
Bạn đã xuất một tệp nhật ký từ một hệ thống cũ và mở nó để tìm các dòng như 72 101 108 108 111 32 87 111 114 108 100 thay vì những từ có thể đọc được. Hoặc một nhà phát triển đã trao cho bạn một bản sao cấu hình đầy các cặp hex (48 65 6C 6C 6F) và nói với bạn "chỉ cần giải mã nó." Đó là lúc một trình tạo ASCII thành văn bản chứng minh giá trị của nó — nó lấy những mã số thô và biến đổi chúng trở lại thành các ký tự mà con người có thể đọc được.
Hướng dẫn này giải thích cách giải mã ASCII thực sự hoạt động, so sánh năm công cụ miễn phí cạnh nhau, hướng dẫn chuyển đổi từ hex sang văn bản, và cho biết khi nào ASCII không phải là mã hóa mà bạn nên nhắm tới.

Mục lục
- ASCII Mã hóa Thực sự Lưu trữ Cái gì (Và Tại sao Nó Xuất hiện dưới dạng Số)
- Cách một Trình tạo ASCII thành Văn bản Giải mã Mã Số Dưới Mui xe
- Năm Trình tạo ASCII thành Văn bản Miễn phí So sánh
- Hướng dẫn từng bước — Chuyển đổi Hex ASCII thành Văn bản Có thể Đọc
- Khắc phục sự cố Khi Chuyển đổi ASCII của Bạn Trả về Rác
- Tự động hóa Giải mã ASCII bằng Python, JavaScript và Bảng tính
- ASCII so với Unicode — Tại sao Quy trình "Chỉ ASCII" Yên tĩnh Phá vỡ Nội dung Hiện đại
- Danh sách Kiểm tra Trước chuyến bay — Xác nhận Giải mã ASCII là Sửa chữa Đúng Trước khi Bắt đầu
ASCII Mã hóa Thực sự Lưu trữ Cái gì (Và Tại sao Nó Xuất hiện dưới dạng Số)
ASCII là một mã hóa ký tự 7 bit với chính xác 128 điểm mã (0–127). Theo tài liệu tham khảo ASCII của Wikipedia, những 128 mã đó chia thành 95 ký tự có thể in được (khoảng trắng ở mã 32 đến dấu ngã ~ ở mã 126) và 33 ký tự điều khiển (mã 0–31 cộng với 127). Các ký tự điều khiển không phải là glyph hiển thị — chúng là các hướng dẫn chức năng như NUL (0), chuông (7), nguồn cấp dữ liệu dòng (10) và trả về carriage (13). Bộ in được bao gồm bảng chữ cái Latin tiếng Anh viết hoa và viết thường, mười chữ số, dấu chấm câu phổ biến và một số ký hiệu khác.
Mỗi mã ánh xạ đến chính xác một ký tự. 65 = 'A'. 97 = 'a'. 48 = '0'. 32 = khoảng trắng. 10 = nguồn cấp dữ liệu dòng. Những ánh xạ này được cố định bởi tiêu chuẩn ANSI X3.4 và chưa thay đổi kể từ năm 1968.
Các mã ASCII được lưu trữ trên 7 bit nhưng được truyền trong 8 byte với bit cao được đặt thành 0, theo nhà cung cấp đóng gói tài liệu tham khảo ASCII của dCode. Bit chưa sử dụng đó là lý do tại sao tồn tại rất nhiều lược đồ "ASCII mở rộng" — Latin-1, Windows-1252, các trang mã IBM — chúng tất cả đều yêu cầu mã 128–255 cho mục đích của riêng chúng, nhưng không ai trong số đó là ASCII.
Khi bạn thấy số thay vì chữ cái, bạn đang xem mã thô. Tệp hoặc luồng đầu ra được tuần tự hóa dưới dạng giá trị số — hex như 0x48, thập phân như 72, nhị phân như 01001000 hoặc bát phân như 110 — thay vì được hiển thị dưới dạng glyph. Một trình tạo ASCII thành văn bản đảo ngược quá trình tuần tự hóa đó. Nó không giải mã bất cứ điều gì. Nó không sửa chữa bất cứ điều gì. Nó chỉ tìm kiếm từng số trong cùng một bảng ánh xạ cố định.
Đây là phần mà hầu hết những người mới bắt đầu hiểu sai: ASCII không phải là "văn bản bị hỏng" — nó là văn bản chưa được hiển thị. Một bộ chuyển đổi không sửa chữa sự hỏng hóc. Nó diễn giải biểu diễn số theo một tiêu chuẩn đã biết.
Đây là hướng dẫn trong một dòng. Lấy 72 101 108 108 111. Tra cứu mỗi giá trị: 72='H', 101='e', 108='l', 108='l', 111='o'. Nối tiếp. Bạn nhận được "Hello." Đó là toàn bộ thuật toán.
Một phần bối cảnh hữu ích cho bất kỳ ai làm việc với mã hóa văn bản: Hiệp hội Unicode định nghĩa 128 điểm mã đầu tiên của nó (U+0000 đến U+007F) là giống hệt với ASCII. Đây không phải là tai nạn — nó là tính tương thích ngược cố ý. Bất kỳ tệp văn bản ASCII thuần túy nào cũng tự động là tệp UTF-8 hợp lệ. Không cần chuyển đổi. Đây là lý do tại sao vấn đề ASCII thành văn bản về cơ bản là một vấn đề kế thừa: bạn chỉ gặp phải nó khi có điều gì đó chọn tuần tự hóa văn bản thành các số trần thay vì byte tiêu chuẩn.
Những bản đổ nạp số này thực sự xuất hiện ở đâu? Xả hex từ xxd hoặc hexdump, chuỗi được mã hóa URL, thử thách CTF, nhật ký thiết bị nhúng, bắt gói (xuất khẩu Wireshark), trích xuất BLOB cơ sở dữ liệu, dấu vết giao thức mạng và tài liệu giáo dục. Ở bất kỳ nơi nào một nhà phát triển hoặc công cụ chọn để hiển thị byte dưới dạng số có thể đọc được thay vì cố gắng hiển thị chúng.

Cách một Trình tạo ASCII thành Văn bản Giải mã Mã Số Dưới Mui xe
Điều trông giống như "chuyển đổi" về mặt kỹ thuật là giải mã: công cụ đọc từng mã token, phân tích cú pháp nó theo một cơ số được khai báo (hex, thập phân, nhị phân, bát phân), ánh xạ nó thành một điểm mã và gọi một tìm kiếm ký tự. Trong JavaScript, tìm kiếm đó là String.fromCharCode(). Trong Python nó là chr(). Trong Excel nó là =CHAR(). Cùng hoạt động, ba cú pháp.
Việc triển khai quan trọng vì những tìm kiếm khác nhau có những giới hạn khác nhau. Theo nhà cung cấp đóng gói tài liệu công cụ chuyển đổi ASCII của CodeShack, công cụ của họ sử dụng String.fromCharCode() trên đơn vị mã UTF-16. Điều đó xử lý ASCII (0–127) và hầu hết Máy bay đa ngôn ngữ cơ bản Unicode (lên đến 0xFFFF) nhưng thất bại lặng lẽ trên các ký tự phụ lục phẳng yêu cầu các cặp thay thế — hầu hết emoji, chẳng hạn, sẽ không sống sót với cách tiếp cận này.
Nhiều công cụ web chấp nhận mã 0–255 (cái gọi là "ASCII mở rộng") mặc dù mã 128–255 không phải là một phần của tiêu chuẩn ASCII. Theo nhà cung cấp đóng gói tài liệu công cụ của Code Beautify, bộ chuyển đổi của họ hoạt động trong phạm vi 0–255. Những mã 128 trên đó được diễn giải bằng bất kỳ trang mã mặc định nào mà công cụ giả định — thường là Latin-1 hoặc Windows-1252 — đó là lý do tại sao dán 255 vào một công cụ sẽ cho ÿ trong khi dán nó vào một trình giải mã ASCII nghiêm ngặt sẽ ném một lỗi.
Cũng có vấn đề định dạng đầu vào. Hex (48 65 6C 6C 6F), thập phân (72 101 108 108 111), nhị phân (01001000 01100101 01101100 01101100 01101111) và bát phân (110 145 154 154 157) đều mã hóa cùng một từ: "Hello." Công cụ chỉ cần biết bạn đang trao cho nó cơ số nào.
| Phương pháp Giải mã | Đầu vào Được chấp nhận | Điều gì Xảy ra Bên trong | Giới hạn |
|---|---|---|---|
| Trình tạo ASCII web | Hex, thập phân, nhị phân, bát phân | JS String.fromCharCode() trên các mã token được phân tích cú pháp | Không có cặp thay thế; tin tưởng cơ số được khai báo |
Python bytes.fromhex().decode('ascii') | Chuỗi Hex | Đối tượng Bytes → mã hóa ASCII | Lỗi trên mã >127 mà không có errors='replace' |
Bảng tính =CHAR(code) | Một giá trị thập phân cho mỗi ô | Tìm kiếm điểm mã tích hợp | Một ô tại một thời điểm; không có phân tích cú pháp hàng loạt |
Dòng lệnh xxd -r -p | Luồng Hex | Đảo ngược xả hex thành byte thô | Kết quả byte; đường ống để xem terminal |
Mỗi phương pháp trên đều thực hiện cùng một hoạt động logic: mã token → điểm mã → glyph. Sự khác biệt là giao diện, kích thước lô và mức độ nghiêm ngặt mà mỗi người thực thi phạm vi ASCII. Một bộ tạo web tha thứ cho bạn vì các dấu phân cách lỏng lẻo; bytes.fromhex() của Python sẽ từ chối bất cứ điều gì không phải là một cặp chữ số hex sạch sẽ. =CHAR() của Excel xử lý một giá trị tại một thời điểm nhưng tồn tại trong một bảng tính nơi bạn đã có dữ liệu của mình. Cách tiếp cận dòng lệnh mở rộng đến gigabyte nhưng giả định bạn thoải mái trong một terminal.
Chọn nơi dữ liệu của bạn đã tồn tại, không phải công cụ nào trông đẹp nhất. Nếu bạn có một chuỗi hex trong một tab trình duyệt, hãy sử dụng một công cụ web. Nếu bạn có một cột CSV của mã, hãy sử dụng công thức bảng tính. Nếu bạn có một bản đổ hex 200 MB, hãy sử dụng Python hoặc xxd. Giới hạn ASCII nghiêm ngặt (mã > 127 lỗi) quan trọng nhất khi bạn kiểm toán xem dữ liệu của bạn có thực sự là ASCII hoặc chỉ là có nhãn là ASCII. Phiên bản nghiêm ngặt bảo bạn sự thật. Phiên bản tha thứ giả vờ mọi thứ đều ổn. Để biết thêm về mối quan hệ của UTF-8 với ASCII như một tập con byte đơn, hãy xem RFC 3629.
Một trình tạo ASCII thành văn bản không sửa chữa dữ liệu bị hỏng — nó diễn giải biểu diễn số. Nếu các số đến sai, các chữ cái sẽ ra sai.
Năm Trình tạo ASCII thành Văn bản Miễn phí So sánh (Cái Mỗi cái Làm Tốt nhất)
Năm công cụ, tất cả miễn phí, tất cả sống trong một trình duyệt. Mỗi cái có một kịch bản nơi nó đánh bại những cái khác.
Trình chuyển đổi ASCII CodeShack chấp nhận thập phân, hex, nhị phân và bát phân trong một giao diện duy nhất và sử dụng String.fromCharCode() dưới mui xe. Giao diện người dùng tiếp xúc cơ chế chuyển đổi, điều này làm cho nó là lựa chọn đúng cho các nhà phát triển muốn kiểm tra những gì đang xảy ra thay vì coi nó như một hộp đen. Nguồn: codeshack.io/ascii-to-text-converter.
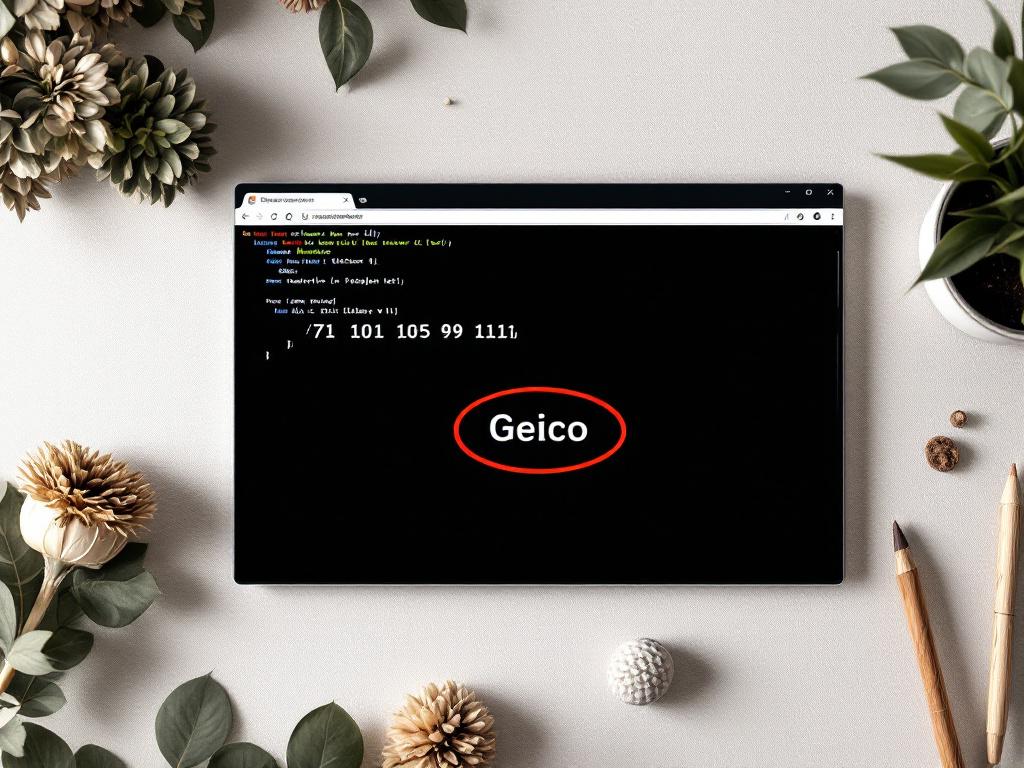
Code Beautify ASCII to Text chấp nhận mã số trong phạm vi 0–255, hỗ trợ tải lên URL và tệp, và trình bày chuyển đổi với dữ liệu mẫu — 71 101 105 99 111 → "Geico". Tải lên tệp là điều làm nó khác biệt: khi bản đổ hex của bạn là 50 MB, dán vào một hộp văn bản là không khả thi. Nguồn: codebeautify.org/ascii-to-text.
Browserling Text to ASCII chạy theo hướng ngược lại theo mặc định (văn bản → mã ASCII), điều này làm cho nó hữu ích để xác minh chuyến đi khứ hồi. Mã hóa một chuỗi đã biết, giải mã ở nơi khác, xác nhận bạn lấy lại bản gốc. Giao diện người dùng tối giản và tập trung vào nhà phát triển. Nguồn: browserling.com/tools/text-to-ascii.
Duplichecker ASCII to Text sử dụng một quy trình dán và nhấp hai bước và tạo bản tải xuống .txt. Tải xuống là những gì phân biệt — khi một đồng nghiệp không phải là kỹ thuật yêu cầu bạn "chuyển đổi cái này và gửi cho tôi tệp", Duplichecker là con đường ít ma sát nhất. Nguồn: duplichecker.com/ascii-to-text.php.
Utilities-Online ASCII to Text hiển thị kết quả nội tuyến mà không có bước tải xuống. Đó là công cụ nhanh nhất cho các tìm kiếm "mã 65 thực sự có nghĩa là gì" — về cơ bản là một sự thay thế kỹ thuật số cho bảng ASCII in được từng cuộc sống cạnh mỗi màn hình của lập trình viên. Nguồn: utilities-online.info/ascii-to-text.
| Công cụ | Hex | Thập phân | Nhị phân | Bát phân | Tải lên Tệp |
|---|---|---|---|---|---|
| CodeShack | Có | Có | Có | Có | Không |
| Code Beautify | Có | Có | Có | Có | Có |
| Browserling | Không | Có | Không | Không | Không |
| Duplichecker | Có | Có | Không | Không | Không |
| Utilities-Online | Có | Có | Không | Không | Không |
CodeShack thắng cho các nhà phát triển muốn tính linh hoạt định dạng trong một tab — hex sáng nay, nhị phân chiều tối nay, bát phân tuần tới, tất cả mà không cần chuyển đổi công cụ. Code Beautify thắng khi dữ liệu nguồn tồn tại dưới dạng tệp và bạn không muốn sao chép dán một megabyte vào textarea. Browserling thắng cho công việc xác minh: mã hóa theo một hướng, giải mã theo hướng khác, xác nhận tính toàn vẹn chuyến đi khứ hồi. Duplichecker thắng khi một phần cần thiết là bắt buộc và người nhận sẽ không chấp nhận "Tôi sẽ gửi cho bạn mã, chỉ cần giải mã chúng đi". Utilities-Online thắng cho tìm kiếm một lần — một giá trị duy nhất, câu trả lời ngay lập tức, không có lễ nghi.
Một lời cảnh báo quan trọng trước khi bạn dán bất cứ điều gì: không đặt dữ liệu nhạy cảm vào bất kỳ công cụ nào trong số này. Khóa API, PII của khách hàng, thông tin đăng nhập cơ sở dữ liệu, dữ liệu nhật ký nội bộ, bất cứ thứ gì được quy định theo HIPAA, GDPR hoặc PCI-DSS — không ai trong số đó thuộc về một công cụ trình duyệt của bên thứ ba. Tờ ghi đầu Bảo vệ Dữ liệu OWASP là rõ ràng về điều này: dữ liệu được gửi đến các dịch vụ bên ngoài là dữ liệu ngoài kiểm soát của bạn, bất kể tuyên bố chính sách bảo mật của nhà cung cấp nói gì. Vì bất cứ điều gì nhạy cảm, hãy sử dụng phương pháp Python trong Phần 6 — byte của bạn không bao giờ rời khỏi máy tính xách tay của bạn.
Hướng dẫn từng bước — Chuyển đổi Hex ASCII thành Văn bản Có thể Đọc
Chuỗi kiểm tra cho hướng dẫn này: 48 65 6C 6C 6F 20 57 6F 72 6C 64. Kết quả giải mã chính xác: "Hello World." Sử dụng đây làm đường cơ sở xác nhận của bạn — nếu bạn không nhận được "Hello World," có điều gì đó trong quy trình của bạn là sai.
- Xác định định dạng đầu vào. Nhìn vào dữ liệu. Chữ A–F trộn với chữ số? Đó là hex. Chỉ các chữ số, lên đến ~127? Thập phân. Chỉ 0 và 1 trong các khối 7 hoặc 8 ký tự? Nhị phân. Chữ số 0–7 chỉ, không có 8 hoặc 9? Bát phân. Đoán sai tạo ra mojibake — cơ số sai ánh xạ từng mã token đến một ký tự hoàn toàn khác. Nói với công cụ một cách rõ ràng cái nào bạn có.
- Chọn công cụ phù hợp từ phần so sánh ở trên. Vì ví dụ này, hãy sử dụng CodeShack — nó xử lý tất cả bốn cơ số trong một giao diện người dùng. Đối với các tệp lớn hơn ~ 1 MB, chuyển sang Python (được đề cập trong Phần 6). Để tìm kiếm giá trị duy nhất nhanh, Utilities-Online nhanh hơn.
- Dán đầu vào của bạn. Thả
48 65 6C 6C 6F 20 57 6F 72 6C 64vào trường đầu vào. Hãy chắc chắn rằng thả xuống định dạng được đặt thành "Hex." Xác nhận dấu phân cách mà công cụ mong đợi — hầu hết chấp nhận khoảng trắng, một số chấp nhận dấu phẩy, một vài yêu cầu không có dấu phân cách nào cả. - Bấm Chuyển đổi. Đầu ra phải đọc "Hello World." Nếu nó không được, những nguyên nhân phổ biến nhất (theo thứ tự): cơ số sai được chọn, dấu phân cách sai (khoảng trắng so với dấu phẩy so với không có gì) hoặc tiền tố
0xtồn tại khi công cụ mong đợi nó được tước vũ khí (hoặc ngược lại). - Xác nhận lại một tài liệu tham khảo đã biết. Luôn kiểm tra ít nhất một ký tự được giải mã lại so với ánh xạ đã biết. 65 = 'A', 97 = 'a', 48 = '0', 32 = khoảng trắng, 10 = nguồn cấp dữ liệu dòng. Nếu những điều đó không giải mã chính xác trong bài kiểm tra của bạn, công cụ, đầu vào hoặc cơ số được khai báo là sai. Không tin tưởng phần còn lại của kết quả cho đến khi các giá trị tham khảo khớp.
- Sao chép đầu ra đến đích của bạn. Khi dán vào Excel hoặc Google Sheets, hãy sử dụng Dán đặc biệt → Giá trị (Ctrl+Shift+V) để tránh bảng tính diễn giải văn bản được giải mã làm công thức. Một
=hoặc+dẫn đầu trong kết quả được giải mã của bạn sẽ kích hoạt đánh giá công thức và làm hỏng ô.
Những cạm bẫy phổ biến. Các dấu phân cách hỗn hợp cắn cứng nhất — một dán chứa cả dấu phẩy và khoảng trắng sẽ phân tích không nhất quán trên hầu hết các công cụ. Dòng mới theo sau từ sao chép dán tạo ra các ký tự vô hình trong kết quả (giải mã để kiểm soát mã 10 hoặc 13). Tiền tố 0x là một đồng tiền lật — công cụ của Duplichecker muốn nó được tước vũ khí; một số con đường Python yêu cầu nó; Utilities-Online dung thứ cả hai. Khi có nghi ngờ, bình thường hóa đầu vào của bạn thành một định dạng nhất quán (dấu phân cách khoảng trắng duy nhất, không có tiền tố, hex chữ thường) trước khi dán.
Khắc phục sự cố Khi Chuyển đổi ASCII của Bạn Trả về Rác
Năm chế độ lỗi, theo thứ tự xấp xỉ bạn sẽ gặp phải chúng.
- "Kết quả của tôi có ký hiệu lạ như é, ’ hoặc ÿ thay vì chữ cái." Dữ liệu của bạn không phải là ASCII thuần túy — nó gần như chắc chắn là UTF-8 được giải mã là Latin-1, hoặc ngược lại. ASCII chỉ định nghĩa mã 0–127. Bất cứ điều gì trên điểm đó là không ASCII, bất kể hệ thống nguồn tuyên bố gì. Chạy các byte thông qua bộ giải mã UTF-8 thay thế hoặc sử dụng
chardet(Python) để tự động phát hiện mã hóa thực tế. Bài tiểu luận cơ bản của Joel Spolsky về chế độ lỗi chính xác này là đọc bắt buộc: Tối thiểu tuyệt đối Mỗi nhà phát triển phần mềm Phải biết về Unicode và Bộ ký tự. - "Bộ chuyển đổi nói 'đầu vào không hợp lệ' hoặc 'lỗi phân tích cú pháp.'" Bạn đã trộn các cơ số — mã hex và mã thập phân trong một dán — hoặc bao gồm tiền tố
0xkhi công cụ không mong đợi nó, hoặc để lại các ký tự không phải số như dấu phẩy, dấu ngoặc hoặc dấu ngoặc kép từ một bản đổ JSON. Tước nhập xuống thành một định dạng nhất quán duy nhất với một dấu phân cách nhất quán. Một khoảng trắng duy nhất giữa các mã token là mặc định an toàn nhất trên các công cụ. - "Đầu ra trống hoặc chỉ là dòng mới." Đầu vào của bạn chứa chỉ các ký tự điều khiển (mã 0–31). LF (10), CR (13), TAB (9) và NUL (0) không hiển thị dưới dạng glyph hiển thị — chúng là các hướng dẫn chức năng cho terminal hoặc màn hình. Giải mã thành công; kết quả chỉ không hiển thị. Mở kết quả trong trình xem hex để xác nhận các byte tồn tại, hoặc đường ống thông qua
cat -Atrên Linux để làm cho các không thuộc hiển thị rõ ràng. - "Nó hoạt động, nhưng emoji hoặc ký tự có dấu của tôi bị thiếu." ASCII không thể biểu diễn emoji hoặc bất kỳ script không phải tiếng Anh nào. Hiệp hội Unicode định nghĩa 149,186 ký tự trên 161 script trong phiên bản 15.0 — ASCII bao gồm 95 cái tập trung vào tiếng Anh có thể in được. Nếu văn bản gốc của bạn chứa ñ, ü, ç, Tiếng Trung Quốc, Tiếng Nga, Tiếng Ả Rập hoặc 😀, những ký tự đó sẽ không bao giờ có thể biểu diễn trong 7 bit ASCII. Mã số bạn đang giữ là byte UTF-8 cần một bộ giải mã UTF-8, không phải là công cụ ASCII.
- "Một số ký tự trong tệp được cho là ASCII của tôi được giải mã sai." Có khả năng là các ký tự máy bay phụ Unicode yêu cầu xử lý cặp thay thế, mà hầu hết các trình tạo ASCII đơn giản (CodeShack bao gồm) không thực hiện. Theo tài liệu của CodeShack, cách tiếp cận
String.fromCharCode()của họ xử lý các ký tự BMP lên đến 0xFFFF nhưng không phải điểm mã máy bay phụ. Hãy sử dụngbytes.decode('utf-8')của Python thay thế — nó xử lý toàn bộ phạm vi Unicode một cách chính xác.
Nếu kết quả của bạn có các ký tự có dấu không đúng, bạn không có vấn đề ASCII — bạn có vấn đề UTF-8 mặc trang phục ASCII.
Tự động hóa Giải mã ASCII bằng Python, JavaScript và Bảng tính
Khi bạn giải mã ASCII nhiều hơn một lần một tuần, các công cụ web tốn thời gian và tạo ra phơi nhiễm riêng tư. Một tập lệnh Python 4 dòng hoặc một công thức bảng tính xử lý chuyển đổi hàng loạt cục bộ mà không có chuyến đi bên thứ ba. Ba tùy chọn dưới đây bao gồm các nhà phát triển, môi trường web và các nhà phân tích sống trong Excel — chọn cái khớp với nơi dữ liệu của bạn đã tồn tại.
Python (chuỗi hex thành ASCII):
hex_data = "48 65 6C 6C 6F 20 57 6F 72 6C 64"
text = bytes.fromhex(hex_data.replace(" ", "")).decode("ascii")
print(text) # → Hello World
bytes.fromhex() yêu cầu không có khoảng trắng trong đầu vào của nó, vì vậy chúng tôi tước chúng bằng .replace(). .decode("ascii") sẽ nâng UnicodeDecodeError trên bất kỳ byte lớn hơn 127, đó chính xác là những gì bạn muốn khi xác nhận ASCII nghiêm ngặt — lỗi là thông tin chẩn đoán, không phải là một thất bại. Để dung thứ các ký tự mở rộng, hãy hoán đổi trong .decode("utf-8") cho văn bản hiện đại hoặc .decode("latin-1") cho dữ liệu kế thừa Tây Âu.
JavaScript (mảng thập phân thành văn bản):
const codes = [72, 101, 108, 108, 111, 32, 87, 111, 114, 108, 100];
const text = String.fromCharCode(...codes);
console.log(text); // → Hello World
String.fromCharCode() chấp nhận các đơn vị mã lên đến ~ 65.535 (giới hạn BMP). Đối với các điểm mã vượt quá điều đó, hãy sử dụng String.fromCodePoint() để xử lý các cặp thay thế một cách chính xác — đây là khoảng trống công cụ UI CodeShack không điền, theo tài liệu của riêng họ. Nếu bạn đang xử lý nội dung do người dùng tạo có thể chứa emoji hoặc script máy bay phụ, hãy mặc định String.fromCodePoint() bất kể dữ liệu kiểm tra của bạn có cần nó hay không.
Google Sheets / Công thức Excel:
=CHAR(72)&CHAR(101)&CHAR(108)&CHAR(108)&CHAR(111)
CHAR() chấp nhận một mã thập phân cho mỗi lệnh gọi. Đối với một cột mã trong A2:A12, hãy sử dụng =CONCAT(CHAR(A2:A12)) trong Google Sheets (xử lý tự động spilling mảng) hoặc =TEXTJOIN("",TRUE,IF(A2:A12<>"",CHAR(A2:A12),"")) như một công thức mảng trong Excel. Tốt nhất cho các bộ dữ liệu nhỏ dưới ~ 100 giá trị — vượt quá điểm đó, công thức trở nên cồng kềnh và Python nhanh hơn để viết và chạy.
Một ghi chú về khi không tự động hóa: một lần di chuyển kế thừa duy nhất hiếm khi chứng minh viết một tập lệnh. Các công cụ web từ phần so sánh nhanh hơn cho công việc một phát. Tự động hóa khi (a) dữ liệu chảy trong lặp đi lặp lại, (b) nó chứa các giá trị nhạy cảm không nên rời khỏi máy của bạn, hoặc (c) các hệ thống hạ lưu cần văn bản được giải mã làm một phần của một đường ống hiện có. Cùng một mã có thể được gói trong điểm cuối API — theo cách tương tự như các dịch vụ hướng tới nhà phát triển như API Chuyển đổi văn bản thành giọng nói và API Nhân bản giọng nói hiển thị logic xử lý văn bản cho các ứng dụng khác. Khi giải mã trở thành một dịch vụ, phần còn lại của ngăn xếp của bạn sẽ ngừng quan tâm đến việc liệu đầu vào đã đến dưới dạng hex, thập phân hay đã được giải mã UTF-8.
ASCII so với Unicode — Tại sao Quy trình "Chỉ ASCII" Yên tĩnh Phá vỡ Nội dung Hiện đại
Bạn đã học cách giải mã ASCII. Phần này giải thích khi đó là mục tiêu sai hoàn toàn.
| Tính chất | ASCII | Unicode (UTF-8) |
|---|---|---|
| Điểm mã được định nghĩa | 128 (0–127) | 149,186 được gán trong 1,114,112 có thể |
| Bit cho mỗi ký tự | 7 | 8–32 (biến, 1–4 byte) |
| Script được hỗ trợ | Chỉ tiếng Anh Latin | 161 script |
| Hỗ trợ Emoji | Không có | Toàn bộ |
| Sử dụng web | <5% là chính | >95% các trang web |
Nguồn: Wikipedia ASCII, Hiệp hội Unicode 15.0, Khảo sát mã hóa ký tự W3Techs.
Nhà cung cấp đóng gói dCode nêu rõ rằng ASCII là "lỗi thời và bị thay thế bởi Unicode." Đó không phải là nhân xét tay lịch sử — đó là một cảnh báo thực tế. Nhiều nhà phát triển xây dựng các đường ống hoạt động hoàn hảo trong bài kiểm tra (dữ liệu ASCII chỉ tiếng Anh) và phá vỡ trong sản xuất lần đầu tiên một người dùng gửi một tên có dấu, một emoji hoặc script không phải Latin. Bài tiểu luận cổ điển của Joel Spolsky khung chính xác thất bại: xử lý byte như thể chúng ở một mã hóa cụ thể mà không xác minh giả định, sau đó xem dữ liệu làm hỏng âm thầm.
Cạm bẫy là chế độ lỗi là yên tĩnh. Mã xử lý các byte phạm vi ASCII sẽ vui vẻ xử lý tập hợp con ASCII của UTF-8 mà không có lỗi — cho đến khi nó gặp một chuỗi nhiều byte, tại thời điểm nó sẽ sập, xáo trộn ký tự hoặc (trường hợp tồi tệ nhất) viết byte bị hỏng trở lại lưu trữ. Đến khi ai đó nhận thấy, dữ liệu xấu đã lan truyền thông qua các bản sao lưu.
Unicode được thiết kế cụ thể để tương thích ngược: bất kỳ văn bản ASCII thuần túy nào đã là UTF-8 hợp lệ mà không cần chuyển đổi. Theo RFC 3629, tập hợp con ASCII của UTF-8 sử dụng chính xác một byte giống hệt như byte ASCII gốc. Điều này có nghĩa là câu hỏi "ASCII thành văn bản" gần như luôn là một dấu hiệu rằng ở đâu đó ở dòng sông, văn bản được tuần tự hóa dưới dạng mã số — không phải bạn có một sự không khớp mã hóa thực sự. Tìm điểm tuần tự hóa, sửa nó để kết quả UTF-8 trực tiếp, và vấn đề giải mã hạ lưu biến mất.
Bài học thực tế: khi xây dựng bất cứ điều gì xử lý nội dung do người dùng tạo, hãy sử dụng UTF-8 từ đầu đến cuối. Lưu bộ giải mã ASCII để kiểm tra dữ liệu kế thừa, các hệ thống nhúng, các thách thức CTF và phiên gỡ lỗi. Đó là những trường hợp sử dụng thực — nhưng chúng là các trường hợp sử dụng kiểm tra, không phải đường dẫn dữ liệu sản xuất.
Điều này trở nên đặc biệt sắc nét khi nội dung di chuyển qua các ngôn ngữ. Phụ đề, script dubbing, văn bản script được chuyển ghi âm, nội dung tiếp thị dịch — bất cứ điều gì đa ngôn ngữ chứa dấu, dấu tổng hợp, ký tự ideographic hoặc script từ phải sang trái mà ASCII đơn giản không thể mã hóa. Bất kỳ đường ống nội dung hiện đại nào — chuyên ghi âm, dịch, AI Dubbing trên 33+ ngôn ngữ mục tiêu — yêu cầu nhận thức Unicode từ cấp độ byte lên, vì ASCII không thể biểu diễn các script mà hầu hết thế giới đọc. Một đường ống yên tĩnh bỏ một dấu tổng hợp Việt Nam hoặc một kanji Nhật Bản không phải là một đường ống hoạt động cho 95% người dùng và phá vỡ cho 5% — nó là một đường ống tạo ra kết quả bị hỏng âm thầm cho đa số ngôn ngữ của con người.
ASCII xử lý 128 ký tự. Unicode xử lý 149,186. Nếu nội dung của bạn chạm vào nhiều hơn một ngôn ngữ, khoảng cách đó là toàn bộ trò chơi.
Danh sách Kiểm tra Trước chuyến bay — Xác nhận Giải mã ASCII là Sửa chữa Đúng Trước khi Bắt đầu
Trước khi dán bất cứ điều gì vào một bộ chuyển đổi, hãy chạy qua kiểm tra bảy mục này. Mỗi câu trả lời "không" sẽ chuyển hướng bạn đến một giải pháp khác — phần khắc phục sự cố để không khớp mã hóa, phần tự động hóa cho quy trình định kỳ, phần ASCII-vs-Unicode cho bất cứ điều gì đa ngôn ngữ. Ba câu trả lời "không" hoặc nhiều hơn có nghĩa là giải mã ASCII không phải là vấn đề thực sự của bạn.
- Dữ liệu của tôi bao gồm các mã token số (hex, thập phân, nhị phân hoặc bát phân) — không phải chữ cái hoặc ký hiệu. Nếu bạn thấy văn bản có thể đọc được thực tế trộn với các số, bạn có một luồng được giải mã một phần. Trích xuất chỉ phần số trước khi dán vào một trình tạo, hoặc công cụ của bạn sẽ sủa trên các ký tự không phải số và từ chối xử lý phần còn lại.
- Tất cả các giá trị số của tôi nằm trong khoảng từ 0 đến 127. Bất cứ điều gì 128 hoặc cao hơn không phải là ASCII tiêu chuẩn. Nếu bạn có các giá trị lên đến 255, bạn đang ở trong lãnh thổ Latin-1 hoặc Windows-1252; hãy sử dụng bộ giải mã nhận biết trang mã thay thế. Nếu các giá trị vượt quá 255, bạn gần như chắc chắn có các điểm mã Unicode thô, không phải mã ASCII — bộ giải mã khác, cách tiếp cận khác.
- Tôi biết cơ số của đầu vào của tôi (hex so với thập phân so với nhị phân so với bát phân). Đoán lãng phí thời gian và tạo ra kết quả yên tĩnh sai. Hex chứa ký tự A–F trộn với chữ số. Nhị phân chỉ là 0 và 1 được nhóm thành các khúc 7 hoặc 8 bit. Octal sử dụng chữ số 0–7 chỉ — không có 8 hoặc 9 xuất hiện. Thập phân là mọi thứ khác dưới 128.
- Nội dung nguồn của tôi chỉ tiếng Anh. ASCII không thể biểu diễn dấu tiếng Pháp, diaeresis tiếng Đức, ký tự Tiếng Nga, ideographs CJK hoặc emoji. Nếu văn bản gốc của bạn từng chứa bất kỳ trong số đó, mã số bạn giữ không phải là ASCII — chúng là byte UTF-8 cần một bộ giải mã UTF-8. Buộc chúng qua một công cụ ASCII sẽ lỗi hoặc tạo mojibake. Cùng một ràng buộc hình thành bất kỳ bước định vị hạ lưu nào, bao gồm các quy trình API AI Dubbing phải bảo tồn mọi ký tự mà một kịch bản chứa.
- Dữ liệu không nhạy cảm (không có thông tin đăng nhập, PII hoặc nội dung được quản lý). Các bộ chuyển đổi web xử lý dán của bạn trên máy chủ bên thứ ba mà không có đảm bảo lưu giữ dữ liệu rõ ràng. H