
Points clés à retenir :
- Pourquoi c'est important : La qualité de la traduction impacte la confiance, la conformité et les revenus. Des secteurs comme le médical (99,9 % de précision) et le juridique (98 % de précision) nécessitent de la précision.
-
Principaux objectifs des tests :
- Exactitude sémantique : Les outils comme COMET s'alignent sur les évaluations humaines dans 89 % des cas.
- Consistance terminologique : Les domaines juridiques exigent une consistance des termes de 99,5 %.
- Adaptation culturelle : Un contenu adapté peut augmenter la rétention des utilisateurs de 34 %.
-
Métriques et Outils :
- Traditionnel : BLEU, TER, ROUGE (par exemple, BLEU ≥0.4 pour la convivialité).
- Avancé : COMET (corrélation de 0,81 avec les scores humains) et MQM pour une catégorisation détaillée des erreurs.
-
Défis :
- Erreurs contextuelles, langues à faibles ressources et données d'entraînement obsolètes.
- Exemple : L'ajout de données des réseaux sociaux a amélioré la précision des traductions en kurde de 45 %.
-
Solutions :
- Les systèmes d'apprentissage actif réduisent les erreurs en signalant les sorties avec faible confiance.
- La combinaison d'outils d'IA avec la supervision humaine améliore les taux de détection des défauts à 91 %.
Comparaison rapide des métriques :
| Mesure | Domaine de concentration | Cas d'utilisation & Seuil |
|---|---|---|
| BLEU | Précision N-gram | Vérifications rapides, scores ≥0.4 |
| TER | Distance d'édition | Niveau professionnel, <9% préféré |
| ROUGE | Mesure de rappel | Validation de contenu, 0,3-0,5 |
| COMET | Évaluation sémantique | Forte corrélation (0,81) |
| MQM | Catégorisation d'erreurs | Détail au niveau entreprise |
Ce guide explique comment les entreprises peuvent combiner l'automatisation et l'expertise humaine pour obtenir des traductions évolutives, précises et culturellement pertinentes.
Métriques de mesure de la qualité
Les outils modernes allient automatisation et expertise humaine pour fournir des traductions précises et conscientes du contexte. Ces métriques sont conçues pour répondre à des objectifs clés tels que l'exactitude sémantique, la cohérence terminologique et l'adaptation aux nuances culturelles.
Métriques de Base : BLEU, TER, ROUGE
Trois métriques principales forment l'épine dorsale des tests de qualité de traduction :
| Mesure | Domaine de concentration | Cas d'utilisation & Seuil |
|---|---|---|
| BLEU | Précision N-gram | Contrôles rapides, scores ≥0.4 sont utilisables |
| TER | Distance d'édition | Niveau professionnel, <9% préféré |
| ROUGE | Mesure de rappel | Validation de contenu, plage 0.3-0.5 |
Les traductions ayant un score supérieur à 0.6 sur BLEU dépassent souvent la qualité humaine moyenne. Cependant, une étude de 2023 a souligné les limites de BLEU : BLEU à référence unique avait une faible corrélation avec les jugements humains (r=0,32), tandis que les configurations à références multiples ont mieux performé (r=0,68).
Nouvelles Métriques : COMET et MQM
Les cadres plus récents comblent les lacunes des métriques traditionnelles. COMET, propulsé par des réseaux neuronaux, évalue la sémantique et a atteint une forte corrélation de 0,81 avec les scores humains dans les benchmarks WMT2022 - bien meilleure que la corrélation de BLEU à 0,45.
MQM divise les erreurs en catégories telles que précision, fluidité et terminologie, en attribuant des poids de gravité. Cette approche détaillée est particulièrement utile pour les traductions au niveau entreprise.
Tests Machine vs. Humain
Une approche équilibrée combinant évaluation machine et humaine est essentielle. Les leaders de l'industrie ont adopté des flux de travail comme celui-ci :
"Filtrage initial TER → évaluation sémantique COMET → post-édition humaine pour les scores COMET <0.8 → révision finale par le client. Ce processus réduit les coûts d'évaluation de 40 % tout en maintenant une conformité de qualité de 98 %."
Pour le contenu hautement spécialisé, l'intervention humaine est indispensable. Les métriques émergentes se concentrent désormais sur des facteurs tels que la cohérence contextuelle et la capture du ton émotionnel, ouvrant la voie pour relever des défis pratiques. Ces avancées seront discutées plus en détail dans la prochaine section sur les problèmes courants de traduction.
Problèmes courants de traduction
Les données de l'industrie soulignent trois défis majeurs qui surviennent souvent :
Contexte et Signification
Un significatif 38 % des traductions évaluées avec des métriques BLEU de base nécessitent une intervention humaine lors du traitement des expressions idiomatiques. Ce problème est particulièrement prononcé dans les environnements professionnels.
"Une erreur de traduction dans un contrat de l'UE concernant 'conjointement et solidairement responsable' a causé des pertes de 2,8 M€, attribuées à l'entraînement incomplet des données juridiques. Une analyse post-incident a montré que l'ajout de 15 000 documents juridiques certifiés a réduit les erreurs similaires de 78 %"
Les outils comme l'analyseur de contexte vidéo de DubSmart ont atteint une précision contextuelle de 92 % en synchronisant les indications visuelles avec les dialogues traduits. Cette approche a notamment réduit les erreurs de traduction de genre de 63 %, grâce à son utilisation de la reconnaissance d'objets dans la scène.
Langues moins courantes
Les langues avec moins de ressources numériques rencontrent des obstacles uniques en matière de qualité de traduction. Voici un aperçu de l'impact de la disponibilité des ressources sur les performances :
| Niveau de Ressources | Impact sur la Qualité | Efficacité de la Solution |
|---|---|---|
| Langues à hautes ressources | Performance de base | Test standard suffisant |
| Langues à ressources moyennes | Réduction de 15 % de la qualité | La rétrotraduction aide |
| Langues à faibles ressources | Scores TER supérieurs de 22 % | Un apprentissage de transfert est nécessaire |
Une étude de cas sur la langue kurde montre que l'ajout de données des réseaux sociaux a amélioré l'exactitude de 45 %. De plus, l'apprentissage par transfert à partir de familles de langues connexes a montré qu'il pouvait réduire de 30 % les données d'entraînement nécessaires.
Qualité des données d'entraînement
La qualité des données d'entraînement joue un rôle crucial dans l'exactitude de la traduction, en particulier dans les domaines spécialisés. Une étude de 2024 a révélé que 68 % des erreurs de traduction médicale provenaient d'un biais envers la terminologie médicale occidentale dans les ensembles de données d'entraînement. Ce déséquilibre est éclatant, avec un ratio de 5:1 favorisant les termes occidentaux par rapport aux concepts de médecine traditionnelle.
Les traductions techniques rencontrent également des défis liés aux données obsolètes :
"Les glossaires techniques datant de plus de 3 ans montrent des taux d'erreur supérieurs de 22 %. Un projet de traduction de manuel de semi-conducteurs a nécessité des mises à jour mensuelles pour maintenir <2 % d'erreurs terminologiques"
Les systèmes d'apprentissage actif qui signalent les termes obsolètes se sont révélés efficaces, réduisant les charges de révision de 37 %, en particulier dans les domaines techniques.
Ces défis soulignent l'importance des méthodes de test pratiques couvertes dans la prochaine section pour garantir que la qualité des traductions demeure élevée.
Tests en pratique
Les méthodes de test pratiques abordent les défis des données d'entraînement et du contexte par le biais de quelques stratégies ciblées :
DubSmart Traduction Vidéo
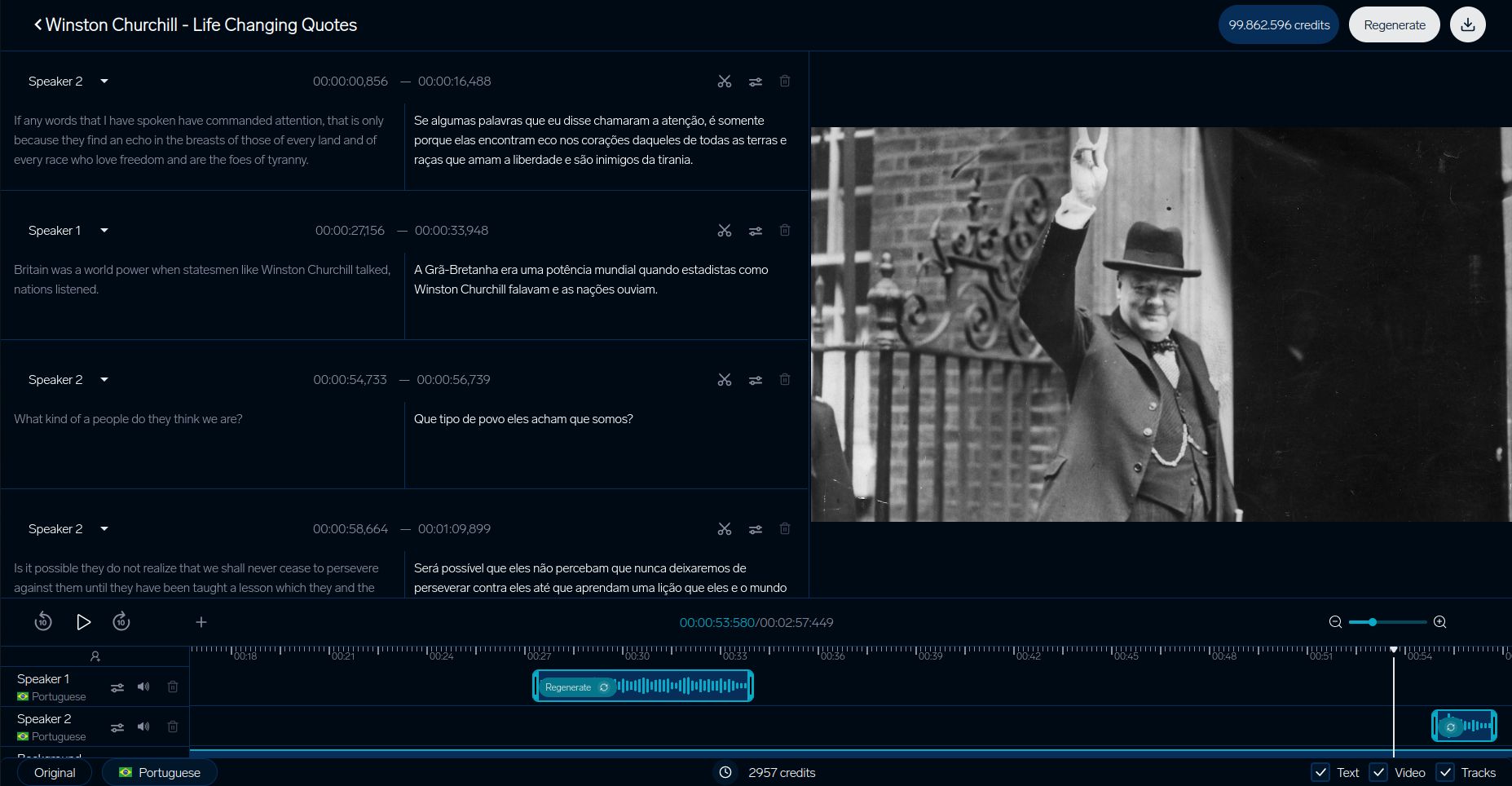
Le système de test de DubSmart met en lumière comment les plateformes de traduction vidéo garantissent la qualité. Leur processus détaillé se concentre sur l'alignement du contexte visuel, en s'attaquant particulièrement aux problèmes de mistraduction de genre abordés précédemment :
| Composant | Métrique |
|---|---|
| Synchronisation labiale | Moins de 200 ms de retard |
| Correspondance vocale | 93 % de similarité |
| Synchronisation visuelle | Moins de 5% de décalage |
Études de cas d'entreprises
Les grandes entreprises ont créé des systèmes de test avancés qui combinent des outils d'IA avec une expertise humaine. L'utilisation par SAP du cadre MQM-DQF est un exemple remarquable :
"En combinant la sortie MT neuronale avec des équipes de validation linguistique, SAP a réussi à réduire de 40 % l'effort de post-édition tout en maintenant des taux de précision de 98 %".
IKEA a rationalisé son processus de localisation de catalogue, réduisant le temps de mise sur le marché de 35 % grâce à une combinaison de validation humaine et IA.
Booking.com démontre également la puissance des tests automatisés. Leur système gère plus de 1 milliard de traductions chaque année dans 45 langues, réduisant les coûts de 40 % tout en maintenant une qualité cohérente pour le contenu généré par les utilisateurs.
Ces exemples montrent comment les entreprises améliorent l'exactitude, l'efficacité et l'évolutivité dans les tests de traduction.
sbb-itb-f4517a0
Prochaines étapes dans les tests de traduction
À mesure que les méthodes de test s'améliorent, trois domaines clés poussent les normes de qualité à de nouveaux niveaux :
Transfert du ton et des émotions
Les systèmes modernes sont désormais meilleurs pour préserver les nuances émotionnelles, grâce au cadre EMO-BLEU, qui a une corrélation de 0,73 avec la perception humaine comparée à 0,41 pour BLEU. Les modèles transformeurs multimodaux ont beaucoup progressé, gardant intactes les émotions des locuteurs. Ces systèmes peuvent maintenir des variations d'intensité dans les ±2dB à travers les langues tout en gérant des marqueurs émotionnels complexes.
Traduction basée sur le contexte
Les systèmes conscients du contexte redéfinissent la façon dont la qualité de la traduction est évaluée. Un excellent exemple est le Mode Contexte de DeepL, qui utilise un suivi d’entités au niveau du document et des ajustements de formalité en temps réel.
Les tests pour ces systèmes sont devenus plus avancés, se concentrant sur des benchmarks clés :
| Composant de Test | Benchmark Actuel | Focalisation de Mesure |
|---|---|---|
| Première réponse mots | <900 ms | Précision du début du discours |
| Qualité du flux | <4 mots de décalage | Consistance du tampon |
| Alignement contextuel | >0,8 score | Adaptation dynamique |
Ces systèmes traitent plus de 100 millions de paires de phrases contextuelles, complètes avec des annotations multicouches.
Systèmes d'IA d'apprentissage
Les systèmes de traduction qui s'améliorent eux-mêmes changent la façon dont la qualité est testée en intégrant des retours continus. Le cadre de Orq.ai met en évidence ce changement, réduisant les coûts de post-édition de 37 % trimestriellement à travers :
"Architectures d'apprentissage actif qui signalent les segments à faible confiance avec des scores COMET inférieurs à 0,6, présentant des alternatives via l'interface de typologie des erreurs MQM et mettant à jour les poids du modèle toutes les deux semaines à l'aide d'échantillons validés".
Ces systèmes identifient automatiquement les traductions à faible confiance (COMET <0,6) et mettent à jour leurs modèles toutes les deux semaines à l'aide d'échantillons validés par des linguistes. Cependant, ils rencontrent également des défis éthiques. Une recherche du MIT montre un décalage de 22 % dans la neutralité de genre sans mesures de décalage appropriées. Ce problème remonte à des problèmes liés aux données d'entraînement biaisées, soulignant la nécessité de protocoles de surveillance mis à jour.
Les outils industriels comme le TAUS Dynamic Quality Framework v3.1 aident à garantir que ces systèmes répondent aux normes évolutives.
Résumé
Principales Méthodes de Test
Les techniques de test modernes ont évolué au-delà du simple appariement d'ngrams et se concentrent désormais sur l'analyse contextuelle. Les mesures traditionnelles comme BLEU, TER et ROUGE fournissent toujours une base pour les évaluations de base. Cependant, des méthodes plus récentes telles que COMET et MQM se sont révélées être plus en phase avec le jugement humain.
Par exemple, le cadre EMO-BLEU a montré que les mesures automatisées peuvent atteindre une corrélation de 73 % avec le jugement humain lorsqu'elles évaluent comment le contenu émotionnel est préservé. Aujourd'hui, les tests de qualité mettent l'accent non seulement sur l'exactitude technique mais aussi sur l'importance de s'aligner avec les nuances culturelles, un objectif clé pour les mises en œuvre au niveau entreprise.
Outils et Ressources
Les tests de traduction modernes utilisent souvent des plateformes qui rassemblent plusieurs méthodes d'évaluation. Un exemple est DubSmart, qui offre une large gamme de fonctionnalités de test et de systèmes de vérification de contenu avancés.
Les composants clés d'un test efficace incluent :
- Portes de qualité basées sur COMET avec des seuils inférieurs à 0.6
- Glossaires qui ont été examinés pour leur pertinence culturelle
- Systèmes d'apprentissage actif mis à jour toutes les deux semaines
Pour les domaines spécialisés tels que le médical, le juridique et le contenu technique, le test combine des métriques générales avec des métriques spécifiques à l'industrie. Cette approche a conduit à une amélioration de 22 % de la qualité lorsqu'on utilise des systèmes d'évaluation combinés.
FAQ
Quels sont les inconvénients du score BLEU ?
Le score BLEU, bien qu'utilisé couramment, présente des limites notables lorsqu'il est appliqué à l'évaluation de la qualité de la traduction. Voici ses principales faiblesses :
| Limitation | Effet sur l'évaluation de la traduction |
|---|---|
| Cécité sémantique | Ne se concentre que sur les correspondances de mots, ignorant le sens ou le contexte |
| Pénalités de diversité phrastique | Pénalise les traductions valides qui utilisent une formulation différente des textes de référence |
Pour surmonter ces problèmes, de nombreuses plateformes de localisation vidéo utilisent un mélange de méthodes d'évaluation. Par exemple, l'analyseur de contexte de DubSmart combine plusieurs métriques pour fournir une évaluation plus précise.
"Bien que BLEU fournisse des mesures de base, des tests complets nécessitent une analyse sémantique et contextuelle - surtout pour les traductions critiques pour l'entreprise."
Pour une meilleure précision, les experts suggèrent :
- COMET pour évaluer le sens et la sémantique
- Validation humaine pour comprendre les nuances culturelles
- Outils spécifiques à la langue pour gérer les structures grammaticales complexes
Cette approche à plusieurs niveaux, comme celle utilisée par DubSmart, mélange les outils automatisés avec les perspectives humaines pour garantir que les traductions répondent aux normes techniques et contextuelles.