
Key Takeaways:
- Why It Matters: Translation quality impacts trust, compliance, and revenue. Industries like medical (99.9% accuracy) and legal (98% accuracy) require precision.
-
Main Testing Goals:
- Semantic Accuracy: Tools like COMET align with human ratings 89% of the time.
- Terminology Consistency: Legal fields demand 99.5% term consistency.
- Cultural Adaptation: Tailored content can increase user retention by 34%.
-
Metrics & Tools:
- Traditional: BLEU, TER, ROUGE (e.g., BLEU ≥0.4 for usability).
- Advanced: COMET (0.81 correlation with human scores) and MQM for detailed error categorization.
-
Challenges:
- Contextual errors, low-resource languages, and outdated training data.
- Example: Adding social media data improved Kurdish translation accuracy by 45%.
-
Solutions:
- Active learning systems reduce errors by flagging low-confidence outputs.
- Combining AI tools with human oversight improves defect detection rates to 91%.
Quick Comparison of Metrics:
| Metric | Focus Area | Use Case & Threshold |
|---|---|---|
| BLEU | N-gram precision | Quick checks, scores ≥0.4 |
| TER | Edit distance | Professional-grade, <9% pref |
| ROUGE | Recall measurement | Content validation, 0.3-0.5 |
| COMET | Semantic evaluation | Strong correlation (0.81) |
| MQM | Error categorization | Enterprise-level detail |
This guide explains how businesses can combine automation and human expertise to achieve scalable, accurate, and culturally relevant translations.
Quality Measurement Metrics
Modern tools blend automation with human expertise to deliver accurate and context-aware translations. These metrics are designed to meet key objectives like semantic accuracy, terminology consistency, and adapting to cultural nuances.
Basic Metrics: BLEU, TER, ROUGE
Three core metrics form the backbone of translation quality testing:
| Metric | Focus Area | Use Case & Threshold |
|---|---|---|
| BLEU | N-gram precision | Quick checks, scores ≥0.4 are usable |
| TER | Edit distance | Professional-grade, <9% preferred |
| ROUGE | Recall measurement | Content validation, 0.3-0.5 range |
Translations scoring above 0.6 on BLEU often exceed average human quality. However, a 2023 study highlighted BLEU’s limitations: single-reference BLEU had a weak correlation with human judgments (r=0.32), while multi-reference setups performed better (r=0.68).
New Metrics: COMET and MQM
Newer frameworks address gaps in traditional metrics. COMET, powered by neural networks, evaluates semantics and achieved a strong 0.81 correlation with human scores in WMT2022 benchmarks - far better than BLEU’s 0.45 correlation.
MQM breaks errors into categories like accuracy, fluency, and terminology, assigning severity weights. This detailed approach is especially useful for enterprise-level translations.
Machine vs. Human Testing
A balanced approach combining machine and human evaluation is essential. Industry leaders have adopted workflows like this:
"Initial TER filtering → COMET semantic evaluation → human post-editing for COMET scores <0.8 → final client review. This process reduces evaluation costs by 40% while maintaining 98% quality compliance."
For highly specialized content, human involvement is indispensable. Emerging metrics now focus on factors like contextual consistency and capturing emotional tone, paving the way for tackling practical challenges. These advancements will be discussed further in the next section on Common Translation Issues.
Common Translation Issues
Industry data points to three major challenges that often arise:
Context and Meaning
A significant 38% of translations assessed with basic BLEU metrics need human intervention when dealing with idiomatic expressions. This issue is especially pronounced in professional environments.
"An EU contract mistranslation of 'jointly and severally liable' caused €2.8M losses, traced to incomplete legal training data. Post-incident analysis showed adding 15k certified legal documents reduced similar errors by 78%"
Tools like DubSmart's video context analyzer have achieved 92% contextual accuracy by syncing visual cues with translated dialogue. This approach has notably reduced gender mistranslations by 63%, thanks to its use of scene-object recognition.
Less Common Languages
Languages with fewer digital resources face unique hurdles in translation quality. Here's a breakdown of how resource availability impacts performance:
| Resource Level | Impact on Quality | Solution Effectiveness |
|---|---|---|
| High-resource Languages | Baseline performance | Standard testing sufficient |
| Mid-resource Languages | 15% quality reduction | Back-translation helps |
| Low-resource Languages | 22% higher TER scores | Transfer learning needed |
A Kurdish language case study highlights how adding social media data improved accuracy by 45%. Additionally, transfer learning from related language families has shown to cut the required training data by 30%.
Training Data Quality
The quality of training data plays a crucial role in translation accuracy, particularly in specialized fields. A 2024 study found that 68% of medical translation errors stemmed from a bias toward Western medical terminology in training datasets. This imbalance is stark, with a 5:1 ratio favoring Western terms over traditional medicine concepts.
Technical translations also encounter challenges tied to outdated data:
"Technical glossaries older than 3 years show 22% higher error rates. A semiconductor manual translation project required monthly updates to maintain <2% term errors"
Active learning systems that flag outdated terms have proven effective, reducing revision workloads by 37%, especially in technical domains.
These challenges underline the importance of the practical testing methods covered in the next section to ensure translation quality remains high.
Testing in Practice
Practical testing methods address the challenges of training data and context through a few focused strategies:
DubSmart Video Translation
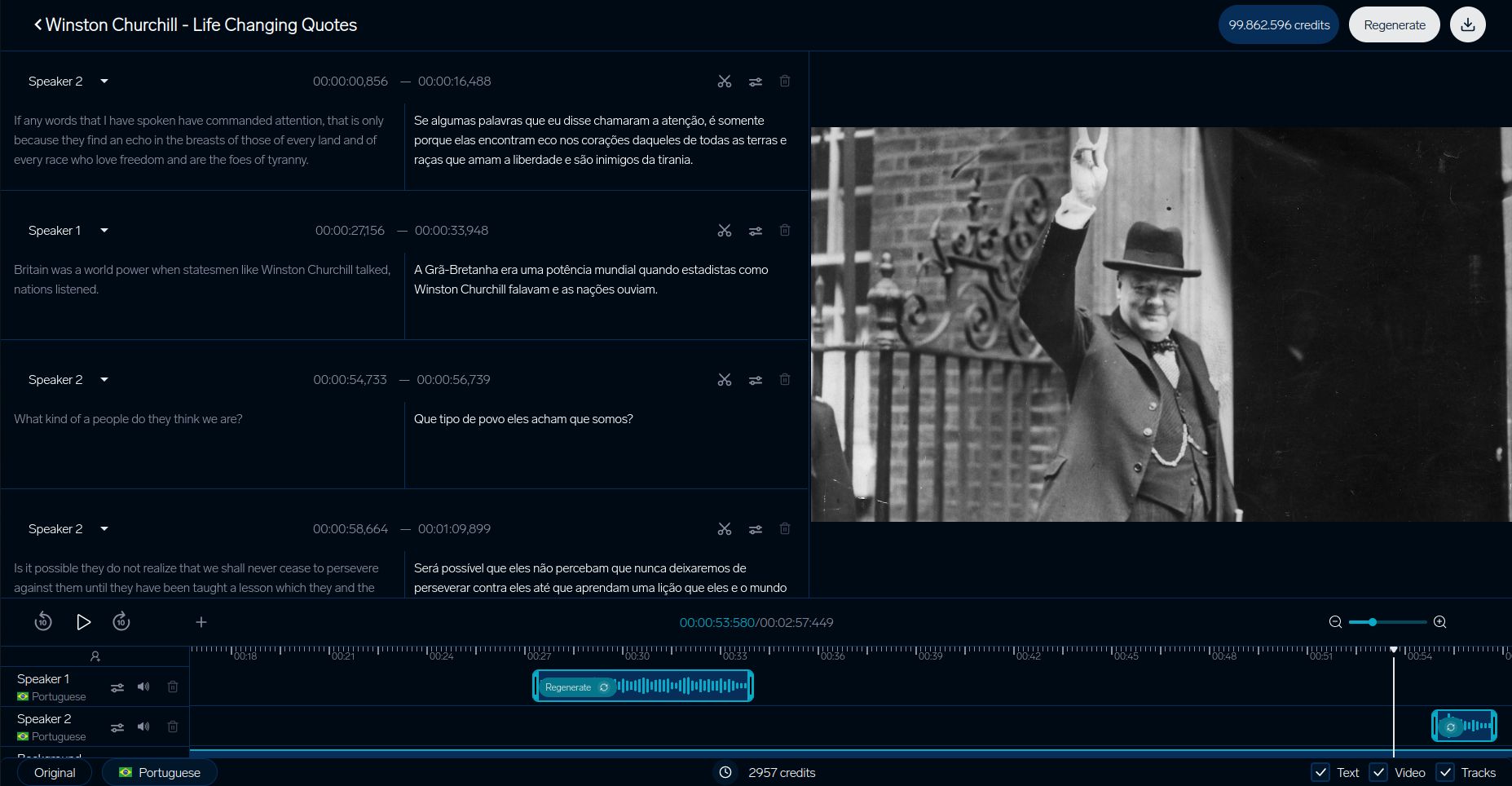
DubSmart's testing system highlights how video translation platforms ensure quality. Their detailed process focuses on aligning visual context, especially tackling gender mistranslation issues discussed earlier:
| Component | Metric |
|---|---|
| Lip-sync | Less than 200ms delay |
| Voice Match | 93% similarity |
| Visual Sync | Less than 5% mismatch |
Business Case Studies
Large companies have created advanced testing systems that combine AI tools with human expertise. SAP's use of the MQM-DQF framework is a standout example:
"By combining neural MT output with linguist validation teams, SAP achieved a 40% reduction in post-editing effort while maintaining 98% accuracy rates".
IKEA streamlined its catalog localization process, cutting time-to-market by 35% through a mix of human and AI validation.
Booking.com also demonstrates the power of automated testing. Their system handles over 1 billion translations each year across 45 languages, reducing costs by 40% while keeping quality consistent for user-generated content.
These examples highlight how businesses are improving accuracy, efficiency, and scalability in translation testing.
sbb-itb-f4517a0
Next Steps in Translation Testing
As testing methods improve, three key areas are pushing quality standards to new levels:
Tone and Emotion Transfer
Modern systems are now better at preserving emotional nuances, thanks to the EMO-BLEU framework, which has a 0.73 Pearson correlation with human perception compared to BLEU's 0.41. Multi-modal transformer models have advanced significantly, keeping speaker emotions intact. These systems can maintain intensity variations within ±2dB across languages while managing complex emotional markers.
Context-Based Translation
Context-aware systems are reshaping how translation quality is assessed. A great example is DeepL's Context Mode, which uses document-level entity tracking and real-time formality adjustments.
Testing for these systems has become more advanced, focusing on key benchmarks:
| Testing Component | Current Benchmark | Measurement Focus |
|---|---|---|
| First-word Response | <900ms | Speech onset accuracy |
| Streaming Quality | <4 word lag | Buffer consistency |
| Context Alignment | >0.8 score | Dynamic adaptation |
These systems handle over 100 million contextual sentence pairs, complete with layered annotations.
Learning AI Systems
Translation systems that improve themselves are changing how quality is tested by integrating continuous feedback. Orq.ai's framework highlights this shift, cutting post-editing costs by 37% quarterly through:
"Active learning architectures that flag low-confidence segments with COMET scores below 0.6, presenting alternatives via MQM error typology UI and updating model weights bi-weekly using validated samples".
These systems automatically identify low-confidence translations (COMET <0.6) and update their models every two weeks using samples validated by linguists. However, they also face ethical challenges. Research from MIT shows a 22% drift in gender neutrality without proper debiasing measures. This issue ties back to problems with biased training data, underscoring the need for updated monitoring protocols.
Industry tools like the TAUS Dynamic Quality Framework v3.1 help ensure these systems meet evolving standards.
Summary
Key Testing Methods
Modern testing techniques have grown beyond simple n-gram matching and now focus on contextual analysis. Traditional metrics like BLEU, TER, and ROUGE still provide a foundation for baseline evaluations. However, newer methods such as COMET and MQM have proven to align more closely with human judgment.
For example, the EMO-BLEU framework has shown that automated metrics can achieve a 73% correlation with human judgment when evaluating how well emotional content is preserved. Today, quality testing emphasizes not only technical accuracy but also the importance of aligning with cultural nuances, a key goal for enterprise-level implementations.
Tools and Resources
Modern translation testing often uses platforms that bring together multiple evaluation methods. One example is DubSmart, which offers a wide range of testing features and advanced content verification systems.
Key components of effective testing include:
- COMET-based quality gates with thresholds below 0.6
- Glossaries that have been reviewed for cultural relevance
- Active learning systems updated every two weeks
For specialized fields like medical, legal, and technical content, testing combines general metrics with industry-specific ones. This approach has led to a 22% improvement in quality when using combined evaluation systems.
FAQs
What are the disadvantages of the BLEU score?
The BLEU score, while widely used, has notable limitations when applied to translation quality assessment. Here are its main weaknesses:
| Limitation | Effect on Translation Assessment |
|---|---|
| Semantic Blindness | Focuses only on word matches, ignoring meaning or context |
| Phrasing Diversity Penalties | Penalizes valid translations that use different phrasing from reference texts |
To address these issues, many video localization platforms use a mix of evaluation methods. For example, DubSmart's context analyzer combines multiple metrics to provide a more accurate assessment.
"While BLEU provides baseline measurements, comprehensive testing requires semantic and contextual analysis - especially for business-critical translations."
For better accuracy, experts suggest:
- COMET for evaluating meaning and semantics
- Human validation for understanding cultural nuances
- Language-specific tools for handling complex grammar structures
This layered approach, as used by DubSmart, blends automated tools with human insights to ensure translations meet both technical and contextual standards.