
النقاط الرئيسية:
- لماذا يهم: تؤثر جودة الترجمة على الثقة والامتثال والإيرادات. تحتاج صناعات مثل الطبية (99.9% دقة) والقانونية (98% دقة) إلى الدقة.
-
الأهداف الرئيسية للاختبار:
- الدقة الدلالية: تتماشى أدوات مثل COMET مع تقييمات البشر بنسبة 89% من الوقت.
- الاتساق في المصطلحات: تتطلب المجالات القانونية اتساق في المصطلحات بنسبة 99.5%.
- التكيف الثقافي: يمكن أن يزيد المحتوى المخصص من احتفاظ المستخدمين بنسبة 34%.
-
المقاييس والأدوات:
- تقليدي: BLEU، TER، ROUGE (مثال: BLEU ≥0.4 للاستخدامية).
- متقدم: COMET (ارتباط 0.81 مع تقييمات البشر) و MQM لتصنيف الأخطاء بشكل مفصل.
-
التحديات:
- الأخطاء السياقية، واللغات ذات الموارد المحدودة، وبيانات التدريب القديمة.
- مثال: أدى إضافة بيانات وسائل التواصل الاجتماعي إلى تحسين دقة الترجمة للكردية بنسبة 45%.
-
الحلول:
- تقلل أنظمة التعلم النشط من الأخطاء عن طريق تحديد المخرجات التي تفتقر إلى الثقة.
- الجمع بين أدوات الذكاء الاصطناعي والإشراف البشري يعزز من معدلات الكشف عن العيوب حتى 91%.
مقارنة سريعة للمقاييس:
| المقياس | مجال التركيز | الحالة والاستخدام & الحد الأدنى |
|---|---|---|
| BLEU | دقة N-gram | التحقق السريع، درجات ≥0.4 |
| TER | مسافة التعديل | مستوى احترافي، <9% مفضل |
| ROUGE | قياس الاسترجاع | تحقق من المحتوى، مدى 0.3-0.5 |
| COMET | التقييم الدلالي | ارتباط قوي (0.81) |
| MQM | تصنيف الأخطاء | تفاصيل على مستوى المؤسسات |
يشرح هذا الدليل كيف يمكن للشركات دمج الأتمتة والخبرة البشرية لتحقيق ترجمات دقيقة وقابلة للتوسع وذات صلة ثقافية.
مقاييس قياس الجودة
تمزج الأدوات الحديثة بين الأتمتة والخبرة البشرية لتقديم ترجمات دقيقة ومدركة للسياق. تم تصميم هذه المقاييس لتلبية أهداف رئيسية مثل الدقة الدلالية، والاستمرارية في المصطلحات، والتكيف مع الفروقات الثقافية.
المقاييس الأساسية: BLEU، TER، ROUGE
تشكل ثلاثة مقاييس رئيسية العمود الفقري لاختبار جودة الترجمة:
| المقياس | مجال التركيز | الحالة والاستخدام & الحد الأدنى |
|---|---|---|
| BLEU | دقة N-gram | تحقق سريع، درجات ≥0.4 قابلة للاستخدام |
| TER | مسافة التعديل | مستوى احترافي، <9% مفضل |
| ROUGE | قياس الاسترجاع | تحقق من المحتوى، مدى 0.3-0.5 |
غالبًا تتجاوز الترجمات التي تسجل فوق 0.6 في BLEU الجودة البشرية المتوسطة. ومع ذلك، سلطت دراسة عام 2023 الضوء على قيود BLEU: أظهرت إعدادات BLEU الفردية مرجعًا ضعيفًا مع أحكام البشر (r=0.32)، بينما أظهرت الإعدادات متعددة المرجع أداءً أفضل (r=0.68).
مقاييس جديدة: COMET و MQM
تعالج الأطر الجديدة الثغرات في المقاييس التقليدية. COMET، مدعوم بالشبكات العصبية، يقيم الدلالات وحقق ارتباطًا قويًا يبلغ 0.81 مع درجات البشر في معايير WMT2022 - أفضل بكثير من ارتباط BLEU الذي يبلغ 0.45.
MQM يقسم الأخطاء إلى فئات مثل الدقة والطلاقة والمصطلحات، ويعين أوزان شدة. هذه الطريقة المفصلة مفيدة بشكل خاص لترجمات على مستوى المؤسسات.
اختبار الآلة مقابل اختبار الإنسان
النهج المتوازن الذي يجمع بين التقييم الآلي والبشري أساسي. لقد تبنى قادة الصناعة تدفقات العمل مثل:
"تصفية TER الأولية → تقييم COMET الدلالي → التحرير البشري لما بعد للتنسيقات برتب COMET <0.8 → المراجعة النهائية للعميل. تخفض هذه العملية تكلفة التقييم بنسبة 40% مع الحفاظ على الامتثال لجودة 98%."
بالنسبة للمحتوى المتخصص بدرجة عالية، لا غنى عن التدخل البشري. تركز المقاييس الناشئة الآن على عوامل مثل الاتساق السياقي والحفاظ على النغمة العاطفية، مما يمهد الطريق لمواجهة التحديات العملية. سيتم مناقشة هذه التطورات بشكل أكبر في القسم التالي حول مشاكل الترجمة الشائعة.
مشاكل الترجمة الشائعة
تظهر البيانات الصناعية ثلاث تحديات رئيسية تنشأ غالبًا:
السياق والمعنى
تحتاج نسبة كبيرة 38% من الترجمات التي تم تقديرها باستخدام مقاييس BLEU الأساسية إلى تدخل بشري عند التعامل مع تعبيرات اصطلاحية. هذه المشكلة بارزة بشكل خاص في البيئات المهنية.
"تسبب خطأ في الترجمة لعقد في الاتحاد الأوروبي لمصطلح "معا وعلى نحو منفصل مسؤول" بخسائر مقدارها €2.8 مليون، تم تتبعها إلى بيانات تدريب قانونية غير مكتملة. أظهرت التحليلات بعد الحادث أن إضافة 15 ألف وثيقة قانونية معتمدة قللت من الأخطاء المماثلة بنسبة 78%"
حققت أدوات مثل محلل الفيديو السياقي DubSmart دقة سياقية بنسبة 92% بمزامنة المؤشرات المرئية مع الحوار المترجم. وقد ساعد هذا النهج في تقليل أخطاء الترجمة الخاصة بالجنس بنسبة 63%، وذلك بفضل استخدامه لتعرف الأشياء في المشهد.
اللغات الأقل شيوعًا
تواجه اللغات التي تحتوي على موارد رقمية أقل عقبات فريدة في جودة الترجمة. إليك تفصيل لكيفية تأثير توافر الموارد على الأداء:
| مستوى الموارد | تأثير على الجودة | فعالية الحل |
|---|---|---|
| لغات ذات موارد عالية | الأداء الأساسي | الاختبار القياسي كافٍ |
| لغات ذات موارد متوسطة | 15% انخفاض في الجودة | الترجمة الخلفية تساعد |
| لغات ذات موارد منخفضة | 22% أعلى من درجات TER | يحتاج إلى التعلم الانتقالي |
تسلط دراسة حالة للغة الكردية الضوء على كيفية إضافة بيانات وسائل التواصل الاجتماعي لتحسين الدقة بنسبة 45%. بالإضافة إلى ذلك، أظهر التعلم الانتقالي من عائلات اللغات ذات الصلة القدرة على تقليل بيانات التدريب المطلوبة بنسبة 30%.
جودة بيانات التدريب
تلعب جودة بيانات التدريب دورًا حيويًا في دقة الترجمة، خاصة في المجالات المتخصصة. وجدت دراسة 2024 أن 68% من أخطاء الترجمة الطبية ناتجة عن تحيز تجاه المصطلحات الطبية الغربية في مجموعات بيانات التدريب. يعكسهذا الخلل بشكل واضح نسبة 5:1 تفضل المصطلحات الغربية على مفاهيم الطب التقليدي.
تواجه الترجمات التقنية أيضًا تحديات مرتبطة بالبيانات القديمة:
"تظهر المسارد التقنية القديمة بأكثر من 3 سنوات زيادة بنسبة 22% في معدلات الخطأ. تطلب مشروع ترجمة دليل أشباه الموصلات تحديثات شهرية للحفاظ على <2% أخطاء المصطلح"
أثبتت الأنظمة النشطة لتعلم الآلات التي تحدد المصطلحات المتقادمة فعاليتها، مما يقلل من أعباء المراجعة بنسبة 37%، خاصة في المجالات التقنية.
تؤكد هذه التحديات على أهمية طرق الاختبار العملية التي تمت مناقشتها في القسم التالي لضمان بقاء جودة الترجمة عالية.
الاختبار في الممارسة العملية
تعالج طرق الاختبار العملية تحديات بيانات التدريب والسياق من خلال بعض الاستراتيجيات المركزة:
DubSmart ترجمة الفيديو
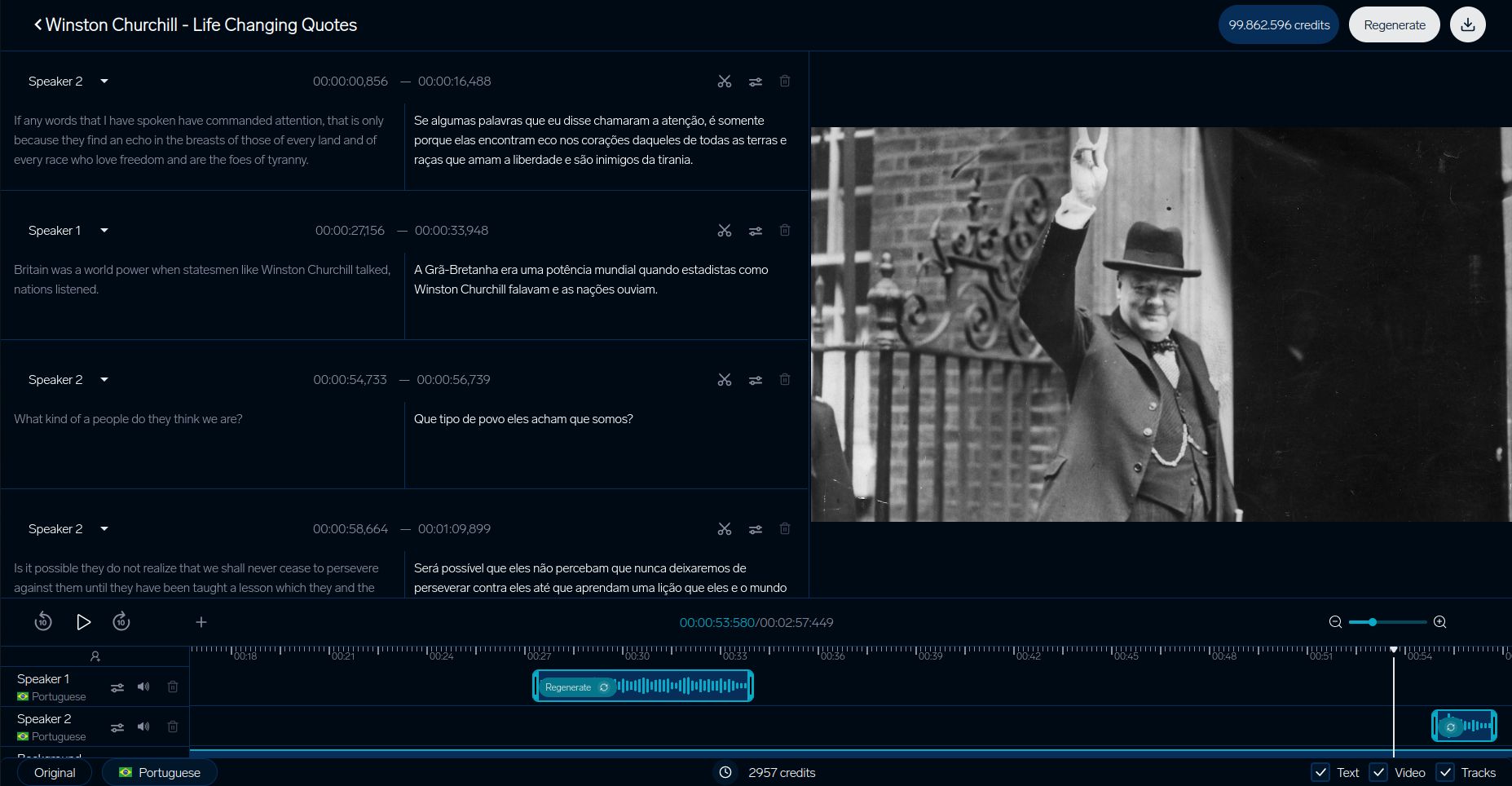
يسلط نظام اختبار DubSmart الضوء على كيفية ضمان منصات ترجمة الفيديو للجودة. يركز عملية المفصلة على مواءمة السياق البصري، خاصة معالجة قضايا الترجمة الخاطئة للجنس التي تمت مناقشتها سابقًا:
| المكون | المقياس |
|---|---|
| التزامن مع الشفاه | أقل من 200 مللي ثانية تأخير |
| التطابق الصوتي | 93% تشابه |
| التزامن البصري | أقل من 5% عدم تطابق |
دراسات حالة الأعمال
أنشأت الشركات الكبرى أنظمة اختبار متقدمة تجمع بين أدوات الذكاء الاصطناعي والخبرة البشرية. يعد استخدام SAP لإطار العمل MQM-DQF مثالًا بارزًا:
"من خلال الجمع بين مخرجات الترجمة الآلية العصبية وفريق تحقق لغوي، تمكنت SAP من تقليل جهد التحرير اللاحق بنسبة 40% مع الحفاظ على معدلات دقة 98%".
اختصرت IKEA عملية توطين الكتالوج الخاص بها، وتقليل الوقت المستغرق للوصول إلى السوق بنسبة 35% من خلال مزيج من التحقق البشري والذكاء الاصطناعي.
Booking.com توضح أيضًا قوة الاختبار الآلي. يتعامل نظامهم مع أكثر من مليار ترجمة كل عام عبر 45 لغة، مما يقلل من التكاليف بنسبة 40% مع الحفاظ على الجودة ثابتة للمحتوى الذي ينشئه المستخدم.
توضح هذه الأمثلة كيف تحسن الشركات الدقة والكفاءة وقابلية التوسع في اختبار الترجمة.
sbb-itb-f4517a0
الخطوات التالية في اختبار الترجمة
مع تحسن طرق الاختبار، تدفع ثلاث مجالات رئيسية المعايير الجودة إلى مستويات جديدة:
نقل النغمة والعاطفة
الأنظمة الحديثة أصبحت أفضل في الحفاظ على الفروق العاطفية، بفضل إطار العمل EMO-BLEU، الذي لديه ارتباط بيرسون 0.73 مع تصور البشر مقارنة بـ BLEU الذي يبلغ 0.41. تقدمت نماذج المحولات متعددة الوسائط بشكل كبير، واحتفظت بعواطف المتحدثين. يمكن لهذه الأنظمة الاحتفاظ بتفاوتات الكثافة ضمن ±2 ديسيبل عبر اللغات مع إدارة العلامات العاطفية المعقدة.
الترجمة المعتمدة على السياق
تعيد الأنظمة المدركة للسياق تشكيل كيفية تقييم جودة الترجمة. يعد وضع السياق في DeepL مثالًا رائعًا، حيث يستخدم تتبع الكيانات على مستوى المستند وتعديلات الفورية في الرسالة الخطابية.
أصبح الاختبار لهذه الأنظمة أكثر تقدمًا، مع التركيز على المعايير الأساسية:
| مكون الاختبار | المعيار الحالي | التركيز في القياس |
|---|---|---|
| استجابة الكلمة الأولى | <900 مللي ثانية | دقة بداية الكلام |
| جودة البث | <4 كلمات تأخير | اتساق المخزن المؤقت |
| توافق السياق | >0.8 نقطة | التكيف الديناميكي |
تتعامل هذه الأنظمة مع أكثر من 100 مليون زوج من الجمل السياقية، كاملة مع طبقات التعليقات التوضيحية.
أنظمة الذكاء الاصطناعي التي تتعلم
تغير الأنسظمة المترجمة التي تحسن نفسها كيفية اختبار الجودة بدمج التغذية الراجعة المستمرة. يسلط إطار العمل Orq.ai الضوء على هذا التحول، مما يقلل من تكاليف التحرير اللاحقة بنسبة 37% ربع سنويًا من خلال:
"بنية التعلم النشط التي تحدد القطع ذات الثقة المنخفضة برتب COMET أقل من 0.6، وتقديم بدائل عبر واجهة نوعية MQM، وتحديث أوزان النموذج كل أسبوعين باستخدام العينات المصادق عليها".
تقوم هذه الأنظمة تلقائيًا بتحديد الترجمات ذات الثقة المنخفضة (COMET <0.6) وتحديث نماذجها كل أسبوعين باستخدام العينات التي تحققها اللغويين. ومع ذلك، فهي تواجه أيضًا تحديات أخلاقية. أبحاث من MIT تظهر 22% انحراف في الحيادية الجنسية بدون إجراءات تصحيحية مناسبة. يرتبط هذا المشكلة بمشاكل مع البيانات التدريبية المتحيزة، مما يبرز الحاجة لمراقبة البروتوكولات المحدثة.
تساعد أدوات الصناعة مثل TAUS إطار الجودة الديناميكي v3.1 لضمان تلبية هذه الأنظمة للمعايير المتطورة.
ملخص
طرق الاختبار الرئيسية
تجاوزت تقنيات الاختبار الحديثة مطابقة النغرامات البسيطة وتركز الآن على التحليل السياقي. لا تزال المقاييس التقليدية مثل BLEU، TER، و ROUGE توفر أساسًا للتقييمات الأساسية. ومع ذلك، أثبتت الأساليب الأحدث مثل COMET و MQM أنها تتماشى بشكل أقرب مع حكم البشر.
على سبيل المثال، أظهر إطار العمل EMO-BLEU أن المقاييس الآلية يمكن أن تحقق ارتباطًا بنسبة 73% مع حكم البشر عند تقييم مدى حفظ المحتوى العاطفي. اليوم، يؤكد اختبار الجودة على ليس فقط الدقة الفنية ولكن أيضًا أهمية مواءمة الفروق الثقافية، وهو هدف رئيسي للتطبيقات على مستوى المؤسسات.
الأدوات والموارد
غالبًا ما تستخدم اختبار الترجمة الحديثة منصات تجمع بين أساليب التقييم المتعددة. يعد DubSmart مثالًا، حيث يقدم مجموعة واسعة من ميزات الاختبار وأنظمة التحقق من المحتوى المتقدمة.
تشمل المكونات الرئيسية لاختبار فعال:
- بوابات الجودة المستندة إلى COMET مع حدود منخفضة عن 0.6
- مسارد تم مراجعتها من حيث الملاءمة الثقافية
- نظم تعلم نشطة يتم تحديثها كل أسبوعين
بالنسبة للمجالات المتخصصة مثل المحتوى الطبي والقانوني والتقني، يجمع الاختبار بين المقاييس العامة وتلك الخاصة بالصناعة. أدى هذا النهج إلى تحسين الجودة بنسبة 22% عند استخدام أنظمة التقييم المشتركة.
الأسئلة الشائعة
ما هي عيوب درجة BLEU؟
درجة BLEU، رغم استخدامها الواسع، لديها محدوديات ملحوظة عند تطبيقها لتقييم جودة الترجمة. إليكم أبرز سلبياتها:
| الحد | التأثير على تقييم الترجمة |
|---|---|
| عمى الدلالات | يركز فقط على مطابقات الكلمات، متجاهلاً المعنى أو السياق |
| العقوبات على تنوع الصياغات | يعاقب على الترجمات الصحيحة التي تستخدم صياغات مختلفة عن النصوص المرجعية |
لمعالجة هذه القضايا، تستخدم العديد من منصات توطين الفيديو مزيجًا من أساليب التقييم. على سبيل المثال، يجمع محلل السياق DubSmart بين عدة مقاييس لتقديم تقييم أدق.
"بينما يوفر BLEU قياسات أساسية، يتطلب الاختبار الشامل التحليل الدلالي والسياقي - خاصة للترجمات المهمة للأعمال."
لتحقيق دقة أفضل، يقترح الخبراء:
- COMET لتقييم المعنى والدلالات
- التحقق البشري لفهم الفروق الثقافية
- أدوات خاصة باللغة لمعالجة الهياكل النحوية المعقدة
هذا النهج المجمع، كما يستخدمه DubSmart، يمزج بين الأدوات الآلية والبصيرة البشرية لضمان أن الترجمات تلبي المعايير الفنية والسياقية.