
Les modèles de reconnaissance vocale sont évalués sur leur capacité à transcrire correctement la parole et à conserver le sens dans différentes conditions. Les trois principales métriques utilisées sont :
- Taux d'Erreur de Mot (WER) : Mesure les erreurs de transcription (insertions, suppressions, substitutions). Meilleur pour l'audio clair mais a des difficultés avec le bruit ou les accents.
- Taux d'Erreur de Caractère (CER) : Suit la précision au niveau des caractères, idéal pour les langues comme le chinois ou le japonais.
- SeMaScore : Se concentre sur le sens sémantique, performant bien dans les environnements bruyants et avec des accents divers.
Comparaison Rapide des Métriques
| Métrique | Focus | Idéal pour | Limites |
|---|---|---|---|
| WER | Précision au niveau des mots | Parole propre | En difficulté avec le bruit/les accents |
| CER | Précision au niveau des caractères | Langues asiatiques | Pas de compréhension sémantique |
| SeMaScore | Conservation du sens sémantique | Audio bruyant, multilingue | Demande calculatoire plus élevée |
Des méthodes avancées comme la modélisation acoustique et la modélisation unifiée améliorent l'évaluation en simulant des conditions réelles. Ces métriques sont cruciales pour améliorer des outils comme les plateformes de transcription multilingues.
Principales Métriques pour l'Évaluation de la Reconnaissance Vocale
Les modèles de reconnaissance vocale utilisent des métriques spécifiques pour évaluer leur performance. Ces métriques aident les développeurs et les chercheurs à comprendre l'efficacité de leurs systèmes de Reconnaissance Automatique de la Parole (ASR) dans diverses conditions et langues.
Taux d'Erreur de Mot (WER)
Taux d'Erreur de Mot (WER) est l'une des métriques les plus largement utilisées pour mesurer la précision d'un système à transcrire la parole. Il identifie les erreurs dans trois catégories :
- Insertions : Mots ajoutés qui ne devraient pas être là.
- Suppressions : Mots manquants à la transcription.
- Substitutions : Mots incorrects remplaçant les bons.
L'objectif est d'obtenir un WER plus bas, car il reflète une meilleure précision. Cela dit, le WER peut avoir des inconvénients, surtout dans des situations avec du bruit de fond ou des schémas de paroles inhabituels.
Taux d'Erreur de Caractère (CER)
Taux d'Erreur de Caractère (CER) offre une analyse plus détaillée en se concentrant sur les caractères individuels plutôt que sur des mots entiers. Cela le rend particulièrement utile pour les langues comme le chinois ou le japonais, où les caractères portent un sens significatif.
Le CER est particulièrement efficace pour les systèmes multilingues ou les cas où les frontières des mots ne sont pas claires. Bien qu'il fournisse une analyse linguistique détaillée, des métriques plus récentes comme le SeMaScore visent à relever des défis plus larges liés au sens.
SeMaScore
SeMaScore va au-delà des métriques traditionnelles comme le WER et le CER en incorporant une couche sémantique dans le processus d'évaluation. Il mesure la capacité du système à conserver le sens voulu, et pas seulement les mots ou les caractères exacts.
Voici comment le SeMaScore se distingue dans des scénarios spécifiques :
| Type de Scénario | Comment SeMaScore Aide |
|---|---|
| Environnement Bruyant | S'aligne sur la perception humaine dans des environnements bruyants |
| Parole Atypique | Concorde avec les évaluations d'experts concernant le sens |
| Dialectes Complexes | Préserve l'exactitude sémantique à travers les dialectes |
Le SeMaScore est particulièrement utile pour évaluer les systèmes ASR dans des conditions difficiles, fournissant une évaluation plus large et plus significative de leur performance. Ensemble, ces métriques offrent un cadre équilibré pour comprendre comment les systèmes ASR se comportent dans différentes situations.
Méthodes Avancées pour Évaluer les Modèles ASR
Le processus d'évaluation des modèles de Reconnaissance Automatique de la Parole (ASR) a dépassé les métriques de base, utilisant des techniques plus avancées pour obtenir des insights plus profonds sur la performance de ces systèmes.
Le Rôle de la Modélisation Acoustique
La modélisation acoustique relie les signaux audio aux unités linguistiques en utilisant des représentations statistiques des caractéristiques de la parole. Son rôle dans l'évaluation de l'ASR dépend de plusieurs facteurs techniques :
| Facteur | Effet sur l'Évaluation |
|---|---|
| Taux d'Échantillonnage & Bits par Échantillon | Des valeurs plus élevées améliorent la précision de reconnaissance mais peuvent ralentir le traitement et augmenter la taille du modèle |
| Bruit Environnemental & Variations de Parole | Rend la reconnaissance plus difficile ; les modèles doivent être testés avec des données diverses et difficiles |
Les modèles acoustiques sont conçus pour gérer une variété de schémas de parole et de défis environnementaux, qui sont souvent manqués par les métriques d'évaluation traditionnelles.
Modélisation Unifiée dans l'ASR
Contrairement à la modélisation acoustique, qui se concentre sur des caractéristiques spécifiques de la parole, la modélisation unifiée combine plusieurs tâches de reconnaissance en un cadre unique. Cette approche améliore l'évaluation de l'ASR en reflétant des cas d'utilisation réels, où les systèmes traitent souvent plusieurs tâches à la fois.
Les facteurs importants pour l'évaluation incluent :
- Équilibrer la vitesse avec la précision
- Maintenir la performance sous une charge élevée
- Assurer une cohérence des résultats dans différents environnements
Plateformes comme DubSmart utilisent ces techniques avancées pour améliorer la reconnaissance vocale pour le contenu multilingue et le clonage de voix.
Ces méthodes fournissent une base pour comparer différentes métriques d'évaluation, éclairant leurs avantages et limitations.
Applications et Défis des Métriques d'Évaluation
Les métriques d'évaluation jouent un rôle essentiel dans l'amélioration des outils comme DubSmart et l'affrontement des défis continus dans les systèmes de reconnaissance automatique de la parole (ASR).
Utilisation dans les Outils d'IA comme DubSmart
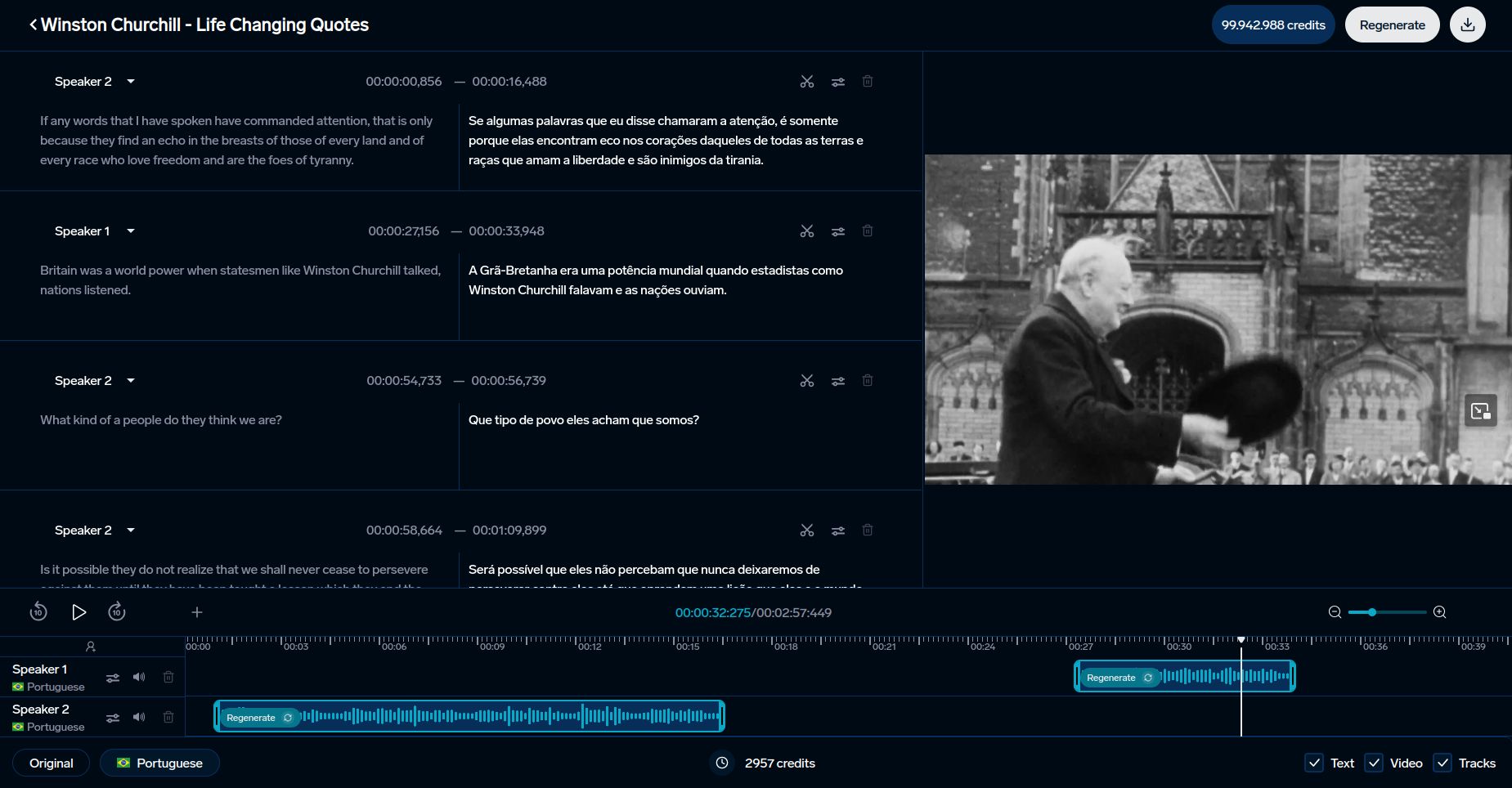
Les métriques de reconnaissance vocale sont essentielles pour améliorer les outils linguistiques pilotés par l'IA. DubSmart exploite ces métriques pour offrir des services de doublage et de transcription multilingues dans 33 langues. La plateforme intègre à la fois des métriques traditionnelles et avancées pour garantir la qualité :
| Métrique | Application | Impact |
|---|---|---|
| SeMaScore | Environnements Multilingues et Bruyants | Préserve l'exactitude sémantique et la conservation du sens |
Cette combinaison assure une précision élevée, même dans des scénarios difficiles comme le traitement de plusieurs locuteurs ou la gestion de l'audio complexe. L'exactitude sémantique est particulièrement importante pour des tâches telles que le clonage de voix et la génération de contenu multilingue.
Défis dans l'Évaluation de l'ASR
Les méthodes d'évaluation traditionnelles échouent souvent face aux accents, au bruit de fond ou aux variations dialectales. Des outils avancés comme le SeMaScore comblent ces lacunes en intégrant une analyse basée sur la sémantique. Le SeMaScore, en particulier, marque des progrès en combinant l'évaluation des taux d'erreur avec une compréhension sémantique plus profonde.
« Évaluer la reconnaissance vocale nécessite de trouver un équilibre entre la précision, la vitesse, et l'adaptabilité à travers les langues, accents, et environnements. »
Pour améliorer l'évaluation de l'ASR, plusieurs facteurs entrent en jeu :
- Améliorer les modèles acoustiques pour atteindre un équilibre entre précision et efficacité
- Répondre aux besoins de traitement en temps réel sans compromettre la précision
- Assurer une performance cohérente dans des contextes variés
Les techniques d'évaluation plus récentes visent à fournir des insights plus détaillés sur la performance de l'ASR, surtout dans des situations exigeantes. Ces avancées aident à affiner les outils pour de meilleures comparaisons de système et une efficacité générale accrue.
sbb-itb-f4517a0
Comparaison des Métriques d'Évaluation
Évaluer les systèmes de reconnaissance vocale revient souvent à choisir la métrique appropriée. Chacune met en lumière différents aspects de la performance, rendant crucial le bon choix en fonction de l'application spécifique.
Bien que le WER (Taux d'Erreur de Mot) et le CER (Taux d'Erreur de Caractère) soient bien établis, des options plus récentes comme le SeMaScore offrent une perspective plus large. Voici comment elles se comparent :
Tableau de Comparaison des Métriques
| Métrique | Performance de Précision | Compréhension Sémantique | Scénarios d'Utilisation | Vitesse de Traitement | Exigences de Calcul |
|---|---|---|---|---|---|
| WER | Élevée pour la parole propre, difficulté avec le bruit | Contexte sémantique limité | Évaluation standard de l'ASR, audio clair | Très rapide | Minimales |
| CER | Excellente pour l'analyse au niveau des caractères | Aucune analyse sémantique | Langues asiatiques, évaluation phonétique | Rapide | Basses |
| SeMaScore | Forte dans des conditions variées | Corrélation sémantique élevée | Environnements multilingues et bruyants | Moyenne | Moyennes à élevées |
WER fonctionne bien dans des scénarios audio propres mais rencontre des difficultés avec la parole bruyante ou accentuée en raison de son manque de profondeur sémantique. D'autre part, SeMaScore comble cette lacune en combinant l'analyse des erreurs avec une compréhension sémantique, le rendant mieux adapté pour des conditions de parole diversifiées et difficiles.
Alors que des outils comme DubSmart intègrent des systèmes ASR dans la transcription multilingue et le clonage de voix, le choix de la bonne métrique devient crucial. La recherche montre que SeMaScore performe mieux dans des environnements bruyants ou complexes, offrant une évaluation plus fiable.
En fin de compte, le choix dépend de facteurs tels que la complexité de la parole, la diversité des accents et les ressources disponibles. WER et CER sont excellents pour des tâches plus simples, tandis que SeMaScore est meilleur pour des évaluations plus nuancées, reflétant un changement vers des métriques qui s'alignent plus étroitement avec l'interprétation humaine.
Ces comparaisons montrent comment l'évaluation de l'ASR évolue, façonnant les outils et les systèmes qui s'appuient sur ces technologies.
Conclusion
La comparaison des métriques souligne comment l'évaluation de l'ASR a évolué et où elle se dirige. Les métriques se sont adaptées pour répondre aux exigences des systèmes ASR de plus en plus complexes. Bien que le Taux d'Erreur de Mot (WER) et le Taux d'Erreur de Caractère (CER) restent des points de repère clés, de nouvelles mesures comme le SeMaScore reflètent un accent sur la combinaison de la compréhension sémantique avec l'analyse traditionnelle des erreurs.
SeMaScore offre un équilibre entre la rapidité et la précision, en faisant un choix solide pour les applications pratiques. Les systèmes ASR modernes, tels que ceux utilisés par des plateformes comme DubSmart, doivent naviguer dans des scénarios réels difficiles, y compris des conditions acoustiques diverses et des besoins multilingues. Par exemple, DubSmart prend en charge la reconnaissance vocale dans 70 langues, démontrant la nécessité de méthodes d'évaluation avancées. Ces métriques non seulement améliorent la précision du système, mais aussi accroissent leur capacité à gérer des défis linguistiques et acoustiques variés.
À l'avenir, on s'attend à ce que les métriques futures combinent l'analyse des erreurs avec une compréhension plus profonde du sens. Alors que la technologie de reconnaissance vocale progresse, les méthodes d'évaluation doivent relever le défi des environnements bruyants, des accents variés et des schémas de paroles complexes. Ce changement influencera la façon dont les entreprises conçoivent et mettent en œuvre les systèmes ASR, en priorisant les métriques qui évaluent à la fois la précision et la compréhension.
Choisir la métrique appropriée est crucial, que ce soit pour de l'audio propre ou des scénarios multilingues complexes. Alors que la technologie ASR continue d'avancer, ces métriques en évolution joueront un rôle clé dans la conception de systèmes qui répondent mieux aux besoins de communication humaine.
FAQs
Quelle métrique est utilisée pour évaluer les programmes de reconnaissance vocale ?
La principale métrique pour évaluer les systèmes de Reconnaissance Automatique de la Parole (ASR) est le Taux d'Erreur de Mot (WER). Il calcule la précision de transcription en comparant le nombre d'erreurs (insertions, suppressions, et substitutions) au nombre total de mots dans la transcription originale. Une autre méthode, le SeMaScore, se concentre sur l'évaluation sémantique, offrant de meilleurs insights dans des scénarios difficiles, comme la parole accentuée ou bruyante.
Comment évalue-t-on un modèle ASR ?
L'évaluation d'un modèle ASR implique l'utilisation d'un mélange de métriques pour mesurer à la fois l'exactitude de transcription et la conservation du sens. Cela garantit que le système fonctionne de manière fiable dans diverses situations.
| Composant d'Évaluation | Description | Meilleure Pratique |
|---|---|---|
| Taux d'Erreur de Mot (WER) | Suit l'exactitude au niveau des mots par rapport aux transcriptions humaines | Calculer le ratio d'erreurs (insertions, suppressions, substitutions) au total des mots |
| Taux d'Erreur de Caractère (CER) | Se concentre sur la précision au niveau des caractères | Idéal pour les langues comme le chinois ou le japonais |
| Compréhension Sémantique | Vérifie si le sens est préservé | Utiliser le SeMaScore pour une évaluation sémantique plus profonde |
| Tests en Conditions Réelles | Évalue la performance dans des environnements diversifiés (par exemple, bruyants, multilingues) | Tester dans divers environnements acoustiques |
« L'évaluation de l'ASR s'est traditionnellement appuyée sur des métriques basées sur les erreurs. »
Lors de l'évaluation des modèles ASR, considérez ces facteurs pratiques en plus des métriques de précision :
- Performance dans différents environnements sonores
- Gestion des accents et des dialectes
- Capacité de traitement en temps réel
- Robustesse contre le bruit de fond
Adaptez le processus d'évaluation à votre application spécifique tout en respectant les standards de l'industrie. Par exemple, des plateformes comme DubSmart mettent l'accent sur l'exactitude sémantique pour le contenu multilingue, rendant ces méthodes d'évaluation particulièrement pertinentes.