 2023 đã nêu bật những hạn chế của BLEU: BLEU tham chiếu đơn có tương quan yếu với đánh giá của con người (r=0.32), trong khi các thiết lập tham chiếu đa có hiệu suất tốt hơn (r=0.68).
Chỉ số mới: COMET và MQM
Các khung phát triển mới hơn giải quyết các khoảng trống trong các chỉ số truyền thống. COMET, dựa trên mạng lưới neural, đánh giá ngữ nghĩa và đạt tương quan mạnh 0.81 với điểm của con người trong các điểm chuẩn WMT2022 - tốt hơn nhiều so với tương quan 0.45 của BLEU.
MQM chia các lỗi thành các loại như độ chính xác, lưu loát, và thuật ngữ, gán trọng số mức độ nghiêm trọng. Cách tiếp cận chi tiết này đặc biệt hữu ích cho các bản dịch cấp doanh nghiệp.
Kiểm tra Máy so với Nhân
Một cách tiếp cận cân bằng kết hợp đánh giá của máy và con người là thiết yếu. Các hãng công nghiệp hàng đầu đã áp dụng các quy trình làm việc như sau:
"Lọc TER ban đầu → Đánh giá ngữ nghĩa COMET → Biên tập sau của con người cho điểm COMET <0.8 → Đánh giá cuối cùng của khách hàng. Quá trình này giảm chi phí đánh giá xuống 40% trong khi duy trì tuân thủ chất lượng 98%."
Đối với nội dung chuyên biệt cao, sự tham gia của con người là không thể thiếu. Các chỉ số đang phát triển hiện tập trung vào các yếu tố như tính nhất quán ngữ cảnh và việc duy trì cảm xúc âm sắc, mở ra con đường cho việc đối mặt với những thách thức thực tế. Những tiến bộ này sẽ được thảo luận thêm trong phần tiếp theo về Vấn đề dịch thuật phổ biến.
Vấn đề dịch thuật phổ biến
Dữ liệu ngành chỉ ra ba thách thức lớn thường phát sinh:
Ngữ cảnh và ý nghĩa
Một chuỗi 38% các bản dịch được đánh giá với các chỉ số BLEU cơ bản cần sự can thiệp của con người khi xử lý các cụm từ thành ngữ. Vấn đề này đặc biệt nổi bật trong môi trường chuyên nghiệp.
"Một bản dịch sai hợp đồng EU về 'chịu trách nhiệm liên đới và riêng lẻ' gây ra tổn thất 2.8 triệu € do dữ liệu huấn luyện pháp lý không đầy đủ. Phân tích sau sự cố cho thấy việc thêm 15k tài liệu pháp lý có chứng nhận đã giảm những lỗi tương tự lên tới 78%"
Các công cụ như phân tích ngữ cảnh video của DubSmart đã đạt độ chính xác ngữ cảnh 92% bằng cách đồng bộ hóa đối tượng hình ảnh với đối thoại được dịch. Cách tiếp cận này đã giảm đáng kể lỗi dịch sai giới tính lên đến 63%, nhờ vào việc sử dụng nhận dạng đối tượng cảnh.
Ngôn ngữ ít phổ biến hơn
Ngôn ngữ có ít tài nguyên kỹ thuật số phải đối mặt với những thách thức đặc biệt về chất lượng dịch thuật. Đây là sự phân tích về cách tài nguyên ảnh hưởng đến hiệu suất:
| Mức tài nguyên | Ảnh hưởng đến chất lượng | Hiệu quả giải pháp |
|---|---|---|
| Ngôn ngữ có tài nguyên cao | Hiệu suất cơ sở | Kiểm tra tiêu chuẩn đủ |
| Ngôn ngữ có tài nguyên trung bình | Giảm chất lượng 15% | Dịch ngược giúp ích |
| Ngôn ngữ có tài nguyên thấp | Điểm TER cao hơn 22% | Cần học chuyển giao |
Một nghiên cứu điển hình bằng ngôn ngữ Kurd cho thấy việc thêm dữ liệu mạng xã hội đã cải thiện độ chính xác lên 45%. Bên cạnh đó, học chuyển giao từ các họ ngôn ngữ liên quan đã cho thấy có thể cắt giảm dữ liệu huấn luyện cần thiết xuống 30%.
Chất lượng dữ liệu huấn luyện
Chất lượng của dữ liệu huấn luyện đóng một vai trò quan trọng trong độ chính xác dịch thuật, đặc biệt trong các lĩnh vực chuyên biệt. Một nghiên cứu năm 2024 nhận thấy rằng 68% lỗi dịch thuật y tế phát sinh từ một xu hướng thiên về thuật ngữ y học phương Tây trong các tập dữ liệu huấn luyện. Sự mất cân bằng này là rõ rệt, với tỷ lệ 5:1 thiên về thuật ngữ phương Tây so với các khái niệm y học truyền thống.
Việc dịch kỹ thuật cũng gặp những thách thức gắn liền với dữ liệu lỗi thời:
"Các thuật ngữ kỹ thuật lâu hơn 3 năm cho thấy tỷ lệ lỗi cao hơn 22%. Một dự án dịch thuật hướng dẫn sử dụng chip bán dẫn yêu cầu cập nhật hàng tháng để duy trì <2% lỗi thuật ngữ"
Các hệ thống học tập tích cực xác định các thuật ngữ lỗi thời đã chứng minh hiệu quả, giảm khối lượng công việc chỉnh sửa lên tới 37%, đặc biệt trong các lĩnh vực kỹ thuật.
Những thách thức này nhấn mạnh tầm quan trọng của các phương pháp kiểm tra thực tế được đề cập trong phần tiếp theo để đảm bảo chất lượng dịch thuật luôn cao.
Kiểm tra trong thực tế
Các phương pháp kiểm tra thực tế giải quyết thách thức của dữ liệu huấn luyện và ngữ cảnh thông qua một số chiến lược tập trung:
DubSmart Dịch Video
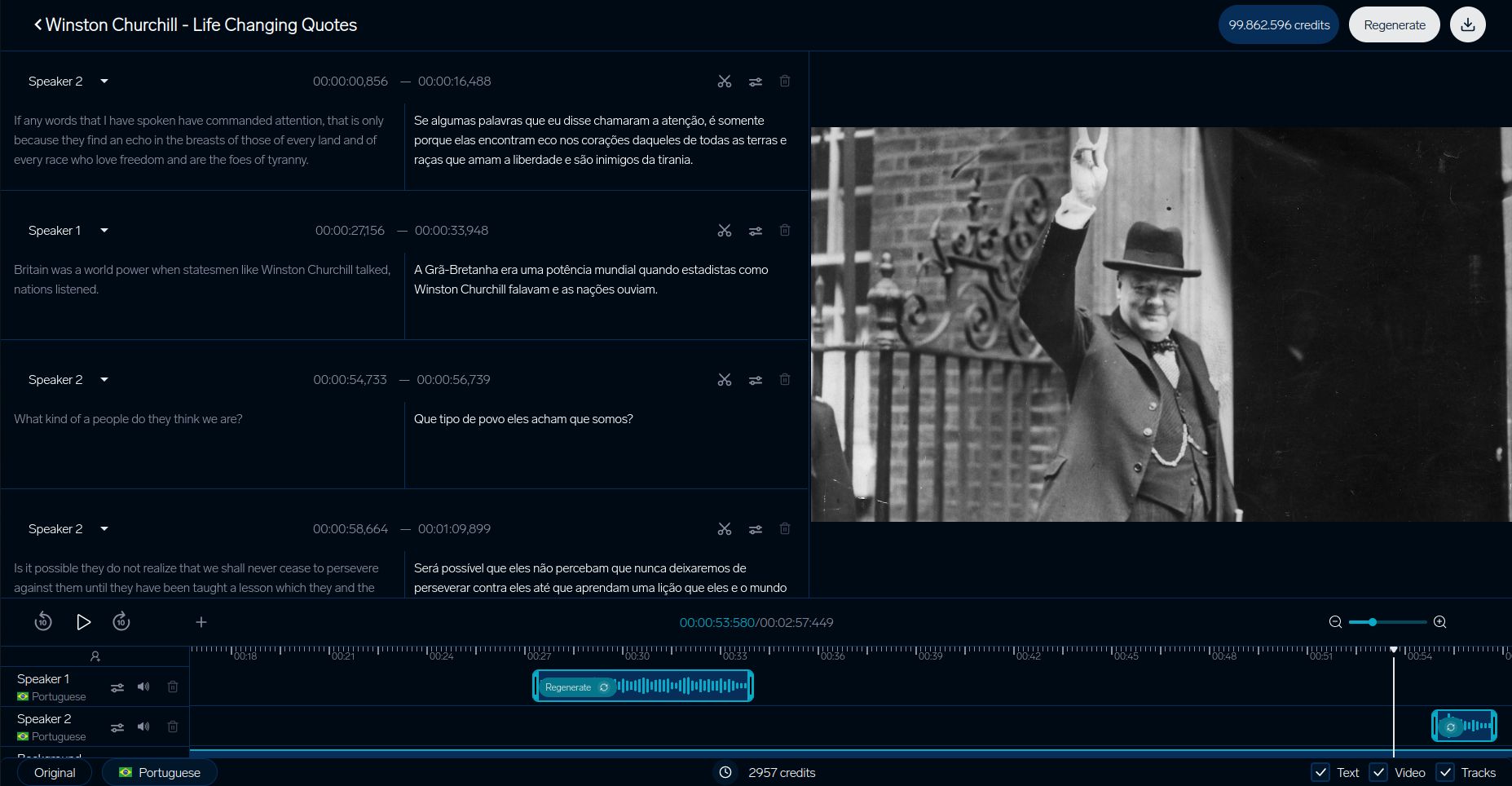
Hệ thống kiểm tra của DubSmart làm nổi bật cách các nền tảng dịch video đảm bảo chất lượng. Quá trình chi tiết của họ tập trung vào việc đồng bộ hóa ngữ cảnh hình ảnh, đặc biệt giải quyết các vấn đề dịch sai giới mà chúng ta đã thảo luận trước đó:
| Thành phần | Chỉ số |
|---|---|
| Khớp với môi | Chậm hơn ít hơn 200ms |
| Khớp giọng | Tương đồng 93% |
| Đồng bộ hình ảnh | Kém khớp ít hơn 5% |
Các nghiên cứu điển hình doanh nghiệp
Các công ty lớn đã tạo ra các hệ thống kiểm tra tiên tiến kết hợp các công cụ AI với chuyên môn của con người. Việc SAP sử dụng khung MQM-DQF là một ví dụ nổi bật:
"Bằng cách kết hợp đầu ra MT của mạng neural với đội ngũ xác nhận ngôn ngữ, SAP đã đạt được giảm 40% nỗ lực biên tập sau trong khi duy trì tỷ lệ chính xác 98%".
IKEA đã tối ưu hóa quy trình địa phương hóa danh mục của mình, giảm thời gian ra thị trường đến 35% thông qua việc kết hợp giám sát nhân và AI.
Booking.com cũng chứng minh sự mạnh mẽ của thử nghiệm tự động hóa. Hệ thống của họ quản lý hơn 1 tỷ bản dịch mỗi năm trên 45 ngôn ngữ, giảm chi phí đến 40% trong khi giữ chất lượng ổn định cho nội dung do người dùng tạo ra.
Những ví dụ này nêu bật cách các doanh nghiệp đang cải thiện độ chính xác, hiệu suất và quy mô của quá trình thử nghiệm dịch thuật.
sbb-itb-f4517a0
Các bước tiếp theo trong kiểm tra dịch thuật
Khi các phương pháp kiểm tra cải tiến, ba lĩnh vực chính đang đẩy tiêu chuẩn chất lượng lên những cấp độ mới:
Chuyển giao tông giọng và cảm xúc
Các hệ thống hiện đại hiện nay tốt hơn trong việc duy trì sắc thái cảm xúc nhờ vào khung EMO-BLEU, có tương quan Pearson 0.73 với nhận thức của con người so với BLEU là 0.41. Các mô hình biến thể đa phương tiện đã phát triển đáng kể, giữ nguyên cảm xúc của người nói. Các hệ thống này có thể duy trì sự thay đổi cường độ trong phạm vi ±2dB giữa các ngôn ngữ trong khi quản lý các dấu hiệu cảm xúc phức tạp.
Dịch dựa trên ngữ cảnh
Các hệ thống nhận biết ngữ cảnh đang tái định hình cách đánh giá chất lượng dịch thuật. Một ví dụ tuyệt vời là Chế độ Ngữ cảnh của DeepL, sử dụng theo dõi thực thể ở cấp tài liệu và điều chỉnh độ trang trọng theo thời gian thực.
Thử nghiệm cho các hệ thống này ngày càng tiên tiến, tập trung vào các chỉ số chính:
| Thành phần thử nghiệm | Điểm chuẩn hiện tại | Trọng tâm đo lường |
|---|---|---|
| Phản hồi từ ngữ đầu tiên | <900ms | Độ chính xác bắt đầu phát ngôn |
| Chất lượng truyền phát | <4 từ trễ | Tính nhất quán bộ nhớ đệm |
| Đồng bộ ngữ cảnh | >0.8 điểm | Thích ứng động |
Các hệ thống này xử lý hơn 100 triệu cặp câu ngữ cảnh, hoàn chỉnh với chú thích phân lớp.
Hệ thống AI học tập
Các hệ thống dịch thuật tự cải thiện đang thay đổi cách chất lượng được kiểm tra bằng cách tích hợp phản hồi liên tục. Khung của Orq.ai làm nổi bật sự chuyển dịch này, giảm chi phí chỉnh sửa hậu kỳ 37% mỗi quý thông qua:
"Kiến trúc học tập tích cực gắn cờ các đoạn có độ tin cậy thấp với điểm COMET dưới 0.6, trình bày các lựa chọn thay thế qua giao diện điển hình lỗi MQM và cập nhật trọng số mô hình mỗi hai tuần bằng các mẫu đã được xác nhận."
Các hệ thống này tự động xác định các bản dịch có độ tin cậy thấp (COMET <0.6) và cập nhật mô hình của họ mỗi hai tuần bằng các mẫu đã được chuyên gia ngôn ngữ xác nhận. Tuy nhiên, họ cũng đối mặt với các thách thức đạo đức. Nghiên cứu từ MIT cho thấy sự trôi dạt 22% về tính trung lập giới mà không có các biện pháp khử thiên lệch thích hợp. Vấn đề này liên quan đến vấn đề dữ liệu huấn luyện thiên lệch, nhấn mạnh sự cần thiết phải có các giao thức giám sát được cập nhật.
Các công cụ công nghiệp như TAUS Khung Chất lượng Động v3.1 giúp đảm bảo các hệ thống này đáp ứng các tiêu chuẩn đang thay đổi.
Tóm tắt
Phương pháp kiểm tra chính
Kỹ thuật kiểm tra hiện đại đã vượt qua sự phù hợp n-gram đơn giản và hiện nay tập trung vào phân tích ngữ cảnh. Các chỉ số truyền thống như BLEU, TER, và ROUGE vẫn cung cấp nền tảng cho các đánh giá cơ bản. Tuy nhiên, các phương pháp mới hơn như COMET và MQM đã chứng tỏ đồng bộ hơn với phán đoán của con người.
Ví dụ, khung EMO-BLEU đã cho thấy rằng các chỉ số tự động có thể đạt được tương quan 73% với phán đoán của con người khi đánh giá mức độ bảo quản nội dung cảm xúc. Hiện nay, kiểm tra chất lượng nhấn mạnh không chỉ có độ chính xác kỹ thuật mà còn có tầm quan trọng của việc đồng bộ với các sắc thái văn hóa, một mục tiêu chính cho các triển khai cấp doanh nghiệp.
Công cụ và tài nguyên
Thử nghiệm dịch thuật hiện đại thường sử dụng các nền tảng kết hợp nhiều phương pháp đánh giá. Một ví dụ là DubSmart, cung cấp một loạt các tính năng kiểm tra và hệ thống xác minh nội dung tiên tiến.
Các thành phần chính của kiểm tra hiệu quả bao gồm:
- Cổng chất lượng dựa trên COMET với ngưỡng dưới 0.6
- Thuật ngữ đã được xét duyệt về sự phù hợp văn hóa
- Hệ thống học tập tích cực cập nhật mỗi hai tuần
Đối với các lĩnh vực chuyên môn như y tế, pháp lý và nội dung kỹ thuật, thử nghiệm kết hợp các chỉ số tổng quát với các chỉ số chuyên ngành. Cách tiếp cận này đã dẫn đến cải thiện 22% chất lượng khi sử dụng hệ thống đánh giá kết hợp.
Câu hỏi thường gặp
Những nhược điểm của điểm BLEU là gì?
Điểm BLEU, dù được sử dụng rộng rãi, có những hạn chế đáng kể khi áp dụng cho đánh giá chất lượng dịch thuật. Dưới đây là những hạn chế chính của nó:
| Hạn chế | Ảnh hưởng đến đánh giá dịch thuật |
|---|---|
| Thiếu nhận thức ngữ nghĩa | Tập trung chỉ vào sự phù hợp từ, không quan tâm đến ngữ nghĩa hay ngữ cảnh |
| Hình phạt đa dạng cụm từ | Phạt các bản dịch hợp lệ sử dụng cách diễn đạt khác với văn bản tham chiếu |
Để giải quyết các vấn đề này, nhiều nền tảng địa phương hóa video sử dụng một loạt các phương pháp đánh giá. Ví dụ, công cụ phân tích ngữ cảnh của DubSmart kết hợp nhiều chỉ số để cung cấp đánh giá chính xác hơn.
"Trong khi BLEU cung cấp các phép đo cơ bản, thử nghiệm toàn diện đòi hỏi phân tích ngữ nghĩa và ngữ cảnh - đặc biệt đối với các bản dịch quan trọng cho doanh nghiệp."
Để có được độ chính xác tốt hơn, các chuyên gia khuyên dùng:
- COMET để đánh giá ý nghĩa và ngữ nghĩa
- Xác nhận của con người để hiểu rõ sắc thái văn hóa
- Công cụ đặc thù ngôn ngữ để xử lý các cấu trúc ngữ pháp phức tạp
Cách tiếp cận nhiều lớp này, như được sử dụng bởi DubSmart, kết hợp các công cụ tự động với những hiểu biết từ con người để đảm bảo các bản dịch đáp ứng cả các tiêu chuẩn kỹ thuật và ngữ cảnh.