
คุณเพิ่งได้ยินมันอีกครั้ง — เสียงร้องที่สดใส คมชัด ดูสังเคราะห์แต่ก็เปี่ยมอารมณ์ ที่แทรกผ่านเข้าไปในเพลง สตรีม VTuber หรือรีมิกซ์เกม แล้วบางอย่างก็คลิกขึ้นมา คุณอยากสร้างเสียงนั้นด้วยตัวเอง ไม่ใช่เดือนหน้าหลังจากที่ซื้อซอฟต์แวร์และดูสอนสี่สิบคลิป แต่ตอนนี้ ปัญหาคือ เส้นทางแบบดั้งเดิมต้องผ่านเอนจิน Vocaloid หรือ Synthesizer V ที่มีลิขสิทธิ์ ซึ่งเสียเงิน ต้องใช้การเรียนรู้ที่ชันมาก และล็อกคาแร็กเตอร์เสียงร้องอันเป็นเอกลักษณ์นั้นไว้หลังเส้นโค้งระดับเสียงที่ต้องวาดเองนับชั่วโมง เครื่องสร้างเสียงมิกุ (miku voice generator) สมัยใหม่พลิกบทนั้น พาคุณจากบรรทัดที่พิมพ์หรือคลิปเสียงสั้น ๆ ไปสู่แทร็กเสียงร้องที่ส่งออกได้ภายในไม่กี่นาที

ส่วนที่ทำให้สบายใจคือ การอยากได้เส้นทางที่ง่ายกว่าไม่ใช่การโกง วัฒนธรรม Vocaloid เติบโตขึ้นผ่านนักงานอดิเรกที่เรียนรู้ทีละขั้นตอนจากการสอนในชุมชน ไม่ใช่วิศวกรเสียงที่ผ่านการฝึกฝน — นักวิชาการด้านสื่อ Hans Coppens มองปรากฏการณ์ทั้งหมดนี้ว่าเป็นระบบนิเวศแบบมีส่วนร่วมที่สร้างโดยผู้ใช้ และอุปสรรคก็ลดลงเรื่อย ๆ โปรเจกต์โอเพนซอร์ส Real-Time-Voice-Cloning โฆษณาว่าสามารถโคลนเสียงที่จดจำได้จากเสียงสะอาดประมาณ 5 วินาที ดังนั้นคำถามที่แท้จริงคือ เครื่องมือใดตรงกับสิ่งที่คุณอยากสร้าง — และนั่นแหละคือสิ่งที่ส่วนที่เหลือของคู่มือนี้จะช่วยจัดการให้
สารบัญ
- "เครื่องสร้างเสียงมิกุ" ทำอะไรได้จริง (และทำอะไรไม่ได้)
- การเลือกวิธีของคุณ: แปลงข้อความเป็นเสียง vs. การโคลนเสียง vs. โมเดลคัฟเวอร์
- ทีละขั้นตอน — การสร้างเสียงร้องสไตล์มิกุด้วยเครื่องมือเสียง AI
- การโคลนเสียงสไตล์มิกุที่กำหนดเองจากตัวอย่างเสียงสั้น ๆ
- การปรับจูนเพื่อความสมจริง — ระดับเสียง โทน และคาแร็กเตอร์ "Vocaloid"
- การให้สิทธิ์ใช้งาน สิทธิ์การใช้ และการอยู่ในกรอบกฎหมายกับเนื้อหาสไตล์มิกุ
- ชุดเครื่องมือสร้างเสียงร้องมิกุของคุณ — เช็กลิสต์พร้อมลงมือ
- เครื่องสร้างเสียงมิกุ — คำถามที่พบบ่อย
"เครื่องสร้างเสียงมิกุ" ทำอะไรได้จริง (และทำอะไรไม่ได้)
ก่อนที่คุณจะเลือกเครื่องมือ ทำความเข้าใจให้ชัดว่า "เครื่องสร้างเสียงมิกุ" หมายถึงอะไรกันแน่ — เพราะคำนี้ครอบคลุมสามเทคโนโลยีที่แตกต่างกัน ซึ่งให้ผลลัพธ์สามแบบที่แตกต่างกัน การเลือกผิดทำให้เสียเวลาหลายชั่วโมง นี่คือการแยกแยะแนวทางต่าง ๆ
เอนจิน Vocaloid / Synthesizer V เหล่านี้คือผลิตภัณฑ์ซอฟต์แวร์ที่มีลิขสิทธิ์ ซึ่งสร้างการร้องเพลงโดยตรงจากอินพุตเชิงสัญลักษณ์ — โน้ต MIDI บวกกับเนื้อร้องที่พิมพ์ — ให้คุณควบคุมระดับเสียง จังหวะ และการแสดงออกในระดับโน้ต นี่คือเส้นทาง voicebank ของ Hatsune Miku อย่างเป็นทางการจาก Crypton Future Media ที่คุณวาดทำนองและเอนจินจะร้องให้ (Hans Coppens) Crypton นิยาม Hatsune Miku อย่างชัดเจนว่าเป็น "Piapro Character" — หนึ่งในกลุ่มผลิตภัณฑ์เครื่องสังเคราะห์เสียงร้อง ซึ่งเป็นเครื่องมือเสียงร้องที่ใช้ซอฟต์แวร์เป็นพื้นฐาน ไม่ใช่นักแสดงที่เป็นมนุษย์ (piapro.net) ควบคุมได้สูงสุด มีเพดานทักษะที่สูงที่สุด
เครื่องมือโคลนเสียง AI และแปลงข้อความเป็นเสียง (Text-to-Speech) เหล่านี้สร้างเสียงพูดและเสียงร้องสไตล์มิกุจากข้อความที่พิมพ์หรือคลิปอ้างอิงสั้น ๆ เมื่อโคลนเสียงแล้ว ระบบอย่าง Real-Time-Voice-Cloning จะสร้างวลีพูดที่ฟังดูเป็นธรรมชาติจากข้อความ แต่ไม่ได้ปรับมาเพื่อควบคุมการร้องทีละโน้ตแบบที่เอนจิน Vocaloid ทำได้ (การอภิปรายเรื่องการโคลนเสียงบน Kaggle) ใช้เอนจิน Text to Speech สำหรับบรรทัดพูดสไตล์มิกุ หรือ Voice cloning เพื่อสร้างทิมเบรอที่กำหนดเองที่คุณเป็นเจ้าของ
โมเดลคัฟเวอร์ / การแปลงเสียง (RVC, so-vits-svc) เหล่านี้รับการแสดงเสียงร้องที่มีอยู่แล้วและแปลงทิมเบรอของมันให้เป็นเสียงแบบมิกุ ขณะที่ยังคงระดับเสียงและจังหวะดั้งเดิมไว้ (การสอน so-vits-svc) นั่นทำให้มันเหมาะอย่างยิ่งสำหรับ "คัฟเวอร์สไตล์มิกุ" ของเนื้อหาที่ร้องไว้แล้ว — คุณป้อนทำนองโดยการร้องเอง และโมเดลจะสลับเสียงให้ พวกมันไม่ได้คิดทำนองใหม่ขึ้นมาจากศูนย์
เส้นทางที่เร็วที่สุดสู่เสียงร้องสไตล์มิกุไม่ใช่ voicebank อย่างเป็นทางการเสมอไป — แต่คือการเลือกเครื่องมือที่ตรงกับผลลัพธ์ของคุณ: เสียงพูด เพลง หรือการแปลงเสียง
ตั้งความคาดหวังของคุณอย่างซื่อสัตย์: TTS และการโคลนให้ผลลัพธ์เป็นเสียงพูดหรือคล้ายเสียงพูด เอนจิน Vocaloid ให้การร้องเพลงจริง ๆ และโมเดลคัฟเวอร์แปลงเทคที่มีอยู่ เส้นแบ่งระหว่างมิกุที่มีลิขสิทธิ์อย่างเป็นทางการกับผลลัพธ์ "สไตล์มิกุ" ทั่วไปก็มีความสำคัญทางกฎหมายด้วย — บางอย่างที่เราจะมาจัดการในภายหลังของคู่มือนี้
การเลือกวิธีของคุณ: แปลงข้อความเป็นเสียง vs. การโคลนเสียง vs. โมเดลคัฟเวอร์
ทีนี้จับคู่วิธีให้ตรงกับเป้าหมายของคุณ ตารางด้านล่างวางแนวทางสี่แบบไว้ตามเกณฑ์ที่ส่งผลต่อการตัดสินใจของคุณจริง ๆ — อะไรออกมา คุณต้องป้อนอะไร มันยากแค่ไหน และภาพรวมการให้สิทธิ์ใช้งานเป็นอย่างไร
| วิธีการ | ประเภทผลลัพธ์ | อินพุตที่ต้องใช้ | กรณีใช้งานที่ดีที่สุด | หมายเหตุการให้สิทธิ์ |
|---|---|---|---|---|
| แปลงข้อความเป็นเสียง | เสียงพูด / คล้ายเสียงพูด | ข้อความที่พิมพ์ | อินโทร VTuber, การบรรยาย, บรรทัดพูด | ใช้ "สไตล์" ทั่วไป ตรวจสอบข้อกำหนดแพลตฟอร์ม |
| การโคลนเสียง | ทิมเบรอเสียงพูดที่กำหนดเอง | เสียงอ้างอิงสะอาด ~5–20 วินาที | เสียงสไตล์มิกุที่กำหนดเองและเป็นเจ้าของได้ | โคลนจากแหล่งที่เป็นของคุณ/มีลิขสิทธิ์ |
| คัฟเวอร์ / การแปลงเสียง | การร้องที่แปลงแล้ว | เสียงร้อง + โมเดล | คัฟเวอร์สไตล์มิกุของเทคที่คุณร้องเอง | สิทธิ์เสียงร้องต้นฉบับ + IP ของคาแร็กเตอร์ |
| เอนจิน Vocaloid / Synth V | การร้องเพลงจริง | MIDI + เนื้อร้อง | เพลงมิกุต้นฉบับ ควบคุมโน้ตเต็มรูปแบบ | Voicebank อย่างเป็นทางการ; Piapro/PCL มีผล |
อ่านมันตามเป้าหมายสุดท้ายของคุณ ถ้าคุณต้องการอินโทร VTuber ที่พูดหรือการบรรยายในเสียงสังเคราะห์สดใส แปลงข้อความเป็นเสียง คือเส้นทางที่มีอุปสรรคน้อยที่สุด — พิมพ์บรรทัด สร้าง เสร็จ ถ้าคุณต้องการทิมเบรอที่เป็นเอกลักษณ์ เป็นเจ้าของได้ ที่ไม่มีใครมี การโคลนเสียง จากคลิปอ้างอิงสั้น ๆ คือทางเลือก และถ้าคุณร้องเดโมไว้แล้วและอยากให้มันออกมาฟังดูแบบมิกุ โมเดล คัฟเวอร์ / การแปลงเสียง ถูกสร้างมาเพื่อสิ่งนั้นโดยเฉพาะ: so-vits-svc และ RVC คงระดับเสียงและจังหวะของการแสดงของคุณไว้ และแทนที่เฉพาะเสียงเท่านั้น (so-vits-svc)
เส้นโค้งทักษะจะชันขึ้นเมื่อคุณเลื่อนลงในตาราง แปลงข้อความเป็นเสียงและการโคลนอยู่ปลายล่าง — ระบบโคลนสมัยใหม่ปรับให้เข้ากับผู้พูดใหม่จากเสียงไม่กี่วินาที (Real-Time-Voice-Cloning) โมเดลคัฟเวอร์อยู่ในช่วงกลางเพราะคุณต้องเตรียมและทำความสะอาดเสียงร้องต้นฉบับก่อน เอนจิน Vocaloid สร้างการร้องจาก MIDI บวกเนื้อร้อง (Hans Coppens) ซึ่งหมายความว่าคุณกำลังแต่งและแก้ไขในระดับโน้ตอย่างมีประสิทธิภาพ — ทรงพลัง แต่เป็นการปีนที่ชันที่สุดในสี่แบบ
นี่คือจุดที่แพลตฟอร์มแบบครบวงจรคุ้มค่า เพราะสามวิธีแรกสามารถอยู่ในเวิร์กโฟลว์เดียว เอนจิน Text to Speech ครอบคลุมบรรทัดพูดสไตล์มิกุ การโคลนเสียงจากคลิปอ้างอิงสั้น ๆ ให้คุณได้ทิมเบรอที่กำหนดเองอย่างรวดเร็วโดยไม่ต้องแตะ DAW และตัวแยกเสียงพูด (Speech Separator) จัดการขั้นตอนที่ไม่หวือหวาแต่จำเป็นในการแยกเสียงร้องออกจากแทร็กที่มีอยู่ก่อนที่คุณจะทำการแปลง — ดังนั้นการทดลองแปลงข้อความเป็นเสียงมิกุและการทดลองคัฟเวอร์ของคุณจึงใช้ชุดเครื่องมือเดียวกัน แทนที่จะกระจัดกระจายไปในห้าแอป
มีคอลัมน์หนึ่งที่ตารางจงใจละเว้น: เรตติ้ง "ดีที่สุดโดยรวม" มันไม่มีหรอก วิธีที่ถูกต้องคือประเภทผลลัพธ์ใดก็ตามที่คุณต้องการ และคอลัมน์การให้สิทธิ์ใช้งานคือคอลัมน์ที่ควรอ่านสองครั้งก่อนที่คุณจะเผยแพร่อะไรในเชิงพาณิชย์ — ข้อกำหนด Piapro license ไม่ใช่การอ่านที่เป็นทางเลือก
ทีละขั้นตอน — การสร้างเสียงร้องสไตล์มิกุด้วยเครื่องมือเสียง AI
นี่คือส่วนที่คุณมาเพื่อสิ่งนี้ นี่คือเวิร์กโฟลว์สร้างและส่งออกที่สมบูรณ์ด้วย เครื่องสร้างเสียงมิกุ ตั้งแต่หน้าจอว่างเปล่าไปจนถึงสเต็มเสียงร้องสะอาดที่คุณสามารถวางลงในโปรเจกต์ของคุณได้ ห้าขั้นตอน ไม่ต้องเล่นกายกรรม DAW

- เลือกอินพุตของคุณ สำหรับบรรทัดพูด ให้พิมพ์เนื้อร้องหรือสคริปต์ของคุณลงในช่องข้อความโดยตรง สำหรับเสียงที่โคลน ให้เตรียมคลิปเสียงร้องอ้างอิงที่สะอาด ไม่ว่าทางใด อินพุตที่สะอาดเป็นสิ่งที่ต่อรองไม่ได้ — ขยะเข้า ขยะออก นักพัฒนาที่ทำอัตโนมัติชุดบรรทัดจำนวนมากสามารถส่งข้อความผ่าน Text to Speech API แทนการวางด้วยมือ
- เลือกหรือโคลนโปรไฟล์เสียง เลือกเสียงสดใส ระดับสูงจากไลบรารีสำเร็จรูป หรือโคลนเสียงของคุณเองเพื่อให้ได้ เสียงร้องสไตล์มิกุ ด้วยคาแร็กเตอร์ที่กำหนดเอง ระบบสมัยใหม่สามารถโคลนจากเสียงสะอาดประมาณ 5 วินาที แม้ว่าคลิปที่ยาวกว่า — หลายสิบวินาที — จะให้ทิมเบรอที่เสถียรกว่า (Real-Time-Voice-Cloning, Kaggle) รายละเอียดการโคลนเต็มรูปแบบอยู่ในส่วนถัดไป
- ปรับระดับเสียง ความเร็ว และโทน ดันระดับเสียงขึ้นไปสู่ช่วงเสียงสูงที่มีความใสแบบสังเคราะห์ที่นิยามคาแร็กเตอร์มิกุ แล้วปรับความเร็วและโทนจนกว่าผลลัพธ์จะอ่านได้คมชัดแทนที่จะอบอุ่น สามแถบเลื่อนนี้คือคันโยกในการแสดงออกหลักของคุณ — เราจะเจาะลึกการปรับมันในเร็ว ๆ นี้
- สร้างและพรีวิว เรนเดอร์เสียงร้องและฟังอย่างวิพากษ์วิจารณ์ ถ้าทิมเบรอสั่นหรือการวลีรู้สึกผิด ให้เปลี่ยนการตั้งค่าหนึ่งอย่างแล้วรันใหม่ การทำซ้ำมีต้นทุนต่ำที่นี่ ดังนั้นจงปฏิบัติต่อการเรนเดอร์ครั้งแรกเป็นฉบับร่าง ไม่ใช่ฉบับสุดท้าย
- ส่งออกสเต็มเสียงร้องสะอาด ดาวน์โหลดสเต็มและวางลงใน DAW หรือโปรแกรมตัดต่อวิดีโอของคุณ ถ้าคุณกำลังสร้างวิดีโอที่เสร็จสมบูรณ์รอบ ๆ มัน Image to Video ให้คุณจับคู่เสียงร้องกับภาพที่สร้างขึ้นโดยไม่ต้องออกจากเวิร์กโฟลว์
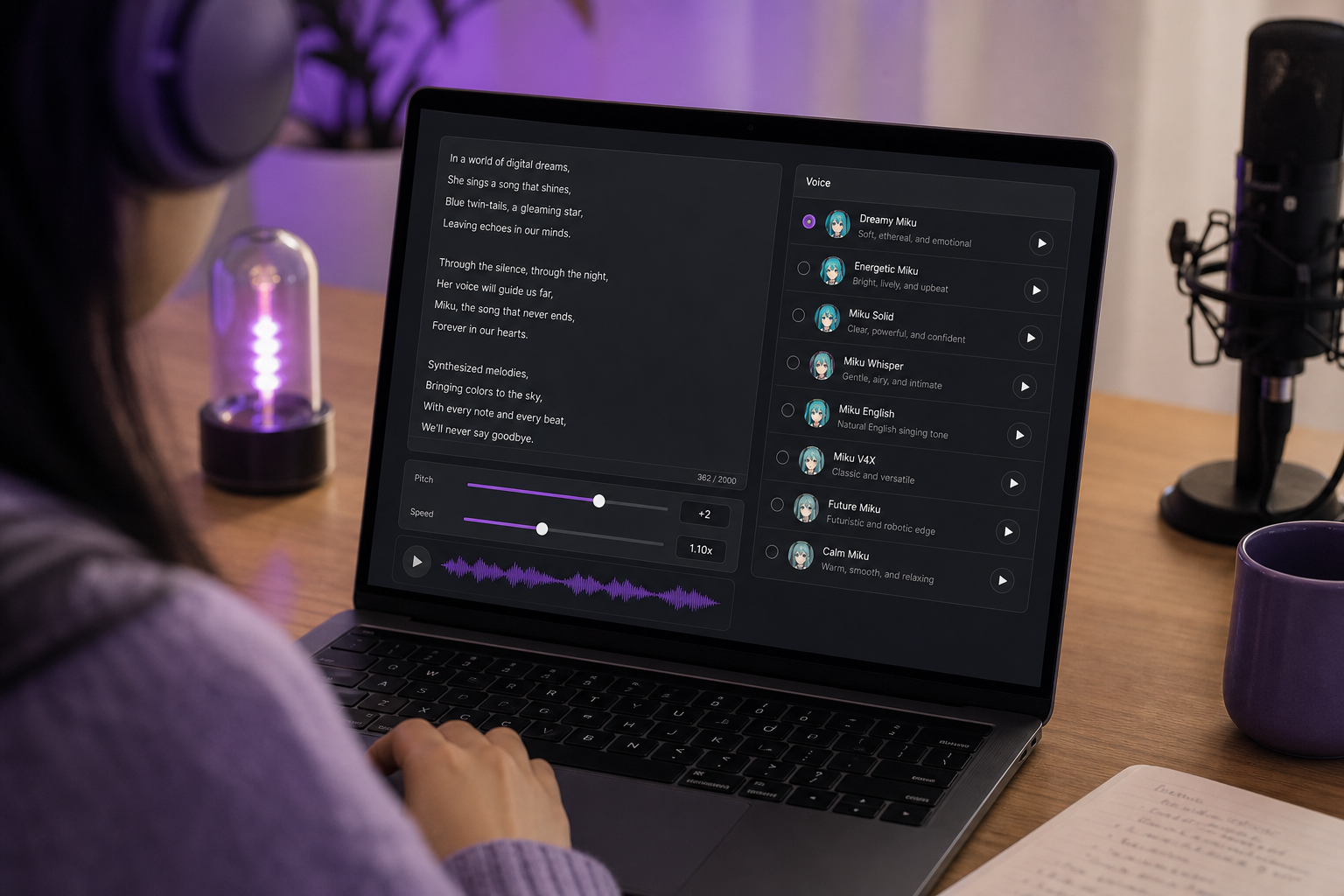
ประเด็นทั้งหมดคือการเข้าถึงได้ เวิร์กโฟลว์นี้ตัดความซับซ้อนของ DAW ที่ทำให้มือใหม่ส่วนใหญ่หยุดชะงัก ซึ่งสะท้อนถึงวิธีที่นักงานอดิเรก Vocaloid เรียนรู้จริง ๆ — ทีละขั้นตอนผ่านเครื่องมือที่เข้าถึงได้ มากกว่าการฝึกอบรมวิศวกรรมอย่างเป็นทางการ (Hans Coppens)
การโคลนเสียงสไตล์มิกุที่กำหนดเองจากตัวอย่างเสียงสั้น ๆ
เสียงสำเร็จรูปทำให้คุณเริ่มต้นได้อย่างรวดเร็ว แต่ถ้าคุณต้องการทิมเบรอที่ไม่มีใครมี — เสียงที่คุณสามารถเรียกว่าเป็นของคุณ — การโคลนเสียงมิกุ จากตัวอย่างสั้น ๆ คือทางเลือก ทำงานตามเช็กลิสต์นี้ตามลำดับ การข้ามขั้นตอนเตรียมการคือจุดที่ผลลัพธ์ของคนส่วนใหญ่พังทลาย
- เก็บเสียงให้เพียงพอ การโคลนแบบ few-shot ทำงานได้จากประมาณ 5 วินาที แต่หลายสิบวินาทีถึงสองสามนาทีให้ทิมเบรอและจังหวะการพูดที่เสถียรขึ้นอย่างเห็นได้ชัด — และความเสถียรนั้นสำคัญยิ่งกว่าสำหรับผลลัพธ์คล้ายการร้องเพลง (Real-Time-Voice-Cloning, Kaggle) ตั้งเป้าไปทางปลายที่ยาวกว่าถ้าทำได้ ข้อมูลสะอาดเพิ่มเติมซื้อความเที่ยงตรงให้คุณ เอเจนซีที่โคลนในระดับใหญ่สามารถเชื่อมต่อสิ่งนี้เข้ากับ Voice Cloning API
- แยกเพลงพื้นหลังออกก่อน เสียงที่สะอาดและแยกออกมาเป็นสิ่งจำเป็น รันตัวอย่างของคุณผ่านตัวแยกเสียงพูด (Speech Separator) หรือเครื่องมือแยกแหล่งเสียงเพื่อกำจัดเพลงและเสียงรบกวนก่อนป้อนให้โมเดลโคลน — เวิร์กโฟลว์ที่สำเร็จเน้นย้ำขั้นตอนนี้โดยเฉพาะเพื่อหลีกเลี่ยงสิ่งแปลกปลอมและการออกเสียงที่ไม่เสถียรในผลลัพธ์ (so-vits-svc)
- หาแหล่งอ้างอิงที่ใส ระดับเสียงสูง บันทึกหรือเลือกตัวอย่างที่สดใส ใส และพยัญชนะคมชัด อยู่ในช่วงเสียงสูง ยิ่งเสียงอ้างอิงของคุณเอนไปทางคุณสมบัติเหล่านั้นอยู่แล้ว การควบคุมระดับเสียงและโทนก็ยิ่งต้องทำงานน้อยลงในภายหลังเพื่อให้ถึงคาแร็กเตอร์ เสียงมิกุ AI
- ตรวจสอบคุณภาพผลลัพธ์และทำซ้ำ ฟังหาความเป็นธรรมชาติและความเสถียรของทิมเบรอ คุณภาพการโคลนดีขึ้นด้วยข้อมูลที่มากและสะอาดกว่า (Kaggle) ดังนั้นถ้าเสียงสั่นหรือเบลอในบางพยางค์ วิธีแก้มักจะเป็นตัวอย่างที่ดีกว่า — ไม่ใช่การปรับแถบเลื่อนเพิ่ม โคลนใหม่และเปรียบเทียบ
- ใช้เสียงของคุณเองหรือที่มีลิขสิทธิ์ โคลนเสียงที่คุณเป็นเจ้าของจริง ๆ หรือมีสิทธิ์ใช้ หัวหน้าโปรเจกต์ Real-Time-Voice-Cloning เตือนอย่างชัดเจนเกี่ยวกับจริยธรรมและการใช้ในทางที่ผิดที่อาจเกิดขึ้นจากการโคลนเสียงโดยไม่ได้รับความยินยอม (Real-Time-Voice-Cloning) การสร้างทิมเบรอต้นฉบับจากเสียงของคุณเองหลีกเลี่ยงหมวดหมู่ความเสี่ยงทั้งหมดนั้น — และเราจะครอบคลุมนัยทางการให้สิทธิ์ใช้งานอย่างเต็มที่ในส่วนถัดไป

การปรับจูนเพื่อความสมจริง — ระดับเสียง โทน และคาแร็กเตอร์ "Vocaloid"
ใครก็สามารถสร้างเสียงพูดสังเคราะห์ที่แบนราบได้ การเปลี่ยนสิ่งนั้นให้เป็น เสียงร้องสไตล์มิกุ ที่น่าเชื่อถือคือฝีมือ และมันอยู่ในการตัดสินใจเฉพาะไม่กี่อย่าง นี่คือสิ่งที่ขยับเข็มได้จริง
ช่วงระดับเสียงและทิมเบรอที่สดใส เอกลักษณ์ของมิกุคือช่วงเสียงสูงควบคู่กับทิมเบรอที่สดใส ใส — ความใสได้รับความนิยมมากกว่าความอบอุ่น ดันการตั้งค่าระดับเสียงขึ้นและต้านความอยากที่จะเพิ่มเนื้อเสียง นี่ก็เป็นจุดที่แนวทางเครื่องมือ AI แตกต่างจากเอนจินอย่างเป็นทางการด้วย: Vocaloid ให้การควบคุมระดับเสียงในระดับโน้ตแก่คุณ ให้คุณดัดและปรับรูปร่างแต่ละโน้ตได้ (Hans Coppens) ด้วยเครื่องสร้าง AI คุณประมาณคาแร็กเตอร์นั้นผ่านการตั้งค่าระดับเสียงและโทนแบบโดยรวม แทนที่จะแก้ไขทีละโน้ต คุณแลกการควบคุมแบบละเอียดกับความเร็ว — การแลกเปลี่ยนที่ยุติธรรมสำหรับโปรเจกต์ส่วนใหญ่ แต่จงรู้ว่าคุณกำลังแลกอะไร
การออกเสียงและความใสของพยัญชนะ ความรู้สึก "ใสแบบสังเคราะห์" นั้นมาจากพยัญชนะที่คมชัดและการเปล่งเสียงที่สะอาดเป็นส่วนใหญ่ ทำให้การวลีอินพุตของคุณเรียบง่ายและตรงไปตรงมา เพื่อให้โมเดลออกเสียงแต่ละคำได้อย่างชัดเจน ประโยคที่ยาว มีเครื่องหมายจุลภาคมาก พร้อมกลุ่มพยัญชนะที่ยาก มักทำให้ผลลัพธ์ขุ่นมัว บรรทัดสั้น ๆ แบบบอกเล่าเรนเดอร์ได้คมชัดกว่า — และคมชัดกว่าคือสิ่งที่อ่านว่าเป็นของแท้ที่นี่ สำหรับนักพัฒนาที่สร้างบรรทัดเหล่านี้ด้วยโปรแกรม เครื่องสร้างภาพ AI สามารถจับคู่ภาพปกที่ตรงกันกับแต่ละวลีที่เรนเดอร์เมื่อคุณสร้างรีลีส
ช่องว่างความเป็นธรรมชาติที่ต้องจัดการ จงซื่อสัตย์กับตัวเองเกี่ยวกับเพดานปัจจุบัน ผู้แสดงความคิดเห็นที่วิเคราะห์งานวิจัยการโคลน 5 วินาทีชี้ให้เห็นว่าเสียงพูดที่สร้างขึ้นยังคงฟังดูเป็นธรรมชาติและแสดงออกน้อยกว่าการบันทึกจริงอย่างเห็นได้ชัด โดยเฉพาะในสภาวะที่มีเสียงรบกวนหรือสำหรับเนื้อหาที่มีอารมณ์ (การอภิปราย media-synthesis บน Reddit) Voice Cloning: Comprehensive Survey บน arXiv ตอกย้ำสิ่งนี้ โดยตั้งข้อสังเกตว่าระบบแลกประสิทธิภาพข้อมูลกับคุณภาพ และโมเดล few-shot ปรับตัวจากเสียงไม่กี่วินาที ในขณะที่ผลลัพธ์ที่มีความเที่ยงตรงสูงกว่าต้องการข้อมูลการปรับจูนเป็นนาทีหรือชั่วโมง คุณจัดการช่องว่าง ไม่ได้กำจัดมัน: ป้อนอินพุตที่สะอาดและยาวกว่า รักษาความต้องการทางอารมณ์ให้พอประมาณ และใช้การประมวลผลแบบเบา ๆ แทนการแก้ไขแบบหนัก
การซ้อนชั้นและการวางตัวในมิกซ์ สเต็มเสียงร้องเปล่า ๆ น้อยครั้งจะฟังดูเสร็จสมบูรณ์ รีเวิร์บเบา ๆ การซ้อนเสียงแบบบาง ๆ และ EQ ที่เจาะจง ช่วยให้เสียงร้องวางตัวในแทร็กโดยไม่จมมัน วินัยที่นี่คือความยับยั้งชั่งใจ — การประมวลผลมากเกินไปผลักเสียงร้องที่เกือบเป็นธรรมชาติเข้าสู่ดินแดนน่าขนลุกโดยตรง เอฟเฟกต์แต่ละอย่างเล็กน้อยมีผลมาก การกองมันรวมกันไม่ช่วย
ความเป็นของแท้ในเสียงร้องสังเคราะห์อยู่ในรายละเอียด — ความคมชัดของพยัญชนะ ช่วงระดับเสียง และความยับยั้งชั่งใจที่จะไม่ประมวลผลมากเกินไป
เชื่อมโยงกลับมาที่การควบคุมของคุณ ความเร็ว ระดับเสียง และโทนคือคันโยกของคุณ และเวิร์กโฟลว์ให้รางวัลกับการทำซ้ำมากกว่าความสมบูรณ์แบบ สร้าง ฟัง ปรับตัวแปรหนึ่งอย่าง สร้างใหม่ เครื่องมืออย่าง Text to Speech ทำให้ลูปนี้เร็วพอที่คุณจะลองฟังหลายสิบรูปแบบในเวลาเท่ากับที่จะใช้แก้ไขวลี Vocaloid วลีเดียวด้วยมือ อย่าคาดหวังความสมบูรณ์แบบในครั้งเดียว — คาดหวังว่าจะลู่เข้าสู่มัน
มีกรอบที่ใหญ่กว่าที่ควรยึดไว้ขณะที่คุณปรับจูน มิกุเจริญรุ่งเรืองภายในระบบนิเวศแบบมีส่วนร่วมของรีมิกซ์ คัฟเวอร์ และการตีความใหม่มาโดยตลอด (Hans Coppens) ตัวเลือกการปรับจูนของคุณไม่ได้ไล่ตามเสียง "ที่ถูกต้อง" คงที่เพียงหนึ่งเดียว — มันเป็นอีกรายการในผืนผ้าใบสร้างสรรค์ที่คนหลายพันได้วาดลงไปแล้ว คาแร็กเตอร์เป็นจุดเริ่มต้น ไม่ใช่เส้นชัย และนั่นแหละคือสิ่งที่ทำให้มันคุ้มค่ากับการทดลอง ไม่มีเป้าหมาย คาแร็กเตอร์ Vocaloid อย่างเป็นทางการเดียวที่คุณกำลังล้มเหลวในการบรรลุ มีช่วงหนึ่ง และคุณสามารถหาจุดของคุณในนั้นได้ด้วย เครื่องสร้างเสียงร้อง AI ที่คุณเลือก
การให้สิทธิ์ใช้งาน สิทธิ์การใช้ และการอยู่ในกรอบกฎหมายกับเนื้อหาสไตล์มิกุ
ถ้าคุณวางแผนที่จะเผยแพร่ — และโดยเฉพาะถ้าคุณวางแผนที่จะทำเงิน — ส่วนนี้คือส่วนที่ทำให้คุณพ้นจากปัญหา กฎเกี่ยวกับ Hatsune Miku เฉพาะเจาะจงกว่าที่ครีเอเตอร์ส่วนใหญ่คิด ดังนั้นจงอ่านอย่างระมัดระวังก่อนที่คุณจะกดอัปโหลด
คาแร็กเตอร์อย่างเป็นทางการ vs. "สไตล์" Hatsune Miku เป็น Piapro Character ที่มีลิขสิทธิ์ซึ่งเป็นเจ้าของโดย Crypton Future Media อยู่ภายใต้การกำกับของ Piapro Character License (PCL) และแนวทางการใช้คาแร็กเตอร์ ข้อกำหนดเหล่านั้นแยกแยะการใช้ภาพและชื่อของคาแร็กเตอร์ออกจากการใช้ voicebank และตั้งเงื่อนไขสำหรับงานอนุพันธ์ การจัดจำหน่าย และการแสดงผล (piapro.net) เสียงร้อง AI "สไตล์มิกุ" ทั่วไปที่คุณสร้างจากเสียงที่โคลนเองเป็นสิ่งที่แตกต่างในเชิงหมวดหมู่จากการใช้ voicebank อย่างเป็นทางการหรือการอ้างถึงคาแร็กเตอร์ที่มีลิขสิทธิ์ด้วยชื่อและรูปลักษณ์ ยิ่งคุณห่างจากทรัพย์สินอย่างเป็นทางการ ความเสี่ยงของคุณก็ยิ่งต่ำ
การใช้เชิงพาณิชย์และการขอเคลียร์สิทธิ์ สำหรับการเผยแพร่เชิงพาณิชย์ที่ใช้ voicebank หรือคาแร็กเตอร์อย่างเป็นทางการ ผู้จัดจำหน่ายต้องขออนุญาตผ่านระบบ "Piapro Link" ในขณะที่การใช้ที่ไม่ใช่เชิงพาณิชย์โดยทั่วไปได้รับอนุญาตภายในแนวทางที่เผยแพร่ (ตาม Otapedia ของ Tokyo Otaku Mode ที่สรุปกฎของ Piapro) ปฏิบัติต่อการเคลียร์สิทธิ์ Piapro Link เป็นเกณฑ์มาตรฐานระดับมืออาชีพสำหรับการส่งเพลงมิกุอย่างเป็นทางการเข้าสู่บริบทที่มีค่าใช้จ่ายอย่างถูกกฎหมาย — มันไม่ใช่พิธีการที่คุณสามารถข้ามและขอโทษภายหลังได้
ไม่มีเสรีภาพ Creative Commons แบบครอบคลุม สิ่งนี้ทำให้คนสะดุดอยู่เสมอ: เว้นแต่จะระบุไว้อย่างชัดเจนเป็นอย่างอื่น เพลงที่เกี่ยวข้องกับ Hatsune Miku ไม่ได้ ให้สิทธิ์ใช้งานภายใต้ Creative Commons BY-NC Piapro ระบุชัดเจนว่าครีเอ